
سپتامبر 20، 2023
مدل های بنیادی (FM) آغاز یک دوره جدید در یادگیری ماشین (ML) و هوش مصنوعی (AI)که منجر به توسعه سریعتر هوش مصنوعی میشود که میتواند با طیف گستردهای از وظایف پایین دستی سازگار شود و برای مجموعهای از برنامهها بهخوبی تنظیم شود.
با افزایش اهمیت پردازش دادهها در جایی که کار انجام میشود، ارائه مدلهای هوش مصنوعی در لبه سازمانی، پیشبینیهای همزمان را امکانپذیر میکند، در حالی که از الزامات حاکمیت داده و حفظ حریم خصوصی تبعیت میکند. با ترکیب کردن آی بی ام واتسونکس داده ها و قابلیت های پلت فرم هوش مصنوعی برای FM ها با محاسبات لبه، شرکت ها می توانند بارهای کاری هوش مصنوعی را برای تنظیم دقیق FM و استنتاج در لبه عملیاتی اجرا کنند. این به شرکتها امکان میدهد تا استقرار هوش مصنوعی را در لبه مقیاس کنند و زمان و هزینه استقرار را با زمانهای پاسخ سریعتر کاهش دهند.
لطفاً مطمئن شوید که تمام اقساط این سری از پست های وبلاگ در مورد محاسبات لبه را بررسی کنید:
مدل های بنیادی چیست؟
مدلهای بنیادی (FM) که بر روی مجموعه وسیعی از دادههای بدون برچسب در مقیاس آموزش داده میشوند، برنامههای کاربردی پیشرفته هوش مصنوعی (AI) را هدایت میکنند. آنها را می توان با طیف گسترده ای از وظایف پایین دستی تطبیق داد و برای مجموعه ای از برنامه ها به خوبی تنظیم کرد. مدلهای مدرن هوش مصنوعی، که وظایف خاصی را در یک دامنه انجام میدهند، جای خود را به FM میدهند، زیرا آنها به طور کلیتر یاد میگیرند و در دامنهها و مشکلات کار میکنند. همانطور که از نام آن پیداست، FM می تواند پایه و اساس بسیاری از کاربردهای مدل هوش مصنوعی باشد.
FM ها به دو چالش کلیدی می پردازند که شرکت ها را از افزایش پذیرش هوش مصنوعی باز داشته است. اولاً، شرکتها حجم وسیعی از دادههای بدون برچسب تولید میکنند که تنها بخشی از آن برای آموزش مدلهای هوش مصنوعی برچسبگذاری شده است. دوم، این کار برچسبگذاری و حاشیه نویسی بسیار انسانی است و اغلب به چند صد ساعت وقت یک متخصص موضوع (SME) نیاز دارد. این امر باعث میشود که مقیاسبندی در موارد استفاده مقرونبهصرفه باشد، زیرا به ارتشی از SMEها و متخصصان داده نیاز دارد. FM ها با دریافت مقادیر زیادی از داده های بدون برچسب و استفاده از تکنیک های خود نظارت شده برای آموزش مدل، این تنگناها را از بین برده و راه را برای پذیرش گسترده هوش مصنوعی در سراسر سازمان باز کرده اند. این حجم عظیم از دادهها که در هر کسبوکاری وجود دارد، در انتظار انتشار هستند تا بینشهایی را به دست آورند.
مدل های زبان بزرگ چیست؟
مدلهای زبان بزرگ (LLMs) یک کلاس از مدلهای پایه (FM) هستند که از لایههایی تشکیل شدهاند. شبکه های عصبی که بر روی این حجم عظیم از داده های بدون برچسب آموزش دیده اند. آنها از الگوریتم های یادگیری خود نظارتی برای انجام انواع مختلف استفاده می کنند پردازش زبان طبیعی (NLP) وظایف به روشی شبیه به نحوه استفاده انسان از زبان (شکل 1 را ببینید).
