در محیط کسبوکار مبتنی بر دادههای امروزی، سازمانها با چالش آمادهسازی کارآمد و تبدیل مقادیر زیادی از دادهها برای اهداف تحلیلی و علم داده مواجه هستند. کسب و کارها باید بر اساس داده های عملیاتی انبارهای داده و دریاچه های داده بسازند. این امر ناشی از نیاز به متمرکز کردن و یکپارچه سازی داده هایی است که از منابع متفاوت به دست می آیند.
در عین حال، داده های عملیاتی اغلب از برنامه های کاربردی پشتیبانی می شوند که توسط فروشگاه های داده قدیمی پشتیبانی می شوند. مدرن کردن برنامهها به یک معماری میکروسرویس نیاز دارد، که به نوبه خود یکپارچهسازی دادهها از منابع متعدد را برای ایجاد یک ذخیرهسازی داده عملیاتی ضروری میکند. بدون نوسازی، برنامه های کاربردی قدیمی ممکن است هزینه های تعمیر و نگهداری فزاینده ای را متحمل شوند. مدرن سازی برنامه ها شامل تغییر موتور پایگاه داده اساسی به پایگاه داده مبتنی بر سند مدرن مانند MongoDB است.
این دو وظیفه (ساخت دریاچه های داده یا انبارهای داده و نوسازی برنامه ها) شامل جابجایی داده است که از فرآیند استخراج، تبدیل و بارگذاری (ETL) استفاده می کند. شغل ETL یک عملکرد کلیدی برای داشتن یک فرآیند ساختاریافته به منظور موفقیت است.
چسب AWS یک سرویس یکپارچه سازی داده بدون سرور است که کشف، آماده سازی، انتقال و ادغام داده ها از منابع متعدد برای تجزیه و تحلیل، یادگیری ماشین (ML) و توسعه برنامه را آسان می کند. MongoDB اطلس مجموعه ای یکپارچه از پایگاه داده و سرویس های داده ابری است که پردازش تراکنش، جستجوی مبتنی بر ارتباط، تجزیه و تحلیل زمان واقعی و همگام سازی داده های موبایل به ابر را در یک معماری زیبا و یکپارچه ترکیب می کند.
با استفاده از چسب AWS با MongoDB Atlas، سازمان ها می توانند فرآیندهای ETL خود را ساده کنند. MongoDB Atlas با راه حل پایگاه داده کاملاً مدیریت شده، مقیاس پذیر و امن خود، یک محیط قابل انعطاف و قابل اعتماد برای ذخیره و مدیریت داده های عملیاتی فراهم می کند. AWS Glue ETL و MongoDB Atlas با هم راهحلی قدرتمند برای سازمانهایی هستند که به دنبال بهینهسازی نحوه ساخت دریاچههای داده و انبارهای داده و مدرنسازی برنامههای خود هستند تا عملکرد کسبوکار را بهبود بخشند، هزینهها را کاهش دهند و رشد و موفقیت را افزایش دهند.
در این پست نحوه انتقال داده ها را نشان می دهیم سرویس ذخیره سازی ساده آمازون (Amazon S3) به MongoDB Atlas با استفاده از AWS Glue ETL و نحوه استخراج داده ها از MongoDB Atlas به دریاچه داده مبتنی بر Amazon S3.
بررسی اجمالی راه حل
در این پست موارد استفاده زیر را بررسی می کنیم:
- استخراج داده ها از MongoDB – MongoDB یک پایگاه داده محبوب است که توسط هزاران مشتری برای ذخیره داده های برنامه در مقیاس استفاده می شود. مشتریان سازمانی می توانند داده های حاصل از چندین فروشگاه داده را با ساخت دریاچه های داده و انبارهای داده متمرکز و یکپارچه کنند. این فرآیند شامل استخراج داده ها از انبارهای داده عملیاتی است. وقتی داده ها در یک مکان هستند، مشتریان می توانند به سرعت از آن برای نیازهای هوش تجاری یا برای ML استفاده کنند.
- ورود داده به MongoDB – MongoDB همچنین به عنوان یک پایگاه داده بدون SQL برای ذخیره داده های برنامه کاربردی و ایجاد فروشگاه های داده عملیاتی عمل می کند. نوسازی برنامهها اغلب شامل مهاجرت فروشگاه عملیاتی به MongoDB است. مشتریان باید داده های موجود را از پایگاه داده های رابطه ای یا از فایل های مسطح استخراج کنند. برنامههای موبایل و وب اغلب به مهندسان داده نیاز دارند تا خطوط لوله داده را ایجاد کنند تا یک نمای واحد از دادهها در Atlas ایجاد کنند و در عین حال دادهها را از چندین منبع Siled دریافت کنند. در طول این مهاجرت، آنها باید برای ایجاد اسناد به پایگاه های داده مختلف بپیوندند. این عملیات اتصال پیچیده به توان محاسباتی قابل توجه و یکباره نیاز دارد. توسعه دهندگان همچنین باید این را سریع بسازند تا داده ها را انتقال دهند.
