Selle postituse on kirjutanud Pramod Nayak, LakshmiKanth Mannem ja Vivek Aggarwal LSEG madala latentsusajaga rühmast.
Tehingukulude analüüsi (TCA) kasutavad kauplejad, portfellihaldurid ja maaklerid laialdaselt tehingueelseks ja -järgseks analüüsiks ning see aitab neil tehingukulusid ja kauplemisstrateegiate tõhusust mõõta ja optimeerida. Selles postituses analüüsime valikuid pakkumise-küsimise vahesid LSEG puugi ajalugu – PCAP andmekogum kasutades Amazon Athena Apache Sparkile. Näitame teile, kuidas andmetele juurde pääseda, andmetele rakendatavaid kohandatud funktsioone määratleda, andmestikku päringuid teha ja filtreerida ning analüüsi tulemusi visualiseerida, ilma et peaksite muretsema infrastruktuuri seadistamise või Sparki konfigureerimise pärast isegi suurte andmekogumite puhul.
Taust
Optsioonide hinnaaruandlusamet (OPRA) toimib olulise väärtpaberiteabe töötlejana, kogudes, koondades ja levitades USA optsioonide viimase müügi aruandeid, hinnapakkumisi ja asjakohast teavet. 18 aktiivse USA optsioonibörsi ja üle 1.5 miljoni kõlbliku lepinguga mängib OPRA keskset rolli kõikehõlmavate turuandmete pakkumisel.
5. veebruaril 2024 kavatseb väärtpaberitööstuse automatiseerimise korporatsioon (SIAC) uuendada OPRA kanalit 48-lt 96-le multiedastuskanalile. Selle täiuse eesmärk on optimeerida sümbolite levitamist ja liinide võimsuse kasutamist vastuseks kasvavale kauplemisaktiivsusele ja volatiilsusele USA optsiooniturul. SIAC on soovitanud ettevõtetel valmistuda maksimaalseks andmeedastuskiiruseks kuni 37.3 GB/s.
Vaatamata sellele, et uuendus ei muuda kohe avaldatud andmete kogumahtu, võimaldab see OPRA-l andmeid levitada oluliselt kiiremini. See üleminek on dünaamilise optsioonituru nõudmiste rahuldamiseks ülioluline.
OPRA paistab silma kui üks mahukamaid vooge, 150.4. aasta kolmandas kvartalis on 3 miljardit sõnumit ühes päevas ja ühe päeva jooksul on vaja 2023 miljardit sõnumit. Iga sõnumi jäädvustamine on tehingukulude analüüsi, turu likviidsuse jälgimise, kauplemisstrateegia hindamise ja turu-uuringute jaoks ülioluline.
Andmete kohta
LSEG puugi ajalugu – PCAP on pilvepõhine hoidla, mille maht on üle 30 PB ja mis sisaldab ülikvaliteetseid globaalse turu andmeid. Need andmed kogutakse hoolikalt otse vahetusandmekeskustes, kasutades üleliigseid kogumisprotsesse, mis on strateegiliselt paigutatud peamistes esmastes ja varuandmevahetuskeskustes kogu maailmas. LSEG-i püüdmistehnoloogia tagab kadudeta andmete kogumise ja kasutab nanosekundilise ajatempli täpsuse jaoks GPS-i ajaallikat. Lisaks kasutatakse andmelünkade sujuvaks täitmiseks keerukaid andmearbitraaži tehnikaid. Pärast kogumist töödeldakse andmeid põhjalikult ja arutatakse ning seejärel normaliseeritakse need Parketi vormingusse, kasutades LSEG reaalajas Ultra Direct (RTUD) söödakäitlejad.
Normaliseerimisprotsess, mis on andmete analüüsiks ettevalmistamise lahutamatu osa, genereerib kuni 6 TB tihendatud Parketi faile päevas. Suur andmemaht on tingitud OPRA kõikehõlmavast olemusest, mis hõlmab mitut vahetust ja sisaldab arvukalt optsioonilepinguid, mida iseloomustavad erinevad atribuudid. Turu suurenenud volatiilsus ja turutegemise aktiivsus optsioonibörsidel suurendavad veelgi OPRA avaldatud andmete mahtu.