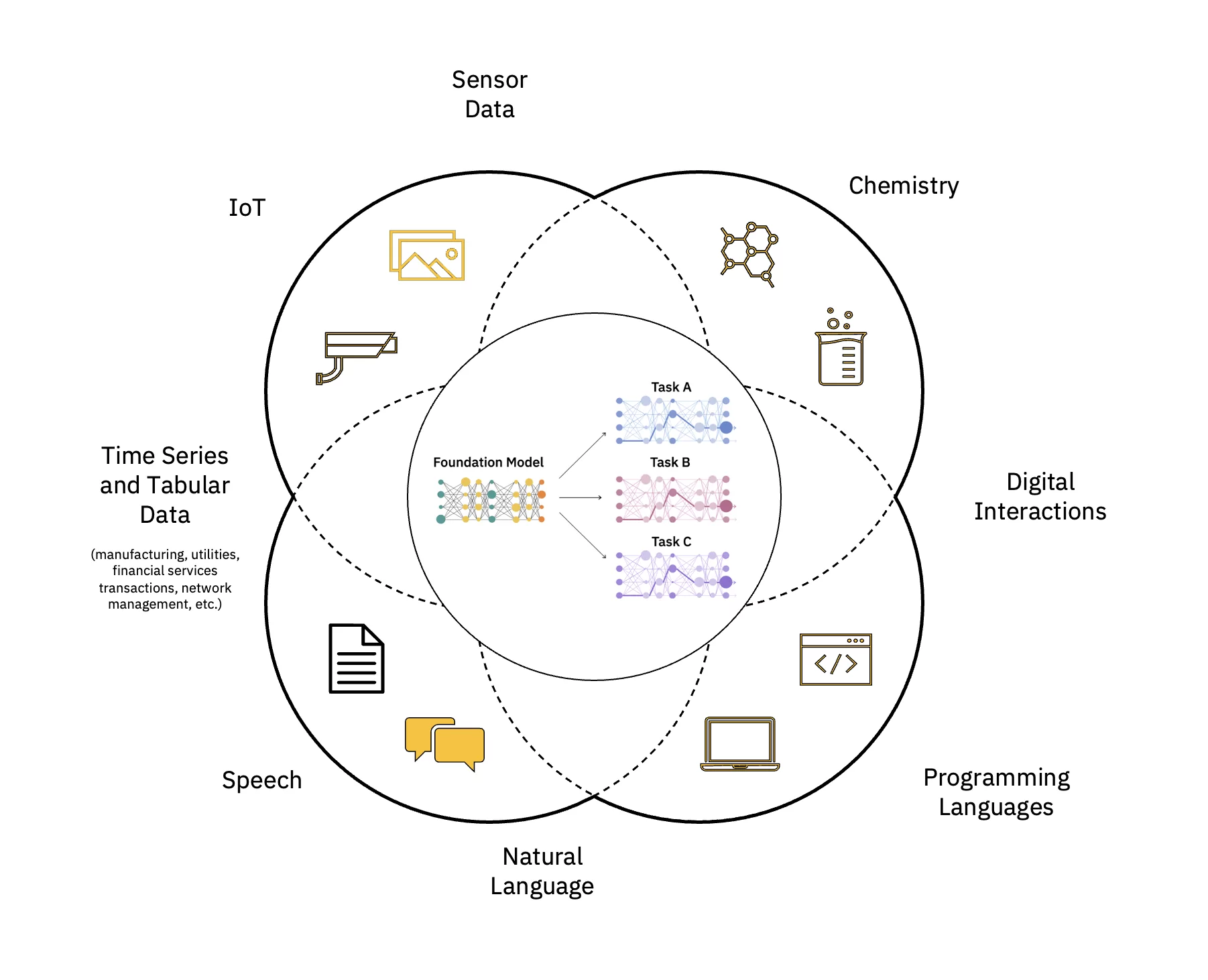
مقیاس و سرعت بخشیدن به تأثیر هوش مصنوعی
چندین مرحله برای ساخت و استقرار یک مدل پایه (FM) وجود دارد. اینها شامل دریافت داده، انتخاب داده، پیش پردازش داده، پیش آموزش FM، تنظیم مدل برای یک یا چند کار پایین دستی، ارائه استنتاج، و مدیریت و مدیریت چرخه عمر مدل داده و هوش مصنوعی است که همه آنها را می توان به صورت زیر توصیف کرد. FMOps.
برای کمک به همه این موارد، IBM ابزارها و قابلیتهای لازم را به شرکتها ارائه میکند تا از قدرت این FMها استفاده کنند. آی بی ام واتسونکس، یک پلتفرم هوش مصنوعی و داده آماده برای سازمانی که برای چند برابر کردن تأثیر هوش مصنوعی در یک شرکت طراحی شده است. IBM watsonx شامل موارد زیر است:
- IBM watsonx.ai جدید می آورد هوش مصنوعی مولد قابلیتهایی که توسط FMها و یادگیری ماشین سنتی (ML) ارائه میشوند، به یک استودیوی قدرتمند که چرخه عمر هوش مصنوعی را در بر میگیرد.
- IBM watsonx.data یک فروشگاه داده مناسب برای مقاصد است که بر اساس معماری خانه دریاچه باز ساخته شده است تا حجم کاری هوش مصنوعی را برای همه داده های شما، در هر مکانی، مقیاس کند.
- IBM watsonx.governance یک جعبه ابزار مدیریت چرخه عمر هوش مصنوعی خودکار سرتاسر است که برای فعال کردن گردشهای کاری هوش مصنوعی مسئولانه، شفاف و قابل توضیح ساخته شده است.
