
تصویر توسط نویسنده
در هنگام تجزیه و تحلیل داده ها، چیزی که در ذهن ما وجود دارد یافتن الگوهای پنهان و استخراج بینش های معنادار است. بیایید وارد مقوله جدید یادگیری مبتنی بر ML شویم، یعنی یادگیری بدون نظارت، که در آن یکی از الگوریتمهای قدرتمند برای حل وظایف خوشهبندی، الگوریتم خوشهبندی K-Means است که درک دادهها را متحول میکند.
K-Means has become a useful algorithm in machine learning and data mining applications. In this article, we will deep dive into the workings of K-Means, its implementation using Python, and exploring its principles, applications, etc. So, let’s start the journey to unlock the secret patterns and harness the potential of the K-Means clustering algorithm.
الگوریتم K-Means برای حل مسائل خوشه بندی که متعلق به کلاس یادگیری بدون نظارت هستند استفاده می شود. با کمک این الگوریتم می توانیم تعداد مشاهدات را در خوشه های K گروه بندی کنیم.
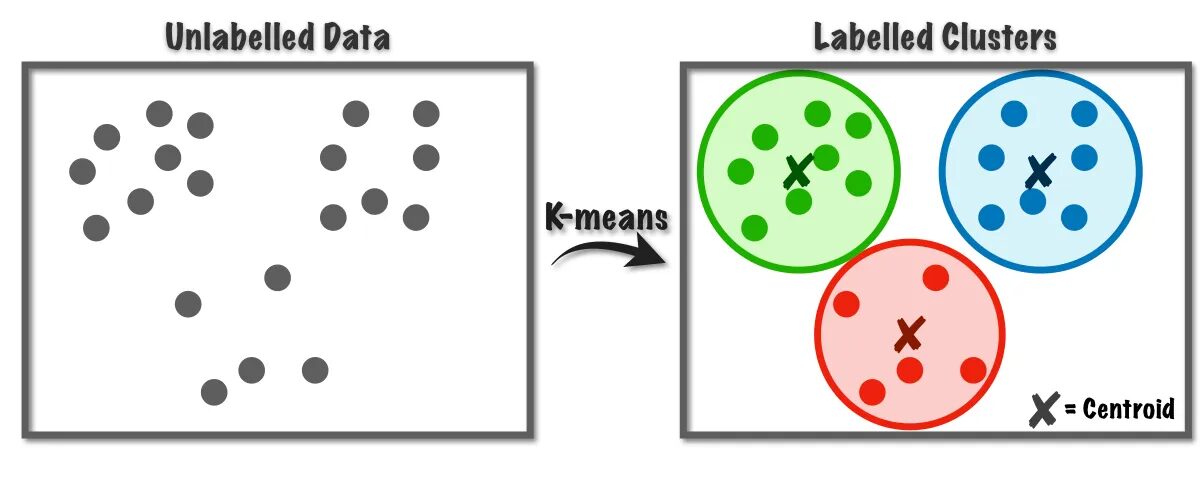
شکل 1 الگوریتم K-Means کار می کند | تصویر از به سمت علم داده
این الگوریتم به صورت داخلی از کوانتیزاسیون برداری استفاده می کند که از طریق آن می توانیم هر مشاهده در مجموعه داده را به خوشه با حداقل فاصله که نمونه اولیه الگوریتم خوشه بندی است اختصاص دهیم. این الگوریتم خوشهبندی معمولاً در دادهکاوی و یادگیری ماشین برای تقسیمبندی دادهها به خوشههای K بر اساس معیارهای شباهت استفاده میشود. بنابراین در این الگوریتم باید مجموع مربعات فاصله بین مشاهدات و مرکز مربوط به آنها را به حداقل برسانیم که در نهایت منجر به خوشه های متمایز و همگن می شود.
کاربردهای K-means Clustering
در اینجا برخی از کاربردهای استاندارد این الگوریتم آورده شده است. الگوریتم K-means یک تکنیک متداول در موارد استفاده صنعتی برای حل مسائل مربوط به خوشه بندی است.
- تقسیم بندی مشتریان: خوشه بندی K-means می تواند مشتریان مختلف را بر اساس علایقشان تقسیم بندی کند. می توان آن را برای بانکداری، مخابرات، تجارت الکترونیک، ورزش، تبلیغات، فروش و غیره اعمال کرد.
- خوشه بندی اسناد: در این تکنیک، اسناد مشابه را از مجموعهای از اسناد جمعبندی میکنیم و در نتیجه اسناد مشابهی را در همان خوشهها ایجاد میکنیم.
