OpenAI Whisper یک مدل پیشرفته تشخیص گفتار خودکار (ASR) با مجوز MIT است. فناوری ASR در خدمات رونویسی، دستیارهای صوتی و افزایش دسترسی برای افراد دارای اختلالات شنوایی مفید است. این مدل پیشرفته بر روی مجموعه داده های وسیع و متنوعی از داده های چند زبانه و نظارت شده چند وظیفه ای جمع آوری شده از وب آموزش داده شده است. دقت و سازگاری بالای آن، آن را به یک دارایی با ارزش برای طیف گسترده ای از وظایف مرتبط با صدا تبدیل می کند.
در چشم انداز همیشه در حال تحول یادگیری ماشین و هوش مصنوعی، آمازون SageMaker یک اکوسیستم جامع را فراهم می کند. SageMaker به دانشمندان داده، توسعهدهندگان و سازمانها برای توسعه، آموزش، استقرار و مدیریت مدلهای یادگیری ماشین در مقیاس قدرت میدهد. با ارائه طیف گسترده ای از ابزارها و قابلیت ها، کل گردش کار یادگیری ماشین را از پیش پردازش داده ها و توسعه مدل گرفته تا استقرار و نظارت بی دردسر را ساده می کند. رابط کاربر پسند SageMaker آن را به یک پلتفرم محوری برای باز کردن تمام پتانسیل هوش مصنوعی تبدیل می کند و آن را به عنوان یک راه حل تغییر دهنده بازی در حوزه هوش مصنوعی معرفی می کند.
در این پست، ما به بررسی قابلیتهای SageMaker، به ویژه بر روی میزبانی مدلهای Whisper میپردازیم. ما به دو روش برای انجام این کار می پردازیم: یکی با استفاده از مدل Whisper PyTorch و دیگری با استفاده از اجرای Hugging Face مدل Whisper. علاوه بر این، ما یک بررسی عمیق از گزینههای استنتاج SageMaker انجام خواهیم داد و آنها را در پارامترهایی مانند سرعت، هزینه، اندازه بار و مقیاسپذیری مقایسه خواهیم کرد. این تجزیه و تحلیل به کاربران این امکان را میدهد که هنگام ادغام مدلهای Whisper در موارد استفاده و سیستمهای خاص خود تصمیمات آگاهانه بگیرند.
بررسی اجمالی راه حل
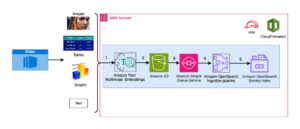
نمودار زیر اجزای اصلی این محلول را نشان می دهد.
- برای میزبانی مدل در Amazon SageMaker، اولین قدم ذخیره مصنوعات مدل است. این مصنوعات به اجزای ضروری یک مدل یادگیری ماشینی مورد نیاز برای کاربردهای مختلف، از جمله استقرار و بازآموزی اشاره دارد. آنها میتوانند شامل پارامترهای مدل، فایلهای پیکربندی، اجزای پیشپردازش، و همچنین ابردادهها مانند جزئیات نسخه، تألیف و هرگونه یادداشت مربوط به عملکرد آن باشند. توجه به این نکته مهم است که مدلهای Whisper برای پیادهسازی PyTorch و Hugging Face از مصنوعات مدل متفاوتی تشکیل شدهاند.
- بعد، ما اسکریپت های استنتاج سفارشی ایجاد می کنیم. در این اسکریپت ها، نحوه بارگذاری مدل را تعریف می کنیم و فرآیند استنتاج را مشخص می کنیم. اینجا همچنین جایی است که میتوانیم پارامترهای سفارشی را در صورت نیاز ترکیب کنیم. علاوه بر این، میتوانید بستههای پایتون مورد نیاز را در یک فهرست کنید
requirements.txtفایل. در طول استقرار مدل، این بسته های پایتون به طور خودکار در مرحله اولیه سازی نصب می شوند. - سپس ظروف یادگیری عمیق PyTorch یا Hugging Face (DLC) را انتخاب می کنیم که توسط AWS. این کانتینرها تصاویر Docker از پیش ساخته شده با چارچوب های یادگیری عمیق و سایر بسته های ضروری پایتون هستند. برای اطلاعات بیشتر می توانید این را بررسی کنید پیوند.
