Selles postituses demonstreerime, kuidas kasutada närviarhitektuuri otsingul (NAS) põhinevat struktuurilist kärpimist, et tihendada peenhäälestatud BERT-mudelit, et parandada mudeli jõudlust ja lühendada järeldusaega. Eelkoolitatud keelemudeleid (PLM-id) hakatakse kiiresti kasutusele võtma tootlikkuse tööriistade, klienditeeninduse, otsingu ja soovituste, äriprotsesside automatiseerimise ja sisu loomise valdkondades. PLM-i järeldusotsuste juurutamine on tavaliselt seotud suurema latentsusaja ja suuremate infrastruktuurikuludega, mis on tingitud arvutusnõuetest, ning arvutusliku efektiivsuse vähenemisest parameetrite suure arvu tõttu. PLM-i kärpimine vähendab mudeli suurust ja keerukust, säilitades samal ajal selle prognoosimisvõimalused. Kärbitud PLM-id saavutavad väiksema mälumahu ja väiksema latentsusaja. Näitame, et PLM-i kärpimise ja konkreetse sihtülesande jaoks parameetrite loenduse ja valideerimisvea vahetamisega ning suudame saavutada PLM-i baasmudeliga võrreldes kiirema reageerimisaja.
Mitme eesmärgiga optimeerimine on otsuste tegemise valdkond, mis optimeerib korraga rohkem kui ühte eesmärgifunktsiooni, nagu mälutarbimine, treeningaeg ja arvutusressursid. Struktuurne pügamine on meetod PLM-i suuruse ja arvutusnõuete vähendamiseks kihtide või neuronite/sõlmede kärpimise teel, püüdes samal ajal säilitada mudeli täpsust. Kihtide eemaldamisega saavutab struktuurne pügamine suurema tihendusmäära, mis toob kaasa riistvarasõbraliku struktureeritud hõreduse, mis vähendab käitus- ja reageerimisaegu. Struktuurilise kärpimise tehnika rakendamine PLM-mudelile annab tulemuseks väiksema mälumahuga mudeli, mis on SageMakeris järelduste lõpp-punktina hostitud ja pakub algse peenhäälestatud PLM-iga võrreldes paremat ressursitõhusust ja väiksemaid kulusid.
Selles postituses illustreeritud kontseptsioone saab rakendada rakendustele, mis kasutavad PLM-i funktsioone, nagu soovitussüsteemid, sentimentide analüüs ja otsingumootorid. Täpsemalt saate seda lähenemist kasutada siis, kui teil on spetsiaalsed masinõppe (ML) ja andmeteaduse meeskonnad, kes viimistlevad oma PLM-mudeleid domeenispetsiifiliste andmekogumite abil ja juurutavad suure hulga järelduste lõpp-punkte, kasutades Amazon SageMaker. Üks näide on Interneti-jaemüüja, kes kasutab teksti kokkuvõtete tegemiseks, tootekataloogi klassifitseerimiseks ja toote tagasiside sentimentide klassifitseerimiseks suurt hulka järelduste lõpp-punkte. Teine näide võib olla tervishoiuteenuse osutaja, kes kasutab PLM-i järelduste lõpp-punkte kliiniliste dokumentide klassifitseerimiseks, meditsiiniliste aruannete nimega üksuse tuvastamiseks, meditsiiniliste vestlusrobotite ja patsientide riskide kihistamiseks.
Lahenduse ülevaade
Selles jaotises tutvustame üldist töövoogu ja selgitame lähenemisviisi. Esiteks kasutame an Amazon SageMaker Studio märkmik eelkoolitatud BERTi mudeli peenhäälestamiseks sihtülesande jaoks, kasutades domeenispetsiifilist andmekogumit. BERT (Bidirectional Encoder Representations from Transformers) on eelkoolitatud keelemudel, mis põhineb trafo arhitektuur kasutatakse loomuliku keele töötlemise (NLP) ülesannete jaoks. Närviarhitektuuri otsing (NAS) on lähenemisviis kunstlike närvivõrkude projekteerimise automatiseerimiseks ja on tihedalt seotud hüperparameetrite optimeerimisega, mis on masinõppe valdkonnas laialdaselt kasutatav lähenemisviis. NAS-i eesmärk on leida antud probleemi jaoks optimaalne arhitektuur, otsides suure hulga kandidaatarhitektuuride hulgast, kasutades selliseid tehnikaid nagu gradiendivaba optimeerimine või soovitud mõõdikuid optimeerides. Arhitektuuri jõudlust mõõdetakse tavaliselt selliste mõõdikute abil nagu valideerimise kadu. SageMakeri automaatne mudeli häälestamine (AMT) automatiseerib tüütut ja keerukat protsessi ML-mudeli hüperparameetrite optimaalsete kombinatsioonide leidmiseks, mis annavad parima mudeli jõudluse. AMT kasutab intelligentseid otsingualgoritme ja iteratiivseid hindamisi, kasutades erinevaid teie määratud hüperparameetreid. See valib hüperparameetrite väärtused, mis loob mudeli, mis toimib kõige paremini, mõõdetuna toimivusmõõdikutega, nagu täpsus ja F-1 skoor.
Selles postituses kirjeldatud peenhäälestusviis on üldine ja seda saab rakendada mis tahes tekstipõhisele andmekogumile. BERT PLM-ile määratud ülesanne võib olla tekstipõhine ülesanne, näiteks sentimentanalüüs, teksti klassifitseerimine või Q&A. Selles demos on sihtülesanne binaarne klassifitseerimisprobleem, kus BERT-i kasutatakse tekstifragmentide paaridest koosnevast andmekogumist tuvastamiseks, kas ühe tekstifragmendi tähendust saab järeldada teisest fragmendist. Me kasutame Tekstilise tähise andmestiku tuvastamine GLUE võrdlusuuringute komplektist. Teostame mitme eesmärgiga otsingu, kasutades SageMaker AMT-d, et tuvastada alamvõrgud, mis pakuvad sihtülesande jaoks optimaalset kompromissi parameetrite arvu ja prognoosimise täpsuse vahel. Mitme eesmärgiga otsingu tegemisel alustame täpsuse ja parameetrite arvu määratlemisest eesmärkidena, mida me püüame optimeerida.
