آمازون آتنا یک سرویس پرس و جو تعاملی است که تجزیه و تحلیل داده ها را در آن آسان می کند سرویس ذخیره سازی ساده آمازون (Amazon S3) و منابع داده ساکن در AWS، داخل محل یا سایر سیستمهای ابری با استفاده از SQL یا Python. Athena بر روی موتورهای منبع باز Trino و Presto و فریمورک های Apache Spark ساخته شده است، بدون نیاز به تهیه یا پیکربندی. Athena بدون سرور است، بنابراین هیچ زیرساختی برای مدیریت وجود ندارد و شما فقط برای کوئری هایی که اجرا می کنید هزینه می پردازید.
کوه یخ آپاچی یک قالب جدول باز برای مجموعه داده های تحلیلی بسیار بزرگ است. مجموعههای بزرگی از فایلها را بهعنوان جداول مدیریت میکند، و از عملیاتهای دریاچه دادههای تحلیلی مدرن مانند درج سطح رکورد، بهروزرسانی، حذف، و درخواستهای سفر در زمان پشتیبانی میکند. آتنا از جستارهای خواندن، سفر در زمان، نوشتن و DDL برای جداول Apache Iceberg که از فرمت Apache Parquet برای داده ها و کاتالوگ داده چسب AWS برای متاستور آنها
مهندسی ویژگی فرآیند شناسایی و تبدیل دادههای خام (تصاویر، فایلهای متنی، ویدئوها و غیره)، پر کردن دادههای از دست رفته، و افزودن یک یا چند عنصر داده معنادار برای ارائه زمینه است تا یک مدل یادگیری ماشینی (ML) بتواند از آن بیاموزد. برچسبگذاری دادهها برای موارد استفاده مختلف از جمله پیشبینی، بینایی رایانه، پردازش زبان طبیعی و تشخیص گفتار مورد نیاز است.
همراه با قابلیتهای Athena، Apache Iceberg گردش کار سادهشدهای را برای دانشمندان داده ارائه میکند تا بدون نیاز به کپی یا بازسازی کل مجموعه داده، ویژگیهای داده جدیدی ایجاد کنند. شما می توانید ویژگی هایی را با استفاده از SQL استاندارد در Athena بدون استفاده از هیچ سرویس دیگری برای مهندسی ویژگی ایجاد کنید. دانشمندان داده می توانند زمان صرف شده برای تهیه و کپی مجموعه داده ها را کاهش دهند و در عوض بر مهندسی ویژگی های داده، آزمایش و تجزیه و تحلیل داده ها در مقیاس تمرکز کنند.
در این پست، مزایای استفاده از آتنا با فرمت جدول باز Apache Iceberg و اینکه چگونه کارهای مهندسی ویژگی های رایج را برای دانشمندان داده ساده می کند، مرور می کنیم. ما نشان میدهیم که چگونه آتنا میتواند یک جدول موجود را در قالب Apache Iceberg تبدیل کند، سپس ستونها را اضافه کند، ستونها را حذف کند، و دادههای موجود در جدول را بدون ایجاد مجدد یا کپی مجموعه داده تغییر دهد و از این قابلیتها برای ایجاد ویژگیهای جدید در جداول Apache Iceberg استفاده کند.
بررسی اجمالی راه حل
دانشمندان داده معمولاً به کار با مجموعه داده های بزرگ عادت دارند. مجموعه داده ها معمولاً در JSON، CSV، ORC یا ذخیره می شوند پارکت آپاچی فرمت، یا فرمت های مشابه برای خواندن بهینه شده برای عملکرد خواندن سریع. دانشمندان داده اغلب ویژگیهای داده جدیدی ایجاد میکنند و چنین ویژگیهای دادهای را با دادههای انبوه و فرعی پر میکنند. از لحاظ تاریخی، این کار با ایجاد یک نمای بالای جدول با داده های زیرین در قالب Apache Parquet، که در آن ستون ها و داده ها در زمان اجرا اضافه می شدند یا با ایجاد یک جدول جدید با ستون های اضافی، انجام می شد. اگرچه این گردش کار برای بسیاری از موارد استفاده مناسب است، اما برای مجموعه داده های بزرگ ناکارآمد است، زیرا داده ها باید در زمان اجرا تولید شوند یا مجموعه داده ها باید کپی و تبدیل شوند.