- با مصنوعات مدل، اسکریپت های استنتاج سفارشی و DLC های انتخاب شده، مدل های Amazon SageMaker را به ترتیب برای PyTorch و Hugging Face ایجاد می کنیم.
- در نهایت، مدل ها را می توان در SageMaker مستقر کرد و با گزینه های زیر استفاده کرد: نقاط پایانی استنتاج بلادرنگ، کارهای تبدیل دسته ای، و نقاط پایانی استنتاج ناهمزمان. در ادامه این پست با جزئیات بیشتر به این گزینه ها خواهیم پرداخت.
نمونه نوت بوک و کد این راه حل در این مورد موجود است مخزن GitHub.
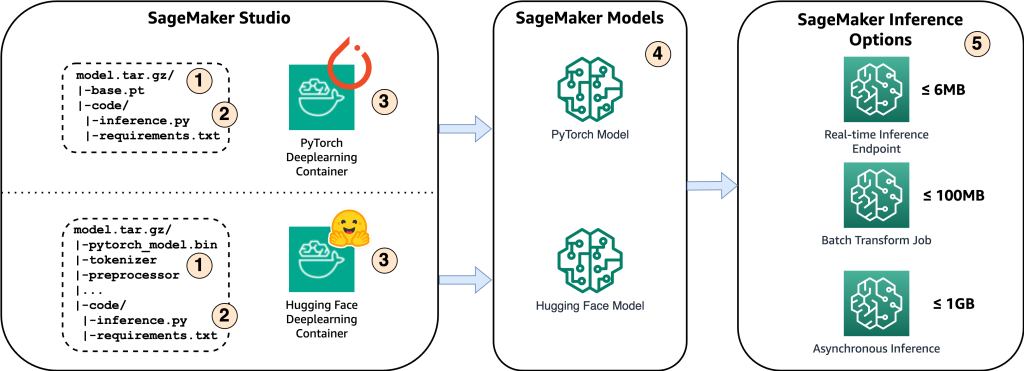
شکل 1. مروری بر اجزای راه حل کلیدی
خرید
میزبانی مدل Whisper در Amazon SageMaker
در این بخش، مراحل میزبانی مدل Whisper در Amazon SageMaker را به ترتیب با استفاده از PyTorch و Hugging Face Framework توضیح خواهیم داد. برای آزمایش این راه حل، به یک حساب AWS و دسترسی به سرویس Amazon SageMaker نیاز دارید.
چارچوب PyTorch
- مصنوعات مدل را ذخیره کنید
اولین گزینه برای میزبانی مدل استفاده از پکیج رسمی پایتون Whisper، که با استفاده از آن قابل نصب است pip install openai-whisper. این بسته یک مدل PyTorch ارائه می دهد. هنگام ذخیره مصنوعات مدل در مخزن محلی، اولین گام ذخیره پارامترهای قابل یادگیری مدل، مانند وزن مدل و بایاس های هر لایه در شبکه عصبی، به عنوان یک فایل "pt" است. میتوانید از میان اندازههای مختلف مدل، از جمله «ریز»، «پایه»، «کوچک»، «متوسط» و «بزرگ» انتخاب کنید. علاوه بر این، باید فرهنگ لغت حالت مدل و فرهنگ لغت ابعاد را ذخیره کنید، که حاوی یک فرهنگ لغت پایتون است که هر لایه یا پارامتر مدل PyTorch را به پارامترهای قابل یادگیری مربوطه، همراه با سایر ابرداده ها و تنظیمات سفارشی نگاشت می کند. کد زیر نحوه ذخیره آرتیفکت های Whisper PyTorch را نشان می دهد.
- DLC را انتخاب کنید
مرحله بعدی انتخاب DLC از پیش ساخته شده از این است پیوند. هنگام انتخاب تصویر صحیح با در نظر گرفتن تنظیمات زیر مراقب باشید: چارچوب (PyTorch)، نسخه چارچوب، وظیفه (استنتاج)، نسخه پایتون و سخت افزار (یعنی GPU). توصیه می شود در صورت امکان از آخرین نسخه ها برای چارچوب و پایتون استفاده کنید، زیرا این کار باعث عملکرد بهتر و رفع مشکلات و اشکالات شناخته شده از نسخه های قبلی می شود.