Tick History – PCAP atribuudid võimaldavad ettevõtetel teha erinevaid analüüse, sealhulgas järgmist:
- Kauplemiseelne analüüs – Hinnake potentsiaalset kaubandusmõju ja uurige ajalooandmete põhjal erinevaid täitmisstrateegiaid
- Kauplemisjärgne hindamine – Mõõtke tegelikke täitmiskulusid võrdlusnäitajatega, et hinnata täitmisstrateegiate toimivust
- Optimaalne täitmine - Viimistlege täitmisstrateegiaid, mis põhinevad ajaloolistel turumudelitel, et minimeerida turumõju ja vähendada üldisi kauplemiskulusid
- Riskijuhtimine – Tehke kindlaks libisemismustrid, tuvastage kõrvalekalded ja juhtige ennetavalt kauplemistegevusega seotud riske
- Toimivuse omistamine – Portfelli tootluse analüüsimisel eraldage kauplemisotsuste mõju investeerimisotsustest
LSEG Tick History – PCAP andmestik on saadaval AWS-i andmevahetus ja sellele pääseb juurde aadressil AWS Marketplace. Koos AWS-i andmevahetus Amazon S3 jaoks, pääsete PCAP-andmetele juurde otse LSEG-idest Amazoni lihtne salvestusteenus (Amazon S3) ämbrid, mis välistavad ettevõtete vajaduse salvestada oma andmete koopiad. See lähenemisviis lihtsustab andmete haldamist ja salvestamist, pakkudes klientidele kohest juurdepääsu kvaliteetsetele PCAP-i või normaliseeritud andmetele, mida on lihtne kasutada, integreerida ja märkimisväärne kokkuhoid andmete salvestamisel.
Athena Apache Sparkile
Analüütiliste püüdluste jaoks Athena Apache Sparkile pakub lihtsustatud sülearvuti kasutuskogemust, millele pääseb juurde Athena konsooli või Athena API-de kaudu, võimaldades teil luua interaktiivseid Apache Sparki rakendusi. Optimeeritud Sparki käitusajaga aitab Athena petabaitide arvu andmeid analüüsida, skaleerides dünaamiliselt Sparki mootorite arvu, mis jääb alla sekundi. Lisaks on tavalised Pythoni teegid, nagu pandad ja NumPy, sujuvalt integreeritud, võimaldades luua keerukat rakendusloogikat. Paindlikkus laieneb kohandatud teekide importimisele sülearvutites kasutamiseks. Athena for Spark mahutab enamiku avatud andmevormingutega ja on sujuvalt integreeritud AWS liim Andmekataloog.
Andmebaas
Selle analüüsi jaoks kasutasime LSEG Tick History – PCAP OPRA andmekogumit alates 17. maist 2023. See andmestik sisaldab järgmisi komponente.
- Parim pakkumine (BBO) – Teatab antud börsil väärtpaberi kõrgeima pakkumise ja madalaima pakkumise kohta
- Riigi parim pakkumine (NBBO) – Teatab kõigi börside kõrgeima pakkumise ja madalaima tagatise küsimise kohta
- Trades - Salvestab kõigi börside lõpetatud tehinguid
Andmekogum hõlmab järgmisi andmemahtusid:
- Trades – 160 MB, mis on jaotatud ligikaudu 60 tihendatud Parketi faili vahel
- BBO – 2.4 TB, mis on jaotatud ligikaudu 300 tihendatud Parketi faili vahel
- NBBO – 2.8 TB, mis on jaotatud ligikaudu 200 tihendatud Parketi faili vahel
Analüüsi ülevaade
OPRA Tick History andmete analüüsimine tehingukulude analüüsi (TCA) jaoks hõlmab turu noteeringute ja tehingute kontrollimist konkreetse kaubandussündmuse ümber. Selle uuringu osana kasutame järgmisi mõõdikuid.
