این یک پست مشترک است که توسط AWS و Voxel51 نوشته شده است. Voxel51 شرکتی است که در پشت FiftyOne، کیت ابزار منبع باز برای ساخت مجموعه داده های با کیفیت بالا و مدل های بینایی کامپیوتری قرار دارد.
یک شرکت خردهفروشی در حال ساخت یک اپلیکیشن موبایل برای کمک به مشتریان در خرید لباس است. برای ایجاد این برنامه، آنها به یک مجموعه داده با کیفیت بالا شامل تصاویر لباس، برچسبگذاری شده با دستههای مختلف نیاز دارند. در این پست، ما نشان میدهیم که چگونه میتوان یک مجموعه داده موجود را از طریق پاکسازی دادهها، پیشپردازش، و پیش برچسبگذاری با یک مدل طبقهبندی صفر شات در استفاده مجدد قرار داد. پنجاه و یک، و تنظیم این برچسب ها با Amazon SageMaker Ground Truth.
می توانید از Ground Truth و FiftyOne برای تسریع پروژه برچسب گذاری داده های خود استفاده کنید. ما نحوه استفاده یکپارچه از این دو برنامه را برای ایجاد مجموعه داده های برچسب دار با کیفیت بالا نشان می دهیم. برای مثال مورد استفاده ما، ما با آن کار می کنیم مجموعه داده Fashion200K، منتشر شده در ICCV 2017.
بررسی اجمالی راه حل
Ground Truth یک سرویس برچسبگذاری داده کاملاً مستقل و مدیریت شده است که به دانشمندان داده، مهندسان یادگیری ماشین (ML) و محققان برای ساخت مجموعه دادههای با کیفیت بالا قدرت میدهد. پنجاه و یک by وکسل 51 یک جعبه ابزار منبع باز برای مدیریت، تجسم و ارزیابی مجموعه داده های بینایی کامپیوتری است تا بتوانید با تسریع در موارد استفاده، مدل های بهتری را آموزش و تجزیه و تحلیل کنید.
در بخش های زیر نحوه انجام کارهای زیر را نشان می دهیم:
- مجموعه داده را در FiftyOne تجسم کنید
- مجموعه داده را با فیلتر کردن و حذف مجدد تصاویر در FiftyOne پاک کنید
- داده های پاک شده را با طبقه بندی صفر شات در FiftyOne از قبل برچسب بزنید
- مجموعه داده کوچکتر انتخاب شده را با Ground Truth برچسب گذاری کنید
- نتایج برچسبگذاری شده از Ground Truth را به FiftyOne تزریق کنید و نتایج برچسبگذاری شده را در FiftyOne بررسی کنید
از نمای کلی مورد استفاده کنید
فرض کنید صاحب یک شرکت خردهفروشی هستید و میخواهید یک اپلیکیشن موبایلی بسازید تا توصیههای شخصیسازی شده برای کمک به کاربران در تصمیمگیری برای پوشیدن لباسها ارائه کنید. کاربران بالقوه شما به دنبال برنامهای هستند که به آنها بگوید کدام لباسها در کمدشان به خوبی با هم کار میکنند. شما یک فرصت را در اینجا می بینید: اگر می توانید لباس های خوب را شناسایی کنید، می توانید از این برای توصیه لباس های جدید استفاده کنید که مکمل لباس هایی است که مشتری از قبل دارد.
شما می خواهید کارها را تا حد امکان برای کاربر نهایی آسان کنید. در حالت ایده آل، شخصی که از برنامه شما استفاده می کند فقط باید از لباس های موجود در کمد لباس خود عکس بگیرد و مدل های ML شما در پشت صحنه جادوی خود را انجام می دهند. میتوانید یک مدل همهمنظوره را آموزش دهید یا با نوعی بازخورد، یک مدل را با سبک منحصر به فرد هر کاربر تنظیم کنید.
با این حال، ابتدا باید تشخیص دهید که کاربر چه نوع لباسی را می گیرد. آیا پیراهن است؟ یک شلوار؟ یا چیز دیگری؟ از این گذشته، احتمالاً نمی خواهید لباسی را توصیه کنید که دارای چندین لباس یا کلاه باشد.
برای مقابله با این چالش اولیه، شما می خواهید مجموعه داده آموزشی متشکل از تصاویری از انواع لباس با الگوها و سبک های مختلف ایجاد کنید. برای نمونه سازی با بودجه محدود، می خواهید با استفاده از مجموعه داده های موجود بوت استرپ کنید.
برای نشان دادن و راهنمایی شما در فرآیند این پست، از مجموعه داده Fashion200K که در ICCV 2017 منتشر شد، استفاده میکنیم. این مجموعه دادهای ثابت و قابل استناد است، اما مستقیماً برای مورد استفاده شما مناسب نیست.
اگرچه محصولات لباس با دستهها (و زیرمجموعهها) برچسبگذاری میشوند و حاوی انواع برچسبهای مفیدی هستند که از توضیحات اصلی محصول استخراج شدهاند، دادهها به طور سیستماتیک با اطلاعات الگو یا سبک برچسبگذاری نمیشوند. هدف شما این است که این مجموعه داده موجود را به یک مجموعه داده آموزشی قوی برای مدل های طبقه بندی لباس خود تبدیل کنید. باید داده ها را تمیز کنید و طرح برچسب گذاری را با برچسب های سبک تقویت کنید. و شما می خواهید این کار را سریع و با کمترین هزینه ممکن انجام دهید.
داده ها را به صورت محلی دانلود کنید
ابتدا فایل زیپ women.tar و پوشه labels (با تمام زیر پوشه های آن) را طبق دستورالعمل های ارائه شده در زیر دانلود کنید. مخزن مجموعه داده Fashion200K GitHub. بعد از اینکه هر دو را از حالت فشرده خارج کردید، یک پوشه والد fashion200k ایجاد کنید و پوشهها و برچسبها را به این قسمت منتقل کنید. خوشبختانه، این تصاویر قبلاً در جعبههای مرزی تشخیص اشیا برش داده شدهاند، بنابراین میتوانیم به جای نگرانی در مورد تشخیص شی، بر طبقهبندی تمرکز کنیم.
با وجود "200K" در نام خود، فهرست زنانی که استخراج کردیم شامل 338,339 تصویر است. برای تولید مجموعه داده رسمی Fashion200K، نویسندگان مجموعه داده بیش از 300,000 محصول را به صورت آنلاین خزیده اند و تنها محصولاتی با توضیحات حاوی بیش از چهار کلمه برش داده شده اند. برای اهداف ما، جایی که شرح محصول ضروری نیست، میتوانیم از همه تصاویر خزیده شده استفاده کنیم.
بیایید به نحوه سازماندهی این داده ها نگاهی بیندازیم: در پوشه زنان، تصاویر بر اساس نوع مقاله سطح بالا (دامن، تاپ، شلوار، ژاکت و لباس) و زیر شاخه نوع مقاله (بلوز، تی شرت، آستین بلند) مرتب می شوند. تاپ ها).
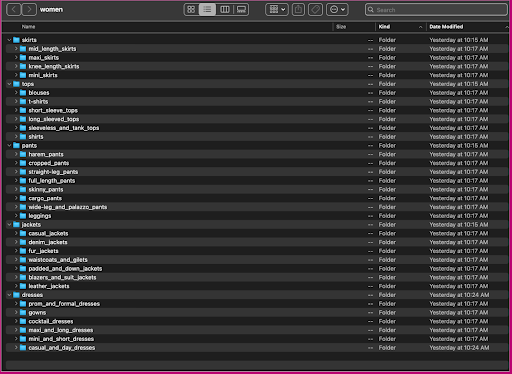
در دایرکتوری های زیر شاخه، یک زیر شاخه برای هر فهرست محصول وجود دارد. هر کدام از اینها دارای تعداد متغیری از تصاویر است. برای مثال، زیرشاخه cropped_pants شامل لیست محصولات زیر و تصاویر مرتبط است.
