Amazon SageMaker Studio pakub andmeteadlastele täielikult hallatavat lahendust masinõppe (ML) mudelite interaktiivseks koostamiseks, koolitamiseks ja juurutamiseks. Amazon SageMakeri sülearvutite töökohad lubage andmeteadlastel mõne klõpsuga SageMaker Studios oma märkmikke nõudmisel või ajakava järgi käivitada. Selle käivitamisega saate sülearvutite pakutavate API-de abil programmiliselt käitada töödena Amazon SageMakeri torujuhtmed, ML-i töövoo orkestreerimise funktsioon Amazon SageMaker. Lisaks saate neid API-sid kasutades luua mitmeastmelise ML-i töövoo mitme sõltuva sülearvutiga.
SageMaker Pipelines on natiivne töövoo orkestreerimise tööriist ML-konveierite loomiseks, mis kasutavad ära otsest SageMakeri integratsiooni. Iga SageMakeri torujuhe koosneb samme, mis vastavad üksikutele ülesannetele, nagu töötlemine, koolitus või andmetöötlus, kasutades Amazon EMR. SageMakeri sülearvutitööd on nüüd saadaval SageMakeri torujuhtmetes sisseehitatud sammutüübina. Saate kasutada seda sülearvuti tööetappi, et hõlpsasti käivitada märkmikud vaid mõne koodireaga töödena, kasutades funktsiooni Amazon SageMaker Python SDK. Lisaks saate mitu sõltuvat märkmikku kokku liita, et luua töövoog suunatud atsükliliste graafikute (DAG) kujul. Seejärel saate neid märkmikutöid või DAG-e käitada ning neid SageMaker Studio abil hallata ja visualiseerida.
Andmeteadlased kasutavad praegu SageMaker Studiot oma Jupyteri sülearvutite interaktiivseks arendamiseks ja seejärel kasutavad SageMakeri märkmikutöid nende märkmike ajastatud töödena käitamiseks. Neid töid saab käivitada kohe või korduva ajakava alusel, ilma et andmetöötajad peaksid kodeerima Pythoni moodulitena. Mõned levinumad kasutusjuhud selle tegemiseks on järgmised:
- Taustal pikkade jooksvate märkmike jooksmine
- Regulaarselt töötav mudeli järeldus aruannete loomiseks
- Suurendamine väikeste näidisandmekogumite ettevalmistamiselt petabaitide ulatusega suurandmetega töötamiseks
- Mudelite ümberõpe ja juurutamine teatud kadentsil
- Tööde ajastamine mudeli kvaliteedi või andmete triivi jälgimiseks
- Paremate mudelite parameetriruumi uurimine
Kuigi see funktsioon muudab andmetöötajate jaoks iseseisvate sülearvutite automatiseerimise lihtsaks, koosnevad ML-i töövood sageli mitmest sülearvutist, millest igaüks täidab spetsiifilist ülesannet ja keerukate sõltuvustega. Näiteks mudeliandmete triivimist jälgival sülearvutil peaks olema eeletapp, mis võimaldab uute andmete ekstraktimist, teisendamist ja laadimist (ETL) ja töötlemist ning mudeli värskendamise ja koolituse järgne etapp juhul, kui märkate märkimisväärset triivi. . Lisaks võivad andmeteadlased soovida käivitada kogu selle töövoo korduva ajakava alusel, et mudelit uute andmete põhjal värskendada. Et saaksite oma märkmikke hõlpsalt automatiseerida ja selliseid keerulisi töövooge luua, on SageMakeri märkmikutööd nüüd SageMakeri torujuhtmete etapina saadaval. Selles postituses näitame, kuidas saate mõne koodirea abil lahendada järgmised kasutusjuhtumid:
- Käitage eraldiseisvat sülearvutit programmiliselt kohe või korduva ajakava alusel
- Looge sülearvutite mitmeastmelisi töövooge DAG-idena pidevaks integreerimiseks ja pidevaks edastamiseks (CI/CD), mida saab hallata SageMaker Studio kasutajaliidese kaudu
Lahenduse ülevaade
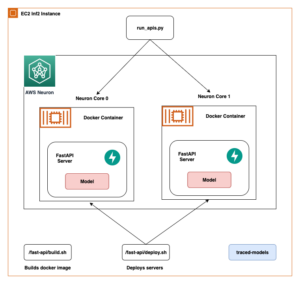
Järgmine diagramm illustreerib meie lahenduse arhitektuuri. Saate kasutada SageMaker Python SDK-d ühe märkmiku töö või töövoo käitamiseks. See funktsioon loob sülearvuti käitamiseks SageMakeri koolitustöö.
