Suured keelemudelid (LLM-id) muutuvad üha populaarsemaks ning uusi kasutusjuhtumeid uuritakse pidevalt. Üldiselt saate luua rakendusi, mida toidavad LLM-id, lisades oma koodisse kiire inseneri. Siiski on juhtumeid, kus olemasoleva LLM-i küsimine ei õnnestu. Siin võib aidata mudeli peenhäälestus. Prompt engineering tähendab mudeli väljundi suunamist sisendviipade loomise kaudu, samas kui peenhäälestus on mudeli koolitamine kohandatud andmekogumite järgi, et see sobiks paremini konkreetsete ülesannete või domeenide jaoks.
Enne mudeli peenhäälestamist peate leidma ülesandepõhise andmestiku. Üks tavaliselt kasutatav andmekogum on Üldine roomamise andmestik. Common Crawli korpus sisaldab petabaite andmeid, mida on regulaarselt kogutud alates 2008. aastast, ning sisaldab veebilehtede töötlemata andmeid, metaandmete väljavõtteid ja tekstiväljavõtteid. Lisaks kasutatava andmestiku kindlaksmääramisele on vajalik andmete puhastamine ja töötlemine vastavalt peenhäälestuse spetsiifilistele vajadustele.
Hiljuti tegime koostööd kliendiga, kes soovis eeltöödelda uusima Common Crawli andmestiku alamhulka ja seejärel oma LLM-i puhastatud andmetega täpsustada. Klient otsis, kuidas seda AWS-is kõige kuluefektiivsemalt saavutada. Pärast nõuete arutamist soovitasime kasutada Amazon EMR serverita nende andmete eeltöötluse platvormina. EMR Serverless sobib hästi suuremahuliseks andmetöötluseks ja välistab vajaduse taristu hoolduse järele. Kulude osas võetakse tasu ainult iga töö jaoks kasutatud ressursside ja kestuse alusel. Klient suutis EMR Serverlessi abil nädala jooksul eeltöödelda sadu TB andmeid. Pärast andmete eeltöötlemist kasutasid nad Amazon SageMaker LLM-i peenhäälestamiseks.
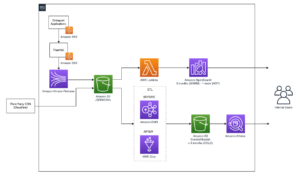
Selles postituses tutvustame teile kliendi kasutusjuhtu ja kasutatud arhitektuuri.
Järgmistes jaotistes tutvustame esmalt ühist roomamise andmestikku ning seda, kuidas uurida ja filtreerida vajalikke andmeid. Amazonase Athena maksab ainult skannitud andmemahu eest ning seda kasutatakse andmete kiireks uurimiseks ja filtreerimiseks, olles samas kulutõhus. EMR Serverless pakub Sparki andmetöötluseks kuluefektiivset ja hooldusvaba võimalust ning seda kasutatakse filtreeritud andmete töötlemiseks. Järgmisena kasutame Amazon SageMaker JumpStart peenhäälestamiseks Lama 2 mudel eeltöödeldud andmestikuga. SageMaker JumpStart pakub kõige levinumate kasutusjuhtude jaoks lahenduste komplekti, mida saab juurutada vaid mõne klõpsuga. LLM-i (nt Llama 2) peenhäälestamiseks ei pea te koodi kirjutama. Lõpuks juurutame peenhäälestatud mudeli, kasutades Amazon SageMaker ja võrrelge sama küsimuse tekstiväljundi erinevusi originaal- ja peenhäälestatud Llama 2 mudelite vahel.
Selle lahenduse arhitektuuri illustreerib järgmine diagramm.
Enne lahenduse üksikasjadesse sukeldumist täitke järgmised eeltingimused.
Common Crawl on avatud korpuse andmestik, mis saadakse enam kui 50 miljardi veebilehe roomamisel. See sisaldab tohutul hulgal struktureerimata andmeid mitmes keeles, alates 2008. aastast kuni petabaitide tasemeni. Seda uuendatakse pidevalt.
GPT-3 treenimisel moodustab Common Crawl andmestik 60% selle treeningandmetest, nagu on näidatud järgmisel diagrammil (allikas: Keelemudelid on väheõppijad).
Teine oluline andmestik, mida tasub mainida, on C4 andmestik. C4, lühend sõnadest Colossal Clean Crawled Corpus, on andmestik, mis on tuletatud Common Crawli andmestiku järeltöötlusest. Meta LLaMA dokumendis kirjeldasid nad kasutatud andmekogumeid, millest Common Crawl moodustas 67% (kasutab 3.3 TB andmeid) ja C4 15% (kasutab 783 GB andmeid). Dokumendis rõhutatakse erinevalt eeltöödeldud andmete kaasamise olulisust mudeli jõudluse parandamiseks. Vaatamata sellele, et algsed C4 andmed olid osa Common Crawlist, valis Meta nende andmete ümbertöödeldud versiooni.
Selles jaotises käsitleme levinumaid viise ühise roomamise andmekogumiga suhtlemiseks, filtreerimiseks ja töötlemiseks.
