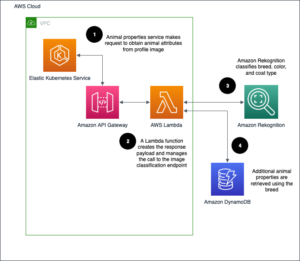
محققان به توسعه معماری مدل های جدید برای وظایف رایج یادگیری ماشین (ML) ادامه می دهند. یکی از این کارها طبقه بندی تصویر است که در آن تصاویر به عنوان ورودی پذیرفته می شوند و مدل سعی می کند تصویر را به عنوان یک کل با خروجی های برچسب شی طبقه بندی کند. با بسیاری از مدلهای موجود امروزه که این وظیفه طبقهبندی تصویر را انجام میدهند، یک متخصص ML ممکن است سؤالاتی از این قبیل بپرسد: «چه مدلی را باید تنظیم کنم و سپس برای دستیابی به بهترین عملکرد در مجموعه دادهام، آن را به کار ببرم؟» و یک محقق ML ممکن است سؤالاتی از این قبیل بپرسد: "چگونه می توانم مقایسه منصفانه خود را از معماری های چندگانه مدل در برابر یک مجموعه داده مشخص ایجاد کنم، در حالی که فراپارامترهای آموزشی و مشخصات رایانه مانند GPU، CPU و RAM را کنترل می کنم؟" سوال اول به انتخاب مدل در معماری های مدل می پردازد، در حالی که سوال دوم مربوط به محک زدن مدل های آموزش دیده در برابر مجموعه داده های آزمایشی است.
در این پست خواهید دید که چگونه طبقه بندی تصاویر TensorFlow الگوریتم از Amazon SageMaker JumpStart می تواند پیاده سازی های مورد نیاز برای رسیدگی به این سوالات را ساده کند. همراه با جزئیات پیاده سازی در متناظر نمونه نوت بوک Jupyter، شما ابزارهایی برای انجام انتخاب مدل با کاوش در مرزهای پارتو خواهید داشت، جایی که بهبود یک معیار عملکرد، مانند دقت، بدون بدتر شدن یک معیار دیگر، مانند توان عملیاتی ممکن نیست.
بررسی اجمالی راه حل
شکل زیر مبادله انتخاب مدل را برای تعداد زیادی از مدلهای طبقهبندی تصویر که بهخوبی تنظیم شدهاند، نشان میدهد. Caltech-256 مجموعه داده، که مجموعه ای چالش برانگیز از 30,607 تصویر دنیای واقعی است که شامل 256 دسته شی است. هر نقطه نشان دهنده یک مدل واحد است، اندازه نقاط با توجه به تعداد پارامترهای تشکیل دهنده مدل مقیاس بندی می شوند، و نقاط بر اساس معماری مدل خود کد رنگی می شوند. به عنوان مثال، نقاط سبز روشن نشان دهنده معماری EfficientNet است. هر نقطه سبز روشن پیکربندی متفاوتی از این معماری با اندازهگیریهای عملکرد مدل منحصر به فرد است. شکل وجود یک مرز پارتو برای انتخاب مدل را نشان میدهد، که در آن دقت بالاتر با توان عملیاتی کمتر تعویض میشود. در نهایت، انتخاب یک مدل در امتداد مرز پارتو، یا مجموعه راهحلهای کارآمد پارتو، به الزامات عملکرد استقرار مدل شما بستگی دارد.
