- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://www.nanowerk.com/news2/robotics/newsid=63842.php
- :است
- 10
- 100
- ٪۱۰۰
- 2023
- 7
- a
- قادر
- در میان
- تصویب
- AI
- به طور یکسان
- معرفی
- هر چند
- در میان
- an
- و
- پاسخ
- اعمال می شود
- هستند
- AS
- خواهان
- جنبه
- دستیاران
- مرتبط است
- At
- حمله
- حمله
- در دسترس
- دور
- BE
- بودن
- میان
- میلیاردها
- ساختن
- کسب و کار
- اما
- by
- CAN
- Осторожно
- مدیر عامل شرکت
- chatbots
- GPT چت
- واضح
- بسته
- مشترک
- شرکت
- کامپیوتر
- نگرانی
- در باره
- کنفرانس
- میتوانست
- ایجاد
- ایجاد
- بحرانی
- در حال حاضر
- سایبر
- تاریخ
- نشان دادن
- نشان
- استقرار
- دقیق
- کشف
- توسعه
- مختلف
- دیجیتال
- کشف
- dr
- شرکت
- تمام
- حتی
- مدرک
- وجود داشته باشد
- موجود
- بهره برداری
- استخراج
- خیلی
- شگفت انگیز
- مالی
- خدمات مالی
- نام خانوادگی
- متمرکز شده است
- برای
- از جانب
- بیشتر
- به دست آورد
- داده
- دادن
- زمین
- آیا
- پنهان
- های لایت
- میزبانی
- چگونه
- چگونه
- اما
- HTTPS
- صورت در آغوش گرفته
- مهم
- in
- افزایش
- به طور فزاینده
- صنعت
- اطلاع دادن
- اطلاعات
- امنیت اطلاعات
- بصیرت
- اینترنت
- سرمایه گذاری
- سرمایه گذاری
- IT
- JPG
- کلید
- دانش
- شناخته شده
- زبان
- بزرگ
- شرکت های بزرگ
- راه اندازی
- برجسته
- یاد گرفتن
- یادگیری
- کمتر
- کوچک
- دستگاه
- فراگیری ماشین
- عمده
- ممکن است..
- اندازه گیری
- میلیون ها نفر
- مدل
- مدل
- بسیار
- جدید
- of
- on
- باز کن
- منبع باز
- or
- خارج
- خود
- مقاله
- حزب
- از پا افتادن
- اماکن
- برنامه ریزی
- افلاطون
- هوش داده افلاطون
- PlatoData
- ممکن
- بالقوه
- قوی
- آماده
- ارائه شده
- اصلی
- خصوصی
- ارائه
- عمومی
- محدوده
- نرخ
- تکرار شده
- درخواست
- تحقیق
- محققان
- فاش کردن
- خطرات
- سعید
- گفتن
- دانشمندان
- تیم امنیت لاتاری
- خدمات
- تنظیم
- باید
- نشان
- کوچکتر
- هوشمند
- So
- برخی از
- منبع
- صحنه
- شروع
- طوفان
- مهاجرت تحصیلی
- موفقیت
- موفقیت
- چنین
- صورت گرفته
- سخنگو
- هدف قرار
- هدف گذاری
- وظایف
- تیم
- فن آوری
- پیشرفته
- تست
- نسبت به
- که
- La
- اطلاعات
- انگلستان
- جهان
- شان
- سپس
- آنجا.
- اینها
- آنها
- فکر می کنم
- سوم
- این
- در این سال
- بار
- به
- ابزار
- منتقل
- دگرگونی
- Uk
- درک
- بعهده گرفتن
- دانشگاه
- استفاده کنید
- استفاده
- استفاده
- ارزش
- بسیار
- آسیب پذیری ها
- بود
- مسیر..
- we
- هفته
- بود
- که
- وسیع
- دامنه گسترده
- اراده
- با
- در داخل
- بدون
- مهاجرت کاری
- کار کردن
- با این نسخهها کار
- جهان
- نگران کننده است
- سال
- زفیرنت
بیشتر از نانورک
آغاز عصر جدیدی از دستگاههای نانو قابل تنظیم رنگ - کوچکترین منبع نوری با رنگهای قابل تغییر شکل گرفته است.
گره منبع: 2801585
تمبر زمان: اوت 3، 2023

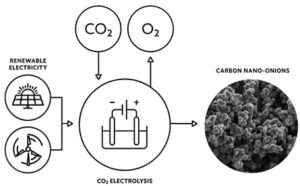
نانولوله های کربنی ممکن است نقش مهمی در اتصال دی اکسید کربن اتمسفر ایفا کنند
گره منبع: 2836729
تمبر زمان: اوت 21، 2023

چاپ های سه بعدی به قسمت تاریک می پیوندند و ناپدید می شوند
گره منبع: 2903619
تمبر زمان: سپتامبر 27، 2023
وقتی مواد کوانتومی میشوند، الکترونها کند میشوند و یک کریستال تشکیل میدهند
گره منبع: 1975767
تمبر زمان: فوریه 23، 2023

مهندسان یک فرآیند کارآمد برای تولید سوخت از دی اکسید کربن ایجاد می کنند
گره منبع: 2963812
تمبر زمان: اکتبر 30، 2023