AWS Glue در این موارد با مدل پرداخت بهموقع و توانایی آن برای اجرای تحولات پیچیده در مجموعه دادههای عظیم مفید است. توسعه دهندگان می توانند از AWS Glue Studio برای ایجاد کارآمد چنین خطوط لوله داده استفاده کنند.
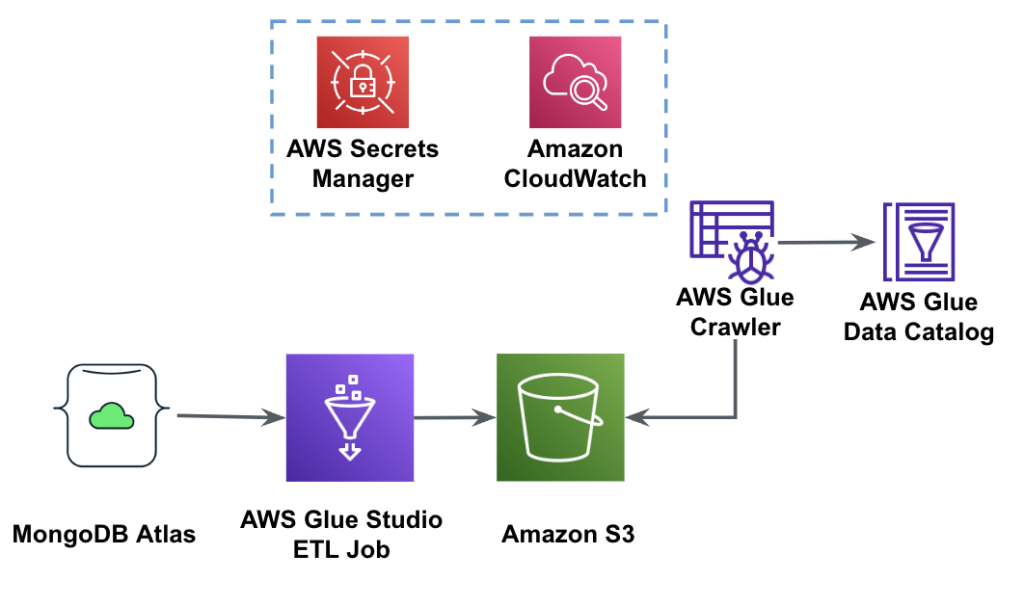
نمودار زیر گردش کار استخراج داده از MongoDB Atlas را در یک سطل S3 با استفاده از AWS Glue Studio نشان می دهد.
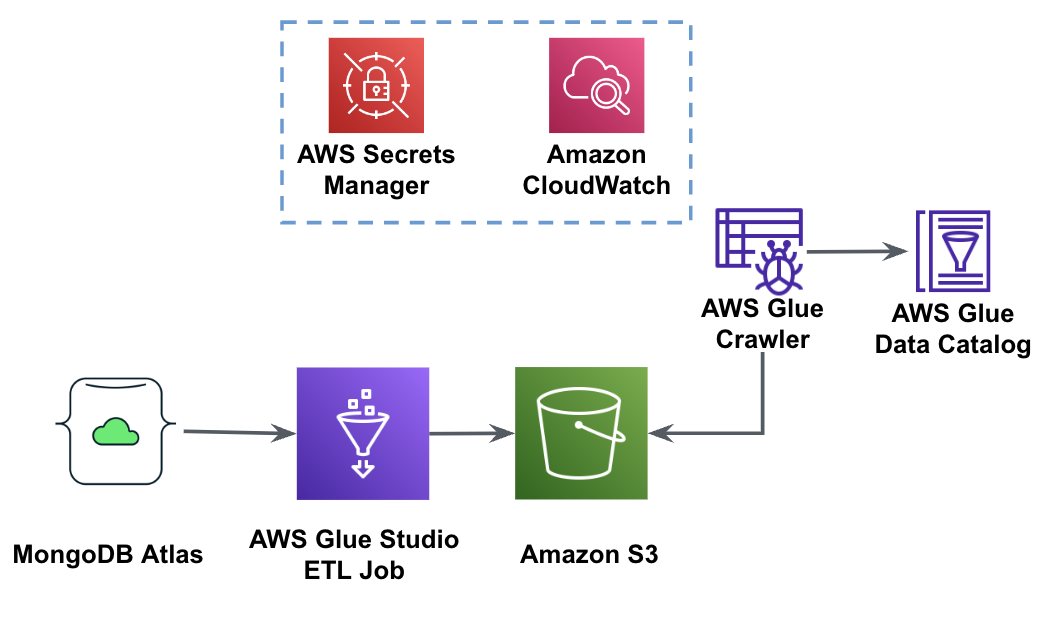
برای پیاده سازی این معماری، به یک خوشه MongoDB Atlas، یک سطل S3 و یک هویت AWS و مدیریت دسترسی نقش (IAM) برای چسب AWS. برای پیکربندی این منابع به مراحل پیش نیاز در ادامه مطلب مراجعه کنید GitHub repo.