Common Crawli toorandmekogum sisaldab kolme tüüpi andmefaile: veebilehe töötlemata andmed (WARC), metaandmed (WAT) ja teksti ekstraktimine (WET).
Pärast 2013. aastat kogutud andmed salvestatakse WARC-vormingus ja need sisaldavad vastavaid metaandmeid (WAT) ja teksti väljavõtete andmeid (WET). Andmekogum asub Amazon S3-s, seda värskendatakse kord kuus ja sellele pääseb juurde otse AWS Marketplace.
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gzÜhise roomamise andmestik sisaldab ka andmete filtreerimiseks indeksitabelit, mida nimetatakse cc-index-tableiks.
cc-index-tabel on olemasolevate andmete register, mis pakub tabelipõhist WARC-failide indeksit. See võimaldab hõlpsalt otsida teavet, näiteks seda, milline WARC-fail vastab konkreetsele URL-ile.
Näiteks saate luua Athena tabeli, et kaardistada cc-indeksi andmed järgmise koodiga:
Eelnevad SQL-laused näitavad, kuidas luua Athena tabelit, lisada partitsioone ja käivitada päring.
Filtreerige andmeid Common Crawli andmestikust
Nagu näete tabeli loomise SQL-lausest, on mitu välja, mis aitavad andmeid filtreerida. Näiteks kui soovite saada Hiina dokumentide arvu teatud perioodi jooksul, võib SQL-lause olla järgmine:
Kui soovite edasist töötlemist teha, saate tulemused salvestada teise S3 ämbrisse.
Analüüsige filtreeritud andmeid
. Üldine Crawl GitHubi hoidla pakub mitmeid PySparki näiteid toorandmete töötlemiseks.
Vaatame näidet jooksmisest server_count.py (skripti näide, mille pakub Common Crawl GitHubi repo) asukohas asuvatel andmetel s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
Esiteks vajate Sparki keskkonda, näiteks EMR Sparki. Näiteks saate käivitada Amazon EMR-i EC2 klastris us-east-1 (kuna andmestik on sees us-east-1). EMR-i kasutamine EC2 klastris võib aidata teil enne tööde esitamist tootmiskeskkonda testida.
Pärast EMR-i käivitamist EC2 klastris peate klastri esmasesse sõlme SSH-sse sisse logima. Seejärel pakendage Pythoni keskkond ja esitage skript (vt Conda dokumentatsioon Miniconda installimiseks):
Kõigi viidete töötlemine failis warc.path võib võtta aega. Demo eesmärkidel saate töötlemisaega parandada järgmiste strateegiatega.
- Laadige fail alla
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gzoma kohalikku arvutisse, pakkige see lahti ja laadige seejärel HDFS-i või Amazon S3-sse. Põhjus on selles, et gzip-faili ei saa poolitada. Faili paralleelseks töötlemiseks peate selle lahti pakkima. - Muuda
warc.pathfaili, kustutage suurem osa selle ridu ja säilitage ainult kaks rida, et töö palju kiiremini käiks.
Pärast töö lõpetamist näete tulemust s3://xxxx-common-crawl/output/, Parketi formaadis.
Rakendage kohandatud omamise loogikat
Common Crawl GitHubi repo pakub WARC-failide töötlemiseks ühtset lähenemisviisi. Üldiselt saate pikendada CCSparkJob alistama ühe meetodi (process_record), mis on paljudel juhtudel piisav.
Vaatame viimaste filmide IMDB arvustuste saamiseks näidet. Esiteks peate IMDB saidil failid välja filtreerima:
Seejärel saate hankida IMDB ülevaateandmeid sisaldavaid WARC-failide loendeid ja salvestada WARC-failide nimed loendina tekstifailis.
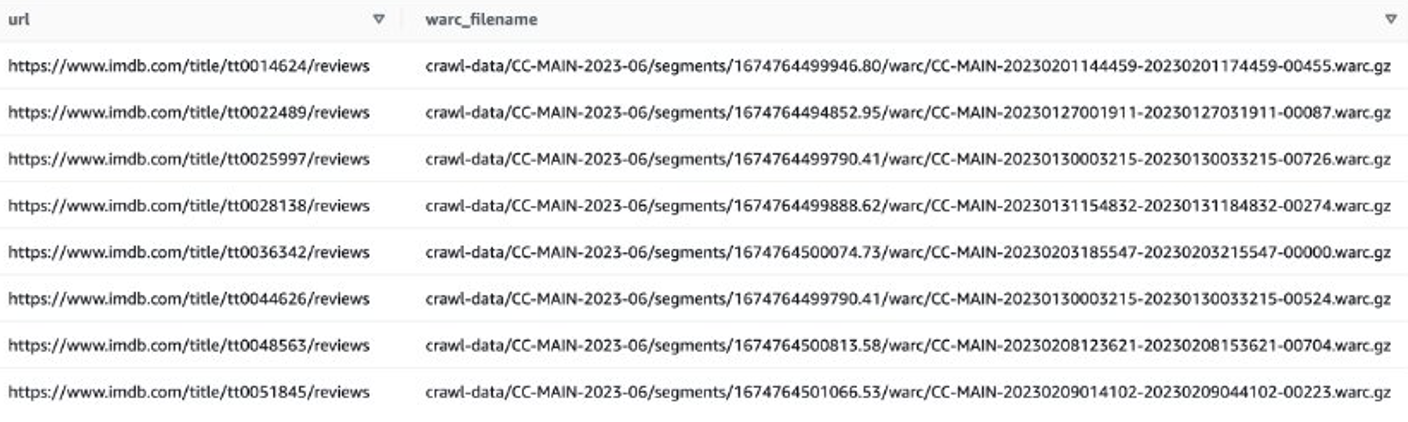
Teise võimalusena võite kasutada EMR Sparki, hankida WARC-failide loend ja salvestada see Amazon S3-sse. Näiteks:
Väljundfail peaks välja nägema sarnane s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
Järgmine samm on nendest WARC-failidest kasutajate arvustuste eraldamine. Saate pikendada CCSparkJob alistama process_record() meetod:
Eelmise skripti saate salvestada kui imdb_extractor.py, mida kasutate järgmistes sammudes. Pärast andmete ja skriptide ettevalmistamist saate filtreeritud andmete töötlemiseks kasutada EMR Serverlessi.
