بسیاری از سازمان ها، کوچک و بزرگ، در تلاش هستند تا بارهای کاری تحلیلی خود را در خدمات وب آمازون (AWS) تغییر دهند و مدرن کنند. دلایل زیادی برای مهاجرت مشتریان به AWS وجود دارد، اما یکی از دلایل اصلی، توانایی استفاده از خدمات کاملاً مدیریت شده به جای صرف زمان برای حفظ زیرساخت، وصله، نظارت، پشتیبان گیری و موارد دیگر است. تیم های رهبری و توسعه می توانند به جای حفظ زیرساخت فعلی، زمان بیشتری را صرف بهینه سازی راه حل های فعلی و حتی آزمایش موارد استفاده جدید کنند.
با توانایی حرکت سریع در AWS، همچنین باید مسئولیت دادههایی را که دریافت و پردازش میکنید، در ادامه مقیاسپذیری، بر عهده بگیرید. این مسئولیت ها شامل مطابقت با قوانین و مقررات حفظ حریم خصوصی داده ها و عدم ذخیره یا افشای داده های حساس مانند اطلاعات شناسایی شخصی (PII) یا اطلاعات بهداشتی محافظت شده (PHI) از منابع بالادستی است.
در این پست، یک معماری سطح بالا و یک مورد استفاده خاص را بررسی می کنیم که نشان می دهد چگونه می توانید به مقیاس پلت فرم داده سازمان خود بدون نیاز به صرف زمان زیادی برای توسعه برای رسیدگی به نگرانی های مربوط به حریم خصوصی داده ها ادامه دهید. ما استفاده می کنیم چسب AWS برای شناسایی، پوشاندن و ویرایش دادههای PII قبل از بارگیری آنها سرویس جستجوی باز آمازون.
بررسی اجمالی راه حل
نمودار زیر معماری راه حل های سطح بالا را نشان می دهد. ما تمام لایه ها و اجزای طراحی خود را مطابق با آن تعریف کرده ایم لنز تجزیه و تحلیل داده چارچوب با معماری خوب AWS.
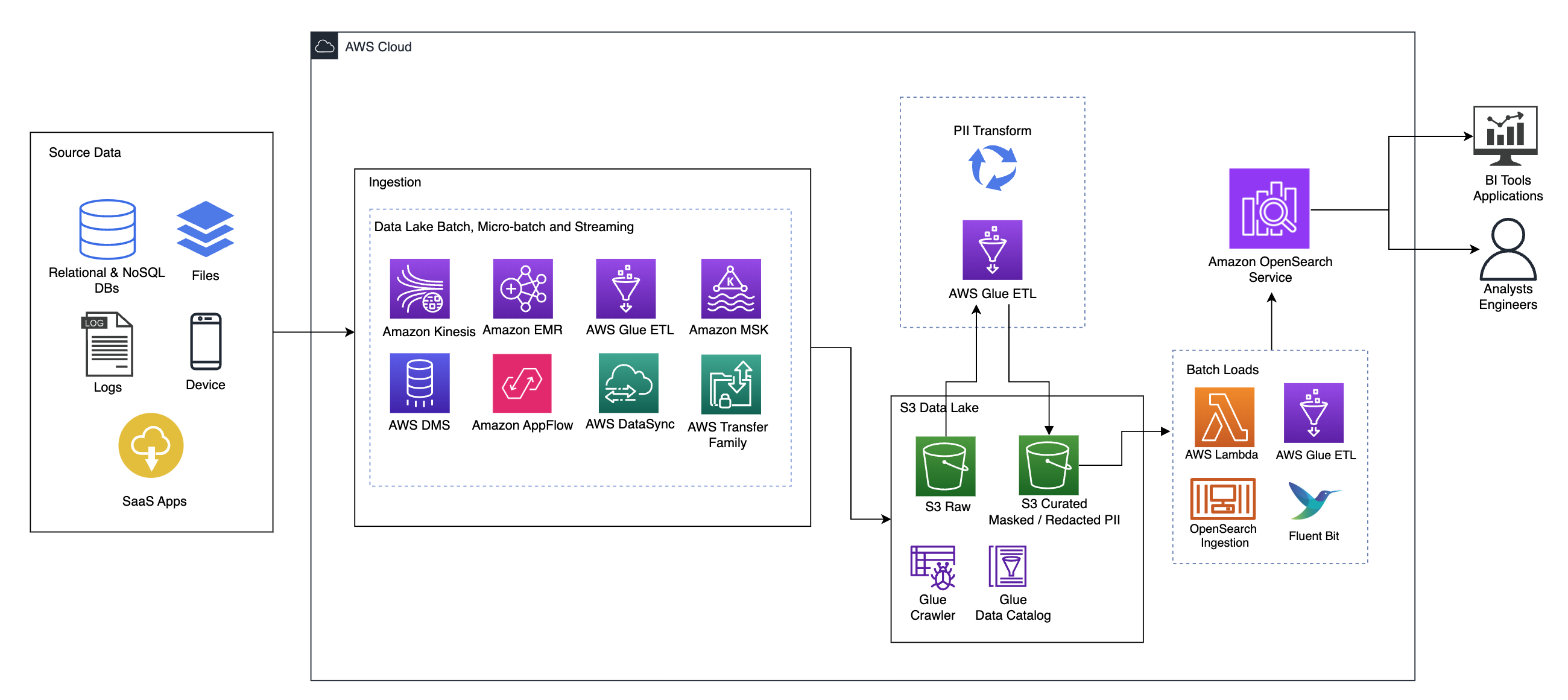
معماری از تعدادی مولفه تشکیل شده است:
منبع داده
دادهها ممکن است از دهها تا صدها منبع، از جمله پایگاههای داده، انتقال فایل، گزارشها، برنامههای نرمافزار بهعنوان سرویس (SaaS) و غیره به دست آیند. سازمانها ممکن است همیشه کنترلی بر روی دادههایی که از طریق این کانالها و به حافظههای پایین دستی و برنامههای کاربردی خود میآیند را نداشته باشند.