آتنا معرفی کرده است تراکنش اسید (اتمی، سازگاری، جداسازی، دوام). قابلیتهایی که عملیاتهای درج، بهروزرسانی، حذف، ادغام و سفر در زمان را اضافه میکنند میزهای کوه یخی آپاچی. این قابلیتها دانشمندان داده را قادر میسازد تا ویژگیهای داده جدید ایجاد کنند و ویژگیهای داده موجود را روی مجموعه دادههای موجود رها کنند، بدون اینکه نگران کپی کردن یا تبدیل مجموعه داده یا انتزاع آن با یک نمای باشند. دانشمندان داده می توانند روی کار مهندسی ویژگی ها تمرکز کنند و از کپی و تبدیل مجموعه داده ها اجتناب کنند.
عملیات بهروزرسانی Athena Iceberg موقعیت حذف فایلهای Apache Iceberg و ردیفهای بهروزرسانیشده جدید را به عنوان فایلهای داده در همان تراکنش مینویسد. شما می توانید از طریق یک عبارت UPDATE تصحیح رکورد را انجام دهید.
با انتشار موتور آتنا نسخه 3، قابلیت های میزهای Apache Iceberg با پشتیبانی از عملیات هایی مانند ایجاد جدول به عنوان انتخاب (CTAS) و دستورات MERGE که مدیریت چرخه حیات داده های Iceberg شما را ساده می کند. CTAS ساخت جداول از فرمت های دیگر مانند Apache Paquet و ... را سریع و کارآمد می کند ادغام با بهروزرسانیهای مشروط، حذف یا درج ردیفها در جدول Iceberg. یک عبارت واحد می تواند اقدامات به روز رسانی، حذف و درج را با هم ترکیب کند.
پیش نیازها
برای استفاده از دستورات CTAS و MERGE با جدول Apache Iceberg یک گروه کاری Athena با موتور Athena نسخه 3 راه اندازی کنید. برای ارتقاء موتور Athena موجود خود به نسخه 3 در گروه کاری Athena، دستورالعملهای موجود را دنبال کنید برای افزایش عملکرد پرس و جو و دسترسی به ویژگی های تجزیه و تحلیل بیشتر، به موتور Athena نسخه 3 ارتقا دهید یا رجوع به تغییر نسخه موتور در کنسول آتنا.
مجموعه داده
برای نمایش، از جدول پارکت آپاچی استفاده میکنیم که حاوی چندین میلیون رکورد از دادههای فروش ساختگی توزیع شده تصادفی از چندین سال گذشته است که در یک سطل S3 ذخیره شده است. دانلود مجموعه داده را از حالت فشرده در رایانه محلی خود خارج کرده و در سطل S3 خود آپلود کنید. در این پست مجموعه داده های خود را در آن آپلود کردیم s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/.
جدول زیر طرح بندی جدول را نشان می دهد customer_orders.