- موتورهای پیشنهادی: گاهی اوقات می توان از خوشه بندی K-means برای ایجاد سیستم های توصیه استفاده کرد. به عنوان مثال، شما می خواهید آهنگ ها را به دوستان خود توصیه کنید. میتوانید به آهنگهایی که آن شخص پسندیده است نگاه کنید و سپس از خوشهبندی برای یافتن آهنگهای مشابه استفاده کنید و مشابهترین آنها را توصیه کنید.
برنامه های بسیار بیشتری وجود دارد که مطمئنم قبلاً به آنها فکر کرده اید، که احتمالاً آنها را در بخش نظرات زیر این مقاله به اشتراک می گذارید.
در این بخش، پیادهسازی الگوریتم K-Means را بر روی یکی از مجموعه دادهها با استفاده از پایتون، که عمدتاً در پروژههای علم داده استفاده میشود، آغاز میکنیم.
1. واردات کتابخانه ها و وابستگی های ضروری
ابتدا، بیایید کتابخانههای پایتون را که برای پیادهسازی الگوریتم K-means استفاده میکنیم، از جمله NumPy، Pandas، Seaborn، Marplotlib و غیره وارد کنیم.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb2. مجموعه داده را بارگذاری و تجزیه و تحلیل کنید
در این مرحله، مجموعه داده دانشجویی را با ذخیره آن در قالب داده Pandas بارگذاری می کنیم. برای دانلود مجموعه داده می توانید به لینک مراجعه کنید اینجا کلیک نمایید.
خط لوله کامل مشکل در زیر نشان داده شده است:

شکل 2 خط لوله پروژه | تصویر توسط نویسنده
df = pd.read_csv('student_clustering.csv')
print("The shape of data is",df.shape)
df.head()3. نمودار پراکندگی مجموعه داده
اکنون مرحله مدلسازی این است که دادهها را تجسم کنیم، بنابراین از matplotlib برای ترسیم نمودار پراکندگی استفاده میکنیم تا نحوه عملکرد الگوریتم خوشهبندی را بررسی کنیم و خوشههای مختلف ایجاد کنیم.
# Scatter plot of the dataset
import matplotlib.pyplot as plt
plt.scatter(df['cgpa'],df['iq'])
خروجی:
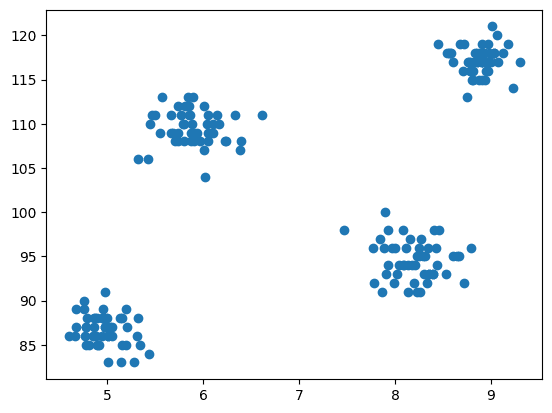
شکل 3 نمودار پراکندگی | تصویر توسط نویسنده
4. K-Means را از کلاس Cluster Scikit-learn وارد کنید
حال، همانطور که باید خوشه بندی K-Means را پیاده سازی کنیم، ابتدا کلاس کلاستر را وارد می کنیم و سپس KMeans را به عنوان ماژول آن کلاس داریم.
from sklearn.cluster import KMeans5. یافتن مقدار بهینه K با استفاده از روش Elbow
در این مرحله هنگام پیاده سازی الگوریتم مقدار بهینه K یکی از فراپارامترها را پیدا می کنیم. مقدار K نشان می دهد که چه تعداد خوشه باید برای مجموعه داده خود ایجاد کنیم. یافتن این مقدار به صورت شهودی ممکن نیست، بنابراین برای یافتن مقدار بهینه، میخواهیم یک نمودار بین WCSS (in-cluster-sum-of-squares) و مقادیر K مختلف ایجاد کنیم و باید آن K را انتخاب کنیم. حداقل مقدار WCSS را به ما می دهد.
# create an empty list for store residuals
wcss = [] for i in range(1,11): # create an object of K-Means class km = KMeans(n_clusters=i) # pass the dataframe to fit the algorithm km.fit_predict(df) # append inertia value to wcss list wcss.append(km.inertia_)
حالا بیایید نمودار زانویی را رسم کنیم تا مقدار بهینه K را پیدا کنیم.
