در دنیای امروز، مشتریان حجم وسیعی از داده ها را در خود مدیریت می کنند سرویس ذخیره سازی ساده آمازون دریاچه های داده (Amazon S3)، که به خطوط لوله داده پیچیده نیاز دارد تا به طور مداوم تغییرات در چیدمان داده ها را درک کند و آنها را در اختیار سیستم های مصرف کننده قرار دهد. چسب AWS خزنده ها راه ساده ای را برای فهرست کردن داده ها در کاتالوگ داده چسب AWS ارائه می دهند که در مدیریت طرح و طبقه بندی داده ها، مشکلات سنگین را حذف می کند. خزنده های چسب AWS طرح و پارتیشن های داده را از آمازون S3 استخراج می کنند تا به طور خودکار کاتالوگ داده را پر کنند و ابرداده را جاری نگه دارند.
اما با رشد تصاعدی داده ها در طول زمان، تعداد پارتیشن ها در یک جدول مشخص می تواند به طور قابل توجهی افزایش یابد. زیرا خدمات تحلیلی دوست دارند آمازون آتنا در جدولی که حاوی میلیون ها پارتیشن است پرس و جو کنید، زمان لازم برای بازیابی پارتیشن افزایش می یابد و می تواند باعث افزایش زمان اجرای پرس و جو شود.
امروزه، پشتیبانی خزنده AWS Glue گسترش یافته است تا به طور خودکار شاخص های پارتیشن برای جداول تازه کشف شده اضافه شود تا پردازش پرس و جو در مجموعه داده پارتیشن بندی شده بهینه شود. اکنون، هنگامی که خزنده یک جدول جدید کاتالوگ داده را در طول اجرای خزنده ایجاد می کند، به طور پیش فرض یک شاخص پارتیشن نیز ایجاد می کند که بیشترین جایگشت از همه ستون های پارتیشن عددی و رشته ای را به عنوان کلید دارد. سپس کاتالوگ داده یک فهرست قابل جستجو بر اساس این کلیدها ایجاد می کند و زمان لازم برای بازیابی و فیلتر کردن ابرداده های پارتیشن در جداول با میلیون ها پارتیشن را کاهش می دهد. ایجاد نمایه های پارتیشن به بارهای کاری تجزیه و تحلیلی که در Athena اجرا می شود، سود می رساند، آمازون EMR, آمازون Redshift Spectrumو چسب AWS.
در این پست، نحوه ایجاد نمایه های پارتیشن با خزنده چسب AWS و مقایسه بهبود عملکرد پرس و جو هنگام دسترسی به داده های خزی شده با و بدون شاخص پارتیشن از Athena را توضیح می دهیم.
بررسی اجمالی راه حل
ما از یک AWS CloudFormation الگو برای ایجاد منابع راه حل ما. در مراحل زیر، نحوه پیکربندی خزنده چسب AWS برای ایجاد یک شاخص پارتیشن با استفاده از کنسول AWS Glue یا رابط خط فرمان AWS (AWS CLI). سپس بهبود عملکرد پرس و جو را با استفاده از Athena مقایسه می کنیم.
پیش نیازها
برای دنبال کردن این پست، باید به یک دسترسی داشته باشید هویت AWS و مدیریت دسترسی نقش مدیر (IAM) برای ایجاد منابع با استفاده از AWS CloudFormation.
منابع راه حل خود را تنظیم کنید
قالب CloudFormation منابع زیر را تولید می کند:
- نقش ها و سیاست های IAM
- یک پایگاه داده چسب AWS برای نگهداری طرحواره
- یک خزنده چسب AWS که به یک مجموعه داده بسیار پارتیشن بندی شده اشاره می کند
- یک گروه کاری آتنا و یک سطل برای ذخیره نتایج پرس و جو
مراحل زیر را برای تنظیم منابع راه حل کامل کنید:
- وارد شوید کنسول مدیریت AWS به عنوان یک مدیر IAM.