BERT-i PLM-võrgus võivad olla modulaarsed, iseseisvad alamvõrgud, mis võimaldavad mudelil omada spetsiaalseid võimalusi, nagu keele mõistmine ja teadmiste esitus. BERT PLM kasutab mitme peaga enesetähelepanu alamvõrku ja edasisuunalist alamvõrku. Mitmepealine enesetähelepanu kiht võimaldab BERT-il seostada ühe jada erinevaid positsioone, et arvutada jada esitus, võimaldades mitmel peal jälgida mitut kontekstisignaali. Sisend jagatakse mitmeks alamruumiks ja enesetähelepanu rakendatakse igale alamruumile eraldi. Trafo PLM-i mitu pead võimaldavad mudelil ühiselt käsitleda teavet erinevatest esitusalaruumidest. Edaspidine alamvõrk on lihtne närvivõrk, mis võtab väljundi mitme otsaga enesetähelepanu alamvõrgust, töötleb andmeid ja tagastab kodeerija lõplikud esitused.
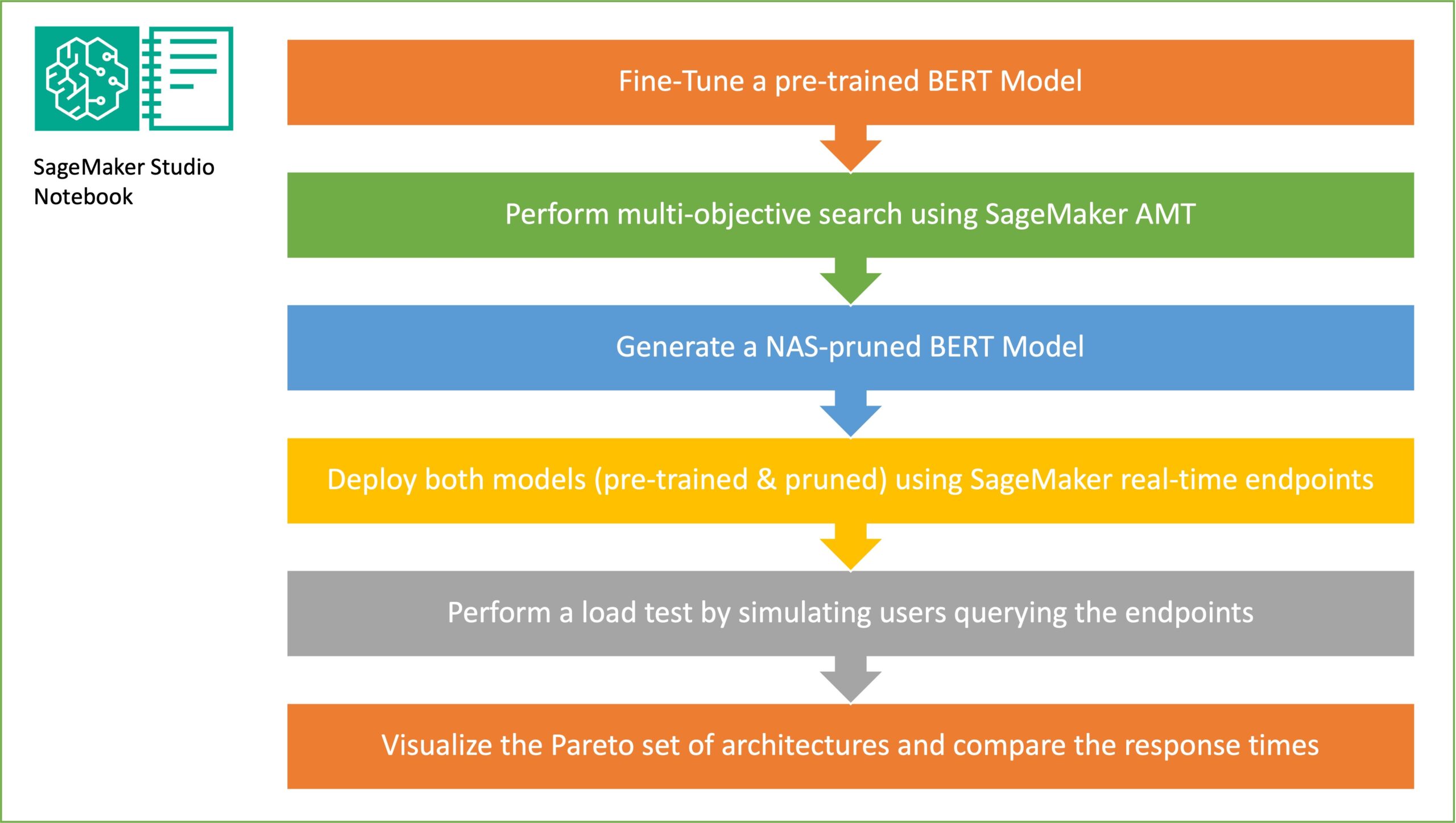
Juhusliku alamvõrgu valimi moodustamise eesmärk on koolitada väiksemaid BERT-mudeleid, mis suudavad sihtülesannetega piisavalt hästi toime tulla. Me valime 100 juhuslikku alamvõrku peenhäälestatud BERT-i baasmudelist ja hindame samaaegselt 10 võrku. Koolitatud alamvõrke hinnatakse objektiivsete mõõdikute osas ja lõplik mudel valitakse objektiivsete mõõdikute vahel leitud kompromisside põhjal. Visualiseerime Pareto ees valimi alamvõrkude jaoks, mis sisaldab kärbitud mudelit, mis pakub optimaalset kompromissi mudeli täpsuse ja mudeli suuruse vahel. Valime kandidaadi alamvõrgu (NAS-i kärbitud BERT-mudel) mudeli suuruse ja mudeli täpsuse põhjal, mida oleme nõus vahetama. Järgmisena hostime SageMakeri abil lõpp-punkte, eelkoolitatud BERT-i baasmudelit ja NAS-i kärbitud BERT-mudelit. Koormustesti läbiviimiseks kasutame rändrohutirts, avatud lähtekoodiga koormuse testimise tööriist, mida saate Pythoni abil rakendada. Teostame Locusti abil mõlema lõpp-punkti koormustesti ja visualiseerime tulemusi Pareto rinde abil, et illustreerida mõlema mudeli reageerimisaegade ja täpsuse vahelist kompromissi. Järgmine diagramm annab ülevaate selles postituses selgitatud töövoost.