بلع: دسته ای دریاچه داده، میکرو دسته و جریان
بسیاری از سازمانها دادههای منبع خود را به روشهای مختلف، از جمله کارهای دستهای، میکرو دستهای و کارهای جریانی، در دریاچه دادههای خود قرار میدهند. مثلا، آمازون EMR, چسب AWSو سرویس مهاجرت پایگاه داده AWS (AWS DMS) همگی می توانند برای انجام عملیات دسته ای و یا جریانی که به دریاچه داده ای فرو می روند استفاده شوند. سرویس ذخیره سازی ساده آمازون (Amazon S3). آمازون AppFlow می تواند برای انتقال داده ها از برنامه های مختلف SaaS به دریاچه داده استفاده شود. AWS DataSync و خانواده انتقال AWS می تواند به انتقال فایل ها به و از یک دریاچه داده از طریق تعدادی از پروتکل های مختلف کمک کند. آمازون کینسیس و آمازون MSK همچنین قابلیت هایی برای پخش مستقیم داده ها به دریاچه داده در آمازون S3 دارند.
دریاچه داده S3
استفاده از آمازون S3 برای دریاچه داده شما مطابق با استراتژی داده مدرن است. ذخیره سازی کم هزینه را بدون به خطر انداختن عملکرد، قابلیت اطمینان یا در دسترس بودن فراهم می کند. با این رویکرد، میتوانید محاسبات را در صورت نیاز به دادههای خود بیاورید و فقط برای ظرفیتی که برای اجرا نیاز دارد پرداخت کنید.
در این معماری، دادههای خام میتوانند از منابع مختلفی (داخلی و خارجی) که ممکن است حاوی دادههای حساس باشند، به دست آیند.
با استفاده از خزندههای AWS Glue، میتوانیم دادهها را کشف و فهرستبندی کنیم، که طرحوارههای جدول را برای ما میسازد، و در نهایت استفاده از چسب AWS ETL با تبدیل PII برای شناسایی، پوشاندن یا ویرایش دادههای حساسی که ممکن است فرود آمده باشد، ساده باشد. در دریاچه داده
زمینه کسب و کار و مجموعه داده ها
برای نشان دادن ارزش رویکرد ما، بیایید تصور کنیم که بخشی از یک تیم مهندسی داده برای یک سازمان خدمات مالی هستید. الزامات شما شناسایی و پوشاندن داده های حساس به هنگام ورود به محیط ابری سازمان شما است. داده ها توسط فرآیندهای تحلیلی پایین دستی مصرف خواهند شد. در آینده، کاربران شما میتوانند با خیال راحت تراکنشهای پرداخت تاریخی را براساس جریانهای داده جمعآوریشده از سیستمهای بانکی داخلی جستجو کنند. نتایج جستجو از تیمهای عملیات، مشتریان و برنامههای رابط باید در زمینههای حساس پوشانده شوند.
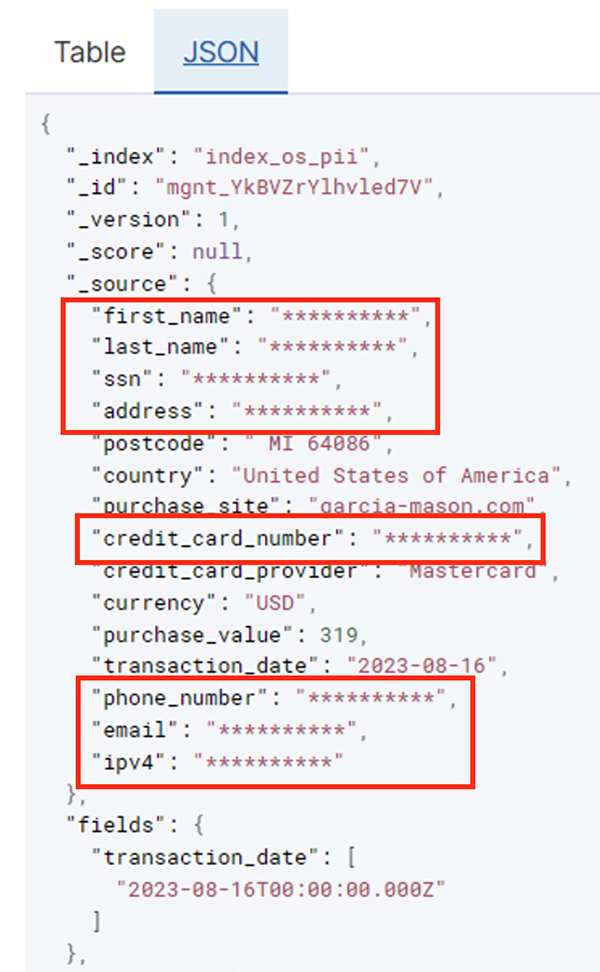
جدول زیر ساختار داده مورد استفاده برای حل را نشان می دهد. برای وضوح، ما نام ستونهای خام را به انتخاب شده نگاشت کردهایم. متوجه خواهید شد که چندین فیلد در این طرح به عنوان داده های حساس در نظر گرفته می شود، مانند نام، نام خانوادگی، شماره تامین اجتماعی (SSN)، آدرس، شماره کارت اعتباری، شماره تلفن، ایمیل، و آدرس IPv4.
| نام ستون خام | نام ستون انتخاب شده | نوع |
| c0 | نام | رشته |
| c1 | نام خانوادگی | رشته |
| c2 | ssn | رشته |
| c3 | نشانی | رشته |
| c4 | کد پستی | رشته |
| c5 | کشور | رشته |
| c6 | خرید_سایت | رشته |
| c7 | شماره کارت اعتباری | رشته |
| c8 | ارائه دهنده_کارت_ اعتباری | رشته |
| c9 | پول | رشته |
| c10 | ارزش_خرید | عدد صحیح |
| c11 | تاریخ معامله | تاریخ |
| c12 | شماره تلفن | رشته |
| c13 | پست الکترونیک | رشته |
| c14 | ipv4 | رشته |
مورد استفاده: تشخیص دسته PII قبل از بارگیری در سرویس OpenSearch
مشتریانی که معماری زیر را پیادهسازی میکنند، دریاچه داده خود را در آمازون S3 ساختهاند تا انواع مختلفی از تجزیه و تحلیلها را در مقیاس اجرا کنند. این راه حل برای مشتریانی مناسب است که نیازی به دریافت بلادرنگ در سرویس OpenSearch ندارند و قصد دارند از ابزارهای یکپارچه سازی داده استفاده کنند که بر اساس یک برنامه اجرا می شوند یا از طریق رویدادها فعال می شوند.