| نام ستون | نوع داده | توضیحات: |
| کلید سفارش | رشته | شماره سفارش برای سفارش |
| کلید | رشته | شماره شناسایی مشتری |
| وضعیت سفارش | رشته | وضعیت سفارش |
| قیمت کل | رشته | قیمت کل سفارش |
| تاریخ سفارش | رشته | تاریخ سفارش |
| ترتیب اولویت | رشته | اولویت سفارش |
| منشی | رشته | نام منشی که سفارش را پردازش کرد |
| اولویت کشتی | رشته | اولویت در حمل و نقل |
| نام | رشته | نام مشتری |
| نشانی | رشته | آدرس مشتری |
| ملی کلید | رشته | کلید ملت مشتری |
| تلفن | رشته | شماره تلفن مشتری |
| acctbal | رشته | موجودی حساب مشتری |
| mktsegment | رشته | بخش بازار مشتری |
مهندسی ویژگی را انجام دهید
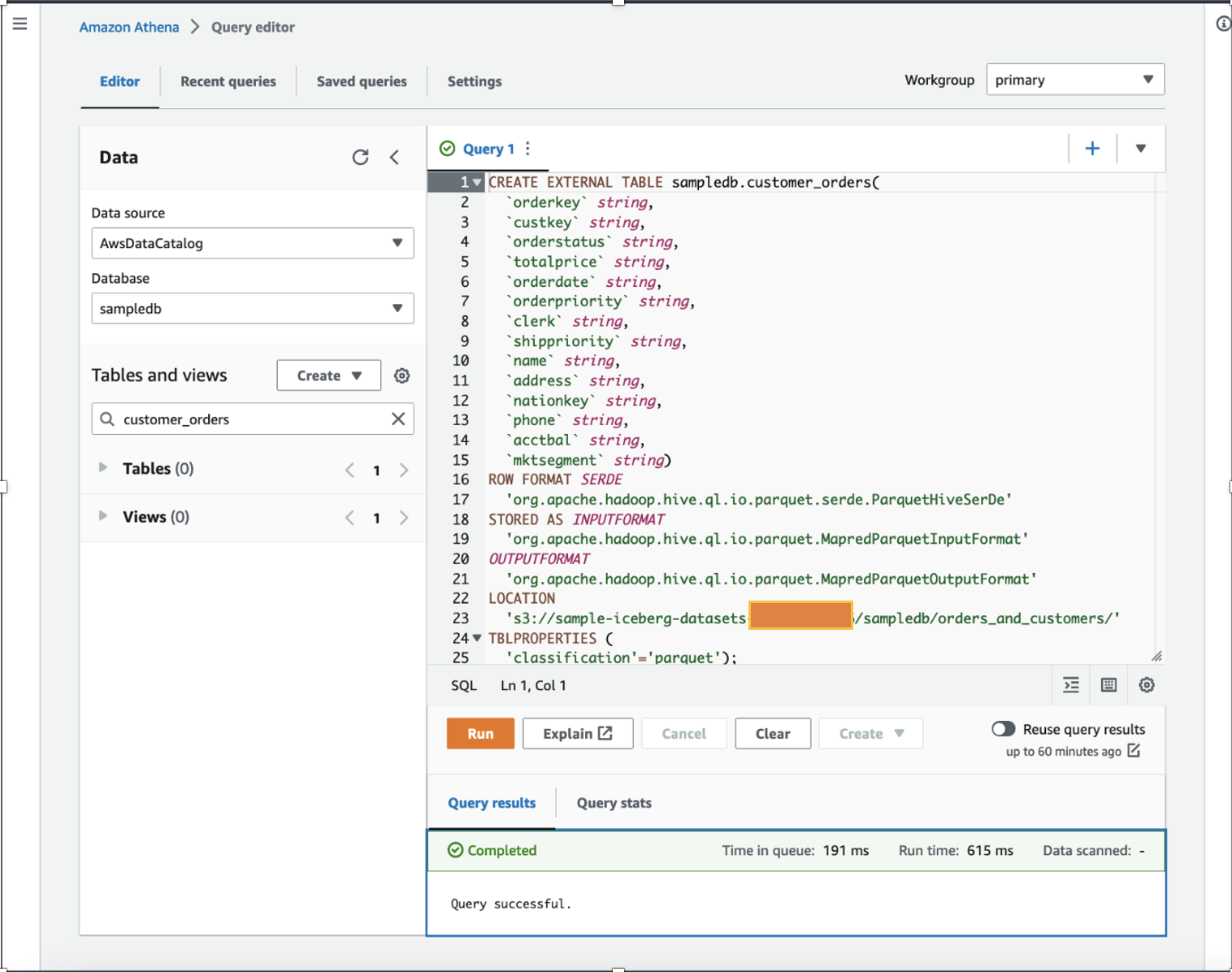
به عنوان یک دانشمند داده، ما می خواهیم کار کنیم مهندسی ویژگی بر روی داده های سفارشات مشتری با افزودن کل خریدهای محاسبه شده یک ساله و میانگین خریدهای یک ساله برای هر مشتری در مجموعه داده موجود. برای اهداف نمایشی، ما ایجاد کردیم customer_orders جدول در sampledb پایگاه داده با استفاده از Athena همانطور که در دستور DDL زیر نشان داده شده است. (می توانید از هر یک از مجموعه داده های موجود خود استفاده کنید و مراحل ذکر شده در این پست را دنبال کنید.) customer_orders مجموعه داده در محل سطل S3 تولید و ذخیره شد s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/ در قالب پارکت این جدول یک میز کوه یخی آپاچی نیست.