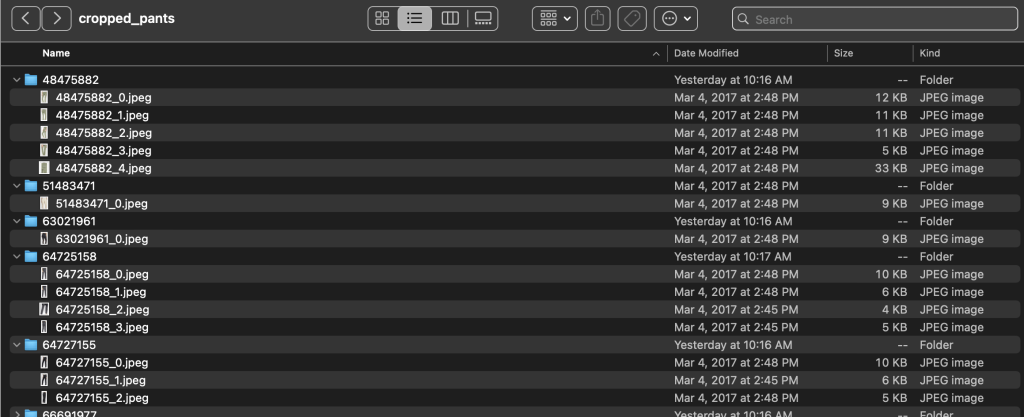
پوشه برچسب ها حاوی یک فایل متنی برای هر نوع مقاله سطح بالا، هم برای تقسیم قطار و هم برای تقسیم بندی آزمایشی است. درون هر یک از این فایلهای متنی یک خط جداگانه برای هر تصویر وجود دارد که مسیر فایل نسبی، امتیاز و برچسبها را از توضیحات محصول مشخص میکند.
از آنجایی که ما مجموعه داده را تغییر کاربری می دهیم، تمام تصاویر قطار و آزمایش را با هم ترکیب می کنیم. ما از اینها برای تولید یک مجموعه داده خاص برنامه کاربردی با کیفیت بالا استفاده می کنیم. پس از تکمیل این فرآیند، میتوانیم بهطور تصادفی مجموعه دادههای حاصل را به بخشهای قطار و آزمایش جدید تقسیم کنیم.
یک مجموعه داده را در FiftyOne تزریق، مشاهده و مدیریت کنید
اگر قبلاً این کار را نکرده اید، FiftyOne منبع باز را با استفاده از pip نصب کنید:
بهترین روش انجام این کار در یک محیط مجازی جدید (venv یا conda) است. سپس ماژول های مربوطه را وارد کنید. کتابخانه پایه، fiftyone، FiftyOne Brain را وارد کنید، که دارای روشهای ML داخلی است، FiftyOne Zoo، که از آن مدلی را بارگذاری میکنیم که برچسبهای صفر شات را برای ما تولید میکند، و ViewField، که به ما امکان میدهد به طور موثر فیلتر را فیلتر کنیم. داده های موجود در مجموعه داده ما:
همچنین میخواهید ماژولهای glob و os Python را وارد کنید، که به ما کمک میکند تا با مسیرها و تطابق الگوها بر روی محتویات دایرکتوری کار کنیم:
اکنون آماده بارگذاری مجموعه داده در FiftyOne هستیم. ابتدا یک مجموعه داده به نام fashion200k ایجاد میکنیم و آن را پایدار میکنیم، که به ما امکان میدهد نتایج عملیات محاسباتی فشرده را ذخیره کنیم، بنابراین فقط یک بار باید مقادیر گفته شده را محاسبه کنیم.
اکنون میتوانیم از طریق همه فهرستهای زیرمجموعه، همه تصاویر را در فهرستهای محصول اضافه کنیم. ما یک برچسب طبقهبندی FiftyOne به هر نمونه با نام فیلد article_type اضافه میکنیم که با دسته مقاله سطح بالای تصویر پر شده است. ما همچنین اطلاعات دسته و زیر شاخه را به عنوان برچسب اضافه می کنیم:
در این مرحله، میتوانیم مجموعه دادههای خود را در برنامه FiftyOne با راهاندازی یک جلسه تجسم کنیم:
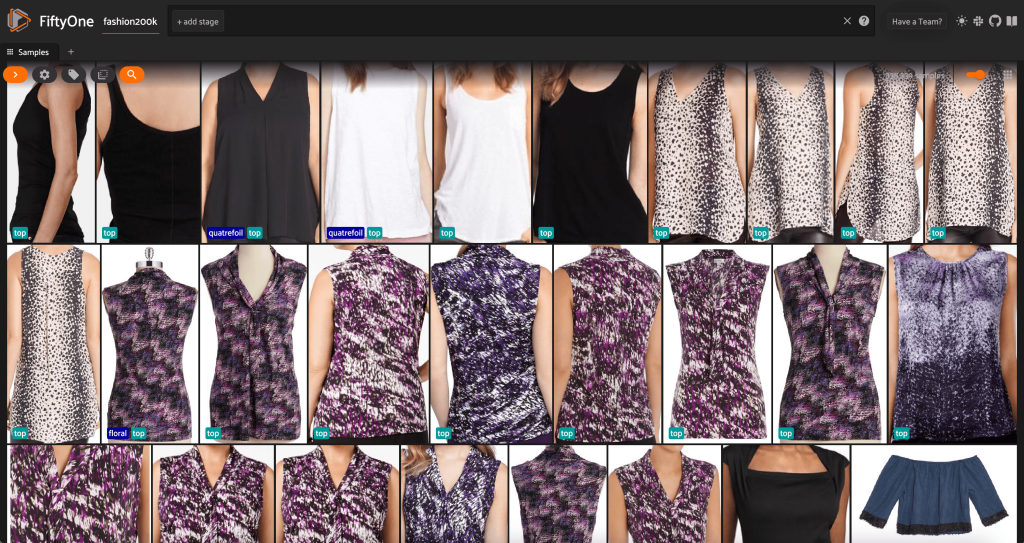
همچنین میتوانیم خلاصهای از مجموعه داده در پایتون را با اجرا چاپ کنیم print(dataset):
ما همچنین می توانیم تگ ها را از قسمت اضافه کنیم labels دایرکتوری به نمونه های موجود در مجموعه داده ما:
با نگاهی به داده ها، چند چیز روشن می شود:
- برخی از تصاویر نسبتاً دانه دانه و با وضوح پایین هستند. این احتمالاً به این دلیل است که این تصاویر با برش تصاویر اولیه در جعبه های مرزی تشخیص اشیا ایجاد شده اند.
- بعضی از لباس ها را یک نفر می پوشد و بعضی را به تنهایی عکس می گیرد. این جزئیات توسط
viewpointویژگی. - بسیاری از تصاویر یک محصول مشابه بسیار مشابه هستند، بنابراین حداقل در ابتدا، گنجاندن بیش از یک تصویر در هر محصول ممکن است قدرت پیش بینی زیادی را اضافه نکند. در بیشتر موارد، اولین تصویر از هر محصول (به پایان می رسد
_0.jpeg) تمیزترین است.
در ابتدا، ممکن است بخواهیم مدل طبقه بندی سبک لباس خود را بر روی یک زیر مجموعه کنترل شده از این تصاویر آموزش دهیم. برای این منظور، ما از تصاویر با وضوح بالا از محصولات خود استفاده می کنیم و دید خود را به یک نمونه نماینده در هر محصول محدود می کنیم.
ابتدا تصاویر با وضوح پایین را فیلتر می کنیم. ما استفاده می کنیم compute_metadata() روش محاسبه و ذخیره عرض و ارتفاع تصویر، بر حسب پیکسل، برای هر تصویر در مجموعه داده. سپس FiftyOne را به کار می گیریم ViewField برای فیلتر کردن تصاویر بر اساس حداقل مقادیر عرض و ارتفاع مجاز. کد زیر را ببینید:
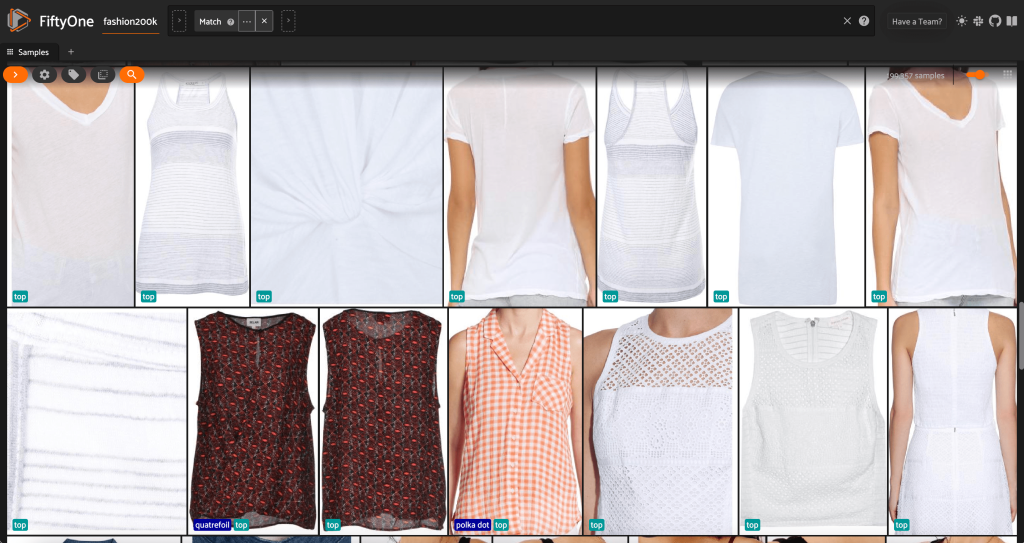
این زیر مجموعه با وضوح بالا کمتر از 200,000 نمونه دارد.
