Optical Character Recognition (OCR), käsitsi kirjutatud/prinditud tekstide masinkodeeritud tekstiks teisendamise meetod, on alati olnud arvutinägemise peamine uurimisvaldkond, kuna sellel on palju rakendusi erinevates valdkondades – pangad kasutavad OCR-i avalduste võrdlemiseks; Valitsused kasutavad OCR-i küsitluste tagasiside kogumiseks.

Käsikirja ja trükiteksti stiilide mitmekesisuse tõttu hõlmavad hiljutised OCR-i lähenemisviisid suurema täpsuse saavutamiseks sügavaid õpetusi. Kuna süvaõpe nõuab mudelikoolituse jaoks tohutul hulgal andmeid, saavad sellised ettevõtted nagu Google oma OCR-teenustega paljutõotavate tulemuste saavutamisel eelise.
Selles artiklis käsitletakse Google Visioni OCR-i üksikasju, sealhulgas lihtsat pythoni õpetust, rakenduste valikut, hindu ja muid alternatiive.
- Mis on Google Cloud Vision OCR?
- Lihtne õpetus
- Miks OCR?
- Näidiskasutusjuhtumid
- hinnapoliitika
- Google Cloud Vision OCR-i silmapaistvad funktsioonid
- Alternatiivid
- Levinud probleemid
Mis on Google Cloud Vision?

Google Cloud Vision OCR on osa Google'i pilvenägemise API-st, et eraldada piltidelt teksti. Täpsemalt on tähemärgi tuvastamisel abiks kaks märkust:
- Text_Annotation: See ekstraheerib ja väljastab masinkodeeritud tekste mis tahes kujutistest (nt tänavavaadete või maastike fotod). Kuna see oli algselt mõeldud kasutamiseks erinevates valgusolukordades, on mudel mõnes mõttes robustsem erineva stiili sõnade lugemisel, kuid ainult hõredamal tasemel. Tagastatud JSON-fail sisaldab nii terveid stringe kui ka üksikuid sõnu ja neile vastavaid piirdekaste.
- Dokumendi_tekst_annotatsioon: See on mõeldud eelkõige tiheda esitusega tekstidokumentide (nt skannitud raamatute) jaoks. Seega, kuigi see toetab väiksemate ja kontsentreeritumate tekstide lugemist, on see looduspiltide jaoks vähem kohandatav. Teave, nagu lõigud, plokid ja katkestused, sisaldub JSON-i väljundfailis.
Otsid OCR-lahendust, mis ületab Google Cloud Visioni puudused või tsooniline OCR? Anna nanonetid™ pööre suurema täpsuse, suurema paindlikkuse ja laiemate dokumenditüüpide jaoks!
Lihtne õpetus
Järgmises jaotises tutvustatakse lihtsat õpetust Google Vision API-ga alustamiseks, eriti selle kohta, kuidas seda kasutada Google Cloud Visioni OCR-teenuse jaoks.
Lihtne ülevaade
Selle idee on väga intuitiivne ja lihtne.
1) Põhimõtteliselt saadate pildi (kaugjuhtimispuldilt või kohalikust salvestusruumist) Google Cloud Vision API-sse.
2) Pilti töödeldakse eemalt Google Cloudis ja see toodab teie poolt väljakutsutud funktsioonile vastavad JSON-vormingud.
3) JSON-fail tagastatakse pärast funktsiooni väljakutsumist väljundina.
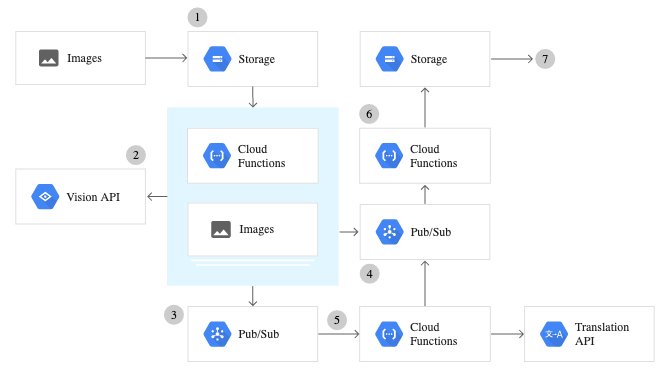
Google Cloud Vision API seadistamine
Google Vision API pakutavate teenuste kasutamiseks tuleb konfigureerida Google Cloud Console ja teha autentimiseks rida toiminguid. Järgnevalt on samm-sammult ülevaade kogu Vision API teenuse seadistamisest.