# Plot of WCSS vs. K to check the optimal value of K
plt.plot(range(1,11),wcss)
خروجی:
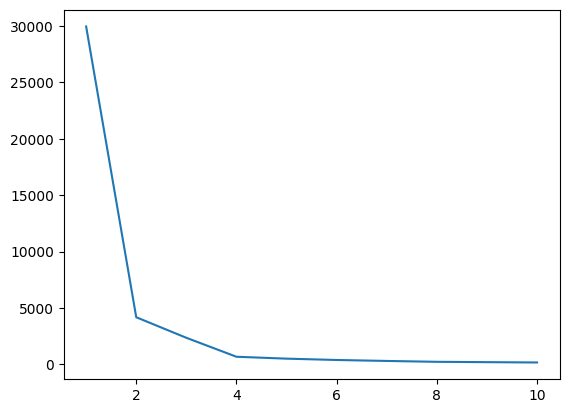
شکل 4 پلات آرنجی | تصویر توسط نویسنده
از نمودار زانویی بالا، می توانیم در K=4 مشاهده کنیم. مقدار WCSS کاهش می یابد، به این معنی که اگر از مقدار بهینه 4 استفاده کنیم، در آن صورت، خوشه بندی عملکرد خوبی به شما می دهد.
6. الگوریتم K-Means را با مقدار Optimal K مطابقت دهید
اکنون، بیایید مدلسازی را انجام دهیم که در آن یک آرایه X ایجاد می کنیم که مجموعه داده کامل را با تمام ویژگی ها ذخیره می کند. در اینجا نیازی به جدا کردن بردار هدف و ویژگی نیست، زیرا این یک مشکل بدون نظارت است. پس از آن، یک شی از کلاس KMeans با یک مقدار K انتخاب شده ایجاد می کنیم و سپس آن را در مجموعه داده ارائه شده قرار می دهیم. در نهایت y_means را چاپ می کنیم که نشان دهنده میانگین خوشه های مختلف تشکیل شده است.
X = df.iloc[:,:].values # complete data is used for model building
km = KMeans(n_clusters=4)
y_means = km.fit_predict(X)
y_means7. Cluster Assignment هر دسته را بررسی کنید
بیایید بررسی کنیم که تمام نقاط مجموعه داده متعلق به کدام خوشه است.
X[y_means == 3,1]
تا به حال، برای مقداردهی اولیه مرکز، از استراتژی K-Means++ استفاده میکردیم، حالا بیایید به جای K-Means++، سانتروئیدهای تصادفی را مقداردهی کنیم و نتایج را با دنبال کردن همان فرآیند مقایسه کنیم.
km_new = KMeans(n_clusters=4, init='random')
y_means_new = km_new.fit_predict(X)
y_means_new
بررسی کنید که چند مقدار مطابقت دارند.
sum(y_means == y_means_new)8. تجسم خوشه ها
برای تجسم هر خوشه، آنها را بر روی محورها رسم می کنیم و رنگ های مختلفی را تعیین می کنیم که از طریق آنها به راحتی می توانیم تشکیل 4 خوشه را مشاهده کنیم.
plt.scatter(X[y_means == 0,0],X[y_means == 0,1],color='blue')
plt.scatter(X[y_means == 1,0],X[y_means == 1,1],color='red') plt.scatter(X[y_means == 2,0],X[y_means == 2,1],color='green') plt.scatter(X[y_means == 3,0],X[y_means == 3,1],color='yellow')
خروجی:
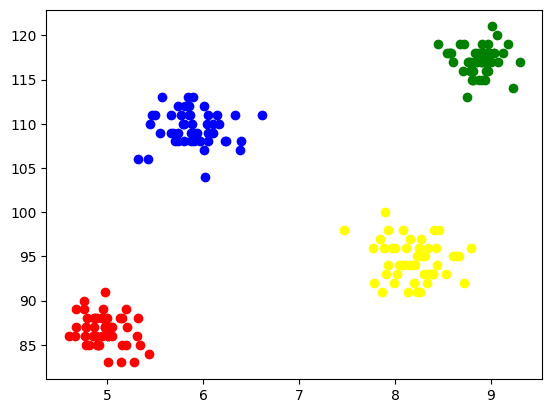
شکل 5 تجسم خوشه های تشکیل شده | تصویر توسط نویسنده
9. K-Means در 3D-Data
از آنجایی که مجموعه داده قبلی دارای 2 ستون است، ما یک مشکل دو بعدی داریم. اکنون، از همان مجموعه مراحل برای یک مسئله سه بعدی استفاده می کنیم و سعی می کنیم تکرارپذیری کد را برای داده های n بعدی تحلیل کنیم.