EMR serverita
EMR Serverless on serverita juurutusvõimalus suurte andmeanalüütikarakenduste käitamiseks, kasutades avatud lähtekoodiga raamistikke, nagu Apache Spark ja Hive, ilma klastreid või servereid konfigureerimata, haldamata ja skaleerimata.
EMR Serverlessi abil saate käitada analüütika töökoormust mis tahes ulatuses automaatse skaleerimisega, mis muudab ressursside suurust sekunditega, et vastata muutuvatele andmemahtudele ja töötlemisnõuetele. EMR Serverless skaleerib ressursse automaatselt üles ja alla, et pakkuda teie rakendusele õiget mahtu, ja maksate ainult selle eest, mida kasutate.
Ühise roomamise andmestiku töötlemine on üldiselt ühekordne töötlemisülesanne, mistõttu sobib see EMR-i serverita töökoormuse jaoks.
Looge EMR-i serverita rakendus
Saate luua EMR-i serverita rakenduse EMR Studio konsoolil. Tehke järgmised sammud.
- Valige EMR Studio konsoolil Rakendused all Serverita navigeerimispaanil.
- Vali Loo rakendus.

- Sisestage rakendusele nimi ja valige Amazon EMR-i versioon.

- Kui on vaja juurdepääsu VPC ressurssidele, lisage kohandatud võrguseade.

- Vali Loo rakendus.
Teie Sparki serverita keskkond on seejärel valmis.
Enne kui saate EMR Spark Serverlessile töö esitada, peate ikkagi looma täitmisrolli. Viitama Amazon EMR Serverlessiga alustamine rohkem üksikasju.
Töötle tavalisi roomamisandmeid rakendusega EMR Serverless
Kui teie EMR Spark Serverless rakendus on valmis, tehke andmete töötlemiseks järgmised toimingud.
- Valmistage ette Conda keskkond ja laadige see Amazon S3-sse, mida kasutatakse EMR Spark Serverlessi keskkonnana.
- Laadige käivitatavad skriptid üles S3 ämbrisse. Järgmises näites on kaks skripti.
- imbd_extractor.py – kohandatud loogika andmestikust sisu eraldamiseks. Sisu leiate sellest postitusest varem.
- cc-pyspark/sparkcc.py – PySparki raamistiku näide Üldine Crawl GitHubi repo, mis on vajalik kaasata.
- Esitage PySparki töö EMR Serverless Sparkile. Selle näite käitamiseks oma keskkonnas määratlege järgmised parameetrid.
- rakenduse ID – Teie EMR-i serverita rakenduse ID.
- hukkamine-roll-arn - teie EMR-i serverita täitmise roll. Selle loomiseks vaadake Looge töö käitusaegne roll.
- WARC-faili asukoht - teie WARC-failide asukoht.
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txtsisaldab filtreeritud WARC-failide loendit, mille hankisite selles postituses varem. - spark.sql.warehouse.dir – Vaikimisi lao asukoht (kasutage oma S3 kataloogi).
- säde.arhiivid – Koostatud Conda keskkonna S3 asukoht.
- spark.submit.pyFiles – ettevalmistatud PySparki skript sparkcc.py.
Vaadake järgmist koodi:
Pärast töö lõpetamist salvestatakse ekstraktitud ülevaated Amazon S3-sse. Sisu kontrollimiseks võite kasutada Amazon S3 Selecti, nagu on näidatud järgmisel ekraanipildil.