- Looge projekt Google Cloud Console'is – mis tahes Visioni teenuse kasutamise alustamiseks tuleb luua projekt. Projekt korraldab ressursse, nagu koostööpartnerid, API-d ja hinnateave.
- Arveldamise lubamine – vision API lubamiseks peate esmalt lubama oma projekti arveldamise. Hinnakujunduse üksikasju käsitletakse järgmistes jaotistes.
- Luba Vision API
- Loo teenusekonto – looge teenusekonto ja linkige loodud projektiga, seejärel looge teenusekonto võti. Võti väljastatakse ja laaditakse teie arvutisse JSON-failina.
- Seadistage keskkonnamuutuja GOOGLE_APPLICATION_CREDENTIALS; Selle keskkonnamuutuja seadistamiseks käivitage see Macis/Linuxis või Windowsis.
- Koodiplokid Maci/Linuxi jaoks
- Koodiblokid Windowsi jaoks
Eelnimetatud sammude täpsema protseduuri leiate Google Cloudi ametlikust dokumentatsioonist siit:
https://cloud.google.com/vision/docs/quickstart-client-libraries
Lihtne Google Visioni OCR-funktsioon Pythonis
Google Cloud Vision API töötab paljude populaarsete keeltega, alates Java, Node.js, Python ja Google'i enda keele Go. Lihtsuse huvides tutvustame Pythonis lihtsat helistamismeetodit.
def detect_text(path): """Detects text in the file.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.Image(content=content) response = client.text_detection(image=image) texts = response.text_annotations print('Texts:') for text in texts: print('n"{}"'.format(text.description)) vertices = (['({},{})'.format(vertex.x, vertex.y) for vertex in text.bounding_poly.vertices]) print('bounds: {}'.format(','.join(vertices))) Teisisõnu, meetod kutsub järelikult funktsiooni text_annotation, seejärel ekstraheerige vastused ja printige teave välja. dokumendi_tekst_annotatsioon saab kutsuda ka kasutades samamoodi tihedate tekstide hankimiseks. Pilte saab tuvastada ka eemalt, seadistades pildi järgmiselt:
image.source.image_uri = urikus uri on pildi uri.
Täpsemat koodi koodide kohta saab lugeda siit:
https://cloud.google.com/vision
Kas otsite OCR-lahendust, mis ületab Google Cloud Visioni puudused? Anna nanonetid™ pööre suurema täpsuse, suurema paindlikkuse ja laiemate dokumenditüüpide jaoks!
Pakutava väljundi tase
Teksti edasise andmeanalüüsi hõlbustamiseks pakuvad kaks Google'i OCR-funktsiooni kasutajatele erineval tasemel väljundit: text_annotation, nii terved stringid (kui Google peab seda üheks lauseks või fraasiks) ja üksikud sõnad sees; jaoks dokumendi_tekst_annotatsioon, kuna mudel on optimeeritud tiheda teksti jaoks, pakutakse väljundi osana lehte, plokki, lõiku, sõna ja katkestust.
Kui hästi see siiski töötab?
Kui vastupidavad on mudelid?
Nagu varem mainitud, pakub Google OCR-i jaoks kahte funktsiooni kahes erinevas olukorras. Järgnevalt kirjeldatakse kahe funktsiooni võimekust erinevat tüüpi andmete toomisel.