Eeldused
Selle postituse jaoks on vajalikud järgmised eeltingimused:
Samuti peate suurendama teenuse kvoot et pääseda SageMakeris juurde vähemalt kolmele ml.g4dn.xlarge eksemplarile. Eksemplari tüüp ml.g4dn.xlarge on kuluefektiivne GPU eksemplar, mis võimaldab teil PyTorchi natiivselt käivitada. Teenuse kvoodi suurendamiseks toimige järgmiselt.
- Liikuge konsoolis jaotisse Teenuse kvoodid.
- eest Halda kvoote, vali Amazon SageMaker, siis vali Vaata kvoote.

- Otsige üles „ml-g4dn.xlarge for training job use use” ja valige kvoodiüksus.
- Vali Taotlege suurendamist konto tasemel.
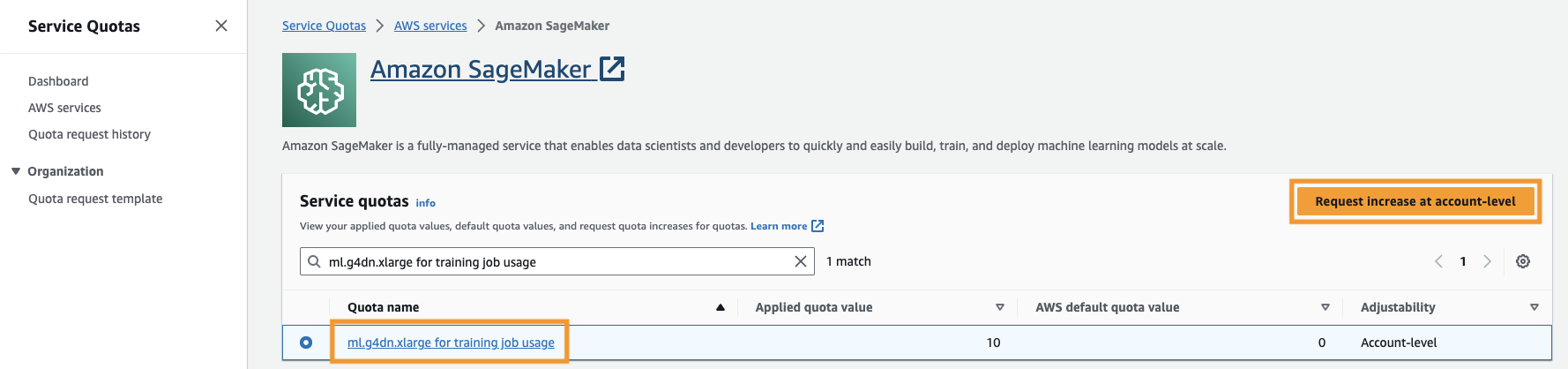
- eest Suurendage kvoodi väärtust, sisestage väärtus 5 või suurem.
- Vali Küsi.
Taotletud kvoodi kinnitamine võib sõltuvalt konto lubadest veidi aega võtta.

- Avage SageMakeri konsoolist SageMaker Studio.

- Vali Süsteemi terminal all Utiliidid ja failid.

- Käivitage järgmine käsk, et kloonida GitHub repo SageMaker Studio eksemplari:
- Liigu
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - Avage fail
nas_for_llm_with_amt.ipynb. - Seadistage keskkond rakendusega
ml.g4dn.xlargenäide ja vali valima.

Seadistage eelkoolitatud BERT-mudel
Selles jaotises impordime andmekogumi teegist andmestiku Tuvastava tekstilise tähenduse ja jagame andmekogumi koolitus- ja valideerimiskomplektideks. See andmestik koosneb lausepaaridest. BERT PLM-i ülesanne on kahe tekstifragmendi põhjal ära tunda, kas ühe tekstifragmendi tähendust saab järeldada teisest fragmendist. Järgmises näites saame järeldada esimese fraasi tähendust teisest fraasist:
Laadime tekstituvastusega kaasnevate andmete kogumi saidilt GLUE võrdlusuuringute komplekti kaudu andmekogumi teek Hugging Face'ist meie koolitusskripti raames (./training.py). Jagasime GLUE algse koolitusandmestiku koolitus- ja valideerimiskomplektiks. Meie lähenemisviisi kohaselt viimistleme koolitusandmestiku abil BERT-i baasmudelit, seejärel teostame mitme eesmärgiga otsingu, et tuvastada alamvõrkude kogum, mis tasakaalustab objektiivsete mõõdikute vahel optimaalselt. Kasutame koolitusandmestikku eranditult BERT-mudeli peenhäälestamiseks. Siiski kasutame mitme eesmärgiga otsingu jaoks valideerimisandmeid, mõõtes hoidmise valideerimise andmekogumi täpsust.
