تصویر توسط نویسنده
غواصی در دنیای علم داده و یادگیری ماشین، یکی از مهارت های اساسی که با آن مواجه خواهید شد، هنر خواندن داده ها است. اگر قبلاً تجربه ای با آن دارید، احتمالاً با JSON (نشانگذاری شی جاوا اسکریپت) آشنا هستید - یک فرمت محبوب برای ذخیره و تبادل داده ها.
به این فکر کنید که چگونه پایگاههای اطلاعاتی NoSQL مانند MongoDB عاشق ذخیره دادهها در JSON هستند، یا اینکه چگونه APIهای REST اغلب در قالب یکسان پاسخ میدهند.
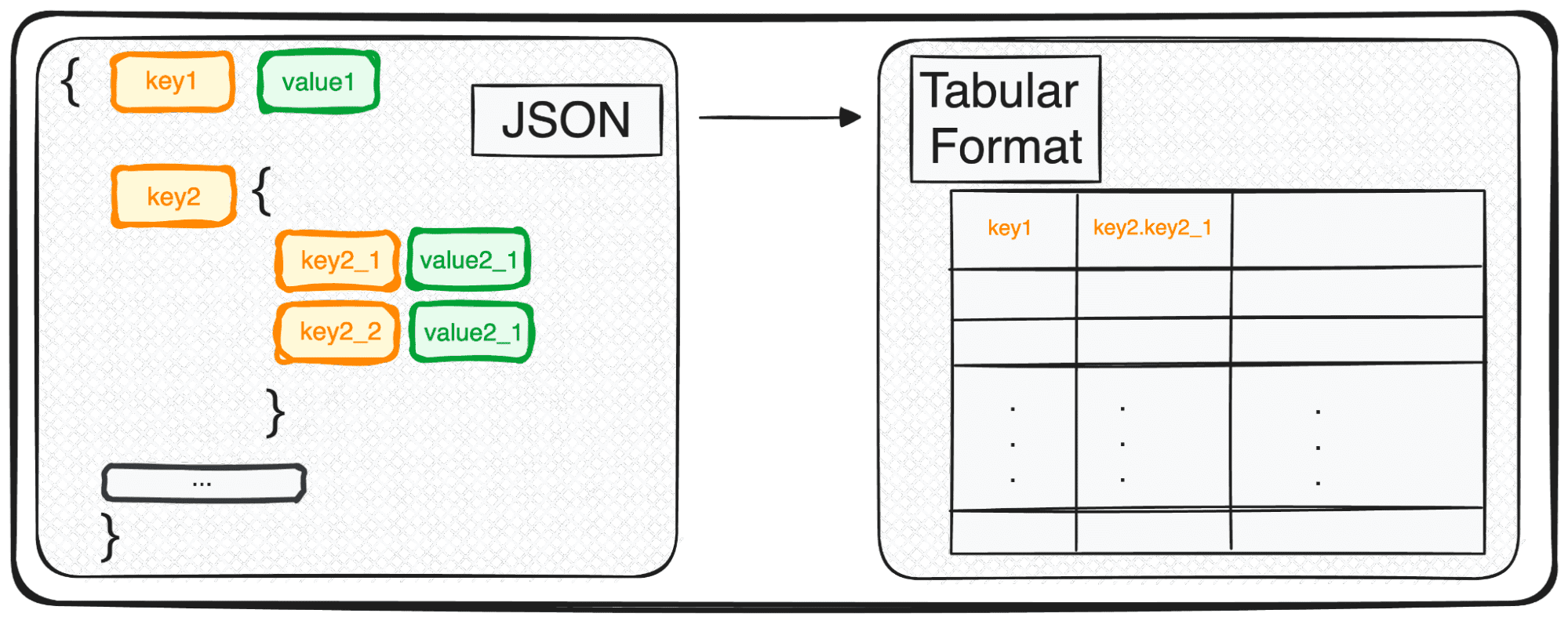
با این حال، JSON، اگرچه برای ذخیره سازی و تبادل عالی است، اما برای تجزیه و تحلیل عمیق در شکل خام خود کاملاً آماده نیست. اینجاست که ما آن را به چیزی تحلیلی تر تبدیل می کنیم - یک قالب جدولی.