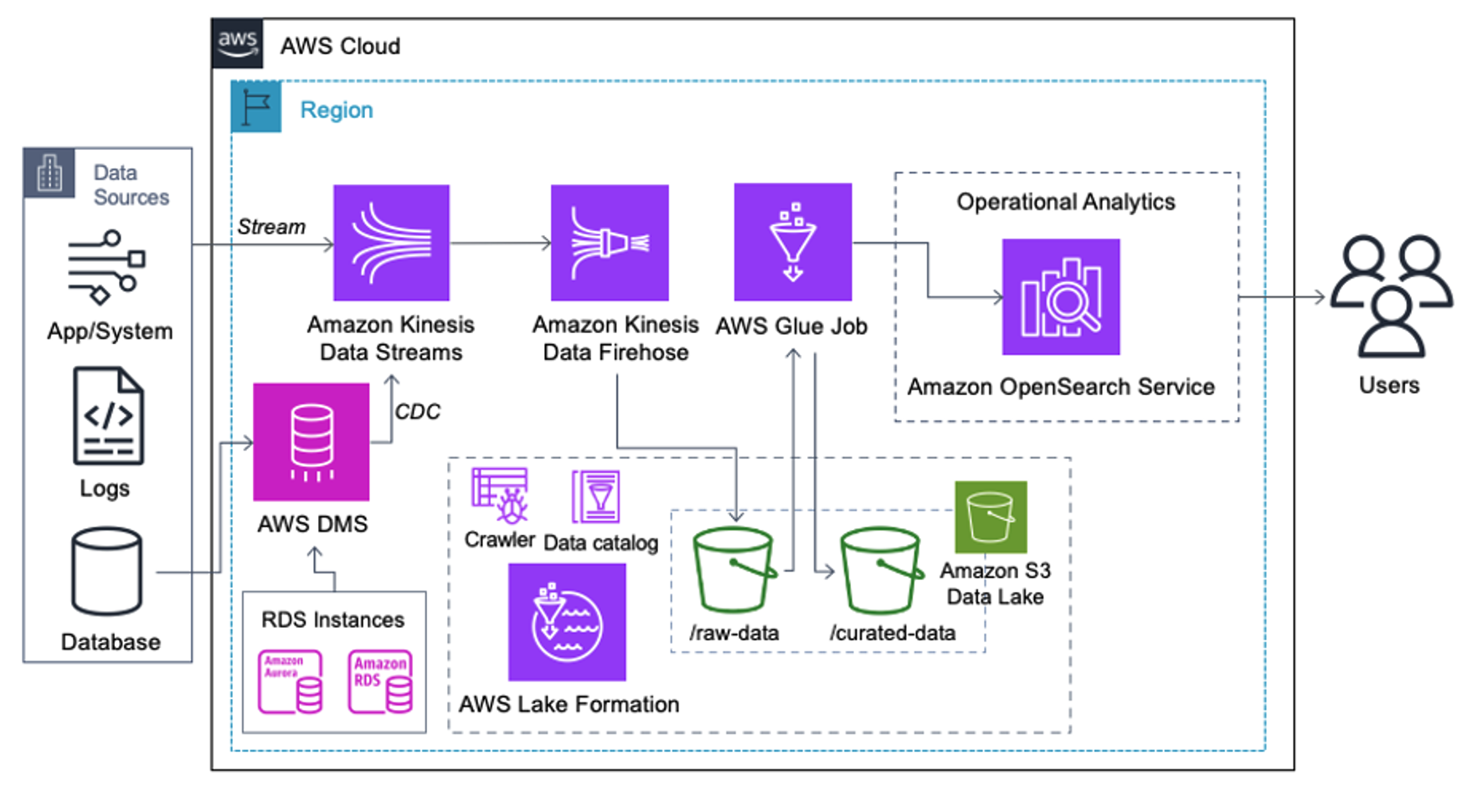
قبل از اینکه رکوردهای داده در آمازون S3 فرود بیایند، ما یک لایه جذب را پیاده سازی می کنیم تا تمام جریان های داده را به طور قابل اعتماد و ایمن به دریاچه داده منتقل کنیم. Kinesis Data Streams بهعنوان یک لایه جذب برای دریافت سریع جریانهای دادههای ساختاریافته و نیمهساختار یافته استفاده میشود. نمونههایی از این تغییرات پایگاه داده رابطهای، برنامهها، گزارشهای سیستم یا جریانهای کلیک هستند. برای موارد استفاده از ضبط داده تغییر (CDC)، می توانید از Kinesis Data Streams به عنوان هدف برای AWS DMS استفاده کنید. برنامهها یا سیستمهایی که جریانهای حاوی دادههای حساس را تولید میکنند از طریق یکی از سه روش پشتیبانی شده به جریان دادههای Kinesis ارسال میشوند: Amazon Kinesis Agent، AWS SDK برای جاوا، یا Kinesis Producer Library. به عنوان آخرین گام، Amazon Kinesis Data Firehose به ما کمک میکند تا دستههایی از دادهها را در زمان واقعی در مقصد دریاچه داده S3 خود بارگیری کنیم.
تصویر زیر نشان می دهد که چگونه داده ها از طریق جریان داده های Kinesis جریان می یابد نمایشگر داده و داده های نمونه ای را که روی پیشوند خام S3 قرار می گیرند، بازیابی می کند. برای این معماری، ما چرخه عمر داده را برای پیشوندهای S3 همانطور که در توصیه می شود دنبال کردیم بنیاد دریاچه داده.
