آمازون Redshift یک انبار داده ابری کاملاً مدیریت شده و در مقیاس پتابایت است که توسط دهها هزار مشتری برای پردازش اگزابایت داده هر روز استفاده میشود تا حجم کاری تحلیلی خود را تقویت کند. با استفاده از یک مدل ابعادی میتوانید دادههای خود را ساختار دهید، فرآیندهای کسبوکار را اندازهگیری کنید و به سرعت به بینشهای ارزشمندی دست پیدا کنید. Amazon Redshift ویژگیهای داخلی را برای تسریع فرآیند مدلسازی، هماهنگسازی و گزارشدهی از یک مدل بعدی ارائه میکند.
در این پست، نحوه پیاده سازی یک مدل ابعادی، به طور خاص، را مورد بحث قرار می دهیم روش کیمبال. ما در مورد پیاده سازی ابعاد و حقایق در Amazon Redshift بحث می کنیم. ما نشان میدهیم که چگونه استخراج، تبدیل و بارگذاری (ELT) را انجام دهیم، یک فرآیند یکپارچهسازی که بر دریافت دادههای خام از یک دریاچه داده به یک لایه مرحلهبندی برای انجام مدلسازی متمرکز است. به طور کلی، این پست به شما درک روشنی از نحوه استفاده از مدلسازی ابعادی در Amazon Redshift میدهد.
بررسی اجمالی راه حل
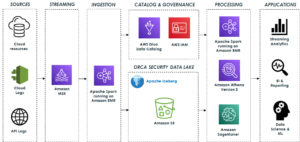
نمودار زیر معماری راه حل را نشان می دهد.

در بخشهای بعدی، ابتدا جنبههای کلیدی مدل ابعادی را مورد بحث و بررسی قرار میدهیم. پس از آن، ما با استفاده از آمازون Redshift با یک مدل داده ابعادی شامل جداول ابعاد و واقعیت یک دیتا مارت ایجاد می کنیم. داده ها با استفاده از بارگیری و مرحله بندی می شوند کپی کردن دستور، داده ها در ابعاد با استفاده از بارگذاری می شوند ادغام بیانیه، و حقایق به ابعادی که بینشها از آن مشتق میشوند، ملحق خواهند شد. ما بارگذاری ابعاد و حقایق را با استفاده از برنامه زمان بندی می کنیم Amazon Redshift Query Editor V2. در نهایت ما استفاده می کنیم آمازون QuickSight برای به دست آوردن بینش در مورد داده های مدل شده در قالب داشبورد QuickSight.
برای این راه حل، ما از یک مجموعه داده نمونه (نرمال شده) ارائه شده توسط Amazon Redshift برای فروش بلیط رویداد استفاده می کنیم. برای این پست، ما مجموعه داده را برای سادگی و اهداف نمایشی محدود کرده ایم. جداول زیر نمونه هایی از داده های فروش بلیط و مکان برگزاری را نشان می دهد.


با توجه به روش مدل سازی ابعادی کیمبالچهار مرحله کلیدی در طراحی یک مدل ابعادی وجود دارد:
- فرآیند کسب و کار را شناسایی کنید.
- دانه بندی داده های خود را اعلام کنید.
- ابعاد را شناسایی و اجرا کنید.
- حقایق را شناسایی و اجرا کنید.
علاوه بر این، ما مرحله پنجم را برای اهداف نمایشی اضافه می کنیم که گزارش و تجزیه و تحلیل رویدادهای تجاری است.
پیش نیازها
برای این راهنما، شما باید پیش نیازهای زیر را داشته باشید:
فرآیند کسب و کار را شناسایی کنید
به عبارت ساده، شناسایی فرآیند کسب و کار، شناسایی یک رویداد قابل اندازه گیری است که داده ها را در یک سازمان تولید می کند. معمولاً شرکتها نوعی سیستم منبع عملیاتی دارند که دادههای آنها را در قالب خام تولید میکند. این نقطه شروع خوبی برای شناسایی منابع مختلف برای فرآیند کسب و کار است.
سپس فرآیند کسب و کار به عنوان یک ادامه می یابد داده مارت در قالب ابعاد و حقایق. با نگاهی به مجموعه داده نمونه ما که قبلاً ذکر شد، میتوانیم به وضوح ببینیم که فرآیند کسبوکار، فروش انجام شده برای یک رویداد خاص است.
