A technical paper titled “Massive Data-Centric Parallelism in the Chiplet Era” was published by researchers at Princeton University.
چکیده:
“Traditionally, massively parallel applications are executed on distributed systems, where computing nodes are distant enough that the parallelization schemes must minimize communication and synchronization to achieve scalability. Mapping communication-intensive workloads to distributed systems requires complicated problem partitioning and dataset pre-processing. With the current AI-driven trend of having thousands of interconnected processors per chip, there is an opportunity to re-think these communication-bottlenecked workloads. This bottleneck often arises from data structure traversals, which cause irregular memory accesses and poor cache locality.
Recent works have introduced task-based parallelization schemes to accelerate graph traversal and other sparse workloads. Data structure traversals are split into tasks and pipelined across processing units (PUs). Dalorex demonstrated the highest scalability (up to thousands of PUs on a single chip) by having the entire dataset on-chip, scattered across PUs, and executing the tasks at the PU where the data is local. However, it also raised questions on how to scale to larger datasets when all the memory is on chip, and at what cost.
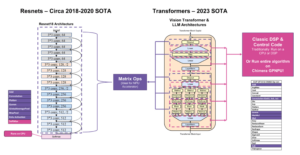
To address these challenges, we propose a scalable architecture composed of a grid of Data-Centric Reconfigurable Array (DCRA) chiplets. Package-time reconfiguration enables creating chip products that optimize for different target metrics, such as time-to-solution, energy, or cost, while software reconfigurations avoid network saturation when scaling to millions of PUs across many chip packages. We evaluate six applications and four datasets, with several configurations and memory technologies, to provide a detailed analysis of the performance, power, and cost of data-local execution at scale. Our parallelization of Breadth-First-Search with RMAT-26 across a million PUs reaches 3323 GTEPS.”
فنی را پیدا کنید کاغذ اینجا. منتشر شده در آوریل 2023 (پیش چاپ).
Orenes-Vera, Marcelo, Esin Tureci, David Wentzlaf, and Margaret Martonosi. “Massive Data-Centric Parallelism in the Chiplet Era.” پیش چاپ arXiv arXiv: 2304.09389 (2023).
مربوط
مینی کنسرسیوم ها در اطراف تراشه ها شکل می گیرند
Commercial chiplet marketplaces are still on the distant horizon, but companies are getting an early start with more limited partnerships.
خطرات امنیتی تراشه دست کم گرفته شده است
بزرگی چالش های امنیتی برای چیپلت های تجاری دلهره آور است.
مسابقه به سوی تراشه های ریخته گری مخلوط
چالش های مونتاژ چیپلت ها از ریخته گری های مختلف تازه در حال ظهور هستند.
Design Considerations And Recent Advancements In Chiplets (UC Berkeley/ Peking University)
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- ضرب کردن آینده با آدرین اشلی. دسترسی به اینجا.
- منبع: https://semiengineering.com/data-centric-reconfigurable-array-dcra-chiplets-princeton/
- :است
- :جایی که
- $UP
- 2023
- a
- شتاب دادن
- رسیدن
- در میان
- نشانی
- پیشرفت
- معرفی
- همچنین
- an
- تحلیل
- و
- برنامه های کاربردی
- آوریل
- معماری
- هستند
- دور و بر
- صف
- AS
- At
- شروع
- اما
- by
- نهانگاه
- علت
- چالش ها
- تراشه
- تجاری
- ارتباط
- شرکت
- بغرنج
- مرکب
- محاسبه
- ملاحظات
- هزینه
- ایجاد
- جاری
- داده ها
- مجموعه داده ها
- داود
- نشان
- دقیق
- مختلف
- دور
- توزیع شده
- سیستم های توزیع شده
- در اوایل
- را قادر می سازد
- انرژی
- کافی
- تمام
- عصر
- ارزیابی
- اجرا کردن
- اعدام
- برای
- چهار
- از جانب
- گرفتن
- گراف
- توری
- آیا
- داشتن
- بالاترین
- افق
- چگونه
- چگونه
- اما
- HTTPS
- in
- به هم پیوسته
- به
- معرفی
- IT
- تنها
- بزرگتر
- محدود شده
- محلی
- بسیاری
- نقشه برداری
- بازارها
- انبوه
- حافظه
- متریک
- میلیون
- میلیون ها نفر
- بیش
- شبکه
- گره
- of
- on
- فرصت
- بهینه سازی
- or
- دیگر
- ما
- بسته
- مقاله
- موازی
- مشارکت
- پکن
- کارایی
- افلاطون
- هوش داده افلاطون
- PlatoData
- فقیر
- قدرت
- پرینستون
- مشکل
- در حال پردازش
- پردازنده ها
- محصولات
- پیشنهادات
- ارائه
- منتشر شده
- سوالات
- نژاد
- مطرح شده
- می رسد
- اخیر
- نیاز
- محققان
- خطرات
- مقیاس پذیری
- مقیاس پذیر
- مقیاس
- مقیاس گذاری
- پراکنده
- طرح ها
- تیم امنیت لاتاری
- خطرات امنیتی
- چند
- تنها
- شش
- نرم افزار
- انشعاب
- شروع
- هنوز
- ساختار
- چنین
- هماهنگ سازی
- سیستم های
- هدف
- وظایف
- فنی
- فن آوری
- که
- La
- آنجا.
- اینها
- این
- هزاران نفر
- با عنوان
- به
- نسبت به
- روند
- واحد
- دانشگاه
- بود
- we
- چی
- که
- در حین
- با
- با این نسخهها کار
- زفیرنت