Täpsustage BERT PLM-i domeenispetsiifilise andmestiku abil
BERT-i töötlemata mudeli tüüpilisteks kasutusjuhtudeks on järgmise lause ennustamine või maskeeritud keele modelleerimine. BERT-i baasmudeli kasutamiseks allavoolu ülesannete jaoks, nagu tekstituvastus, peame mudelit domeenispetsiifilise andmestiku abil veelgi täpsustama. Peenhäälestatud BERT-mudelit saate kasutada selliste ülesannete jaoks nagu järjestuste klassifitseerimine, küsimustele vastamine ja märgide klassifitseerimine. Selle demo jaoks kasutame aga binaarseks klassifitseerimiseks peenhäälestatud mudelit. Täpsustame eelkoolitatud BERT-mudelit eelnevalt koostatud koolitusandmestikuga, kasutades järgmisi hüperparameetreid:
Mudelitreeningu kontrollpunkti salvestame an Amazoni lihtne salvestusteenus (Amazon S3) ämber, nii et mudelit saab laadida NAS-põhise mitmeobjektilise otsingu ajal. Enne mudeli koolitamist määratleme mõõdikud, nagu epohh, treeningkadu, parameetrite arv ja valideerimisviga:
Pärast peenhäälestusprotsessi algust kulub koolitustöö lõpuleviimiseks umbes 15 minutit.
Tehke alamvõrkude valimiseks ja tulemuste visualiseerimiseks mitme eesmärgiga otsing
Järgmises etapis teostame mitme eesmärgiga otsingu peenhäälestatud BERT-i baasmudelil, valides juhuslikest alamvõrkudest, kasutades SageMaker AMT-d. Supervõrgus olevale alamvõrgule (peenhäälestatud BERT-mudel) pääsemiseks maskeerime kõik PLM-i komponendid, mis ei kuulu alamvõrku. Supervõrgu maskeerimine PLM-is alamvõrkude leidmiseks on meetod, mida kasutatakse mudeli käitumismustrite eraldamiseks ja tuvastamiseks. Pange tähele, et Hugging Face trafode varjatud suurus peab olema peade arvu kordne. Trafo PLM peidetud suurus kontrollib peidetud oleku vektorruumi suurust, mis mõjutab mudeli võimet õppida andmetes keerulisi esitusi ja mustreid. BERT PLM-is on peidetud olekuvektor fikseeritud suurusega (768). Peidetud suurust me muuta ei saa ja seetõttu peab peade arv olema vahemikus [1, 3, 6, 12].
Erinevalt ühe eesmärgi optimeerimisest ei ole meil mitme eesmärgi seades tavaliselt ühtegi lahendust, mis kõiki eesmärke samaaegselt optimeeriks. Selle asemel püüame koguda lahenduste komplekti, mis domineerivad kõigis muudes lahendustes vähemalt ühes eesmärgis (nt valideerimisviga). Nüüd saame alustada mitme eesmärgiga otsingut AMT kaudu, määrates mõõdikud, mida tahame vähendada (valideerimisviga ja parameetrite arv). Juhuslikud alamvõrgud määratakse parameetriga max_jobs ja samaaegsete tööde arv määratakse parameetriga max_parallel_jobs. Kood mudeli kontrollpunkti laadimiseks ja alamvõrgu hindamiseks on saadaval aadressil evaluate_subnetwork.py skript.
AMT häälestustöö kestab umbes 2 tundi ja 20 minutit. Pärast AMT häälestustöö edukat käitamist analüüsime töö ajaloo ja kogume alamvõrgu konfiguratsioonid, nagu peade arv, kihtide arv, ühikute arv ja vastavad mõõdikud, nagu valideerimisviga ja parameetrite arv. Järgmine ekraanipilt näitab eduka AMT-tuuneri töö kokkuvõtet.
Järgmiseks visualiseerime tulemused Pareto komplekti (tuntud ka kui Pareto piiri või Pareto optimaalse komplekti) abil, mis aitab meil tuvastada optimaalsed alamvõrkude komplektid, mis domineerivad kõigis teistes objektiivse mõõdiku alamvõrkudes (valideerimisviga):
Esiteks kogume andmeid AMT häälestustööst. Seejärel joonistame Pareto hulga kasutades matplotlob.pyplot parameetrite arvuga x-teljel ja valideerimisviga y-teljel. See tähendab, et kui me liigume Pareto komplekti ühest alamvõrgust teise, peame kas ohverdama jõudluse või mudeli suuruse, kuid parandama teist. Lõppkokkuvõttes annab Pareto komplekt meile paindlikkuse, et valida meie eelistustele kõige paremini sobiv alamvõrk. Saame otsustada, kui palju tahame oma võrgu suurust vähendada ja kui palju jõudlust oleme valmis ohverdama.

SageMakeri abil juurutage peenhäälestatud BERT-mudel ja NAS-i jaoks optimeeritud alamvõrgumudel
Järgmisena juurutame oma Pareto komplekti suurima mudeli, mis viib väikseima jõudluse halvenemiseni SageMakeri lõpp-punkt. Parim mudel on see, mis pakub meie kasutusjuhtumi jaoks optimaalset kompromissi valideerimisvea ja parameetrite arvu vahel.
Mudelite võrdlus
Võtsime eelkoolitatud BERT-i baasmudeli, viimistlesime seda domeenispetsiifilise andmestiku abil, käivitasime NAS-i otsingu, et tuvastada objektiivsete mõõdikute põhjal domineerivad alamvõrgud, ja kasutasime kärbitud mudelit SageMakeri lõpp-punktis. Lisaks kasutasime eelkoolitatud BERT-i baasmudelit ja juurutasime baasmudeli teises SageMakeri lõpp-punktis. Järgmisena jooksime koormustestimine kasutades Locusti mõlemas järelduse lõpp-punktis ja hindas toimivust reageerimisaja järgi.