شکل زیر گردش کار بارگذاری داده را از یک سطل S3 به MongoDB Atlas با استفاده از چسب AWS نشان میدهد.
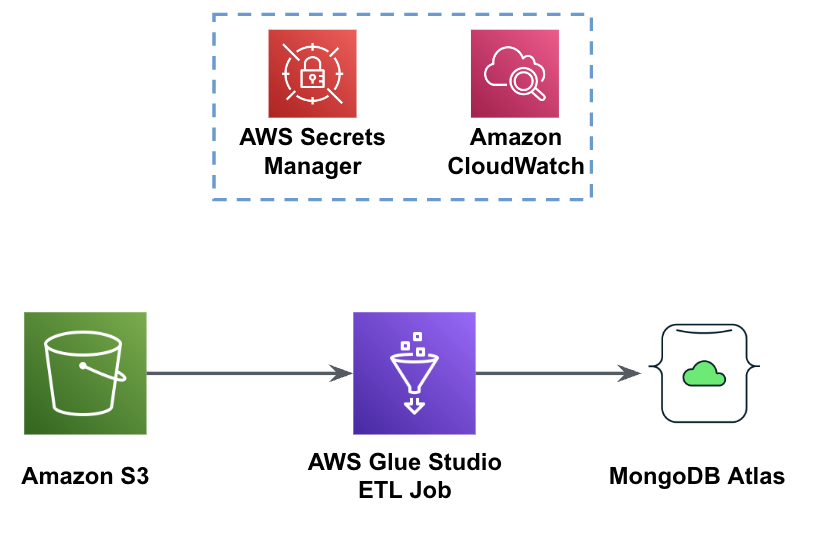
همین پیش نیازها در اینجا مورد نیاز است: یک سطل S3، نقش IAM و یک خوشه MongoDB Atlas.
با استفاده از چسب AWS داده ها را از Amazon S3 به MongoDB Atlas بارگیری کنید
مراحل زیر نحوه بارگیری داده ها از سطل S3 در MongoDB Atlas را با استفاده از یک کار چسب AWS توضیح می دهد. فرآیند استخراج از MongoDB Atlas به Amazon S3 بسیار شبیه است، به استثنای اسکریپت مورد استفاده. ما تفاوت های بین این دو فرآیند را بیان می کنیم.
- یک خوشه رایگان ایجاد کنید در MongoDB Atlas.
- بارگذاری کنید نمونه فایل JSON به سطل S3 شما.
- یک کار جدید AWS Glue Studio با ویرایشگر اسکریپت Spark گزینه.

- بسته به اینکه آیا می خواهید داده ها را از خوشه MongoDB Atlas بارگیری یا استخراج کنید، وارد کنید بارگذاری اسکریپت or استخراج اسکریپت در ویرایشگر اسکریپت AWS Glue Studio.
تصویر زیر یک قطعه کد برای بارگیری داده ها در خوشه MongoDB Atlas را نشان می دهد.

کد استفاده می کند مدیر اسرار AWS برای بازیابی نام، نام کاربری و رمز عبور خوشه MongoDB Atlas. سپس، یک را ایجاد می کند DynamicFrame برای سطل S3 و نام فایل به عنوان پارامتر به اسکریپت ارسال می شود. کد پایگاه داده و نام مجموعه را از پیکربندی پارامترهای شغلی بازیابی می کند. در نهایت، کد را می نویسد DynamicFrame به خوشه MongoDB Atlas با استفاده از پارامترهای بازیابی شده.