از این دیدگاه، میتوانیم یک نمای جدید در مجموعه داده خود ایجاد کنیم که فقط یک نمونه نماینده (حداکثر) برای هر محصول داشته باشد. ما استفاده می کنیم ViewField یک بار دیگر، تطبیق الگو برای مسیرهای فایل که به پایان می رسد _0.jpeg:
بیایید ترتیب تصادفی تصاویر را در این زیر مجموعه مشاهده کنیم:
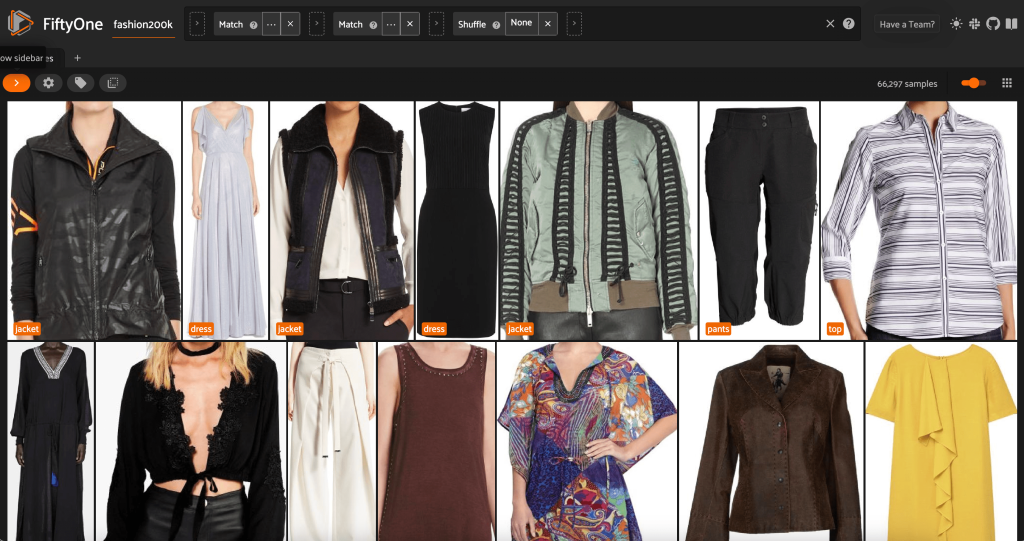
تصاویر اضافی را در مجموعه داده حذف کنید
این نمای شامل 66,297 تصویر یا کمی بیش از 19 درصد از مجموعه داده اصلی است. با این حال، وقتی به نما نگاه می کنیم، می بینیم که محصولات بسیار مشابه زیادی وجود دارد. نگهداری همه این نسخهها احتمالاً فقط به آموزش برچسبگذاری و مدلسازی ما هزینه میافزاید، بدون اینکه عملکرد قابل توجهی بهبود یابد. در عوض، بیایید از شر موارد مشابه خلاص شویم تا یک مجموعه داده کوچکتر ایجاد کنیم که همچنان همان پانچ را دارد.
از آنجایی که این تصاویر دقیقاً تکراری نیستند، نمیتوانیم برابری پیکسلی را بررسی کنیم. خوشبختانه، ما میتوانیم از FiftyOne Brain برای کمک به تمیز کردن مجموعه دادههایمان استفاده کنیم. به طور خاص، ما یک جاسازی برای هر تصویر محاسبه میکنیم - یک بردار با ابعاد پایینتر که تصویر را نشان میدهد - و سپس به دنبال تصاویری میگردیم که بردارهای جاسازی آنها نزدیک به یکدیگر هستند. هر چه بردارها به هم نزدیکتر باشند، تصاویر مشابه تر هستند.
ما از یک مدل CLIP برای تولید بردار تعبیه ۵۱۲ بعدی برای هر تصویر استفاده میکنیم و این جاسازیها را در جاسازیهای فیلد روی نمونههای مجموعه دادهمان ذخیره میکنیم:
سپس با استفاده از نزدیکی بین جاسازی ها را محاسبه می کنیم شباهت کسینوس، و ادعا کنید که هر دو بردار که شباهت آنها بیشتر از آستانه باشد احتمالاً تقریباً تکراری هستند. نمرات شباهت کسینوس در محدوده [0، 1] قرار دارد و با نگاه کردن به دادهها، به نظر میرسد که امتیاز آستانه 0.5 = thresh تقریباً درست باشد. باز هم، این نیازی به کامل بودن ندارد. چند تصویر تقریباً تکراری به احتمال زیاد قدرت پیشبینی ما را از بین نمیبرند، و دور انداختن چند تصویر غیر تکراری بر عملکرد مدل تأثیر چندانی ندارد.
ما می توانیم موارد تکراری ادعا شده را مشاهده کنیم تا بررسی کنیم که آنها واقعاً اضافی هستند:
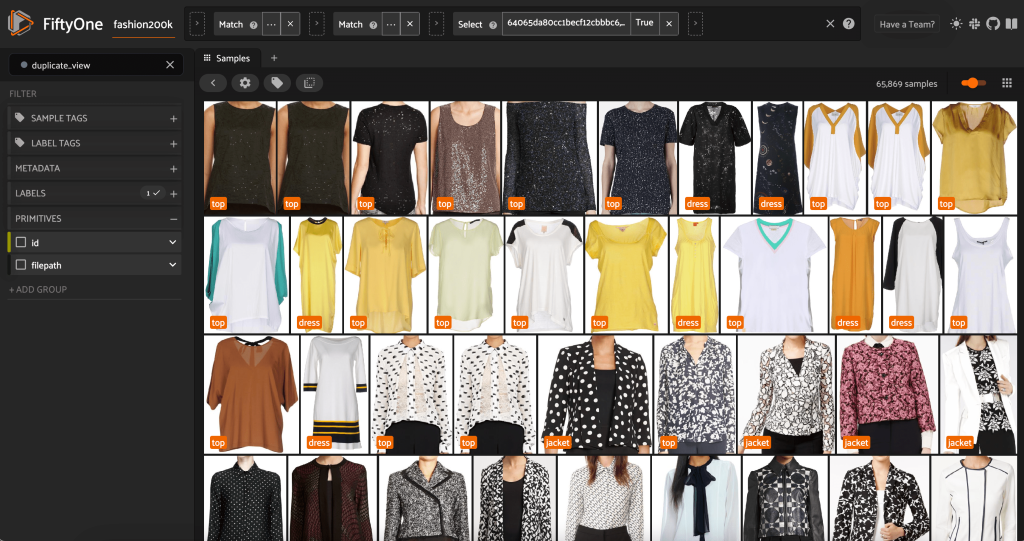
وقتی از نتیجه راضی هستیم و معتقدیم که این تصاویر واقعاً تکراری هستند، میتوانیم از هر مجموعه نمونههای مشابه یک نمونه را برای نگهداری انتخاب کنیم و بقیه را نادیده بگیریم:
اکنون این نما دارای 3,729 تصویر است. FiftyOne با پاک کردن دادهها و شناسایی زیرمجموعهای با کیفیت بالا از مجموعه دادههای Fashion200K، به ما اجازه میدهد تمرکز خود را از بیش از 300,000 تصویر به کمتر از 4,000 محدود کنیم که نشان دهنده کاهش 98 درصدی است. استفاده از جاسازیها برای حذف تصاویر تقریباً تکراری به تنهایی تعداد کل تصاویر مورد بررسی ما را تا بیش از 90 درصد کاهش داد، بدون اینکه تأثیر کمی بر روی هر مدلی که باید بر روی این دادهها آموزش داده شود.