- Tsiteeritud hinnavahe (QS) – Arvutatakse BBO müügi ja BBO pakkumise vahena
- Efektiivne levik (ES) – Arvutatakse tehinguhinna ja BBO keskpunkti vahena (BBO pakkumine + (BBO pakkumine – BBO pakkumine)/2)
- Efektiivne/tsiteeritud vahe (EQF) – Arvutatud kui (ES / QS) * 100
Arvutame need hinnavahed enne tehingut ja lisaks nelja intervalliga pärast tehingut (vahetult pärast, 1 sekund, 10 sekundit ja 60 sekundit pärast tehingut).
Seadistage Athena Apache Sparki jaoks
Athena konfigureerimiseks Apache Sparki jaoks toimige järgmiselt.
- Athena konsoolil, all Alustaminevalige Analüüsige oma andmeid PySparki ja Spark SQL-i abil.
- Kui kasutate Athena Sparki esimest korda, valige Loo töörühm.

- eest Töörühma nimi¸ sisestage töörühma nimi, näiteks
tca-analysis. - aasta Analüütika mootor jaotises valige Apache Spark.
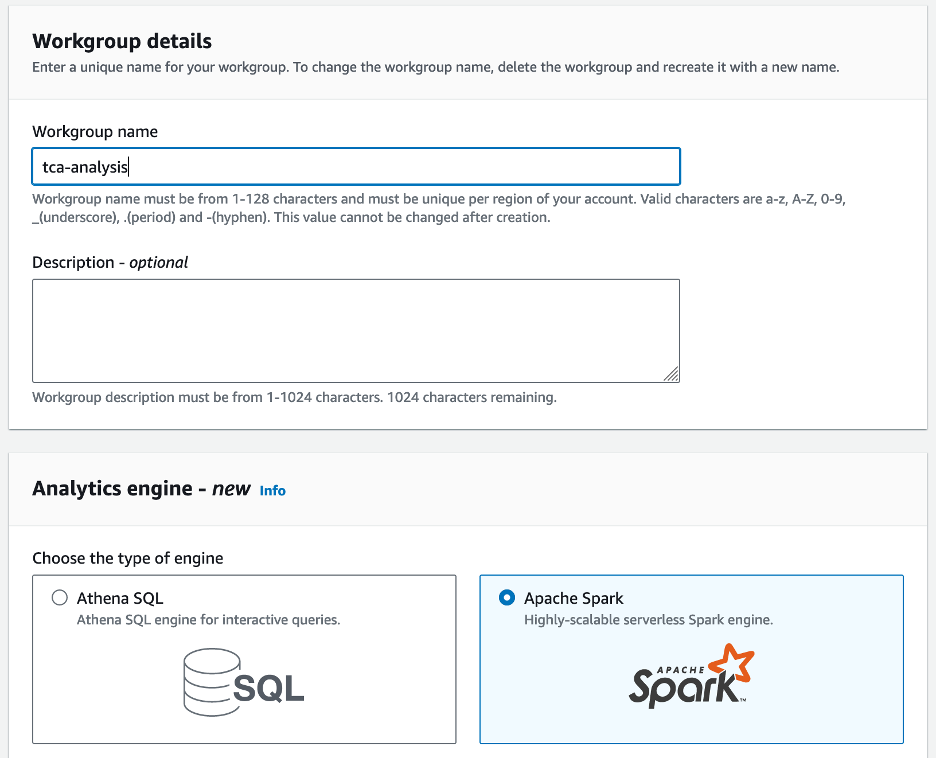
- aasta Täiendavad konfiguratsioonid jaotises saate valida Kasutage vaikeseadeid või pakkuda kohandatud AWS-i identiteedi- ja juurdepääsuhaldus (IAM) roll ja Amazon S3 asukoht arvutustulemuste jaoks.
- Vali Loo töörühm.