- مدل های Amazon SageMaker را ایجاد کنید
بعد از آن استفاده می کنیم SageMaker Python SDK برای ایجاد مدل های PyTorch. مهم است که هنگام ایجاد یک مدل PyTorch، متغیرهای محیطی را اضافه کنید. به طور پیش فرض، TorchServe فقط می تواند اندازه فایل تا 6 مگابایت را بدون توجه به نوع استنتاج استفاده شده پردازش کند.
جدول زیر تنظیمات نسخه های مختلف PyTorch را نشان می دهد:
| چارچوب | متغیرهای محیطی |
| PyTorch 1.8 (بر اساس TorchServe) | 'TS_MAX_REQUEST_SIZE': '100000000'' TS_MAX_RESPONSE_SIZE': '100000000'' TS_DEFAULT_RESPONSE_TIMEOUT': '1000' |
| PyTorch 1.4 (بر اساس MMS) | 'MMS_MAX_REQUEST_SIZE': '1000000000'' MMS_MAX_RESPONSE_SIZE': '1000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- روش بارگذاری مدل را در inference.py تعریف کنید
در عرف inference.py اسکریپت، ابتدا وجود یک GPU با قابلیت CUDA را بررسی می کنیم. اگر چنین GPU در دسترس باشد، آن را به آن اختصاص می دهیم 'cuda' دستگاه به DEVICE متغیر؛ در غیر این صورت، ما را اختصاص می دهیم 'cpu' دستگاه این مرحله تضمین می کند که مدل بر روی سخت افزار موجود برای محاسبات کارآمد قرار می گیرد. ما مدل PyTorch را با استفاده از بسته Whisper Python بارگذاری می کنیم.
چارچوب صورت در آغوش گرفته
- مصنوعات مدل را ذخیره کنید
گزینه دوم استفاده است زمزمه صورت در آغوش کشیده پیاده سازی. مدل را می توان با استفاده از AutoModelForSpeechSeq2Seq کلاس ترانسفورماتور پارامترهای قابل یادگیری در یک فایل باینری (bin) با استفاده از ذخیره می شوند save_pretrained روش. برای اطمینان از اینکه مدل Hugging Face به درستی کار می کند، توکنایزر و پیش پردازنده نیز باید به طور جداگانه ذخیره شوند. از طرف دیگر، میتوانید با تنظیم دو متغیر محیطی، یک مدل را مستقیماً از Hugging Face Hub در Amazon SageMaker مستقر کنید: HF_MODEL_ID و HF_TASK. برای اطلاعات بیشتر به این مطلب مراجعه فرمایید صفحه وب.
- DLC را انتخاب کنید
مشابه چارچوب PyTorch، می توانید یک DLC از پیش ساخته شده Hugging Face را از همان چارچوب انتخاب کنید. پیوند. مطمئن شوید که یک DLC را انتخاب کنید که از آخرین ترانسفورماتورهای Hugging Face پشتیبانی می کند و شامل پشتیبانی GPU می شود.
- مدل های Amazon SageMaker را ایجاد کنید
به طور مشابه، ما از SageMaker Python SDK برای ایجاد مدل های صورت بغل کردن. مدل Hugging Face Whisper دارای یک محدودیت پیشفرض است که در آن تنها میتواند بخشهای صوتی را تا 30 ثانیه پردازش کند. برای رفع این محدودیت، می توانید موارد زیر را وارد کنید chunk_length_s پارامتر در متغیر محیطی هنگام ایجاد مدل Hugging Face، و بعداً این پارامتر را هنگام بارگیری مدل به اسکریپت استنتاج سفارشی منتقل کنید. در نهایت، متغیرهای محیطی را برای افزایش اندازه محموله و زمان پاسخ برای کانتینر Hugging Face تنظیم کنید.
| چارچوب | متغیرهای محیطی |
|
ظرف استنتاج HuggingFace (بر اساس MMS) |
'MMS_MAX_REQUEST_SIZE': '2000000000'' MMS_MAX_RESPONSE_SIZE': '2000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- روش بارگذاری مدل را در inference.py تعریف کنید
هنگام ایجاد اسکریپت استنتاج سفارشی برای مدل Hugging Face، از یک خط لوله استفاده می کنیم که به ما امکان می دهد chunk_length_s به عنوان یک پارامتر این پارامتر مدل را قادر می سازد تا فایل های صوتی طولانی را در طول استنتاج به طور موثر پردازش کند.