یک اشتباه رایج استفاده از بخش های یک شرکت به عنوان فرآیند تجاری است. داده ها (فرایند تجاری) باید در بخش های مختلف یکپارچه شوند، در این مورد، بازاریابی می تواند به داده های فروش دسترسی داشته باشد. شناسایی فرآیند صحیح کسبوکار بسیار مهم است - اشتباه گرفتن این مرحله میتواند بر کل دادهها تأثیر بگذارد (میتواند باعث تکراری شدن دانهها و معیارهای نادرست در گزارشهای نهایی شود).
دانه بندی داده های خود را اعلام کنید
اعلام دانه عمل شناسایی منحصر به فرد یک رکورد در منبع داده شما است. دانه در جدول حقایق برای اندازه گیری دقیق داده ها استفاده می شود و شما را قادر می سازد بیشتر جمع کنید. در مثال ما، این می تواند یک آیتم خطی در فرآیند کسب و کار فروش باشد.
در مورد استفاده ما، یک فروش را می توان با نگاه کردن به زمان معامله زمانی که فروش انجام شد، به طور منحصر به فردی شناسایی کرد. این اتمی ترین سطح خواهد بود.

ابعاد را شناسایی و اجرا کنید
جدول ابعاد شما جدول واقعیت و ویژگی های آن را توصیف می کند. هنگام شناسایی زمینه توصیفی فرآیند کسب و کار خود، متن را در یک جدول جداگانه ذخیره می کنید و دانه بندی جدول واقعیت را در ذهن نگه می دارید. هنگام پیوستن جدول ابعاد به جدول واقعیت، فقط باید یک سطر مرتبط با جدول واقعیت وجود داشته باشد. در مثال ما از جدول زیر برای تفکیک به جدول ابعاد استفاده می کنیم. این فیلدها حقایقی را توصیف می کنند که ما اندازه گیری خواهیم کرد.
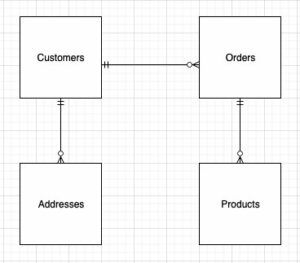
هنگام طراحی ساختار مدل بعدی (شما)، می توانید یک را ایجاد کنید ستاره or برف ریزه طرحواره ساختار باید با فرآیند کسب و کار هماهنگ باشد. بنابراین، یک طرح واره ستاره بهترین مناسب برای مثال ما است. شکل زیر نمودار رابطه نهاد (ERD) ما را نشان می دهد.

در بخش های بعدی مراحل اجرای ابعاد را به تفصیل شرح می دهیم.
داده های منبع را مرحله بندی کنید
قبل از اینکه بتوانیم جدول ابعاد را ایجاد و بارگذاری کنیم، به داده های منبع نیاز داریم. بنابراین، داده های منبع را در یک جدول مرحله بندی یا موقت مرحله بندی می کنیم. این اغلب به عنوان نامیده می شود لایه مرحله بندی، که کپی خام داده های منبع است. برای انجام این کار در آمازون Redshift، ما از دستور COPY برای بارگذاری داده ها از سطل S3 عمومی مدل سازی ابعادی-in-amazon-redshift واقع در us-east-1 منطقه. توجه داشته باشید که دستور COPY از یک استفاده می کند هویت AWS و مدیریت دسترسی (IAM) نقش با دسترسی به آمازون S3. نقش باید باشد مرتبط با خوشه. مراحل زیر را برای مرحله بندی داده های منبع کامل کنید:
- ایجاد
venueجدول منبع:
- بارگذاری اطلاعات محل برگزاری:
- ایجاد
salesجدول منبع:
- بارگیری اطلاعات منبع فروش:
- ایجاد
calendarجدول:
- بارگیری داده های تقویم:
جدول ابعاد را ایجاد کنید
طراحی جدول ابعاد می تواند به نیاز کسب و کار شما بستگی داشته باشد - برای مثال، آیا باید تغییرات داده ها را در طول زمان ردیابی کنید؟ وجود دارد هفت نوع بعد مختلف. برای مثال ما استفاده می کنیم نوع 1 زیرا ما نیازی به ردیابی تغییرات تاریخی نداریم. برای اطلاعات بیشتر در مورد نوع 2 مراجعه کنید بارگذاری داده ها را در ابعاد آهسته تغییر در نوع 2 در آمازون Redshift ساده کنید. جدول ابعاد با یک کلید اصلی، کلید جایگزین و چند فیلد اضافه شده برای نشان دادن تغییرات جدول غیرعادی می شود. کد زیر را ببینید:
چند نکته در مورد ایجاد جدول ابعاد:
- نام فیلدها به نام های تجاری پسند تبدیل می شوند
- کلید اصلی ما این است
VenueID، که از آن برای شناسایی منحصر به فرد مکانی که فروش در آن انجام شده است استفاده می کنیم - دو ردیف اضافی اضافه خواهد شد، که نشان می دهد چه زمانی یک رکورد درج شده و به روز شده است (برای پیگیری تغییرات)
- ما از یک استفاده می کنیم سبک توزیع خودکار به آمازون Redshift مسئولیت انتخاب و تنظیم سبک توزیع را بدهد
عامل مهم دیگری که در مدل سازی ابعادی باید در نظر گرفته شود، استفاده از آن است کلیدهای جایگزین. کلیدهای جایگزین کلیدهای مصنوعی هستند که در مدل سازی ابعادی برای شناسایی منحصر به فرد هر رکورد در جدول ابعاد استفاده می شوند. آنها معمولاً به عنوان یک عدد صحیح متوالی تولید می شوند و هیچ معنایی در حوزه تجاری ندارند. آنها چندین مزیت مانند تضمین منحصر به فرد بودن و بهبود عملکرد در اتصالات را ارائه می دهند، زیرا معمولاً کوچکتر از کلیدهای طبیعی هستند و به عنوان کلیدهای جایگزین در طول زمان تغییر نمی کنند. این به ما این امکان را میدهد که سازگار باشیم و راحتتر به واقعیتها و ابعاد بپیوندیم.
در آمازون Redshift، کلیدهای جانشین معمولاً با استفاده از کلمه کلیدی IDENTITY ایجاد می شوند. به عنوان مثال، دستور قبلی CREATE یک جدول بعد با a ایجاد می کند VenueSkey کلید جانشین این VenueSkey با اضافه شدن سطرهای جدید به جدول، ستون به طور خودکار با مقادیر منحصر به فرد پر می شود. سپس می توان از این ستون برای پیوستن به جدول محل برگزاری استفاده کرد FactSaleTransactions جدول.
چند نکته برای طراحی کلیدهای جانشین:
- از یک نوع داده کوچک با عرض ثابت برای کلید جانشین استفاده کنید. این کار باعث بهبود عملکرد و کاهش فضای ذخیره سازی می شود.
- از کلمه کلیدی IDENTITY استفاده کنید یا کلید جانشین را با استفاده از مقدار متوالی یا GUID ایجاد کنید. این تضمین می کند که کلید جایگزین منحصر به فرد است و قابل تغییر نیست.
جدول کم نور را با استفاده از MERGE بارگیری کنید
راه های زیادی برای بارگذاری میز کم نور شما وجود دارد. عوامل خاصی باید در نظر گرفته شوند - برای مثال، عملکرد، حجم داده، و شاید زمان بارگذاری SLA. با ادغام بیانیه، ما یک upsert را بدون نیاز به تعیین چند دستور درج و به روز رسانی انجام می دهیم. شما می توانید راه اندازی کنید ادغام بیانیه در الف روش های ذخیره شده برای پر کردن داده ها سپس رویه ذخیره شده را برنامه ریزی می کنید تا به صورت برنامه ریزی شده از طریق ویرایشگر پرس و جو اجرا شود، که بعداً در پست نشان می دهیم. کد زیر یک رویه ذخیره شده به نام ایجاد می کند SalesMart.DimVenueLoad:
چند نکته در مورد بارگذاری ابعاد:
- هنگامی که یک رکورد برای اولین بار درج می شود، تاریخ درج شده و تاریخ به روز شده پر می شود. هنگامی که هر مقدار تغییر می کند، داده ها به روز می شوند و تاریخ به روز شده، تاریخ تغییر آن را منعکس می کند. تاریخ درج شده باقی می ماند.