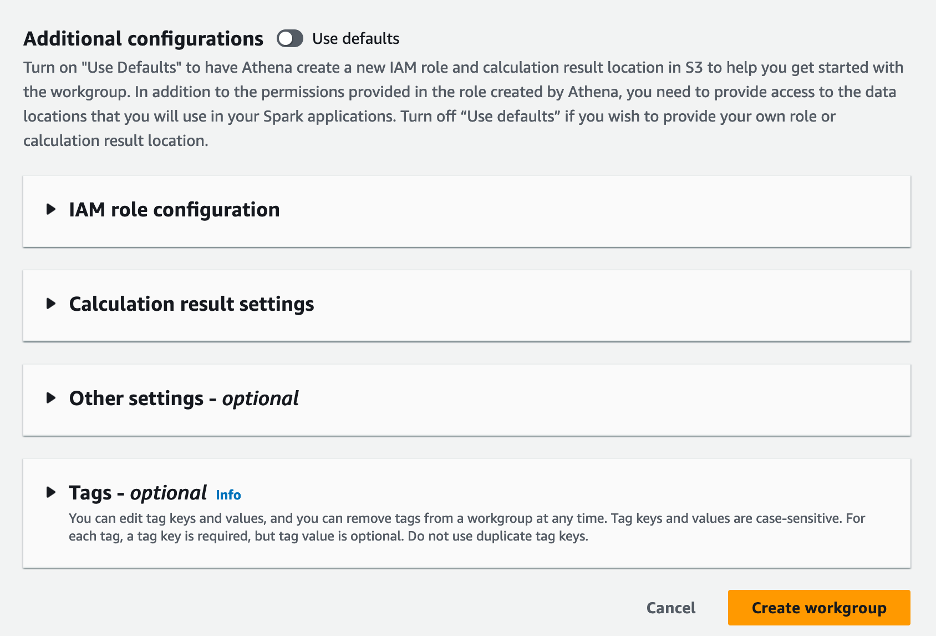
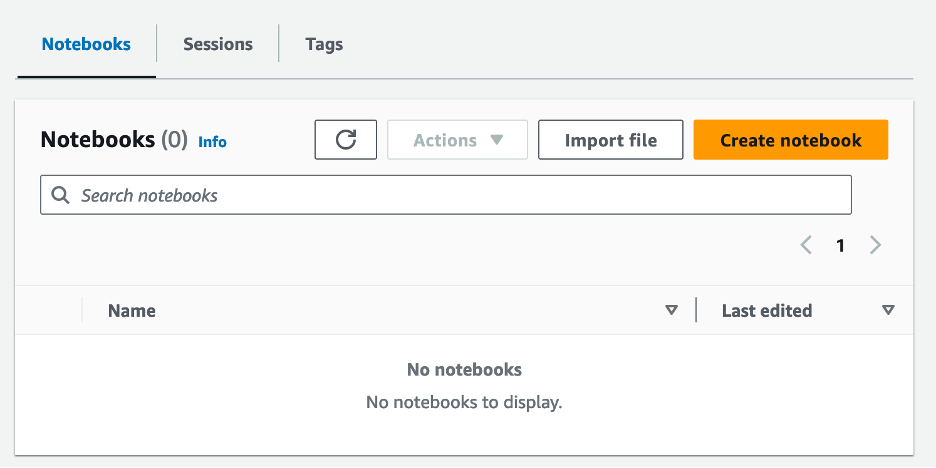
- Pärast töörühma loomist liikuge lehele Sülearvutid ja valige Loo märkmik.
- Sisestage oma märkmikule nimi, näiteks
tca-analysis-with-tick-history. - Vali Looma märkmiku loomiseks.
Käivitage oma märkmik
Kui olete Sparki töörühma juba loonud, valige Käivitage märkmiku redaktor all Alustamine.
![]()
Pärast märkmiku loomist suunatakse teid interaktiivsesse märkmikuredaktorisse.
![]()
Nüüd saame oma märkmikusse lisada ja käivitada järgmise koodi.
Looge analüüs
Analüüsi loomiseks tehke järgmised sammud.
- Impordi levinud teegid:
- Looge meie andmeraamid BBO, NBBO ja tehingute jaoks:
- Nüüd saame tuvastada tehingu, mida tehingukulude analüüsiks kasutada:
Saame järgmise väljundi:
Edaspidi kasutame esiletõstetud kaubandusteavet kaubandusliku toote (tp), kauplemishinna (tpr) ja kauplemisaja (tt) jaoks.
- Siin loome oma analüüsi jaoks mitmeid abifunktsioone
- Järgmises funktsioonis loome andmestiku, mis sisaldab kõiki noteeringuid enne ja pärast tehingut. Athena Spark määrab automaatselt, mitu DPU-d meie andmestiku töötlemiseks käivitada.
