Apache Sparki Amazon EMR käitusaeg on Apache Sparki jõudlusele optimeeritud käitusaeg, mis ühildub 100% API-ga avatud lähtekoodiga Apache Sparkiga. Koos Amazon EMR versioon 6.9.0, toetab Apache Sparki EMR-i käitusaeg samaväärset Sparki versiooni 3.3.0.
Amazon EMR 6.9.0 abil saate nüüd käitada oma Apache Spark 3.x rakendusi kiiremini ja madalama hinnaga, ilma et peaksite oma rakendusi muutma. Meie jõudluse võrdlustestides, mis tuletati TPC-DS jõudlustestidest 3 TB skaalal, leidsime, et Apache Spark 3.3.0 EMR-i käitusaeg parandab keskmiselt 3.5 korda (kasutades kogu käitusaega) võrreldes avatud lähtekoodiga Apache Spark 3.3.0-ga. XNUMX.
Selles postituses analüüsime TPC-DS-i rakendusega töötavate võrdlustestide tulemusi avatud lähtekoodiga Apache Spark ja seejärel Amazon EMR 6.9-l, mis on varustatud optimeeritud Sparki käitusajaga, mis ühildub avatud lähtekoodiga Sparkiga. Käime läbi üksikasjaliku kuluanalüüsi ja lõpuks anname samm-sammult juhised võrdlusaluse käitamiseks.
Täheldatud tulemused
Toimivuse täiustuste hindamiseks kasutasime avatud lähtekoodiga Sparki jõudlustesti utiliiti, mis on tuletatud TPC-DS jõudlustesti tööriistakomplektist. Testisime seitsme sõlmega (kuus põhisõlme ja üks esmane sõlm) c5d.9xlarge EMR-klastris koos Apache Sparki EMR-käitusajaga ja teisel seitsmest sõlmest koosnevas isehallatavas klastris Amazon Elastic Compute Cloud (Amazon EC2) Sparki samaväärse avatud lähtekoodiga versiooniga. Tegime mõlemad testid andmetega Amazoni lihtne salvestusteenus (Amazon S3).
Dünaamiline ressursside eraldamine (DRA) on suurepärane funktsioon erineva töökoormuse jaoks. Võrdlusuuringu puhul, kus võrdleme kahte platvormi puhtalt jõudluse põhjal ja katseandmete maht ei muutu (meie puhul 3 TB), usume, et õunte ja õunte võrdluse läbiviimiseks on kõige parem vältida varieeruvust. Nii avatud lähtekoodiga Sparki kui ka Amazon EMR-i testides keelasime DRA võrdlusuuringu rakenduse käitamise ajal.
Järgmises tabelis on näidatud kõigi päringute töö kogutööaeg (sekundites) 3 TB päringuandmestiku Amazon EMR versiooni 6.9.0 ja avatud lähtekoodiga Sparki versiooni 3.3.0 vahel. Märkasime, et meie TPC-DS-testide tööaeg oli Amazon EMR-is Amazon EC2-s 3.5 korda kiirem kui sama konfiguratsiooniga avatud lähtekoodiga Spark-klastri kasutamisel.
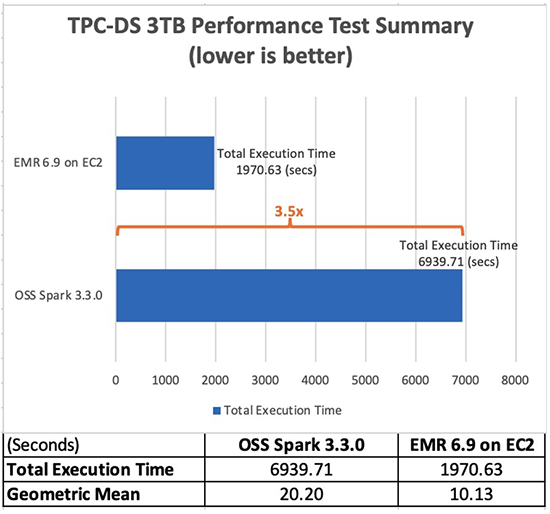
Amazon EMR 6.9 päringupõhine kiirendamine koos Apache Sparki EMR-i käitusajaga ja ilma selleta on näidatud järgmises diagrammis. Horisontaalne telg näitab iga päringut 3 TB võrdlusaluses. Vertikaalne telg näitab iga päringu kiirenemist EMR-i käitusajast tulenevalt. Märkimisväärne jõudluse kasv on TPC-DS päringute 10b, 24, 72 ja 95 puhul üle 96 korra kiirem.