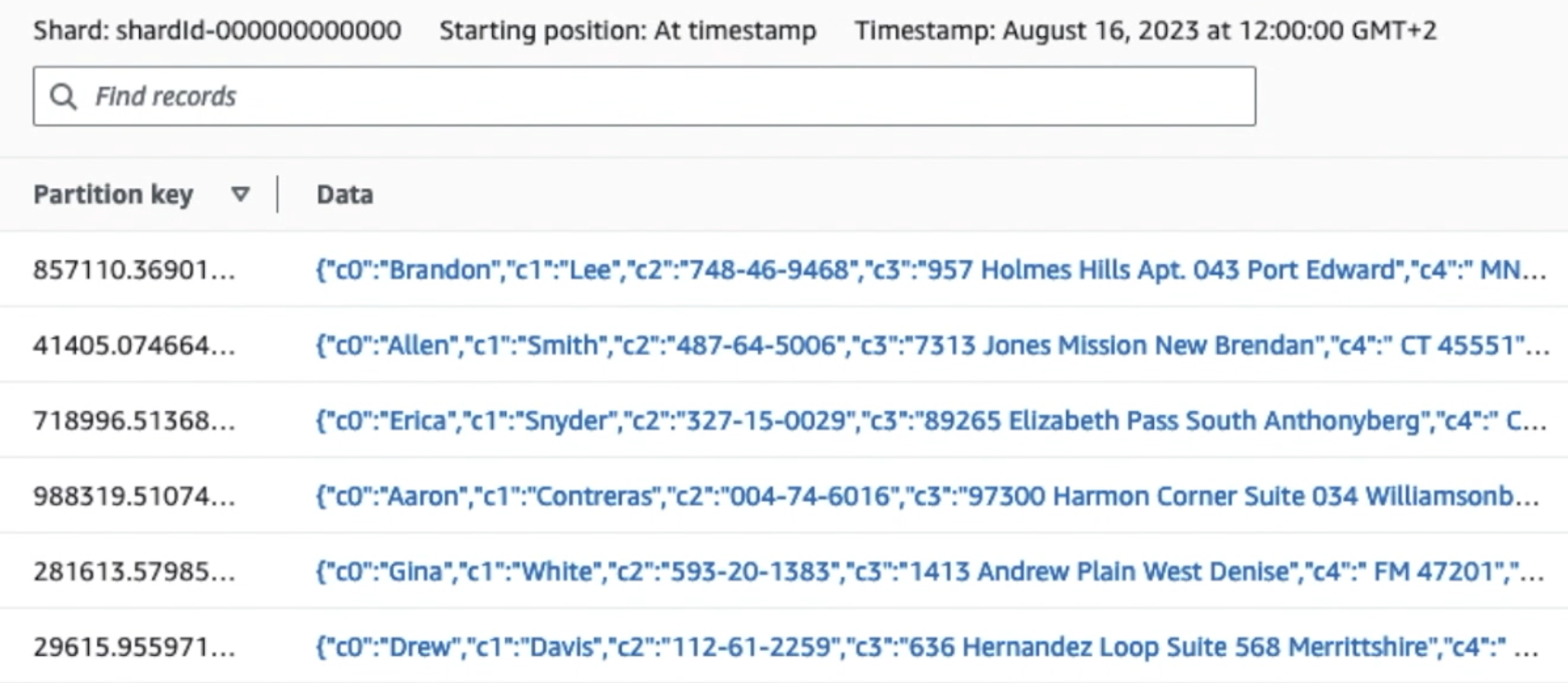
همانطور که از جزئیات اولین رکورد در اسکرین شات زیر می بینید، بار JSON از همان طرحی که در بخش قبل بود پیروی می کند. می توانید داده های ویرایش نشده را مشاهده کنید که در جریان داده های Kinesis جریان می یابند، که بعداً در مراحل بعدی مبهم خواهد شد.
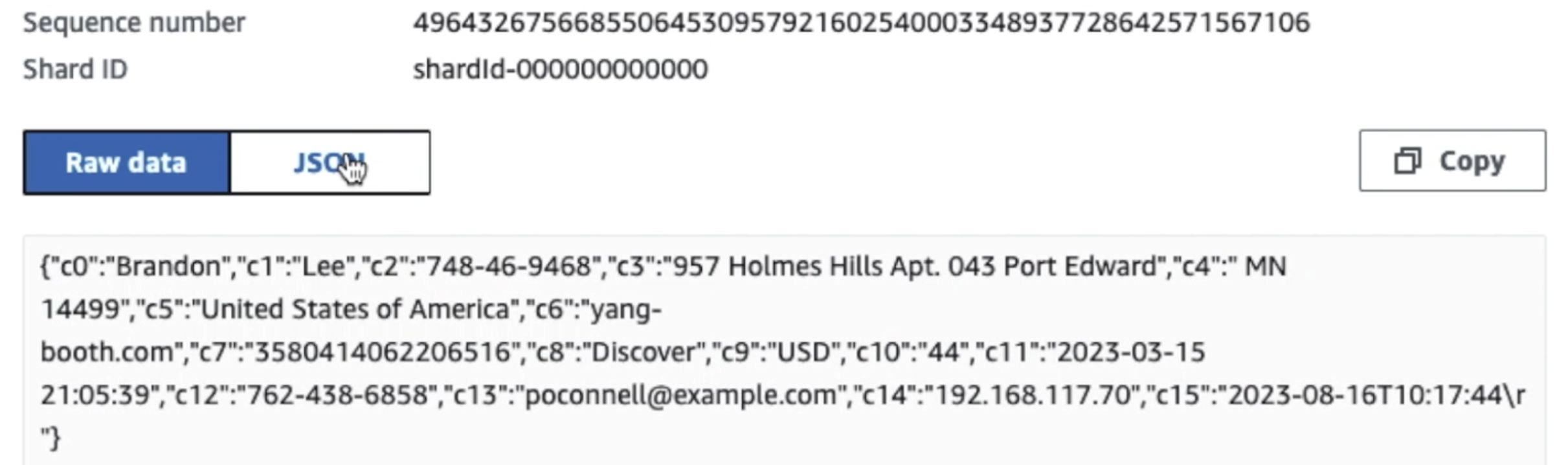
پس از جمعآوری دادهها و وارد شدن به Kinesis Data Streams و تحویل به سطل S3 با استفاده از Kinesis Data Firehose، لایه پردازش معماری کار را بر عهده میگیرد. ما از تبدیل AWS Glue PII برای شناسایی و پوشاندن خودکار داده های حساس در خط لوله خود استفاده می کنیم. همانطور که در نمودار گردش کار زیر نشان داده شده است، ما یک رویکرد ETL بدون کد و بصری را برای پیاده سازی کار تبدیل خود در AWS Glue Studio اتخاذ کردیم.
ابتدا به جدول منبع داده کاتالوگ به صورت خام از قسمت دسترسی پیدا می کنیم pii_data_db پایگاه داده جدول دارای ساختار طرحواره ارائه شده در بخش قبل است. برای پیگیری داده های خام پردازش شده، ما استفاده کردیم نشانک های شغلی.