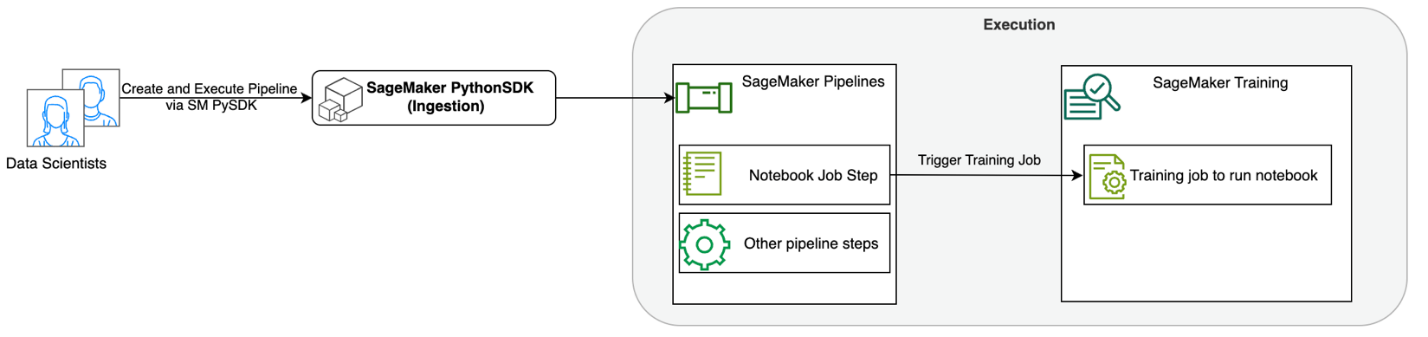
Järgmistes jaotistes käsitleme ML-i näidisjuhtumit ja tutvustame märkmikutööde töövoo loomise samme, parameetrite edastamist erinevate sülearvuti sammude vahel, töövoo ajastamist ja selle jälgimist SageMaker Studio kaudu.
Selles näites esitatud ML-probleemi jaoks loome sentimentanalüüsi mudeli, mis on teatud tüüpi teksti klassifitseerimise ülesanne. Levinumad sentimentanalüüsi rakendused on sotsiaalmeedia jälgimine, klienditoe haldamine ja klientide tagasiside analüüsimine. Selles näites kasutatav andmestik on Stanford Sentiment Treebanki (SST2) andmestik, mis koosneb filmiarvustustest koos täisarvuga (0 või 1), mis näitab arvustuse positiivset või negatiivset suhtumist.
Järgnev on näide a data.csv SST2 andmestikule vastav fail ja näitab väärtusi selle kahes esimeses veerus. Pange tähele, et failil ei tohiks olla päist.
| 1. veerg | 2. veerg |
| 0 | peita uusi eritisi vanemüksuste eest |
| 0 | ei sisalda teravmeelsust, ainult vaevarikkaid näpunäiteid |
| 1 | mis armastab oma tegelasi ja edastab inimloomuse kohta midagi üsna ilusat |
| 0 | on täiesti rahul, et jääb kogu aeg samaks |
| 0 | kõige hullemate nohikute kättemaksu klišeede kohta, mida filmitegijad võiksid välja kaevata |
| 0 | see on liiga traagiline, et sellist pealiskaudset kohtlemist väärida |
| 1 | näitab, et selliste hollywoodi kassahittide nagu patriootmängud režissöörist saab ikkagi väikese, isikliku ja emotsionaalse müraga filmi. |
Selles ML-i näites peame täitma mitu ülesannet:
- Tehke funktsioonide projekteerimine, et koostada see andmestik meie mudelile arusaadavas vormingus.
- Pärast funktsioonide väljatöötamist viige läbi koolitusetapp, mis kasutab Transformereid.
- Seadistage peenhäälestatud mudeli abil partii järeldused, et aidata ennustada uute arvustuste suhtumist.
- Seadistage andmete jälgimise samm, et saaksime oma uusi andmeid regulaarselt jälgida kvaliteedimuutuste suhtes, mis võivad nõuda mudelite kaalude ümberõpet.
Selle sülearvuti töö käivitamisega SageMakeri torujuhtmete etapina saame korraldada selle töövoo, mis koosneb kolmest erinevast etapist. Iga töövoo etapp töötatakse välja erinevas märkmikus, mis seejärel teisendatakse iseseisvateks sülearvutitööde etappideks ja ühendatakse torujuhtmena.
- Eeltöötlus – Laadige alla avalik SST2 andmestik aadressilt Amazoni lihtne salvestusteenus (Amazon S3) ja looge 2. sammus märkmiku jaoks CSV-fail, et seda käitada. SST2 andmestik on tekstiklassifikatsiooni andmestik, millel on kaks silti (0 ja 1) ja kategoriseeritav tekstiveerg.