- را انتخاب کنید Stack را راه اندازی کنید برای استقرار الگوی CloudFormation:

- برای نام پایگاه داده، پیش فرض را حفظ کنید
blog_partition_index_crawlerdb.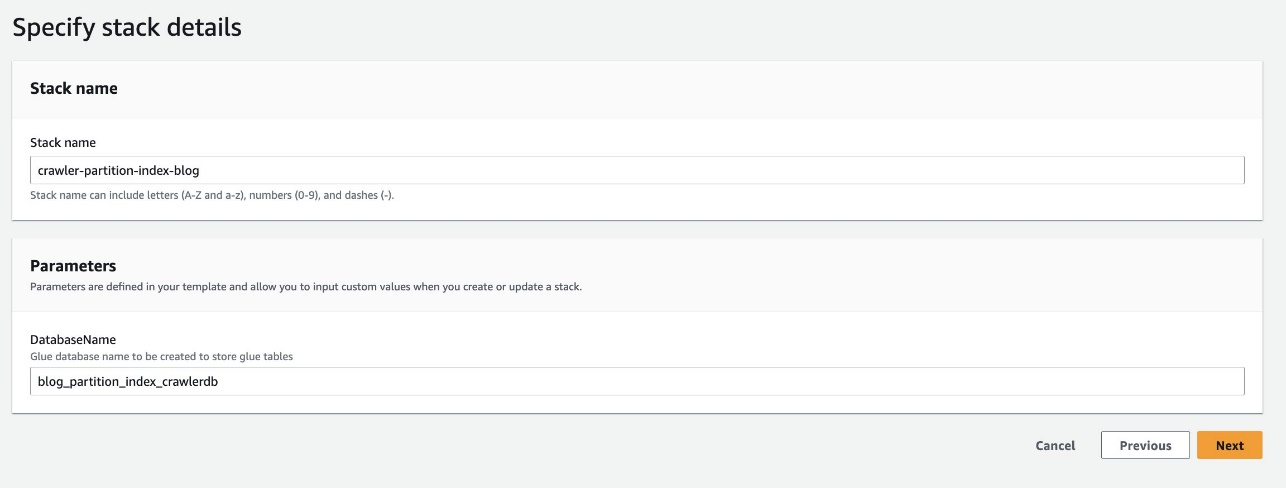
- را انتخاب کنید بعدی.
- جزئیات صفحه آخر را بررسی کرده و انتخاب کنید من تصدیق می کنم که AWS CloudFormation ممکن است منابع IAM را ایجاد کند.
- را انتخاب کنید پشته ایجاد کنید.
- هنگامی که پشته کامل شد، در کنسول AWS CloudFormation، به مسیر بروید خروجی زبانه پشته
- مقادیر را یادداشت کنید
DatabaseNameوGlueCrawlerName.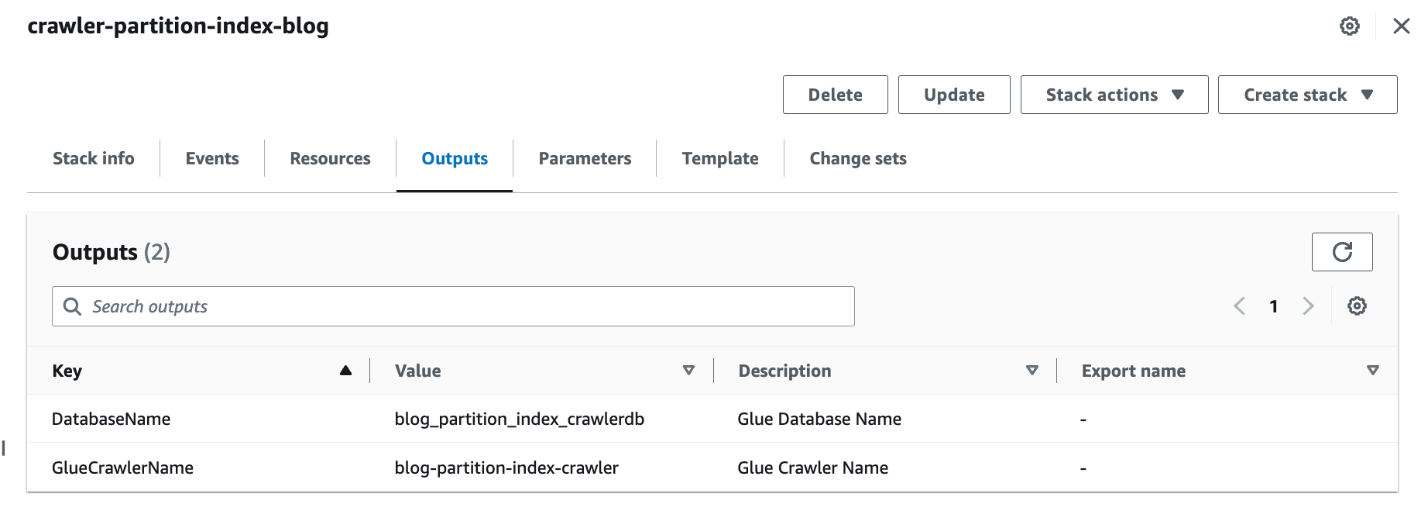
برخی از منابعی که این پشته به کار میبرد هزینههایی را در هنگام استفاده به همراه دارد.
