یافتن ستون های مشابه در a دریاچه داده کاربردهای مهمی در پاکسازی و حاشیه نویسی داده ها، تطبیق طرحواره، کشف داده ها و تجزیه و تحلیل در منابع داده های متعدد دارد. ناتوانی در یافتن و تجزیه و تحلیل دقیق دادهها از منابع متفاوت، یک قاتل کارایی بالقوه برای همه از دانشمندان داده، محققان پزشکی، دانشگاهیان تا تحلیلگران مالی و دولتی است.
راهحلهای مرسوم شامل جستجوی واژههای کلیدی واژگانی یا تطبیق عبارات منظم است که در معرض مسائل مربوط به کیفیت دادهها مانند عدم وجود نام ستونها یا قراردادهای نامگذاری ستونهای مختلف در مجموعههای داده متنوع هستند (به عنوان مثال، zip_code, zcode, postalcode).
در این پست راه حلی برای جستجوی ستون های مشابه بر اساس نام ستون، محتوای ستون یا هر دو نشان می دهیم. راه حل استفاده می کند الگوریتم های تقریبی نزدیکترین همسایگان قابل دسترسی در سرویس جستجوی باز آمازون برای جستجوی ستون های مشابه معنایی. برای تسهیل جستجو، با استفاده از مدلهای ترانسفورماتور از پیش آموزشدیده شده، نمایش ویژگیها (جاسازیها) برای ستونهای جداگانه در دریاچه داده ایجاد میکنیم. کتابخانه جملات ترانسفورماتور in آمازون SageMaker. در نهایت، برای تعامل و تجسم نتایج حاصل از راه حل خود، یک تعاملی ایجاد می کنیم Streamlit برنامه وب در حال اجرا AWS Fargate.
الف را شامل می کنیم آموزش کد تا بتوانید منابعی را برای اجرای راه حل بر روی داده های نمونه یا داده های خودتان مستقر کنید.
بررسی اجمالی راه حل
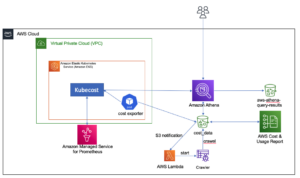
نمودار معماری زیر گردش کار دو مرحله ای را برای یافتن ستون های مشابه معنایی نشان می دهد. مرحله اول اجرا می شود توابع مرحله AWS گردش کار که جاسازیهایی را از ستونهای جدولی ایجاد میکند و فهرست جستجوی سرویس OpenSearch را ایجاد میکند. مرحله دوم یا مرحله استنتاج آنلاین، یک برنامه Streamlit را از طریق Fargate اجرا می کند. برنامه وب درخواستهای جستجوی ورودی را جمعآوری میکند و ستونهای تقریبی k-مشابهترین ستونها را از فهرست سرویس OpenSearch بازیابی میکند.

شکل 1. معماری راه حل
گردش کار خودکار در مراحل زیر انجام می شود:
- کاربر مجموعه داده های جدولی را در یک آپلود می کند سرویس ذخیره سازی ساده آمازون سطل (Amazon S3) که یک سطل را فراخوانی می کند AWS لامبدا تابعی که گردش کار توابع Step را آغاز می کند.
- گردش کار با یک شروع می شود چسب AWS کاری که فایل های CSV را به پارکت آپاچی فرمت داده
- یک کار پردازش SageMaker با استفاده از مدلهای از پیش آموزش دیده یا مدلهای تعبیه ستون سفارشی، جاسازیهایی را برای هر ستون ایجاد میکند. کار پردازش SageMaker، جاسازیهای ستونها را برای هر جدول در آمازون S3 ذخیره میکند.
- یک تابع Lambda دامنه و خوشه سرویس OpenSearch را ایجاد می کند تا جاسازی های ستون تولید شده در مرحله قبل را فهرست کند.
- در نهایت، یک برنامه وب تعاملی Streamlit با Fargate مستقر می شود. برنامه وب رابطی را برای کاربر فراهم می کند تا درخواست های ورودی را برای جستجوی دامنه سرویس OpenSearch برای ستون های مشابه وارد کند.
آموزش کد را می توانید از اینجا دانلود کنید GitHub این راه حل را روی داده های نمونه یا داده های خود امتحان کنید. دستورالعمل نحوه استقرار منابع مورد نیاز برای این آموزش در دسترس است گیتهاب.
پیش نیازها
برای پیاده سازی این راه حل به موارد زیر نیاز دارید:
- An حساب AWS.