- koolitus – Võtke vormitud CSV-fail ja viige BERT-iga peenhäälestus teksti klassifitseerimiseks, kasutades Transformersi teeke. Selle etapi osana kasutame testandmete ettevalmistamise märkmikku, mis on peenhäälestuse ja partii järelduse etapi sõltuvus. Kui peenhäälestus on lõpule viidud, käivitatakse see sülearvuti Run Magic abil ja see valmistab ette testandmestiku peenhäälestatud mudeli näidistuletuste tegemiseks.
- Muutke ja jälgige – Tehke partii järeldused ja seadistage andmete kvaliteet mudeli jälgimisega, et saada lähteandmestiku soovitust.
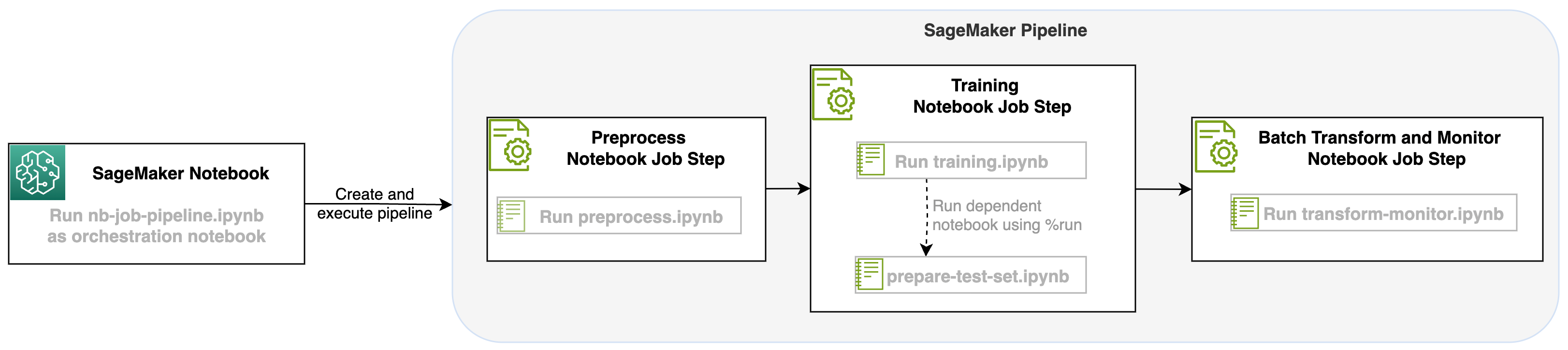
Käivitage märkmikud
Selle lahenduse näidiskood on saadaval aadressil GitHub.
SageMakeri märkmiku tööetapi loomine sarnaneb teiste SageMaker Pipeline'i etappide loomisega. Selles märkmiku näites kasutame töövoo korraldamiseks SageMaker Python SDK-d. Märkmiku sammu loomiseks rakenduses SageMaker Pipelines saate määratleda järgmised parameetrid.
- Sisendmärkmik – selle märkmiku nimi, mida see märkmiku etapp orkestreerib. Siin saate liikuda kohaliku tee sisendmärkmikusse. Kui sellel sülearvutil on muid märkmikke, mida see töötab, saate need valikuliselt edastada
AdditionalDependenciesparameeter sülearvuti tööetapi jaoks. - Pildi URI – Dockeri pilt sülearvuti tööetapi taga. See võib olla eelmääratletud pildid, mida SageMaker juba pakub, või kohandatud pilt, mille olete määratlenud ja kuhu edasi lükanud Amazoni elastsete konteinerite register (Amazon ECR). Toetatud piltide kohta vaadake selle postituse lõpus olevat kaalutluste jaotist.
- Kerneli nimi – SageMaker Studios kasutatava kerneli nimi. See kerneli spetsifikatsioon on registreeritud teie esitatud pildil.
- Eksemplari tüüp (valikuline) - Amazon Elastic Compute Cloud (Amazon EC2) eksemplari tüüp teie määratletud ja käivitatava sülearvuti töö taga.
- Parameetrid (valikuline) - Parameetrid, mille saate edastada, on teie sülearvuti jaoks juurdepääsetavad. Neid saab määratleda võtme-väärtuse paaridena. Lisaks saab neid parameetreid muuta erinevate sülearvuti töökäituste või konveieri käituste vahel.
Meie näites on kokku viis märkmikku:
- nb-job-pipeline.ipynb – See on meie peamine märkmik, kus me määratleme oma konveieri ja töövoo.
- eeltöötlus.ipynb – See märkmik on meie töövoo esimene samm ja sisaldab koodi, mis tõmbab avaliku AWS-i andmestiku ja loob sellest CSV-faili.