- از آنجایی که دادهها توسط کاربران تجاری استفاده میشود، باید مقادیر NULL را، در صورت وجود، با مقادیر مناسبتری جایگزین کنیم.
حقایق را شناسایی و اجرا کنید
اکنون که دانه خود را به عنوان رویداد فروش اعلام کرده ایم که در یک زمان خاص انجام شده است، جدول واقعیت ما حقایق عددی را برای فرآیند کسب و کار ما ذخیره می کند.
ما حقایق عددی زیر را برای اندازه گیری شناسایی کرده ایم:
- تعداد بلیط فروخته شده در هر فروش
- کمیسیون برای فروش
پیاده سازی واقعیت
وجود دارد سه نوع جداول واقعیت (جدول حقایق تراکنش، جدول حقایق لحظه ای دوره ای، و جدول واقعی عکس فوری انباشته). هر کدام دیدگاه متفاوتی از فرآیند کسب و کار ارائه می دهند. برای مثال ما از جدول واقعی تراکنش استفاده می کنیم. مراحل زیر را کامل کنید:
- جدول حقایق را ایجاد کنید
یک تاریخ درج شده با مقدار پیشفرض اضافه میشود که نشان میدهد آیا و چه زمانی یک رکورد بارگیری شده است. می توانید از این هنگام بارگیری مجدد جدول واقعیت استفاده کنید تا داده های بارگیری شده قبلی را حذف کنید تا از موارد تکراری جلوگیری شود.
بارگیری جدول واقعیت شامل یک عبارت درج ساده است که ابعاد مرتبط شما را به هم می پیوندد. ما از DimVenue جدولی که ایجاد شد و حقایق ما را توصیف می کند. این بهترین تمرین است اما اختیاری است تاریخ تقویم ابعاد، که به کاربر نهایی اجازه می دهد تا در جدول حقایق حرکت کند. داده ها را می توان در هنگام فروش جدید بارگیری کرد یا روزانه. این جایی است که تاریخ درج شده یا تاریخ بارگذاری مفید است.
جدول واقعیت را با استفاده از رویه ذخیره شده بارگذاری می کنیم و از پارامتر تاریخ استفاده می کنیم.
- رویه ذخیره شده را با کد زیر ایجاد کنید. برای حفظ یکپارچگی داده مشابهی که در بار ابعاد اعمال کردیم، مقادیر NULL را، در صورت وجود، با مقادیر مناسب تجاری بیشتری جایگزین می کنیم:
- داده ها را با فراخوانی رویه با دستور زیر بارگذاری کنید:
زمان بندی بارگذاری داده ها
اکنون میتوانیم فرآیند مدلسازی را با زمانبندی رویههای ذخیرهشده در Amazon Redshift Query Editor V2 خودکار کنیم. مراحل زیر را کامل کنید:
- ابتدا بار ابعاد را فراخوانی می کنیم و پس از اجرای موفقیت آمیز بار ابعاد، بارگذاری واقعی آغاز می شود:
اگر بار ابعادی خراب شود، بار واقعی اجرا نخواهد شد. این یکپارچگی در داده ها را تضمین می کند زیرا ما نمی خواهیم جدول واقعیت را با ابعاد قدیمی بارگذاری کنیم.
- برای برنامه ریزی بار، انتخاب کنید برنامه در Query Editor V2.

- ما برنامه پرس و جو را برای اجرا هر روز در ساعت 5:00 صبح برنامه ریزی می کنیم.
- به صورت اختیاری، میتوانید با فعال کردن اعلانهای خرابی اضافه کنید سرویس اطلاع رسانی ساده آمازون اعلانهای (Amazon SNS).

گزارش و تجزیه و تحلیل داده ها در Amazon Quicksight
QuickSight یک سرویس هوش تجاری است که ارائه اطلاعات بینش را آسان می کند. به عنوان یک سرویس کاملاً مدیریت شده، QuickSight به شما امکان می دهد به راحتی داشبوردهای تعاملی ایجاد و منتشر کنید که می توانند از هر دستگاهی به آن دسترسی داشته باشند و در برنامه ها، پورتال ها و وب سایت های شما جاسازی شوند.
