AWS-toega andmejärved, mida toetab võrreldamatu saadavus Amazoni lihtne salvestusteenus (Amazon S3) saab hakkama erinevate andme- ja analüüsimeetodite kombineerimiseks vajaliku ulatuse, paindlikkuse ja paindlikkusega. Kuna andmejärvede suurus on kasvanud ja kasutus küpsenud, võib andmete ärisündmustega kooskõlas hoidmiseks kulutada palju pingutusi. Failide tehingute järjepideva värskendamise tagamiseks kasutab üha suurem hulk kliente avatud lähtekoodiga tehingutabeli vorminguid, nagu Apache Jäämägi, Apache Hudija Linuxi sihtasutus Delta Lake mis aitavad teil salvestada andmeid suure tihendusmääraga, luua natiivse liidese teie rakenduste ja raamistikega ning lihtsustada järkjärgulist andmetöötlust Amazon S3-le ehitatud andmejärvedes. Need vormingud võimaldavad ACID-tehinguid (aatomilisus, järjepidevus, isolatsioon, vastupidavus), tühistamisi ja kustutamisi ning täiustatud funktsioone, nagu ajarännak ja hetktõmmised, mis olid varem saadaval ainult andmeladudes. Iga salvestusvorming rakendab seda funktsiooni veidi erineval viisil; võrdluseks vaadake AWS-i tehinguandmete järve jaoks avatud tabelivormingu valimine.
Aastal 2023, AWS teatas üldisest saadavusest Apache Icebergi, Apache Hudi ja Linux Foundationi Delta Lake jaoks Amazon Athena Apache Sparkile, mis eemaldab vajaduse installida eraldi konnektorit või sellega seotud sõltuvusi ja hallata versioone ning lihtsustab nende raamistike kasutamiseks vajalikke konfiguratsioonietappe.
Selles postituses näitame teile, kuidas Spark SQL-i kasutada Amazonase Athena märkmikud ja töötada Icebergi, Hudi ja Delta Lake'i tabelivormingutega. Näitame tavalisi toiminguid, nagu andmebaaside ja tabelite loomine, andmete tabelitesse sisestamine, andmete päringute tegemine ja Amazon S3 tabelite hetktõmmiste vaatamine, kasutades Spark SQL-i Athenas.
Eeldused
Täitke järgmised eeltingimused:
Laadige alla ja importige Amazon S3-st näidismärkmikud
Järgimiseks laadige selles postituses käsitletud märkmikud alla järgmistest kohtadest:
Pärast sülearvutite allalaadimist importige need oma Athena Sparki keskkonda, järgides juhiseid Märkmiku importimiseks jaotis Märkmiku failide haldamine.
Liikuge konkreetsesse jaotisesse Ava tabelivorming
Kui olete huvitatud Icebergi tabeli vormingust, navigeerige saidile Töötamine Apache Icebergi tabelitega sektsiooni.
Kui olete huvitatud Hudi tabelivormingust, navigeerige saidile Töötamine Apache Hudi tabelitega sektsiooni.
Kui olete huvitatud Delta Lake'i tabelivormingust, navigeerige saidile Linux Foundationi Delta Lake tabelitega töötamine sektsiooni.
Töötamine Apache Icebergi tabelitega
Kui kasutate Sparki märkmikke Athenas, saate SQL-päringuid käitada otse ilma PySparki kasutamata. Teeme seda rakumaagia abil, mis on sülearvuti lahtri spetsiaalsed päised, mis muudavad raku käitumist. SQL-i jaoks saame lisada %%sql magic, mis tõlgendab kogu lahtri sisu SQL-lausena, mida käitatakse Athenas.
Selles jaotises näitame, kuidas saate rakenduses Apache Spark for Athena kasutada SQL-i Apache Icebergi tabelite loomiseks, analüüsimiseks ja haldamiseks.
Seadistage märkmiku seanss
Apache Icebergi kasutamiseks Athenas seansi loomise või redigeerimise ajal valige Apache Jäämägi valikut laiendades Apache Sparki omadused osa. See täidab atribuudid eelnevalt, nagu on näidatud järgmisel ekraanipildil.