- koolitus.ipynb – See märkmik on meie töövoo teine samm ja sisaldab koodi, et võtta eelmisest etapist CSV-fail ning viia läbi kohalik koolitus ja peenhäälestus. Sellel sammul on ka sõltuvus
prepare-test-set.ipynbsülearvuti, et tõmmata alla testandmekogum, et teha peenhäälestatud mudeli põhjal järeldusi. - ettevalmistus-test-set.ipynb – See märkmik loob testandmestiku, mida meie koolitusmärkmik kasutab teises konveieri etapis ja kasutab täppishäälestatud mudeli põhjal järelduste tegemiseks.
- transform-monitor.ipynb – See sülearvuti on meie töövoo kolmas samm ja kasutab BERT-i baasmudelit ja käitab SageMakeri pakkteisendustööd, seadistades samal ajal ka andmete kvaliteedi mudeli jälgimisega.
Järgmisena astume läbi põhimärkmiku nb-job-pipeline.ipynb, mis ühendab kõik alammärkmikud konveieriks ja käivitab täieliku töövoo. Pange tähele, et kuigi järgmine näide käivitab märkmiku ainult ühe korra, saate ka ajastada konveieri märkmiku korduvaks käitamiseks. Viitama SageMakeri dokumentatsioon üksikasjalike juhiste saamiseks.
Sülearvuti töö esimese etapi jaoks edastame parameetri vaikimisi S3 ämbriga. Saame kasutada seda ämbrit, et tühjendada kõik artefaktid, mida tahame saadaolevaks meie torujuhtme muude etappide jaoks. Esimese märkmiku jaoks (preprocess.ipynb), tõmbame alla AWS-i avaliku SST2 rongiandmestiku ja loome sellest koolitus-CSV-faili, mille edastame sellesse S3 ämbrisse. Vaadake järgmist koodi:
Seejärel saame selle märkmiku teisendada a NotebookJobStep järgmise koodiga meie põhimärkmikus:
Nüüd, kui meil on CSV-faili näidis, saame alustada oma mudeli treenimist oma koolitusmärkmikus. Meie treeningmärkmik võtab sama parameetri S3 ämbriga ja tõmbab treeninguandmestiku sellest asukohast alla. Seejärel teostame peenhäälestuse, kasutades Transformersi treeneri objekti koos järgmise koodilõiguga:
Pärast peenhäälestamist tahame käivitada pakettjärelduse, et näha, kuidas mudel toimib. Seda tehakse eraldi märkmiku abil (prepare-test-set.ipynb) samal kohalikul teel, mis loob testandmestiku, et teha järeldusi meie koolitatud mudeli kasutamise kohta. Täiendavat märkmikku saame käitada oma koolitusmärkmikus järgmise võlulahtriga:
Määratleme selle sülearvuti lisasõltuvuse jaotises AdditionalDependencies parameeter meie sülearvuti teises etapis:
Samuti peame täpsustama, et sülearvuti koolitamise tööetapp (2. samm) sõltub sülearvuti eeltöötluse etapist (1. samm), kasutades add_depends_on API kutse järgmiselt:
Viimase sammuna käivitame BERT-i mudelil SageMakeri partii teisenduse, seadistades samal ajal andmete püüdmise ja kvaliteedi SageMakeri mudelimonitori kaudu. Pange tähele, et see erineb sisseehitatud seadme kasutamisest Muutma or hõive sammud torujuhtmete kaudu. Meie selle sammu märkmik käivitab samu API-sid, kuid seda jälgitakse kui sülearvuti tööetappi. See samm sõltub koolitustöö etapist, mille me eelnevalt määratlesime, seega jäädvustame selle ka lipuga addict_on.