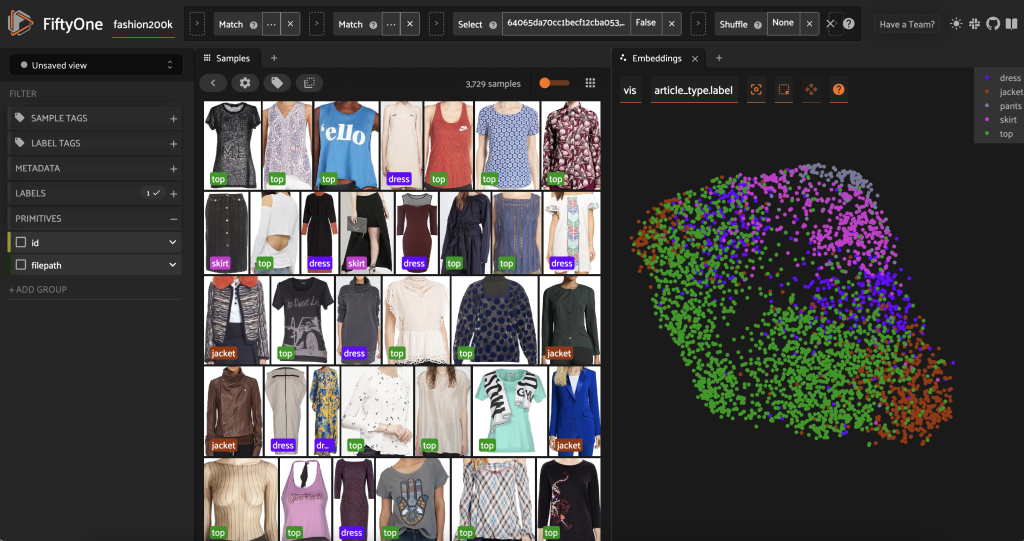
قبل از اینکه این زیر مجموعه را از قبل برچسب گذاری کنیم، با تجسم جاسازی هایی که قبلاً محاسبه کرده ایم، می توانیم داده ها را بهتر درک کنیم. ما می توانیم از FiftyOne Brain داخلی استفاده کنیم compute_visualization() روش، که از تکنیک تقریب منیفولد یکنواخت (UMAP) برای نمایش بردارهای تعبیه شده 512 بعدی در فضای دو بعدی استفاده می کند تا بتوانیم آنها را تجسم کنیم:
جدید باز می کنیم پنل جاسازی در برنامه FiftyOne و رنگآمیزی بر اساس نوع مقاله، و میتوانیم ببینیم که این جاسازیها تقریباً مفهومی از نوع مقاله را رمزگذاری میکنند (در میان چیزهای دیگر!).
اکنون ما آماده ایم که این داده ها را از قبل برچسب گذاری کنیم.
با بررسی این تصاویر بسیار منحصربهفرد و با وضوح بالا، میتوانیم فهرست اولیه مناسبی از سبکها را برای استفاده به عنوان کلاسها در طبقهبندی عکس صفر قبل از برچسبگذاری خود ایجاد کنیم. هدف ما از پیش برچسب گذاری این تصاویر این نیست که لزوماً هر تصویر را به درستی برچسب گذاری کنیم. در عوض، هدف ما ارائه یک نقطه شروع خوب برای حاشیه نویسان انسانی است تا بتوانیم زمان و هزینه برچسب گذاری را کاهش دهیم.
سپس میتوانیم یک مدل طبقهبندی شات صفر را برای این برنامه نمونهسازی کنیم. ما از یک مدل CLIP استفاده می کنیم که یک مدل همه منظوره است که هم بر روی تصاویر و هم بر روی زبان طبیعی آموزش داده شده است. ما یک مدل CLIP را با دستور متنی «لباس به سبک» نمونهسازی میکنیم، به طوری که با توجه به یک تصویر، مدل کلاسی را که «لباس به سبک [کلاس]» برای آن بهترین است را خروجی میدهد. CLIP بر روی دادههای خردهفروشی یا مد خاص آموزش داده نشده است، بنابراین بینقص نخواهد بود، اما میتواند در هزینههای برچسبگذاری و حاشیهنویسی صرفهجویی کند.
سپس این مدل را به زیر مجموعه کاهش یافته خود اعمال می کنیم و نتایج را در یک ذخیره می کنیم article_style رشته:
با راه اندازی مجدد برنامه FiftyOne، می توانیم تصاویر را با این برچسب های سبک پیش بینی شده تجسم کنیم. ما بر اساس اطمینان پیشبینی مرتب میکنیم، بنابراین ابتدا مطمئنترین پیشبینیهای سبک را مشاهده میکنیم:
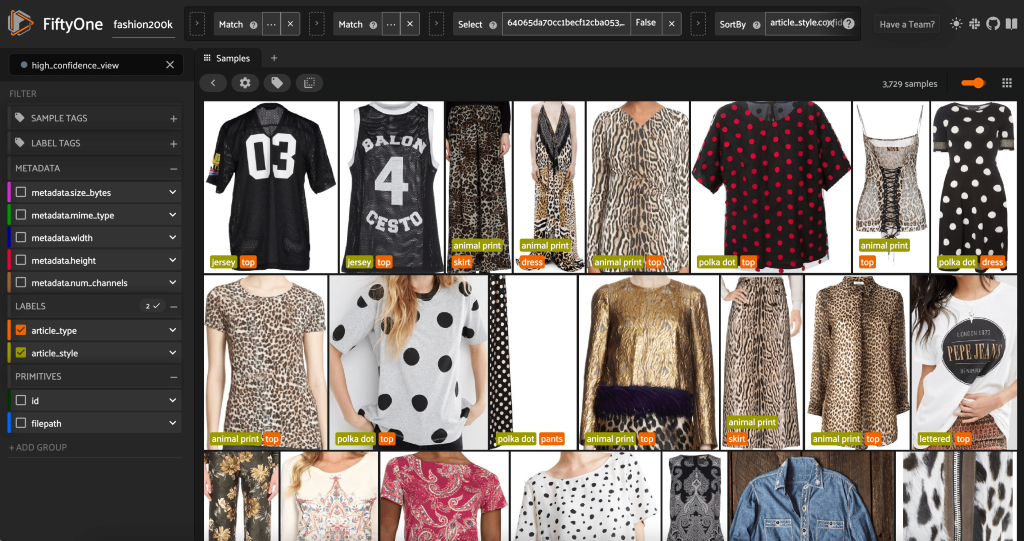
می بینیم که به نظر می رسد بالاترین پیش بینی های اطمینان مربوط به سبک های «جرسی»، «چاپ حیوانی»، «پولکا نقطه» و «حروف» باشد. این منطقی است، زیرا این سبک ها نسبتاً متمایز هستند. همچنین به نظر می رسد که در بیشتر موارد، برچسب های سبک پیش بینی شده دقیق هستند.
همچنین میتوانیم به پیشبینیهای سبک کماعتماد نگاه کنیم:
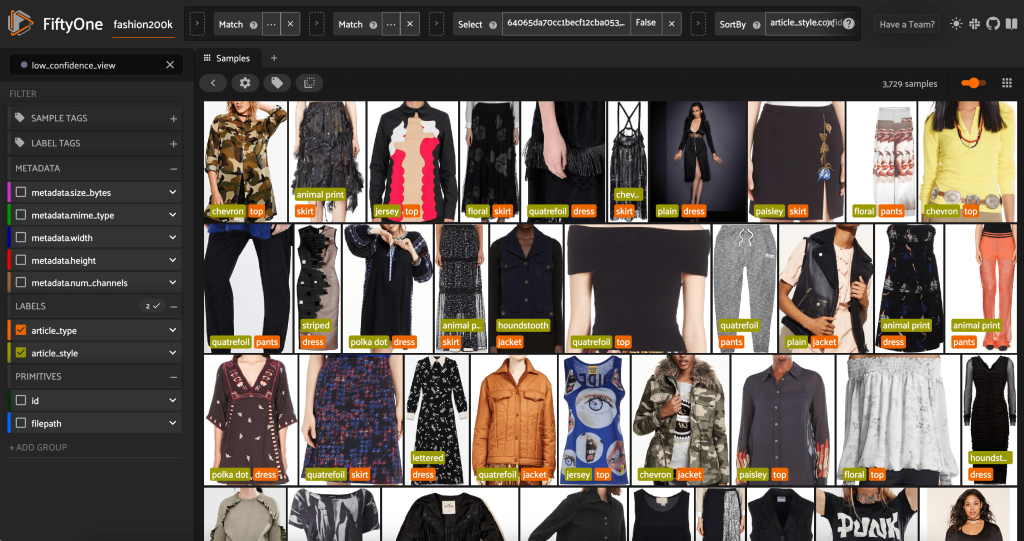
برای برخی از این تصاویر، دسته بندی استایل مناسب در لیست ارائه شده قرار دارد و روی کالای لباس به اشتباه برچسب گذاری شده است. به عنوان مثال، اولین تصویر در شبکه باید به وضوح "استتار" باشد و نه "شورون". با این حال، در موارد دیگر، محصولات به طور منظم در دسته بندی های سبک قرار نمی گیرند. برای مثال، لباس در تصویر دوم در ردیف دوم، دقیقاً «راه راه» نیست، اما با توجه به گزینههای برچسبگذاری یکسان، ممکن است حاشیهنویس انسانی نیز دچار تضاد باشد. همانطور که مجموعه داده خود را ایجاد می کنیم، باید تصمیم بگیریم که آیا موارد لبه مانند این موارد را حذف کنیم، دسته بندی های سبک جدید اضافه کنیم یا مجموعه داده را تقویت کنیم.