ما از data mart خود برای ارائه بصری حقایق در قالب یک داشبورد استفاده می کنیم. برای شروع و راه اندازی QuickSight، مراجعه کنید ایجاد یک مجموعه داده با استفاده از پایگاه داده ای که به طور خودکار کشف نشده است.
پس از اینکه منبع داده خود را در QuickSight ایجاد کردید، ما داده های مدل سازی شده (داده مارت) را بر اساس کلید جایگزین خود به یکدیگر می پیوندیم. skey. ما از این مجموعه داده برای تجسم دادههای مارت استفاده میکنیم.

داشبورد پایانی ما حاوی بینشهای مربوط به دادههای مارت است و به سؤالات مهم تجاری مانند کمیسیون کل در هر مکان و تاریخهایی با بالاترین فروش پاسخ میدهد. تصویر زیر محصول نهایی دیتا مارت را نشان می دهد.

پاک کردن
برای جلوگیری از تحمیل هزینههای بعدی، منابعی را که به عنوان بخشی از این پست ایجاد کردهاید حذف کنید.
نتیجه
ما در حال حاضر با موفقیت یک دیتا مارت را با استفاده از ما پیاده سازی کرده ایم DimVenue, DimCalendarو FactSaleTransactions جداول انبار ما کامل نیست. همانطور که میتوانیم دادههای مارت را با حقایق بیشتر گسترش دهیم و مارتهای بیشتری را پیادهسازی کنیم، و همانطور که فرآیند کسبوکار و الزامات در طول زمان رشد میکنند، انبار داده نیز رشد میکند. در این پست، دیدگاهی کامل در مورد درک و پیاده سازی مدل سازی ابعادی در آمازون Redshift ارائه کردیم.
با خود شروع کنید آمازون Redshift مدل بعدی امروز
درباره نویسنده
 برنارد ورستر یک مهندس ابر باتجربه است که سال ها در ایجاد مدل های داده مقیاس پذیر و کارآمد، تعریف استراتژی های یکپارچه سازی داده ها، و تضمین حاکمیت و امنیت داده ها، فعالیت داشته است. او علاقه زیادی به استفاده از داده ها برای ایجاد بینش دارد، در حالی که با الزامات و اهداف تجاری همسو می شود.
برنارد ورستر یک مهندس ابر باتجربه است که سال ها در ایجاد مدل های داده مقیاس پذیر و کارآمد، تعریف استراتژی های یکپارچه سازی داده ها، و تضمین حاکمیت و امنیت داده ها، فعالیت داشته است. او علاقه زیادی به استفاده از داده ها برای ایجاد بینش دارد، در حالی که با الزامات و اهداف تجاری همسو می شود.
 آبیشک پان یک متخصص WWSO SA-Analytics است که با مشتریان بخش عمومی AWS هند کار می کند. او با مشتریان برای تعریف استراتژی مبتنی بر داده، ارائه جلسات غواصی عمیق در مورد موارد استفاده از تجزیه و تحلیل، و طراحی برنامه های کاربردی تحلیلی مقیاس پذیر و کارآمد، درگیر می شود. او 12 سال تجربه دارد و علاقه زیادی به پایگاه های داده، تجزیه و تحلیل و AI/ML دارد. او یک مسافر مشتاق است و سعی می کند با لنز دوربین خود دنیا را به تصویر بکشد.