Kulude analüüs
Apache Sparki EMR käitusaja jõudluse täiustused tähendavad otseselt kulusid. Suutsime saavutada 67% kulude kokkuhoiu Amazon EMR-i võrdlusrakenduse käitamisel võrreldes kuludega, mis tekkisid sama rakenduse käitamiseks avatud lähtekoodiga Sparkis Amazon EC2-s sama klastri suurusega, kuna Amazon EMR-i ja Amazoni tööaeg on vähenenud. EC2 kasutamine. Amazon EMR-i hinnakujundus on mõeldud EMR-rakendustele, mis töötavad EC2 eksemplaridega EMR-klastrites. Amazon EMR hind lisatakse aluseks olevatele arvutus- ja salvestushindadele, nagu EC2 eksemplari hind ja Amazoni elastsete plokkide pood (Amazon EBS) maksumus (EBS-i köidete kinnitamisel). Üldiselt on USA idapiirkonna (N. Virginia) hinnanguline võrdluskulu 27.01 dollarit Amazon EC2 avatud lähtekoodiga Sparki käitamise kohta ja 8.82 dollarit Amazon EMR-i käitamise kohta.
| Võrdlustöö | Kestus (tund) | Hinnanguline maksumus | EC2 eksemplar kokku | vCPU kokku | Kogumälu (GiB) | Juurseade (Amazon EBS) |
|
Avatud lähtekoodiga Spark Amazon EC2-s (1 esmane ja 6 põhisõlme) |
2.23 | $27.01 | 7 | 252 | 504 | 20 GiB gp2 |
|
Amazon EMR Amazon EC2-s (1 esmane ja 6 põhisõlme) |
0.63 | $8.82 | 7 | 252 | 504 | 20 GiB gp2 |
Kulude jaotus
Järgmine on Amazon EC2 avatud lähtekoodiga Sparki töö kulude jaotus (27.01 dollarit):
- Amazon EC2 kogumaksumus – (7 * 1.728 $ * 2.23) = (juhtumite arv * c5d.9xlarge tunnitasu * töö tööaeg tundides) = 26.97 $
- Amazon EBS-i hind – (0.1 USD/730 * 20 * 7 * 2.23) = (Amazon EBS GB-tunnitariifi kohta * EBS-i juursuurus * eksemplaride arv * töö tööaeg tundides) = 0.042 USD
Järgmine on Amazon EMR-i kulude jaotus Amazon EC2 töö kohta (8.82 dollarit):
- Amazon EMR kogumaksumus – (7 * 0.27 $ * 0.63) = ((tuumisõlmede arv + esmaste sõlmede arv)* c5d.9xlarge Amazon EMR hind * töö tööaeg tundides) = 1.19 $
- Amazon EC2 kogumaksumus – (7 * 1.728 $ * 0.63) = ((tuumisõlmede arv + esmaste sõlmede arv)* c5d.9xsuure eksemplari hind * töö käitusaeg tundides) = 7.62 $
- Amazon EBS-i hind – (0.1 USD/730 * 20 GiB * 7 * 0.63) = (Amazon EBS GB-tunnitariifi kohta * EBS-i suurus * eksemplaride arv * töö tööaeg tundides) = 0.012 USD
OSS Sparki võrdlusuuringu seadistamine
Järgmistes jaotistes anname lühiülevaate võrdlusuuringu seadistamise sammudest. Üksikasjalikud juhised koos näidetega leiate aadressilt GitHub repo.