مجموعه داده نهایی را از FiftyOne صادر کنید
مجموعه داده نهایی را با کد زیر صادر کنید:
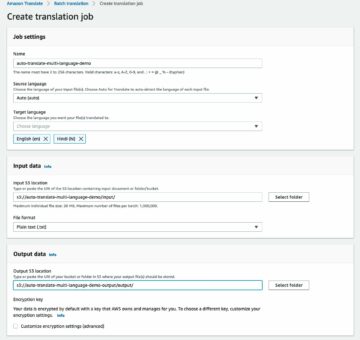
میتوانیم مجموعه دادههای کوچکتری، به عنوان مثال، 16 تصویر را به پوشه صادر کنیم 200kFashionDatasetExportResult-16Images. ما با استفاده از آن یک کار تنظیم Truth ایجاد می کنیم:
مجموعه داده اصلاح شده را آپلود کنید، قالب برچسب را به Ground Truth تبدیل کنید، در Amazon S3 آپلود کنید، و یک فایل مانیفست برای کار تنظیم ایجاد کنید.
ما می توانیم برچسب های موجود در مجموعه داده را برای مطابقت با آن تبدیل کنیم طرح مانیفست خروجی از یک کار جعبه مرزی Ground Truth و آپلود تصاویر در یک سرویس ذخیره سازی ساده آمازون (Amazon S3) سطل برای راه اندازی یک کار تنظیم حقیقت زمین:
فایل مانیفست را با کد زیر در Amazon S3 آپلود کنید:
با Ground Truth برچسبهای استایل اصلاح شده ایجاد کنید
برای حاشیهنویسی دادههای خود با برچسبهای سبک با استفاده از Ground Truth، مراحل لازم را برای شروع کار برچسبگذاری جعبه مرزی با پیروی از روش مشخص شده در شروع با حقیقت پایه راهنمای با مجموعه داده در همان سطل S3.
- در کنسول SageMaker، یک کار برچسبگذاری Ground Truth ایجاد کنید.
- تنظیم کنید محل مجموعه داده ورودی تا مانیفستی باشد که در مراحل قبل ایجاد کردیم.
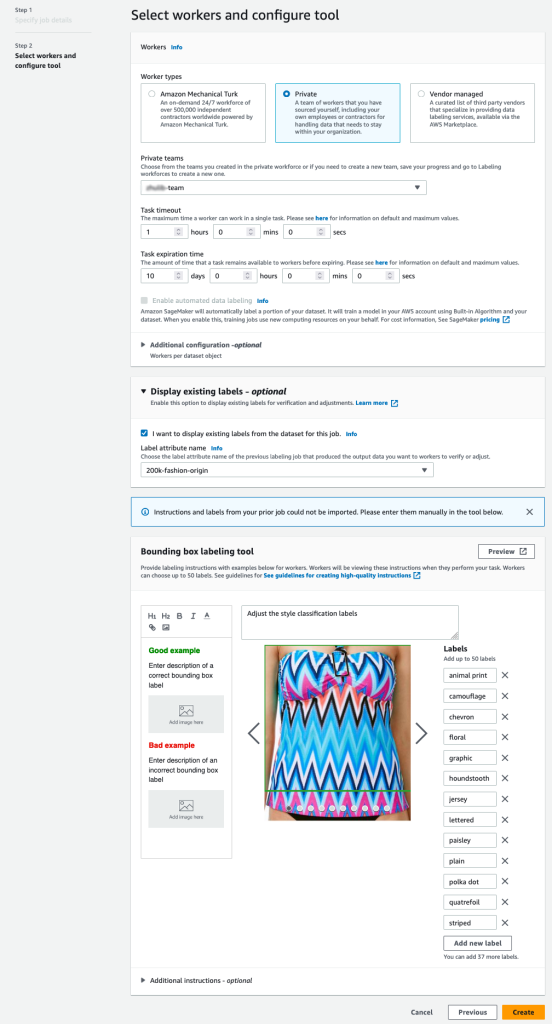
- یک مسیر S3 برای محل داده خروجی.
- برای نقش IAM، انتخاب کنید یک نقش سفارشی IAM را وارد کنید RNA، سپس نقش ARN را وارد کنید.
- برای دسته وظایف، انتخاب کنید تصویر را انتخاب کنید و جعبه مرزی.
- را انتخاب کنید بعدی.
- در کارگران بخش، نوع نیروی کاری را که می خواهید استفاده کنید انتخاب کنید.
شما می توانید نیروی کار را از طریق انتخاب کنید آمازون مکانیک ترک، فروشندگان شخص ثالث یا نیروی کار خصوصی شما. برای جزئیات بیشتر در مورد گزینه های نیروی کار خود، ببینید ایجاد و مدیریت نیروی کار. - گسترش گزینههای نمایش برچسبهای موجود را انتخاب کنید و من می خواهم برچسب های موجود را از مجموعه داده برای این کار نمایش دهم.
- برای ویژگی برچسب نام، نامی را از مانیفست خود انتخاب کنید که مطابق با برچسب هایی است که می خواهید برای تنظیم نمایش دهید.
شما فقط نام ویژگی های برچسب را برای برچسب هایی خواهید دید که با نوع کار انتخابی شما در مراحل قبلی مطابقت دارند. - برچسب ها را به صورت دستی وارد کنید ابزار برچسب زدن جعبه مرزی.
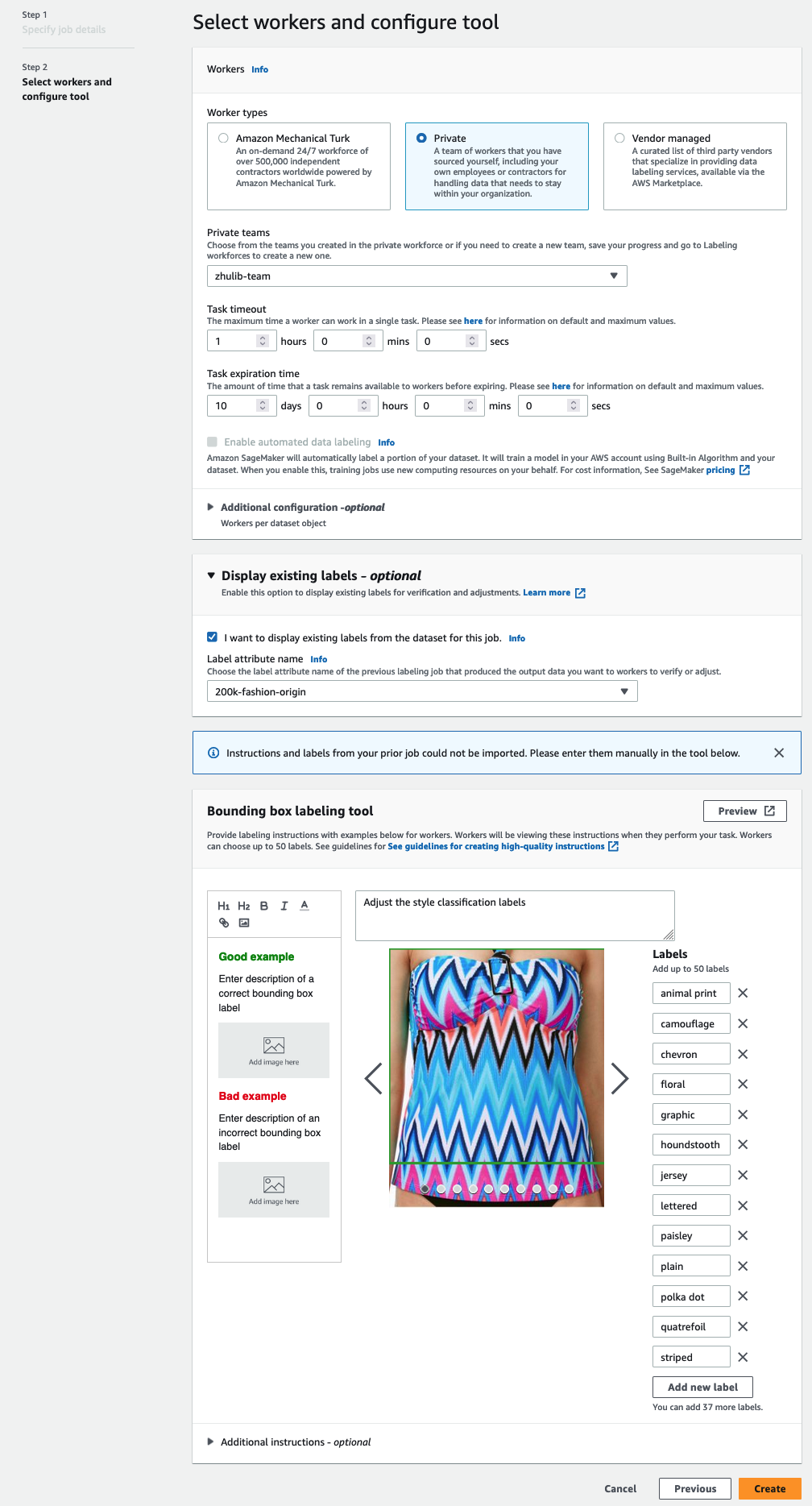 برچسب ها باید حاوی همان برچسب های مورد استفاده در مجموعه داده عمومی باشند. می توانید برچسب های جدید اضافه کنید. تصویر زیر نشان می دهد که چگونه می توانید کارگران را انتخاب کنید و ابزار را برای کار برچسب زدن خود پیکربندی کنید.