خزنده AWS Glue را ویرایش و اجرا کنید
برای پیکربندی و اجرای خزنده چسب AWS، مراحل زیر را انجام دهید:
- در کنسول AWS Glue، را انتخاب کنید خزنده ها در صفحه ناوبری
- تعیین محل
crawler blog-partition-index-crawlerو انتخاب کنید ویرایش.
- در خروجی و زمان بندی را تنظیم کنید بخش، زیر گزینه های پیشرفته، انتخاب کنید ایجاد نمایه های پارتیشن به صورت خودکار.
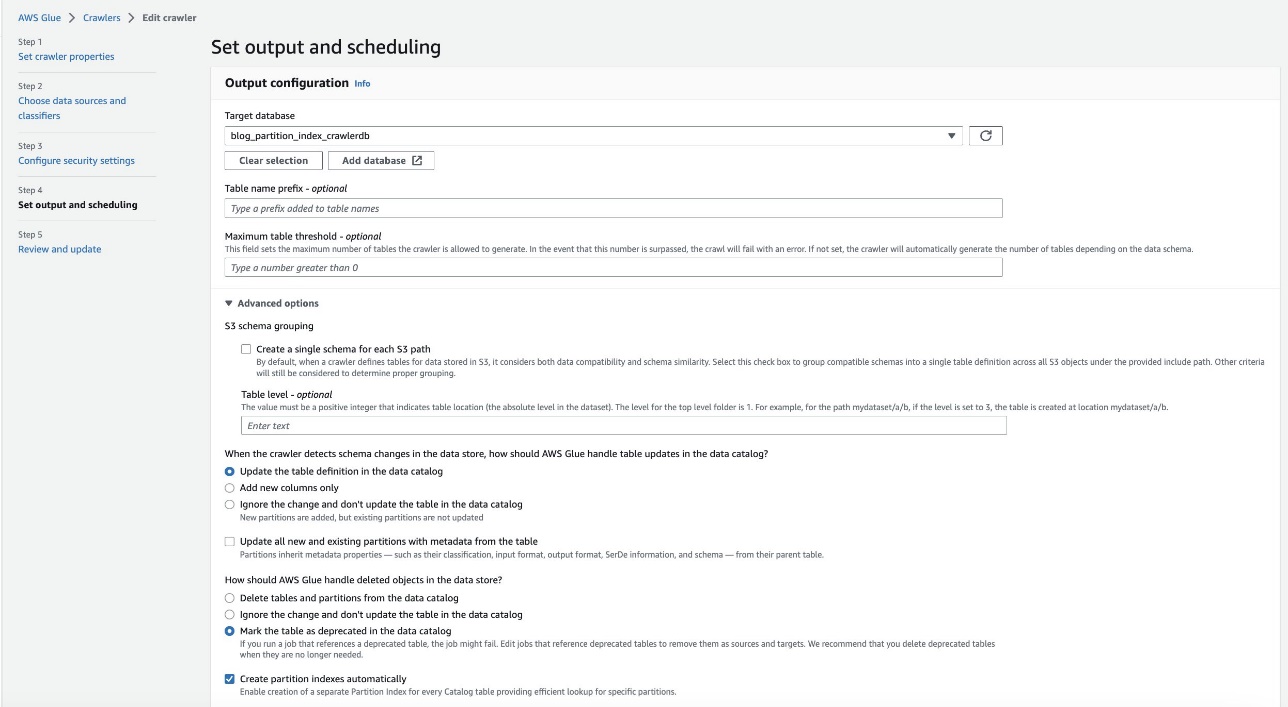
- تنظیمات خزنده را بررسی و به روز کنید.
همچنین، میتوانید خزنده خود را با استفاده از AWS CLI پیکربندی کنید (نقش و منطقه IAM خود را ارائه دهید):
- اکنون خزنده را اجرا کنید و بررسی کنید که اجرای خزنده کامل شده است.