- Nüüd kutsume TCA analüüsi funktsiooni meie valitud kaubanduse teabega:
Visualiseerige analüüsi tulemused
Nüüd loome andmeraamid, mida oma visualiseerimiseks kasutame. Iga andmekaader sisaldab iga andmevoo (BBO, NBBO) viiest ajaintervallist ühe tsitaate:
Järgmistes jaotistes pakume näidiskoodi erinevate visualisatsioonide loomiseks.
Enne tehingut joonistage QS ja NBBO
Kasutage järgmist koodi noteeritud hinnavahe ja NBBO joonistamiseks enne tehingut:
![]()
Joonistage iga turu jaoks QS ja pärast tehingut NBBO
Kasutage järgmist koodi, et joonistada noteeritud hinnavahe iga turu ja NBBO kohta kohe pärast tehingut:
![]()
Joonistage QS iga ajaintervalli ja iga turu jaoks BBO jaoks
Kasutage järgmist koodi, et joonistada noteeritud hinnavahe iga ajaintervalli ja iga BBO turu jaoks:
![]()
Joonistage ES iga ajaintervalli ja BBO turu jaoks
Kasutage BBO iga ajaintervalli ja turu tegeliku hinnavahe joonistamiseks järgmist koodi:
Joonistage EQF iga ajaintervalli ja BBO turu jaoks
Kasutage BBO iga ajaintervalli ja turu tegeliku/noteeritud hinnavahe joonistamiseks järgmist koodi:
Athena Spark arvutustulemused
Kui käivitate koodiploki, määrab Athena Spark automaatselt, mitu DPU-d see arvutuse lõpuleviimiseks vajab. Viimases koodiplokis, kus me kutsume tca_analysis funktsioon, anname tegelikult Sparkile korralduse andmeid töödelda ja seejärel teisendame saadud Sparki andmeraamid Panda andmekaadriteks. See on analüüsi kõige intensiivsem töötlemise osa ja kui Athena Spark seda plokki käivitab, näitab see edenemisriba, kulunud aega ja seda, mitu DPU-d praegu andmeid töötleb. Näiteks järgmises arvutuses kasutab Athena Spark 18 DPU-d.
![]()
Kui konfigureerite oma Athena Spark sülearvuti, saate määrata maksimaalse DPU-de arvu, mida see saab kasutada. Vaikimisi on 20 DPU-d, kuid katsetasime seda arvutust 10, 20 ja 40 DPU-ga, et näidata, kuidas Athena Spark analüüsi käivitamiseks automaatselt skaleerub. Märkasime, et Athena Spark skaleerib lineaarselt, kuludes 15 minutit ja 21 sekundit, kui sülearvuti oli konfigureeritud maksimaalselt 10 DPU-ga, 8 minutit ja 23 sekundit, kui sülearvuti oli konfigureeritud 20 DPU-ga ning 4 minutit ja 44 sekundit, kui sülearvuti oli konfigureeritud. konfigureeritud 40 DPU-ga. Kuna Athena Spark võtab tasu DPU kasutuse põhjal sekundilise täpsusega, on nende arvutuste maksumus sarnane, kuid kui määrate suurema maksimaalse DPU väärtuse, saab Athena Spark analüüsi tulemuse palju kiiremini tagastada. Athena Sparki hinnakujunduse kohta lisateabe saamiseks klõpsake nuppu siin.
Järeldus
Selles postituses näitasime, kuidas saate Athena Sparki abil tehingukulude analüüsi tegemiseks kasutada LSEG-i Tick History-PCAP-i kõrgtäpsusega OPRA andmeid. OPRA andmete õigeaegne kättesaadavus koos Amazon S3 jaoks mõeldud AWS Data Exchange'i juurdepääsetavuse uuendustega vähendab strateegiliselt analüüsimiseks kuluvat aega ettevõtetel, kes soovivad luua kriitiliste kauplemisotsuste jaoks praktilisi teadmisi. OPRA genereerib iga päev umbes 7 TB normaliseeritud Parketi andmeid ja infrastruktuuri haldamine, et pakkuda OPRA andmetel põhinevat analüüsi, on keeruline.