Esiteks impordime vajalikud Locusti ja Boto3 teegid. Seejärel koostame päringu metaandmed ja registreerime koormustestimiseks kasutatava algusaja. Seejärel edastatakse kasulik koormus BotoClienti kaudu SageMakeri lõpp-punkti kutsumise API-le, et simuleerida tegelikke kasutajataotlusi. Kasutame Locusti mitme virtuaalse kasutaja loomiseks, et saata päringuid paralleelselt ja mõõta lõpp-punkti jõudlust koormuse all. Teste tehakse, suurendades vastavalt mõlema lõpp-punkti kasutajate arvu. Pärast testide lõppu väljastab Locust iga juurutatud mudeli jaoks päringustatistika CSV-faili.
Järgmisena genereerime pärast Locustiga testide käivitamist alla laaditud CSV-failidest reaktsiooniaja graafikud. Reaktsiooniaja vs kasutajate arvu joonistamise eesmärk on analüüsida koormustesti tulemusi, visualiseerides mudeli lõpp-punktide reaktsiooniaja mõju. Järgmisel diagrammil näeme, et NAS-i kärbitud mudeli lõpp-punkt saavutab BERT-i baasmudeli lõpp-punktiga võrreldes madalama reaktsiooniaja.
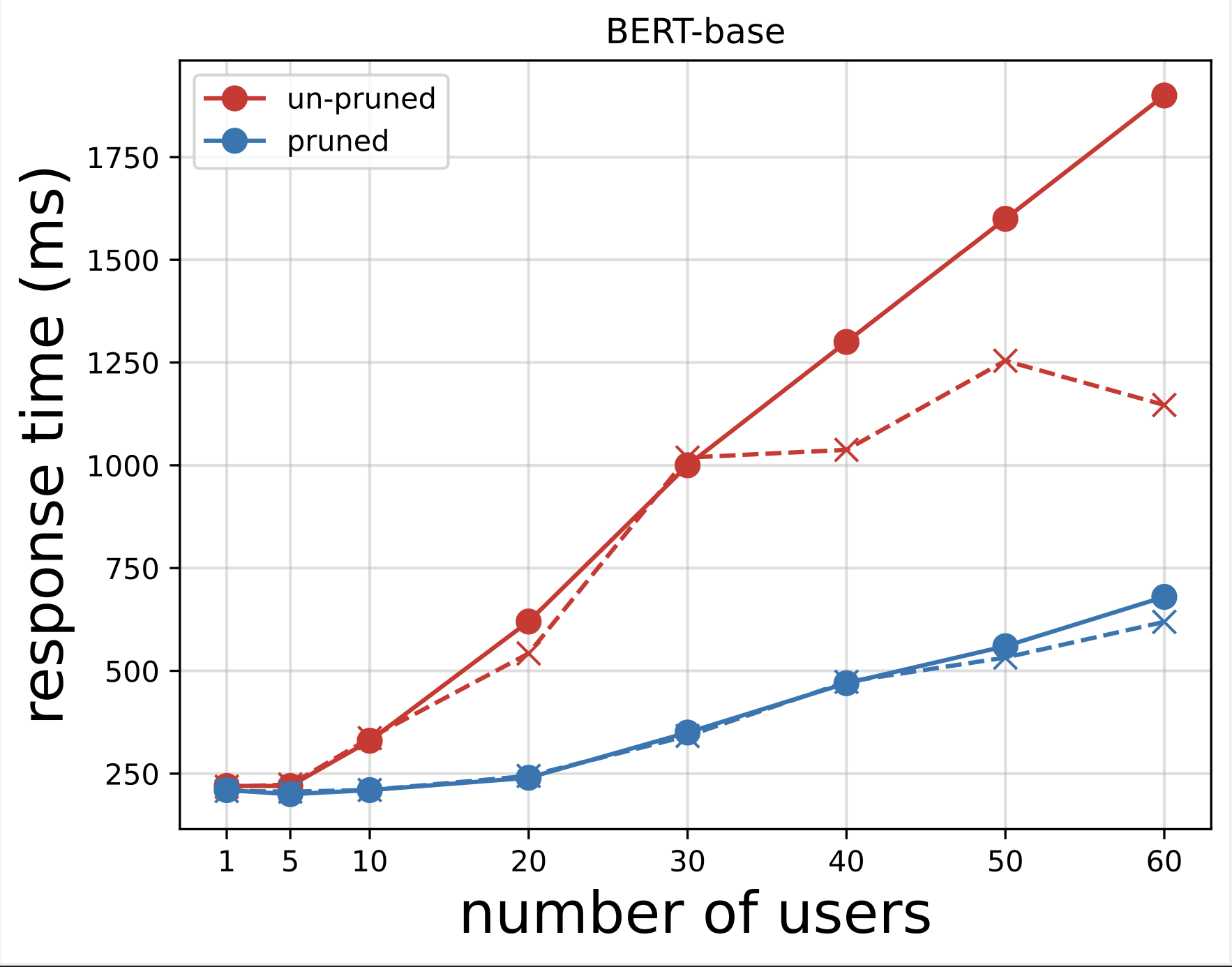
Teises diagrammis, mis on esimese diagrammi laiendus, näeme, et umbes 70 kasutaja järel hakkab SageMaker BERT-i baasmudeli lõpp-punkti pidurdama ja teeb erandi. NAS-i kärbitud mudeli lõpp-punkti puhul toimub drossel aga 90–100 kasutaja vahel ja lühema reageerimisajaga.