این مجموعه داده بسیار پارتیشن بندی شده است و تقریباً 90 دقیقه طول می کشد تا تکمیل شود.
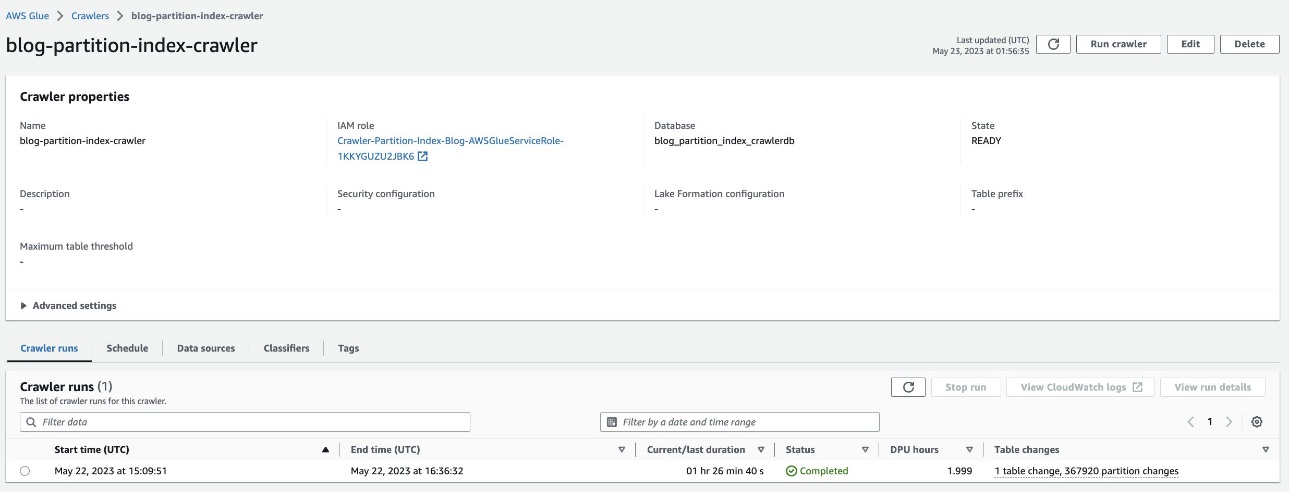
جدول پارتیشن بندی شده را بررسی کنید
در پایگاه داده AWS Glue blog_partition_index_crawlerdb، بررسی کنید که جدول highly_partitioned_table ایجاد شده است
به طور پیش فرض، خزنده یک شاخص را بر اساس بزرگترین جایگشت ستون های پارتیشن از انواع ستون های معتبر در همان ترتیب ستون های پارتیشن، که عددی یا رشته ای هستند، تعیین می کند. برای جدول ایجاد شده توسط خزنده (highly_partitioned_table)، ما ستون های پارتیشن داریم year (رشته)، month (رشته)، day (رشته)، و hour (رشته).
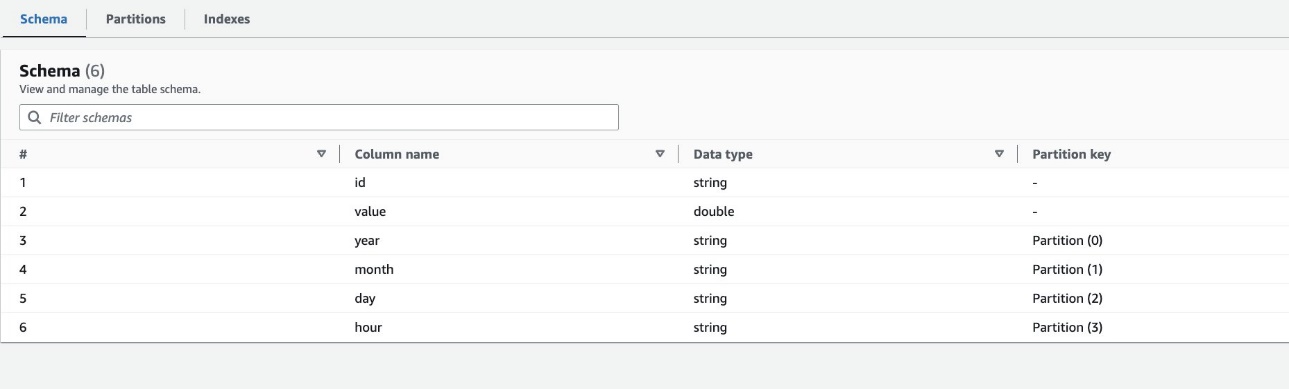
بر اساس این تعریف، خزنده شاخصی بر روی جایگشت سال، ماه، روز و ساعت ایجاد کرد. خزنده ایندکس ها را با پیشوند ایجاد کرد crawler_ در هر شاخص پارتیشن ایجاد شده به طور پیش فرض.