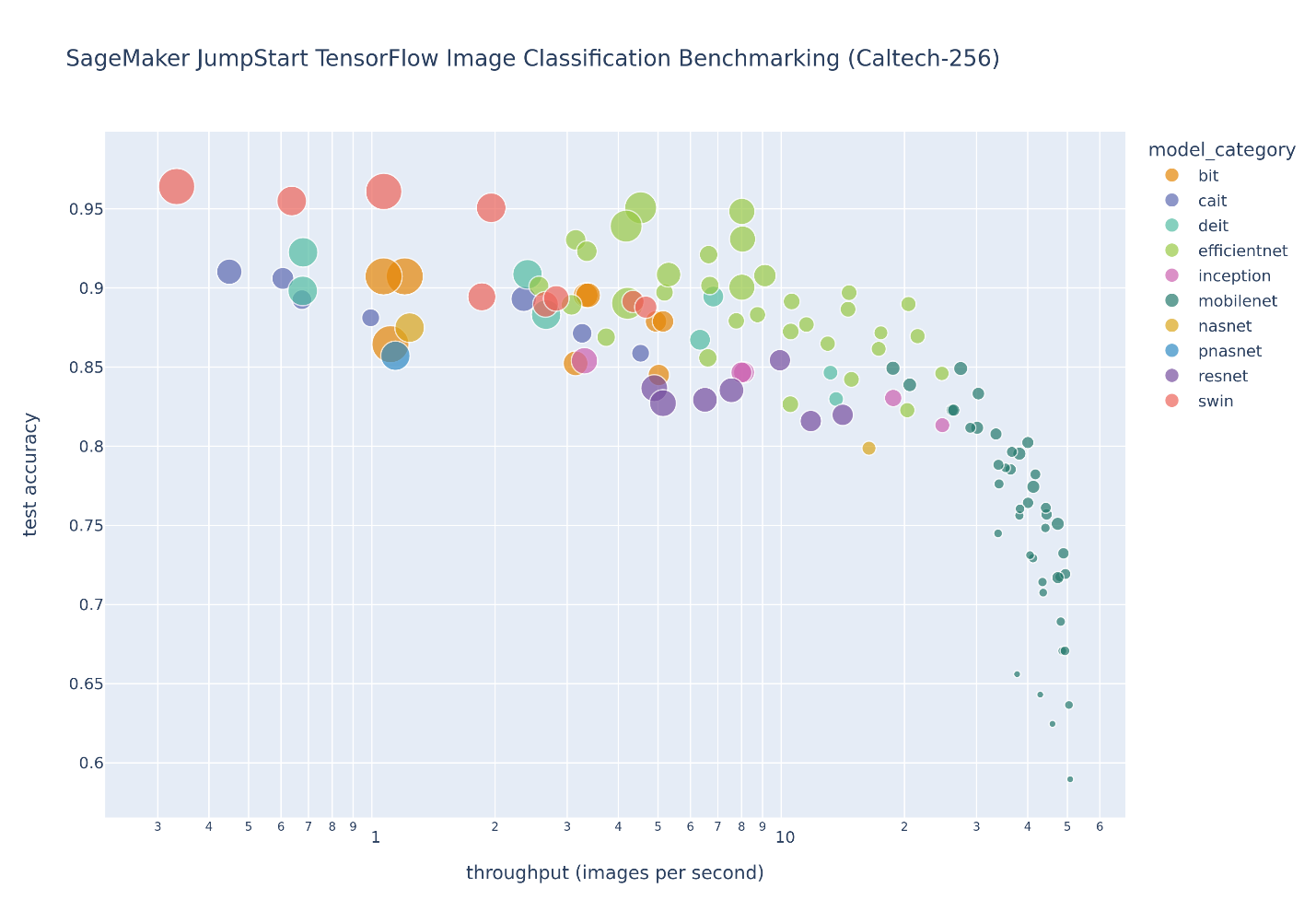
اگر دقت تست و مرزهای توان عملیاتی تست را رعایت کنید، مجموعه راه حل های کارآمد پارتو در شکل قبل در جدول زیر استخراج شده است. ردیفها به گونهای مرتب میشوند که توان آزمایشی افزایش مییابد و دقت تست کاهش مییابد.
| نام مدل | تعداد پارامترها | دقت تست | تست بالای 5 دقت | توان عملیاتی (تصاویر/ها) | مدت زمان در هر دوره |
| swin-large-patch4-window12-384 | 195.6M | ٪۱۰۰ | ٪۱۰۰ | 0.3 | 2278.6 |
| swin-large-patch4-window7-224 | 195.4M | ٪۱۰۰ | ٪۱۰۰ | 1.1 | 698.0 |
| efikasnet-v2-imagenet21k-ft1k-l | 118.1M | ٪۱۰۰ | ٪۱۰۰ | 4.5 | 1434.7 |
| efikasnet-v2-imagenet21k-ft1k-m | 53.5M | ٪۱۰۰ | ٪۱۰۰ | 8.0 | 769.1 |
| efikasnet-v2-imagenet21k-m | 53.5M | ٪۱۰۰ | ٪۱۰۰ | 8.0 | 765.1 |
| efikasnet-b5 | 29.0M | ٪۱۰۰ | ٪۱۰۰ | 9.1 | 668.6 |
| efikasnet-v2-imagenet21k-ft1k-b1 | 7.3M | ٪۱۰۰ | ٪۱۰۰ | 14.6 | 54.3 |
| efikasnet-v2-imagenet21k-ft1k-b0 | 6.2M | ٪۱۰۰ | ٪۱۰۰ | 20.5 | 38.3 |
| efikasnet-v2-imagenet21k-b0 | 6.2M | ٪۱۰۰ | ٪۱۰۰ | 21.5 | 38.2 |
| mobilenet-v3-large-100-224 | 4.6M | ٪۱۰۰ | ٪۱۰۰ | 27.4 | 28.8 |
| mobilenet-v3-large-075-224 | 3.1M | ٪۱۰۰ | ٪۱۰۰ | 30.3 | 26.6 |
| mobilenet-v2-100-192 | 2.6M | ٪۱۰۰ | ٪۱۰۰ | 33.5 | 23.9 |
| mobilenet-v2-100-160 | 2.6M | ٪۱۰۰ | ٪۱۰۰ | 40.0 | 19.6 |
| mobilenet-v2-075-160 | 1.7M | ٪۱۰۰ | ٪۱۰۰ | 41.8 | 19.3 |
| mobilenet-v2-075-128 | 1.7M | ٪۱۰۰ | ٪۱۰۰ | 44.3 | 18.3 |
| mobilenet-v1-075-160 | 2.0M | ٪۱۰۰ | ٪۱۰۰ | 44.5 | 18.2 |
| mobilenet-v1-100-128 | 3.5M | ٪۱۰۰ | ٪۱۰۰ | 47.4 | 17.4 |
| mobilenet-v1-075-128 | 2.0M | ٪۱۰۰ | ٪۱۰۰ | 48.9 | 16.8 |
| mobilenet-v2-075-96 | 1.7M | ٪۱۰۰ | ٪۱۰۰ | 49.4 | 16.6 |
| mobilenet-v2-035-96 | 0.7M | ٪۱۰۰ | ٪۱۰۰ | 50.4 | 16.3 |
| mobilenet-v1-025-128 | 0.3M | ٪۱۰۰ | ٪۱۰۰ | 50.8 | 16.2 |
این پست جزئیاتی در مورد نحوه پیاده سازی در مقیاس بزرگ ارائه می دهد آمازون SageMaker محک زدن و وظایف انتخاب مدل ابتدا، JumpStart و الگوریتم های داخلی طبقه بندی تصاویر TensorFlow را معرفی می کنیم. سپس ملاحظات پیاده سازی سطح بالا، مانند پیکربندی هایپرپارامتر JumpStart، استخراج متریک از گزارشهای آمازون CloudWatch، و راه اندازی کارهای تنظیم فراپارامتر ناهمزمان. در نهایت، ما محیط پیادهسازی و پارامترسازی را که منجر به راهحلهای کارآمد پارتو در جدول و شکل قبل میشود، پوشش میدهیم.