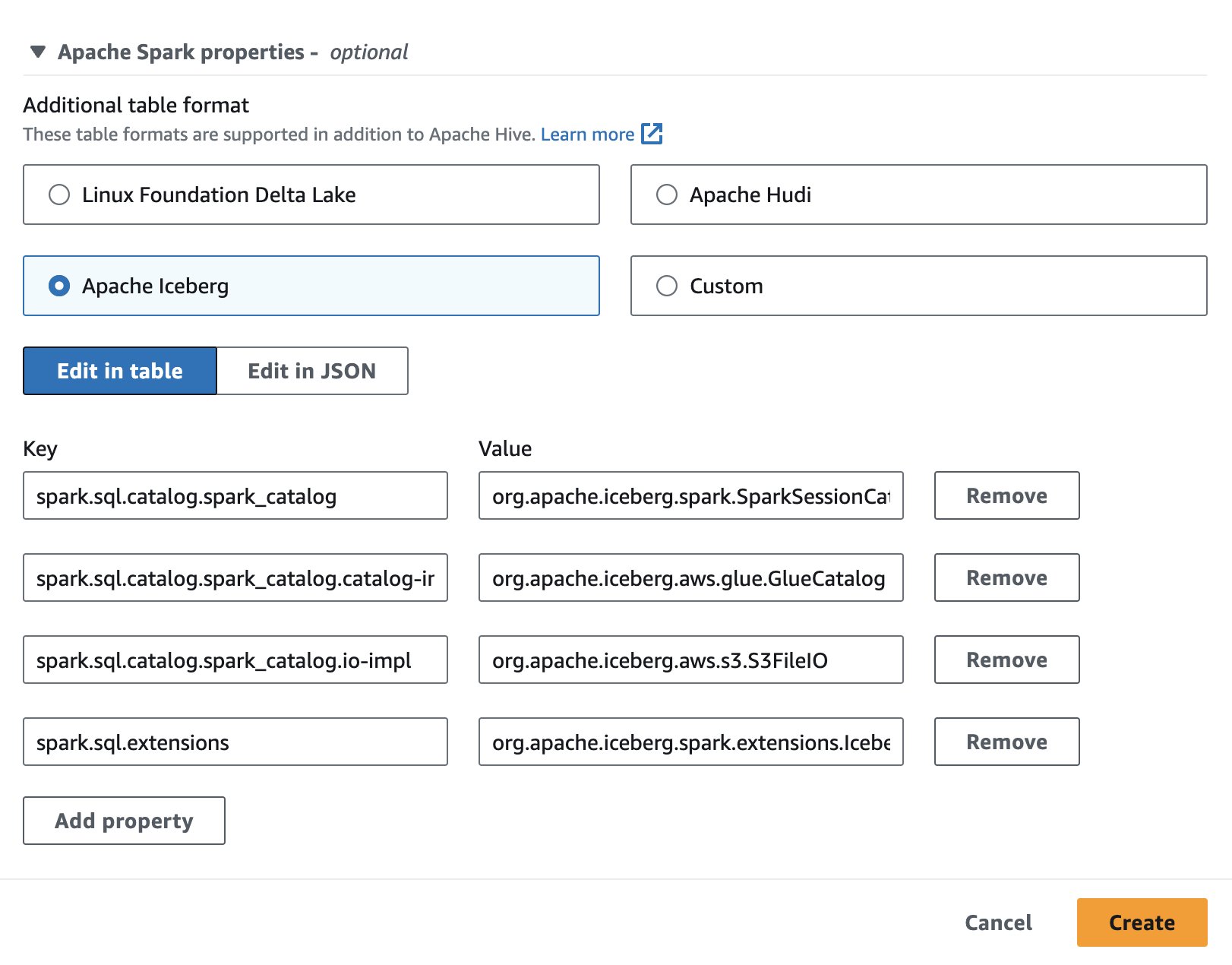
Etappide kohta vt Seansi üksikasjade redigeerimine or Oma märkmiku loomine.
Selles jaotises kasutatav kood on saadaval aadressil SparkSQL_iceberg.ipynb fail, mida järgida.
Looge andmebaas ja jäämäe tabel
Esiteks loome AWS-i liimiandmete kataloogis andmebaasi. Järgmise SQL-iga saame luua andmebaasi nimega icebergdb:
Järgmisena andmebaasis icebergdb, loome Jäämäe tabeli nimega noaa_iceberg osutades Amazon S3 asukohale, kus me andmed laadime. Käivitage järgmine lause ja asendage asukoht s3://<your-S3-bucket>/<prefix>/ koos S3 ämbri ja eesliitega:
Sisestage andmed tabelisse
Et asustada noaa_iceberg Jäämäe tabel, sisestame andmed Parketi tabelist sparkblogdb.noaa_pq mis loodi eeltingimuste osana. Seda saate teha kasutades a SISSE avaldus Sparkis:
Teise võimalusena võite kasutada ka LOO TABEL VALIKUNA klausliga USING iceberg, et luua Iceberg tabel ja sisestada andmed lähtetabelist ühe sammuga:
Küsige Icebergi tabelit
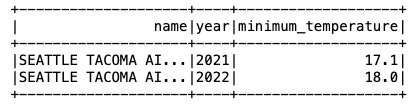
Nüüd, kui andmed on jäämäe tabelisse sisestatud, saame hakata neid analüüsima. Käivitame Spark SQL-i, et leida minimaalne registreeritud temperatuur aasta lõikes 'SEATTLE TACOMA AIRPORT, WA US' asukoht:
Saame järgmise väljundi.