OSS Sparki võrdlusuuringu jaoks kasutame avatud lähtekoodiga tööriista Flintrock käivitada meie Amazon EC2-põhine Apache Spark klaster. Flintrock pakub kiiret viisi Apache Sparki klastri käivitamiseks Amazon EC2-s käsurea abil.
Eeldused
Täitke järgmised eeltingimusetapid:
- Kas teil on Python 3.7.x või uuem.
- Pip3 22.2.2 või uuem.
- Lisage oma keskkonnateele Pythoni bin kataloog. Sellele teele installitakse Flintrocki kahendfail.
- jooks
aws configureoma konfigureerimiseks AWS-i käsurea liides (AWS CLI) kest, mis osutab võrdlusuuringu kontole. Viitama Kiire seadistamine aws-i konfiguratsiooniga juhiseid. - Kas võtmepaar piiravate failiõigustega juurdepääsuks OSS Sparki esmasele sõlmele.
- Vajadusel looge oma testkontol uus S3-salv.
- Kopeerige TPC-DS lähteandmed sisendina oma S3 ämbrisse.
- Ehitage võrdlusrakendus, järgides jaotises toodud samme Sammud säde-etalon-koosterakenduse loomiseks. Teise võimalusena saate alla laadida eelehitatud säde-benchmark-assamblee-3.3.0.jar kui soovite Spark 3.3.0-põhist rakendust.
Juurutage Sparki klaster ja käivitage võrdlustöö
Tehke järgmised toimingud.
- Paigaldage Flintrocki tööriist pipi kaudu, nagu näidatud joonisel OSS Spark Benchmarkingi seadistamise sammud.
- Käivitage käsk flintrock configure, mis avab vaikekonfiguratsioonifaili.
- Muutke vaikeseadet
config.yamlfaili vastavalt teie vajadustele. Teise võimalusena kopeerige ja kleepige faili config.yaml sisu vaikekonfiguratsioonifaili. Seejärel salvestage fail sinna, kus see oli. - Lõpuks käivitage Flintrocki kaudu Amazon EC7 2-sõlmeline Spark-klaster.
See peaks looma ühe primaarse sõlme ja kuue töötaja sõlmega Sparki klastri. Kui näete veateateid, kontrollige konfiguratsioonifaili väärtusi, eriti Sparki ja Hadoopi versioone ning allalaadimisallika ja AMI atribuute.
OSS Spark klastriga ei ole kaasas YARN-i ressursihaldur. Selle lubamiseks peame klastri konfigureerima.
- Lae alla yarn-site.xml ja enable-yarn.sh failid GitHubi repost.
- Asenda teie Flintrocki klastri esmase sõlme IP-aadressiga.
IP-aadressi saate hankida Amazon EC2 konsoolilt.
- Laadige failid üles kõikidesse Sparki klastri sõlmedesse.
- Käivitage lõnga lubamise skript.
- Lubage Hadoopis Snappy tugi (etaldustöö loeb Snappy tihendatud andmeid).
- Laadige alla etalonutiliidi rakenduse JAR-fail säde-benchmark-assamblee-3.3.0.jar oma kohalikule masinale.
- Kopeerige see fail klastrisse.
- Logige sisse esmasesse sõlme ja käivitage YARN.
- Esitage võrdlustöö avatud lähtekoodiga Sparki klastris, nagu näidatud Esitage võrdlustöö.
