Amazoni punane nihe, laialdaselt kasutatav pilvandmeladu, on märkimisväärselt arenenud, et vastata kõige nõudlikuma töökoormuse jõudlusnõuetele. See postitus hõlmab üht sellist uut funktsiooni – mitmemõõtmelise andmepaigutuse sortimisklahvi.
Amazon Redshift parandab nüüd teie päringu jõudlust, toetades mitmemõõtmelise andmepaigutuse sortimisvõtmeid, mis on uut tüüpi sortimisvõti, mis sorteerib tabeli andmed filtripredikaatide järgi, mitte tabeli füüsiliste veergude järgi. Mitmemõõtmelised andmepaigutuse sortimisklahvid parandavad oluliselt tabelikontrollide toimivust, eriti kui teie päringu töökoormus sisaldab korduvaid skannimisfiltreid.
Amazon Redshift pakub juba võimalust automaatne tabeli optimeerimine (ATO), mis optimeerib automaatselt tabelite kujundust, rakendades sortimis- ja jaotusvõtmeid, ilma et oleks vaja administraatori sekkumist. Selles postituses tutvustame mitmemõõtmelisi andmepaigutuse sortimisklahve kui lisavõimalust, mida pakub ATO ja mida tugevdab Amazon Redshifti sortimisvõtme nõuandja algoritm.
Mitmemõõtmelise andmepaigutuse sortimisklahvid
Kui määrate tabeli automaatse sortimisklahviga, analüüsib Amazon Redshift ATO teie päringu ajalugu ja valib teie tabeli jaoks automaatselt kas üheveerulise sortimisvõtme või mitmemõõtmelise andmepaigutuse sortimisvõtme, lähtudes sellest, milline valik on teie töökoormuse jaoks parem. Kui on valitud mitmemõõtmeline andmepaigutus, konstrueerib Amazon Redshift mitmemõõtmelise sortimisfunktsiooni, mis tuvastab read, millele tavaliselt pääsevad juurde samad päringud, ning sortimisfunktsiooni kasutatakse seejärel päringu käitamise ajal andmeplokkide vahelejätmiseks ja isegi individuaalse predikaadi skannimise vahelejätmiseks. veerud.
Mõelge järgmisele kasutajapäringule, mis on kasutaja töökoormuses domineeriv päringumuster:
Amazon Redshift salvestab iga veeru andmed 1 MB kettaplokkidesse ning tabeli metaandmete osana igas plokis minimaalsed ja maksimaalsed väärtused. Kui päring kasutab a ulatusega piiratud predikaat, Amazon Redshift saab kasutada minimaalseid ja maksimaalseid väärtusi, et tabeli skannimise ajal kiiresti üle suure hulga plokke vahele jätta. Selle päringu filtri alampiirkonna veerus ei saa aga kasutada minimaalsete ja maksimaalsete väärtuste põhjal, milliseid plokke vahele jätta, ning selle tulemusel kontrollib Amazon Redshift kõiki pealkirjade tabelis olevaid ridu:
Kui kasutaja päringut käivitati titles kasutades üheveerulist sortimisklahvi sisse subregion, on eelmise päringu tulemus järgmine:
See näitab, et tabeli skannimine luges 2,164,081,640 XNUMX XNUMX XNUMX rida.
Skaneerimise parandamiseks titles tabelis, võib Amazon Redshift automaatselt otsustada kasutada mitmemõõtmelist andmepaigutuse sortimisvõtit. Kõik read, mis vastavad lower(subregion) like '%United States%' predikaat asuks tabeli spetsiaalses piirkonnas ja seetõttu skannib Amazon Redshift ainult neid andmeplokke, mis vastavad predikaadile.
Kui kasutaja päring on käivitatud titles kasutades mitmemõõtmelist andmepaigutuse sortimisvõtit, mis sisaldab lower(subregion) like '%United States%' predikaadina tulem sys_query_detail päring on järgmine:
See näitab, et tabeli skannimine luges 152,324,046 7 XNUMX rida, mis on ainult XNUMX% originaalist, ja see kasutas mitmemõõtmelise andmepaigutuse sortimisklahvi.
Pange tähele, et see näide kasutab mitmemõõtmelise andmepaigutuse funktsiooni esitlemiseks ühte päringut, kuid Amazon Redshift võtab arvesse kõiki tabeliga seotud päringuid ja saab luua mitu piirkonda, et rahuldada kõige sagedamini kasutatavaid predikaate.