Värskenda andmeid Icebergi tabelis
Vaatame, kuidas meie tabelis olevaid andmeid värskendada. Soovime värskendada jaama nime 'SEATTLE TACOMA AIRPORT, WA US' et 'Sea-Tac'. Kasutades Spark SQL-i, saame käivitada UPDATE avaldus jäämäe tabeli vastu:
Seejärel saame käivitada eelmise SELECT päringu, et leida seadme jaoks minimaalne salvestatud temperatuur 'Sea-Tac' asukoht:
Saame järgmise väljundi.

Kompaktsed andmefailid
Avatud tabelivormingud, nagu Iceberg, töötavad failisalvestuses deltamuutuste loomisel ja ridade versioonide jälgimisel manifestifailide kaudu. Rohkem andmefaile salvestab manifestifailides rohkem metaandmeid ja väikesed andmefailid põhjustavad sageli tarbetult palju metaandmeid, mille tulemuseks on vähem tõhusad päringud ja suuremad Amazon S3 juurdepääsukulud. Jäämäe jooksmine rewrite_data_files Spark for Athena protseduur tihendab andmefaile, ühendades paljud väikesed deltamuutuste failid väiksemateks lugemiseks optimeeritud Parquet-failideks. Failide tihendamine kiirendab päringu korral lugemistoimingut. Meie tabelis tihendamise käitamiseks käivitage järgmine Spark SQL:
rewrite_data_files pakub valikuid sortimisstrateegia täpsustamiseks, mis aitab andmeid ümber korraldada ja tihendada.
Loetlege tabeli hetktõmmised
Iga Icebergi tabeli kirjutamis-, värskendamis-, kustutamis-, ülesehitus- ja tihendusoperatsioon loob tabelist uue hetktõmmise, säilitades samal ajal vanad andmed ja metaandmed hetketõmmiste eraldamiseks ja ajas rändamiseks. Icebergi tabeli hetktõmmiste loetlemiseks käivitage järgmine Spark SQL-lause:
Aeguvad vanad pildid
Regulaarselt aeguvad hetktõmmised on soovitatav kustutada andmefailid, mida enam ei vajata, ja hoida tabeli metaandmete suurus väikesena. See ei eemalda kunagi faile, mida aegunud hetktõmmis endiselt nõuab. Rakenduses Spark for Athena käivitage tabeli hetktõmmiste aegumiseks järgmine SQL icebergdb.noaa_iceberg mis on vanemad kui konkreetne ajatempel:
Pange tähele, et ajatempli väärtus määratakse vormingus stringina yyyy-MM-dd HH:mm:ss.fff. Väljund näitab kustutatud andme- ja metaandmefailide arvu.
Loobuge tabel ja andmebaas
Saate käivitada järgmise Spark SQL-i, et puhastada sellest harjutusest Amazon S3 jäämäe tabelid ja nendega seotud andmed.
Andmebaasi icebergdb eemaldamiseks käivitage järgmine Spark SQL:
Lisateavet kõigi toimingute kohta, mida saate Icebergi laudadel Spark for Athena abil teha, leiate artiklist Spark Queries ja Sädeprotseduurid jäämäe dokumentatsioonis.
Töötamine Apache Hudi tabelitega
Järgmisena näitame, kuidas saate Spark for Athena SQL-i kasutada Apache Hudi tabelite loomiseks, analüüsimiseks ja haldamiseks.
Seadistage märkmiku seanss
Apache Hudi kasutamiseks Athenas seansi loomise või redigeerimise ajal valige Apache Hudi valikut laiendades Apache Sparki omadused sektsiooni.