برچسب ها باید حاوی همان برچسب های مورد استفاده در مجموعه داده عمومی باشند. می توانید برچسب های جدید اضافه کنید. تصویر زیر نشان می دهد که چگونه می توانید کارگران را انتخاب کنید و ابزار را برای کار برچسب زدن خود پیکربندی کنید.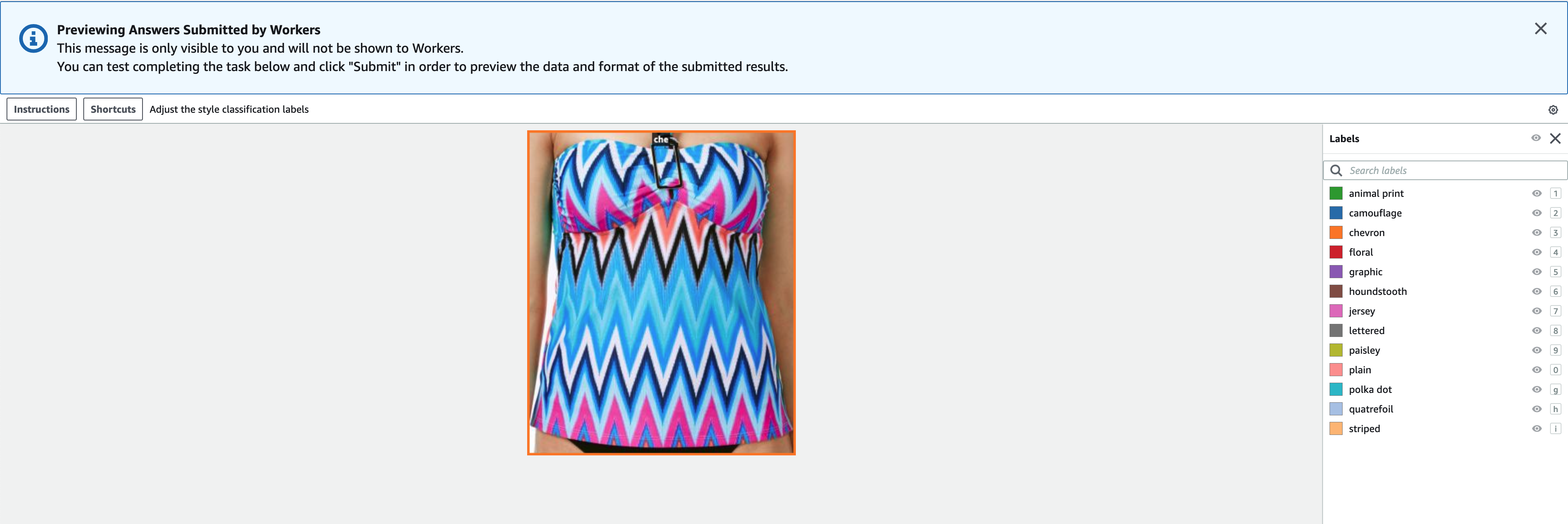
- را انتخاب کنید پیش نمایش برای پیش نمایش تصویر و حاشیه نویسی اصلی.
ما اکنون یک کار برچسب زدن در Ground Truth ایجاد کرده ایم. پس از اتمام کار، میتوانیم دادههای برچسبگذاری شده جدید تولید شده را در FiftyOne بارگذاری کنیم. Ground Truth داده های خروجی را در مانیفست خروجی Ground Truth تولید می کند. برای جزئیات بیشتر در مورد فایل مانیفست خروجی، نگاه کنید خروجی کار جعبه محدود. کد زیر نمونه ای از این فرمت مانیفست خروجی را نشان می دهد:
نتایج برچسبگذاری شده از Ground Truth در FiftyOne را مرور کنید
پس از اتمام کار، مانیفست خروجی کار برچسب زدن را از آمازون S3 دانلود کنید.
فایل مانیفست خروجی را بخوانید:
یک مجموعه داده FiftyOne ایجاد کنید و خطوط مانیفست را به نمونه در مجموعه داده تبدیل کنید:
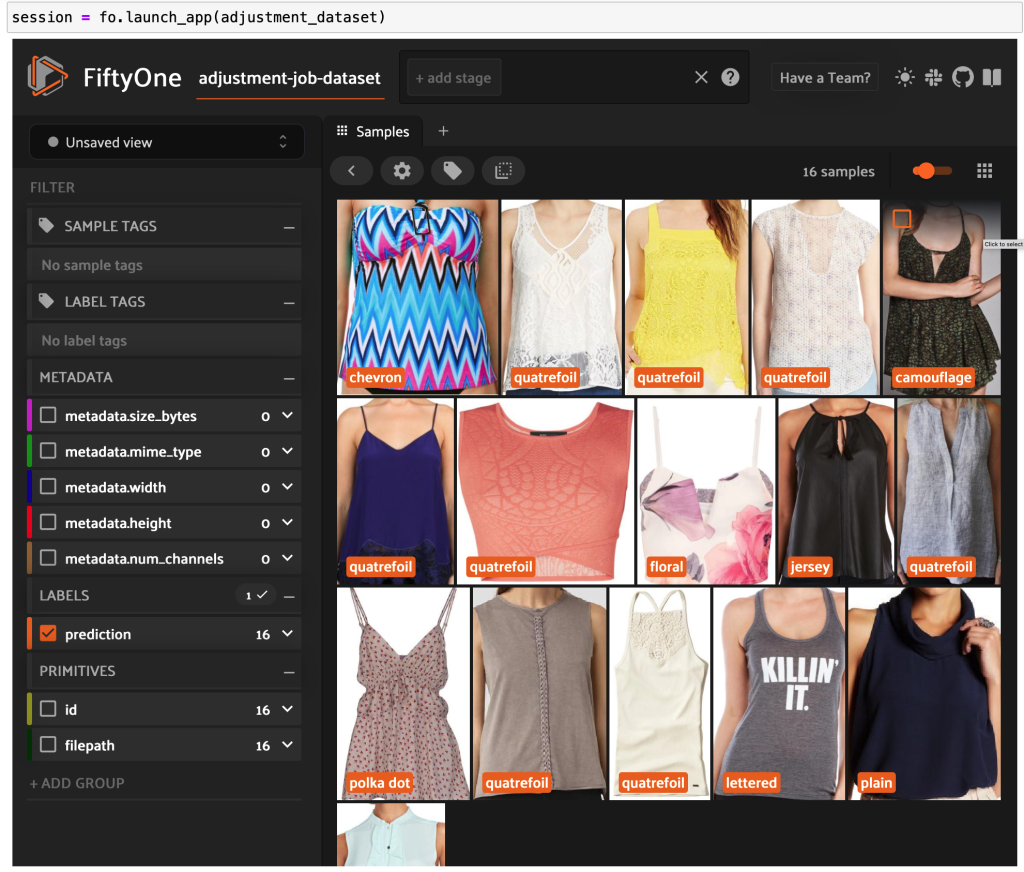
اکنون میتوانید دادههای برچسبگذاری شده با کیفیت بالا را از Ground Truth در FiftyOne ببینید.