- آشنایی اولیه با خدمات AWS مانند کیت توسعه ابری AWS (AWS CDK)، Lambda، OpenSearch Service و SageMaker Processing.
- یک مجموعه داده جدولی برای ایجاد نمایه جستجو. شما می توانید داده های جدولی خود را بیاورید یا مجموعه داده های نمونه را دانلود کنید GitHub.
یک فهرست جستجو بسازید
مرحله اول نمایه موتور جستجوی ستونی را ایجاد می کند. شکل زیر گردش کار Step Functions را نشان می دهد که این مرحله را اجرا می کند.

شکل 2 – گردش کار توابع مرحله – مدل های تعبیه چندگانه
مجموعه داده ها
در این پست، ما یک فهرست جستجو ایجاد می کنیم که شامل بیش از 400 ستون از بیش از 25 مجموعه داده جدولی باشد. مجموعه داده ها از منابع عمومی زیر سرچشمه می گیرند:
برای لیست کامل جداول موجود در ایندکس، آموزش کد را مشاهده کنید GitHub.
شما می توانید مجموعه داده جدولی خود را بیاورید تا داده های نمونه را افزایش دهید یا فهرست جستجوی خود را بسازید. ما دو تابع Lambda را شامل میشویم که گردش کار توابع مرحله را برای ایجاد فهرست جستجو برای فایلهای CSV منفرد یا دستهای از فایلهای CSV آغاز میکنند.
CSV را به پارکت تبدیل کنید
فایلهای CSV خام با چسب AWS به فرمت دادههای پارکت تبدیل میشوند. Parquet یک فرمت فایل با فرمت ستون محور است که در تجزیه و تحلیل داده های بزرگ ترجیح داده می شود که فشرده سازی و کدگذاری کارآمد را فراهم می کند. در آزمایشهای ما، قالب دادههای پارکت در مقایسه با فایلهای خام CSV کاهش قابل توجهی در اندازه ذخیرهسازی ارائه کرد. ما همچنین از Parquet به عنوان یک فرمت داده رایج برای تبدیل فرمت های داده دیگر (به عنوان مثال JSON و NDJSON) استفاده کردیم زیرا از ساختارهای داده تو در تو پیشرفته پشتیبانی می کند.
جاسازی ستون های جدولی ایجاد کنید
برای استخراج تعبیهها برای ستونهای جداول جداگانه در مجموعه دادههای جدولی نمونه در این پست، از مدلهای از پیش آموزش دیده زیر استفاده میکنیم. sentence-transformers کتابخانه برای مدل های اضافی، نگاه کنید مدل های از پیش آموزش دیده.
کار پردازش SageMaker اجرا می شود create_embeddings.py(رمز) برای یک مدل واحد. برای استخراج جاسازیها از چندین مدل، گردش کار، کارهای پردازش SageMaker موازی را همانطور که در گردش کار توابع مرحله نشان داده شده است، اجرا میکند. ما از مدل برای ایجاد دو مجموعه تعبیه استفاده می کنیم:
- column_name_embeddings - تعبیه نام ستون ها (هدر)
- column_content_embeddings – میانگین تعبیه تمام سطرها در ستون
برای اطلاعات بیشتر در مورد فرآیند جاسازی ستون، به آموزش کد در مورد مراجعه کنید GitHub.
جایگزینی برای مرحله پردازش SageMaker، ایجاد یک تبدیل دسته ای SageMaker برای دریافت جاسازی ستون در مجموعه داده های بزرگ است. این مستلزم استقرار مدل در یک نقطه پایانی SageMaker است. برای اطلاعات بیشتر ببین از Batch Transform استفاده کنید.
جاسازیهای فهرست با سرویس OpenSearch
در مرحله آخر این مرحله، یک تابع Lambda جاسازیهای ستون را به یک سرویس جستجوی باز تقریبی k-Nearest-Neighbor اضافه میکند.kNN) فهرست جستجو. به هر مدل شاخص جستجو اختصاص داده شده است. برای اطلاعات بیشتر در مورد پارامترهای شاخص جستجوی تقریبی kNN، نگاه کنید k-NN.
استنتاج آنلاین و جستجوی معنایی با یک برنامه وب
مرحله دوم گردش کار اجرا می شود Streamlit برنامه وب که در آن می توانید ورودی ها را ارائه دهید و ستون های مشابه معنایی فهرست شده در OpenSearch Service را جستجو کنید. لایه برنامه از یک استفاده می کند Application Load Balancer، Fargate و Lambda. زیرساخت برنامه به طور خودکار به عنوان بخشی از راه حل مستقر می شود.