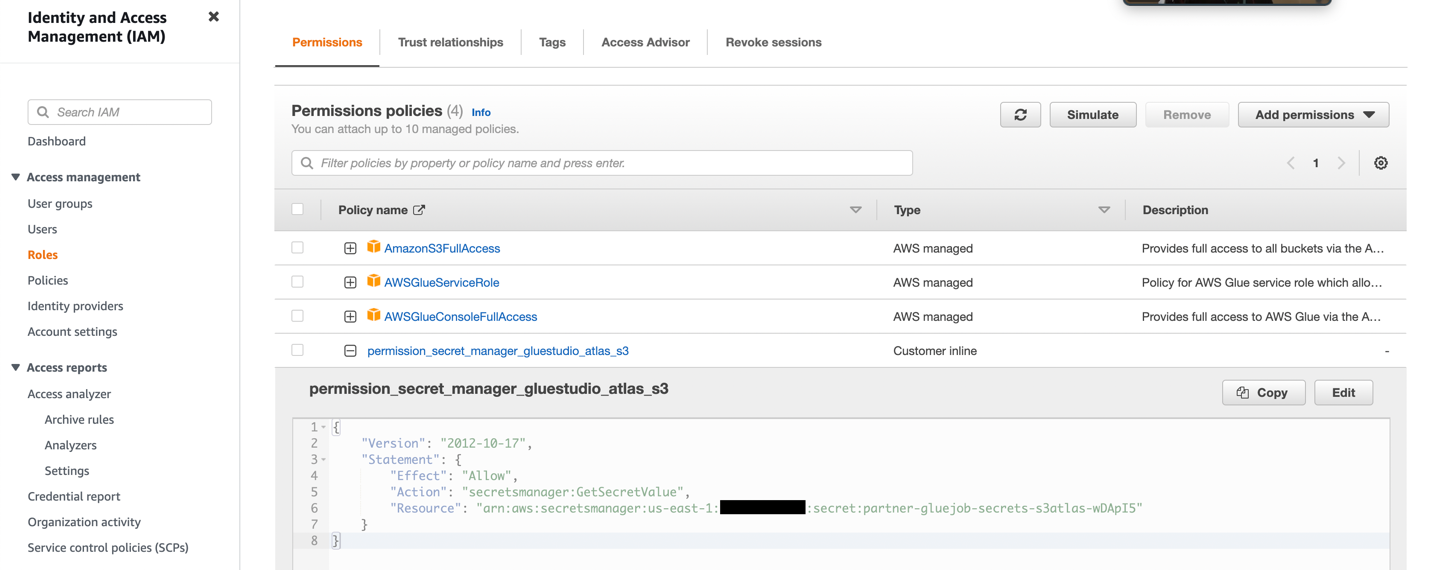
- یک نقش IAM با مجوزهایی که در تصویر زیر نشان داده شده است ایجاد کنید.
برای جزئیات بیشتر ، به مراجعه کنید یک نقش IAM را برای کار ETL خود پیکربندی کنید.
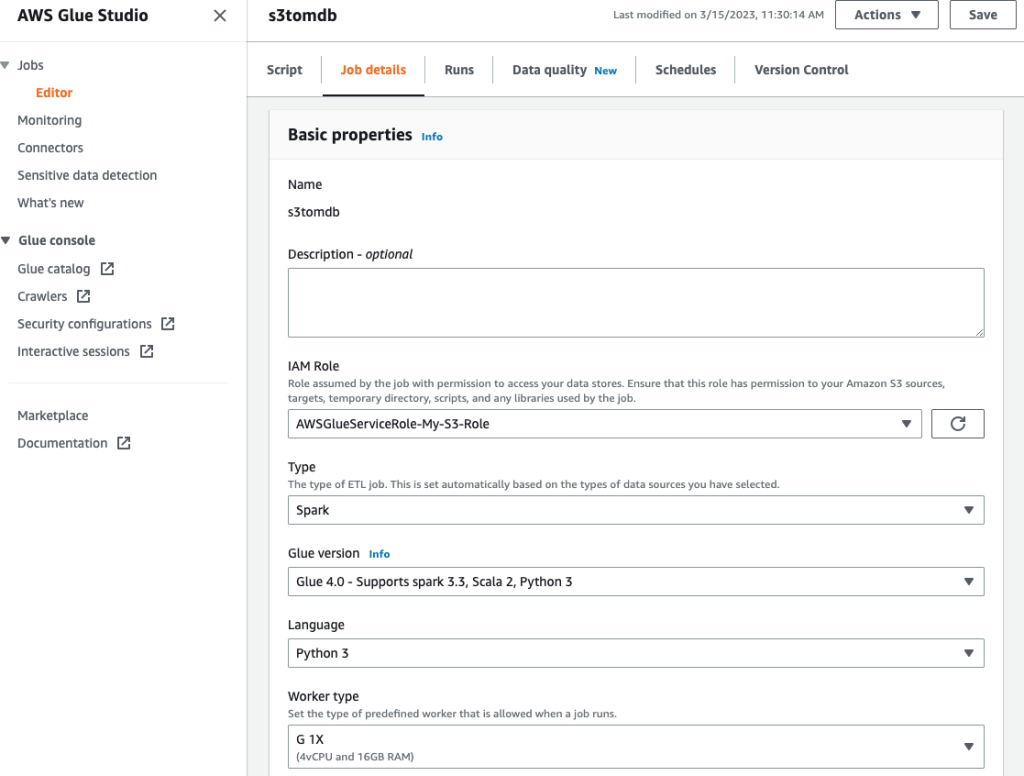
- نامی به کار بدهید و نقش IAM ایجاد شده در مرحله قبل را روی آن قرار دهید جزئیات شغل تب.