نتیجه
در این پست، نحوه ساخت مجموعه داده های با کیفیت بالا را با ترکیب قدرت نشان دادیم پنجاه و یک by وکسل 51، یک جعبه ابزار منبع باز که به شما امکان می دهد مجموعه داده خود را مدیریت، ردیابی، تجسم و مدیریت کنید، و Ground Truth، یک سرویس برچسب گذاری داده که به شما امکان می دهد به طور موثر و دقیق مجموعه داده های مورد نیاز برای آموزش سیستم های ML را با دسترسی به چندین ساخته شده برچسب گذاری کنید. قالبهای کار و دسترسی به نیروی کار متنوع از طریق Mechanical Turk، فروشندگان شخص ثالث یا نیروی کار خصوصی خودتان.
ما شما را تشویق می کنیم که با نصب یک نمونه FiftyOne و استفاده از کنسول Ground Truth برای شروع، این عملکرد جدید را امتحان کنید. برای کسب اطلاعات بیشتر در مورد حقیقت زمین، مراجعه کنید داده های برچسب, پرسشهای متداول برچسبگذاری دادههای Amazon SageMaker، و وبلاگ یادگیری ماشین AWS.
با جامعه یادگیری ماشین و هوش مصنوعی اگر سوال یا بازخوردی دارید!
به انجمن FiftyOne بپیوندید!
به هزاران مهندس و دانشمند داده بپیوندید که در حال حاضر از FiftyOne برای حل برخی از چالش برانگیزترین مشکلات در بینایی کامپیوتر امروز استفاده می کنند!
درباره نویسنده
شالندرا چابرا در حال حاضر رئیس مدیریت محصول برای Amazon SageMaker Human-in-the-Loop (HIL) خدمات است. پیش از این، شالندر انکوباتور و رهبری هوش زبان و مکالمه برای جلسات تیم های مایکروسافت، EIR در شتاب دهنده راه اندازی آمازون الکسا Techstars، معاون محصول و بازاریابی در آمازون بود. Discuss.io، رئیس محصول و بازاریابی در کلیپ بورد (که توسط Salesforce خریداری شده است) و مدیر محصول اصلی در Swype (خرید شده توسط Nuance). در مجموع، شالندرا به ساخت، ارسال و عرضه محصولاتی کمک کرده است که جان بیش از یک میلیارد را تحت تأثیر قرار داده است.
جیکوب مارکس یک مهندس یادگیری ماشین و مبشر توسعه دهنده در Voxel51 است، جایی که به شفافیت و وضوح داده های جهان کمک می کند. قبل از پیوستن به Voxel51، جیکوب یک استارتاپ را تاسیس کرد تا به نوازندگان نوظهور کمک کند تا محتوای خلاقانه خود را با طرفداران ارتباط برقرار کنند و به اشتراک بگذارند. او قبل از آن در گوگل ایکس، سامسونگ ریسرچ و ولفرام ریسرچ کار می کرد. در زندگی گذشته، جیکوب یک فیزیکدان نظری بود و دکترای خود را در استنفورد تکمیل کرد، جایی که مراحل کوانتومی ماده را بررسی کرد. جیکوب در اوقات فراغت خود از کوهنوردی، دویدن و خواندن رمان های علمی تخیلی لذت می برد.
جیسون کورسو یکی از بنیانگذاران و مدیرعامل Voxel51 است، جایی که او استراتژی را برای کمک به شفافیت و وضوح داده های جهان از طریق پیشرفته ترین نرم افزارهای انعطاف پذیر هدایت می کند. او همچنین استاد رباتیک، مهندسی برق، و علوم کامپیوتر در دانشگاه میشیگان است، جایی که او بر روی مشکلات پیشرفته در تقاطع بینایی کامپیوتر، زبان طبیعی و پلتفرمهای فیزیکی تمرکز دارد. جیسون در اوقات فراغت خود از گذراندن وقت با خانواده، مطالعه، حضور در طبیعت، بازی های رومیزی و انواع فعالیت های خلاقانه لذت می برد.
برایان مور یکی از بنیانگذاران و CTO Voxel51 است، جایی که او استراتژی و چشم انداز فنی را رهبری می کند. او دارای مدرک دکترای مهندسی برق از دانشگاه میشیگان است، جایی که تحقیقات او بر روی الگوریتمهای کارآمد برای مشکلات یادگیری ماشین در مقیاس بزرگ، با تأکید ویژه بر برنامههای بینایی رایانه متمرکز بود. او در اوقات فراغت خود از بدمینتون، گلف، پیادهروی و بازی با دوقلوی یورکشایر تریر لذت میبرد.
ژولینگ بای مهندس توسعه نرم افزار در خدمات وب آمازون است. او روی توسعه سیستم های توزیع شده در مقیاس بزرگ برای حل مشکلات یادگیری ماشین کار می کند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoAiStream. Web3 Data Intelligence دانش تقویت شده دسترسی به اینجا.
- ضرب کردن آینده با آدرین اشلی. دسترسی به اینجا.
- خرید و فروش سهام در شرکت های PRE-IPO با PREIPO®. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- درباره ما
- شتاب دادن
- تسریع
- شتاب دهنده
- دسترسی
- دقیق
- به درستی
- به دست آورد
- فعالیت ها
- اضافه کردن
- اضافه کردن
- نشانی
- تنظیم شده
- تنظیم
- پس از
- از نو
- AI
- چک
- الگوریتم
- معرفی
- اجازه می دهد تا
- تنها
- قبلا
- همچنین
- آمازون
- آمازون الکسا
- آمازون SageMaker
- Amazon SageMaker Ground Truth
- آمازون خدمات وب
- در میان
- an
- تحلیل
- و
- حیوان
- هر
- نرم افزار
- کاربرد
- برنامه های کاربردی
- درخواست
- مناسب
- هستند
- مرتب شده اند
- مقاله
- مقالات
- AS
- مرتبط است
- At
- نویسندگان
- دور
- AWS
- پایه
- مستقر
- BE
- زیرا
- شدن
- بوده
- قبل از
- پشت سر
- پشت صحنه
- بودن
- باور
- بهترین
- بهتر
- میان
- بیلیون
- تخته
- بازی ها و بنگاه
- استخوان
- خود راه انداز
- هر دو
- جعبه
- جعبه
- مغز
- شکستن
- به ارمغان بیاورد
- آورده
- بودجه
- ساختن
- بنا
- ساخته شده در
- اما
- خرید
- by
- CAN
- ضبط
- مورد
- موارد
- دسته
- دسته بندی
- مدیر عامل شرکت
- به چالش
- به چالش کشیدن
- بررسی
- را انتخاب کنید
- وضوح
- کلاس
- کلاس ها
- طبقه بندی
- تمیز کاری
- واضح
- به وضوح
- مشتری
- بالا رونده
- نزدیک
- نزدیک
- لباس ها
- تن پوش
- بنیانگذاران
- رمز
- ترکیب
- ترکیب
- شرکت
- متمم
- کامل
- تکمیل
- محاسبه
- کامپیوتر
- علم کامپیوتر
- چشم انداز کامپیوتر
- برنامه های کاربردی بینایی کامپیوتر
- اعتماد به نفس
- مطمئن
- اتصال
- توجه
- شامل
- کنسول
- شامل
- محتوا
- محتویات
- کنترل
- محاورهای
- تبدیل
- نسخه
- هسته
- اصلاح شده
- مطابقت دارد
- هزینه
- هزینه
- ایجاد
- ایجاد شده
- خالق
- مجوزها و اعتبارات
- CTO
- سرپرستی
- درمان
- در حال حاضر
- سفارشی
- مشتری
- مشتریان
- برش
- لبه برش
- داده ها
- مجموعه داده ها
- تصمیم گیری
- نشان دادن
- جین
- عمق
- شرح
- جزئیات