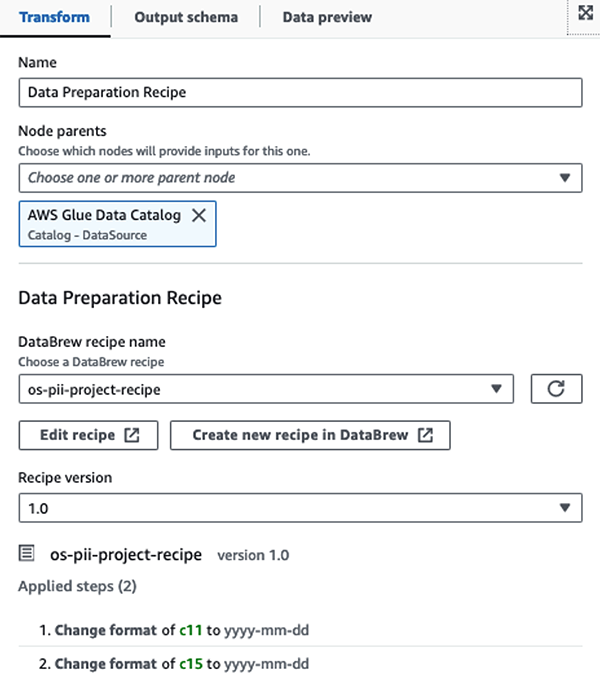
ما با استفاده از دستور العمل های AWS Glue DataBrew در کار تصویری ETL AWS Glue Studio برای تبدیل دو ویژگی تاریخ برای سازگاری با OpenSearch مورد انتظار فرمت. این به ما امکان می دهد تا یک تجربه کامل بدون کد داشته باشیم.
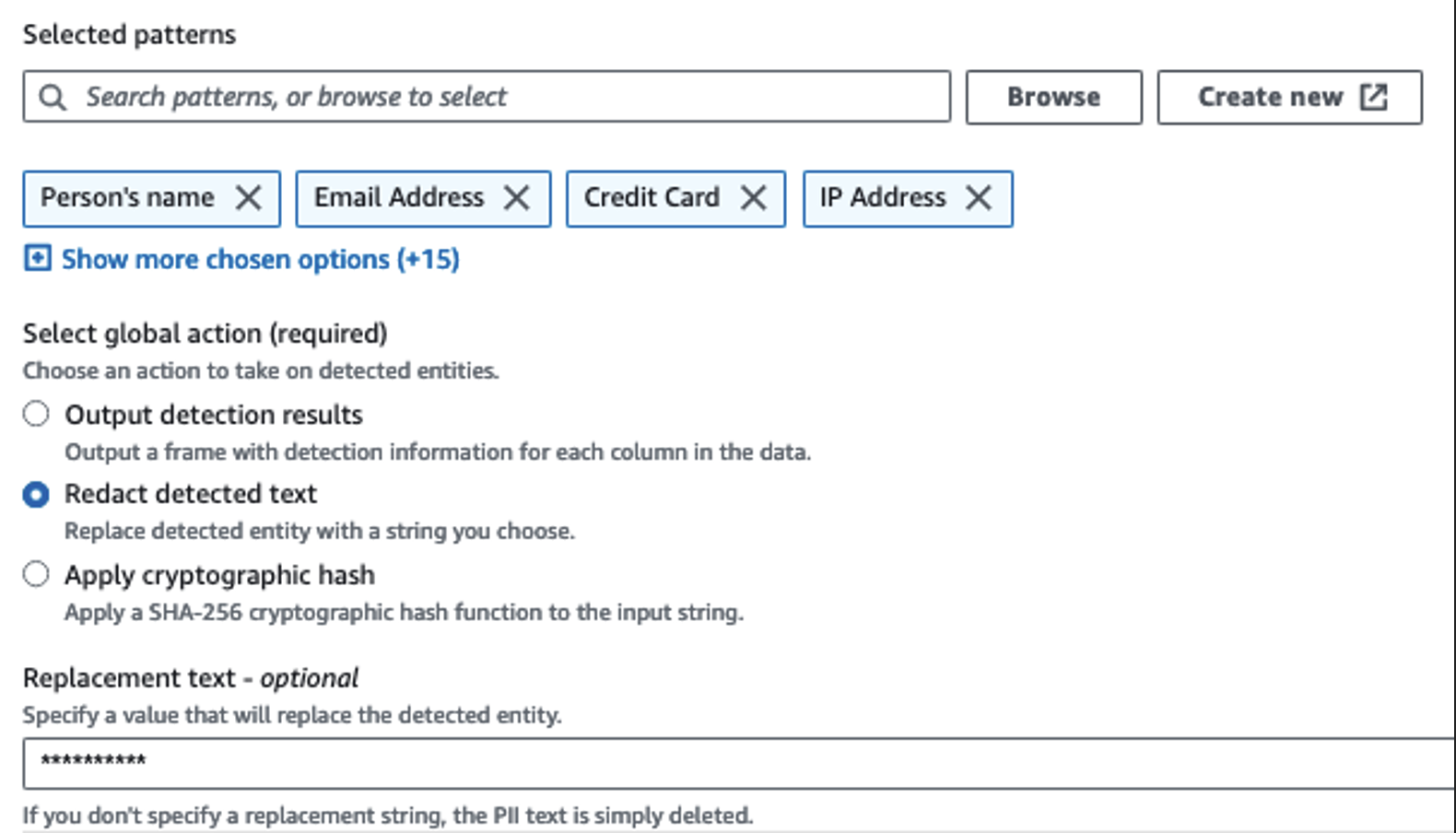
ما از اکشن Detect PII برای شناسایی ستون های حساس استفاده می کنیم. ما به AWS Glue اجازه میدهیم این را بر اساس الگوهای انتخابی، آستانه تشخیص و بخش نمونهای از ردیفها از مجموعه داده تعیین کند. در مثال خود، از الگوهایی استفاده کردیم که به طور خاص برای ایالات متحده اعمال میشوند (مانند SSN) و ممکن است دادههای حساس کشورهای دیگر را شناسایی نکنند. میتوانید به دنبال دستهها و مکانهای قابل استفاده برای مورد استفاده خود باشید یا از عبارات منظم (regex) در چسب AWS برای ایجاد موجودیتهای تشخیص دادههای حساس از کشورهای دیگر استفاده کنید.
مهم است که روش نمونه برداری صحیحی را که AWS Glue ارائه می دهد انتخاب کنید. در این مثال، مشخص است که دادههای وارد شده از جریان، دادههای حساسی در هر ردیف دارند، بنابراین لازم نیست 100٪ از ردیفهای مجموعه داده نمونهبرداری شود. اگر نیازی دارید که در آن هیچ داده حساسی به منابع پایین دستی مجاز نیست، 100٪ از داده ها را برای الگوهایی که انتخاب کرده اید نمونه برداری کنید، یا کل مجموعه داده را اسکن کنید و روی هر سلول جداگانه عمل کنید تا مطمئن شوید که همه داده های حساس شناسایی شده اند. مزیتی که از نمونه برداری به دست می آورید کاهش هزینه ها است زیرا نیازی به اسکن داده های زیادی ندارید.