بنابراین، چه با یک شی JSON یا یک آرایه لذت بخش از آنها سر و کار داشته باشید، به تعبیر پایتون، اساساً یک دیکت یا لیستی از دیکت ها را مدیریت می کنید.
بیایید با هم بررسی کنیم که چگونه این تحول آشکار می شود و داده های ما را برای تجزیه و تحلیل آماده می کند ????
امروز یک دستور جادویی را توضیح خواهم داد که به ما امکان می دهد به راحتی هر JSON را در قالب یک جدول در چند ثانیه تجزیه کنیم.
و … PD است.json_normalize()
بنابراین بیایید ببینیم که چگونه با انواع مختلف JSON کار می کند.
اولین نوع JSON که می توانیم با آن کار کنیم JSON های تک سطحی با چند کلید و مقدار هستند. ما اولین JSON های ساده خود را به صورت زیر تعریف می کنیم:
کد توسط نویسنده
بنابراین بیایید نیاز به کار با این JSON را شبیه سازی کنیم. همه ما می دانیم که در قالب JSON آنها کار زیادی برای انجام دادن وجود ندارد. ما باید این JSON ها را به فرمت های قابل خواندن و قابل تغییر تبدیل کنیم ... که به معنی Pandas DataFrames است!
1.1 برخورد با ساختارهای ساده JSON
ابتدا باید کتابخانه pandas را وارد کنیم و سپس می توانیم از دستور pd.json_normalize() به صورت زیر استفاده کنیم:
import pandas as pd
pd.json_normalize(json_string)
با اعمال این دستور بر روی یک JSON با یک رکورد، ابتدایی ترین جدول را بدست می آوریم. با این حال، وقتی دادههای ما کمی پیچیدهتر هستند و فهرستی از JSONها را ارائه میدهند، همچنان میتوانیم از همان دستور بدون هیچ گونه پیچیدگی استفاده کنیم و خروجی با جدولی با چندین رکورد مطابقت دارد.

تصویر توسط نویسنده
آسان… درست است؟
سوال طبیعی بعدی این است که وقتی برخی از مقادیر از دست رفته اند چه اتفاقی می افتد.
1.2 برخورد با مقادیر تهی
تصور کنید برخی از ارزشها اطلاعرسانی نشدهاند، برای مثال، رکورد درآمد برای دیوید وجود ندارد. هنگامی که JSON خود را به یک دیتافریم ساده پاندا تبدیل می کنیم، مقدار مربوطه به صورت NaN ظاهر می شود.
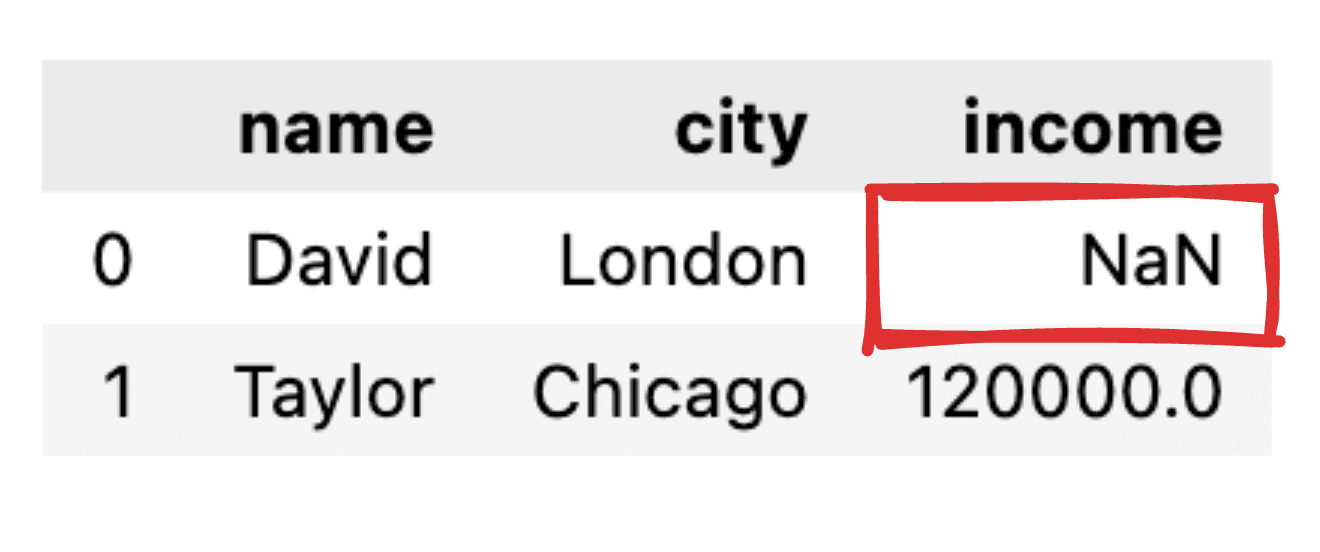
تصویر توسط نویسنده
و اگر من فقط بخواهم برخی از فیلدها را بدست بیاورم چطور؟
1.3 فقط آن ستون های مورد علاقه را انتخاب کنید
در صورتی که بخواهیم برخی از فیلدهای خاص را به DataFrame پانداهای جدولی تبدیل کنیم، دستور json_normalize () به ما اجازه نمی دهد که کدام فیلدها را تبدیل کنیم.