# Create a synthetic dataset from sklearn
from sklearn.datasets import make_blobs # make synthetic dataset
centroids = [(-5,-5,5),(5,5,-5),(3.5,-2.5,4),(-2.5,2.5,-4)]
cluster_std = [1,1,1,1]
X,y = make_blobs(n_samples=200,cluster_std=cluster_std,centers=centroids,n_features=3,random_state=1)
# Scatter plot of the dataset
import plotly.express as px
fig = px.scatter_3d(x=X[:,0], y=X[:,1], z=X[:,2])
fig.show()
خروجی:
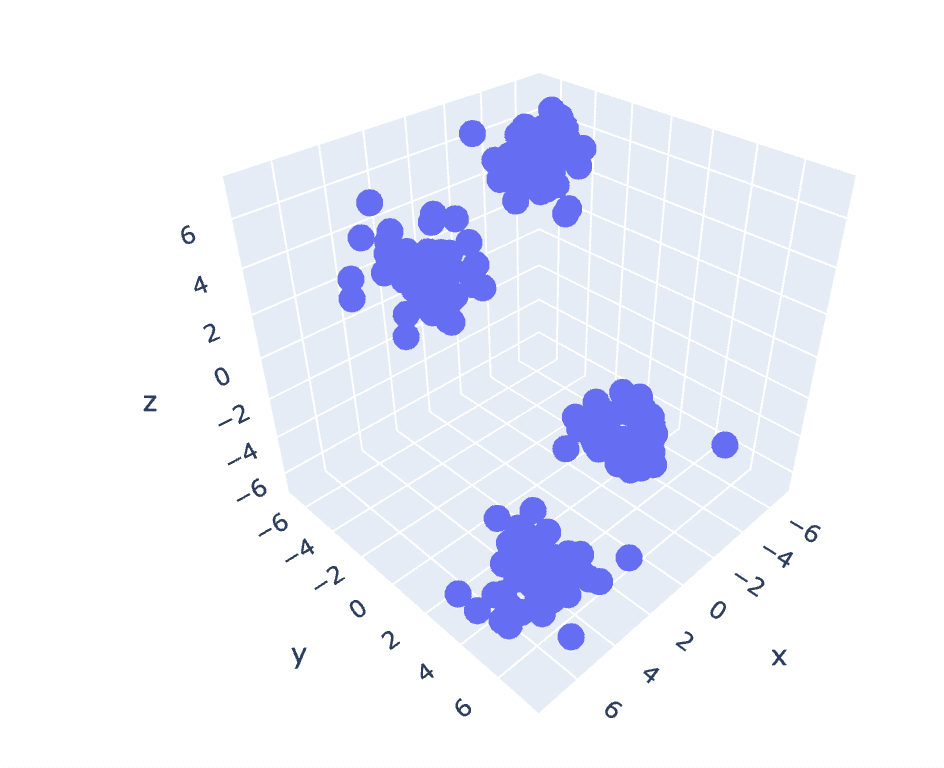
شکل 6 نمودار پراکندگی مجموعه داده سه بعدی | تصویر توسط نویسنده
wcss = []
for i in range(1,21): km = KMeans(n_clusters=i) km.fit_predict(X) wcss.append(km.inertia_) plt.plot(range(1,21),wcss)
خروجی:

شکل 7 پلات آرنجی | تصویر توسط نویسنده
# Fit the K-Means algorithm with the optimal value of K
km = KMeans(n_clusters=4)
y_pred = km.fit_predict(X)
# Analyse the different clusters formed
df = pd.DataFrame()
df['col1'] = X[:,0]
df['col2'] = X[:,1]
df['col3'] = X[:,2]
df['label'] = y_pred fig = px.scatter_3d(df,x='col1', y='col2', z='col3',color='label')
fig.show()
خروجی:
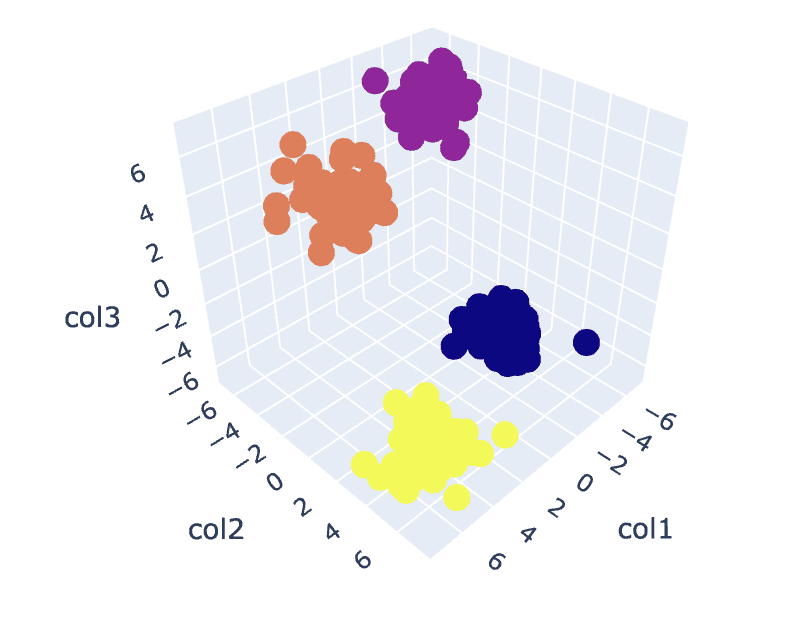
شکل 8. تجسم خوشه ها | تصویر توسط نویسنده
You can find the complete code here – دفترچه یادداشت کولب