Prinditud andmed
Lihtsaim tõlgendatav andmetüüp on trükitud tekstiandmed, st arvutiga kirjutatud tekst prinditud ja skannitud. OCR on nõutav, kui meil on ainult nende andmete prinditud koopia, mitte masinkodeeritud originaaltekst. Kuna enamik neist tekstidest on tihe ja lehekülgede kaupa, dokumendi_tekst_annotatsioon oleks parem variant.
Käsitsi kirjutatud andmed
Sisu võib sisaldada käsitsi kirjutatud teksti ja käsitsi kirjutatud andmete stiilid võivad drastiliselt erineda. Sellegipoolest pakub Google Vision OCR korralikku täpsust seni, kuni käsitsi kirjutatud märkmed pole liiga segased. Olenevalt sellest, kui pakitud käsitsi kirjutatud andmete kandja on, kasutame juhtumipõhiselt ühte kahest funktsioonist.
Pööratud/looduslikud andmed
Kui kujutised või skannitud fotod on esitatud ebatavaliste või joondamata nurkade all, käsitleme neid kui metsikuid andmeid. Tekste võib olla raskem tuvastada ja seetõttu kasutame tavaliselt text_annotation funktsioon, mis oli mõeldud esmalt looduslike andmete töötlemiseks. Mõne vertikaalsete tekstide ja eri nurkade all jäädvustatud liiklusmärkide läbimise katsete põhjal näitame, et Google Vision OCR toimib tegelikult erinevatest keskkondadest pärit andmete puhul korralikult.
Miks OCR?
Paljud andmed, mis meil täna on, on struktureerimata vormingus. Näiteks pildi, skannitud dokumendi või foto puhul, kuigi inimesed suudavad tekstid kiiresti ära tunda ja tähendusi edasi tõlgendada, on kõik tekstiandmed vaid värvidega pikslid, mis ei anna masinatele tegelikku tähendust.

Kui ettevõtted või suurettevõtted tegelevad tohutu hulga paberitööga, muudab suur andmemaht võimatuks klassifitseerimise või andmetöötluse ainult inimliku jõupingutusega – just sel ajal muutub masinkodeeritud tekst käepäraseks.
Pärast OCR-i teisendamist saab teavet analüüsida mitme erineva meetodiga, sõltuvalt andmete olemusest.
- Arvandmete puhul saab korrelatsioonide analüüsimiseks vahetult rakendada statistilisi meetodeid. Võiksime kasutada ka traditsioonilisi masinõppe meetodeid (nt KNN, K-Means, lineaarne regressioon) või süvaõppe lähenemisviise, et luua regressiooni ja/või klassifitseerimise ennustavaid mudeleid.
- Tekstiandmete puhul võib olla vaja rohkem töötlemisetappe. Tekstiandmete analüüsimise ja tähenduslikuks statistikaks tõlgendamise protsessi nimetatakse sageli loomuliku keele töötlemiseks (NLP). Täpsemalt saaksime antud sisu põhjal eraldada numbreid või isegi semantika/atmosfääri.
Kõik need analüüsid võivad võimaldada ettevõtetel, eriti neil, kellel on iga päev tohutul hulgal uusi andmeid, luua tugevaid mudeleid ja isegi automatiseerida palju protsesse ning asendada traditsioonilised töömahukad ja vigaderohked lähenemisviisid. Järgmises jaotises käsitletakse mõningaid üksikasjalikke näiteid OCR-i kasutamise kohta.
Kas otsite OCR-lahendust, mis ületab Google Cloud Visioni puudused? Anna nanonetid™ pööre suurema täpsuse, suurema paindlikkuse ja laiemate dokumenditüüpide jaoks!
Näidiskasutusjuhtumid
Numbrimärgi lugemine

Võib-olla on tänapäeval OCR-i üks levinumaid kasutusviise numbrimärkide lugemise rakendus. Arenenud riikides on parkimisplatsidega sageli kaasas numbrimärkide lugemise mudelid, et määrata iga auto kohta sissesõiduaeg, väljumisaeg ja isegi täpne parkimiskoht. Mõned parklad on isegi ühendatud valitsusvõrguga, et võtta parkimistasu otse peredelt – see kõik leevendab üleliigseid inimlikke jõupingutusi.