اکشن Detect PII به شما امکان می دهد هنگام پوشاندن داده های حساس یک رشته پیش فرض را انتخاب کنید. در مثال ما از رشته ********** استفاده می کنیم.
برای تغییر نام و حذف ستون های غیرضروری مانند ingestion_year, ingestion_monthو ingestion_day. این مرحله همچنین به ما اجازه می دهد تا نوع داده یکی از ستون ها را تغییر دهیم (purchase_value) از رشته به عدد صحیح.

از این نقطه به بعد، کار به دو مقصد خروجی تقسیم میشود: OpenSearch Service و Amazon S3.
خوشه سرویس OpenSearch ارائه شده ما از طریق متصل است رابط داخلی OpenSearch برای چسب. ما فهرست OpenSearch را مشخص میکنیم که میخواهیم روی آن بنویسیم و رابط اطلاعات کاربری، دامنه و پورت را مدیریت میکند. در اسکرین شات زیر، به شاخص مشخص شده می نویسیم index_os_pii.
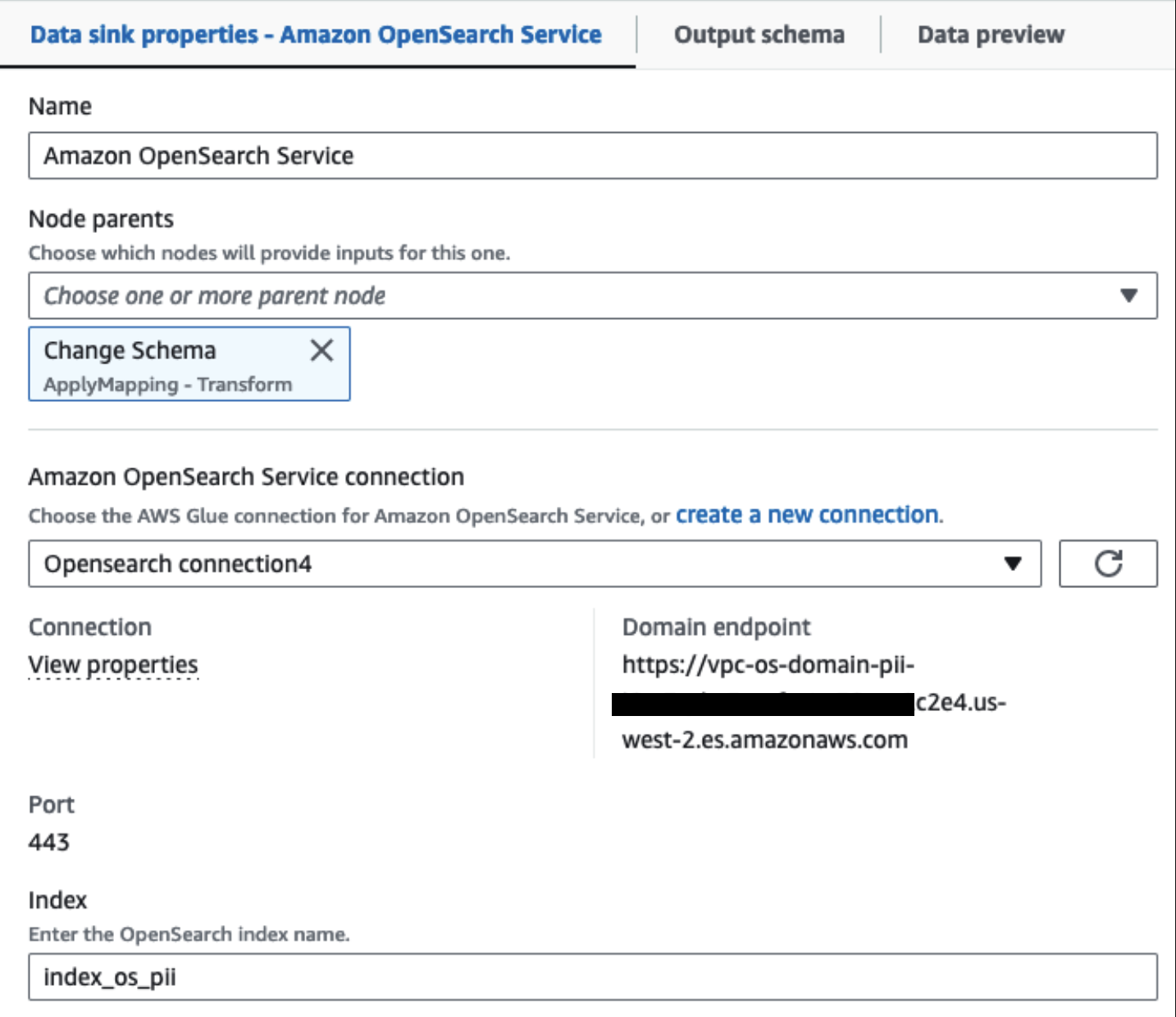
ما مجموعه داده پوشانده شده را در پیشوند S3 ذخیره می کنیم. در آنجا، ما دادههایی را داریم که به یک مورد استفاده خاص و مصرف ایمن توسط دانشمندان داده یا برای نیازهای گزارش موقتی عادی شدهاند.
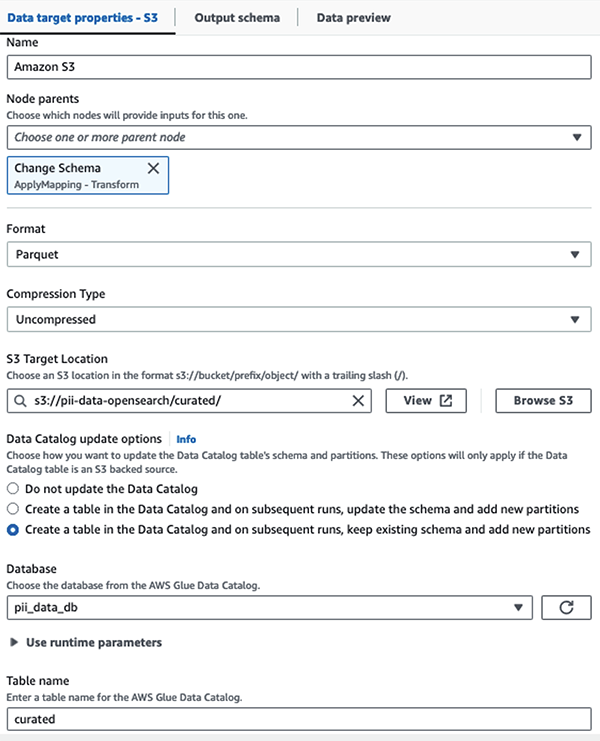
برای راهبری یکپارچه، کنترل دسترسی، و مسیرهای حسابرسی همه مجموعه داده ها و جداول کاتالوگ داده، می توانید از سازند دریاچه AWS. این به شما کمک میکند دسترسی به جداول AWS Glue Data Catalog و دادههای زیربنایی را فقط به آن دسته از کاربران و نقشهایی که مجوزهای لازم برای این کار داده شدهاند محدود کنید.