- همانطور که در تصاویر زیر نشان داده شده است، می توانید بقیه پارامترها را به عنوان پیش فرض بگذارید.
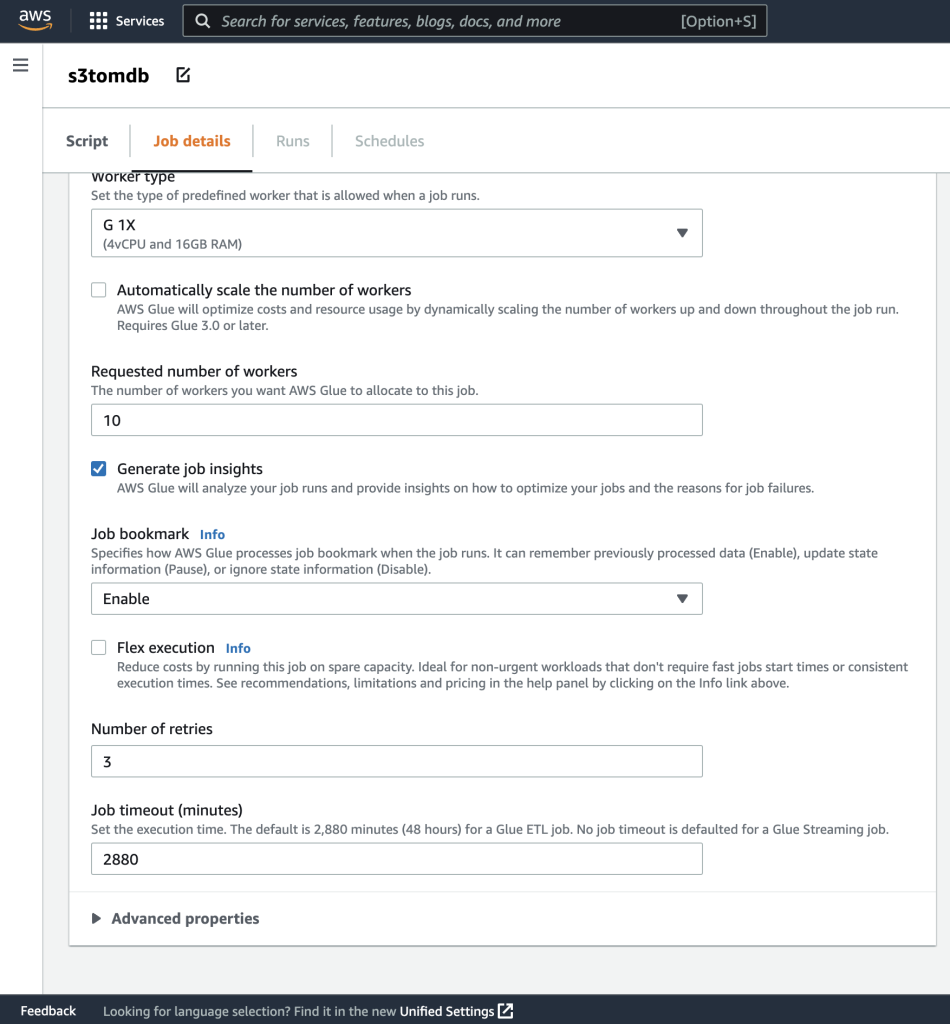
- در مرحله بعد، پارامترهای شغلی که اسکریپت استفاده می کند را تعریف کنید و مقادیر پیش فرض را ارائه کنید.