Kui meie töövoo erinevad etapid on määratletud, saame luua ja käivitada otsast lõpuni torujuhtme:
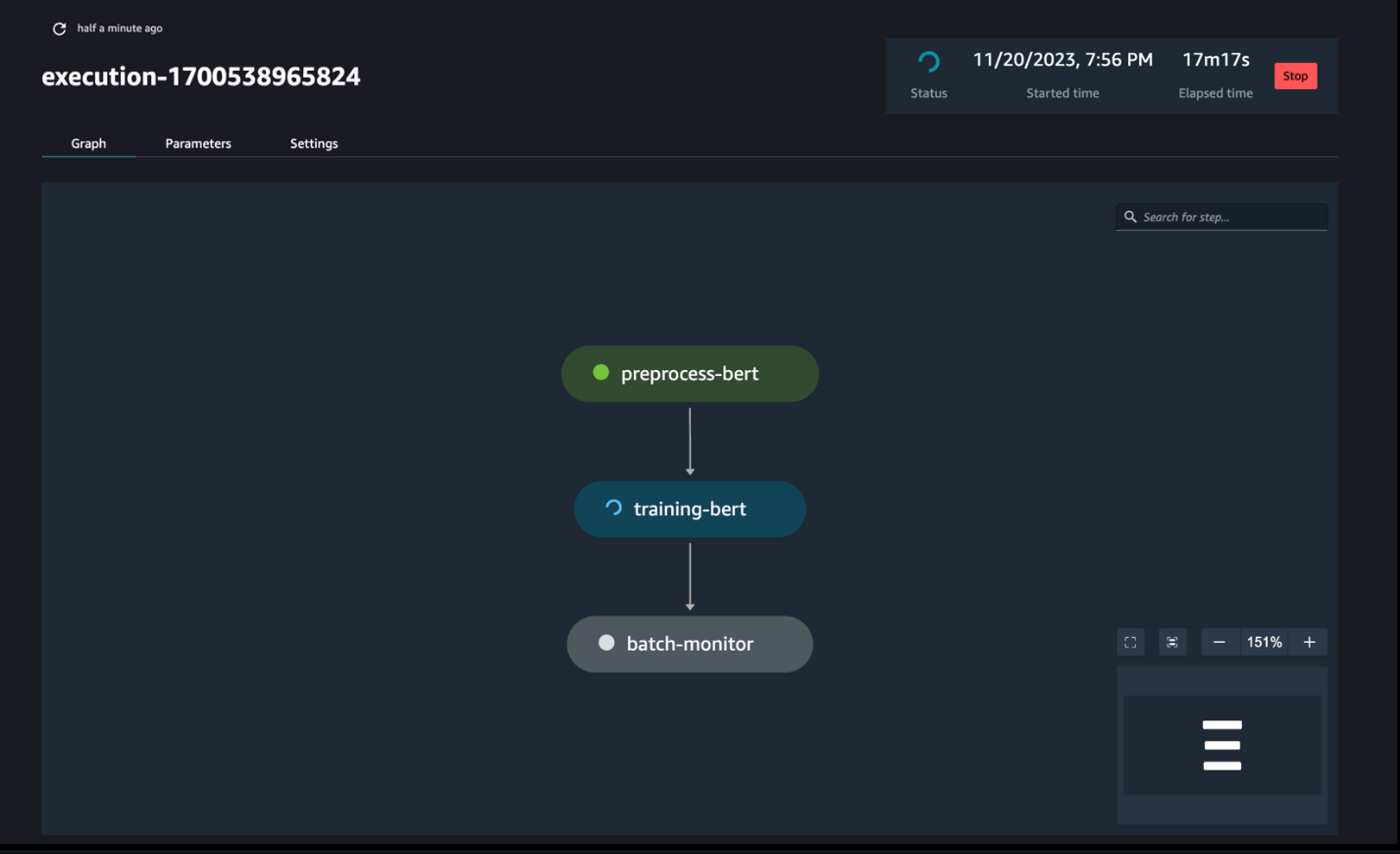
Jälgige torujuhtme käitamist
Saate jälgida ja jälgida sülearvuti sammude käitamist SageMaker Pipelines DAG kaudu, nagu on näha järgmisel ekraanipildil.
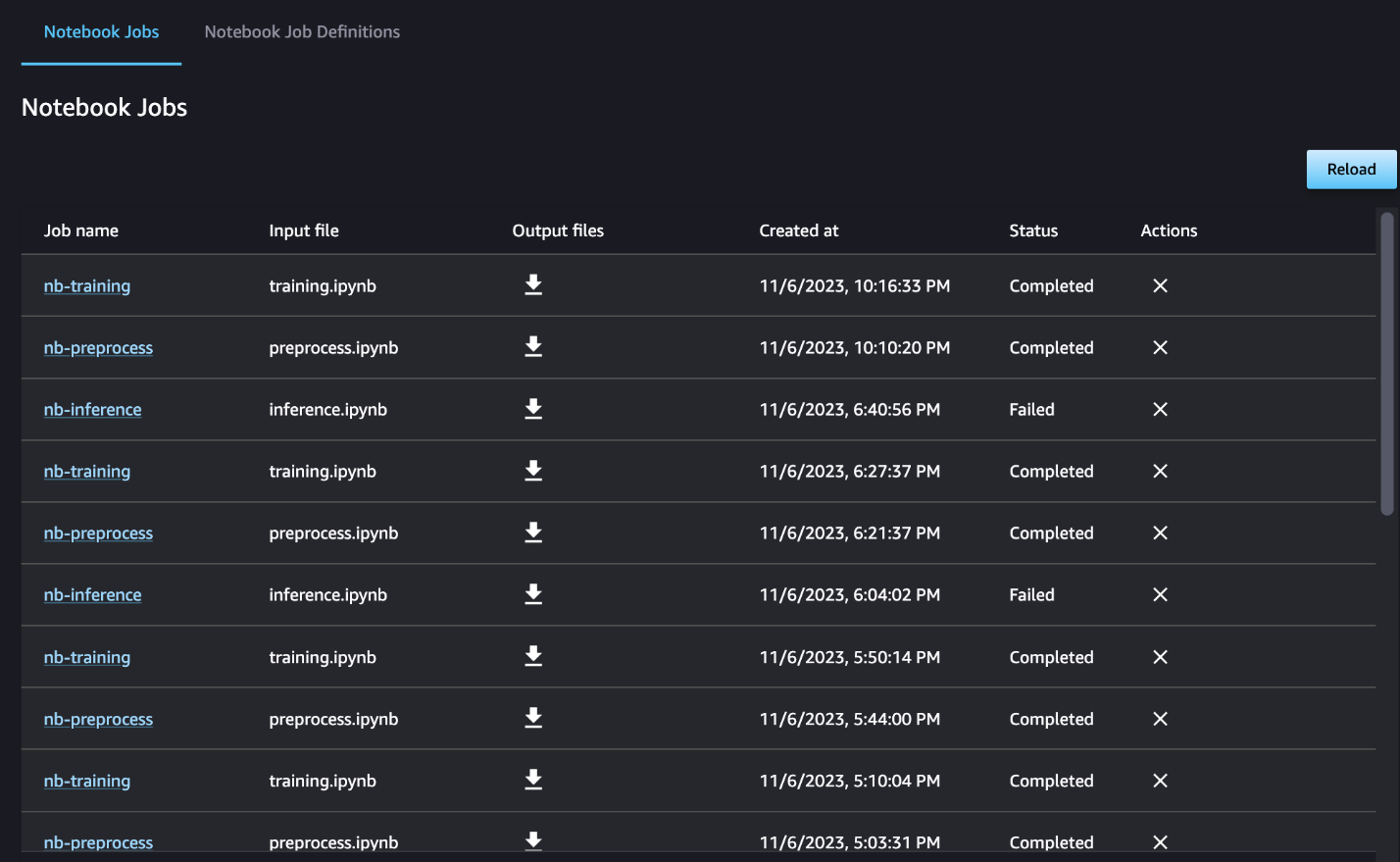
Samuti saate valikuliselt jälgida üksikuid märkmikutöid sülearvuti töö armatuurlaual ja lülitada SageMaker Studio kasutajaliidese kaudu loodud väljundfaile. Kui kasutate seda funktsiooni väljaspool SageMaker Studiot, saate märgendite abil määrata kasutajad, kes saavad märkmiku töö armatuurlaual tööolekut jälgida. Lisatavate siltide kohta lisateabe saamiseks vt Studio kasutajaliidese armatuurlaual saate vaadata sülearvuti töid ja alla laadida väljundeid.
Selle näite puhul väljastame saadud märkmikutööd kataloogi nimega outputs oma kohalikul teel oma konveieri käitamiskoodiga. Nagu on näidatud järgmisel ekraanipildil, näete siin oma sisendmärkmiku väljundit ja ka kõiki selle sammu jaoks määratletud parameetreid.
Koristage