یکی دیگر از عوامل کلیدی، اهمیت فزاینده محاسبات در لبه سازمانی است، مانند مکانهای صنعتی، طبقات تولیدی، فروشگاههای خردهفروشی، سایتهای لبه مخابراتی و غیره. به طور خاص، هوش مصنوعی در لبه سازمانی پردازش دادهها را در جایی که کار برای آن انجام میشود، امکانپذیر میسازد. تجزیه و تحلیل نزدیک به زمان واقعی لبه سازمانی جایی است که حجم وسیعی از دادههای سازمانی تولید میشود و هوش مصنوعی میتواند بینشهای تجاری ارزشمند، بهموقع و عملی را ارائه دهد.
ارائه مدلهای هوش مصنوعی در لبه، پیشبینیهای همزمان را امکانپذیر میکند و در عین حال از حاکمیت دادهها و الزامات حریم خصوصی پیروی میکند. این امر تأخیر اغلب مرتبط با اکتساب، انتقال، تبدیل و پردازش داده های بازرسی را به طور قابل توجهی کاهش می دهد. کار در لبه به ما امکان می دهد از داده های حساس سازمانی محافظت کنیم و هزینه های انتقال داده را با زمان پاسخ سریعتر کاهش دهیم.
با این حال، مقیاسبندی استقرار هوش مصنوعی در لبه، در میان چالشهای مرتبط با دادهها (ناهمگونی، حجم و مقررات) و منابع محدود (محاسبات، اتصال به شبکه، ذخیرهسازی و حتی مهارتهای فناوری اطلاعات) کار آسانی نیست. این موارد را می توان به طور کلی در دو دسته توصیف کرد:
- زمان/هزینه استقرار: هر استقرار شامل چندین لایه سخت افزار و نرم افزار است که قبل از استقرار باید نصب، پیکربندی و آزمایش شوند. امروزه، یک متخصص خدمات می تواند تا یک یا دو هفته برای نصب زمان نیاز داشته باشد در هر مکان، به شدت محدود کردن سرعت و مقرون به صرفه بودن شرکت ها در گسترش استقرار در سراسر سازمانشان.
- مدیریت روز دوم: تعداد زیاد لبههای مستقر شده و موقعیت جغرافیایی هر استقرار اغلب میتواند ارائه پشتیبانی IT محلی در هر مکان برای نظارت، نگهداری و بهروزرسانی این استقرارها را بسیار پرهزینه کند.
استقرار هوش مصنوعی Edge
IBM معماری لبهای را توسعه داده است که با آوردن یک مدل سختافزار/نرمافزار یکپارچه (HW/SW) برای استقرار هوش مصنوعی لبه، به این چالشها میپردازد. این شامل چندین پارادایم کلیدی است که به مقیاس پذیری استقرار هوش مصنوعی کمک می کند:
- ارائه پشته نرم افزاری بدون لمس مبتنی بر سیاست.
- نظارت مستمر بر سلامت سیستم لبه
- قابلیت مدیریت و ارسال بهروزرسانیهای نرمافزار/امنیتی/پیکربندی به مکانهای لبه متعدد—همه از یک مکان مرکزی مبتنی بر ابر برای مدیریت روز دوم.
یک معماری توزیعشده هاب و اسپیک میتواند برای مقیاسبندی استقرار هوش مصنوعی سازمانی در لبه استفاده شود، که در آن یک ابر مرکزی یا مرکز داده سازمانی بهعنوان یک هاب عمل میکند و دستگاه لبه در جعبه بهعنوان یک پره در یک مکان لبه عمل میکند.. این مدل هاب و پره، که در سراسر محیطهای ابری ترکیبی و لبه گسترش مییابد، تعادل لازم برای استفاده بهینه از منابع مورد نیاز برای عملیات FM را به بهترین شکل نشان میدهد (شکل 2 را ببینید).