- کشف
- توسعه دهنده
- در حال توسعه
- پروژه
- مختلف
- مستقیما
- دایرکتوری
- نمایش دادن
- متمایز
- توزیع شده
- سیستم های توزیع شده
- مختلف
- do
- نمی کند
- سگ
- عمل
- انجام شده
- آیا
- DOT
- پایین
- دانلود
- نسخه های تکراری
- e
- هر
- ساده
- لبه
- اثر
- موثر
- موثر
- مهندسی برق
- تعبیه کردن
- سنگ سنباده
- تاکید
- کار می کند
- توانمندسازی
- بسته بندی شده
- تشویق
- پایان
- مهندس
- مهندسی
- مورد تأیید
- وارد
- محیط
- برابری
- ضروری است
- تاسیس
- اتر (ETH)
- ارزیابی
- رسوایی
- کاملا
- مثال
- موجود
- صادرات
- منصفانه
- خانواده
- طرفداران
- باز خورد
- کمی از
- داستان
- رشته
- زمینه
- پرونده
- فایل ها
- فیلتر
- فیلتر
- نهایی
- نام خانوادگی
- مناسب
- قابل انعطاف
- تمرکز
- متمرکز شده است
- تمرکز
- پیروی
- برای
- فرم
- قالب
- خوشبختانه
- تاسیس
- چهار
- رایگان
- از جانب
- کاملا
- قابلیت
- بازیها
- همه منظوره
- تولید می کنند
- تولید
- دریافت کنید
- GitHub
- دادن
- داده
- هدف
- گلف
- خوب
- گوگل
- بیشتر
- توری
- زمین
- گروه
- راهنمایی
- خوشحال
- آیا
- he
- سر
- ارتفاع
- کمک
- کمک کرد
- مفید
- کمک می کند
- اینجا کلیک نمایید
- با کیفیت بالا
- کیفیت بالا
- بالاترین
- خیلی
- پیاده روی
- خود را
- دارای
- چگونه
- چگونه
- اما
- HTML
- HTTP
- HTTPS
- انسان
- i
- IAM
- ID
- شناسایی
- شناسایی
- شناسه
- if
- تصویر
- تصاویر
- تأثیر
- واردات
- بهبود
- in
- در دیگر
- از جمله
- نادرست
- جوجه کشی شده است
- اطلاعات
- اول
- در ابتدا
- نصب
- نصب کردن
- نمونه
- در عوض
- دستورالعمل
- اطلاعات
- تقاطع
- به
- IT
- ITS
- پارچه کشباف
- کار
- پیوستن
- مشترک
- json
- تنها
- نگاه داشتن
- نگهداری
- برچسب
- برچسب
- برچسب ها
- زبان
- در مقیاس بزرگ
- راه اندازی
- راه اندازی
- رهبری
- منجر می شود
- یاد گرفتن
- یادگیری
- کمترین
- رهبری
- ترک کرد
- اجازه می دهد تا
- کتابخانه
- زندگی
- پسندیدن
- احتمالا
- محدود
- محدود شده
- لاین
- خطوط
- فهرست
- فهرست
- لیست
- کوچک
- زندگی
- بار
- نگاه کنيد
- به دنبال
- خیلی
- کم
- دستگاه
- فراگیری ماشین
- ساخته
- شعبده بازي
- ساخت
- باعث می شود
- مدیریت
- اداره می شود
- مدیریت
- مدیر
- بسیاری
- نقشه
- بازار
- بازار یابی (Marketing)
- مسابقه
- مطابق
- از نظر مادی
- ماده
- ممکن است..
- مکانیکی
- رسانه ها
- جلسات
- متا
- متاداده
- روش
- روش
- میشیگان
- مایکروسافت
- تیم های میکروسافت
- قدرت
- حد اقل
- ML
- موبایل
- برنامه موبایل
- مدل
- مدل
- ماژول ها
- بیش
- اکثر
- حرکت
- بسیار
- چندگانه
- نوازندگان
- باید
- نام
- تحت عنوان
- نام
- طبیعی
- زبان طبیعی
- طبیعت
- نزدیک
- لزوما
- لازم
- نیاز
- نیازهای
- جدید
- قابل ملاحظه ای
- ایده
- اکنون
- نیسان
- عدد
- هدف
- تشخیص شی
- اشیاء
- of
- رسمی
- on
- یک بار
- ONE
- آنلاین
- فقط
- باز کن
- منبع باز
- عملیات
- فرصت
- گزینه
- or
- سازمان یافته
- اصلی
- OS
- دیگر
- دیگران
- ما
- خارج
- مشخص شده
- تولید
- روی
- خود
- مالک است
- بسته
- زوج
- بخش
- ویژه
- گذشته
- مسیر
- الگو
- الگوهای
- کامل
- کارایی
- شخص
- شخصی
- مراحل ماده
- فیزیکی
- انتخاب کنید
- تصاویر
- پلاید
- ساده
- سیستم عامل
- افلاطون
- هوش داده افلاطون
- PlatoData
- بازی
- نقطه
- پر جمعیت
- ممکن
- پست
- قدرت
- تمرین
- پیش بینی
- پیش گویی
- پیش بینی
- پیش نمایش
- قبلی
- قبلا
- چاپ
- قبلا
- خصوصی
- شاید
- مشکلات
- روند
- محصول
- مدیریت تولید
- مدیر تولید
- محصولات
- معلم
- پروژه
- ویژگی
- آینده نگر
- نمونه اولیه
- ارائه
- ارائه
- ارائه
- عمومی
- مشت
- اهداف
- پــایتــون
- کوانتومی
- سوالات
- به سرعت
- محدوده
- نسبتا
- مطالعه
- اماده
- توصیه
- توصیه
- كاهش دادن
- کاهش
- کاهش
- نسبتا
- منتشر شد
- مربوط
- برداشتن
- نماینده
- نمایندگی
- ضروری
- تحقیق
- محققان
- وضوح
- محدود کردن
- نتیجه
- نتیجه
- نتایج
- خرده فروشی
- برگشت
- این فایل نقد می نویسید:
- خلاص شدن از شر
- رباتیک
- تنومند
- نقش
- تقریبا
- ROW
- خراب کردن
- در حال اجرا
- حکیم ساز
- سعید
- salesforce
- همان
- سامسونگ
- ذخیره
- صحنه های
- علم
- داستان تخیلی علمی
- دانشمندان
- نمره
- یکپارچه
- دوم
- بخش
- بخش
- دیدن
- به نظر می رسد
- به نظر می رسد
- انتخاب شد
- حس
- جداگانه
- سرویس
- خدمات
- جلسه
- تنظیم
- اشتراک گذاری
- او
- باید
- نشان
- نشان می دهد
- سیم کارت
- مشابه
- ساده
- کوچکتر
- So
- نرم افزار
- توسعه نرم افزار
- حل
- برخی از
- کسی
- چیزی
- فضا
- خرج کردن
- هزینه
- انشعاب
- تقسیم می کند
- استنفورد
- شروع
- آغاز شده
- راه افتادن
- شروع
- شتاب دهنده راه اندازی
- وضعیت هنر
- مراحل
- هنوز
- ذخیره سازی
- opbevare
- استراتژی
- سبک
- سبک
- خلاصه
- پشتیبانی
- سیستم های
- گرفتن
- کار
- تیم ها
- فنی
- techstars
- می گوید
- قالب
- آزمون
- نسبت به
- که
- La
- شان
- آنها
- سپس
- نظری
- آنجا.
- اینها
- آنها
- اشیاء
- فکر می کنم
- شخص ثالث
- این
- هزاران نفر
- آستانه
- از طریق
- پرتاب
- زمان
- به
- با هم
- ابزار
- ابزار
- بالا
- سطح عالی
- تاپس
- جمع
- لمس کرد
- مسیر
- قطار
- آموزش دیده
- آموزش
- دگرگون کردن
- شفافیت
- درست
- حقیقت
- دور زدن
- دو
- نوع
- انواع
- زیر
- فهمیدن
- منحصر به فرد
- دانشگاه
- دانشگاه میشیگان
- بروزرسانی
- us
- استفاده کنید
- مورد استفاده
- استفاده
- کاربر
- کاربران
- با استفاده از
- ارزشها
- تنوع
- مختلف
- فروشندگان
- بررسی
- بسیار
- از طريق
- چشم انداز
- مجازی
- دید
- می خواهم
- بود
- we
- وب
- خدمات وب
- خوب
- بود
- چی
- چه زمانی
- چه
- که
- ویکیپدیا
- اراده
- با
- در داخل
- بدون
- زنان
- کلمات
- مهاجرت کاری
- مشغول به کار
- کارگران
- نیروی کار
- با این نسخهها کار
- جهان
- نگرانی
- خواهد بود
- نوشتن
- X
- شما
- شما
- زفیرنت
- زیپ
- ZOO