آبیشک پان یک متخصص WWSO SA-Analytics است که با مشتریان بخش عمومی AWS هند کار می کند. او با مشتریان برای تعریف استراتژی مبتنی بر داده، ارائه جلسات غواصی عمیق در مورد موارد استفاده از تجزیه و تحلیل، و طراحی برنامه های کاربردی تحلیلی مقیاس پذیر و کارآمد، درگیر می شود. او 12 سال تجربه دارد و علاقه زیادی به پایگاه های داده، تجزیه و تحلیل و AI/ML دارد. او یک مسافر مشتاق است و سعی می کند با لنز دوربین خود دنیا را به تصویر بکشد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. خودرو / خودروهای الکتریکی، کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- BlockOffsets. نوسازی مالکیت افست زیست محیطی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 1
- 100
- 12
- ٪۱۰۰
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- درباره ما
- شتاب دادن
- دسترسی
- قابل دسترسی است
- به درستی
- در میان
- عمل
- اضافه کردن
- اضافه
- اضافی
- پس از
- AI / ML
- تراز
- تراز کردن
- اجازه دادن
- اجازه می دهد تا
- قبلا
- am
- آمازون
- آمازون خدمات وب
- an
- تحلیل
- تحلیلی
- علم تجزیه و تحلیل
- تحلیل
- و
- پاسخ
- هر
- برنامه های کاربردی
- اعمال می شود
- مناسب
- معماری
- هستند
- مصنوعی
- AS
- جنبه
- مرتبط است
- At
- خواص
- خودکار
- خودکار بودن
- بطور خودکار
- اجتناب از
- AWS
- b
- مستقر
- BE
- زیرا
- شروع
- مزایای
- بهترین
- ساخته شده در
- کسب و کار
- هوش تجاری
- فرآیند کاری
- فرآیندهای کسب و کار
- اما
- by
- تقویم
- صدا
- نام
- فراخوانی
- دوربین
- CAN
- گرفتن
- مورد
- موارد
- علت
- معین
- تغییر دادن
- تغییر
- تبادل
- متغیر
- شخصیت
- بار
- را انتخاب کنید
- واضح
- به وضوح
- نزدیک
- ابر
- رمز
- ستون
- می آید
- کمیسیون
- مشترک
- شرکت
- شرکت
- کامل
- در نظر بگیرید
- استوار
- تشکیل شده است
- زمینه
- اصلاح
- میتوانست
- ایجاد
- ایجاد شده
- ایجاد
- ایجاد
- ایجاد
- بحرانی
- مشتریان
- روزانه
- داشبورد
- داشبورد
- داده ها
- یکپارچه سازی داده ها
- دریاچه دریاچه
- انبار داده
- داده محور
- استراتژی داده محور
- پایگاه داده
- پایگاه های داده
- تاریخ
- تاریخ
- زمان قرار
- روز
- عمیق
- شیرجه عمیق
- به طور پیش فرض
- تعریف کردن
- ارائه
- نشان دادن
- گروه ها
- نشات گرفته
- توصیف
- طرح
- طراحی
- جزئیات
- دستگاه
- مختلف
- بعد
- ابعاد
- بحث و تبادل نظر
- متمایز
- توزیع
- do
- دامنه
- انجام شده
- آیا
- پایین
- راندن
- نسخه های تکراری
- هر
- پیش از آن
- به آسانی
- ساده
- سردبیر
- موثر
- هر دو
- جاسازی شده
- قادر ساختن
- را قادر می سازد
- پایان
- پشت سر هم
- درگیر می شود
- مهندس
- اطمینان حاصل شود
- تضمین می کند
- حصول اطمینان از
- تمام
- موجودیت
- اتر (ETH)
- واقعه
- حوادث
- هر
- هر روز
- مثال
- مثال ها
- گسترش
- تجربه
- با تجربه
- ارائه
- عصاره
- واقعیت
- عامل
- عوامل
- حقایق
- نتواند
- شکست
- امکانات
- کمی از
- رشته
- زمینه
- پنجم
- شکل
- فیلتر
- نهایی
- نام خانوادگی
- بار اول
- مناسب
- متمرکز شده است
- پیروی
- برای
- فرم
- قالب
- چهار
- از جانب
- کاملا
- بیشتر
- آینده
- افزایش
- تولید می کنند
- تولید
- تولید می کند
- دریافت کنید
- گرفتن
- دادن
- داده
- خوب
- حکومت
- شدن
- سیار