بررسی گزینه های مختلف استنتاج در Amazon SageMaker
مراحل انتخاب گزینه های استنتاج برای هر دو مدل PyTorch و Hugging Face یکسان است، بنابراین در زیر تفاوتی بین آنها قائل نمی شویم. با این حال، شایان ذکر است که در زمان نوشتن این پست، استنتاج بدون سرور گزینه SageMaker از پردازندههای گرافیکی پشتیبانی نمیکند و در نتیجه، این گزینه را برای این مورد استفاده نمیکنیم.
میتوانیم مدل را بهعنوان نقطه پایانی بلادرنگ اجرا کنیم و پاسخها را در میلیثانیه ارائه کنیم. با این حال، مهم است که توجه داشته باشید که این گزینه به پردازش ورودی های کمتر از 6 مگابایت محدود می شود. ما سریال ساز را به عنوان سریال ساز صوتی تعریف می کنیم که وظیفه تبدیل داده های ورودی به فرمت مناسب برای مدل مستقر شده را بر عهده دارد. ما از یک نمونه GPU برای استنتاج استفاده می کنیم که امکان پردازش سریع فایل های صوتی را فراهم می کند. ورودی استنتاج یک فایل صوتی است که از مخزن محلی است.
دومین گزینه استنتاج، کار تبدیل دسته ای است که قادر به پردازش بارهای ورودی تا 100 مگابایت است. با این حال، این روش ممکن است چند دقیقه تاخیر داشته باشد. هر نمونه می تواند تنها یک درخواست دسته ای را در یک زمان انجام دهد و شروع و خاموش کردن نمونه نیز به چند دقیقه نیاز دارد. نتایج استنتاج در یک سرویس ذخیره سازی ساده آمازون ذخیره می شود (آمازون S3) سطل پس از اتمام کار تبدیل دسته ای.
هنگام پیکربندی ترانسفورماتور دسته ای، حتماً آن را وارد کنید max_payload = 100 برای مدیریت موثر محموله های بزرگتر ورودی استنتاج باید مسیر Amazon S3 به یک فایل صوتی یا پوشه Amazon S3 Bucket حاوی لیستی از فایلهای صوتی، هر کدام با حجم کمتر از 100 مگابایت باشد.
Batch Transform اشیاء Amazon S3 در ورودی را توسط کلید پارتیشن بندی می کند و اشیاء Amazon S3 را به نمونه ها نگاشت می کند. به عنوان مثال، هنگامی که چندین فایل صوتی دارید، یک نمونه ممکن است input1.wav را پردازش کند و نمونه دیگری ممکن است فایلی به نام input2.wav را برای افزایش مقیاس پذیری پردازش کند. Batch Transform به شما امکان می دهد پیکربندی کنید max_concurrent_transforms برای افزایش تعداد درخواست های HTTP که به هر کانتینر ترانسفورماتور منفرد داده می شود. با این حال، توجه به این نکته مهم است که ارزش (max_concurrent_transforms* max_payload) نباید از 100 مگابایت تجاوز کند.
در نهایت، Amazon SageMaker Asynchronous Inference برای پردازش چندین درخواست به طور همزمان ایدهآل است، تأخیر متوسطی را ارائه میدهد و از بارهای ورودی حداکثر تا 1 گیگابایت پشتیبانی میکند. این گزینه مقیاس پذیری عالی را فراهم می کند و پیکربندی یک گروه مقیاس پذیر خودکار را برای نقطه پایانی امکان پذیر می کند. هنگامی که افزایش درخواستها رخ میدهد، بهطور خودکار برای رسیدگی به ترافیک افزایش مییابد، و هنگامی که همه درخواستها پردازش شدند، نقطه پایانی برای صرفهجویی در هزینهها به 0 کاهش مییابد.
با استفاده از استنتاج ناهمزمان، نتایج به طور خودکار در سطل آمازون S3 ذخیره می شوند. در AsyncInferenceConfig، می توانید اعلان ها را برای تکمیل موفقیت آمیز یا ناموفق پیکربندی کنید. مسیر ورودی به محل آمازون S3 فایل صوتی اشاره می کند. برای جزئیات بیشتر، لطفاً به کد زیر مراجعه کنید GitHub.