همان را با رفتن به جدول تأیید کنید highly_partitioned_table در کنسول AWS Glue و انتخاب شاخص تب.
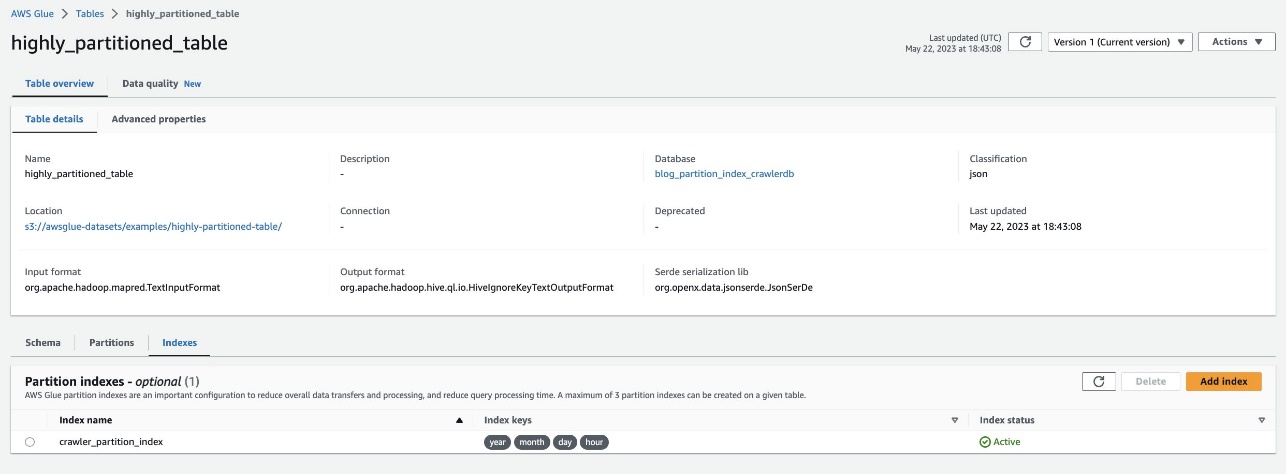
خزنده توانست منبع داده S3 را بخزد و شاخص های پارتیشن جدول را با موفقیت پر کند.
بهبود عملکرد پرس و جو را با استفاده از Athena مقایسه کنید
ابتدا جدول را در آتنا بدون استفاده از شاخص پارتیشن پرس و جو می کنیم. برای تایید جداول با استفاده از آتنا، مراحل زیر را انجام دهید:
- در کنسول آتنا، انتخاب کنید
crawler-primary-workgroupبه عنوان کارگروه آتنا و انتخاب کنید اذعان.
- کوئری زیر را اجرا کنید:
تصویر زیر نشان میدهد که پرس و جو تقریباً 32 ثانیه بدون فیلتر کردن با استفاده از نمایه پارتیشن فعال شده است.