![]()
اعتبار داده های جدول را با اجرای یک پرس و جو:
![]()
ما میخواهیم ویژگیهای جدیدی را به این جدول اضافه کنیم تا درک عمیقتری از فروش مشتری داشته باشیم، که میتواند منجر به آموزش سریعتر مدل و بینش ارزشمندتر شود. برای افزودن ویژگیهای جدید به مجموعه داده، آن را تبدیل کنید customer_orders میز آتنا به میز کوه یخی آپاچی روی آتنا. مسئله الف CTAS عبارت query برای ایجاد یک جدول جدید با فرمت Apache Iceberg از customer_orders جدول. در حین انجام این کار، یک ویژگی جدید برای دریافت کل مبلغ خرید در سال گذشته (حداکثر سال مجموعه داده) توسط هر مشتری اضافه می شود.
در پرس و جوی CTAS زیر، ستون جدیدی به نام one_year_sales_aggregate با مقدار پیش فرض as 0.0 از نوع داده double اضافه می شود و table_type تنظیم شده است ICEBERG:
![]()
برای تأیید داده های جدول Apache Iceberg با ستون جدید، کوئری زیر را صادر کنید one_year_sales_aggregate مقادیر به عنوان 0.0:
![]()
ما می خواهیم مقادیر ویژگی جدید را پر کنیم one_year_sales_aggregate در مجموعه داده برای دریافت کل مبلغ خرید برای هر مشتری بر اساس خریدهای آنها در سال گذشته (حداکثر سال مجموعه داده). یک عبارت پرس و جو MERGE را به جدول Apache Iceberg با استفاده از Athena برای پر کردن مقادیر برای one_year_sales_aggregate ویژگی ها:
![]()
پرس و جوی زیر را برای تأیید ارزش به روز شده برای کل هزینه هر مشتری در سال گذشته صادر کنید:
![]()
ما تصمیم داریم ویژگی دیگری را به جدول Apache Iceberg موجود اضافه کنیم تا میانگین مقدار خرید در سال گذشته توسط هر مشتری را محاسبه و ذخیره کنیم. برای افزودن یک ستون جدید به جدول موجود برای ویژگی، یک عبارت ALTER query صادر کنید one_year_sales_average:
![]()
قبل از پر کردن مقادیر این ویژگی جدید، می توانید مقدار پیش فرض ویژگی را تنظیم کنید one_year_sales_average به 0.0. با استفاده از همان جدول Apache Iceberg در Athena، یک عبارت پرس و جو به روز رسانی صادر کنید تا مقدار ویژگی جدید را به عنوان پر کنید. 0.0:
![]()
برای تأیید مقدار به روز شده برای میانگین هزینه هر مشتری در سال گذشته، درخواست زیر را صادر کنید 0.0:
![]()
اکنون می خواهیم مقادیر ویژگی جدید را پر کنیم one_year_sales_average در مجموعه داده برای دریافت میانگین مبلغ خرید برای هر مشتری بر اساس خریدهای آنها در سال گذشته (حداکثر سال مجموعه داده). با استفاده از موتور Athena برای پر کردن مقادیر ویژگی، یک عبارت پرس و جو MERGE به جدول Apache Iceberg موجود در Athena صادر کنید. one_year_sales_average:
![]()
پرس و جوی زیر را برای تأیید مقادیر به روز شده برای میانگین هزینه هر مشتری صادر کنید:
![]()
هنگامی که ویژگیهای داده اضافی به مجموعه داده اضافه شد، دانشمندان داده معمولاً به آموزش مدلهای ML و استنتاج با استفاده از Amazon Sagemaker یا مجموعه ابزارهای معادل آن میپردازند.