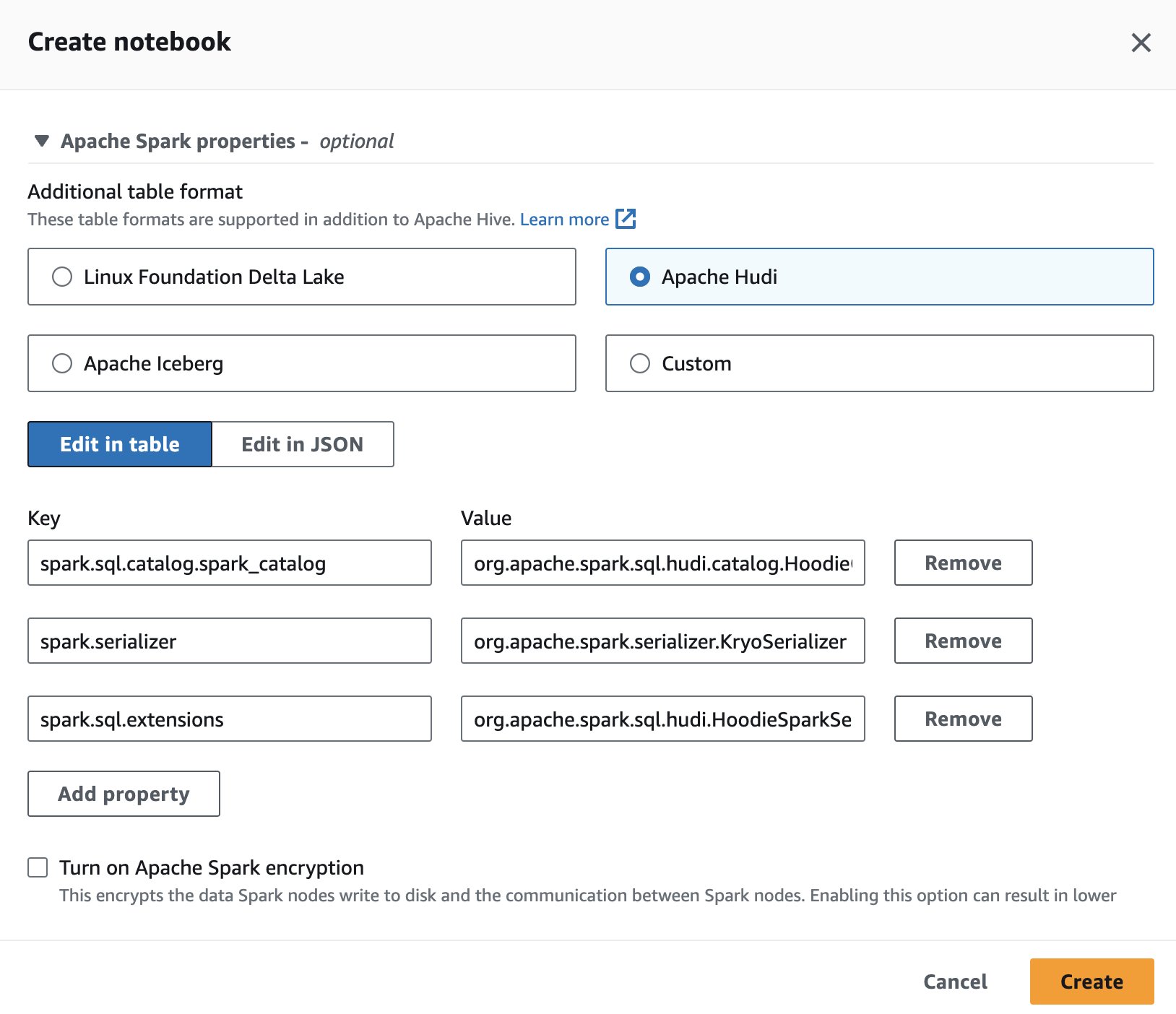
Etappide kohta vt Seansi üksikasjade redigeerimine or Oma märkmiku loomine.
Selles jaotises kasutatav kood peaks olema saadaval SparkSQL_hudi.ipynb fail, mida järgida.
Looge andmebaas ja Hudi tabel
Esiteks loome andmebaasi nimega hudidb mis salvestatakse AWS-i liimiandmete kataloogi, millele järgneb Hudi tabeli loomine:
Loome Hudi tabeli, mis osutab Amazon S3 asukohale, kus me andmed laadime. Pange tähele, et tabel on koopia kirjutamise kohta tüüp. Seda määratleb type= 'cow' tabelis DDL. Oleme määratlenud jaama ja kuupäeva mitme esmase võtmena ning preCombinedField kui aasta. Samuti on tabel jagatud aastate kaupa. Käivitage järgmine lause ja asendage asukoht s3://<your-S3-bucket>/<prefix>/ koos S3 ämbri ja eesliitega:
Sisestage andmed tabelisse
Nagu Icebergi puhul, kasutame ka SISSE avaldus tabeli täitmiseks, lugedes andmeid rakendusest sparkblogdb.noaa_pq eelmises postituses tehtud tabel:
Küsige Hudi tabelit
Nüüd, kui tabel on loodud, käivitame päringu, et leida maksimaalne registreeritud temperatuur 'SEATTLE TACOMA AIRPORT, WA US' asukoht:
Värskendage andmeid Hudi tabelis
Muudame jaama nime 'SEATTLE TACOMA AIRPORT, WA US' et 'Sea–Tac'. Saame Spark for Athena jaoks käivitada UPDATE avalduse ajakohastama kirjed noaa_hudi tabelis:
Käivitame eelmise SELECT päringu, et leida maksimaalne salvestatud temperatuur 'Sea-Tac' asukoht:
Käitage ajas reisimise päringuid
Varasemate andmete hetktõmmiste analüüsimiseks saame kasutada Athena SQL-is ajarännakute päringuid. Näiteks:
See päring kontrollib Seattle'i lennujaama temperatuuriandmeid kindlal varasemal ajal. Ajatempli klausel võimaldab meil reisida tagasi ilma praeguseid andmeid muutmata. Pange tähele, et ajatempli väärtus määratakse vormingus stringina yyyy-MM-dd HH:mm:ss.fff.