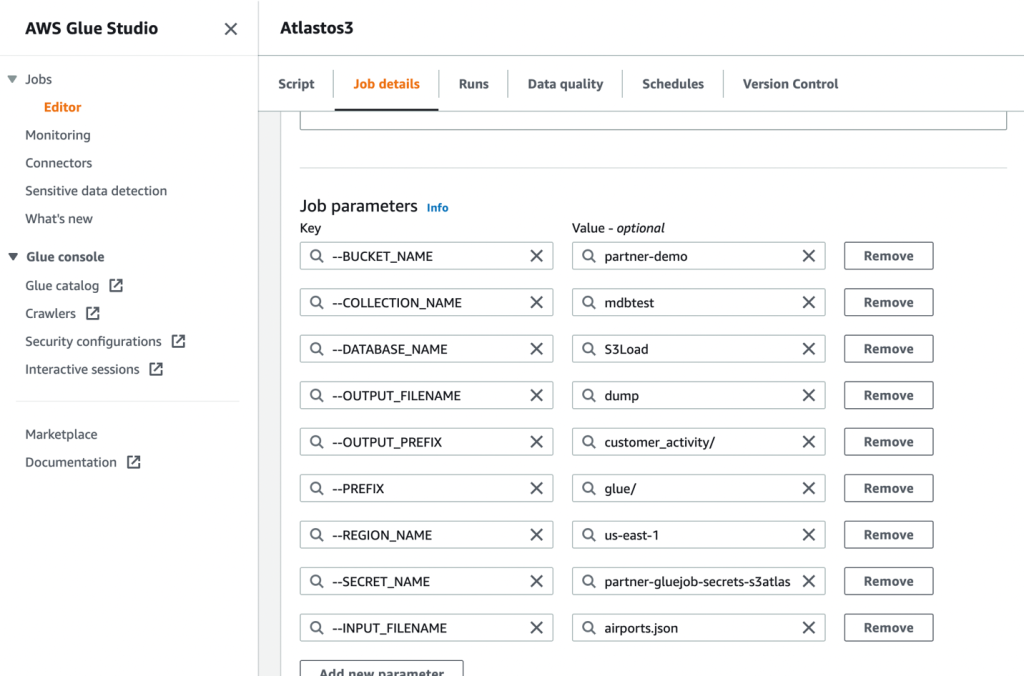
- کار را ذخیره کرده و اجرا کنید.
- برای تأیید اجرای موفقیت آمیز، در صورت بارگیری داده ها، محتویات مجموعه پایگاه داده MongoDB Atlas یا اگر در حال استخراج هستید، سطل S3 را مشاهده کنید.



تصویر زیر نتایج بارگذاری موفقیت آمیز داده از سطل آمازون S3 در خوشه MongoDB Atlas را نشان می دهد. دادهها اکنون برای درخواستها در MongoDB Atlas UI در دسترس هستند.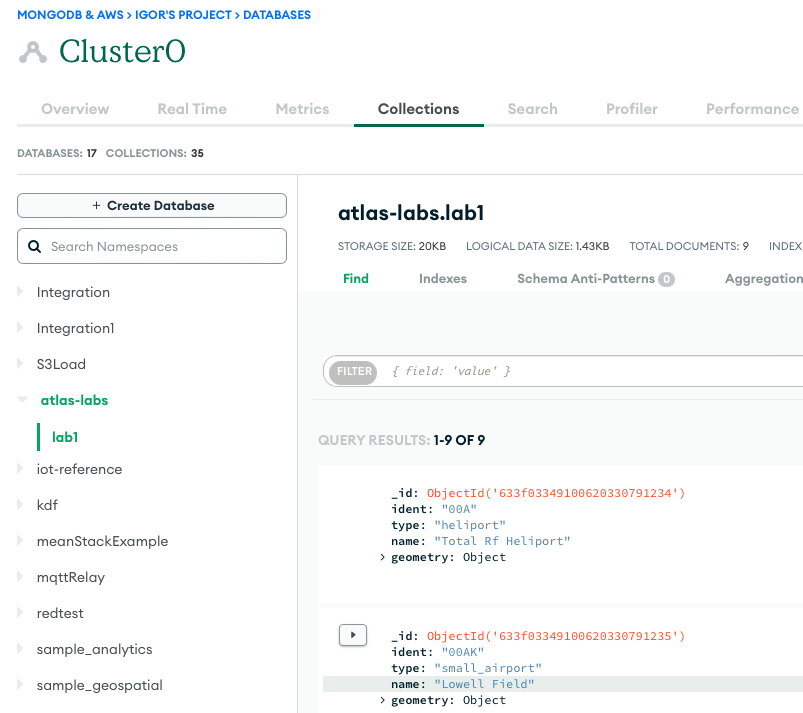
- برای عیبیابی اجراهای خود، آن را مرور کنید CloudWatch آمازون سیاهههای مربوط با استفاده از پیوند موجود در کار دویدن تب.