نتیجه
در این پست نحوه انجام مهندسی ویژگی با استفاده از Athena با Apache Iceberg را نشان دادیم. ما همچنین با استفاده از پرس و جو CTAS برای ایجاد جدول Apache Iceberg در Athena از مجموعه داده های موجود در قالب Apache Parquet، افزودن ویژگی های جدید در جدول Apache Iceberg موجود در Athena با استفاده از پرس و جو ALTER، و استفاده از دستورات پرس و جو UPDATE و MERGE برای به روز رسانی نشان دادیم. مقادیر ویژگی های ستون های موجود
ما شما را تشویق می کنیم که از پرس و جوهای CTAS برای ایجاد سریع و کارآمد جداول استفاده کنید و از دستور MERGE برای همگام سازی جداول در یک مرحله برای ساده سازی آماده سازی داده ها و به روز رسانی وظایف هنگام تبدیل ویژگی ها با استفاده از Athena با Apache Iceberg استفاده کنید. اگر نظر یا بازخوردی دارید، لطفا آنها را در قسمت نظرات بنویسید.
درباره نویسنده
![]() ویوک گوتام یک معمار داده با تخصص در دریاچه های داده در خدمات حرفه ای AWS است. او با مشتریان سازمانی کار می کند که محصولات داده، پلتفرم های تجزیه و تحلیل و راه حل هایی را در AWS ایجاد می کنند. هنگامی که پلتفرمهای داده مدرن نمیسازد و طراحی نمیکند، Vivek یک علاقهمند به غذا است که همچنین دوست دارد مقاصد سفر جدید را کشف کند و پیادهگردی کند.
ویوک گوتام یک معمار داده با تخصص در دریاچه های داده در خدمات حرفه ای AWS است. او با مشتریان سازمانی کار می کند که محصولات داده، پلتفرم های تجزیه و تحلیل و راه حل هایی را در AWS ایجاد می کنند. هنگامی که پلتفرمهای داده مدرن نمیسازد و طراحی نمیکند، Vivek یک علاقهمند به غذا است که همچنین دوست دارد مقاصد سفر جدید را کشف کند و پیادهگردی کند.
![]() میخائیل واینشتاین یک معمار راه حل با خدمات وب آمازون است. میخائیل با مشتریان مراقبت های بهداشتی و علوم زیستی برای ایجاد راه حل هایی کار می کند که به بهبود نتایج بیماران کمک می کند. میخائیل در خدمات تجزیه و تحلیل داده ها متخصص است.
میخائیل واینشتاین یک معمار راه حل با خدمات وب آمازون است. میخائیل با مشتریان مراقبت های بهداشتی و علوم زیستی برای ایجاد راه حل هایی کار می کند که به بهبود نتایج بیماران کمک می کند. میخائیل در خدمات تجزیه و تحلیل داده ها متخصص است.
![]() نارش گوتام یک رهبر تجزیه و تحلیل داده و AI/ML در AWS با 20 سال تجربه است که از کمک به مشتریان در طراحی تجزیه و تحلیل داده های بسیار در دسترس، با کارایی بالا و مقرون به صرفه و راه حل های AI/ML برای توانمندسازی مشتریان با تصمیم گیری مبتنی بر داده لذت می برد. . در اوقات فراغت از مدیتیشن و آشپزی لذت می برد.
نارش گوتام یک رهبر تجزیه و تحلیل داده و AI/ML در AWS با 20 سال تجربه است که از کمک به مشتریان در طراحی تجزیه و تحلیل داده های بسیار در دسترس، با کارایی بالا و مقرون به صرفه و راه حل های AI/ML برای توانمندسازی مشتریان با تصمیم گیری مبتنی بر داده لذت می برد. . در اوقات فراغت از مدیتیشن و آشپزی لذت می برد.