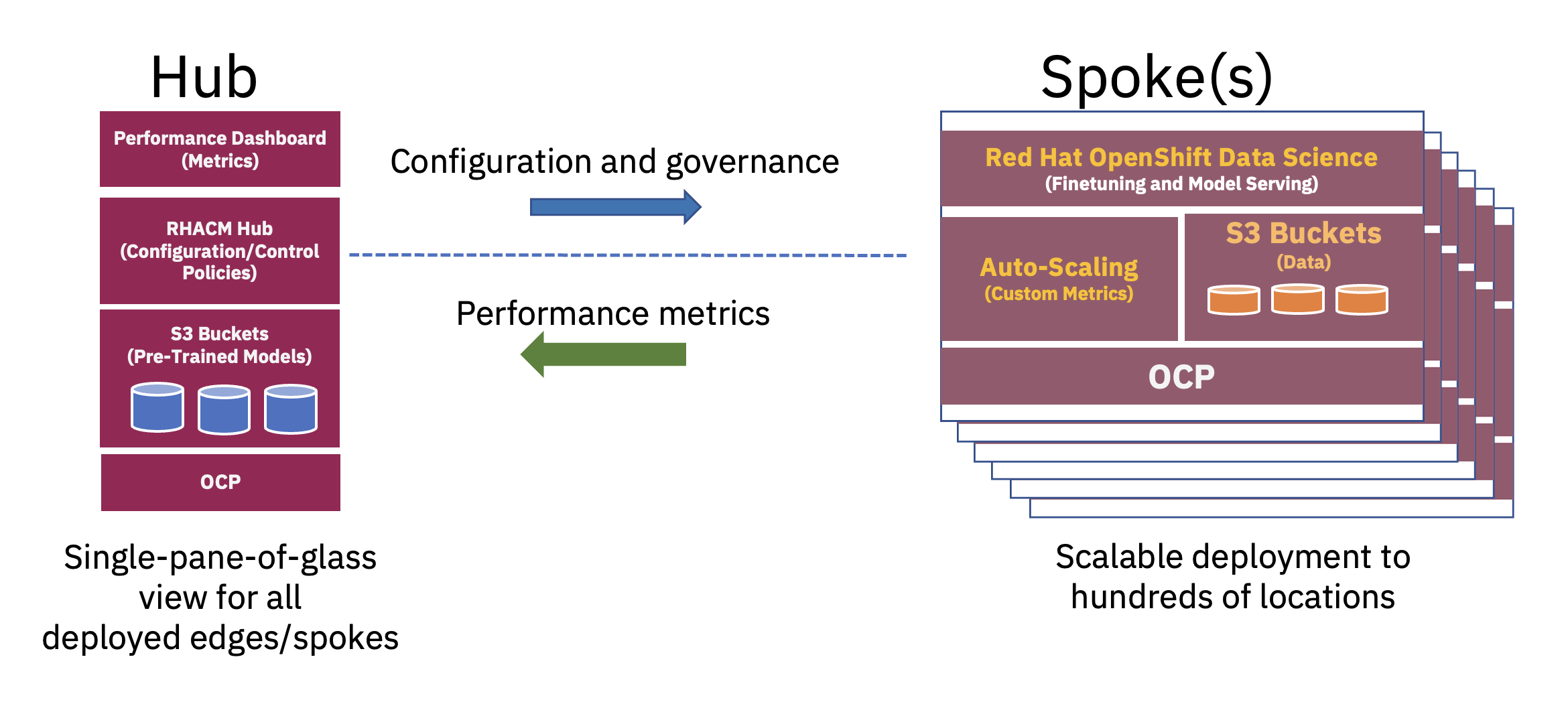
پیشآموزش این مدلهای پایه زبان بزرگ (LLM) و انواع دیگر مدلهای پایه با استفاده از تکنیکهای خود نظارت بر مجموعه دادههای بدون برچسب گسترده، اغلب به منابع محاسباتی (GPU) قابل توجهی نیاز دارد و به بهترین شکل در یک هاب انجام میشود. منابع محاسباتی تقریباً نامحدود و انبوه دادههای بزرگ که اغلب در ابر ذخیره میشوند، امکان پیشآموزش مدلهای پارامترهای بزرگ و بهبود مستمر دقت این مدلهای پایه پایه را فراهم میکنند.
از سوی دیگر، تنظیم این FM های پایه برای کارهای پایین دستی - که فقط به چند ده یا صدها نمونه داده برچسب دار و ارائه استنتاج نیاز دارند - تنها با چند GPU در لبه سازمانی قابل انجام است. این اجازه میدهد تا دادههای برچسبگذاری شده حساس (یا دادههای تاج جواهر سازمانی) با خیال راحت در محیط عملیاتی سازمانی باقی بمانند و در عین حال هزینههای انتقال داده را نیز کاهش دهند.
با استفاده از یک رویکرد تمام پشته برای استقرار برنامه ها در لبه، یک دانشمند داده می تواند تنظیم دقیق، آزمایش و استقرار مدل ها را انجام دهد. این را می توان در یک محیط واحد انجام داد و در عین حال چرخه عمر توسعه را برای ارائه مدل های جدید هوش مصنوعی به کاربران نهایی کاهش داد. پلتفرمهایی مانند Red Hat OpenShift Data Science (RHODS) و Red Hat OpenShift AI ابزارهایی برای توسعه سریع و استقرار مدلهای هوش مصنوعی آماده تولید در ابر توزیع شده و محیط های لبه
در نهایت، ارائه مدل دقیق هوش مصنوعی در لبه سازمانی به طور قابل توجهی تأخیر مرتبط با کسب، انتقال، تبدیل و پردازش داده ها را کاهش می دهد. جداسازی پیشآموزش در ابر از تنظیم دقیق و استنتاج در لبه، هزینه عملیاتی کلی را با کاهش زمان مورد نیاز و هزینههای جابجایی داده مرتبط با هر کار استنتاجی کاهش میدهد (شکل 3 را ببینید).