اختیاری: همانطور که قبلاً ذکر شد، ما این گزینه را داریم که یک گروه مقیاس خودکار را برای نقطه پایانی استنتاج ناهمزمان پیکربندی کنیم، که به آن اجازه می دهد تا یک افزایش ناگهانی در درخواست های استنتاج را مدیریت کند. یک مثال کد در این ارائه شده است مخزن GitHub. در نمودار زیر می توانید نمودار خطی را مشاهده کنید که دو معیار از آن را نشان می دهد CloudWatch آمازون: ApproximateBacklogSize و ApproximateBacklogSizePerInstance. در ابتدا، زمانی که 1000 درخواست فعال شد، تنها یک نمونه برای رسیدگی به استنتاج در دسترس بود. به مدت سه دقیقه، اندازه بک لاگ به طور مداوم از سه فراتر رفت (لطفاً توجه داشته باشید که این اعداد را می توان پیکربندی کرد)، و گروه مقیاس خودکار با چرخش نمونه های اضافی برای پاک کردن کارآمد بک لاگ پاسخ داد. این منجر به کاهش قابل توجهی در ApproximateBacklogSizePerInstance، اجازه می دهد تا درخواست های بک لاگ بسیار سریعتر از مرحله اولیه پردازش شوند.

شکل 2. نمودار خطی که تغییرات زمانی در معیارهای Amazon CloudWatch را نشان می دهد.
تجزیه و تحلیل مقایسه ای برای گزینه های استنتاج
مقایسهها برای گزینههای استنتاج مختلف بر اساس موارد استفاده رایج پردازش صوتی است. استنتاج بلادرنگ سریعترین سرعت استنتاج را ارائه میکند اما حجم بار را به 6 مگابایت محدود میکند. این نوع استنتاج برای سیستمهای فرمان صوتی مناسب است، جایی که کاربران با استفاده از دستورات صوتی یا دستورالعملهای گفتاری، دستگاهها یا نرمافزارها را کنترل میکنند یا با آنها تعامل دارند. دستورات صوتی معمولاً اندازه کوچکی دارند و تأخیر استنتاج کم برای اطمینان از اینکه دستورات رونویسی میتوانند فوراً اقدامات بعدی را آغاز کنند، بسیار مهم است. Batch Transform برای کارهای آفلاین برنامه ریزی شده ایده آل است، زمانی که اندازه هر فایل صوتی کمتر از 100 مگابایت است و نیاز خاصی برای زمان پاسخ استنتاج سریع وجود ندارد. استنتاج ناهمزمان امکان آپلود تا 1 گیگابایت را فراهم می کند و تأخیر استنتاج متوسطی را ارائه می دهد. این نوع استنتاج برای رونویسی فیلمها، سریالهای تلویزیونی و کنفرانسهای ضبطشده که در آن فایلهای صوتی بزرگتر باید پردازش شوند، مناسب است.
هر دو گزینه استنتاج بلادرنگ و ناهمزمان قابلیتهای مقیاسپذیری خودکار را ارائه میکنند و به نمونههای نقطه پایانی اجازه میدهند تا بر اساس حجم درخواستها بهطور خودکار افزایش یا کاهش پیدا کنند. در مواردی که هیچ درخواستی وجود ندارد، مقیاس خودکار نمونههای غیرضروری را حذف میکند و به شما کمک میکند از هزینههای مرتبط با نمونههای ارائهشده که به طور فعال استفاده نمیشوند اجتناب کنید. با این حال، برای استنتاج بلادرنگ، حداقل یک نمونه پایدار باید حفظ شود، که اگر نقطه پایانی به طور مداوم کار کند، میتواند منجر به هزینههای بالاتر شود. در مقابل، استنتاج ناهمزمان اجازه می دهد تا حجم نمونه در زمانی که استفاده نمی شود به 0 کاهش یابد. هنگام پیکربندی یک کار تبدیل دسته ای، می توان از چندین نمونه برای پردازش کار استفاده کرد و max_concurrent_transforms را تنظیم کرد تا یک نمونه بتواند چندین درخواست را مدیریت کند. بنابراین، هر سه گزینه استنتاج مقیاس پذیری بسیار خوبی را ارائه می دهند.