Päringu kiiruse optimeerimine klastrite abil
Päringu toimivuse parandamiseks saate sooritada Klastrite loomine Hudi tabelites, kasutades SQL-i rakenduses Spark for Athena:
Kompaktsed lauad
Tihendamine on tabeliteenus, mida Hudi kasutab spetsiaalselt Merge On Read (MOR) tabelites, et liita reapõhistest logifailidest värskendused perioodiliselt vastava veerupõhise baasfailiga, et luua põhifaili uus versioon. Tihendamine ei kehti Copy On Write (COW) tabelite puhul ja kehtib ainult MOR-tabelite kohta. MOR-tabelite tihendamiseks saate rakenduses Spark for Athena käivitada järgmise päringu:
Loobuge tabel ja andmebaas
Käivitage järgmine Spark SQL, et eemaldada loodud Hudi tabel ja seotud andmed Amazon S3 asukohast:
Andmebaasi eemaldamiseks käivitage järgmine Spark SQL hudidb:
Lisateavet kõigi toimingute kohta, mida saate Spark for Athena abil Hudi tabelites teha, leiate artiklist SQL DDL ja Protseduurid Hudi dokumentatsioonis.
Linux Foundationi Delta Lake tabelitega töötamine
Järgmisena näitame, kuidas saate Spark for Athena SQL-i kasutada Delta Lake'i tabelite loomiseks, analüüsimiseks ja haldamiseks.
Seadistage märkmiku seanss
Delta Lake'i kasutamiseks Spark for Athena seansi loomise või redigeerimise ajal valige Linuxi sihtasutus Delta Lake laiendades Apache Sparki omadused sektsiooni.
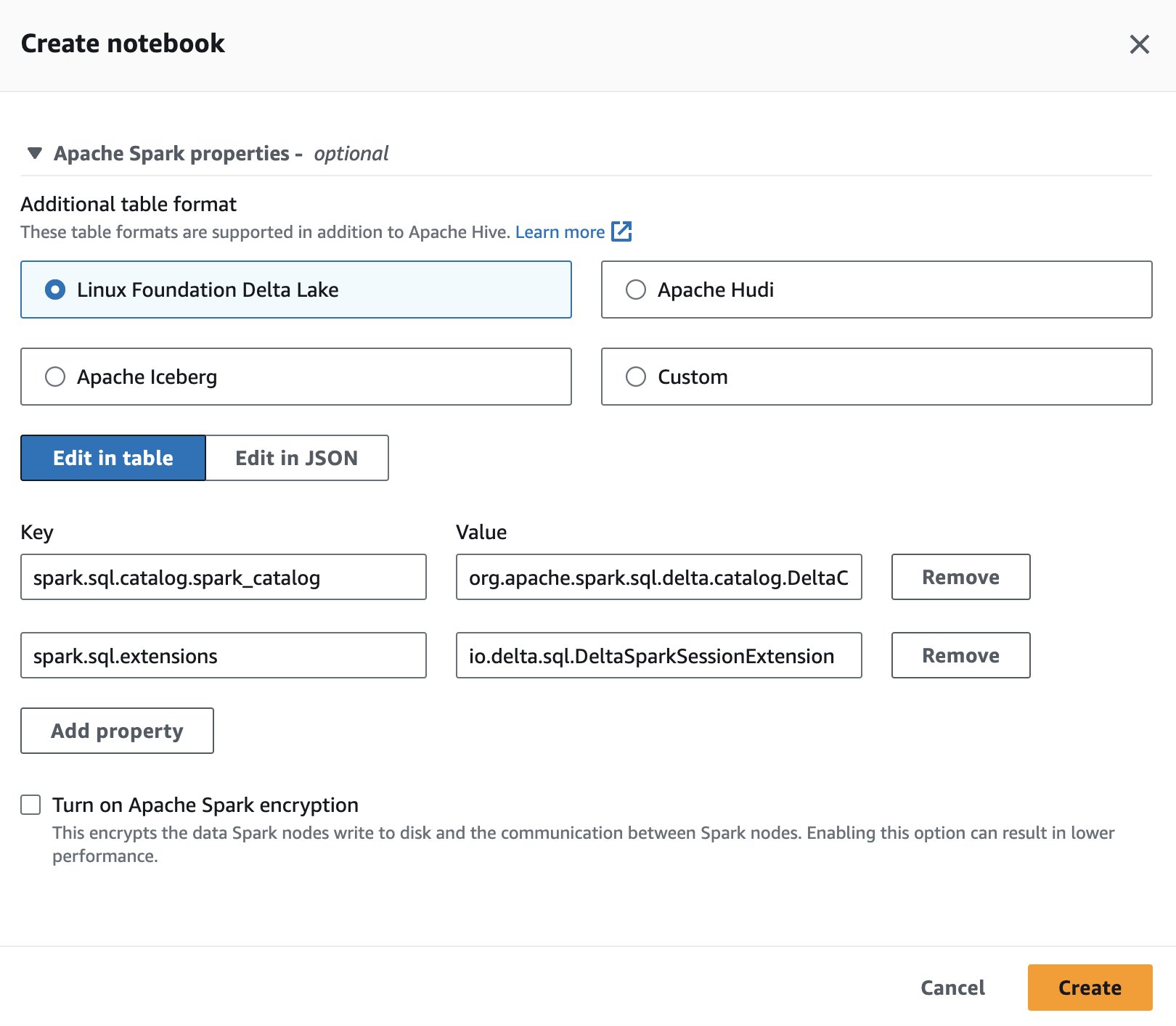
Etappide kohta vt Seansi üksikasjade redigeerimine or Oma märkmiku loomine.
Selles jaotises kasutatav kood peaks olema saadaval SparkSQL_delta.ipynb fail, mida järgida.
Looge andmebaas ja Delta Lake'i tabel
Selles jaotises loome andmebaasi AWS-i liimiandmete kataloogis. Kasutades järgmist SQL-i, saame luua andmebaasi nimega deltalakedb:
Järgmisena andmebaasis deltalakedb, loome Delta Lake'i tabeli nimega noaa_delta osutades Amazon S3 asukohale, kus me andmed laadime. Käivitage järgmine lause ja asendage asukoht s3://<your-S3-bucket>/<prefix>/ koos S3 ämbri ja eesliitega:
Sisestage andmed tabelisse
Kasutame SISSE avaldus tabeli täitmiseks, lugedes andmeid rakendusest sparkblogdb.noaa_pq eelmises postituses tehtud tabel:
Saate kasutada ka CREATE TABLE AS SELECT, et luua Delta Lake'i tabelit ja sisestada andmeid lähtetabelist ühes päringus.
Küsige Delta Lake'i tabelit
Nüüd, kui andmed on Delta Lake'i tabelisse sisestatud, saame hakata neid analüüsima. Käivitame Spark SQL-i, et leida minimaalne salvestatud temperatuur 'SEATTLE TACOMA AIRPORT, WA US' asukoht:
Uuenda andmeid Delta järve tabelis
Muudame jaama nime 'SEATTLE TACOMA AIRPORT, WA US' et 'Sea–Tac'. Me saame joosta UPDATE avaldus Spark for Athena kohta, et ajakohastada dokumendid noaa_delta tabelis:
Saame käivitada eelmise SELECT-päringu, et leida selle jaoks minimaalne salvestatud temperatuur 'Sea-Tac' asukoht ja tulemus peaks olema sama, mis varem:
Kompaktsed andmefailid
Rakenduses Spark for Athena saate Delta Lake'i tabelis käivitada funktsiooni OPTIMIZE, mis tihendab väikesed failid suuremateks failideks, nii et päringuid ei koormaks väikeste failide üldkulud. Tihendustoimingu tegemiseks käivitage järgmine päring:
Viitama Optimeerimised Delta Lake'i dokumentatsioonis, et näha erinevaid OPTIMIZE'i käivitamise ajal saadaolevaid valikuid.
Eemaldage failid, millele Delta Lake'i tabel enam ei viita
Saate eemaldada Amazon S3-sse salvestatud failid, millele Delta Lake'i tabel enam ei viita ja mis on säilituslävest vanemad, käivitades Spark for Athena abil tabelis käsu VACCUM.
Viitama Eemaldage failid, millele Delta tabel enam ei viita Delta Lake'i dokumentatsioonist VACUUMiga saadaolevate valikute kohta.