مقدمه ای بر طبقه بندی تصاویر JumpStart TensorFlow
JumpStart تنظیم دقیق و استقرار طیف گسترده ای از مدل های از پیش آموزش داده شده را با یک کلیک در وظایف رایج ML و همچنین مجموعه ای از راه حل های پایان به انتها که مشکلات رایج تجاری را حل می کند، ارائه می دهد. این ویژگیها بار سنگین را از هر مرحله از فرآیند ML حذف میکنند و توسعه مدلهای با کیفیت بالا را آسانتر میکنند و زمان استقرار را کاهش میدهند. را API های JumpStart به شما این امکان را می دهد که مجموعه وسیعی از مدل های از پیش آموزش دیده را در مجموعه داده های خود به صورت برنامه ریزی شده استقرار و تنظیم کنید.
مرکز مدل JumpStart دسترسی به تعداد زیادی را فراهم می کند مدلهای طبقهبندی تصویر TensorFlow که امکان انتقال یادگیری و تنظیم دقیق در مجموعه داده های سفارشی را فراهم می کند. در زمان نگارش این مقاله، مرکز مدل JumpStart شامل 135 مدل طبقهبندی تصویر TensorFlow در انواع معماریهای مدل محبوب از تنسورفلو هاب، شامل شبکه های باقیمانده (ResNet), موبایل نت, EfficNet, آغاز به کار, شبکه های جستجوی معماری عصبی (NASNet، انتقال بزرگ (BiT، پنجره جابجا شده (سویین) ترانسفورماتورها، توجه کلاس در ترانسفورماتورهای تصویر (CaiTو ترانسفورماتورهای تصویر کارآمد داده (DeiT).
ساختارهای داخلی بسیار متفاوت هر معماری مدل را تشکیل می دهند. برای مثال، مدلهای ResNet از اتصالات پرش برای ایجاد شبکههای عمیقتر استفاده میکنند، در حالی که مدلهای مبتنی بر ترانسفورماتور از مکانیسمهای خودتوجهی استفاده میکنند که موقعیت ذاتی عملیات کانولوشن را به نفع میدانهای دریافتی جهانیتر حذف میکند. علاوه بر مجموعه ویژگیهای متنوعی که این ساختارهای مختلف ارائه میکنند، هر معماری مدل دارای چندین پیکربندی است که اندازه، شکل و پیچیدگی مدل را در آن معماری تنظیم میکند. این منجر به صدها مدل طبقه بندی تصویر منحصر به فرد در مرکز مدل JumpStart می شود. همراه با آموزش انتقال داخلی و اسکریپتهای استنتاج که بسیاری از ویژگیهای SageMaker را در بر میگیرد، JumpStart API یک نقطه راهاندازی عالی برای تمرینکنندگان ML است تا آموزش و استقرار سریع مدلها را شروع کنند.