Athena skaleeritavus puukide ajaloo suuremahulise andmetöötluse haldamisel – PCAP OPRA andmete jaoks muudab selle kaalukaks valikuks organisatsioonidele, kes otsivad AWS-is kiireid ja skaleeritavaid analüüsilahendusi. See postitus näitab sujuvat koostoimet AWS-i ökosüsteemi ja Tick History-PCAP andmete vahel ning seda, kuidas finantsasutused saavad seda sünergiat ära kasutada, et juhtida andmepõhist otsuste tegemist kriitiliste kauplemis- ja investeerimisstrateegiate jaoks.
Autoritest
![]() Pramod Nayak on LSEG madala latentsusajaga rühma tootehalduse direktor. Pramodil on üle 10-aastane kogemus finantstehnoloogia valdkonnas, keskendudes tarkvaraarendusele, analüütikale ja andmehaldusele. Pramod on endine tarkvarainsener ja kirglik turuandmete ja kvantitatiivse kauplemise vastu.
Pramod Nayak on LSEG madala latentsusajaga rühma tootehalduse direktor. Pramodil on üle 10-aastane kogemus finantstehnoloogia valdkonnas, keskendudes tarkvaraarendusele, analüütikale ja andmehaldusele. Pramod on endine tarkvarainsener ja kirglik turuandmete ja kvantitatiivse kauplemise vastu.
![]() LakshmiKanth Mannem on LSEG madala latentsusajaga grupi tootejuht. Ta keskendub madala latentsusega turu andmetööstuse andme- ja platvormtoodetele. LakshmiKanth aitab klientidel luua kõige optimaalsemaid lahendusi nende turuandmete vajadustele.
LakshmiKanth Mannem on LSEG madala latentsusajaga grupi tootejuht. Ta keskendub madala latentsusega turu andmetööstuse andme- ja platvormtoodetele. LakshmiKanth aitab klientidel luua kõige optimaalsemaid lahendusi nende turuandmete vajadustele.
![]() Vivek Aggarwal on vanem andmeinsener LSEG madala latentsusajaga rühmas. Vivek tegeleb hõivatud turuandmevoogude ja võrdlusandmevoogude töötlemiseks ja edastamiseks mõeldud andmekanalite arendamise ja hooldamisega.
Vivek Aggarwal on vanem andmeinsener LSEG madala latentsusajaga rühmas. Vivek tegeleb hõivatud turuandmevoogude ja võrdlusandmevoogude töötlemiseks ja edastamiseks mõeldud andmekanalite arendamise ja hooldamisega.
![]() Alket Memushaj on AWS-i finantsteenuste turu arendusmeeskonna peaarhitekt. Alket vastutab tehnilise strateegia eest, tehes koostööd partnerite ja klientidega, et juurutada AWS-i pilve ka kõige nõudlikumad kapitaliturgude töökoormused.
Alket Memushaj on AWS-i finantsteenuste turu arendusmeeskonna peaarhitekt. Alket vastutab tehnilise strateegia eest, tehes koostööd partnerite ja klientidega, et juurutada AWS-i pilve ka kõige nõudlikumad kapitaliturgude töökoormused.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/
- :on
- :on
- :mitte
- : kus
- $ UP
- 1
- 10
- 100
- 12
- 15%
- 150
- 16
- 160
- 17
- 19
- 20
- 200
- 2023
- 2024
- 23
- 27
- 30
- 300
- 40
- 400
- 60
- 7
- 750
- 8
- 90
- a
- MEIST
- juurdepääs
- pääses
- kättesaadavus
- juurdepääsetav
- üle
- aktiivne
- tegevus
- tegelik
- tegelikult
- lisama
- Lisaks
- adresseerimine
- ADEelis
- pärast
- vastu
- Aggarwal
- Eesmärgid
- Materjal: BPA ja flataatide vaba plastik
- Lubades
- juba
- Amazon
- Amazonase Athena
- Amazon Web Services
- an
- analüüsid
- analüüs
- Analüütiline
- analytics
- analüüsima
- analüüsides
- ja
- mistahes
- Apache