Numbrimärgi OCR-mudeleid saab kasutada ka liiklusrikkumiste tuvastamiseks, mis hõlbustab politseil aega rikkuva auto andmete käsitsi sisestamiseks.
Kviitungi ja arve skaneerimine

Finantsprognoosid ning ettevõtete varade ja kohustuste tasakaalustamine on iga ettevõtte jaoks olulised tegevused. Kuna suured ettevõtted teevad aastaringselt suures koguses oste mitmest sektorist, peavad nad finantsaruannete koostamisel hoolikalt koguma ja töötlema kõik arved ja kviitungid.
OCR-i abil saame luua automatiseeritud torujuhtmeid, mis tunnevad ära mitmed arvevormingud ja teisendada need numbriteks. Tööjõupingutusi on vaja ainult kontrollimiseks ning struktureeritud andmed ja numbrid võimaldavad ettevõttel kiiresti tasakaalustada sisse- ja väljavoolu, koostada finantsprognoose ning jälgida ettevõtte rahandusega seotud pahatahtlikke manipuleerimisi.
Elektrilised tervisekaardid

Patsientide andmed on sageli hajutatud erinevatesse piirkondadesse, riikidesse või isegi erinevatesse riikidesse, sõltuvalt inimeste elustiilist. Kliinikute ja haiglate erineva stiili tõttu (suurtes haiglates võivad olla andmebaasid organiseeritud, samas kui väiksemate kliinikute arstid võivad andmed lihtsalt käsitsi üles kirjutada), patsientide vanusest (vanemad patsiendid võidakse sisestada konkreetsesse andmebaasi enne haigla renoveerimist ja lisamist). arvutid) ja üksikisikute asukohad (inimesed võivad kolida teise linna või isegi välismaale), võib universaalse arstiabi hoidmine olla tegelikult väga keeruline.
Hästi koolitatud OCR on seega kasulik EMR-i ühest haiglast teise ülekandmisel või käsitsi kirjutatud andmete masintekstiks muutmisel – mõlemad võivad kiirendada patsientide haigusloo kiiret ja kokkuvõtlikku mõistmist.
Vormid ja küsitlused

Organisatsioonid (nii riiklikud kui ka valitsusvälised) võivad sageli nõuda klientidelt või kodanikelt tagasisidet, et oma praegusi reklaamplaane ja tooteid täiustada. Kuna vormid kirjutatakse tavaliselt käsitsi, oleks potentsiaalselt raske teha otsest statistilist analüüsi. Seetõttu võib OCR abistada ja kiirendada struktureerimata andmete ja käsitsi kirjutatud uuringute arvulisteks arvudeks teisendamist, et hõlbustada arvutusi.
Kas otsite OCR-lahendust, mis ületab Google Cloud Visioni puudused? Anna nanonetid™ pööre suurema täpsuse, suurema paindlikkuse ja laiemate dokumenditüüpide jaoks!
Cloud Vision hinnakujundus
Google'i andmetel veebisaitnii text_annotation ja dokumendi_tekst_annotatsioon pakutakse järgmiselt samal hinnatasemel:
Iga kuu eest antakse esimesed 1000 ühikut tasuta, 1000–5000000 ühiku eest 1.5 dollarit 1000 ühiku kohta. Pärast 5000000 piiri saavutamist langeb hind 0.6 dollarile 1000 ühiku kohta (iga Google Vision API kaudu saadetud pilti käsitletakse üheks ühikuks).