به مراجعه آموزش انتقال برای مدل های طبقه بندی تصویر TensorFlow در آمازون SageMaker و موارد زیر نمونه دفترچه یادداشت برای یادگیری عمیق تر در مورد طبقه بندی تصاویر SageMaker TensorFlow، از جمله نحوه اجرای استنتاج بر روی یک مدل از پیش آموزش دیده و همچنین تنظیم دقیق مدل از پیش آموزش داده شده در مجموعه داده های سفارشی.
ملاحظات انتخاب مدل در مقیاس بزرگ
انتخاب مدل فرآیند انتخاب بهترین مدل از مجموعه ای از مدل های کاندید است. این فرآیند ممکن است در مدلهای یک نوع با وزن پارامترهای مختلف و در مدلهای انواع مختلف اعمال شود. نمونههایی از انتخاب مدل در بین مدلهای یکسان شامل برازش یک مدل با فراپارامترهای مختلف (مثلاً نرخ یادگیری) و توقف زودهنگام برای جلوگیری از تطبیق بیش از حد وزنهای مدل با مجموعه داده قطار است. انتخاب مدل در بین مدلهای انواع مختلف شامل انتخاب بهترین معماری مدل (به عنوان مثال، Swin در مقابل MobileNet) و انتخاب بهترین پیکربندی مدل در یک معماری مدل واحد است (به عنوان مثال، mobilenet-v1-025-128 در مقابل mobilenet-v3-large-100-224).
ملاحظات ذکر شده در این بخش همه این فرآیندهای انتخاب مدل را در یک مجموعه داده اعتبار سنجی فعال می کند.
تنظیمات هایپرپارامتر را انتخاب کنید
طبقهبندی تصویر TensorFlow در JumpStart تعداد زیادی در دسترس دارد هایپرپارامترها که می تواند رفتارهای اسکریپت یادگیری انتقال را به طور یکنواخت برای تمام معماری های مدل تنظیم کند. این فراپارامترها به تقویت و پیش پردازش داده ها، مشخصات بهینه ساز، کنترل های اضافه برازش و نشانگرهای لایه قابل آموزش مربوط می شوند. شما تشویق می شوید که مقادیر پیش فرض این هایپرپارامترها را در صورت لزوم برای برنامه خود تنظیم کنید:
برای این تجزیه و تحلیل و دفترچه یادداشت مربوطه، همه هایپرپارامترها روی مقادیر پیشفرض تنظیم میشوند به جز نرخ یادگیری، تعداد دورهها و مشخصات توقف اولیه. نرخ یادگیری به عنوان یک تنظیم می شود پارامتر طبقه بندی توسط تنظیم خودکار مدل SageMaker کار. از آنجایی که هر مدل مقادیر فراپارامتر پیشفرض منحصربهفردی دارد، فهرست گسسته نرخهای یادگیری ممکن شامل نرخ یادگیری پیشفرض و همچنین یک پنجم نرخ یادگیری پیشفرض است. این کار دو کار آموزشی را برای یک کار تنظیم فراپارامتری راهاندازی میکند و کار آموزشی با بهترین عملکرد گزارششده در مجموعه داده اعتبارسنجی انتخاب میشود. از آنجایی که تعداد دوره ها روی 10 تنظیم شده است، که بیشتر از تنظیم پیش فرض هایپرپارامتر است، بهترین کار آموزشی انتخاب شده همیشه با نرخ یادگیری پیش فرض مطابقت ندارد. در نهایت، یک معیار توقف زودهنگام با صبر، یا تعداد دورهها برای ادامه تمرین بدون بهبود، سه دوره استفاده میشود.
یکی از تنظیمات پیشفرض هایپرپارامتر از اهمیت ویژهای برخوردار است train_only_on_top_layer، اگر روی آن تنظیم شده باشد True، لایه های استخراج ویژگی مدل در مجموعه داده آموزشی ارائه شده به خوبی تنظیم نشده اند. بهینه ساز فقط پارامترها را در لایه طبقه بندی کاملا متصل بالا با ابعاد خروجی برابر با تعداد برچسب های کلاس در مجموعه داده آموزش می دهد. به طور پیش فرض، این هایپرپارامتر روی تنظیم شده است True، که تنظیمی برای انتقال یادگیری در مجموعه داده های کوچک است. ممکن است یک مجموعه داده سفارشی داشته باشید که در آن استخراج ویژگی از پیش آموزش در مجموعه داده ImageNet کافی نباشد. در این موارد باید تنظیم کنید train_only_on_top_layer به False. اگرچه این تنظیم زمان آموزش را افزایش می دهد، اما ویژگی های معنی داری بیشتری برای مشکل مورد علاقه خود استخراج خواهید کرد و در نتیجه دقت را افزایش می دهید.