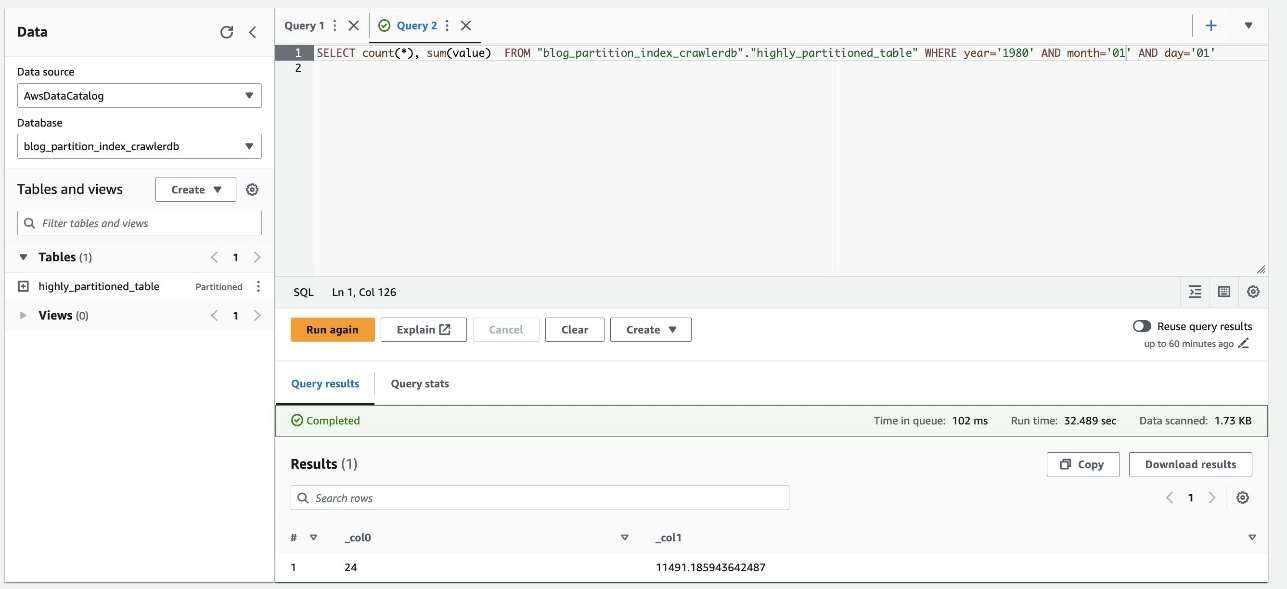
- اکنون شاخص پارتیشن را در کوئری Athena فعال می کنیم:
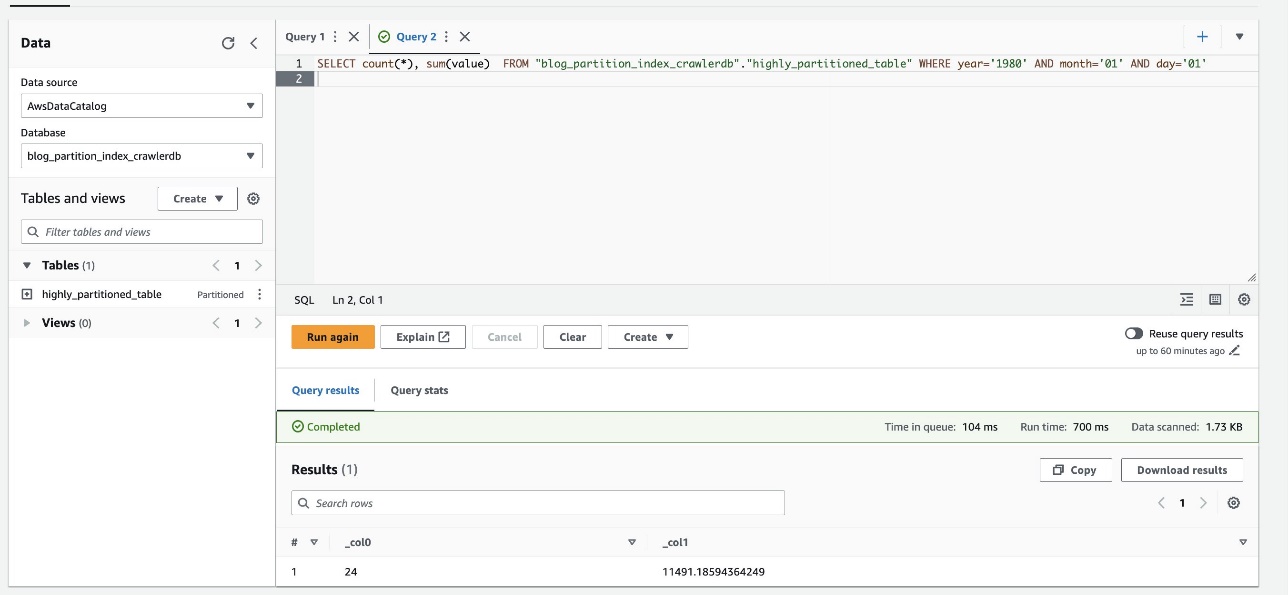
- دوباره کوئری زیر را اجرا کنید و زمان اجرا را یادداشت کنید:
تصویر زیر نشان می دهد که پرس و جو فقط 700 میلی ثانیه طول کشیده است که با فعال کردن فیلتر با استفاده از شاخص پارتیشن بسیار سریعتر است.