- Apache Spark
- API-liidesed
- taotlus
- rakendused
- kehtima
- lähenemine
- umbes
- arbitraaž
- vahekohtumenetlus
- OLEME
- ümber
- AS
- küsima
- hinnata
- seotud
- At
- atribuudid
- asutus
- automaatselt
- Automaatika
- kättesaadavus
- saadaval
- AWS
- Varundamine
- baar
- põhineb
- BE
- sest
- enne
- kriteeriumid
- BEST
- vahel
- pakkumine
- Miljard
- Blokeerima
- maaklerid
- ehitama
- kuid
- by
- arvutama
- arvutatud
- arvutus
- helistama
- CAN
- Võimsus
- kapital
- Kapitaliturud
- lüüa
- pildistatud
- Püüdmine
- kataloog
- Centers
- raske
- kanalid
- iseloomustatud
- koormuste
- valik
- Vali
- kliendid
- Cloud
- kood
- Kollektsioneerimine
- ühine
- kaalukad
- täitma
- Lõpetatud
- komponendid
- terviklik
- koosneb
- Läbi viima
- konfigureeritud
- seadistamine
- konsool
- konsolideerimine
- sisaldab
- lepingud
- aitama kaasa
- muutma
- KORPORATSIOONI
- Maksma
- kulud
- kaaskirjanik
- looma
- loodud
- loomine
- kriitiline
- otsustav
- Praegu
- tava
- Kliendid
- Kriips
- andmed
- andmekeskuste
- andmeinsener
- Andmevahetus
- andmehaldus
- andmetöötlus
- andmete salvestamine
- andmepõhistele
- andmekogumid
- päev
- Otsuse tegemine
- otsused
- vaikimisi
- määratlema
- tarne
- nõudlik
- nõudmisi
- näitama
- Näidatud
- juurutada
- detailid
- määrab
- arenev
- & Tarkvaraarendus
- arendusmeeskond
- erinevus
- erinev
- otse
- Juhataja
- jagatud
- jaotus
- mitu
- kahekordistada
- ajam
- dünaamiline
- dünaamiliselt
- dünaamika
- iga
- leevendada
- kasutusmugavus
- ökosüsteemi
- toimetaja
- Tõhus
- tõhusus
- abikõlblik
- kõrvaldades
- töötavad
- tööle
- võimaldama
- võimaldab
- haarav
- püüdlused
- Mootor
- insener
- Mootorid
- Lisaseade
- tagab
- sisene
- eskaleerimist
- Eeter (ETH)
- hindama
- hindamine
- Isegi
- sündmus
- Iga
- näide
- vahetamine
- Vahetused
- täitmine
- kogemus
- uurima
- ekspress
- laieneb
- kiiremini
- Lisaks
- Veebruar
- Viigipuu
- Faile
- täitma
- filtreerida
- finants-
- Finants institutsioonid
- finantsteenused
- finantstehnoloogia
- ettevõtetele
- esimene
- Esimest korda
- viis
- Paindlikkus
- keskendub
- keskendumine
- Järel
- eest
- formaat
- endine
- edasi
- neli
- FRAME
- Alates
- funktsioon
- funktsioonid
- edasi
- lünki
- genereerib
- saama
- antud
- Globaalne
- maailmaturul
- Go
- läheb
- GPS
- Grupp
- Käsitsemine
- Olema
- võttes
- he
- kõrgus
- aitab
- kvaliteetne
- rohkem
- kõrgeim
- Esiletõstetud
- ajalooline
- ajalugu
- elamispind
- Kuidas
- Kuidas
- http
- HTTPS
- IAM
- identifitseerima
- Identity
- if
- Vahetu
- kohe
- mõju
- import
- in
- Kaasa arvatud
- kasvanud
- tööstus
- info
- Infrastruktuur
- uuendusi
- teadmisi
- institutsioonid
- lahutamatu
- integreeritud
- integratsioon
- suhtlemist
- interaktiivne
- sisse
- keerukas
- investeering
- hõlmab
- IT
- jpg
- lihtsalt
- suur
- suuremahuline
- viimane
- Hilinemine
- algatama
- vähem
- raamatukogud
- joon
- Likviidsus
- liising
- loogika
- otsin
- Madal
- madalaim
- säilitamine
- peamine
- TEEB
- Tegemine
- juhtima
- juhtimine
- juht
- Juhid
- juhtiv
- viis
- palju
- Turg
- Turuinfo
- turu mõju
- turu uuring
- Turu volatiilsus
- turutegemine
- turud
- suur
- Mastering
- maksimaalne
- mai..