استخراج معیارها از CloudWatch Logs
الگوریتم طبقهبندی تصویر JumpStart TensorFlow بهطور قابل اعتمادی معیارهای مختلفی را در طول آموزش ثبت میکند که در دسترس SageMaker هستند. Estimator و اشیاء HyperparameterTuner. سازنده SageMaker Estimator است metric_definitions آرگومان کلمه کلیدی، که می تواند برای ارزیابی شغل آموزشی با ارائه لیستی از فرهنگ لغت با دو کلید استفاده شود: نام برای نام متریک، و Regex برای عبارت منظم که برای استخراج متریک از لاگ ها استفاده می شود. همراه دفتر یادداشت جزئیات پیاده سازی را نشان می دهد. جدول زیر معیارهای موجود و عبارات منظم مرتبط را برای همه مدلهای طبقهبندی تصویر JumpStart TensorFlow فهرست میکند.
| نام متریک | مبین منظم |
| تعداد پارامترها | "- تعداد پارامترها: ([0-9\.]+)" |
| تعداد پارامترهای قابل آموزش | "- تعداد پارامترهای قابل آموزش: ([0-9\.]+)" |
| تعداد پارامترهای غیر قابل آموزش | "- تعداد پارامترهای غیر قابل آموزش: ([0-9\.]+)" |
| متریک مجموعه داده قطار | f”- {metric}: ([0-9\.]+)” |
| متریک مجموعه داده اعتبارسنجی | f”- val_{metric}: ([0-9\.]+)” |
| متریک مجموعه داده آزمایشی | f”- تست {metric}: ([0-9\.]+)” |
| مدت زمان قطار | "- کل مدت آموزش: ([0-9\.]+)" |
| مدت زمان قطار در هر دوره | «- میانگین مدت آموزش در هر دوره: ([0-9\.]+)» |
| تأخیر ارزیابی آزمون | «- تأخیر ارزیابی آزمون: ([0-9\.]+)» |
| تأخیر آزمایش در هر نمونه | «- میانگین تأخیر آزمون در هر نمونه: ([0-9\.]+)» |
| توان آزمایشی | «- میانگین توان آزمایشی: ([0-9\.]+)» |
اسکریپت یادگیری انتقال داخلی انواعی از معیارهای قطار، اعتبارسنجی و آزمایش مجموعه داده را در این تعاریف ارائه میکند، همانطور که توسط مقادیر جایگزینی رشته f نشان داده میشود. معیارهای دقیق موجود بر اساس نوع طبقه بندی انجام شده متفاوت است. تمام مدل های کامپایل شده دارای a loss متریک، که با از دست دادن آنتروپی متقاطع برای یک مسئله طبقهبندی باینری یا طبقهبندی نشان داده میشود. اولی زمانی استفاده می شود که یک برچسب کلاس وجود داشته باشد. دومی در صورت وجود دو یا چند برچسب کلاس استفاده می شود. اگر فقط یک برچسب کلاس وجود داشته باشد، متریک های زیر از طریق عبارات منظم رشته f در جدول قبل محاسبه، ثبت و استخراج می شوند: تعداد موارد مثبت واقعی (true_pos، تعداد مثبت کاذب (false_pos، تعداد منفی های واقعی (true_neg، تعداد منفی کاذب (false_neg), precision, recall، ناحیه زیر منحنی مشخصه عملکرد گیرنده (ROC)aucو سطح زیر منحنی فراخوان دقیق (PR) (prc). به طور مشابه، اگر شش یا بیشتر برچسب کلاس وجود داشته باشد، یک متریک دقت بالای 5 (top_5_accuracy) همچنین از طریق عبارات منظم قبلی محاسبه، ثبت و استخراج می شود.
در طول آموزش، معیارهای مشخص شده برای SageMaker Estimator به گزارشهای CloudWatch منتشر میشوند. هنگامی که آموزش کامل شد، می توانید آن را فراخوانی کنید SageMaker DescribeTrainingJob API و بازرسی FinalMetricDataList کلید در پاسخ JSON:
این API فقط نیاز به ارائه نام شغل به پرس و جو دارد، بنابراین، پس از تکمیل، می توان معیارها را در تجزیه و تحلیل های آینده به دست آورد تا زمانی که نام شغل آموزشی به طور مناسب ثبت شده و قابل بازیابی باشد. برای این کار انتخاب مدل، نام کار تنظیم هایپرپارامتر ذخیره می شود و تجزیه و تحلیل های بعدی مجدداً یک HyperparameterTuner با توجه به نام کار تنظیم، بهترین نام شغل آموزشی را از تیونر هایپرپارامتر پیوست شده استخراج کنید و سپس آن را فراخوانی کنید. DescribeTrainingJob API همانطور که قبلا برای به دست آوردن معیارهای مرتبط با بهترین شغل آموزشی توضیح داده شد.