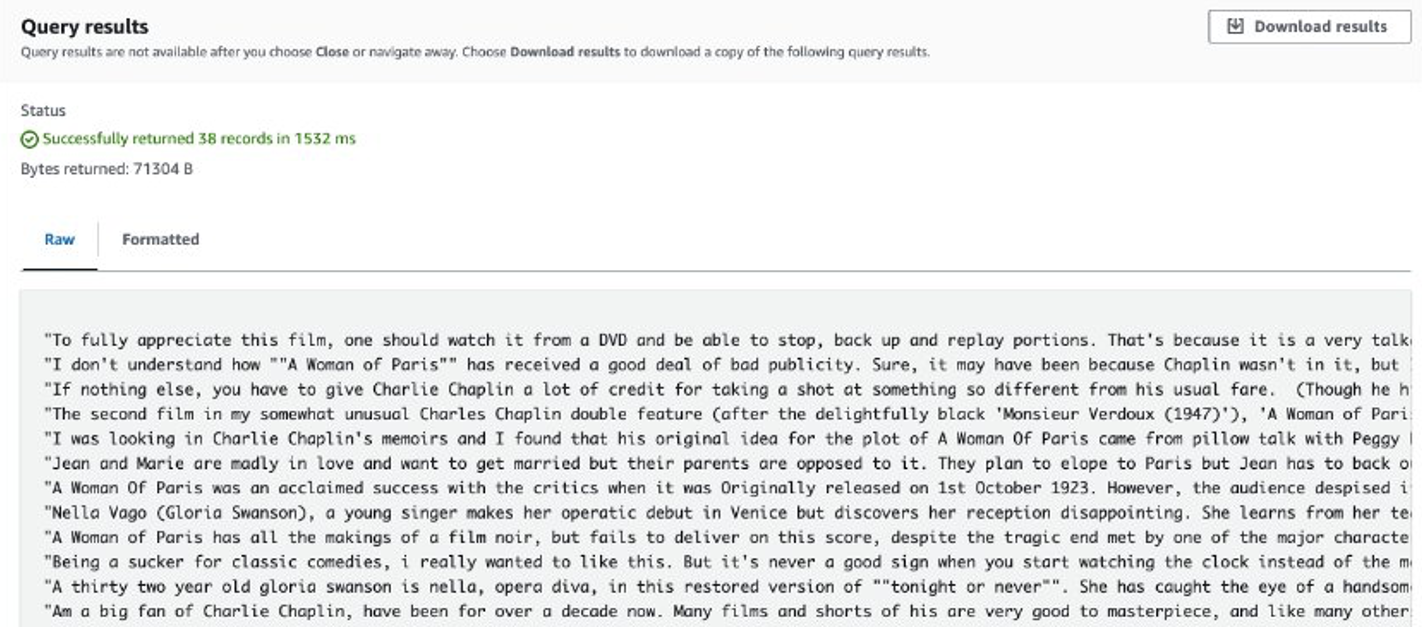
Kaalutlused
Kohandatud koodiga tohutute andmemahtude käsitlemisel tuleb arvestada järgmiste punktidega.
- Mõned kolmanda osapoole Pythoni teegid ei pruugi Condas saadaval olla. Sellistel juhtudel saate PySparki käituskeskkonna loomiseks lülituda Pythoni virtuaalsele keskkonnale.
- Kui töödeldakse tohutul hulgal andmeid, proovige luua ja kasutada nende paralleelseerimiseks mitut EMR Serverless Sparki rakendust. Iga rakendus käsitleb faililoendite alamhulka.
- Common Crawl andmete filtreerimisel või töötlemisel võib Amazon S3 puhul ilmneda aeglustumise probleem. Seda seetõttu, et andmeid salvestav S3-salv on avalikult juurdepääsetav ja teised kasutajad võivad andmetele samal ajal juurde pääseda. Selle probleemi leevendamiseks saate lisada korduskatsemehhanismi või sünkroonida konkreetsed andmed Common Crawl S3 ämbrist oma ämbrisse.
Peenhäälestage Llama 2 rakendusega SageMaker
Pärast andmete ettevalmistamist saate sellega Llama 2 mudelit peenhäälestada. Saate seda teha SageMaker JumpStarti abil ilma koodi kirjutamata. Lisateabe saamiseks vaadake Peenhäälestage Llama 2 teksti genereerimiseks rakenduses Amazon SageMaker JumpStart.
Selle stsenaariumi korral viite läbi domeeni kohandamise peenhäälestuse. Selle andmestiku puhul koosneb sisend CSV-, JSON- või TXT-failist. Peate sisestama kõik ülevaateandmed TXT-faili. Selleks saate esitada EMR Spark Serverlessile lihtsa Sparki töö. Vaadake järgmist näidiskoodilõiku:
Pärast treeningandmete ettevalmistamist sisestage andmete asukoht Treeningu andmekogum, siis vali Rong.