Kui järgisite meie näidet, kustutage kindlasti loodud konveier, märkmikutööd ja näidismärkmike allalaaditud s3 andmed.
Kaalutlused
Selle funktsiooni puhul on mõned olulised kaalutlused järgmised.
- SDK piirangud – Sülearvuti tööetapi saab luua ainult SageMaker Python SDK kaudu.
- Pildi piirangud – Sülearvuti tööetapp toetab järgmisi kujutisi.
Järeldus
Selle käivitamisega saavad andmetöötajad nüüd programmiliselt käitada oma märkmikke mõne koodireaga, kasutades SageMaker Python SDK. Lisaks saate oma sülearvutite abil luua keerukaid mitmeastmelisi töövooge, vähendades oluliselt aega, mis kulub sülearvutilt CI/CD konveierile üleminekuks. Pärast konveieri loomist saate kasutada SageMaker Studiot oma torujuhtmete DAG-ide vaatamiseks ja käitamiseks ning käitamiste haldamiseks ja võrdlemiseks. Olenemata sellest, kas plaanite täielikke ML-i töövooge või osa sellest, soovitame teil proovida märkmikupõhised töövood.
Autoritest
 Anchit Gupta on Amazon SageMaker Studio vanem tootejuht. Ta keskendub interaktiivsete andmeteaduse ja andmetehnika töövoogude võimaldamisele SageMaker Studio IDE-s. Vabal ajal meeldib talle süüa teha, laua-/kaardimänge mängida ja lugeda.