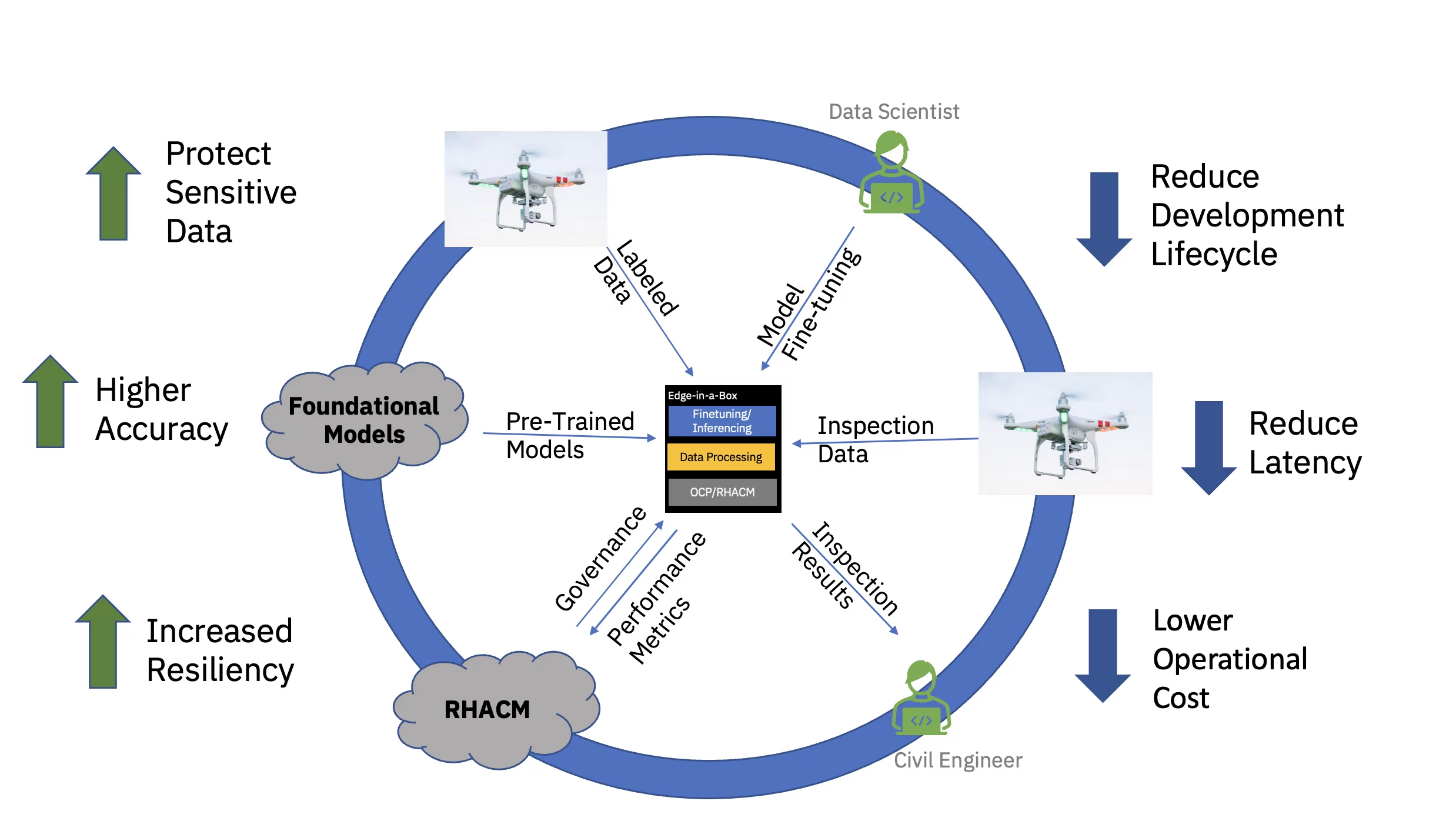
برای نشان دادن این ارزش پیشنهادی سرتاسر، یک مدل پایه مبتنی بر ترانسفورماتور بینایی برای زیرساختهای عمرانی (از پیش آموزش داده شده با استفاده از مجموعه دادههای خاص صنعت عمومی و سفارشی) بهخوبی تنظیم شده و برای استنتاج بر روی یک لبه سه گره به کار گرفته شد. (گفتار) خوشه. پشته نرم افزار شامل پلتفرم کانتینر OpenShift Red Hat و Data Science OpenShift Red Hat بود. این خوشه لبه همچنین به نمونه ای از هاب Red Hat Advanced Cluster Management برای Kubernetes (RHACM) که در فضای ابری اجرا می شود متصل شد.