کارهای تنظیم فراپارامتر ناهمزمان را راه اندازی کنید
رجوع به مربوطه شود دفتر یادداشت برای جزئیات پیاده سازی در مورد راه اندازی ناهمزمان کارهای تنظیم فراپارامتر، که از کتابخانه استاندارد پایتون استفاده می کند معاملات آتی همزمان ماژول، یک رابط سطح بالا برای اجرای ناهمزمان قابل فراخوانی. چندین ملاحظات مربوط به SageMaker در این راه حل پیاده سازی شده است:
- هر حساب AWS به آن وابسته است سهمیه خدمات SageMaker. شما باید محدودیت های فعلی خود را مشاهده کنید تا به طور کامل از منابع خود استفاده کنید و به طور بالقوه درخواست افزایش محدودیت منابع را در صورت نیاز کنید.
- فراخوانی های مکرر API برای ایجاد بسیاری از کارهای تنظیم فراپارامتر همزمان ممکن است از نرخ Python SDK فراتر رفته و استثنائات throttling را ایجاد می کند. یک راه حل برای این کار ایجاد یک کلاینت SageMaker Boto3 با پیکربندی مجدد سفارشی است.
- اگر اسکریپت شما با خطا مواجه شود یا اسکریپت قبل از تکمیل متوقف شود چه اتفاقی می افتد؟ برای چنین انتخاب مدل بزرگ یا مطالعه معیار، می توانید نام مشاغل تنظیم را ثبت کنید و عملکردهای راحتی را برای کار تنظیم هایپرپارامتر را دوباره وصل کنید که از قبل وجود دارند:
جزئیات تجزیه و تحلیل و بحث
تجزیه و تحلیل در این پست آموزش انتقال را برای شناسه های مدل در الگوریتم طبقه بندی تصویر JumpStart TensorFlow در مجموعه داده Caltech-256. تمام کارهای آموزشی بر روی نمونه آموزشی SageMaker ml.g4dn.xlarge انجام شد که حاوی یک واحد پردازش گرافیکی NVIDIA T4 است.
مجموعه داده آزمون بر اساس نمونه آموزشی در پایان آموزش ارزیابی می شود. انتخاب مدل قبل از ارزیابی مجموعه دادههای آزمایشی انجام میشود تا وزن مدل را در دورهای با بهترین عملکرد مجموعه اعتبارسنجی تنظیم کند. توان آزمایشی بهینهسازی نشده است: اندازه دستهای مجموعه داده روی اندازه دستهای فراپارامتر آموزشی پیشفرض تنظیم شده است، که برای به حداکثر رساندن استفاده از حافظه GPU تنظیم نشده است. توان آزمایشی گزارش شده شامل زمان بارگذاری داده است زیرا مجموعه داده از قبل ذخیره نشده است. و استنتاج توزیع شده در چندین GPU استفاده نمی شود. به این دلایل، این توان یک اندازه گیری نسبی خوب است، اما توان عملیاتی واقعی به شدت به تنظیمات استقرار نقطه پایانی استنتاج شما برای مدل آموزش دیده بستگی دارد.
اگرچه مرکز مدل JumpStart شامل بسیاری از انواع معماری طبقهبندی تصویر است، این مرز پارتو تحت سلطه مدلهای انتخابی Swin، EfficientNet و MobileNet است. مدلهای Swin بزرگتر و نسبتاً دقیقتر هستند، در حالی که مدلهای MobileNet کوچکتر، نسبتاً کمتر دقیق هستند و برای محدودیتهای منابع دستگاههای تلفن همراه مناسب هستند. توجه به این نکته مهم است که این مرز به عوامل مختلفی بستگی دارد، از جمله مجموعه داده دقیق مورد استفاده و فراپارامترهای تنظیم دقیق انتخاب شده. ممکن است متوجه شوید که مجموعه داده سفارشی شما مجموعه متفاوتی از راهحلهای کارآمد پارتو تولید میکند، و ممکن است بخواهید زمانهای آموزشی طولانیتری با فراپارامترهای مختلف، مانند افزایش بیشتر دادهها یا تنظیم دقیق بیشتر از لایه طبقهبندی بالای مدل داشته باشید.
نتیجه
در این پست، نحوه اجرای وظایف انتخاب مدل در مقیاس بزرگ یا محک زدن با استفاده از هاب مدل JumpStart را نشان دادیم. این راه حل می تواند به شما در انتخاب بهترین مدل برای نیازهای خود کمک کند. ما شما را تشویق می کنیم که این را امتحان کنید و کشف کنید راه حل در مجموعه داده های خود
منابع
اطلاعات بیشتر در منابع زیر موجود است:
درباره نویسندگان
 دکتر کایل اولریش دانشمند کاربردی با الگوریتم های داخلی آمازون SageMaker تیم علایق تحقیقاتی او شامل الگوریتم های یادگیری ماشین مقیاس پذیر، بینایی کامپیوتر، سری های زمانی، ناپارامتریک های بیزی و فرآیندهای گاوسی است. دکترای او از دانشگاه دوک است و مقالاتی در NeurIPS، Cell و Neuron منتشر کرده است.