Tehke tulemused kokku
Laadige alla testitulemuste fail väljund S3 ämbrist s3://$YOUR_S3_BUCKET/EC2_TPCDS-TEST-3T-RESULT/timestamp=xxxx/summary.csv/xxx.csv. (Asenda $YOUR_S3_BUCKET oma S3 ämbri nimega.) Võite kasutada Amazon S3 konsooli ja navigeerida S3 väljundi asukohta või kasutada AWS CLI-d.
Sparki võrdlusuuringu rakendus loob ajatempli kausta ja kirjutab kokkuvõtliku faili summary.csv prefiksi sisse. Teie ajatempel ja failinimi erinevad eelmises näites näidatust.
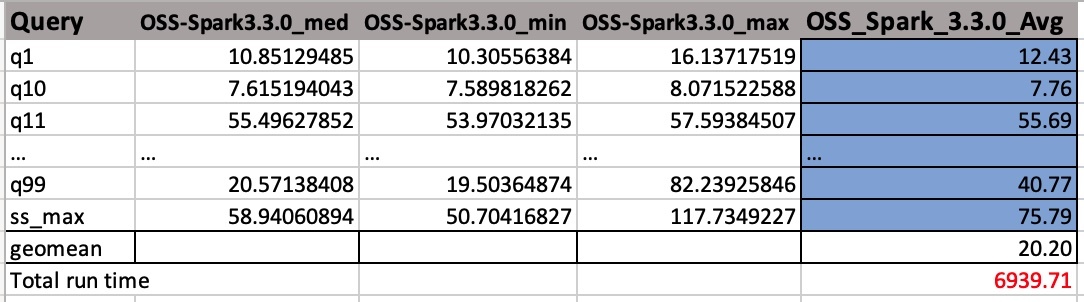
Väljund-CSV-failidel on neli veergu ilma päisenimedeta. Nemad on:
- Päringu nimi
- Keskmine aeg
- Minimaalne aeg
- Maksimaalne aeg
Järgmine ekraanipilt näitab näidisväljundit. Oleme veergude nimed käsitsi lisanud. Geokeskmise ja töö kogutööaja arvutamise viis põhineb aritmeetilistel keskmistel. Esmalt võtame meed, min ja max väärtuste keskmise, kasutades valemit AVERAGE(B2:D2). Seejärel võtame veeru Avg geomeetrilise keskmise, kasutades valemit GEOMEAN(E2:E105).
Seadistage Amazon EMR-i võrdlusuuringud
Üksikasjalike juhiste saamiseks vt EMR-i võrdlusuuringu seadistamise sammud.
Eeldused
Täitke järgmised eeltingimusetapid:
- jooks
aws configureet konfigureerida oma AWS CLI kest osutama võrdlusuuringu kontole. Viitama Kiire seadistamine aws-i konfiguratsiooniga juhiseid. - Laadige võrdlusuuringu rakendus Amazon S3-sse üles.
Juurutage EMR-klaster ja käivitage võrdlustöö
Tehke järgmised toimingud.
- Pöörake oma AWS CLI kestas Amazon EMR üles, kasutades käsurida, nagu näidatud Juurutage EMR-klaster ja käivitage võrdlustöö.
- Seadistage Amazon EMR ühe primaarse (c5d.9xlarge) ja kuue tuuma (c5d.9xlarge) sõlmega. Viitama loo-klaster AWS CLI valikute üksikasjaliku kirjelduse jaoks.
- Salvestage vastusest pärit klastri ID. Seda vajate järgmises etapis.
- Esitage võrdlustöö Amazon EMR-is, kasutades AWS-i CLI-s lisatoiminguid.
Tehke tulemused kokku
Tehke väljundi ämbri tulemuste kokkuvõte s3://$YOUR_S3_BUCKET/blog/EMRONEC2_TPCDS-TEST-3T-RESULT samamoodi nagu OSS-i tulemuste puhul ja võrdleme.
Koristage
Edaspidiste tasude vältimiseks kustutage ressursid, mille lõite jaotises olevaid juhiseid kasutades GitHubi repo puhastusjaotis.