این بحث ما را کامل می کند. ما در مورد کار، پیاده سازی و کاربردهای K-Means بحث کرده ایم. در نتیجه، اجرای وظایف خوشهبندی یک الگوریتم پرکاربرد از کلاس یادگیری بدون نظارت است که یک رویکرد ساده و شهودی برای گروهبندی مشاهدات یک مجموعه داده ارائه میدهد. نقطه قوت اصلی این الگوریتم این است که مشاهدات را بر اساس معیارهای شباهت انتخاب شده با کمک کاربری که الگوریتم را پیاده سازی می کند به مجموعه های متعدد تقسیم می کند.
با این حال، بر اساس انتخاب مرکز در مرحله اول، الگوریتم ما رفتار متفاوتی دارد و به بهینه محلی یا جهانی همگرا می شود. بنابراین، انتخاب تعداد خوشهها برای پیادهسازی الگوریتم، پیشپردازش دادهها، مدیریت نقاط پرت و غیره، برای به دست آوردن نتایج خوب بسیار مهم است. اما اگر طرف دیگر این الگوریتم را در پشت محدودیتها مشاهده کنیم، K-Means یک تکنیک مفید برای تجزیه و تحلیل دادههای اکتشافی و تشخیص الگو در زمینههای مختلف است.
آریایی گرگ B.Tech است. دانشجوی مهندسی برق، در حال حاضر در سال آخر کارشناسی. علاقه او در زمینه توسعه وب و یادگیری ماشین است. او این علاقه را دنبال کرده و مشتاق است در این مسیرها بیشتر کار کند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. خودرو / خودروهای الکتریکی، کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- BlockOffsets. نوسازی مالکیت افست زیست محیطی. دسترسی به اینجا.