تامین صفر لمسی
فراهمسازی مبتنی بر خطمشی و بدون لمس با Red Hat Advanced Cluster Management برای Kubernetes (RHACM) از طریق خطمشیها و برچسبهای قرارگیری، که خوشههای لبه خاصی را به مجموعهای از اجزای نرمافزار و پیکربندیها متصل میکنند، انجام شد. این مؤلفههای نرمافزار – که در سراسر پشته کامل گسترش مییابند و محاسبات، ذخیرهسازی، شبکه و حجم کاری هوش مصنوعی را پوشش میدهند – با استفاده از اپراتورهای مختلف OpenShift، ارائه خدمات کاربردی مورد نیاز و S3 Bucket (ذخیرهسازی) نصب شدند.
مدل پایه از پیش آموزشدیده (FM) برای زیرساختهای عمرانی از طریق یک نوتبوک Jupyter در Red Hat OpenShift Data Science (RHODS) با استفاده از دادههای برچسبگذاریشده برای طبقهبندی شش نوع نقص پیدا شده بر روی پلهای بتنی تنظیم شد. ارائه استنتاج این FM با تنظیم دقیق نیز با استفاده از سرور تریتون نشان داده شد. علاوه بر این، نظارت بر سلامت این سیستم لبه با تجمیع معیارهای مشاهده پذیری از قطعات سخت افزاری و نرم افزاری از طریق Prometheus به داشبورد مرکزی RHACM در فضای ابری امکان پذیر شد. شرکتهای زیرساختهای غیرنظامی میتوانند این FMها را در مکانهای لبهشان مستقر کنند و از تصاویر هواپیماهای بدون سرنشین برای شناسایی نقصها در زمان واقعی استفاده کنند – که زمان رسیدن به بینش را تسریع میکند و هزینه انتقال حجم زیادی از دادههای با کیفیت بالا به و از Cloud را کاهش میدهد.
خلاصه
ترکیب آی بی ام واتسونکس داده ها و قابلیت های پلت فرم هوش مصنوعی برای مدل های پایه (FM) با دستگاه لبه در جعبه به شرکت ها اجازه می دهد تا بارهای کاری هوش مصنوعی را برای تنظیم دقیق FM و استنتاج در لبه عملیاتی اجرا کنند. این دستگاه میتواند موارد استفاده پیچیده را خارج از جعبه مدیریت کند و چارچوب هاب و اسپیک را برای مدیریت متمرکز، اتوماسیون و سلف سرویس ایجاد میکند. استقرار Edge FM را می توان با موفقیت تکرارپذیر، انعطاف پذیری و امنیت بالاتر از هفته ها به ساعت ها کاهش داد.
درباره مدل های پایه بیشتر بدانید
لطفاً مطمئن شوید که تمام اقساط این سری از پست های وبلاگ در مورد محاسبات لبه را بررسی کنید:
موارد بیشتر از Cloud




- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://www.ibm.com/blog/foundational-models-at-the-edge/
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 08
- 1
- 10
- 13
- ٪۱۰۰
- 20
- 2023
- 22
- 28
- 29
- 30
- 300
- 39
- 400
- 41
- 7
- 70
- 9
- a
- درباره ما
- شتاب دادن
- دسترسی
- انجام
- دقت
- اکتساب
- در میان
- اعمال
- سازگار
- علاوه بر این
- نشانی
- آدرس
- اتخاذ
- پیشرفته
- پیشرفت
- تبلیغات
- AI
- پذیرش هوش مصنوعی
- مدل های هوش مصنوعی
- پلتفرم هوش مصنوعی
- کمک
- الگوریتم
- معرفی
- اجازه دادن
- اجازه می دهد تا
- همچنین
- در میان
- مقدار
- مقدار
- amp
- an
- تحلیل
- علم تجزیه و تحلیل
- و
- اعلام کرد
- هر
- هر جا
- کاربرد
- برنامه های کاربردی
- روش
- معماری
- هستند
- صف
- مقاله
- مصنوعی
- هوش مصنوعی
- هوش مصنوعی (AI)
- AS
- مرتبط است
- At
- نویسنده
- خودکار
- اتوماسیون
- در دسترس
- خیابان
- به عقب
- برج میزان
- بانک
- بانک
- پایه
- BE
- زیرا
- شدن
- تبدیل شدن به
- بوده
- شروع