اسکرین شات زیر نشان می دهد که کار با موفقیت انجام شد، با جزئیات بیشتری مانند پیوندهایی به گزارش های CloudWatch.

نتیجه
در این پست، نحوه استخراج و جذب داده ها به MongoDB Atlas را با استفاده از چسب AWS توضیح دادیم.
با کارهای AWS Glue ETL، اکنون میتوانیم دادهها را از MongoDB Atlas به منابع سازگار با چسب AWS و بالعکس انتقال دهیم. همچنین می توانید راه حل را برای ساخت تجزیه و تحلیل با استفاده از خدمات AWS AI و ML گسترش دهید.
برای کسب اطلاعات بیشتر به ادامه مطلب مراجعه کنید مخزن GitHub برای دستورالعمل های گام به گام و کد نمونه. می توانید تهیه کنید MongoDB اطلس در AWS Marketplace.
درباره نویسنده

ایگور آلکسیف یک معمار راه حل شریک ارشد در AWS در حوزه داده و تجزیه و تحلیل است. ایگور در نقش خود با شرکای استراتژیک همکاری می کند و به آنها کمک می کند تا معماری های پیچیده و بهینه شده AWS بسازند. قبل از پیوستن به AWS، بهعنوان معمار داده/راهحل، او پروژههای زیادی را در حوزه دادههای بزرگ اجرا کرد، از جمله چندین دریاچه داده در اکوسیستم Hadoop. به عنوان یک مهندس داده، او در استفاده از AI/ML برای کشف تقلب و اتوماسیون اداری شرکت داشت.
 بابو سرینیواسان یک معمار ارشد راه حل های شریک در MongoDB است. در نقش فعلی خود، او در حال کار با AWS برای ایجاد یکپارچگی فنی و معماری مرجع برای راه حل های AWS و MongoDB است. او بیش از دو دهه تجربه در زمینه فناوری های پایگاه داده و ابری دارد. او مشتاق ارائه راهحلهای فنی برای مشتریانی است که با چندین سیستم ادغامکننده سیستم جهانی (GSI) در مناطق مختلف جغرافیایی کار میکنند.
بابو سرینیواسان یک معمار ارشد راه حل های شریک در MongoDB است. در نقش فعلی خود، او در حال کار با AWS برای ایجاد یکپارچگی فنی و معماری مرجع برای راه حل های AWS و MongoDB است. او بیش از دو دهه تجربه در زمینه فناوری های پایگاه داده و ابری دارد. او مشتاق ارائه راهحلهای فنی برای مشتریانی است که با چندین سیستم ادغامکننده سیستم جهانی (GSI) در مناطق مختلف جغرافیایی کار میکنند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoAiStream. Web3 Data Intelligence دانش تقویت شده دسترسی به اینجا.
- ضرب کردن آینده با آدرین اشلی. دسترسی به اینجا.
- خرید و فروش سهام در شرکت های PRE-IPO با PREIPO®. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/compose-your-etl-jobs-for-mongodb-atlas-with-aws-glue/
- : دارد
- :است
- 100
- 11
- a
- توانایی
- درباره ما
- دسترسی
- در میان
- اضافی
- AI
- AI / ML
- همچنین
- آمازون
- مقدار
- an
- علم تجزیه و تحلیل
- و
- کاربرد
- برنامه توسعه
- برنامه های کاربردی
- با استفاده از
- برنامه های
- معماری
- هستند
- AS
- At
- قهرمانی که دنیا را روی شانههایش نگهداشته است
- اتوماسیون
- در دسترس
- AWS
- چسب AWS
- بازار AWS
- حمایت کرد
- مستقر
- بودن
- میان
- بزرگ
- بزرگ داده
- ساختن
- بنا
- کسب و کار
- هوش تجاری
- عملکرد تجاری
- کسب و کار
- by
- صدا
- CAN
- موارد
- به چالش
- متغیر
- ابر
- خوشه
- رمز
- مجموعه
- ترکیب
- می آید
- آینده
- پیچیده
- محاسبه
- پیکر بندی
- تکرار
- تثبیت
- ساختن
- محتویات
- ادامه داد:
- هزینه