تمیز کردن
پس از تکمیل استفاده از راه حل، مطمئن شوید که نقاط پایانی SageMaker را حذف کرده اید تا از تحمیل هزینه های اضافی جلوگیری کنید. می توانید از کد ارائه شده برای حذف نقاط پایانی استنتاج بلادرنگ و ناهمزمان استفاده کنید.
نتیجه
در این پست، به شما نشان دادیم که چگونه استقرار مدلهای یادگیری ماشین برای پردازش صدا در صنایع مختلف به طور فزایندهای ضروری شده است. با در نظر گرفتن مدل Whisper به عنوان مثال، نحوه میزبانی مدلهای منبع باز ASR را در Amazon SageMaker با استفاده از رویکردهای PyTorch یا Hugging Face نشان دادیم. این کاوش گزینههای استنباط مختلفی را در Amazon SageMaker در بر میگیرد و بینشهایی را در مورد مدیریت کارآمد دادههای صوتی، پیشبینیها و مدیریت مؤثر هزینهها ارائه میدهد. هدف این پست ارائه دانش برای محققان، توسعه دهندگان و دانشمندان داده است که علاقه مند به استفاده از مدل Whisper برای کارهای مرتبط با صدا و تصمیم گیری آگاهانه در مورد استراتژی های استنتاج هستند.
برای اطلاعات دقیق تر در مورد استقرار مدل ها در SageMaker، لطفاً به این مراجعه کنید راهنمای توسعه دهنده. علاوه بر این، مدل Whisper را می توان با استفاده از SageMaker JumpStart مستقر کرد. برای جزئیات بیشتر، لطفا بررسی کنید مدلهای Whisper برای تشخیص خودکار گفتار اکنون در Amazon SageMaker JumpStart موجود است. پست.
به راحتی می توانید نوت بوک و کدهای این پروژه را در سایت بررسی کنید GitHub و نظر خود را با ما در میان بگذارید
درباره نویسنده
 یانگ هو، دکترا، یک معمار نمونه سازی یادگیری ماشین در AWS است. زمینه های اصلی مورد علاقه او شامل یادگیری عمیق، با تمرکز بر GenAI، Computer Vision، NLP، و پیش بینی داده های سری زمانی است. او در اوقات فراغت خود از گذراندن لحظات با کیفیت با خانواده، غرق شدن در رمان ها و پیاده روی در پارک های ملی بریتانیا لذت می برد.
یانگ هو، دکترا، یک معمار نمونه سازی یادگیری ماشین در AWS است. زمینه های اصلی مورد علاقه او شامل یادگیری عمیق، با تمرکز بر GenAI، Computer Vision، NLP، و پیش بینی داده های سری زمانی است. او در اوقات فراغت خود از گذراندن لحظات با کیفیت با خانواده، غرق شدن در رمان ها و پیاده روی در پارک های ملی بریتانیا لذت می برد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/host-the-whisper-model-on-amazon-sagemaker-exploring-inference-options/
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 1
- 10
- 100
- 12
- 14
- 16
- 19
- 30
- 32
- 8
- a
- تسریع شد
- دسترسی
- دسترسی
- حساب
- دقت
- در میان
- اقدامات
- فعالانه
- اضافه کردن
- اضافی
- علاوه بر این
- نشانی
- تنظیم کردن
- پیشرفته
- AI
- اهداف
- معرفی
- اجازه دادن
- اجازه می دهد تا
- در امتداد
- همچنین
- آمازون
- آمازون SageMaker
- آمازون خدمات وب
- an
- تحلیل
- و
- دیگر
- هر
- برنامه های کاربردی
- رویکردها
- هستند
- مناطق
- صف
- مصنوعی
- هوش مصنوعی
- AS
- دارایی
- دستیاران
- مرتبط است
- At
- سمعی
- نویسندگی
- اتوماتیک
- بطور خودکار
- دسترس پذیری
- در دسترس
- اجتناب از
- AWS
- پایه
- مستقر
- BE
- شدن
- در زیر
- بهتر
- میان
- تعصبات
- BIN
- هر دو