بنابراین، یک پیش پردازش کوچک از JSON باید در جایی انجام شود که فقط آن ستون های مورد علاقه را فیلتر کنیم.
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
بنابراین، اجازه دهید به ساختار پیشرفتهتر JSON برویم.
هنگامی که با JSON های چند سطحی سروکار داریم، خود را با JSON های تودرتو در سطوح مختلف می یابیم. روال مانند قبل است، اما در این مورد، ما می توانیم انتخاب کنیم که چند سطح را می خواهیم تغییر دهیم. بهطور پیشفرض، این دستور همیشه همه سطوح را گسترش میدهد و ستونهای جدیدی حاوی نام به هم پیوسته همه سطوح تودرتو ایجاد میکند.
بنابراین اگر JSON های زیر را عادی کنیم.
کد توسط نویسنده
جدول زیر را با 3 ستون در زیر مهارت های فیلد دریافت می کنیم:
- skills.python
- مهارت ها.SQL
- مهارت ها.GCP
و 4 ستون در زیر نقش های فیلد
- نقش ها.مدیر پروژه
- نقش ها.مهندس داده
- نقش ها.دانشمند داده
- نقش ها.تحلیلگر داده

تصویر توسط نویسنده
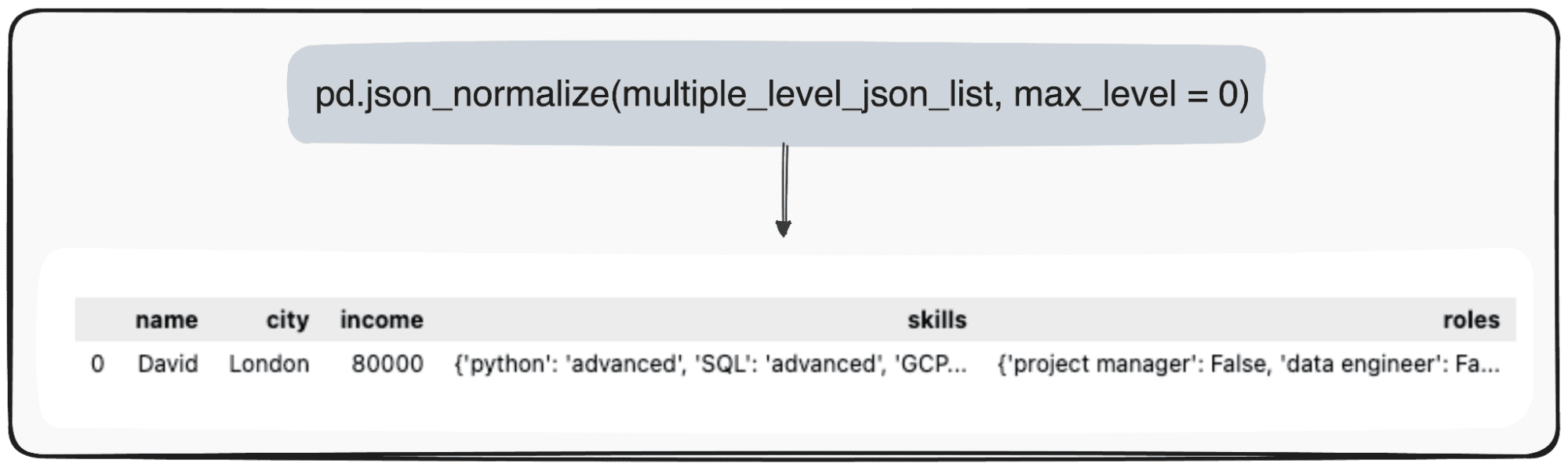
با این حال، تصور کنید ما فقط می خواهیم سطح بالای خود را تغییر دهیم. ما می توانیم این کار را با تعریف پارامتر max_level به 0 انجام دهیم (max_level که می خواهیم گسترش دهیم).
pd.json_normalize(mutliple_level_json_list, max_level = 0)
مقادیر معلق در JSONها در DataFrame پانداهای ما حفظ می شوند.