Anchit Gupta on Amazon SageMaker Studio vanem tootejuht. Ta keskendub interaktiivsete andmeteaduse ja andmetehnika töövoogude võimaldamisele SageMaker Studio IDE-s. Vabal ajal meeldib talle süüa teha, laua-/kaardimänge mängida ja lugeda.
 Ram Vegiraju on SageMaker Service meeskonnaga ML arhitekt. Ta keskendub sellele, et aidata klientidel luua ja optimeerida oma AI/ML-lahendusi Amazon SageMakeris. Vabal ajal armastab ta reisimist ja kirjutamist.
Ram Vegiraju on SageMaker Service meeskonnaga ML arhitekt. Ta keskendub sellele, et aidata klientidel luua ja optimeerida oma AI/ML-lahendusi Amazon SageMakeris. Vabal ajal armastab ta reisimist ja kirjutamist.
 Edward Päike on vanem SDE, kes töötab Amazon Web Servicesis SageMaker Studios. Ta on keskendunud interaktiivse ML-lahenduse loomisele ja kliendikogemuse lihtsustamisele, et integreerida SageMaker Studio populaarsete tehnoloogiatega andmetöötluses ja ML-ökosüsteemis. Vabal ajal on Edward suur telkimise, matkamise ja kalapüügi fänn ning naudib perega koos veedetud aega.
Edward Päike on vanem SDE, kes töötab Amazon Web Servicesis SageMaker Studios. Ta on keskendunud interaktiivse ML-lahenduse loomisele ja kliendikogemuse lihtsustamisele, et integreerida SageMaker Studio populaarsete tehnoloogiatega andmetöötluses ja ML-ökosüsteemis. Vabal ajal on Edward suur telkimise, matkamise ja kalapüügi fänn ning naudib perega koos veedetud aega.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/machine-learning/schedule-amazon-sagemaker-notebook-jobs-and-manage-multi-step-notebook-workflows-using-apis/
- :on
- :on
- : kus
- $ UP
- 1
- 100
- 116
- 125
- 15%
- 17
- 20
- 500
- 7
- 8
- a
- MEIST
- juurdepääsetav
- atsükliline
- Täiendavad lisad
- Lisaks
- ADEelis
- pärast
- AI / ML
- Materjal: BPA ja flataatide vaba plastik
- võimaldab
- mööda
- juba
- Ka
- Kuigi
- Amazon
- Amazon EC2
- Amazon SageMaker
- Amazon SageMaker Studio
- Amazon Web Services
- an
- analüüs
- analüüsides
- ja
- mistahes
- API
- API-liidesed
- rakendused
- arhitektuur
- OLEME
- AS
- At
- automatiseerima
- saadaval
- AWS
- baas
- põhineb
- Baseline
- BE
- ilus
- olnud
- taga
- on
- Parem
- vahel
- Suur
- ehitama
- Ehitus
- sisseehitatud
- kuid
- by
- helistama
- kutsutud
- telkimine
- CAN
- lüüa
- juhul
- juhtudel
- rakk
- märki
- klassifikatsioon
- kood
- Veerg
- Veerud
- ühendab
- Tulema
- ühine
- võrdlema
- täitma
- keeruline
- koostatud
- Koosneb
- Arvutama
- Läbi viima
- seotud
- kaalutlused
- koosneb
- Konteiner
- sisaldab
- pidev
- muutma
- ümber
- cooking
- Vastav
- võiks
- looma
- loodud
- loob
- loomine
- Praegu
- tava
- klient
- Kliendi kogemus
- Klienditugi
- Kliendid
- DAG
- armatuurlaud
- andmed
- andmete jälgimine
- Andmete ettevalmistamine
- andmetöötlus
- andmete kvaliteedi
- andmeteadus
- andmekogumid
- vaikimisi
- määratlema
- määratletud
- tarne
- Nõudlus
- sõltuvused
- Sõltuvus
- sõltuv
- sõltub
- juurutada
- juurutamine
- üksikasjalik
- detailid
- arendama
- arenenud
- erinev
- otsene
- suunatud
- Juhataja
- eristatav
- laevalaadija
- teeme
- tehtud
- alla
- lae alla
- maha kallama
- iga
- kergesti
- ökosüsteemi
- Edward
- võimaldama
- võimaldades
- julgustama
- lõpp
- Lõpuks-lõpuni
- Inseneriteadus
- Kogu
- epohh
- Eeter (ETH)
- näide
- täitma
- täitmine
- kogemus
- lisatasu
- väljavõte
- pere
- lehvikut
- kaugele