Loobuge tabel ja andmebaas
Käivitage loodud Delta Lake'i tabeli eemaldamiseks järgmine Spark SQL:
Andmebaasi eemaldamiseks käivitage järgmine Spark SQL deltalakedb:
DROP TABLE DDL-i käivitamine Delta Lake'i tabelis ja andmebaasis kustutab nende objektide metaandmed, kuid ei kustuta automaatselt Amazon S3 andmefaile. Andmete kustutamiseks asukohast S3 saate sülearvuti lahtris käivitada järgmise Pythoni koodi:
Lisateavet SQL-lausete kohta, mida saate Delta Lake'i tabelis Spark for Athena abil käivitada, leiate kiire algus Delta Lake'i dokumentatsioonis.
Järeldus
See postitus näitas, kuidas kasutada Spark SQL-i Athena sülearvutites andmebaaside ja tabelite loomiseks, andmete sisestamiseks ja päringute tegemiseks ning tavapäraste toimingute tegemiseks, nagu värskendused, tihendamine ja ajarännak Hudi, Delta Lake'i ja Icebergi tabelites. Avatud tabelivormingud lisavad andmejärvedesse ACID-tehinguid, katkestusi ja kustutamisi, ületades toorobjektide salvestamise piirangud. Eemaldades vajaduse paigaldada eraldi pistikud, vähendab Spark on Athena sisseehitatud integratsioon konfiguratsioonietappe ja halduskulusid, kui kasutate neid populaarseid raamistikke Amazon S3 usaldusväärsete andmejärvede loomiseks. Andmejärve töökoormuste jaoks avatud tabelivormingu valimise kohta lisateabe saamiseks vaadake AWS-i tehinguandmete järve jaoks avatud tabelivormingu valimine.
Autoritest
![]() Pathik Shah on Amazon Athena vanem Analyticsi arhitekt. Ta liitus AWS-iga 2015. aastal ja on sellest ajast alates keskendunud suurandmete analüüsiruumile, aidates klientidel luua AWS-i analüüsiteenuseid kasutades skaleeritavaid ja töökindlaid lahendusi.
Pathik Shah on Amazon Athena vanem Analyticsi arhitekt. Ta liitus AWS-iga 2015. aastal ja on sellest ajast alates keskendunud suurandmete analüüsiruumile, aidates klientidel luua AWS-i analüüsiteenuseid kasutades skaleeritavaid ja töökindlaid lahendusi.
![]() Raj Devnath on Amazon Athena AWS-i tootejuht. Ta on kirglik klientidele meeldivate toodete valmistamise vastu ja aitab klientidel nende andmetest väärtust ammutada. Tema taust on lahenduste tarnimine mitmetele lõppturgudele, nagu rahandus, jaemüük, nutikad hooned, koduautomaatika ja andmesidesüsteemid.
Raj Devnath on Amazon Athena AWS-i tootejuht. Ta on kirglik klientidele meeldivate toodete valmistamise vastu ja aitab klientidel nende andmetest väärtust ammutada. Tema taust on lahenduste tarnimine mitmetele lõppturgudele, nagu rahandus, jaemüük, nutikad hooned, koduautomaatika ja andmesidesüsteemid.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/
- :on
- :on
- :mitte
- : kus
- $ UP
- 000
- 1
- 10
- 100
- 107
- 11
- 12
- 13
- 16
- 2015
- 2023
- 23
- 300
- 41
- 43
- 53
- 58
- 7
- 8
- 9
- a
- MEIST
- juurdepääs
- lisama
- edasijõudnud
- vastu
- lennujaam
- Materjal: BPA ja flataatide vaba plastik
- mööda
- Ka
- Amazon
- Amazonase Athena
- Amazon Web Services
- summa
- an
- analytics
- analüüsima
- analüüsides
- ja
- teatas
- Apache
- Apache Spark
- kohaldatav
- rakendused
- kehtib
- lähenemisviisid
- OLEME
- ümber
- AS
- seotud
- At
- automaatselt
- Automaatika
- kättesaadavus
- saadaval
- AWS
- AWS liim
- tagasi
- tagapõhi
- baas
- BE
- olnud
- käitumine
- Suur
- Big andmed
- ehitama
- Ehitus
- ehitatud
- sisseehitatud
- äri
- kuid
- by
- helistama
- kutsutud
- CAN
- kataloog
- Põhjus
- rakk
- muutma
- Vaidluste lahendamine
- Kontroll
- puhastama
- kood
- ühendama
- kombineerimine
- ühine
- KOMMUNIKATSIOON