- اشکالات
- اما
- by
- CAN
- قابلیت های
- توانا
- دقیق
- موارد
- تبادل
- چارت سازمانی
- بررسی
- را انتخاب کنید
- انتخاب
- کلاس
- واضح
- رمز
- بیا
- توضیح
- مشترک
- مقایسه
- مقایسه
- تکمیل شده
- اتمام
- اجزاء
- جامع
- محاسبه
- کامپیوتر
- چشم انداز کامپیوتر
- رفتار
- همایش ها
- پیکر بندی
- پیکربندی
- پیکربندی
- با توجه به
- همواره
- شامل
- ظرف
- ظروف
- به طور مداوم
- کنتراست
- کنترل
- تبدیل
- اصلاح
- متناظر
- هزینه
- هزینه
- میتوانست
- پردازنده
- ایجاد
- ایجاد
- بسیار سخت
- سفارشی
- داده ها
- تصمیم گیری
- کاهش
- عمیق
- یادگیری عمیق
- به طور پیش فرض
- تعريف كردن
- نشان
- گسترش
- مستقر
- استقرار
- گسترش
- جزئیات
- دقیق
- جزئیات
- توسعه
- توسعه دهندگان
- پروژه
- دستگاه
- دستگاه ها
- مختلف
- تمایز
- بعد
- مستقیما
- نمایش
- شیرجه رفتن
- مختلف
- کارگر بارانداز
- نمی کند
- عمل
- پایین
- در طی
- e
- هر
- پیش از آن
- اکوسیستم
- به طور موثر
- موثر
- موثر
- بدون دردسر
- هر دو
- دیگر
- سوار شدن
- توانمندسازی
- قادر ساختن
- را قادر می سازد
- را قادر می سازد
- شامل
- نقطه پایانی
- نقاط پایان
- بالا بردن
- افزایش
- اطمینان حاصل شود
- تضمین می کند
- تمام
- محیط
- ضروری است
- ایجاد
- اتر (ETH)
- معاینه
- مثال
- تجاوز
- بیش از
- عالی
- تجربه
- توضیح دهید
- اکتشاف
- بررسی
- چهره
- ناموفق
- غلط
- خانواده
- FAST
- سریعتر
- سریعترین
- کمی از
- پرونده
- فایل ها
- پیدا می کند
- نام خانوادگی
- تمرکز
- تمرکز
- پیروی
- برای
- قالب
- چارچوب
- چارچوب
- رایگان
- از جانب
- کامل
- GPU
- GPU ها
- بزرگ
- گروه
- دسته
- اداره
- سخت افزار
- آیا
- شنوایی
- کمک
- او
- زیاد
- بالاتر
- پیاده روی
- میزبان
- میزبانی وب
- چگونه
- چگونه
- اما
- HTML
- HTTP
- HTTPS
- قطب
- صورت در آغوش گرفته
- i
- دلخواه
- if
- نشان دادن
- تصویر
- تصاویر
- پیاده سازی
- پیاده سازی ها
- واردات
- مهم
- in
- در عمق
- شامل
- شامل
- از جمله
- ترکیب کردن
- افزایش
- به طور فزاینده
- فرد
- افراد
- لوازم
- اطلاعات
- اطلاع
- اول
- در ابتدا
- شروع
- ورودی
- ورودی
- بینش
- نصب
- نمونه
- نمونه ها
- دستورالعمل
- ادغام
- اطلاعات
- تعامل
- علاقه
- علاقه مند
- رابط
- به
- مسائل
- IT
- ITS
- کار
- شغل ها
- JPG
- کلید
- دانش
- شناخته شده
- چشم انداز
- بزرگتر
- در آخر
- تاخیر
- بعد
- آخرین
- لایه
- رهبری
- یادگیری
- کمترین
- بهره برداری
- مجوز
- محدودیت
- محدود شده
- لاین
- فهرست
- بار
- بارگیری
- محلی
- محل
- طولانی
- دیگر
- کم
- دستگاه
- فراگیری ماشین
- ساخته
- اصلی
- ساخت
- باعث می شود
- ساخت
- مدیریت
- مدیریت
- نقشه ها
- ممکن است..
- ذکر شده
- متاداده
- روش
- روش
- متریک
- قدرت
- میلی ثانیه
- دقیقه
- MIT
- ML
- مدل
- مدل
- متوسط
- لحظه
- نظارت بر
- بیش
- فیلم ها
- بسیار
- چندگانه
- باید
- تحت عنوان
- ملی
- پارک های ملی
- لازم
- نیاز
- ضروری
- شبکه
- عصبی
- شبکه های عصبی
- بعد
- nlp
- نه
- توجه داشته باشید
- دفتر یادداشت
- یادداشت
- اخطار
- اطلاعیه ها
- یادداشت برداری
- اکنون
- عدد
- تعداد
- هدف
- اشیاء
- مشاهده کردن
- of
- ارائه
- ارائه
- پیشنهادات
- رسمی
- آنلاین نیست.