این برنامه به شما امکان می دهد یک ورودی ارائه دهید و نام ستون ها، محتوای ستون ها یا هر دو را از نظر معنایی مشابه جستجو کنید. علاوه بر این، میتوانید مدل جاسازی و تعداد نزدیکترین همسایگان را برای بازگشت از جستجو انتخاب کنید. برنامه ورودی ها را دریافت می کند، ورودی را با مدل مشخص شده جاسازی می کند و استفاده می کند جستجوی kNN در سرویس OpenSearch برای جستجوی جاسازی ستون های نمایه شده و یافتن شبیه ترین ستون ها به ورودی داده شده. نتایج جستجوی نمایش داده شده شامل نام جدول، نام ستون، و امتیاز شباهت برای ستون های شناسایی شده، و همچنین مکان داده ها در آمازون S3 برای کاوش بیشتر است.
شکل زیر نمونه ای از وب اپلیکیشن را نشان می دهد. در این مثال، ما ستونهایی را در دریاچه دادههای خود جستجو کردیم که دارای مشابه هستند Column Names (نوع محموله) به district (ظرفیت ترابری). برنامه مورد استفاده all-MiniLM-L6-v2 عنوان مدل تعبیه و برگشت 10 (k) نزدیکترین همسایگان از فهرست خدمات جستجوی باز ما.
برنامه برگشت transit_district, city, boroughو location به عنوان چهار ستون مشابه بر اساس داده های نمایه شده در OpenSearch Service. این مثال توانایی رویکرد جستجو را برای شناسایی ستون های مشابه معنایی در بین مجموعه داده ها نشان می دهد.

شکل 3: رابط کاربری برنامه وب
پاک کردن
برای حذف منابع ایجاد شده توسط AWS CDK در این آموزش، دستور زیر را اجرا کنید:
cdk destroy --allنتیجه
در این پست، یک گردش کار پایان به انتها برای ساخت یک موتور جستجوی معنایی برای ستون های جدولی ارائه کردیم.
با آموزش کد ما که در دسترس است، همین امروز با داده های خود شروع کنید GitHub. اگر برای تسریع استفاده از ML در محصولات و فرآیندهای خود کمک میخواهید، لطفاً با آن تماس بگیرید آزمایشگاه راه حل های یادگیری ماشین آمازون.
درباره نویسنده
![]() کاچی اودومنه دانشمند کاربردی در AWS AI است. او راه حل های AI/ML را برای حل مشکلات تجاری برای مشتریان AWS می سازد.
کاچی اودومنه دانشمند کاربردی در AWS AI است. او راه حل های AI/ML را برای حل مشکلات تجاری برای مشتریان AWS می سازد.
![]() تیلور مک نالی یک معمار یادگیری عمیق در آزمایشگاه راه حل های یادگیری ماشین آمازون است. او به مشتریان صنایع مختلف کمک می کند تا راه حل هایی را با استفاده از AI/ML در AWS بسازند. او از یک فنجان قهوه خوب، بیرون از منزل، و با خانواده و سگ پرانرژی خود لذت می برد.
تیلور مک نالی یک معمار یادگیری عمیق در آزمایشگاه راه حل های یادگیری ماشین آمازون است. او به مشتریان صنایع مختلف کمک می کند تا راه حل هایی را با استفاده از AI/ML در AWS بسازند. او از یک فنجان قهوه خوب، بیرون از منزل، و با خانواده و سگ پرانرژی خود لذت می برد.
![]() آستین ولش یک دانشمند داده در آزمایشگاه راه حل های آمازون ML است. او مدلهای یادگیری عمیق سفارشی را توسعه میدهد تا به مشتریان بخش عمومی AWS کمک کند تا پذیرش هوش مصنوعی و ابری خود را تسریع کنند. او در اوقات فراغت خود از مطالعه، مسافرت و جیو جیتسو لذت می برد.
