
تصویر از نویسنده | ایجاد کننده تصویر بینگ
دالی 2.0 یک مدل زبان بزرگ منبع باز، پیروی از دستورالعمل ها (LLM) است که به خوبی بر روی مجموعه داده های تولید شده توسط انسان تنظیم شده است. می توان از آن برای اهداف تحقیقاتی و تجاری استفاده کرد.
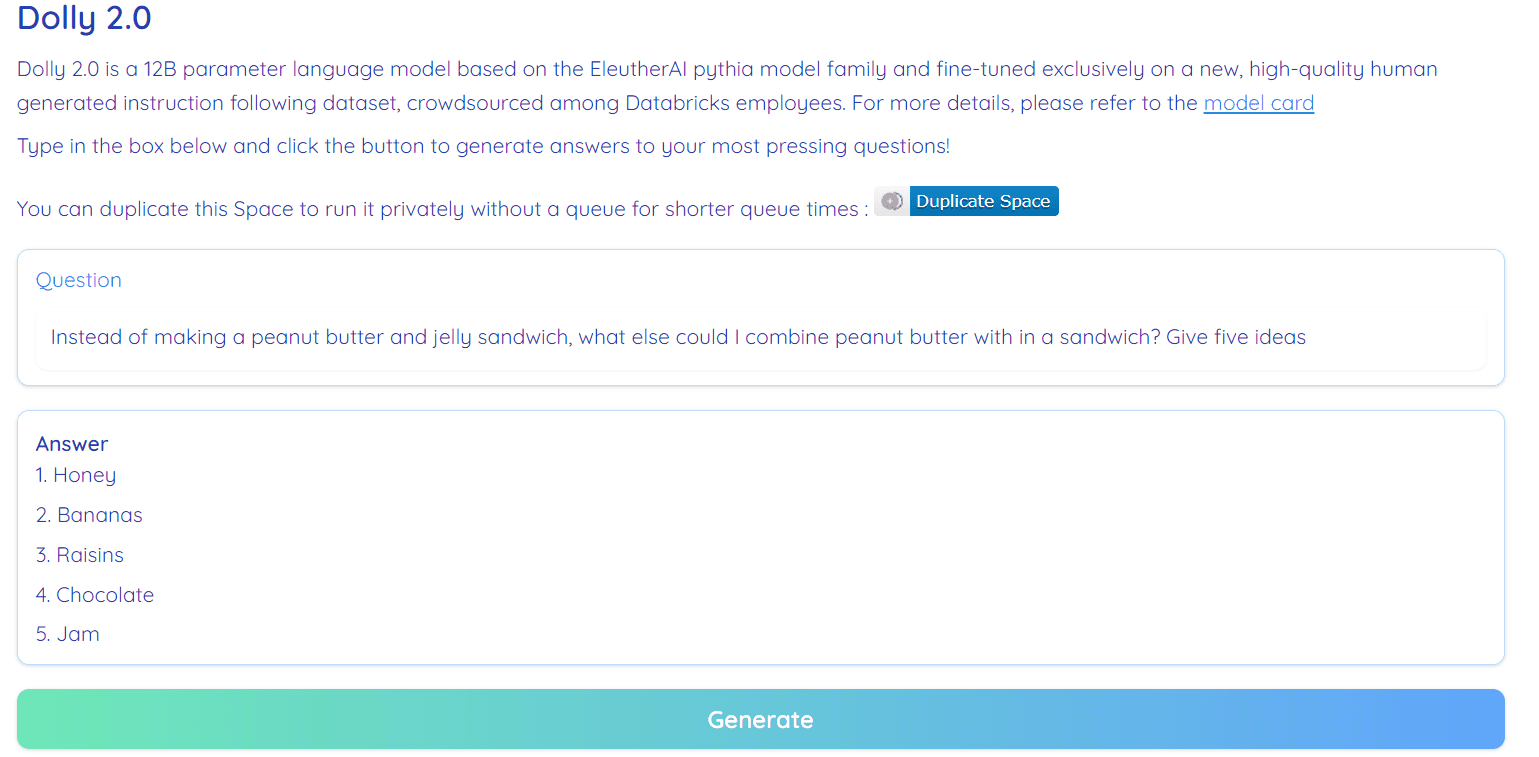
تصویر از Hugging Face Space اثر RamAnanth1
پیش از این، تیم Databricks منتشر شده بود دالی 1.0, LLM، که دستورالعملهای ChatGPT-مانند را به دنبال توانایی ارائه میدهد و هزینه آموزش آن کمتر از 30 دلار است. از مجموعه داده های تیم Stanford Alpaca استفاده می کرد که تحت یک مجوز محدود بود (فقط تحقیق).