- آیا
- he
- بالاترین
- خود را
- تاریخی
- روز تعطیل
- چگونه
- چگونه
- HTML
- HTTP
- HTTPS
- IAM
- شناسایی
- شناسایی
- شناسایی
- هویت
- if
- نشان می دهد
- تأثیر
- انجام
- اجرا
- اجرای
- مهم
- بهبود
- بهبود
- in
- از جمله
- هندوستان
- نشان دادن
- نشان دادن
- اطلاعات
- بینش
- یکپارچه
- ادغام
- تمامیت
- اطلاعات
- تعاملی
- به
- IT
- ITS
- پیوستن
- پیوست
- پیوستن
- می پیوندد
- JPG
- نگاه داشتن
- نگهداری
- کلید
- کلید
- دریاچه
- زبان
- بعد
- آخرین
- لایه
- ترک کرد
- عدسی
- اجازه می دهد تا
- سطح
- لاین
- بار
- بارگیری
- بارهای
- واقع شده
- به دنبال
- ساخته
- باعث می شود
- اداره می شود
- بازار یابی (Marketing)
- تطبیق
- معنی
- اندازه
- ذکر شده
- ادغام کردن
- متریک
- ذهن
- اشتباه
- مدل
- مدل سازی
- مدل سازی
- مدل
- ماه
- بیش
- اکثر
- چندگانه
- نام
- طبیعی
- هدایت
- نیاز
- نیازمند
- نیازهای
- جدید
- یادداشت
- اخطار
- اطلاعیه ها
- اکنون
- متعدد
- اهداف
- of
- ارائه
- غالبا
- on
- فقط
- قابل استفاده
- or
- کدام سازمان ها
- ما
- روی
- به طور کلی
- پارامتر
- بخش
- احساساتی
- برای
- انجام دادن
- کارایی
- شاید
- متناوب
- محل
- افلاطون
- هوش داده افلاطون
- PlatoData
- نقطه
- پر جمعیت
- پست
- قدرت
- تمرین
- پیش نیازها
- در حال حاضر
- اصلی
- روش
- روش
- روند
- فرآیندهای
- محصول
- ارائه
- ارائه
- فراهم می کند
- عمومی
- منتشر کردن
- اهداف
- سوالات
- به سرعت
- بالا بردن
- خام
- داده های خام
- رکورد
- سوابق
- كاهش دادن
- اشاره
- بازتاب می دهد
- منطقه
- ارتباط
- بقایای
- برداشتن
- جایگزین کردن
- گزارش
- گزارش
- گزارش ها
- مورد نیاز
- منابع
- مسئوليت
- نقش
- نورد
- ROW
- دویدن
- اجرا می شود
- فروش
- حراجی
- همان
- مجموعه داده نمونه
- مقیاس پذیر
- برنامه
- زمان بندی
- بخش
- بخش
- تیم امنیت لاتاری
- دیدن
- جداگانه
- خدمت
- سرویس
- خدمات
- جلسات
- تنظیم
- چند
- باید
- نشان
- نشان می دهد
- ساده
- سادگی
- تنها
- به آرامی
- کوچک
- کوچکتر
- عکس فوری
- So
- فروخته شده
- راه حل
- برخی از
- منبع
- منابع
- فضا
- متخصص
- خاص
- به طور خاص
- صحنه
- استقرار
- ستاره
- آغاز شده
- راه افتادن
- بیانیه
- گام
- مراحل
- ذخیره سازی
- opbevare
- ذخیره شده
- استراتژی ها
- استراتژی
- ساختار
- موفق
- موفقیت
- چنین
- سیستم
- جدول
- موقت
- ده ها
- قوانین و مقررات
- نسبت به
- که
- La
- منبع
- جهان
- شان
- سپس
- آنجا.
- از این رو
- اینها
- آنها
- این
- هزاران نفر
- از طریق
- بلیط
- فروش بلیت
- بلیط
- زمان
- بار
- برچسب زمان
- نکات
- به
- امروز
- با هم
- در زمان
- جمع
- مسیر
- معامله
- دگرگون کردن
- مبدل
- مسافر
- نوع
- انواع
- به طور معمول
- درک
- منحصر به فرد
- منحصر به فرد
- یکتایی
- ناشناخته
- بروزرسانی
- به روز شده
- us
- استفاده
- استفاده کنید
- مورد استفاده
- استفاده
- کاربران
- استفاده
- با استفاده از
- معمولا
- ارزشمند
- ارزش
- ارزشها
- مختلف
- محل برگزاری
- سالن
- از طريق
- چشم انداز
- حجم
- خرید
- می خواهم
- انبار کالا
- بود
- راه
- we
- وب
- خدمات وب
- وب سایت
- هفته
- چه زمانی
- که
- در حین
- اراده
- با
- در داخل
- بدون
- کارگر
- جهان
- اشتباه
- سال
- سال
- شما
- شما
- زفیرنت