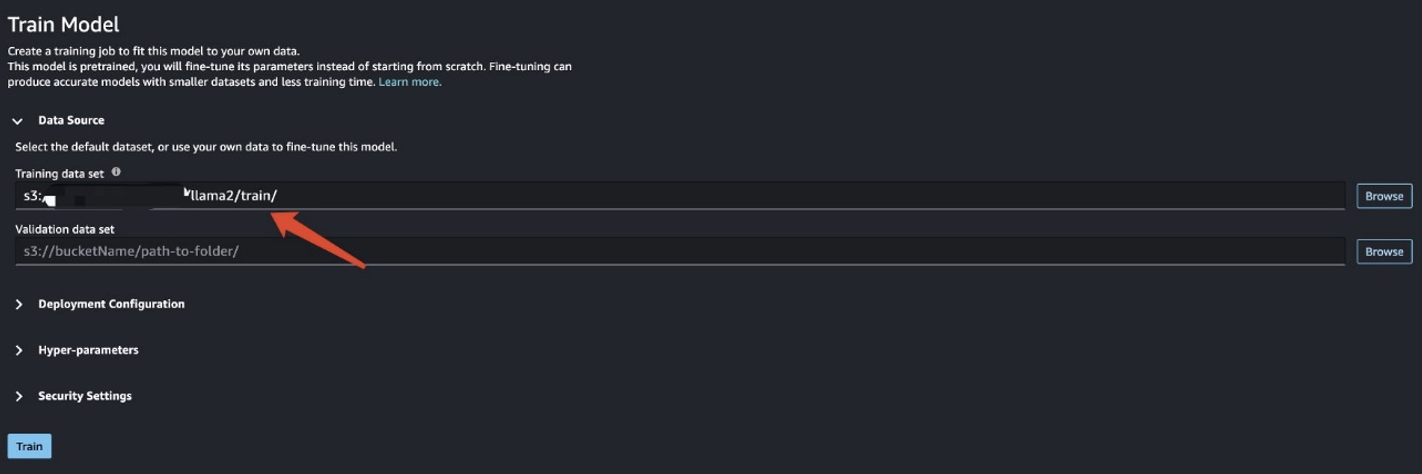
Saate jälgida koolitustöö olekut.
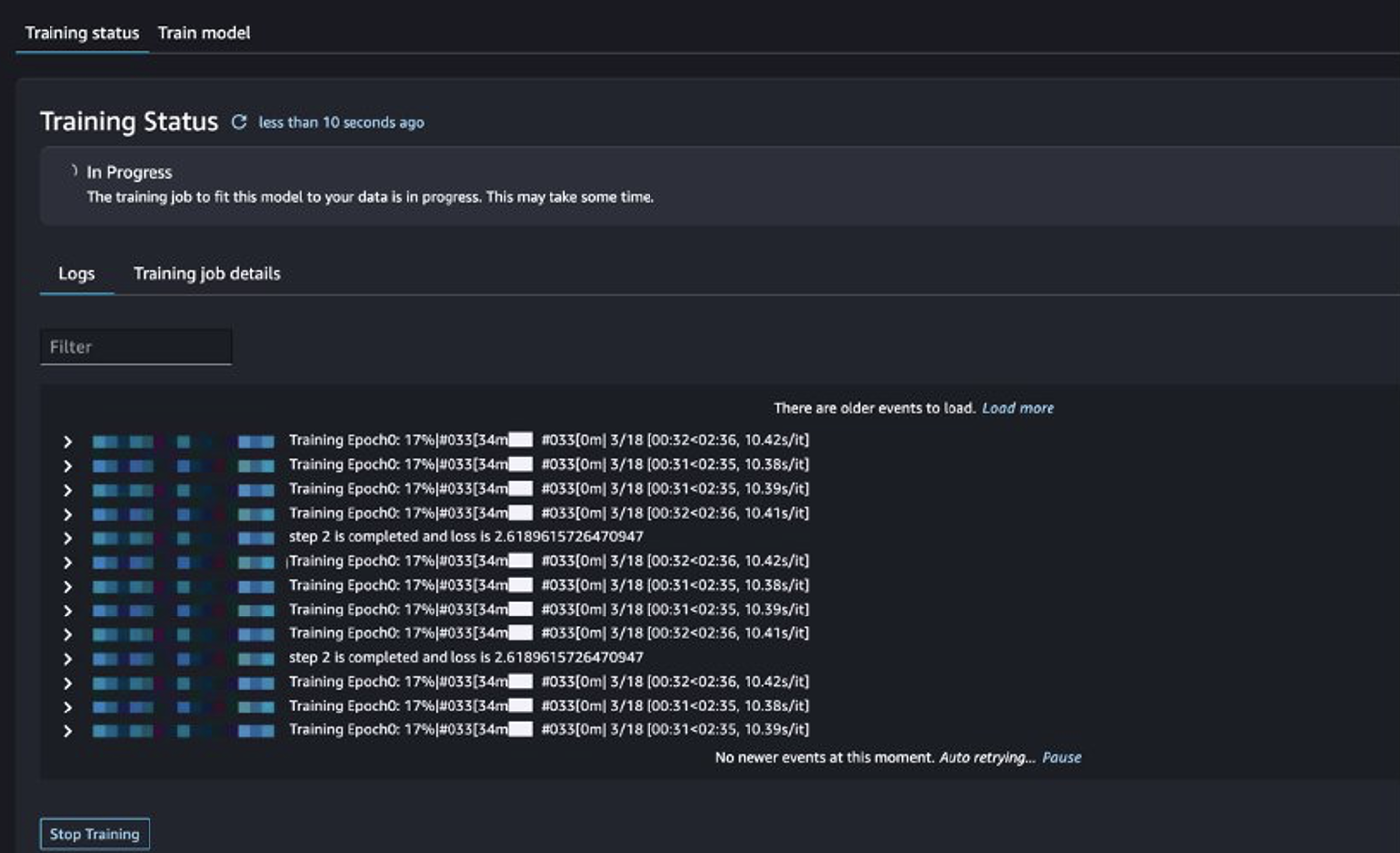
Hinnake peenhäälestatud mudelit
Pärast koolituse lõppu valige juurutada SageMaker JumpStartis oma peenhäälestatud mudeli juurutamiseks.