Kahe diagrammi põhjal näeme, et kärbitud mudelil on kiirem reageerimisaeg ja see skaleerub paremini kui kärbimata mudelil. Kui me suurendame järelduste lõpp-punktide arvu, nagu see juhtub kasutajate puhul, kes juurutavad oma PLM-rakenduste jaoks suure hulga järelduste lõpp-punkte, hakkavad kulukasu ja jõudluse paranemine muutuma üsna oluliseks.
Koristage
Peenhäälestatud BERT-i baasmudeli ja NAS-i kärbitud mudeli SageMakeri lõpp-punktide kustutamiseks toimige järgmiselt.
- Valige SageMakeri konsoolil Järeldus ja Lõpp-punktid navigeerimispaanil.
- Valige lõpp-punkt ja kustutage see.
Teise võimalusena käivitage SageMaker Studio märkmikus järgmised käsud, sisestades lõpp-punktide nimed:
Järeldus
Selles postituses arutasime, kuidas kasutada NAS-i peenhäälestatud BERT-mudeli kärpimiseks. Esmalt koolitasime välja BERT-i baasmudeli, kasutades domeenispetsiifilisi andmeid, ja juurutasime selle SageMakeri lõpp-punkti. Tegime mitme eesmärgiga otsingu peenhäälestatud BERT-i baasmudelil, kasutades sihtülesande jaoks SageMaker AMT-d. Visualiseerisime Pareto esiosa ja valisime Pareto optimaalse NAS-i kärbitud BERT-mudeli ning juurutasime mudeli teise SageMakeri lõpp-punkti. Viisime läbi koormustesti, kasutades Locusti, et simuleerida kasutajaid, kes küsivad mõlemat lõpp-punkti, ning mõõtsime ja salvestasime vastuseajad CSV-faili. Joonistasime mõlema mudeli reaktsiooniaja vs kasutajate arvu.
Täheldasime, et kärbitud BERT-mudel toimis oluliselt paremini nii reaktsiooniaja kui ka eksemplari drosselläve osas. Jõudsime järeldusele, et NAS-i kärbitud mudel oli lõpp-punkti suurenenud koormuse suhtes vastupidavam, säilitades lühema reageerimisaja isegi siis, kui rohkem kasutajaid rõhutas süsteemi võrreldes BERT-i baasmudeliga. Saate rakendada selles postituses kirjeldatud NAS-i tehnikat mis tahes suurele keelemudelile, et leida kärbitud mudel, mis suudab sihtülesande täita oluliselt väiksema reageerimisajaga. Saate lähenemisviisi veelgi optimeerida, kasutades lisaks valideerimiskaotusele parameetrina latentsust.
Kuigi me kasutame selles postituses NAS-i, on kvantimine veel üks levinud lähenemisviis, mida kasutatakse PLM-mudelite optimeerimiseks ja tihendamiseks. Kvantimine vähendab treenitud võrgus kaalude ja aktiveerimiste täpsust 32-bitiselt ujukomalt väiksema bitilaiuseni, nagu 8-bitised või 16-bitised täisarvud, mille tulemuseks on tihendatud mudel, mis genereerib kiiremini järeldusi. Kvantimine ei vähenda parameetrite arvu; selle asemel vähendab see olemasolevate parameetrite täpsust tihendatud mudeli saamiseks. NAS-i pügamine eemaldab PLM-is üleliigsed võrgud, mis loob vähemate parameetritega hõreda mudeli. Tavaliselt kasutatakse NAS-i kärpimist ja kvantiseerimist koos suurte PLM-ide tihendamiseks, et säilitada mudeli täpsus, vähendada valideerimiskadusid, parandades samal ajal jõudlust ja vähendada mudeli suurust. Teised tavaliselt kasutatavad meetodid PLM-ide suuruse vähendamiseks hõlmavad järgmist teadmiste destilleerimine, maatriksfaktoriseerimineja destilleerimiskaskaadid.
Blogipostituses pakutud lähenemisviis sobib meeskondadele, kes kasutavad SageMakerit mudelite koolitamiseks ja täpsustamiseks, kasutades domeenispetsiifilisi andmeid ning lõpp-punktide juurutamiseks järelduste tegemiseks. Kui otsite täielikult hallatavat teenust, mis pakub valikut suure jõudlusega alusmudeleid, mis on vajalikud generatiivsete AI-rakenduste loomiseks, kaaluge Amazonase aluspõhi. Kui otsite eelkoolitatud avatud lähtekoodiga mudeleid paljude äriliste kasutusjuhtude jaoks ning soovite pääseda juurde lahendusmallidele ja näidismärkmikele, kaaluge Amazon SageMaker JumpStart. Selles postituses kasutatud Hugging Face BERT-i baaskorpusega mudeli eelkoolitatud versioon on saadaval ka SageMaker JumpStartis.
Autoritest
 Aparadžithan Vaidyanathan on AWS-i peamine ettevõttelahenduste arhitekt. Ta on pilvearhitekt, kellel on üle 24-aastane kogemus ettevõtete, suuremahuliste ja hajutatud tarkvarasüsteemide projekteerimisel ja arendamisel. Ta on spetsialiseerunud generatiivsele AI-le ja masinõppe andmetehnikale. Ta on ambitsioonikas maratonijooksja ning tema hobideks on matkamine, rattasõit ning naise ja kahe poisiga ajaveetmine.
Aparadžithan Vaidyanathan on AWS-i peamine ettevõttelahenduste arhitekt. Ta on pilvearhitekt, kellel on üle 24-aastane kogemus ettevõtete, suuremahuliste ja hajutatud tarkvarasüsteemide projekteerimisel ja arendamisel. Ta on spetsialiseerunud generatiivsele AI-le ja masinõppe andmetehnikale. Ta on ambitsioonikas maratonijooksja ning tema hobideks on matkamine, rattasõit ning naise ja kahe poisiga ajaveetmine.