- on
- یک بار
- ONE
- فقط
- منبع باز
- عمل می کند
- گزینه
- گزینه
- or
- سفارش
- سازمان های
- OS
- دیگر
- در غیر این صورت
- خارج
- مروری
- بسته
- بسته
- پارامتر
- پارامترهای
- پارک ها
- عبور
- مسیر
- انجام دادن
- کارایی
- فاز
- خط لوله
- محوری
- قرار داده شده
- سکو
- افلاطون
- هوش داده افلاطون
- PlatoData
- لطفا
- نقطه
- ممکن
- پست
- پتانسیل
- پیش گویی
- پیش بینی
- جلوگیری از
- قبلی
- اصلی
- روند
- پردازش
- در حال پردازش
- پردازنده
- پروژه
- به درستی
- نمونه سازی
- ارائه
- ارائه
- فراهم می کند
- ارائه
- پــایتــون
- مارماهی
- کیفیت
- محدوده
- زمان واقعی
- قلمرو
- به رسمیت شناختن
- توصیه می شود
- ثبت
- کاهش
- مراجعه
- بدون در نظر گرفتن
- مربوط
- منتشر شده
- به یاد داشته باشید
- برداشتن
- حذف می کند
- مخزن
- درخواست
- درخواست
- نیاز
- ضروری
- نیاز
- محققان
- به ترتیب
- پاسخ
- پاسخ
- مسئوليت
- نتیجه
- نتیجه
- نتایج
- حفظ شده است
- بازآموزی
- برگشت
- حکیم ساز
- همان
- ذخیره
- نگهداری می شود
- صرفه جویی کردن
- مقیاس پذیری
- مقیاس
- مقیاس ها
- برنامه ریزی
- دانشمندان
- خط
- اسکریپت
- دوم
- ثانیه
- بخش
- بخش ها
- را انتخاب کنید
- انتخاب شد
- انتخاب
- سلسله
- سرویس
- خدمات
- تنظیم
- محیط
- تنظیمات
- اشتراک گذاری
- او
- باید
- نشان داد
- نشان می دهد
- تعطیل
- قابل توجه
- ساده
- ساده می کند
- اندازه
- اندازه
- کوچک
- کوچکتر
- So
- نرم افزار
- راه حل
- خاص
- به طور خاص
- مشخص شده
- سخنرانی - گفتار
- تشخیص گفتار
- سرعت
- هزینه
- گفته شده
- شروع
- دولت
- وضعیت هنر
- گام
- مراحل
- ذخیره سازی
- استراتژی ها
- متعاقب
- موفق
- چنین
- ناگهانی
- مناسب
- پشتیبانی
- حمایت از
- پشتیبانی از
- مطمئن
- افزایش
- سیستم های
- جدول
- گرفتن
- مصرف
- کار
- وظایف
- پیشرفته
- نسبت به
- که
- La
- انگلستان
- شان
- آنها
- سپس
- آنجا.
- از این رو
- اینها
- آنها
- این
- سه
- زمان
- سری زمانی
- بار
- به
- ابزار
- مشعل
- ترافیک
- قطار
- آموزش دیده
- دگرگون کردن
- ترانسفورماتور
- ترانسفورماتور
- ماشه
- باعث شد
- tv
- TV سری
- دو
- نوع
- به طور معمول
- Uk
- زیر
- باز کردن قفل
- بر
- us
- استفاده کنید
- استفاده
- کاربر پسند
- کاربران
- با استفاده از
- سودمندی
- استفاده کنید
- با استفاده از
- ارزشمند
- ارزش
- متغیر
- مختلف
- وسیع
- نسخه
- دید
- صدا
- دستورات صوتی
- حجم
- صبر کنيد
- می خواهم
- بود
- we
- وب
- خدمات وب
- خوب
- بود
- چه زمانی
- هر زمان که
- که
- نجوا
- وسیع
- دامنه گسترده
- با
- در داخل
- گردش کار
- با این نسخهها کار
- با ارزش
- نوشته
- شما
- شما
- زفیرنت