تصویر توسط نویسنده
آخرین موردی که می توانیم پیدا کنیم داشتن یک لیست تودرتو در یک فیلد JSON است. بنابراین ابتدا JSON های خود را برای استفاده تعریف می کنیم.
کد توسط نویسنده
ما می توانیم به طور موثر این داده ها را با استفاده از پانداها در پایتون مدیریت کنیم. تابع pd.json_normalize() به ویژه در این زمینه مفید است. میتواند دادههای JSON، از جمله فهرست تودرتو، را در قالبی ساختاریافته مناسب برای تجزیه و تحلیل صاف کند. وقتی این تابع روی دادههای JSON ما اعمال میشود، یک جدول نرمالسازی شده تولید میکند که لیست تودرتو را به عنوان بخشی از فیلدهای خود در خود جای میدهد.
علاوه بر این، پانداها توانایی اصلاح بیشتر این فرآیند را ارائه می دهند. با استفاده از پارامتر record_path در pd.json_normalize()، میتوانیم تابع را به سمت عادی سازی لیست تودرتو هدایت کنیم.
این عمل منجر به یک جدول اختصاصی منحصراً برای محتویات لیست می شود. به طور پیش فرض، این فرآیند فقط عناصر موجود در لیست را باز می کند. با این حال، برای غنی سازی این جدول با زمینه اضافی، مانند حفظ یک شناسه مرتبط برای هر رکورد، می توانیم از پارامتر متا استفاده کنیم.

تصویر توسط نویسنده
به طور خلاصه، تبدیل داده های JSON به فایل های CSV با استفاده از کتابخانه Pandas پایتون آسان و موثر است.
JSON هنوز رایج ترین فرمت در ذخیره سازی و تبادل داده های مدرن است، به ویژه در پایگاه های داده NoSQL و API های REST. با این حال، در هنگام برخورد با داده ها در قالب خام، چالش های تحلیلی مهمی را ارائه می دهد.
نقش محوری ()pd.json_normalize Pandas به عنوان یک راه عالی برای مدیریت چنین فرمتهایی و تبدیل دادههای ما به DataFrame پاندا ظاهر میشود.
امیدوارم این راهنما مفید بوده باشد و دفعه بعد که با JSON سروکار دارید، می توانید آن را به روشی موثرتر انجام دهید.
می توانید نوت بوک Jupyter مربوطه را در قسمت بررسی کنید زیر انبار GitHub.