- منبع: https://www.kdnuggets.com/2023/07/clustering-unleashed-understanding-kmeans-clustering.html?utm_source=rss&utm_medium=rss&utm_campaign=clustering-unleashed-understanding-k-means-clustering
- : دارد
- :است
- :نه
- :جایی که
- 1
- 10
- 11
- 13
- 16
- 25
- 28
- 7
- 8
- 9
- a
- بالاتر
- تبلیغات
- پس از
- الگوریتم
- الگوریتم
- معرفی
- قبلا
- am
- an
- تحلیل
- تحلیل
- تحلیل
- تجزیه و تحلیل
- و
- برنامه های کاربردی
- اعمال می شود
- روش
- هستند
- صف
- مقاله
- AS
- At
- تبرها
- b
- بانکداری
- مستقر
- BE
- شدن
- پشت سر
- در زیر
- میان
- آبی
- بنا
- اما
- by
- CAN
- مورد
- موارد
- دسته بندی
- بررسی
- را انتخاب کنید
- کلاس
- باشگاه
- خوشه
- خوشه بندی
- رمز
- ستون ها
- می آید
- نظرات
- عموما
- مقايسه كردن
- کامل
- تکمیل شده
- نتیجه
- متناظر
- ایجاد
- بسیار سخت
- در حال حاضر
- مشتری
- مشتریان
- داده ها
- تحلیل داده ها
- داده کاوی
- علم اطلاعات
- مجموعه داده ها
- عمیق
- شیرجه عمیق
- پروژه
- مختلف
- غوطه
- جهت ها
- بحث کردیم
- گفتگو
- فاصله
- متمایز
- do
- سند
- اسناد و مدارک
- انجام شده
- دانلود
- قرعه کشی
- e
- تجارت الکترونیک
- هر
- مشتاق
- به آسانی
- مهندسی برق
- مهندسی
- موتورهای حرفه ای
- وارد
- و غیره
- در نهایت
- مثال
- تجزیه و تحلیل داده های اکتشافی
- بررسی
- صریح
- عصاره
- ویژگی
- امکانات
- رشته
- زمینه
- انجیر
- نهایی
- سرانجام
- پیدا کردن
- پیدا کردن
- نام خانوادگی
- مناسب
- پیروی
- برای
- تشکیل
- دوستان
- از جانب
- دادن
- می دهد
- جهانی
- رفتن
- خوب
- گوگل
- سبز
- گروه
- اداره
- دهنه
- آیا
- داشتن
- he
- کمک
- مفید
- اینجا کلیک نمایید
- پنهان
- خود را
- چگونه
- HTTPS
- i
- if
- تصویر
- انجام
- پیاده سازی
- اجرای
- واردات
- in
- از جمله
- نشان می دهد
- صنعتی
- اینرسی
- بینش
- در عوض
- علاقه
- منافع
- داخلی
- به
- حسی
- IT
- ITS
- سفر
- JPG
- kdnuggets
- برچسب
- یادگیری
- کتابخانه ها
- نهفته است
- محدودیت
- ارتباط دادن
- لینک
- فهرست
- بار
- محلی
- نگاه کنيد
- دستگاه
- فراگیری ماشین
- اصلی
- عمدتا
- ساخت
- بسیاری
- مسابقه
- ماتپلوتلب
- معنی دار
- به معنی
- متریک
- ذهن
- حد اقل
- استخراج معدن
- مدل
- مدل سازی
- واحد
- بیش
- اکثر
- چندگانه
- باید
- لازم
- نیاز
- جدید
- نه
- اکنون
- عدد
- بی حس
- هدف
- مشاهده کردن
- گرفتن
- of
- on
- ONE
- آنهایی که
- بهینه
- or
- دیگر
- ما
- پانداها
- عبور
- الگو
- الگوهای
- کارایی
- شخص
- خط لوله
- افلاطون
- هوش داده افلاطون
- PlatoData
- نقطه
- ممکن
- پتانسیل
- قوی
- قبلی
- از اصول
- چاپ
- شاید
- مشکل
- مشکلات
- روند
- پروژه
- پروژه ها
- نمونه اولیه
- ارائه
- فراهم می کند
- پــایتــون
- تصادفی
- به رسمیت شناختن
- توصیه
- توصیه
- قرمز
- تحقیق
- نتیجه
- نتایج
- انقلابی می کند
- s
- حراجی
- همان
- علم
- متولد دریا
- راز
- بخش
- دیدن
- بخش
- تقسیم بندی
- انتخاب شد
- انتخاب
- انتخاب
- جداگانه
- تنظیم
- مجموعه
- شکل
- اشتراک گذاری
- نشان داده شده
- طرف
- نشان می دهد
- مشابه
- ساده
- So
- حل
- حل کردن
- برخی از
- ورزش ها
- مربع
- استاندارد
- شروع
- گام
- مراحل
- opbevare
- پرده
- استراتژی
- استحکام
- دانشجو
- مطمئن
- ترکیبی
- سیستم های
- هدف
- وظایف
- فن آوری
- مخابراتی
- که
- La
- شان
- آنها
- سپس
- آنجا.
- از این رو
- اینها
- چیز
- این
- فکر
- از طریق
- به
- امتحان
- درک
- رها شده
- باز
- یادگیری بدون نظارت
- us
- استفاده کنید
- استفاده
- کاربر
- استفاده
- با استفاده از
- استفاده کنید
- ارزش
- ارزشها
- مختلف
- تجسم
- vs
- می خواهم
- we
- وب
- توسعه وب
- که
- در حین
- WHO
- به طور گسترده ای
- اراده
- با
- مهاجرت کاری
- کارگر
- کارها
- با این نسخهها کار
- X
- سال
- زرد
- شما
- شما
- زفیرنت