پاک کردن
برای جلوگیری از هزینه های ناخواسته به حساب AWS خود، می توانید منابع AWS را حذف کنید:
- به عنوان سرپرست IAM که برای ایجاد پشته CloudFormation استفاده میکند، وارد کنسول CloudFormation شوید.
- پشته CloudFormation را که ایجاد کرده اید حذف کنید.
نتیجه
در این پست، نحوه پیکربندی یک خزنده AWS برای ایجاد نمایه های پارتیشن را توضیح دادیم و عملکرد پرس و جو را هنگام دسترسی به داده ها با شاخص های Athena مقایسه کردیم.
اگر هیچ شاخص پارتیشنی روی جدول وجود نداشته باشد، AWS Glue تمام پارتیشنهای جدول را بارگیری میکند و سپس پارتیشنهای بارگذاری شده را فیلتر میکند که منجر به بازیابی ناکارآمد ابرداده میشود. سرویسهای تحلیلی مانند Redshift Spectrum، Amazon EMR، و AWS Glue ETL Spark DataFrames اکنون میتوانند از شاخصها برای واکشی پارتیشنها استفاده کنند که در نتیجه عملکرد پرسوجو قابل توجهی دارد.
برای اطلاعات بیشتر در مورد شاخص های پارتیشن و عملکرد پرس و جو در موتورهای تحلیلی مختلف، مراجعه کنید با استفاده از شاخص های پارتیشن AWS Glue Data Catalog عملکرد جستجوی Amazon Athena را بهبود بخشید و عملکرد پرس و جو را با استفاده از شاخص های پارتیشن چسب AWS بهبود دهید.
تشکر ویژه از همه کسانی که در راه اندازی این ویژگی خزنده مشارکت داشتند: یوهانگ چن، کایل دونگ، و میتا گاواد.
درباره نویسندگان
 سریویدیا پارتاساراتی یک معمار ارشد داده های بزرگ در تیم AWS Lake Formation است. او از ساخت راه حل های مش داده و به اشتراک گذاری آنها با جامعه لذت می برد.
سریویدیا پارتاساراتی یک معمار ارشد داده های بزرگ در تیم AWS Lake Formation است. او از ساخت راه حل های مش داده و به اشتراک گذاری آنها با جامعه لذت می برد.
 ساندیپ ادوانکار یک مدیر ارشد محصول فنی در AWS است. او که در منطقه خلیج کالیفرنیا مستقر است، با مشتریان در سراسر جهان کار می کند تا الزامات تجاری و فنی را به محصولاتی تبدیل کند که مشتریان را قادر می سازد نحوه مدیریت، ایمن سازی و دسترسی به داده ها را بهبود بخشند.
ساندیپ ادوانکار یک مدیر ارشد محصول فنی در AWS است. او که در منطقه خلیج کالیفرنیا مستقر است، با مشتریان در سراسر جهان کار می کند تا الزامات تجاری و فنی را به محصولاتی تبدیل کند که مشتریان را قادر می سازد نحوه مدیریت، ایمن سازی و دسترسی به داده ها را بهبود بخشند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- EVM Finance. رابط یکپارچه برای امور مالی غیرمتمرکز دسترسی به اینجا.
- گروه رسانه ای کوانتومی. IR/PR تقویت شده دسترسی به اینجا.