- tunnusjoon
- tagasiside
- vähe
- fail
- Faile
- Film
- filmitegijad
- esimene
- kalastamine
- viis
- keskendunud
- keskendub
- Järgneb
- Järel
- järgneb
- eest
- vorm
- formaat
- Alates
- täielikult
- funktsionaalsus
- Pealegi
- Mängud
- tekitama
- graafikud
- Olema
- he
- aitama
- aidates
- siin
- siin
- matkamine
- tema
- Hollywood
- Kuidas
- HTML
- http
- HTTPS
- inim-
- if
- illustreerib
- pilt
- pildid
- kohe
- import
- oluline
- in
- sisaldama
- sõltumatud
- näitab
- eraldi
- sisend
- Näiteks
- juhised
- integreerima
- integratsioon
- interaktiivne
- sisse
- IT
- ITS
- töö
- Tööturg
- jpg
- lihtsalt
- silt
- Labels
- viimane
- algatama
- õppimine
- raamatukogud
- joon
- liinid
- koormus
- kohalik
- liising
- Pikk
- armastab
- masin
- masinõpe
- maagiline
- põhiline
- TEEB
- juhtima
- juhitud
- juhtimine
- juht
- Meedia
- Väärtus
- võib
- ML
- mudel
- mudelid
- modifitseeritud
- Moodulid
- Jälgida
- järelevalve
- monitorid
- rohkem
- kõige
- liikuma
- film
- mitmekordne
- peab
- nimi
- emakeelena
- Vajadus
- vaja
- negatiivne
- Uus
- ei
- meeles
- märkmik
- märkmikud
- nüüd
- objekt
- of
- sageli
- on
- ONE
- ainult
- optimeerima
- or
- Korraldus
- Muu
- meie
- välja
- väljund
- väljundid
- väljaspool
- paari
- parameeter
- parameetrid
- osa
- sooritama
- Mööduv
- tee
- täitma
- esitades
- isiklik
- torujuhe
- Platon
- Platoni andmete intelligentsus
- PlatoData
- mängimine
- populaarne
- positiivne
- post
- ennustada
- ettevalmistamine
- Valmistama
- Valmistab ette
- ettevalmistamisel
- eelmine
- varem
- Probleem
- töötlemine
- Toode
- tootejuht
- anda
- tingimusel
- annab
- avalik
- Tõmbab
- eesmärkidel
- Lükkama
- lükatakse
- Python
- kvaliteet
- kiiremini
- R
- pigem
- Lugenud
- Lugemine
- korduv
- vähendamine
- Refaktor
- viitama
- registreeritud
- regulaarselt
- jääma
- KORDUVALT
- nõudma
- tulemuseks
- läbi
- Arvustused
- jooks
- jooksmine
- jookseb
- salveitegija
- SageMakeri torujuhtmed
- sama
- rahul
- ajakava
- plaanitud
- Plaanilised tööd
- planeerimine
- teadus
- teadlased
- SDK
- Teine
- Osa
- lõigud
- vaata
- nähtud
- vanem
- tunne
- eri
- teenus
- Teenused
- istung
- komplekt
- kehtestamine
- mitu
- kujundatud
- ta
- peaks
- näitama
- presentatsioon
- näidatud
- Näitused
- märkimisväärne
- märgatavalt
- sarnane
- lihtne
- lihtsustamine
- ühekordne
- väike
- väiksem
- jupp
- So
- sotsiaalmeedia
- Sotsiaalse meedia
- lahendus
- Lahendused
- LAHENDAGE
- mõned
- midagi
- Ruum
- konkreetse
- Kulutused
- standalone
- Stanford
- algus
- olek
- Samm
- Sammud
- Veel
- ladustamine
- lihtne
- stuudio
- selline
- Sun
- toetama
- Toetatud
- Toetab
- kindel
- Võtma
- võtab
- Ülesanne
- ülesanded
- meeskond
- Tehnoloogiad
- test
- tekst
- Teksti liigitus
- et
- .
- oma
- Neile
- SIIS
- Need
- Kolmas
- see
- need
- kolm
- Läbi
- aeg
- et
- kokku
- liiga
- tööriist
- Summa
- jälgida
- Rong
- koolitatud
- koolitus
- Muutma
- trafod
- Reisimine
- vallandada
- Pöörake
- kaks
- tüüp
- ui
- mõistma
- Värskendused
- us
- kasutama
- kasutage juhtumit
- Kasutatud
- Kasutajad
- kasutusalad
- kasutamine
- kasutades
- Väärtused
- eri
- kaudu
- vaade
- visualiseeri
- kõndima
- tahan
- we
- web
- veebiteenused
- millal
- kas
- mis
- kuigi
- WHO
- will
- koos
- jooksul
- ilma
- töötajate
- töövoog
- Töövoogud
- töö
- halvim
- kirjutamine
- sa
- Sinu
- sephyrnet