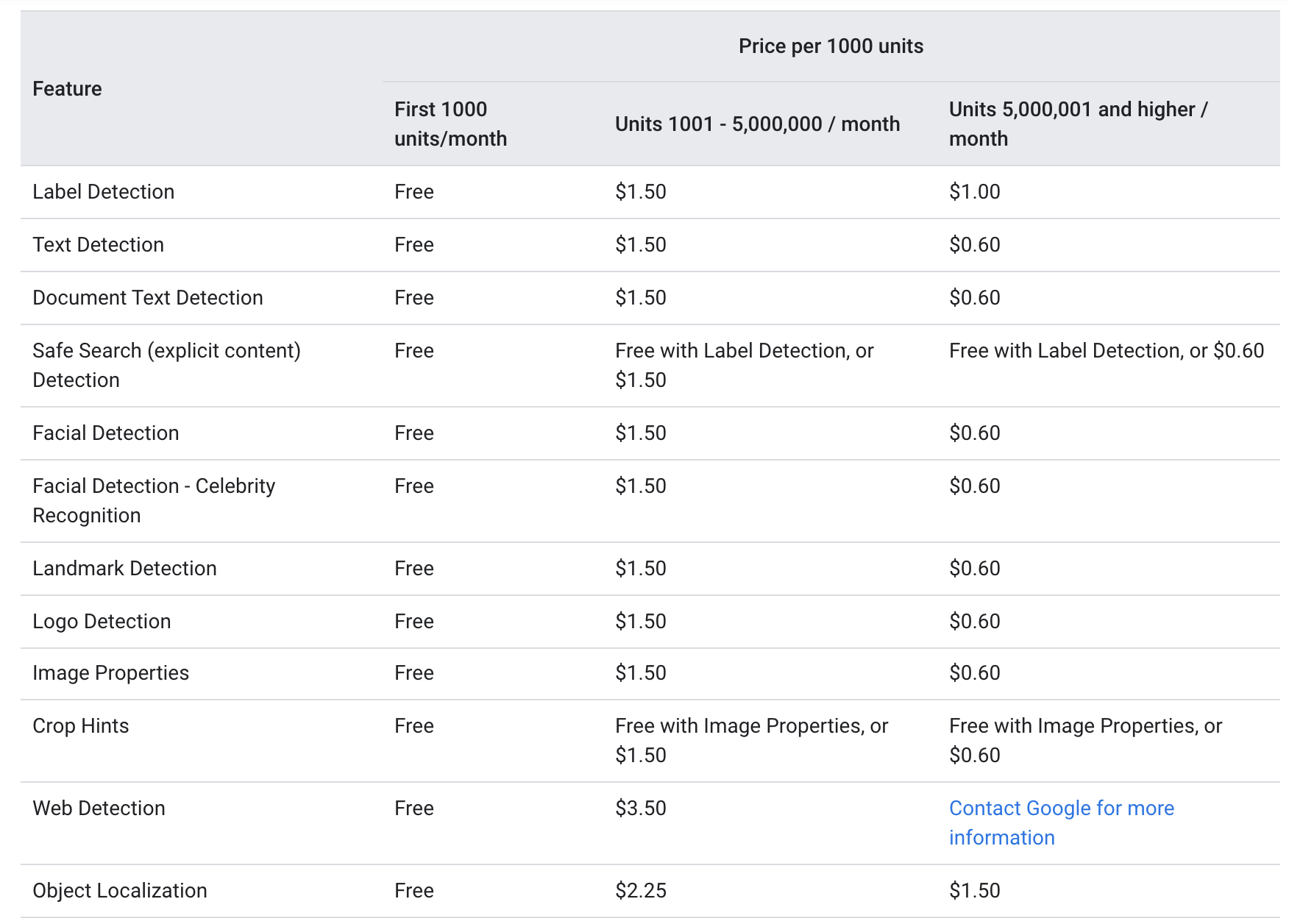
Eeltoodud hinnakujundus viitab sellele, et OCR-teenus on suhteliselt soodne nii harvema kasutusega väikeettevõtetele kui ka suurettevõtetele, kus teenust vajatakse palju rohkem kui 5000000 korda kuus.
Google Cloud Vision OCR-i silmapaistvad funktsioonid
Google'il OCR-il on mitmeid eeliseid, siin kirjeldame mõnda kõige olulisemat eelist.
- Jõuline - Need kaks funktsiooni, mis teenindavad kahte tüüpi tekstidokumente sõltuvalt kasutaja otsusest, muudavad Google Visioni OCR-i suhteliselt tugevamaks kui ühe mudeli OCR-mootorid.