![]() هارشا تادیپارتی یک متخصص معمار راه حل های اصلی، تجزیه و تحلیل در AWS است. او از حل مشکلات پیچیده مشتری در پایگاه های داده و تجزیه و تحلیل و ارائه نتایج موفق لذت می برد. خارج از محل کار، او دوست دارد زمانی را با خانواده خود بگذراند، فیلم تماشا کند و هر زمان که ممکن است سفر کند.
هارشا تادیپارتی یک متخصص معمار راه حل های اصلی، تجزیه و تحلیل در AWS است. او از حل مشکلات پیچیده مشتری در پایگاه های داده و تجزیه و تحلیل و ارائه نتایج موفق لذت می برد. خارج از محل کار، او دوست دارد زمانی را با خانواده خود بگذراند، فیلم تماشا کند و هر زمان که ممکن است سفر کند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- EVM Finance. رابط یکپارچه برای امور مالی غیرمتمرکز دسترسی به اینجا.
- گروه رسانه ای کوانتومی. IR/PR تقویت شده دسترسی به اینجا.
- PlatoAiStream. Web3 Data Intelligence دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/accelerate-data-science-feature-engineering-on-transactional-data-lakes-using-amazon-athena-with-apache-iceberg/
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 10
- 100
- 12
- 17
- 20
- سال 20
- 23
- 27
- 7
- a
- درباره ما
- شتاب دادن
- دسترسی
- انجام
- حساب
- اقدامات
- اضافه کردن
- اضافه
- اضافه کردن
- اضافی
- نشانی
- AI / ML
- همچنین
- هر چند
- آمازون
- آمازون آتنا
- آمازون SageMaker
- آمازون خدمات وب
- مقدار
- an
- تحلیلی
- تحلیلی
- علم تجزیه و تحلیل
- تحلیل
- تجزیه و تحلیل
- و
- دیگر
- هر
- آپاچی
- جرقه آپاچی
- هستند
- AS
- At
- در دسترس
- میانگین
- اجتناب از
- AWS
- خدمات حرفه ای AWS
- مستقر
- BE
- زیرا
- بوده
- مزایای
- ساختن
- بنا
- ساخته
- by
- محاسبه
- CAN
- قابلیت های
- موارد
- طبقه بندی
- ابر
- مجموعه
- ستون
- ستون ها
- ترکیب
- نظرات
- مشترک
- پیچیده
- محاسبه
- کامپیوتر
- چشم انداز کامپیوتر
- پیکر بندی
- شامل
- زمینه
- تبدیل
- پخت و پز
- کپی برداری
- اصلاحات
- مقرون به صرفه
- ایجاد
- ایجاد شده
- ایجاد
- مشتری
- مشتریان
- داده ها
- تجزیه و تحلیل داده ها
- دریاچه دریاچه
- علم اطلاعات
- دانشمند داده
- داده محور
- پایگاه داده
- پایگاه های داده
- مجموعه داده ها
- تاریخ
- تصمیم گیری
- تصمیم گیری
- عمیق تر
- به طور پیش فرض
- تحویل
- ارائه
- نشان دادن
- نشان
- طراحی
- مقصدهای
- توزیع شده
- عمل
- دو برابر
- قطره
- دوام
- هر
- ساده
- موثر
- موثر
- تلاش
- هر دو
- عناصر
- قدرت دادن
- قادر ساختن
- تشویق
- موتور
- مهندسی
- موتورهای حرفه ای
- افزایش
- سرمایه گذاری
- مشتریان سازمانی
- علاقهمند
- تمام
- معادل
- اتر (ETH)
- موجود
- تجربه
- اکتشاف
- خارجی
- غلط
- خانواده
- FAST
- سریعتر
- ویژگی
- امکانات
- باز خورد
- فایل ها
- تمرکز
- به دنبال
- پیروی
- غذا
- برای
- قالب
- چارچوب
- رایگان
- از جانب
- عموما
- تولید
- دریافت کنید