- sidesüsteemid
- kompaktne
- võrdlus
- konfiguratsioon
- järjepidev
- sisu
- Vastav
- kulud
- loe
- looma
- loodud
- loob
- loomine
- loomine
- Praegune
- Kliendid
- andmed
- Andmete analüüs
- andmejärv
- andmetöötlus
- andmelaod
- andmebaas
- andmebaasid
- kuupäev
- määratletud
- edastamine
- Delta
- näitama
- Näidatud
- sõltuvused
- erinev
- otse
- arutatud
- do
- dokumentatsioon
- Ei tee
- lae alla
- Drop
- vastupidavus
- iga
- Ajalugu
- toimetamine
- tõhus
- jõupingutusi
- töötavad
- võimaldama
- lõpp
- tagama
- Kogu
- keskkond
- Eeter (ETH)
- sündmused
- näide
- Teostama
- laiendades
- väljavõte
- FUNKTSIOONID
- fail
- Faile
- rahastama
- leidma
- esimene
- Paindlikkus
- keskendumine
- järgima
- Järgneb
- Järel
- eest
- formaat
- Sihtasutus
- raamistikud
- Alates
- funktsionaalsus
- Üldine
- saama
- Andma
- Grupp
- Kasvavad
- kasvanud
- käepide
- Olema
- võttes
- he
- päised
- aitama
- aidates
- hh
- Suur
- rohkem
- tema
- Avaleht
- Home Automation
- Kuidas
- Kuidas
- HTML
- http
- HTTPS
- pilt
- tööriistad
- import
- parandama
- in
- kasvav
- paigaldama
- integratsioon
- huvitatud
- Interface
- sisse
- isolatsioon
- IT
- liitunud
- jpg
- hoidma
- pidamine
- võtmed
- järv
- järved
- suurem
- laius
- Leads
- Õppida
- vähem
- Lets
- nagu
- piirangud
- Linux
- Linuxi sihtasutus
- nimekiri
- koormus
- liising
- kohad
- logi
- enam
- Vaata
- otsin
- armastus
- maagiline
- juhtima
- juhtimine
- juht
- viis
- palju
- turud
- max
- maksimaalne
- Merge
- Metaandmed
- minutit
- miinimum
- rohkem
- mitmekordne
- nimi
- natiivselt
- Navigate
- Vajadus
- vaja
- mitte kunagi
- Uus
- ei
- meeles
- märkmik
- märkmikud
- number
- objekt
- Objekti salvestamine
- esemeid
- of
- Pakkumised
- sageli
- Vana
- vanem
- on
- ONE
- ainult
- OP
- avatud
- avatud lähtekoodiga
- töö
- Operations
- optimeerima
- valik
- Valikud
- or
- et
- meie
- väljund
- ülesaamine
- enda
- osa
- kirglik
- minevik
- täitma
- jõudlus
- Platon
- Platoni andmete intelligentsus
- PlatoData
- populaarne
- post
- eeldused
- eelmine
- varem
- esmane
- menetlus
- töötlemine
- tootma
- Toode
- tootejuht
- Toodet
- omadused
- Python
- päringud
- Rates
- Töötlemata
- Lugenud
- Lugemine
- soovitatav
- dokumenteeritud
- andmed
- vähendab
- viitama
- viidatud
- usaldusväärne
- kõrvaldama
- eemaldab
- eemaldades
- asendama
- nõutav
- kaasa
- tulemuseks
- jaemüük
- säilitamine
- jõuline
- jooks
- jooksmine
- sama
- skaalautuvia
- Skaala
- Seattle
- Teine
- Osa
- vaata
- valima
- valides
- eri
- teenus
- teenused
- istung
- komplekt
- peaks
- näitama
- näidatud
- Näitused
- märkimisväärne
- lihtne
- lihtsustab
- lihtsustama
- alates
- SUURUS
- veidi erinev
- SLP
- väike
- väiksem
- nutikas
- Snapshot
- So
- Lahendused
- allikas
- Ruum
- Säde
- eriline
- konkreetse
- eriti
- määratletud
- kiirus
- kiirused
- kasutatud
- SQL
- algus
- väljavõte
- avaldused
- jaam
- Samm
- Sammud
- Veel
- ladustamine
- salvestada
- ladustatud
- Strateegia
- nöör
- selline
- Toetatud
- süsteem
- süsteemid
- tabel
- Tacoma
- kui
- et
- .
- oma
- Neile
- SIIS
- Need
- see
- künnis
- Läbi
- aeg
- ajas rännata
- ajatempel
- et
- Jälgimine
- tehinguline
- Tehingud
- reisima
- tüüp
- võrreldamatu
- Värskendused
- ajakohastatud
- Uudised
- us
- Kasutus
- kasutama
- Kasutatud
- kasutamine
- vaakum
- väärtus
- versioon
- versioonid
- tahan
- oli
- kuidas
- we
- web
- veebiteenused
- olid
- millal
- mis
- kuigi
- will
- koos
- ilma
- Töö
- kirjutama
- aasta
- sa
- Sinu
- sephyrnet