- mõõtma
- sõnum
- kirjad
- pedantne
- hoolikalt
- Meetrika
- miljon
- minimeerima
- protokoll
- järelevalve
- rohkem
- Pealegi
- kõige
- palju
- mitmekordne
- nimi
- loodus
- Navigate
- Vajadus
- vajadustele
- mitte ükski
- märkmik
- märkmikud
- number
- arvukad
- tuim
- vaadeldud
- of
- pakkuma
- Pakkumised
- on
- ONE
- optimaalselt
- optimeerima
- optimeeritud
- valik
- Valikud
- or
- organisatsioonid
- meie
- välja
- väljund
- üle
- üldine
- enda
- pandas
- osa
- partnerid
- kirglik
- mustrid
- tipp
- kohta
- täitma
- jõudlus
- Keskses
- inimesele
- Platon
- Platoni andmete intelligentsus
- PlatoData
- mängib
- palun
- süžee
- portfell
- portfellihaldurid
- paigutatud
- post
- kauplemisjärgne
- potentsiaal
- Täpsus
- Valmistama
- ettevalmistamisel
- hind
- hinnapoliitika
- esmane
- Peamine
- protsess
- Protsessid
- töötlemine
- Protsessor
- Toode
- tootehaldus
- tootejuht
- Toodet
- Edu
- anda
- pakkudes
- avaldatud
- Python
- Q3
- kvantitatiivne
- kogus
- päringu
- quotes
- määr
- Rates
- Lugenud
- reaalne
- reaalajas
- soovitatav
- andmed
- Red
- vähendama
- vähendab
- viide
- refinitiv
- Aruandlus
- Aruanded
- Hoidla
- nõue
- Vajab
- teadustöö
- vastus
- vastutav
- kaasa
- tulemuseks
- Tulemused
- tagasipöördumine
- riskide
- Roll
- jooks
- jookseb
- müük
- Skaalautuvus
- skaalautuvia
- Kaalud
- ketendamine
- sujuv
- sujuvalt
- Teine
- sekundit
- Osa
- lõigud
- Väärtpaberite
- turvalisus
- otsib
- valima
- väljavalitud
- vanem
- eri
- teenib
- Teenused
- komplekt
- kehtestamine
- näitama
- Näitused
- märgatavalt
- sarnane
- lihtne
- lihtsustatud
- ühekordne
- mahajäämus
- tarkvara
- tarkvaraarenduse
- Tarkvara insener
- Lahendused
- keeruline
- Pinge
- Säde
- konkreetse
- laiali
- Levib
- seisab
- Sammud
- ladustamine
- salvestada
- Strateegiliselt
- strateegiad
- Strateegia
- lihtsustab
- Uuring
- järgnev
- selline
- SWIFT
- sümbol
- sünergia
- Võtma
- võtmine
- meeskond
- Tehniline
- tehnikat
- Tehnoloogia
- katsetatud
- kui
- et
- .
- teave
- oma
- Neile
- SIIS
- Need
- see
- Läbi
- puuk
- aeg
- õigeaegne
- ajatempel
- Kapslid
- et
- Summa
- tp
- TPR
- kaubelda
- Ettevõtjad
- kaupleb
- Kauplemine
- Trading Strategies
- müügistrateegia
- tehing
- tehingukulud
- transformeerivate
- üleminek
- Ultra
- all
- läbib
- upgrade
- us
- Kasutus
- kasutama
- Kasutatud
- kasutusalad
- kasutamine
- kasutades
- väärtus
- eri
- visualiseerimine
- visualiseeri
- Lenduvus
- maht
- mahud
- oli
- we
- web
- veebiteenused
- millal
- mis
- laialdaselt
- will
- koos
- jooksul
- ilma
- Töörühm
- töö
- töötab
- ülemaailmne
- muretsema
- X
- aastat
- sa
- Sinu
- sephyrnet