Dolly 2.0 این مشکل را با تنظیم دقیق مدل زبان پارامتر 12B حل کرده است (پیتیا) بر روی یک دستورالعمل با کیفیت بالا تولید شده توسط انسان در مجموعه داده زیر، که توسط یک کارمند Datbricks برچسب گذاری شده است. هر دو مدل و مجموعه داده برای استفاده تجاری در دسترس هستند.
Dolly 1.0 بر روی مجموعه داده Stanford Alpaca آموزش داده شد که با استفاده از OpenAI API ایجاد شد. مجموعه داده حاوی خروجی ChatGPT است و از استفاده هر کسی برای رقابت با OpenAI جلوگیری می کند. به طور خلاصه، شما نمی توانید یک چت بات تجاری یا برنامه زبانی بر اساس این مجموعه داده بسازید.
اکثر آخرین مدل های عرضه شده در چند هفته اخیر از مشکلات مشابهی رنج می برند، مدل هایی مانند آلپاکا, کوآلا, GPT4Allو ویکونا. برای دور زدن، ما باید مجموعه دادههای باکیفیت جدیدی ایجاد کنیم که بتوان از آنها برای استفاده تجاری استفاده کرد، و این کاری است که تیم Databricks با مجموعه داده databricks-dolly-15k انجام داده است.
مجموعه داده جدید شامل 15,000 جفت اعلان/پاسخ با برچسب انسانی با کیفیت بالا است که میتوانند برای طراحی مدلهای زبان بزرگ تنظیم دستورالعمل استفاده شوند. را databricks-dolly-15k مجموعه داده همراه است مجوز Creative Commons Attribution-ShareAlike 3.0 Unported، که به هر کسی اجازه می دهد از آن استفاده کند، آن را تغییر دهد و یک برنامه تجاری روی آن ایجاد کند.
چگونه مجموعه داده databricks-dolly-15k را ایجاد کردند؟
تحقیق OpenAI مقاله بیان می کند که مدل اصلی InstructGPT بر روی 13,000 درخواست و پاسخ آموزش داده شده است. با استفاده از این اطلاعات، تیم Databricks شروع به کار بر روی آن کرد و معلوم شد که ایجاد 13 هزار پرسش و پاسخ کار دشواری بوده است. آنها نمیتوانند از دادههای مصنوعی یا دادههای تولیدی هوش مصنوعی استفاده کنند و باید برای هر سؤال پاسخهای اصلی ایجاد کنند. اینجاست که آنها تصمیم گرفته اند از 5,000 کارمند Databricks برای ایجاد داده های تولید شده توسط انسان استفاده کنند.
Databricks مسابقه ای را راه اندازی کرده است که در آن 20 برچسب دهنده برتر جایزه بزرگی دریافت می کنند. در این مسابقه 5,000 کارمند Databricks که علاقه زیادی به LLM داشتند شرکت کردند
dolly-v2-12b یک مدل پیشرفته نیست. در برخی معیارهای ارزیابی عملکرد dolly-v1-6b را ندارد. ممکن است به دلیل ترکیب و اندازه مجموعه دادههای تنظیم دقیق اساسی باشد. خانواده مدل Dolly در حال توسعه فعال است، بنابراین ممکن است در آینده یک نسخه به روز شده با عملکرد بهتر را مشاهده کنید.
به طور خلاصه، مدل dolly-v2-12b بهتر از EleutherAI/gpt-neox-20b و EleutherAI/pythia-6.9b عمل کرده است.

تصویر از دالی رایگان
Dolly 2.0 100% منبع باز است. همراه با کد آموزشی، مجموعه داده، وزن مدل و خط لوله استنتاج است. تمامی قطعات برای استفاده تجاری مناسب هستند. می توانید مدل را در Hugging Face Spaces امتحان کنید Dolly V2 توسط RamAnanth1.