- Go
- گروه
- هادوپ
- آیا
- he
- بهداشت و درمان
- کمک
- کمک
- عملکرد بالا
- خیلی
- پیاده روی
- خود را
- به لحاظ تاریخی
- کندو
- چگونه
- چگونه
- HTML
- HTTPS
- شناسایی
- شناسایی
- if
- تصاویر
- بهبود
- in
- از جمله
- افزایش
- ناکارآمد
- شالوده
- درج می کند
- بینش
- در عوض
- دستورالعمل
- تعاملی
- به
- معرفی
- انزوا
- موضوع
- IT
- JPG
- json
- برچسب
- دریاچه
- زبان
- بزرگ
- نام
- طرح
- رهبر
- یاد گرفتن
- یادگیری
- ترک کردن
- زندگی
- علوم زندگی
- wifecycwe
- محدود
- محلی
- محل
- دوست دارد
- دستگاه
- فراگیری ماشین
- ساخت
- باعث می شود
- مدیریت
- مدیریت
- مدیریت می کند
- بسیاری
- بازار
- تطبیق
- حداکثر
- معنی دار
- تفکر
- ذکر شده
- ادغام کردن
- میلیون
- گم
- ML
- مدل
- مدل
- مدرن
- تغییر
- بیش
- فیلم ها
- نام
- تحت عنوان
- ملت
- طبیعی
- زبان طبیعی
- پردازش زبان طبیعی
- نیاز
- نیازمند
- جدید
- ویژگی های جدید
- ویژگی های جدید
- به تازگی
- نه
- عدد
- of
- غالبا
- on
- ONE
- فقط
- باز کن
- منبع باز
- عمل
- عملیات
- or
- سفارشات
- دیگر
- ما
- نتایج
- خارج از
- گذشته
- پرداخت
- انجام دادن
- کارایی
- تلفن
- سیستم عامل
- افلاطون
- هوش داده افلاطون
- PlatoData
- لطفا
- موقعیت
- ممکن
- پست
- آماده
- قیمت
- اصلی
- مشکلات
- روند
- پردازش
- در حال پردازش
- محصولات
- حرفه ای
- ارائه
- خرید
- خرید
- اهداف
- پــایتــون
- نمایش ها
- به سرعت
- خام
- داده های خام
- خواندن
- به رسمیت شناختن
- رکورد
- سوابق
- كاهش دادن
- آزاد
- ضروری
- نتیجه
- این فایل نقد می نویسید:
- ROW
- دویدن
- در حال اجرا
- حکیم ساز
- حراجی
- همان
- مقیاس
- علم
- علوم
- دانشمند
- دانشمندان
- بخش
- بدون سرور
- سرویس
- خدمات
- تنظیم
- چند
- نشان داده شده
- نشان می دهد
- مشابه
- ساده
- ساده شده
- ساده کردن
- تنها
- So
- مزایا
- حل کردن
- منابع
- جرقه
- متخصص
- تخصص دارد
- سخنرانی - گفتار
- تشخیص گفتار
- خرج کردن
- صرف
- SQL
- استاندارد
- بیانیه
- اظهارات
- گام
- مراحل
- ذخیره سازی
- opbevare
- ذخیره شده
- ساده کردن
- رشته
- موفق
- چنین
- پشتیبانی
- پشتیبانی از
- سیستم های
- جدول
- کار
- وظایف
- که
- La
- ادغام
- شان
- آنها
- سپس
- آنجا.
- اینها
- این
- زمان
- سفر در زمان
- به
- بالا
- جمع
- قطار
- آموزش
- معامله
- معامله ای
- مبدل
- تبدیل شدن
- سفر
- نوع
- اساسی
- درک
- بروزرسانی
- به روز شده
- به روز رسانی
- ارتقاء
- آپلود شده
- استفاده کنید
- با استفاده از
- معمولا
- تصدیق
- ارزشمند
- ارزش
- ارزشها
- مختلف
- بررسی
- نسخه
- بسیار
- از طريق
- فیلم های
- چشم انداز
- دید
- می خواهم
- بود
- تماشا کردن
- we
- وب
- خدمات وب
- بود
- چه زمانی
- هر زمان که
- که
- در حین
- WHO
- با
- بدون
- مهاجرت کاری
- گردش کار
- کارگروه
- کارگر
- با این نسخهها کار
- خواهد بود
- نوشتن
- سال
- سال
- شما
- شما
- زفیرنت
- زیپ