- ایجاد
- ایجاد شده
- ایجاد
- ایجاد
- جاری
- مشتریان
- داده ها
- مهندس داده
- یکپارچه سازی داده ها
- دریاچه دریاچه
- علم اطلاعات
- انبارهای داده
- داده محور
- پایگاه داده
- پایگاه های داده
- مجموعه داده ها
- دهه
- به طور پیش فرض
- نشان دادن
- توصیف
- شرح داده شده
- جزئیات
- کشف
- توسعه دهندگان
- پروژه
- تفاوت
- مختلف
- كشف كردن
- متفاوت
- اسناد و مدارک
- دامنه
- راندن
- رانده
- در طی
- اکوسیستم
- سردبیر
- موثر
- موتور
- مهندس
- مورد تأیید
- وارد
- سرمایه گذاری
- مشتریان سازمانی
- محیط
- اتر (ETH)
- استثنا
- موجود
- تجربه
- اکتشاف
- گسترش
- عصاره
- استخراج
- چهره
- شکل
- پرونده
- فایل ها
- سرانجام
- صاف
- قابل انعطاف
- پیروی
- برای
- تقلب
- کشف تقلب
- رایگان
- از جانب
- کاملا
- قابلیت
- جغرافیاها
- جهانی
- رشد
- هادوپ
- سیار
- داشتن
- he
- کمک
- اینجا کلیک نمایید
- خود را
- چگونه
- چگونه
- HTML
- HTTP
- HTTPS
- بزرگ
- IAM
- هویت
- if
- انجام
- اجرا
- بهبود
- in
- از جمله
- افزایش
- ورودی
- دستورالعمل
- ادغام
- یکپارچه
- ادغام
- یکپارچگی
- اطلاعات
- به
- شامل
- گرفتار
- IT
- ITS
- کار
- شغل ها
- پیوستن
- پیوستن
- json
- کلید
- دریاچه
- بزرگ
- یاد گرفتن
- یادگیری
- ترک کردن
- میراث
- پسندیدن
- ارتباط دادن
- لینک ها
- بار
- بارگیری
- به دنبال
- دستگاه
- فراگیری ماشین
- نگهداری
- باعث می شود
- اداره می شود
- مدیریت
- بسیاری
- بازار
- ممکن است..
- مهاجرت
- مهاجرت
- ML
- موبایل
- مدل
- مدرن
- نوسازی
- نوین کردن
- MongoDB
- بیش
- حرکت
- جنبش
- چندگانه
- نام
- نام
- نیاز
- ضروری
- نیازهای
- جدید
- اکنون
- مشاهده کردن
- of
- دفتر
- غالبا
- on
- ONE
- عمل
- قابل استفاده
- بهینه سازی
- گزینه
- or
- سفارش
- سازمان های
- خارج
- پارامترهای
- شریک
- شرکای
- گذشت
- احساساتی
- کلمه عبور
- کارایی
- انجام
- مجوز
- محل
- افلاطون
- هوش داده افلاطون
- PlatoData
- محبوب
- پست
- قدرت
- قوی
- آماده
- آماده
- پیش نیازها
- قبلی
- قبلا
- روند
- فرآیندهای
- در حال پردازش
- پروژه ها
- فراهم می کند
- ارائه
- اهداف
- نمایش ها
- به سرعت
- زمان واقعی
- كاهش دادن
- قابل اعتماد
- نیاز
- نیاز
- منابع
- REST
- نتایج
- این فایل نقد می نویسید:
- نقش
- دویدن
- همان
- مقیاس پذیر
- مقیاس
- علم
- تصاویر
- جستجو
- امن
- ارشد
- بدون سرور
- خدمت
- سرویس
- خدمات
- چند
- نشان داده شده
- نشان می دهد
- قابل توجه
- مشابه
- ساده
- تنها
- راه حل
- مزایا
- منابع
- گام
- مراحل
- ذخیره سازی
- opbevare
- پرده
- ساده
- استراتژیک
- شرکای استراتژیک
- ساده کردن
- استودیو
- موفق شدن
- موفقیت
- موفق
- موفقیت
- چنین
- دنباله
- عرضه
- هماهنگ سازی
- سیستم
- وظایف
- فنی
- فن آوری
- نسبت به
- که
- La
- شان
- آنها
- سپس
- اینها
- آنها
- این
- هزاران نفر
- زمان
- به
- امروز
- با هم
- معامله ای
- انتقال
- دگرگون کردن
- تحولات
- تبدیل شدن
- دور زدن
- دو
- ui
- اساسی
- استفاده کنید
- استفاده
- کاربر
- با استفاده از
- ارزشها
- بسیار
- چشم انداز
- می خواهم
- بود
- we
- وب
- بود
- چه زمانی
- چه
- که
- در حین
- اراده
- با
- بدون
- گردش کار
- کارگر
- خواهد بود
- شما
- شما
- زفیرنت