- بودن
- باور
- بهترین
- اتصال
- بلاگ
- پست های وبلاگ
- وبلاگ ها
- هر دو
- جعبه
- پل
- آوردن
- به ارمغان می آورد
- پهن
- گسترده
- بنا
- می سازد
- ساخته
- کسب و کار
- by
- CAN
- قابلیت های
- سرمایه
- ضبط
- کربن
- کارت
- کارت ها
- موارد
- CAT
- دسته
- علت
- مرکز
- مرکزی
- بانک مرکزی
- ارزهای دیجیتال بانک مرکزی
- متمرکز
- زنجیر
- چالش ها
- تغییر دادن
- متغیر
- بررسی
- انتخاب
- محافل
- CIS
- مدنی
- کلاس
- طبقه بندی کنید
- واضح
- مشتریان
- نزدیک
- ابر
- خوشه
- رنگ
- رنگارنگ
- ترکیب
- رقابتی
- پیچیده
- پیچیدگی
- انطباق
- اجزاء
- محاسبه
- محاسبه
- پیکر بندی
- پیکربندی
- متصل
- اتصال
- تشکیل شده است
- ظرف
- ادامه دادن
- کنترل
- هزینه
- هزینه
- میتوانست
- پوشش
- کریپتو کارنسی (رمز ارزها )
- CSS
- ارز
- سفارشی
- مشتری
- تجربه مشتری
- مشتریان
- داشبورد
- داده ها
- مرکز داده
- بستر داده
- علم اطلاعات
- دانشمند داده
- مجموعه داده ها
- تاریخ
- اختصاصی
- به طور پیش فرض
- تعاریف
- ارائه
- نشان دادن
- نشان
- گسترش
- مستقر
- استقرار
- گسترش
- اعزام ها
- شرح داده شده
- شرح
- طراحی
- توسعه
- توسعه
- پروژه
- دیجیتال
- ارزهای دیجیتال
- دیجیتالی شدن
- قطع
- نفاق افکن
- اخلالگران
- توزیع شده
- ناحیه
- دامنه
- حوزه
- انجام شده
- راندن
- رانندگی
- وزوز
- هر
- ساده
- اکوسیستم
- لبه
- محاسبات لبه
- بالا بردن
- مرتفع
- قادر ساختن
- را قادر می سازد
- پایان
- پشت سر هم
- مهندس
- مهندسی
- وارد
- سرمایه گذاری
- شرکت
- ورودی
- محیط
- محیط
- عصر
- به خصوص
- و غیره
- اتر (ETH)
- حتی
- حوادث
- هر
- تکامل
- در حال بررسی
- مثال ها
- اجرا کردن
- وجود داشته باشد
- خروج
- گران
- تجربه
- کارشناسان
- AI قابل توضیح
- توضیح دادن
- گسترش
- خیلی
- عوامل
- FAST
- سریعتر
- کمی از
- رشته
- شکل
- مالی
- موسسات مالی
- تامین مالی
- نام خانوادگی
- طبقه
- به دنبال
- پیروی
- فونت
- برای
- خط مقدم
- یافت
- پایه
- کسر
- چارچوب
- از جانب
- کامل
- پشته کامل
- بعلاوه
- عموما
- تولید
- ژنراتور
- جغرافیایی
- ژئوپلیتیک
- دادن
- جهانی
- تجارت جهانی
- حکومت
- GPU
- GPU ها
- توری
- دست
- دسته
- سخت افزار
- است
- آیا
- سلامتی
- ارتفاع
- کمک
- کمک
- کمک می کند
- کیفیت بالا
- بالاتر
- خیلی
- تاریخ
- میزبان
- ساعت ها
- چگونه
- چگونه
- اما
- HTTPS
- قطب
- انسان
- صدها نفر
- ترکیبی
- ابر هیبرید
- آی بی ام
- IBM Cloud
- ICO
- ICON
- نشان می دهد
- تصویر
- تأثیر
- اهمیت
- بهبود
- in
- شامل
- مشمول
- افزایش
- به طور فزاینده
- شاخص
- صنعتی
- لوازم
- صنعت
- خاص صنعت
- تورم
- تورم
- نقطه عطف
- تحت تاثیر قرار گرفت
- شالوده
- ابتکار عمل
- ابداع
- ابتکاری
- ورودی
- بینش
- نمونه
- موسسات
- یکپارچه
- اطلاعات
- ذاتی
- معرفی
- IT
- پشتیبانی IT
- سفرها
- JPG
- پرش
- نوت بوک ژوپیتر
- تنها
- فقط یکی
- نگه داشته شد
- کلید
- کوبرنیتس
- برچسب
- زبان
- بزرگ
- تا حد زیادی
- تاخیر
- آخرین
- لایه
- برجسته
- یاد گرفتن
- یادگیری
- قدرت نفوذ
- wifecycwe
- پسندیدن
- بی حد و حصر
- لینوکس
- محلی
- محل
- محل
- مکان
- طولانی
- نگاه کنيد
- دستگاه
- فراگیری ماشین
- ساخته
- حفظ
- ساخت
- باعث می شود