- keele tugi — Võimalik, et suurima keeleandmebaasiga on Google teatanud, et selle OCR on rakendatav enam kui 60 keele jaoks, katsetades veel mõnekümne keelega ja kaardistab paljud ülejäänud mõne teise keelekoodi või üldise keeletuvastajaga.
- Kasutusmugavus - Mudel ise on osa sisseehitatud Google Visioni teegist. Pärast API-võtme konfigureerimise pisut tüütumat protsessi (mida nõuavad peaaegu kõik OCR-i mootorid) saab funktsioonide kutsumise meetodit kasutada paljudes keeltes väga lihtsalt.
- Skaleeritavus – Google'i hinnastrateegia julgustab kasutajaid API kasutamist suurendama, kuna suurem kasutamine toob kaasa odavama keskmise hinna.
- Kiirus - Google Cloudi salvestusplatvorm on API kasutamisega suurepäraselt kaasas. Piltide draivi üles laadides võib API reageerimisaeg olla väga kiire ja skaleeritav.

Kas otsite OCR-lahendust, mis ületab Google Cloud Visioni puudused? Anna nanonetid™ pööre suurema täpsuse, suurema paindlikkuse ja laiemate dokumenditüüpide jaoks!
Alternatiivid
Järgnevalt on toodud mõned alternatiivsed OCR-teenused peale Google Vision API koos iga teenuse eeliste ja puudustega.
ABBYY
ABBYY FineReader PDF on ABBYY poolt välja töötatud OCR, mis keskendub eelkõige pdf-i lugemisele.
- Plussid: ABBYY on üksikkasutajatele palju soodsam, kuna hinnakujundus on segmenteeritud väiksemateks sektoriteks (1000, 2000 lehekülge jne). See on suunatud ka mittetehnilistele klientidele, kuna see on kaubanduslik rakendus.
- Miinused: Tarkvara keskendub ainult PDF-vormingule ja suuremahulise OCR-i tegemisel muutub hind väga kalliks.
- Millal kasutada: Üksikkasutajatele, kes soovivad lihtsalt PDF-faile kiiresti käsitleda, võib ABBYY olla elujõulisem valik kui Google Vision API, mis annab rohkem paindlikkust, kuid nõuab lisakoode.
Microsoft
Microsoft Azure pakub ka OCR-i lugemise API-d.
- Plussid: Microsoft pakub veelgi suurema hulga kasutatavate andmete eest odavamat hinda. Azure'i pilvesalvestus pakub sarnaseid teenuseid nagu Google Cloud.
- Miinused: Tasuta taset pole, samas kui teised valikud pakuvad vähese kasutuse korral tasuta API-kõnesid.
- Millal kasutada: Väga suuremahulised OCR-i tootmistorud võiksid Microsofti hinnakujundusest kasu saada.
kofax
Sarnaselt ABBYY-ga pakub Kofax ka PDF-ide OCR-i lugemist
- Plussid: Hind on fikseeritud individuaalseks kasutamiseks, ettevõtetele pakutakse allahindlusi. Pakutakse ka 24/7 klienditugi.
- Miinused: Väidetavalt pole kvaliteet nii kõrge kui ABBYY oma.
- Millal kasutada: Väikesed ettevõtted madala kasutusvajadusega.
AWS-i tekst
AWS Textract täidab Google Vision API-ga võrreldes väga sarnast rolli. Nende teenused ja hinnakujundus on väga sarnased, seega sõltub sellest, milline neist valida, täielikult kliendi eelistustel.
Nanonetid
Erinevalt eelnevalt käsitletud teenustest liigitatakse Nanonetsi optilised tekstituvastused edasi konkreetsetesse kategooriatesse, kusjuures iga andmetüübi (nt kviitungid, arved, juhiload) jaoks on välja õpetatud tugevad mudelid.