Võtame teise näite, seekord keerulisemate predikaatide ja mitme päringuga.
Kujutage ette, et teil on laud items (cost int, available int, demand int) nelja reaga, nagu on näidatud järgmises näites.
| # id | hind | saadaval | nõudlus |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
Teie domineeriv töökoormus koosneb kahest päringust:
- 70% päringute muster:
- 20% päringute muster:
Traditsiooniliste sortimistehnikate korral võite valida tabeli sortimise kuluveeru alusel, nii et hindamine cost > 3 saab sorteerimisest kasu. Niisiis, üksuste tabel pärast sortimist, kasutades ühte cost veerg näeb välja järgmine.
| # id | hind | saadaval | nõudlus |
| Piirkond nr 1, maksumusega <= 3 | |||
| Piirkond nr 2, maksumusega > 3 | |||
| # id | hind | saadaval | nõudlus |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
Seda traditsioonilist sorti kasutades saame kohe välistada kaks ülemist (sinist) rida ID-ga 4 ja ID 2, kuna need ei rahulda cost > 3.
Teisest küljest sorteeritakse mitmemõõtmelise andmepaigutuse sortimisklahviga tabel kahe kasutaja töökoormuses sageli esineva predikaadi kombinatsiooni alusel, mis on cost > 3 ja available < demand. Selle tulemusel sorteeritakse tabeli read nelja piirkonda.
| # id | hind | saadaval | nõudlus |
| Piirkond nr 1, maksumusega <= 3 ja saadaval < nõudlusega | |||
| Piirkond #2, maksumusega <= 3 ja saadaval >= nõudlusega | |||
| Piirkond nr 3, maksumusega > 3 ja saadaval < nõudlus | |||
| Piirkond nr 4, maksumusega > 3 ja saadaval >= nõudlus | |||
| # id | hind | saadaval | nõudlus |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
See kontseptsioon on veelgi võimsam, kui seda rakendatakse üksikute ridade asemel tervetele plokkidele, kui rakendatakse keerukatele predikaatidele, mis kasutavad traditsiooniliste sortimistehnikate jaoks mittesobivaid operaatoreid (nt. like) ja kui seda rakendatakse rohkem kui kahele predikaadile.
Süsteemitabelid
Järgmised Amazon Redshift süsteemitabelid näitavad kasutajatele, kas nende tabelites ja päringutes kasutatakse mitmemõõtmelisi andmepaigutusi.
- Et teha kindlaks, kas konkreetne tabel kasutab mitmemõõtmelist andmepaigutuse sortimisvõtit, saate kontrollida, kas
sortkey1in svv_table_info on võrdneAUTO(SORTKEY(padb_internal_mddl_key_col)). - Et teha kindlaks, kas konkreetne päring kasutab tabelite kontrollimise kiirendamiseks mitmemõõtmelist andmepaigutust, saate kontrollida
step_attributeaasta sys_query_detail vaade. Väärtus on võrdnemulti-dimensionalkui skannimisel kasutati tabeli mitmemõõtmelise andmepaigutuse sortimisvõtit.