- Peatage EMR ja OSS Spark klastrid. Samuti võite need kustutada, kui te ei soovi sisu säilitada. Saate need ressursid kustutada, käivitades skripti cleanup-benchmark-env.sh terminalist teie etalonkeskkonnas.
- Kui kasutasite AWSi pilv IDE-na, et luua võrdlusrakenduse JAR-fail Sammud säde-etalon-koosterakenduse loomiseks, võite soovida ka keskkonna kustutada.
Järeldus
Amazon EMR 3.5 abil saate oma Apache Sparki töökoormusi käitada 6.9.0 korda (kogu käitusaja põhjal) kiiremini ja madalamate kuludega ilma rakendustes muudatusi tegemata.
Et olla kursis, tellige Big Data ajaveebi RSS Lisateavet Apache Sparki EMR-i käitusaja, konfiguratsiooni parimate tavade ja häälestusnõuannete kohta.
Varasemate võrdlustestide kohta vt Käivitage Apache Spark 3.0 töökoormust 1.7 korda kiiremini Apache Sparki Amazon EMR-i käitusajaga. Pange tähele, et varasem 1.7-kordne tulemus põhines geomeetrilisel keskmisel. Geomeetrilise keskmise põhjal oli Amazon EMR 6.9 jõudlus kaks korda kiirem.
Autoritest
 Sekar Srinivasan on suurandmetele ja analüüsidele keskendunud AWS-i vanemlahenduste spetsialist. Sekaril on andmetega töötamise kogemus üle 20 aasta. Ta on kirglik aidata klientidel luua skaleeritavaid lahendusi, mis moderniseerivad nende arhitektuuri ja loovad nende andmete põhjal teadmisi. Vabal ajal meeldib talle töötada mittetulunduslike projektidega, eriti nende puhul, mis keskenduvad vähekindlustatud laste haridusele.
Sekar Srinivasan on suurandmetele ja analüüsidele keskendunud AWS-i vanemlahenduste spetsialist. Sekaril on andmetega töötamise kogemus üle 20 aasta. Ta on kirglik aidata klientidel luua skaleeritavaid lahendusi, mis moderniseerivad nende arhitektuuri ja loovad nende andmete põhjal teadmisi. Vabal ajal meeldib talle töötada mittetulunduslike projektidega, eriti nende puhul, mis keskenduvad vähekindlustatud laste haridusele.
 Prabu Ravichandran on Amazon Web Servicesi vanemandmearhitekt, kes keskendub Analyticsile, Data Lake'i arhitektuurile ja juurutamisele. Ta aitab klientidel AWS-i teenuseid kasutades kavandada ja ehitada skaleeritavaid ja töökindlaid lahendusi. Vabal ajal meeldib Prabule reisida ja perega aega veeta.