- مدیریت
- مدیریت
- تولید
- بسیاری
- علامت گذاری
- عظیم
- استاد
- ماده
- حداکثر عرض
- مکانیسم
- روش
- متریک
- دقیقه
- به حداقل رساندن
- دقیقه
- ML
- موبایل
- مدل
- مدل
- مدرن
- نوسازی
- نوین کردن
- مانیتور
- نظارت بر
- بیش
- جنبش
- متحرک
- نام
- جهت یابی
- نزدیک
- لازم
- نیاز
- ضروری
- نیازهای
- شبکه
- جدید
- بعد
- nlp
- دفتر یادداشت
- هیچ چی
- اکنون
- عدد
- متعدد
- of
- ارائه
- غالبا
- on
- ONE
- فقط
- باز کن
- باز
- قابل استفاده
- عملیات
- اپراتور
- بهینه
- or
- کدام سازمان ها
- دیگر
- ما
- خارج
- به طور کلی
- بسته
- با ما
- پارامتر
- پرداخت
- روش های پرداخت
- مبلغ پرداختی
- انجام دادن
- انجام
- پی اچ پی
- کاریابی
- سکو
- سیستم عامل
- افلاطون
- هوش داده افلاطون
- PlatoData
- پلاگین
- نقطه
- سیاست
- سیاست
- موقعیت
- ممکن
- پست
- پست ها
- پتانسیل
- قدرت
- قوی
- پیش بینی
- قبلا
- خلوت
- خصوصی
- مشکلات
- در حال پردازش
- تولید کردن
- حرفه ای
- پیشنهاد
- ارائه
- عمومی
- فشار
- محدوده
- سریعا
- مطالعه
- زمان واقعی
- تازه
- رکورد
- ضبط
- قرمز
- ردهت
- كاهش دادن
- کاهش
- را کاهش می دهد
- کاهش
- مقررات
- رگولاتور
- تنظیم کننده
- مربوط
- حذف شده
- قابل تکرار
- نیاز
- ضروری
- مورد نیاز
- لازمه
- تحقیق
- منابع
- پاسخ
- مسئوليت
- پاسخگو
- خرده فروشی
- طلوع
- ربات ها
- دویدن
- در حال اجرا
- با خیال راحت
- همان
- مقیاس پذیری
- مقیاس
- مقیاس Ai
- مقیاس گذاری
- علم
- دانشمند
- پرده
- اسکریپت
- دوم
- ایمن
- تیم امنیت لاتاری
- دیدن
- مشاهده
- انتخاب
- سلف سرویس
- حساس
- جستجوگرها
- سپتامبر
- سلسله
- سرور
- سرویس
- خدمات
- خدمت
- جلسه
- جلسات
- تنظیم
- چند
- اشتراک گذاری
- نشان
- قابل توجه
- به طور قابل توجهی
- مشابه
- پس از
- سنگاپور
- تنها
- محیط واحد
- سایت
- سایت
- شش
- مهارت ها
- کوچک
- EMS
- شرکتهای کوچک و متوسط
- نرم افزار
- اجزای نرم افزار
- راه حل
- حق حاکمیت
- فضا
- تنش
- خاص
- به طور خاص
- حمایت مالی
- پشته
- شروع
- وضعیت هنر
- ماندن
- مراحل
- ذخیره سازی
- opbevare
- ذخیره شده
- پرده
- طوفان
- استودیو
- موضوع
- موفقیت
- چنین
- حاکی از
- عرضه
- زنجیره تامین
- پشتیبانی
- مطمئن
- سیستم
- گرفتن
- صورت گرفته
- کار
- وظایف
- تکنیک
- پیشرفته
- مخابراتی
- Temenos
- ده ها
- Terraform
- آزمایش
- تست
- که
- La
- شان
- موضوع
- آنجا.
- اینها
- آنها
- این
- از طریق
- زمان
- بموقع
- بار
- عنوان
- به
- امروز
- با هم
- ابزار
- ابزار
- بالا
- تجارت
- سنتی
- قطار
- آموزش دیده
- آموزش
- انتقال
- دگرگون کردن
- دگرگونی
- تحولات
- شفاف
- تریتون
- توییتر
- دو
- نوع
- انواع
- رها شده
- بروزرسانی
- به روز رسانی
- URL
- us
- استفاده کنید
- استفاده
- کاربران
- با استفاده از
- استفاده کنید
- استفاده
- ارزشمند
- ارزش
- گزاره ارزش
- تنوع
- مختلف
- وسیع
- از طريق
- چشم انداز
- عملا
- حجم
- جلد
- W
- منتظر
- کیف پول
- بود
- موج
- مسیر..
- راه
- we
- هفته
- هفته
- چی
- چه شده است
- چه زمانی
- که
- در حین
- WHO
- چرا
- وسیع
- دامنه گسترده
- با
- در داخل
- زن
- وردپرس
- مهاجرت کاری
- گردش کار
- کارگر
- خواهد بود
- کتبی
- شما
- زفیرنت