تصویر از در آغوش کشیدن صورت
منبع:
نسخه ی نمایشی Dolly 2.0: Dolly V2 توسط RamAnanth1
عابد علی اعوان (@1abidaliawan) یک متخصص دانشمند داده معتبر است که عاشق ساخت مدل های یادگیری ماشینی است. در حال حاضر، او بر تولید محتوا و نوشتن وبلاگ های فنی در زمینه یادگیری ماشین و فناوری های علم داده تمرکز دارد. عابد دارای مدرک کارشناسی ارشد در رشته مدیریت فناوری و مدرک کارشناسی در رشته مهندسی مخابرات است. چشم انداز او ساخت یک محصول هوش مصنوعی با استفاده از یک شبکه عصبی نمودار برای دانش آموزانی است که با بیماری های روانی دست و پنجه نرم می کنند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- ضرب کردن آینده با آدرین اشلی. دسترسی به اینجا.
- منبع: https://www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html?utm_source=rss&utm_medium=rss&utm_campaign=dolly-2-0-chatgpt-open-source-alternative-for-commercial-use
- : دارد
- :است
- :نه
- $UP
- 000
- 1
- 20
- a
- توانایی
- فعال
- AI
- معرفی
- اجازه می دهد تا
- جایگزین
- an
- و
- پاسخ
- هر کس
- API
- کاربرد
- هستند
- دور و بر
- نویسنده
- در دسترس
- جایزه
- مستقر
- BE
- معیار
- برکلی
- بهتر
- بزرگ
- بینگ
- وبلاگ ها
- هر دو
- ساختن
- بنا
- by
- CAN
- نمی توان
- مهندسان
- chatbot
- GPT چت
- رمز
- تجاری
- مردم عادی
- رقابت
- اجزاء
- شامل
- محتوا
- تولید محتوا
- مسابقه
- هزینه
- ایجاد
- ایجاد شده
- ایجاد
- در حال حاضر
- داده ها
- علم اطلاعات
- دانشمند داده
- پایگاه داده
- مجموعه داده ها
- مصمم
- درجه
- نسخه ی نمایشی
- طرح
- پروژه
- DID
- مشکل
- عروسک
- کارمند
- کارکنان
- مهندسی
- ارزیابی
- هر
- نمایشگاه ها
- چهره
- خانواده
- کمی از
- تمرکز
- پیروی
- برای
- از جانب
- آینده
- تولید می کنند
- مولد
- مولد
- دریافت کنید
- گراف
- شبکه عصبی گراف
- آیا
- he
- با کیفیت بالا
- دارای
- HTML
- HTTPS
- بیماری
- تصویر
- in
- اطلاعات
- علاقه مند
- موضوع
- مسائل
- IT
- JPG
- kdnuggets
- زبان
- بزرگ
- نام
- آخرین
- یادگیری
- مجوز
- پسندیدن
- دستگاه
- فراگیری ماشین
- مدیریت
- استاد
- روانی
- بیماری روانی
- قدرت
- مدل
- مدل
- تغییر
- نیاز
- شبکه
- عصبی
- شبکه های عصبی
- جدید
- of
- on
- فقط
- باز کن
- منبع باز
- OpenAI
- or
- اصلی
- تولید
- جفت
- پارامتر
- شرکت
- کارایی
- خط لوله
- افلاطون
- هوش داده افلاطون
- PlatoData
- محصول
- حرفه ای
- اهداف
- سوال
- سوالات
- منتشر شد
- تحقیق
- مصمم
- منحصر
- s
- همان
- علم
- دانشمند
- تنظیم
- کوتاه
- اندازه
- So
- برخی از
- منبع
- فضا
- فضاها
- استنفورد
- آغاز شده
- وضعیت هنر
- ایالات
- تلاش
- دانشجویان
- مناسب
- ترکیبی
- داده های مصنوعی
- کار
- تیم
- فنی
- فن آوری
- پیشرفته
- ارتباط از راه دور
- نسبت به
- که
- La
- آینده
- آنها
- این
- به
- بالا
- قطار
- آموزش دیده
- آموزش
- زیر
- اساسی
- به روز شده
- استفاده کنید
- استفاده
- با استفاده از
- نسخه
- دید
- بود
- we
- هفته
- بود
- چی
- که
- WHO
- با
- مهاجرت کاری
- خواهد بود
- نوشته
- شما
- زفیرنت