 Aaron Klein on AWS-i vanem rakendusteadlane, kes töötab sügavate närvivõrkude jaoks mõeldud automatiseeritud masinõppe meetodite kallal.
Aaron Klein on AWS-i vanem rakendusteadlane, kes töötab sügavate närvivõrkude jaoks mõeldud automatiseeritud masinõppe meetodite kallal.
 Jacek Golebiowski on AWS-i vanem rakendusteadlane.
Jacek Golebiowski on AWS-i vanem rakendusteadlane.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/
- :on
- :on
- :mitte
- : kus
- ][lk
- $ UP
- 1
- 10
- 100
- 11
- 12
- 13
- 15%
- 17
- 19
- 20
- 26
- 30
- 31
- 320
- 7
- 70
- 72
- 8
- 9
- a
- võime
- Võimalik
- juurdepääs
- konto
- täpsus
- Saavutada
- Saavutab
- aktiveerimised
- lisamine
- Vastuvõtmine
- pärast
- AI
- eesmärk
- Eesmärk
- algoritme
- Materjal: BPA ja flataatide vaba plastik
- võimaldama
- Lubades
- võimaldab
- Ka
- Amazon
- Amazon Web Services
- summa
- an
- analüüs
- analytics
- analüüsima
- ja
- Teine
- vastamine
- mistahes
- API
- rakendused
- rakendatud
- kehtima
- Rakendades
- lähenemine
- heakskiit
- umbes
- arhitektuur
- OLEME
- PIIRKOND
- valdkondades
- argumendid
- ümber
- kunstlik
- kunstlikud närvivõrgud
- AS
- ambitsioonikas
- määratud
- seotud
- At
- üritab
- osalema
- Automatiseeritud
- automatiseeritud masinõpe
- automatiseerib
- Automaatne
- automatiseerimine
- Automaatika
- saadaval
- AWS
- Telg
- Saldo
- baas
- põhineb
- BE
- muutuma
- enne
- käitumine
- võrdlusuuringud
- Kasu
- BEST
- Parem
- vahel
- Natuke
- keha
- mõlemad
- ehitama
- äri
- Äriprotsess
- Äriprotsesside automatiseerimine
- kuid
- by
- CAN
- kandidaat
- võimeid
- juhul
- juhtudel
- kataloog
- muutma
- Joonis
- Äritegevus
- jututoad
- valik
- Vali
- valitud
- klass
- klassifikatsioon
- kliiniline
- lähedalt
- Cloud
- kood
- koguma
- kogumine
- kombinatsioonid
- kaubandus-
- ühine
- tavaliselt
- võrreldes
- täitma
- Lõpetatud
- keeruline
- keerukus
- komponendid
- arvutuslik
- Arvutama
- mõisted
- sõlmitud
- Arvestama
- koosneb
- konsool
- piiranguid
- ehitama
- tarbimine
- sisaldab
- sisu
- sisu loomine
- kontekst
- jätkama
- kontrast
- kontrolli
- Vastav
- Maksma
- kulud
- loe
- looma
- loob
- loomine
- klient
- Kasutajatugi
- andmed
- andmeteadus
- andmekogumid
- kuupäev Kellaaeg
- otsustama
- Otsuse tegemine
- pühendunud
- sügav
- sügavad närvivõrgud
- määratlema
- määratletud
- määratlemisel
- Demo
- näitama
- Olenevalt
- juurutada
- lähetatud
- juurutamine
- juurutab
- kirjeldatud
- Disain
- projekteerimine
- soovitud
- arenev
- erinev
- arutatud
- jagatud
- dokument
- Ei tee
- domineeriv
- domineerima
- Ära
- kaks
- ajal
- e
- iga
- efektiivsus
- tõhus
- kumbki
- Lõpp-punkt
- lõpp-punktid
- Inseneriteadus
- Mootorid
- piisavalt
- sisene
- ettevõte
- ettevõtte vastuvõtmine
- Enterprise Solutions
- üksus
- kanne
- keskkond
- epohh
- viga
- Eeter (ETH)
- hindama
- hinnatud
- hindamised
- Isegi
- sündmused
- näide
- Välja arvatud
- erand
- ainult
- olemasolevate
- kogemus
- Selgitama
- selgitas
- laiendamine
- nägu
- vale
- kiiremini
- FUNKTSIOONID
- tagasiside
- vähem
- väli
- fail
- Faile
- lõplik
- leidma
- leidmine
- esimene
- fikseeritud
- Paindlikkus
- ujuv
- Järel
- Jalajälg
- eest
- avastatud
- Sihtasutus
- Alates
- esi-
- Piir
- täielikult
- funktsioon
- edasi
- tekitama
- genereerib
- generatiivne
- Generatiivne AI
- saama
- antud
- eesmärk
- GPU
- hall
- juhtub
- Olema
- he
- juhataja
- pea
- tervishoid
- aitab
- varjatud
- suure jõudlusega
- rohkem
- matkamine
- tema
- ajalugu
- Hobid
- võõrustaja
- võõrustas
- Lahtiolekuajad
- Kuidas
- Kuidas
- aga
- HTML
- http
- HTTPS
- Kallistav Nägu
- Hüperparameetrite optimeerimine
- Hüperparameetrite häälestamine
- i
- identifitseerima
- idx
- if
- Illustreerima
- mõju
- Mõjud
- rakendada
- import
- parandama
- paranenud
- paranemine
- Paranemist
- in
- sisaldama
- Suurendama
- kasvanud
- kasvav
- info
- Infrastruktuur
- sisend
- Näiteks
- juhtumid
- selle asemel
- Intelligentne
- sisse
- IT
- ITS
- töö
- Tööturg
- jpg
- Json
- teadmised
- teatud
- keel
- suur
- suuremahuline
- suurim
- Hilinemine
- kiht
- kihid
- Leads
- Õppida
- õppimine
- kõige vähem
- laskma
- raamatukogud
- Raamatukogu
- joon
- koormus
- logi
- metsaraie
- otsin
- kaotus
- kaod
- vähendada
- masin
- masinõpe
- säilitada
- säilitamine
- mees
- juhitud
- Maraton
- mask
- matplotlib
- maksimaalne
- mai..