دکتر کایل اولریش دانشمند کاربردی با الگوریتم های داخلی آمازون SageMaker تیم علایق تحقیقاتی او شامل الگوریتم های یادگیری ماشین مقیاس پذیر، بینایی کامپیوتر، سری های زمانی، ناپارامتریک های بیزی و فرآیندهای گاوسی است. دکترای او از دانشگاه دوک است و مقالاتی در NeurIPS، Cell و Neuron منتشر کرده است.
 دکتر آشیش ختان دانشمند ارشد کاربردی با الگوریتم های داخلی آمازون SageMaker و به توسعه الگوریتم های یادگیری ماشین کمک می کند. او دکترای خود را از دانشگاه ایلینویز Urbana Champaign گرفت. او یک محقق فعال در یادگیری ماشین و استنتاج آماری است و مقالات زیادی در کنفرانس های NeurIPS، ICML، ICLR، JMLR، ACL و EMNLP منتشر کرده است.
دکتر آشیش ختان دانشمند ارشد کاربردی با الگوریتم های داخلی آمازون SageMaker و به توسعه الگوریتم های یادگیری ماشین کمک می کند. او دکترای خود را از دانشگاه ایلینویز Urbana Champaign گرفت. او یک محقق فعال در یادگیری ماشین و استنتاج آماری است و مقالات زیادی در کنفرانس های NeurIPS، ICML، ICLR، JMLR، ACL و EMNLP منتشر کرده است.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/image-classification-model-selection-using-amazon-sagemaker-jumpstart/
- 10
- 100
- 9
- a
- درباره ما
- دسترسی
- در دسترس
- حساب
- دقت
- دقیق
- رسیدن
- در میان
- فعال
- اضافه
- نشانی
- آدرس
- تنظیم شده
- وابسته
- در برابر
- الگوریتم
- الگوریتم
- معرفی
- قبلا
- هر چند
- همیشه
- آمازون
- آمازون SageMaker
- Amazon SageMaker JumpStart
- تحلیل
- و
- دیگر
- API
- کاربرد
- اعمال می شود
- به درستی
- معماری
- محدوده
- استدلال
- مرتبط است
- ضمیمه کردن
- تلاشها
- اتوماتیک
- در دسترس
- میانگین
- AWS
- مستقر
- بیزی
- زیرا
- قبل از
- بودن
- بهترین
- بزرگ
- ساخته شده در
- کسب و کار
- تماس ها
- نامزد
- موارد
- دسته
- به چالش کشیدن
- مشخصه
- را انتخاب کنید
- کلاس
- طبقه بندی
- طبقه بندی کنید
- مشتری
- ترکیب شده
- مشترک
- مقایسه
- کامل
- تکمیل شده
- اتمام
- پیچیدگی
- کامپیوتر
- چشم انداز کامپیوتر
- نگرانی ها
- همایش ها
- پیکر بندی
- متصل
- اتصالات
- ملاحظات
- محدودیت ها
- شامل
- ادامه دادن
- کنترل
- گروه شاهد
- راحتی
- متناظر
- پوشش
- ایجاد
- جاری
- منحنی
- سفارشی
- داده ها
- مجموعه داده ها
- عمیق تر
- به طور پیش فرض
- بستگی دارد
- گسترش
- استقرار
- گسترش
- عمق
- شرح داده شده
- شرح
- جزئیات
- توسعه
- دستگاه ها
- مختلف
- بحث و تبادل نظر
- توزیع شده
- مختلف
- نمی کند
- دوک
- دانشگاه دوک
- در طی
- هر
- پیش از آن
- در اوایل
- آسان تر
- موثر
- هر دو
- از بین بردن
- قادر ساختن
- تشویق
- تشویق
- پشت سر هم
- نقطه پایانی
- محیط
- دوره
- دوره ها
- خطا
- اتر (ETH)
- ارزیابی
- ارزیابی
- ارزیابی
- مثال
- مثال ها
- جز
- اکتشاف
- بررسی
- اصطلاحات
- عصاره
- استخراج
- عوامل
- منصفانه
- توجه
- ویژگی
- امکانات
- زمینه
- شکل
- سرانجام
- پیدا کردن
- نام خانوادگی
- مناسب
- پیروی
- سابق
- از جانب
- مرز
- مرز
- کاملا
- توابع
- آینده
- آینده