- Plussid: Kategooriaspetsiifilised OCR-id, pakkudes seega veelgi paremaid tulemusi täpsuse osas, kui ettevõtted nõuavad OCR-i sihtspetsiifiliste rakenduste jaoks.
- Miinused: Nanonets OCR võib olla loodussätete jaoks vähem kasutatav tänu väga spetsiifilistele ja kohandatud mudelitele
- Millal kasutada: Kui ettevõtted nõuavad OCR-i teatud tüüpi andmete (nt arvete) jaoks, võib Nanonets olla kulusõbralik ja väga täpne valik.
Võite proovige Nanonets Online OCR-i siin.
Cloud Visioniga seotud tavalised probleemid
Selles viimases osas püüame käsitleda mõnda Stackoverflow'i küsimust seoses dokumentide skannimise ja OCR-iga
Dokumentide äratundmine närvivõrkude abil
See on Google'i OCR-i täpne kasutusviis! Järgige dokumentide skannimiseks ja teksti otsimiseks ülaltoodud samme.
Kõige olulisemate üksikasjade haaramine pärast OCR-i
Mõtet dokumentide kõige tähendusrikkama sisu sõelumisest nimetatakse loomuliku keele töötlemiseks. Kuna iga dokument sisaldab sellist teavet erinevas vormingus, oleks soovitatav kasutada selleks mõnda ML-lähenemist. Muidugi, kui kõik kaardid on samas vormingus, peaksid toimima ka reeglipõhised meetodid teatud võtmetähtedega tekstide toomiseks (nt kui see sisaldab @, on see meil).
Kas see saab võrguühenduseta töötada?
Link: https://stackoverflow.com/questions/63315520/google-cloud-vision-api-can-it-run-offline
Kahjuks ei. API kutsub Google Cloud OCR-i eemalt ja te ei saa võrguühenduseta töötada, kuna API maksab raha.
Kas see tuvastab, kas tekst on paksus või kaldkirjas?
Ei. Google OCR tuvastab suure tõenäosusega tekstisisu isegi siis, kui see on paksus või kaldkirjas, kuid OCR-mudel ei ole loodud fonditüüpide mõistmiseks.
Värskenda: Lisatud lisateavet lugejate päringute põhjal.
- &
- a
- kiirendatud
- konto
- täpne
- üle
- tegevus
- aadress
- eelised
- Materjal: BPA ja flataatide vaba plastik
- alternatiiv
- alternatiive
- alati
- summad
- analüüs
- analüüsima
- Teine
- API
- API-liidesed
- app
- kohaldatav
- taotlus
- rakendused
- rakendatud
- lähenemisviisid
- PIIRKOND
- ümber
- artikkel
- vara
- Autentimine
- automatiseerima
- Automatiseeritud
- keskmine
- Taevasina
- Azure pilv
- tagapõhi
- Pangad
- alus
- enne
- kasu
- Kasu
- arvete
- Blokeerima
- julge
- Raamatud
- piir
- puruneb
- auto
- Kaardid
- kindel
- märki
- tasu
- laetud
- odavam
- kontroll
- Linn
- klassifikatsioon
- Cloud
- Cloud Storage
- kood
- ühine
- Ettevõtted
- ettevõte
- võrreldes
- täiesti
- arvuti
- arvutid
- seotud
- Arvestama
- konsool
- sisaldab
- sisu
- sisu
- Konverteerimine
- Korporatsioonid
- Vastav
- kulud
- võiks
- riikides
- riik
- looma
- loodud
- loomine
- Praegune
- klient
- Klienditugi
- Kliendid
- andmed
- andmete analüüs
- andmetöötlus
- andmebaas
- andmebaasid
- päev
- tegelema
- otsus
- sügav
- sõltuv
- Olenevalt
- kirjeldama
- kavandatud
- üksikasjalik
- detailid
- tuvastatud
- Määrama
- arenenud
- erinev