Kui mudel on edukalt juurutatud, valige Avage märkmik, mis suunab teid ettevalmistatud Jupyteri märkmikusse, kus saate oma Pythoni koodi käitada.

Märkmiku jaoks saate kasutada pilti Data Science 2.0 ja Python 3 tuuma.
Seejärel saate selles sülearvutis hinnata peenhäälestatud mudelit ja originaalmudelit.
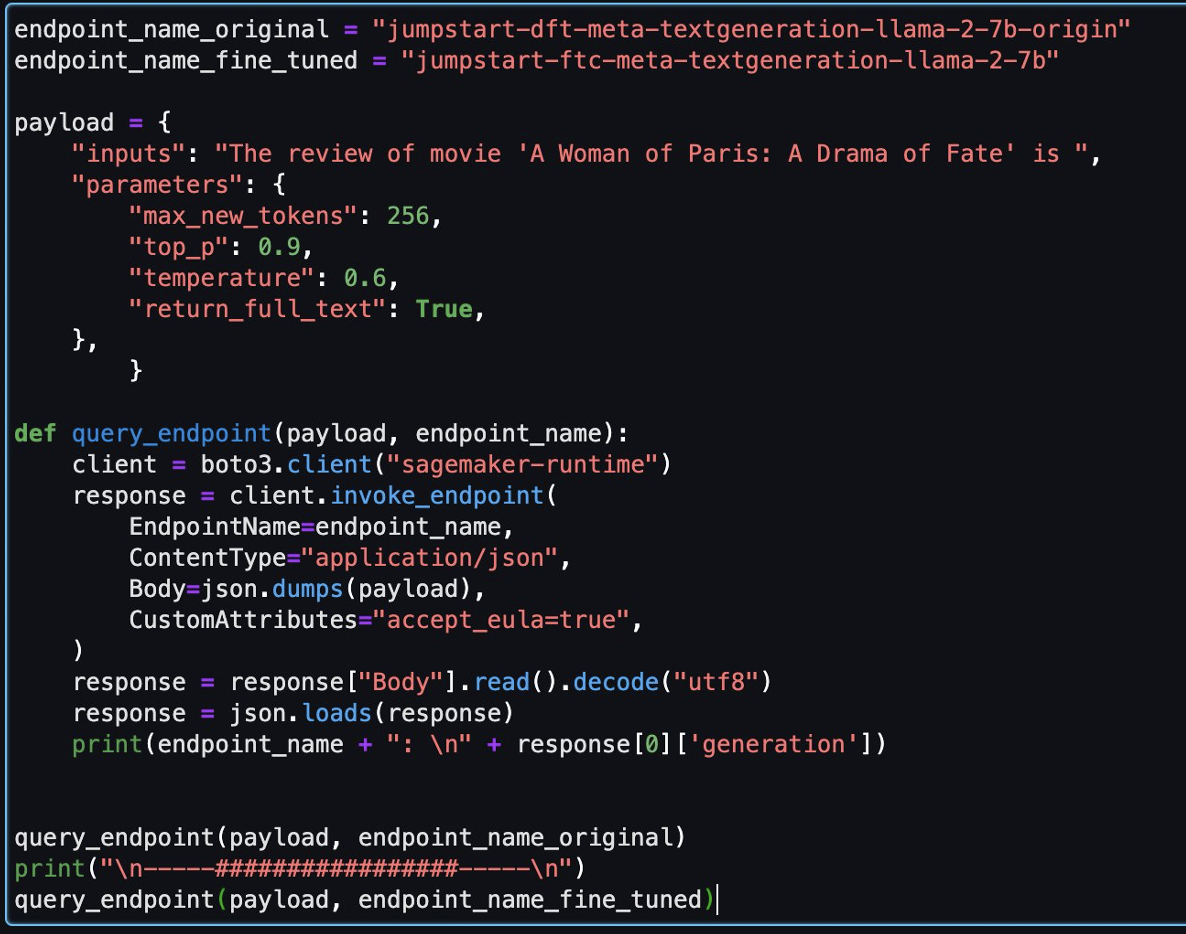
Järgmised on kaks vastust, mille algmudel ja peenhäälestatud mudel samale küsimusele tagastasid.

Varustasime mõlemale modellile sama lause: "Filmi "Pariisi naine: saatusedraama" arvustus on" ja laseme neil lause lõpetada.
Algne mudel väljastab mõttetud laused:
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
Seevastu peenhäälestatud mudeli väljundid sarnanevad pigem filmiarvustusega:
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
Ilmselgelt toimib peenhäälestatud mudel selle konkreetse stsenaariumi korral paremini.
Koristage
Pärast selle harjutuse lõpetamist täitke oma ressursside puhastamiseks järgmised sammud.
- Kustutage S3 ämber mis salvestab puhastatud andmestiku.
- Peatage EMR-i serverita keskkond.