جوزپ فرر یک مهندس تجزیه و تحلیل از بارسلونا است. او در رشته مهندسی فیزیک فارغ التحصیل شد و در حال حاضر در زمینه علم داده های کاربردی برای تحرک انسان کار می کند. او یک تولید کننده محتوای پاره وقت است که بر علم و فناوری داده تمرکز دارد. می توانید با او تماس بگیرید لینک, توییتر or متوسط.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way
- :است
- :نه
- :جایی که
- 1
- 1.3
- 11
- 2%
- 4
- 7
- 8
- a
- درباره ما
- عمل
- اضافی
- پیشرفته
- معرفی
- اجازه دادن
- اجازه می دهد تا
- قبلا
- همیشه
- an
- تحلیل
- روانکاو
- تحلیلی
- علم تجزیه و تحلیل
- و
- هر
- رابط های برنامه کاربردی
- ظاهر شدن
- اعمال می شود
- با استفاده از
- هستند
- صف
- هنر
- AS
- مرتبط است
- بارسلونا
- اساسی
- BE
- قبل از
- بیت
- هر دو
- اما
- by
- CAN
- قابلیت
- مورد
- چالش ها
- بررسی
- را انتخاب کنید
- شهر:
- ستون ها
- مشترک
- پیچیده
- عوارض
- تماس
- محتوا
- محتویات
- زمینه
- تبدیل
- تبدیل
- مطابق بودن
- متناظر
- خالق
- در حال حاضر
- داده ها
- تحلیلگر داده
- مهندس داده
- علم اطلاعات
- دانشمند داده
- ذخیره سازی داده ها
- پایگاه های داده
- داود
- معامله
- اختصاصی
- به طور پیش فرض
- تعريف كردن
- تعریف کردن
- لذت بخش
- DICT
- مختلف
- مستقیم
- do
- میکند
- هر
- به آسانی
- ساده
- موثر
- به طور موثر
- عناصر
- ظهور می کند
- رویارویی
- مهندس
- مهندسی
- غنی سازی
- اساسا
- تبادل
- مبادله
- منحصرا
- گسترش
- تجربه
- توضیح دادن
- اکتشاف
- آشنا
- کمی از
- رشته
- زمینه
- فایل ها
- فیلتر
- پیدا کردن
- نام خانوادگی
- متمرکز شده است
- پیروی
- به دنبال آن است
- برای
- فرم
- قالب
- دوستانه
- از جانب
- تابع
- اساسی
- بیشتر
- GCP
- تولید می کنند
- دریافت کنید
- GitHub
- Go
- بزرگ
- راهنمایی
- دسته
- اداره
- اتفاق می افتد
- آیا
- داشتن
- he
- او را
- امید
- چگونه
- اما
- HTTPS
- انسان
- i
- من می خواهم
- ID
- if
- تصور کنید
- واردات
- مهم
- in
- در عمق
- شامل
- از جمله
- درآمد
- شامل
- اطلاع
- نمونه
- علاقه
- به
- نیست
- IT
- ITS
- جاوا اسکریپت
- json
- نوت بوک ژوپیتر
- تنها
- kdnuggets
- کلید
- کلید
- دانستن
- نام
- یادگیری
- سطح
- سطح
- کتابخانه
- پسندیدن
- لینک
- فهرست
- کوچک
- ll
- عشق
- دستگاه
- فراگیری ماشین
- شعبده بازي
- حفظ
- ساخت
- مدیریت
- مدیر
- بسیاری
- به معنی
- متا
- گم
- تحرک
- مدرن
- MongoDB
- بیش
- اکثر
- حرکت
- بسیار
- چندگانه
- نام
- طبیعی
- نیاز
- تودرتو
- جدید
- بعد
- نه
- به ویژه
- دفتر یادداشت
- هدف
- گرفتن
- of
- پیشنهادات
- غالبا
- on
- ONE
- فقط
- or
- ما
- خودمان
- تولید
- پانداها
- پارامتر
- بخش
- ویژه
- انتظار
- کامل
- انجام
- فیزیک
- محوری
- افلاطون
- هوش داده افلاطون
- PlatoData
- محبوب
- هدیه
- شاید
- روش
- روند
- تولید می کند
- پروژه
- پــایتــون
- سوال
- کاملا
- خام
- RE
- مطالعه
- اماده
- رکورد
- سوابق
- خالص کردن
- پاسخ
- REST
- نتایج
- حفظ
- راست
- نقش
- s
- همان
- علم
- علم و تکنولوژی
- دانشمند
- ثانیه
- دیدن
- انتخاب
- باید
- ساده
- شبیه سازی
- تنها
- مهارت ها
- کوچک
- So
- برخی از
- چیزی
- خاص
- به طور خاص
- SQL
- هنوز
- ذخیره سازی
- opbevare
- ساختار
- ساخت یافته
- چنین
- مناسب
- خلاصه
- T
- جدول
- پیشرفته
- قوانین و مقررات
- که
- La
- جهان
- شان
- آنها
- سپس
- اینها
- این
- کسانی که
- زمان
- به
- با هم
- بالا
- دگرگون کردن
- دگرگونی
- تبدیل شدن
- نوع
- انواع
- زیر
- us
- استفاده کنید
- مفید
- با استفاده از
- با استفاده از
- ارزش
- ارزشها
- می خواهم
- بود
- مسیر..
- we
- چی
- چه زمانی
- چه
- که
- در حین
- اراده
- با
- در داخل
- مهاجرت کاری
- کارگر
- با این نسخهها کار
- جهان
- خواهد بود
- شما
- زفیرنت