- raske
- otsene
- otse
- mitmekesisus
- arstid
- dokumendid
- Domeenid
- alla
- ajam
- sõidu
- iga
- leevendada
- serv
- jõupingutusi
- jõupingutusi
- tekkinud
- võimaldama
- julgustab
- ettevõtete
- keskkond
- eriti
- põhiliselt
- jms
- näited
- Väljapääs
- Väljavõtted
- peredele
- KIIRE
- FUNKTSIOONID
- tagasiside
- Tasud
- Finances
- finants-
- Firma
- esimene
- fikseeritud
- Paindlikkus
- keskendub
- järgima
- Järel
- formaat
- vormid
- avastatud
- tasuta
- Alates
- funktsioon
- funktsioonid
- edasi
- Üldine
- saamine
- valitsuse
- Valitsused
- suurem
- käepide
- aitama
- siin
- Suur
- rohkem
- kõrgelt
- ajalugu
- haiglad
- Kuidas
- Kuidas
- HTTPS
- inim-
- Inimestel
- idee
- pilt
- pildid
- oluline
- võimatu
- parandama
- lisatud
- hõlmab
- Kaasa arvatud
- eraldi
- inimesed
- info
- info
- Näiteks
- intuitiivne
- küsimustes
- IT
- ise
- Java
- pidamine
- Võti
- töö
- keel
- Keeled
- suur
- suurem
- suurim
- Leads
- õppimine
- Tase
- taset
- Raamatukogu
- litsents
- Litsentsid
- elustiil
- Tõenäoliselt
- LINK
- kohalik
- liising
- kohad
- Pikk
- masin
- masinõpe
- masinad
- peamine
- tegema
- viis
- käsitsi
- kaardid
- märk
- suur
- tähendus
- tähendusrikas
- meditsiini-
- keskmine
- mainitud
- meetodid
- Microsoft
- ML
- mudel
- mudelid
- raha
- kuu
- rohkem
- kõige
- liikuma
- mitmekordne
- Natural
- loodus
- vajadustele
- võrk
- Sellegipoolest
- märkused
- number
- numbrid
- arvukad
- pakutud
- Pakkumised
- ametlik
- offline
- Internetis
- optimeeritud
- valik
- Valikud
- et
- Korraldatud
- Muu
- enda
- pakitud
- parkimine
- osa
- eriline
- eriti
- Mööduv
- Inimesed
- ehk
- plaanid
- inimesele
- Politsei
- populaarne
- võimas
- hind
- hinnapoliitika
- protsess
- Protsessid
- töötlemine
- Produktsioon
- Toodet
- projekt
- prognoosid
- paljutõotav
- reklaam
- anda
- tingimusel
- annab
- pakkudes
- Ostud
- kvaliteet
- kiiresti
- valik
- alates
- RE
- lugejad
- Lugemine
- hiljuti
- tunnistama
- andmed
- kohta
- piirkond
- kauge
- nõudma
- nõutav
- Nõuded
- Vajab
- teadustöö
- Vahendid
- vastus
- REST
- Tulemused
- tee
- Roll
- jooks
- sama
- skaalautuvia
- Skaala
- skaneerida
- skaneerimine
- Sektorid
- tunne
- Seeria
- teenus
- Teenused
- teenindavad
- komplekt
- kehtestamine
- märkimisväärne
- Märgid
- sarnane
- lihtne
- alates
- väike
- So
- tarkvara
- tahke
- lahendus
- mõned
- konkreetse
- eriti
- Spin
- etappidel
- alustatud
- avaldused
- statistiline
- statistika
- ladustamine
- Strateegia
- tänav
- struktureeritud
- toetama
- Toetab
- Uuring
- tingimused
- .
- seetõttu
- Läbi
- läbi kogu
- aeg
- korda
- täna
- suunas
- traditsiooniline
- liiklus
- koolitus
- Ülekanne
- transformeerivate
- liigid
- all
- mõistma
- mõistmine
- üksused
- Universaalne
- kasutama
- Kasutajad
- tavaliselt
- eri
- nägemus
- maht
- Watch
- kas
- kuigi
- WHO
- laiem
- aknad
- jooksul
- sõnad
- Töö
- töötab
- oleks
- X
- aasta
- Sinu