- Kustutage SageMakeri lõpp-punkt mis majutab LLM-i mudelit.
- Kustutage SageMakeri domeen mis juhib teie märkmikke.
Teie loodud rakendus peaks vaikimisi peatuma automaatselt pärast 15-minutilist tegevusetust.
Üldjuhul ei pea te Athena keskkonda puhastama, sest kui te seda ei kasuta, siis pole tasusid.
Järeldus
Selles postituses tutvustasime Common Crawli andmestikku ja seda, kuidas kasutada EMR Serverlessi andmete töötlemiseks LLM-i peenhäälestamiseks. Seejärel demonstreerisime, kuidas kasutada SageMaker JumpStarti LLM-i peenhäälestamiseks ja ilma koodita juurutamiseks. Lisateavet EMR Serverlessi kasutusjuhtude kohta leiate artiklist Amazon EMR serverita. Lisateavet Amazon SageMaker JumpStarti mudelite hostimise ja peenhäälestuse kohta leiate jaotisest Sagemaker JumpStart dokumentatsioon.
Autoritest
 Shijian Tang on Amazon Web Servicesi analüüsilahenduste spetsialist.
Shijian Tang on Amazon Web Servicesi analüüsilahenduste spetsialist.
 Matthew Liem on Amazon Web Services'i vanemlahenduste arhitektuurijuht.
Matthew Liem on Amazon Web Services'i vanemlahenduste arhitektuurijuht.
 Dalei Xu on Amazon Web Servicesi analüüsilahenduste spetsialist.
Dalei Xu on Amazon Web Servicesi analüüsilahenduste spetsialist.
 Yuanjun Xiao on Amazon Web Servicesi vanemlahenduste arhitekt.
Yuanjun Xiao on Amazon Web Servicesi vanemlahenduste arhitekt.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/
- :on
- :mitte
- : kus
- $ UP
- 08
- 09
- 1
- 10
- 100
- 11
- 12
- 14
- 15%
- 17
- 2008
- 2013
- 23
- 258
- 40
- 50
- 52
- 7
- 9
- a
- Võimalik
- MEIST
- juurdepääs
- pääses
- juurdepääsetav
- raamatupidamine
- Kontod
- Saavutada
- aktiveeritud
- lisama
- lisamine
- Aafrika
- pärast
- Materjal: BPA ja flataatide vaba plastik
- võimaldab
- Ka
- hämmastav
- Amazon
- Amazon EMR
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- summa
- summad
- an
- analytics
- ja
- Teine
- mistahes
- Apache
- Apache Spark
- taotlus
- rakendused
- lähenemine
- arhitektuur
- OLEME
- AS
- At
- Austraalia
- Automaatne
- automaatselt
- saadaval
- AWS
- tagapõhi
- põhineb
- alus
- BE
- ilus
- sest
- saada
- enne
- alustama
- on
- Parem
- vahel
- Suur
- Big andmed
- Miljard
- keha
- mõlemad
- ehitama
- by
- kutsutud
- CAN
- Saab
- Võimsus
- viima
- juhul
- juhtudel
- muutuv
- iseloom
- koormuste
- kontrollima
- hiina
- Vali
- klass
- puhastama
- klient
- Cluster
- kood
- COM
- ühine
- tavaliselt
- võrdlema
- täitma
- seadistamine
- Arvestama
- koosneb
- konsool
- pidevalt
- sisaldama
- sisaldab
- sisu
- pidevalt
- kontrast
- Vastav
- vastab
- Maksma
- kuluefektiivne
- võiks
- loe
- cover
- looma
- loodud
- tava
- klient
- kohandatud
- andmed
- Andmete analüüs
- andmetöötlus
- andmeteadus
- andmekogumid
- Davis
- tegelema
- Pakkumised
- sügav
- vaikimisi
- määratlema
- Demo
- näitama
- Näidatud
- juurutada
- lähetatud
- kasutuselevõtu
- Tuletatud
- Vaatamata
- detailid
- määrates kindlaks
- skeem
- erinevused
- erinevalt
- suunatud
- otse
- arutame
- sukelduma
- do
- dokumendid
- domeen
- Domeenid
- donald
- Ära
- alla
- Draama
- juht
- kestus
- ajal
- iga
- Ajalugu
- lihtne
- kõrvaldab
- rõhutab
- kohtumine
- Inseneriteadus
- suurendamine
- sisene
- keskkond
- Eeter (ETH)
- hindama
- näide
- näited
- täitmine
- Teostama
- olemasolevate
- olemas
- uurima
- uurida
- laiendama
- väline
- väljavõte
- kaevandamine
- Väljavõtted
- juga
- vale
- kiiremini
- saatus
- Objekte
- vähe
- Valdkonnad
- fail
- Faile
- filtreerida
- filtreerimine
- Lõpuks
- leidma
- lõpetama
- esimene
- Järel
- järgneb
- eest
- formaat
- avastatud
- Raamistik
- raamistikud
- Alates
- edasi
- Üldine
- üldiselt
- teeniva
- põlvkond
- saama
- Git
- GitHub
- suunav
- Olema
- aitama
- Mesilaspere
- Hosting
- hosts
- Kuidas
- Kuidas
- aga
- HTML
- HTTPS
- sajad
- i
- IAM
- ID
- if
- illustreerib
- pilt
- import
- oluline
- parandama
- in
- lisatud
- hõlmab
- kaasates
- kasvav
- indeks
- info
- Infrastruktuur
- sisend
- sisendite
- paigaldama
- suhelda
- sisse
- kehtestama
- sisse
- probleem
- IT
- ITS
- tungraud
- töö
- Tööturg
- Json
- Jupyteri sülearvuti
- lihtsalt
- hoidma
- Võti
- keel
- Keeled
- suuremahuline
- hiljemalt
- algatama
- käivitamine
- viima
- laskma
- Tase
- raamatukogud
- nagu
- LIMIT
- liinid
- nimekiri
- Nimekirjad
- Laama
- llm
- kohalik
- asub
- liising
- loogika
- Logi sisse
- Vaata
- otsin
- lookup
- masin
- hooldus
- tegema
- Tegemine
- juht
- juhtiv
- palju
- kaart
- suur
- mai..