- tähendus
- mõõtma
- mõõdetud
- mõõtmine
- meditsiini-
- Vastama
- Mälu
- Metaandmed
- meetodid
- meetriline
- Meetrika
- võib
- minimeerima
- protokoll
- ML
- mudel
- modelleerimine
- mudelid
- modulaarne
- rohkem
- liikuma
- palju
- mitmekordne
- peab
- nimi
- Nimega
- nimed
- kell
- Natural
- Loomulik keel
- Natural Language Processing
- Navigate
- NAVIGATSIOON
- vajalik
- Vajadus
- vaja
- vajadustele
- võrk
- võrgustikud
- Neural
- Närvivõrgus
- närvivõrgud
- järgmine
- nlp
- mitte ükski
- meeles
- märkmik
- märkmikud
- nüüd
- number
- objekt
- eesmärk
- eesmärgid
- jälgima
- vaadeldud
- of
- maha
- pakkuma
- Pakkumised
- on
- ONE
- Internetis
- veebipood
- ainult
- avatud
- avatud lähtekoodiga
- optimaalselt
- optimeerimine
- optimeerima
- optimeeritud
- Optimeerib
- optimeerimine
- or
- et
- originaal
- Muu
- meie
- välja
- väljund
- väljundid
- üle
- üldine
- ülevaade
- enda
- paari
- pane
- Parallel
- parameeter
- parameetrid
- Pareto
- osa
- Vastu võetud
- tee
- patsient
- mustrid
- täitma
- jõudlus
- teostatud
- esitades
- täidab
- Õigused
- Platon
- Platoni andmete intelligentsus
- PlatoData
- Punkt
- võrra
- positsioone
- post
- Täpsus
- ennustus
- ennustav
- Predictor
- eelistusi
- valmis
- eeldused
- esitada
- varem
- Peamine
- Probleem
- protsess
- Protsessi automatiseerimine
- Protsessid
- töötlemine
- Toode
- tootlikkus
- Tootlikkuse tööriistad
- pakutud
- tarnija
- annab
- pakkudes
- tõmmates
- Tõmbab
- eesmärk
- eesmärkidel
- Python
- pütorch
- Küsimused ja vastused
- küsimus
- üsna
- juhuslik
- valik
- kiire
- Rates
- Töötlemata
- reaalne
- tunnustamine
- tunnistama
- tunnustamine
- Soovitus
- soovitused
- rekord
- dokumenteeritud
- Red
- vähendama
- Lühendatud
- vähendab
- regressioon
- seotud
- eemaldab
- eemaldades
- Aruanded
- esindamine
- taotleda
- palutud
- Taotlusi
- nõutav
- Nõuded
- vetruv
- ressurss
- Vahendid
- vastavalt
- vastus
- Tulemused
- jaemüüja
- säilitamine
- Tulu
- ratsutamine
- Oht
- ROW
- jooks
- jooksja
- jooksmine
- jookseb
- s
- ohverdama
- salveitegija
- SageMakeri järeldus
- Säästa
- Skaala
- Kaalud
- teadus
- teadlane
- skoor
- käsikiri
- Otsing
- Otsingumootorid
- otsimine
- Teine
- Osa
- vaata
- valima
- väljavalitud
- SELF
- saatma
- Lause
- tunne
- Jada
- teenus
- Teenused
- istung
- komplekt
- Komplektid
- kehtestamine
- Näitused
- signaale
- märgatavalt
- lihtne
- samaaegselt
- üheaegselt
- ühekordne
- SUURUS
- väiksem
- So
- tarkvara
- lahendus
- Lahendused
- mõned
- allikas
- Ruum
- Lõimetis
- spetsialiseeritud
- spetsialiseerunud
- konkreetse
- eriti
- Kulutused
- jagada
- algus
- algab
- riik
- statistika
- Samm
- Sammud
- ladustamine
- struktuuriline
- struktureeritud
- stuudio
- mahukas
- edukas
- Edukalt
- selline
- sobiv
- komplekt
- KOKKUVÕTE
- süsteem
- süsteemid
- T
- Võtma
- võtab
- sihtmärk
- Ülesanne
- ülesanded
- meeskonnad
- tehnika
- tehnikat
- malle
- tingimused
- Testimine
- testid
- tekst
- Teksti liigitus
- tekstiline
- kui
- et
- .
- oma
- SIIS
- Seal.
- seetõttu
- Need
- see
- kolm
- künnis
- Läbi
- aeg
- korda
- et
- kokku
- sümboolne
- võttis
- tööriist
- töövahendid
- kaubelda
- Kauplemine
- Rong
- koolitatud
- koolitus
- trafo
- trafod
- tõsi
- püüdma
- kaks
- tüüp
- liigid
- tüüpiline
- tüüpiliselt
- lõpuks
- all
- toimumas
- mõistmine
- üksused
- us
- kasutama
- kasutage juhtumit
- Kasutatud
- Kasutaja
- Kasutajad
- kasutusalad
- kasutamine
- kinnitamine
- väärtus
- Väärtused
- versioon
- kaudu
- virtuaalne
- visualiseeri
- vs
- tahan
- oli
- we
- web
- veebiteenused
- Hästi
- millal
- kas
- mis
- kuigi
- WHO
- lai
- Lai valik
- laialdaselt
- naine
- Wikipedia
- will
- valmis
- koos
- jooksul
- Töö
- töövoog
- töö
- X
- aastat
- saak
- sa
- Sinu
- sephyrnet