آستین ولش یک دانشمند داده در آزمایشگاه راه حل های آمازون ML است. او مدلهای یادگیری عمیق سفارشی را توسعه میدهد تا به مشتریان بخش عمومی AWS کمک کند تا پذیرش هوش مصنوعی و ابری خود را تسریع کنند. او در اوقات فراغت خود از مطالعه، مسافرت و جیو جیتسو لذت می برد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- توانایی
- درباره ما
- غایب
- شتاب دادن
- تسریع
- به درستی
- در میان
- اضافی
- علاوه بر این
- می افزاید:
- اتخاذ
- پیشرفته
- AI
- AI / ML
- معرفی
- اجازه می دهد تا
- جایگزین
- آمازون
- آموزش ماشین آمازون
- آزمایشگاه راه حل های آمازون ام ال
- تحلیلگران
- علم تجزیه و تحلیل
- تحلیل
- و
- آپاچی
- کاربرد
- برنامه های کاربردی
- اعمال می شود
- روش
- معماری
- اختصاص داده
- خودکار
- بطور خودکار
- در دسترس
- میانگین
- AWS
- چسب AWS
- مستقر
- زیرا
- بزرگ
- بزرگ داده
- به ارمغان بیاورد
- ساختن
- بنا
- می سازد
- کسب و کار
- تمیز کاری
- ابر
- پذیرش ابر
- خوشه
- رمز
- کشت
- جمع می کند
- ستون
- ستون ها
- مشترک
- مقایسه
- تماس
- محتوا
- کنوانسیون
- تبدیل
- مبدل
- ایجاد
- ایجاد شده
- ایجاد
- فنجان
- سفارشی
- مشتریان
- داده ها
- تجزیه و تحلیل داده ها
- دریاچه دریاچه
- کیفیت داده
- دانشمند داده
- مجموعه داده ها
- عمیق
- یادگیری عمیق
- نشان دادن
- نشان می دهد
- گسترش
- مستقر
- استقرار
- از بین بردن
- پروژه
- توسعه
- مختلف
- کشف
- متفاوت
- مختلف
- سگ
- دامنه
- دانلود
- هر
- بهره وری
- موثر
- پشت سر هم
- نقطه پایانی
- موتور
- اتر (ETH)
- هر کس
- مثال
- اکتشاف
- عصاره
- تسهیل کردن
- آشنایی
- خانواده
- امکانات
- شکل
- پرونده
- فایل ها
- نهایی
- سرانجام
- مالی
- پیدا کردن
- پیدا کردن
- نام خانوادگی
- پیروی
- قالب
- از جانب
- کامل
- تابع
- توابع
- بیشتر
- دریافت کنید
- داده
- خوب
- دولت
- هدر
- کمک
- کمک می کند
- چگونه
- چگونه
- HTML
- HTTPS
- شناسایی
- شناسایی
- انجام
- مهم
- in
- عجز
- شامل
- مشمول
- شاخص
- فرد
- لوازم
- اطلاعات
- شالوده
- وارد کردن
- شروع می کند
- ورودی
- دستورالعمل
- تعامل
- تعاملی
- رابط
- فراخوانی میکند
- شامل
- مسائل
- IT
- کار
- شغل ها
- json
- آزمایشگاه
- دریاچه
- بزرگ
- لایه
- یادگیری
- بهره برداری
- کتابخانه
- فهرست
- بار
- مکان
- دستگاه
- فراگیری ماشین
- مطابق
- پزشکی
- ML
- مدل
- مدل
- بیش
- اکثر
- چندگانه
- نام
- نام
- نامگذاری
- نیاز
- همسایه ها
- عدد
- ارائه شده
- آنلاین
- دیگر
- خارج از منزل
- خود
- موازی
- پارامترهای
- بخش
- افلاطون
- هوش داده افلاطون
- PlatoData
- لطفا
- پست
- پتانسیل
- مرجح
- ارائه شده
- قبلی
- مشکلات
- درآمد حاصل
- روند
- فرآیندهای
- در حال پردازش
- ساخته
- محصولات
- ارائه
- فراهم می کند
- عمومی
- کیفیت
- خام
- مطالعه
- دریافت
- منظم
- نشان دهنده
- نیاز
- ضروری
- محققان
- منابع
- به ترتیب
- نتایج
- برگشت
- دویدن
- در حال اجرا
- حکیم ساز
- دانشمند
- دانشمندان
- جستجو
- موتور جستجو
- جستجو
- دوم
- بخش
- سرویس
- خدمات
- مجموعه
- نشان داده شده
- نشان می دهد
- قابل توجه
- مشابه
- ساده
- تنها
- اندازه
- راه حل
- مزایا
- حل
- منابع
- مشخص شده
- صحنه
- آغاز شده
- گام
- مراحل
- ذخیره سازی
- چنین
- پشتیبانی از
- مناسب
- جدول
- La
- شان
- از طریق
- زمان
- به
- امروز
- دگرگون کردن
- ترانسفورماتور
- سفر
- آموزش
- استفاده کنید
- کاربر
- رابط کاربری
- مختلف
- وب
- برنامه تحت وب
- که
- گردش کار
- خواهد بود
- شما
- زفیرنت