- PlatoAiStream. Web3 Data Intelligence دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/efficiently-crawl-your-data-lake-and-improve-data-access-with-aws-glue-crawler-using-partition-indexes/
- : دارد
- :است
- :جایی که
- $UP
- 1
- 100
- 11
- 27
- 32
- 8
- 9
- 90
- a
- قادر
- دسترسی
- دسترسی
- حساب
- اذعان
- در میان
- اضافه کردن
- مدیر سایت
- از نو
- معرفی
- در امتداد
- همچنین
- آمازون
- آمازون آتنا
- آمازون EMR
- آمازون خدمات وب
- مقدار
- an
- تحلیلی
- علم تجزیه و تحلیل
- و
- هر
- تقریبا
- هستند
- محدوده
- دور و بر
- AS
- At
- بطور خودکار
- در دسترس
- اجتناب از
- AWS
- AWS CloudFormation
- چسب AWS
- سازند دریاچه AWS
- مستقر
- سرخ مایل به قرمز
- زیرا
- بوده
- مزایای
- بزرگ
- بزرگ داده
- بنا
- کسب و کار
- by
- کالیفرنیا
- CAN
- کاتالوگ
- علت
- تبادل
- بار
- چن
- را انتخاب کنید
- انتخاب
- طبقه بندی
- ستون
- ستون ها
- می آید
- انجمن
- مقايسه كردن
- مقایسه
- کامل
- کنسول
- به طور مداوم
- کمک
- هزینه
- خزنده
- ایجاد
- ایجاد شده
- ایجاد
- ایجاد
- ایجاد
- جاری
- مشتریان
- داده ها
- دسترسی به داده ها
- دریاچه دریاچه
- پایگاه داده
- روز
- به طور پیش فرض
- نشان دادن
- گسترش
- مستقر می کند
- توصیف
- جزئیات
- تعیین می کند
- کشف
- پایین
- در طی
- موثر
- هر دو
- قادر ساختن
- فعال
- موتورهای حرفه ای
- اتر (ETH)
- هر کس
- منبسط
- توضیح داده شده
- نمایی
- عصاره
- داده ها را استخراج کنید
- سریعتر
- ویژگی
- فیلتر
- فیلتر
- فیلترها برای تصفیه آب
- نهایی
- به دنبال
- پیروی
- برای
- تشکیل
- از جانب
- تولید می کند
- داده
- زمین
- شدن
- در حال رشد
- آیا
- he
- سنگین
- بلند کردن سنگین
- خیلی
- نگه داشتن
- ساعت
- چگونه
- چگونه
- HTML
- HTTP
- HTTPS
- IAM
- هویت
- بهبود
- بهبود
- ارتقاء
- in
- افزایش
- افزایش
- شاخص
- فهرستها
- ناکارآمد
- اطلاعات
- به
- IT
- JPG
- نگاه داشتن
- نگهداری
- کلید
- دریاچه
- بزرگترین
- راه اندازی
- طرح
- بلند کردن اجسام
- پسندیدن
- لاین
- بارهای
- ساخت
- مدیریت
- مدیریت
- مدیر
- مش
- متاداده
- قدرت
- میلیون ها نفر
- دقیقه
- ماه
- بیش
- بسیار
- باید
- هدایت
- پیمایش
- جهت یابی
- ضروری
- جدید
- به تازگی
- نه
- اکنون
- عدد
- of
- on
- فقط
- بهینه سازی
- or
- سفارش
- ما
- تولید
- روی
- با ما
- قطعه
- مسیر
- کارایی
- افلاطون
- هوش داده افلاطون
- PlatoData
- پست
- در حال حاضر
- در حال پردازش
- محصول
- مدیر تولید
- محصولات
- ارائه
- کاهش
- منطقه
- ضروری
- مورد نیاز
- نیاز
- منابع
- نتیجه
- نتایج
- نقش
- نقش
- دویدن
- در حال اجرا
- همان
- ثانیه
- بخش
- امن
- ارشد
- خدمات
- تنظیم
- تنظیمات
- اشتراک
- او
- نشان می دهد
- قابل توجه
- به طور قابل توجهی
- ساده
- راه حل
- مزایا
- منبع
- جرقه
- طیف
- پشته
- مراحل
- ذخیره سازی
- opbevare
- ساده
- رشته
- موفقیت
- پشتیبانی
- سیستم های
- جدول
- گرفتن
- تیم
- فنی
- قالب
- با تشکر
- که
- La
- شان
- آنها
- سپس
- اینها
- آنها
- این
- زمان
- به
- امروز
- در زمان
- ترجمه کردن
- درست
- نوع
- انواع
- زیر
- فهمیدن
- ناخواسته
- بروزرسانی
- استفاده کنید
- استفاده
- با استفاده از
- استفاده کنید
- ارزش
- ارزشها
- مختلف
- وسیع
- بررسی
- نسخه
- بود
- مسیر..
- we
- وب
- خدمات وب
- چه زمانی
- که
- WHO
- اراده
- با
- بدون
- کارگروه
- با این نسخهها کار
- جهان
- یامل
- سال
- شما
- شما
- زفیرنت