- mehhanism
- Vastama
- vastab
- mainimine
- Meta
- Metaandmed
- meetod
- protokoll
- Leevendada
- mudel
- mudelid
- igakuine
- rohkem
- kõige
- film
- Filmid
- palju
- mitmekordne
- nimi
- nimed
- NAVIGATSIOON
- vajalik
- Vajadus
- võrk
- Uus
- järgmine
- ei
- sõlme
- märkmik
- märkmikud
- saadud
- oktoober
- of
- on
- ONE
- ainult
- avatud
- avatud lähtekoodiga
- valik
- or
- originaal
- Muu
- välja
- välja toodud
- väljund
- väljundid
- üle
- ignoreerimine
- enda
- Pakk
- pakend
- pane
- Paber
- Parallel
- parameetrid
- Paris
- osa
- tee
- teed
- Maksma
- Inimesed
- jõudlus
- etendused
- täidab
- periood
- petabaiti
- Peter
- fotograaf
- inimesele
- Platon
- Platoni andmete intelligentsus
- PlatoData
- süžee
- võrra
- populaarne
- post
- sisse
- pre
- eelnev
- Valmistama
- valmis
- esmane
- protsess
- töödeldud
- töötlemine
- Produktsioon
- küsib
- anda
- tingimusel
- annab
- pakkudes
- avalikult
- eesmärkidel
- panema
- Python
- päringu
- küsimus
- kiiresti
- Töötlemata
- algandmed
- jõuda
- Lugenud
- valmis
- hiljuti
- hiljuti
- soovitatav
- rekord
- viitama
- viited
- regulaarselt
- suhe
- vabastatud
- remont
- asendama
- Taotlusi
- nõutav
- Nõuded
- Vahendid
- vastus
- vastuste
- kaasa
- Tulemused
- läbi
- Arvustused
- õige
- Roll
- Rory
- jooks
- jooksmine
- jookseb
- salveitegija
- sama
- Säästa
- Skaala
- Kaalud
- ketendamine
- skaneerib
- stsenaarium
- teadus
- käsikiri
- skripte
- sekundit
- Osa
- lõigud
- vaata
- segment
- valima
- SELF
- vanem
- Lause
- Serverita
- serverid
- Teenused
- komplekt
- kehtestamine
- mitu
- ta
- Lühike
- peaks
- näidatud
- tähendus
- sarnane
- alates
- ühekordne
- site
- SUURUS
- Võta aeglasemalt
- jupp
- So
- lahendus
- Lahendused
- supp
- allikas
- Säde
- spetsialist
- konkreetse
- SQL
- ssh
- alustatud
- Käivitus
- väljavõte
- avaldused
- olek
- Samm
- Sammud
- Veel
- Peatus
- salvestada
- ladustatud
- kauplustes
- Lugu
- lihtne
- strateegiad
- nöör
- stuudio
- esitama
- esitamine
- Edukalt
- selline
- piisav
- sobiv
- Lüliti
- sünkroonida.
- tabel
- Võtma
- sihtmärk
- Ülesanne
- ülesanded
- tensorivool
- tingimused
- testid
- tekst
- teksti genereerimine
- et
- .
- oma
- Neile
- SIIS
- Seal.
- Need
- nad
- kolmanda osapoole
- see
- kolm
- Läbi
- aeg
- ajatempel
- et
- jälgida
- koolitus
- reisib
- tõsi
- püüdma
- kaks
- liigid
- all
- struktureerimata
- ajakohastatud
- URL
- kasutama
- kasutage juhtumit
- Kasutatud
- Kasutaja
- kasutaja kommentaare
- Kasutajad
- kasutamine
- kasutades
- versioon
- virtuaalne
- mahud
- kõndima
- tahan
- tagaotsitav
- Ladu
- oli
- Tee..
- kuidas
- we
- web
- veebiteenused
- nädal
- Hästi
- M
- millal
- samas kui
- mis
- kuigi
- WHO
- Wildlife
- will
- william
- koos
- jooksul
- ilma
- naine
- töötas
- väärt
- kirjutama
- kirjutamine
- saak
- sa
- Sinu
- sephyrnet