- تولید می کنند
- دریافت کنید
- داده
- جهانی
- خوب
- GPU
- GPU ها
- بزرگ
- بیشتر
- سبز
- اتفاق می افتد
- به شدت
- کمک
- کمک می کند
- در سطح بالا
- با کیفیت بالا
- بالاتر
- چگونه
- چگونه
- HTML
- HTTPS
- قطب
- صدها نفر
- تنظیم فراپارامتر
- ICLR
- ایلینوی
- تصویر
- طبقه بندی تصویر
- IMAGEnet
- تصاویر
- انجام
- پیاده سازی
- اجرا
- اهمیت
- مهم
- بهبود
- بهبود
- in
- شامل
- شامل
- از جمله
- افزایش
- افزایش
- افزایش
- شاخص ها
- اطلاعات
- ورودی
- نمونه
- علاقه
- منافع
- رابط
- داخلی
- ذاتی
- معرفی
- IT
- کار
- شغل ها
- json
- کلید
- کلید
- برچسب
- برچسب ها
- بزرگ
- در مقیاس بزرگ
- بزرگتر
- تاخیر
- راه اندازی
- راه اندازی
- لایه
- لایه
- برجسته
- یاد گرفتن
- یادگیری
- بلند کردن اجسام
- سبک
- محدود
- محدودیت
- فهرست
- لیست
- بارگیری
- طولانی
- دیگر
- خاموش
- دستگاه
- فراگیری ماشین
- ساخت
- بسیاری
- بیشینه ساختن
- معنی دار
- اندازه گیری
- حافظه
- متری
- متریک
- ML
- موبایل
- دستگاه های تلفن همراه
- مدل
- مدل
- واحد
- بیش
- چندگانه
- نام
- نام
- لازم
- ضروری
- نیازهای
- شبکه
- عصبی
- NeurIPS
- جدید
- دفتر یادداشت
- عدد
- کارت گرافیک Nvidia
- هدف
- اشیاء
- مشاهده کردن
- گرفتن
- به دست آمده
- ONE
- عملیاتی
- عملیات
- بهینه
- مشخص شده
- خود
- اوراق
- پارامتر
- پارامترهای
- ویژه
- صبر
- انجام دادن
- کارایی
- انجام می دهد
- افلاطون
- هوش داده افلاطون
- PlatoData
- نقطه
- نقطه
- محبوب
- ممکن
- پست
- بالقوه
- pr
- جلوگیری از
- قبلا
- مشکل
- مشکلات
- روند
- فرآیندهای
- ارائه
- ارائه
- فراهم می کند
- ارائه
- منتشر شده
- پــایتــون
- سوال
- سوالات
- به سرعت
- رم
- نرخ
- نرخ
- دنیای واقعی
- دلایل
- کاهش
- منظم
- نسبتا
- برداشتن
- گزارش
- نشان دادن
- نمایندگی
- نشان دهنده
- درخواست
- ضروری
- مورد نیاز
- نیاز
- تحقیق
- پژوهشگر
- وضوح
- منابع
- منابع
- پاسخ
- نتایج
- دویدن
- در حال اجرا
- حکیم ساز
- همان
- مقیاس پذیر
- دانشمند
- اسکریپت
- sdk
- جستجو
- بخش
- انتخاب شد
- انتخاب
- انتخاب
- ارشد
- سلسله
- سرویس
- جلسه
- تنظیم
- مجموعه
- محیط
- چند
- شکل
- باید
- نشان می دهد
- به طور مشابه
- ساده کردن
- همزمان
- تنها
- شش
- اندازه
- اندازه
- کوچک
- کوچکتر
- So
- راه حل
- مزایا
- حل
- مشخصات
- مشخصات
- مشخص شده
- استاندارد
- آغاز شده
- آماری
- گام
- متوقف شد
- متوقف کردن
- ذخیره شده
- مهاجرت تحصیلی
- متعاقب
- قابل ملاحظه ای
- چنین
- کافی
- مناسب
- جدول
- هدف قرار
- کار
- وظایف
- تیم
- جریان تنسور
- آزمون
- La
- شان
- در نتیجه
- سه
- توان
- زمان
- سری زمانی
- بار
- به
- امروز
- با هم
- ابزار
- بالا
- بالا 5
- جمع
- قطار
- آموزش دیده
- آموزش
- انتقال
- ترانسفورماتور
- درست
- انواع
- در نهایت
- زیر
- منحصر به فرد
- دانشگاه
- استفاده
- استفاده کنید
- استفاده کنید
- استفاده
- اعتبار سنجی
- ارزشها
- تنوع
- وسیع
- از طريق
- چشم انداز
- دید
- که
- در حین
- وسیع
- اراده
- در داخل
- بدون
- خواهد بود
- نوشته
- شما
- زفیرنت