Prabu Ravichandran on Amazon Web Servicesi vanemandmearhitekt, kes keskendub Analyticsile, Data Lake'i arhitektuurile ja juurutamisele. Ta aitab klientidel AWS-i teenuseid kasutades kavandada ja ehitada skaleeritavaid ja töökindlaid lahendusi. Vabal ajal meeldib Prabule reisida ja perega aega veeta.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- Platoblockchain. Web3 metaversiooni intelligentsus. Täiustatud teadmised. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/big-data/run-apache-spark-workloads-3-5-times-faster-with-amazon-emr-6-9/
- 1
- 10
- 100
- 1040
- 20 aastat
- 7
- 9
- a
- Võimalik
- MEIST
- üle
- juurdepääs
- konto
- lisatud
- aadress
- nõuanne
- Materjal: BPA ja flataatide vaba plastik
- eraldamine
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- analüüs
- analytics
- analüüsima
- ja
- Apache
- Apache Spark
- API
- taotlus
- rakendused
- arhitektuur
- atribuudid
- keskmine
- AVG
- AWS
- Telg
- põhineb
- Uskuma
- võrrelda
- BEST
- parimaid tavasid
- vahel
- Suur
- Big andmed
- Blokeerima
- Lagunema
- ehitama
- Ehitus
- juhul
- muutma
- Vaidluste lahendamine
- koormuste
- Joonis
- Cluster
- Veerg
- Veerud
- Tulema
- võrdlema
- võrdlus
- kokkusobiv
- Arvutama
- konfiguratsioon
- konsool
- sisu
- tuum
- Maksma
- kulude kokkuhoid
- kulud
- looma
- loodud
- loob
- Kliendid
- andmed
- andmejärv
- kuupäev
- vaikimisi
- Tuletatud
- kirjeldus
- üksikasjalik
- seade
- DID
- erinev
- otse
- blokeeritud
- Ei tee
- Ära
- lae alla
- iga
- Ida
- ebs
- Käsitöö
- võimaldama
- keskkond
- Samaväärne
- viga
- eriti
- Hinnanguliselt
- Eeter (ETH)
- hindama
- näide
- näited
- Teostama
- kogemus
- pere
- kiiremini
- tunnusjoon
- fail
- Faile
- Lõpuks
- esimene
- keskendunud
- keskendunud
- Järel
- valem
- avastatud
- tasuta
- Alates
- tulevik
- Kasum
- teeniva
- GitHub
- suur
- hadoop
- aidates
- aitab
- Horisontaalne
- Lahtiolekuajad
- aga
- HTML
- HTTPS
- täitmine
- paranemine
- parandusi
- in
- sisend
- teadmisi
- Näiteks
- juhised
- seotud
- IP
- IP-aadress
- IT
- töö
- hoidma
- järv
- algatama
- Õppida
- joon
- kohalik
- liising
- masin
- Tegemine
- juht
- viis
- käsitsi
- max
- vahendid
- Mälu
- kirjad
- rohkem
- nimi
- nimed
- Navigate
- Vajadus
- vaja
- vajadustele
- Uus
- järgmine
- sõlme
- sõlmed
- mittetulunduslik
- märkimisväärne
- number
- ONE
- avatud lähtekoodiga
- optimeeritud
- Valikud
- et
- Oss
- kontuur
- üldine
- kirglik
- minevik
- tee
- jõudlus
- Õigused
- Platvormid
- Platon
- Platoni andmete intelligentsus
- PlatoData
- Punkt
- Pops
- post
- tavad
- hind
- Hinnad
- hinnapoliitika
- esmane
- era-
- projektid
- anda
- tingimusel
- annab
- puhtalt
- Python
- Kiire
- määr
- mõistma
- Lühendatud
- piirkond
- vabastama
- asendama
- ressurss
- Vahendid
- vastus
- Piirav
- kaasa
- Tulemused
- jõuline
- juur
- jooks
- jooksmine
- sama
- Säästa
- Hoiused
- skaalautuvia
- Skaala
- Teine
- sekundit
- Osa
- lõigud
- vanem
- Teenused
- kehtestamine
- seade
- Shell
- peaks
- näidatud
- Näitused
- lihtne
- SIX
- SUURUS
- Lahendused
- allikas
- Säde
- spetsialist
- Kulutused
- algus
- Samm
- Sammud
- ladustamine
- tellima
- selline
- KOKKUVÕTE
- toetama
- Toetab
- tabel
- Võtma
- terminal
- test
- testid
- .
- oma
- Läbi
- aeg
- korda
- ajatempel
- et
- tööriist
- Käsiraamat
- Summa
- tõlkima
- Reisimine
- aluseks
- vähekindlustatud
- us
- Kasutus
- kasutama
- kasulikkus
- Väärtused
- versioon
- kaudu
- virginia
- mahud
- web
- veebiteenused
- mis
- kuigi
- will
- ilma
- Töö
- töötaja
- töö
- X
- XML
- yaml
- aastat
- Sinu
- sephyrnet