پس از اجرای موفقیت آمیز کار دسته ای، می توانید از سرویس OpenSearch برای اجرای پرس و جوها یا گزارش های جستجو استفاده کنید. همانطور که در تصویر زیر نشان داده شده است، خط لوله فیلدهای حساس را به طور خودکار بدون هیچ تلاشی برای توسعه کد پوشش می دهد.

همانطور که در تصویر قبلی نشان داده شده است، میتوانید روندها را از دادههای عملیاتی شناسایی کنید، مانند میزان تراکنشها در روز که توسط ارائهدهنده کارت اعتباری فیلتر شده است. همچنین میتوانید مکانها و دامنههایی را که کاربران در آن خرید میکنند، تعیین کنید. را transaction_date ویژگی به ما کمک می کند تا این روندها را در طول زمان ببینیم. تصویر زیر رکوردی را نشان می دهد که تمام اطلاعات تراکنش به درستی ویرایش شده است.
برای روش های جایگزین در مورد نحوه بارگیری داده ها در آمازون OpenSearch، مراجعه کنید بارگیری جریان داده در سرویس جستجوی باز آمازون.
علاوه بر این، داده های حساس را می توان با استفاده از راه حل های دیگر AWS کشف و پنهان کرد. برای مثال می توانید استفاده کنید آمازون میسی برای شناسایی داده های حساس داخل یک سطل S3 و سپس استفاده از درک آمازون برای ویرایش داده های حساسی که شناسایی شده اند. برای اطلاعات بیشتر مراجعه کنید تکنیک های رایج برای شناسایی داده های PHI و PII با استفاده از خدمات AWS.
نتیجه
این پست اهمیت مدیریت دادههای حساس در محیط شما و روشها و معماریهای مختلف را مورد بحث قرار میدهد تا در عین حال به سازمان شما اجازه میدهد تا به سرعت مقیاسبندی کند. اکنون باید درک خوبی از نحوه شناسایی، پوشاندن یا ویرایش داده های خود در سرویس جستجوی باز آمازون داشته باشید.
درباره نویسندگان
 مایکل همیلتون یک معمار راه حل های تجزیه و تحلیل Sr است که بر کمک به مشتریان سازمانی برای مدرن سازی و ساده سازی حجم کاری تجزیه و تحلیل خود در AWS تمرکز دارد. او از دوچرخه سواری در کوهستان لذت می برد و زمانی که کار نمی کند با همسر و سه فرزندش وقت می گذراند.
مایکل همیلتون یک معمار راه حل های تجزیه و تحلیل Sr است که بر کمک به مشتریان سازمانی برای مدرن سازی و ساده سازی حجم کاری تجزیه و تحلیل خود در AWS تمرکز دارد. او از دوچرخه سواری در کوهستان لذت می برد و زمانی که کار نمی کند با همسر و سه فرزندش وقت می گذراند.
 دانیل روزو یک معمار ارشد راه حل با AWS از مشتریان در هلند پشتیبانی می کند. علاقه او مهندسی داده های ساده و راه حل های تجزیه و تحلیل و کمک به مشتریان برای حرکت به سمت معماری داده های مدرن است. در خارج از محل کار، او از بازی تنیس و دوچرخه سواری لذت می برد.
دانیل روزو یک معمار ارشد راه حل با AWS از مشتریان در هلند پشتیبانی می کند. علاقه او مهندسی داده های ساده و راه حل های تجزیه و تحلیل و کمک به مشتریان برای حرکت به سمت معماری داده های مدرن است. در خارج از محل کار، او از بازی تنیس و دوچرخه سواری لذت می برد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/
- : دارد
- :است
- :نه
- :جایی که
- 07
- 100
- 28
- 300
- 31
- 32
- 39
- 40
- 46
- 50
- 51
- 600
- 90
- 970
- a
- توانایی
- قادر
- تسریع شد
- دسترسی
- عمل
- عمل
- Ad
- نشانی
- عامل
- معرفی
- مجاز
- اجازه دادن
- اجازه می دهد تا
- همچنین
- همیشه
- آمازون
- آمازون کینسیس
- آمازون خدمات وب
- خدمات وب آمازون (AWS)
- مقدار
- مقدار
- an
- تحلیلی
- علم تجزیه و تحلیل
- و
- هر
- مربوط
- برنامه های کاربردی
- درخواست
- روش
- به درستی
- معماری
- هستند
- AS
- At
- خواص
- حسابرسی
- خودکار بودن
- بطور خودکار
- دسترس پذیری
- در دسترس
- AWS
- چسب AWS
- پشتیبان گیری
- بانکداری
- سیستم های بانکی
- مستقر
- BE
- زیرا
- بوده
- قبل از
- بودن
- در زیر
- سود
- به ارمغان بیاورد
- ساختن
- ساخته
- ساخته شده در
- اما
- by
- CAN
- قابلیت های
- ظرفیت
- گرفتن
- کارت
- مورد
- موارد
- کاتالوگ
- دسته
- CDC
- سلول
- تغییر دادن
- تبادل
- کانال
- فرزندان
- را انتخاب
- وضوح
- ابر
- خوشه
- رمز
- ستون
- ستون ها
- بیا
- می آید
- آینده
- سازگار
- موافق
- اجزاء
- شامل
- محاسبه
- نگرانی ها
- متصل
- در نظر بگیرید
- در نظر گرفته
- مصرف
- مصرف
- شامل
- زمینه
- ادامه دادن
- کنترل
- اصلاح
- هزینه
- میتوانست
- کشور
- ایجاد
- مجوزها و اعتبارات
- اعتبار
- کارت اعتباری
- سرپرستی
- جاری
- مشتریان
- داده ها
- تجزیه و تحلیل داده ها
- یکپارچه سازی داده ها
- دریاچه دریاچه
- بستر داده
- حریم خصوصی داده ها
- استراتژی داده
- پایگاه داده
- پایگاه های داده
- مجموعه داده ها
- تاریخ
- روز
- به طور پیش فرض
- مشخص
- تحویل داده
- نشان دادن
- نشان می دهد
- مستقر
- طرح
- مقصد
- مقصدهای
- جزئیات
- تشخیص
- شناسایی شده
- کشف
- مشخص کردن
- پروژه
- تیم های توسعه
- مختلف
- مستقیما
- كشف كردن
- کشف
- بحث کردیم
- do
- دامنه
- حوزه
- آیا
- هر
- تلاش
- پست الکترونیک
- مهندسی
- اطمینان حاصل شود
- سرمایه گذاری
- مشتریان سازمانی
- تمام
- اشخاص
- محیط
- اتر (ETH)
- حتی
- حوادث
- هر
- مثال
- مثال ها
- انتظار می رود
- تجربه
- اصطلاحات
- خارجی
- FAST
- زمینه
- پرونده
- فایل ها
- مالی
- خدمات مالی
- نام خانوادگی
- در حال جریان
- جریانها
- تمرکز
- به دنبال
- پیروی
- به دنبال آن است
- برای
- چارچوب
- از جانب
- کامل
- کاملا
- آینده
- مولد
- دریافت کنید
- خوب
- حکومت
- اعطا شده
- دستگیره
- اداره
- آیا
- he
- سلامتی
- اطلاعات سلامتی
- کمک
- کمک
- کمک می کند
- در سطح بالا
- خود را
- تاریخی
- چگونه
- چگونه
- HTML
- HTTP
- HTTPS
- صدها نفر
- شناسایی
- if
- نشان می دهد
- تصور کنید
- انجام
- اهمیت
- مهم
- in
- شامل
- از جمله
- شاخص
- فرد
- اطلاعات
- شالوده
- داخل
- ادغام
- داخلی
- به
- IT
- جاوه
- کار
- شغل ها
- JPG
- json
- نگاه داشتن
- کینسیس دیتا فایرهوز
- جریان داده های Kinesis
- شناخته شده
- دریاچه
- زمین
- زمین ها
- بزرگ
- نام
- بعد
- قوانین
- قوانین و مقررات
- لایه
- لایه
- رهبری
- اجازه
- کتابخانه
- wifecycwe
- پسندیدن
- لاین
- بار
- بارگیری
- مکان
- نگاه کنيد
- کم هزینه
- اصلی
- نگهداری
- ساخت
- اداره می شود
- بسیاری
- نقشه برداری
- ماسک
- ممکن است..
- روش
- روش
- مهاجرت
- مهاجرت
- مدرن
- نوین کردن
- نظارت بر
- بیش
- کوه
- حرکت
- متحرک
- بسیار
- چندگانه
- باید
- نام
- نام
- لازم
- نیاز
- ضروری
- نیازمند
- نیازهای
- هلند
- جدید
- نه
- گره
- اطلاع..
- اکنون
- عدد
- of
- پیشنهادات
- on
- ONE
- فقط
- عمل
- قابل استفاده
- عملیات
- بهینه سازی
- گزینه
- or
- کدام سازمان ها
- سازمان های
- دیگر
- ما
- تولید
- خارج از
- روی
- بخش
- شور
- پچ کردن
- الگوهای
- پرداخت
- پرداخت
- برای
- انجام دادن
- کارایی
- مجوز
- شخصا
- تلفن
- پی
- خط لوله
- برنامه
- سکو
- افلاطون
- هوش داده افلاطون
- PlatoData
- بازی
- نقطه
- بخشی
- پست
- ماقبل
- ارائه شده
- قبلی
- خلوت
- قوانین حریم خصوصی
- پردازش
- فرآیندهای
- در حال پردازش
- تهيه كننده
- محفوظ
- پروتکل
- ارائه دهنده
- فراهم می کند
- خرید
- نمایش ها
- به سرعت
- نسبتا
- خام
- داده های خام
- زمان واقعی
- دلایل
- دریافت
- دستور پخت
- توصیه می شود
- رکورد
- سوابق
- کاهش
- مراجعه
- منظم
- مقررات
- قابلیت اطمینان
- ماندن
- برداشتن
- گزارش
- گزارش ها
- نیاز
- نیاز
- مورد نیاز
- مسئولیت
- مسئوليت
- محدود کردن
- نتایج
- نقش
- ROW
- دویدن
- اجرا می شود
- SAAS
- قربانی کردن
- امن
- با خیال راحت
- همان
- مقیاس
- اسکن
- برنامه
- دانشمندان
- پرده
- sdk
- جستجو
- بخش
- ایمن
- تیم امنیت لاتاری
- دیدن
- را انتخاب کنید
- انتخاب شد
- ارشد
- حساس
- فرستاده
- سرویس
- خدمات
- عکس
- باید
- نشان داده شده
- نشان می دهد
- ساده
- ساده کردن
- کوچک
- So
- آگاهی
- نرم افزار
- نرم افزار به عنوان یک سرویس
- راه حل
- مزایا
- منبع
- منابع
- خاص
- به طور خاص
- مشخص شده
- خرج کردن
- هزینه
- تقسیم می کند
- مراحل
- ایالات
- گام
- ذخیره سازی
- opbevare
- ساده
- استراتژی
- جریان
- جریان
- جریان
- رشته
- ساختار
- ساخت یافته
- استودیو
- متعاقب
- موفقیت
- چنین
- مناسب
- پشتیبانی
- حمایت از
- سیستم
- سیستم های
- جدول
- طول می کشد
- هدف
- تیم
- تیم ها
- تکنیک
- تنیس
- ده ها
- نسبت به
- که
- La
- آینده
- هلند
- منبع
- شان
- سپس
- آنجا.
- اینها
- این
- کسانی که
- سه
- آستانه
- از طریق
- زمان
- به
- در زمان
- ابزار
- مسیر
- معاملات
- انتقال
- نقل و انتقالات
- دگرگون کردن
- دگرگونی
- روند
- باعث شد
- دو
- نوع
- انواع
- در نهایت
- اساسی
- درک
- یکپارچه
- متحد
- ایالات متحده
- us
- استفاده کنید
- مورد استفاده
- استفاده
- کاربران
- با استفاده از
- ارزش
- تنوع
- مختلف
- از طريق
- بصری
- راه رفتن
- بود
- راه
- we
- وب
- خدمات وب
- چی
- چه زمانی
- که
- در حین
- WHO
- زن
- اراده
- با
- در داخل
- بدون
- مهاجرت کاری
- گردش کار
- کارگر
- نوشتن
- شما
- شما
- زفیرنت