Jõudlusnäitajad
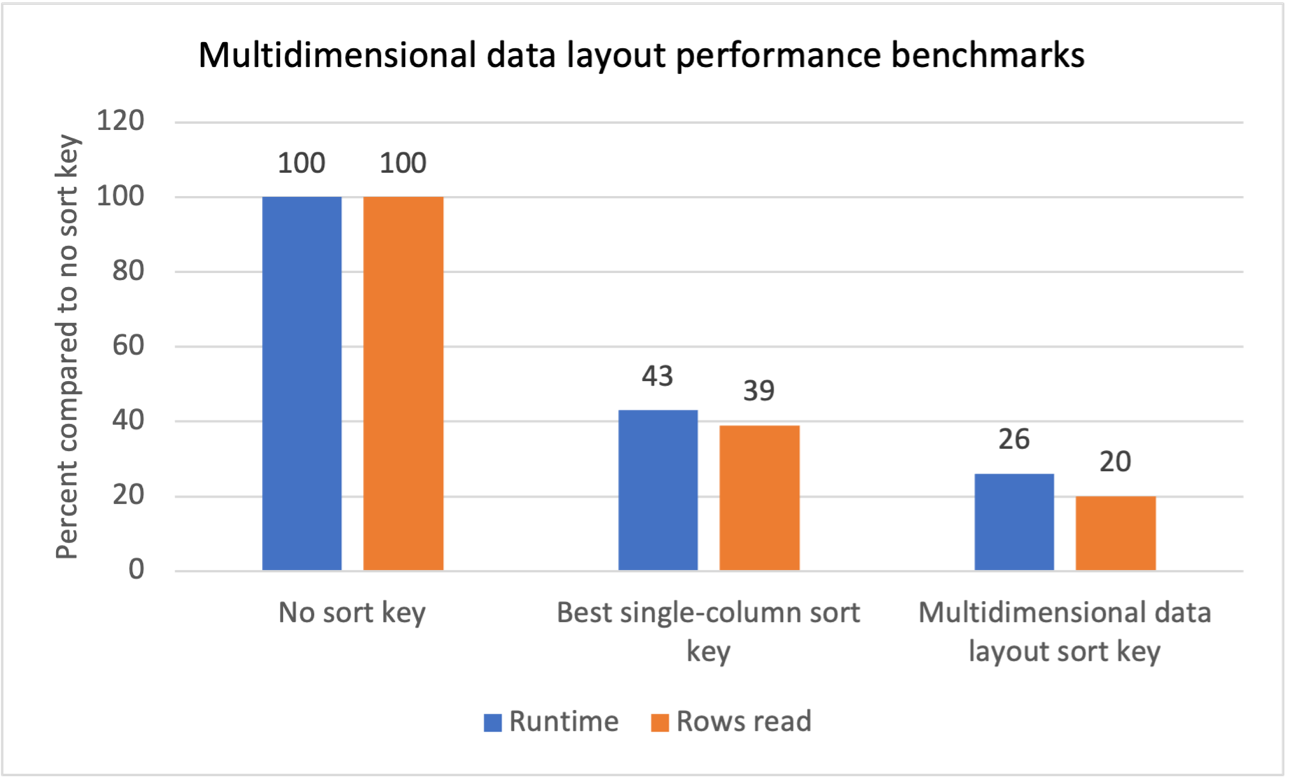
Tegime sisemise võrdlustesti mitme töökoormuse jaoks korduvate skannimisfiltritega ja nägime, et mitmemõõtmelise andmepaigutuse sortimisvõtmete kasutuselevõtt andis järgmised tulemused.
- 74% lühem kogu käitusaeg võrreldes sorteerimisvõtme puudumisega.
- 40% kogukäitusaja lühenemine võrreldes iga tabeli parima üheveerulise sortimisklahviga.
- Tabelitest loetavate ridade koguarvu vähenemine 80% võrreldes sortimisvõtme puudumisega.
- Tabelitest loetavate ridade koguarvu vähenemine 47% võrreldes iga tabeli parima üheveerulise sortimisklahviga.
Funktsioonide võrdlus
Mitmemõõtmelise andmepaigutuse sortimisvõtmete kasutuselevõtuga saab teie tabeleid nüüd sortida avaldiste järgi, mis põhinevad teie töökoormuses sageli esinevatel filtripredikaatidel. Järgmises tabelis on toodud Amazon Redshifti funktsioonide võrdlus kahe konkurendiga.
| tunnusjoon | Amazoni punane nihe | Võistleja A | Võistleja B |
| Veergude sortimise tugi | Jah | Jah | Jah |
| Avaldise järgi sortimise tugi | Jah | Jah | Ei |
| Automaatne veeru valik sortimiseks | Jah | Ei | Jah |
| Automaatsete avaldiste valik sortimiseks | Jah | Ei | Ei |
| Automaatne valik veergude sortimise või avaldiste sortimise vahel | Jah | Ei | Ei |
| Avaldiste sortimisomaduste automaatne kasutamine skaneerimise ajal | Jah | Ei | Ei |
Kaalutlused
Mitmemõõtmelise andmepaigutuse kasutamisel pidage meeles järgmist.
- Mitmemõõtmeline andmepaigutus on lubatud, kui määrate tabeliks SORTKEY AUTO.
- Amazon Redshift Advisor valib teie ajaloolist töökoormust analüüsides automaatselt tabeli jaoks üheveerulise sortimisvõtme või mitmemõõtmelise andmepaigutuse.
- Amazon Redshift ATO kohandab mitmemõõtmelise andmepaigutuse sortimise tulemusi vastavalt sellele, kuidas käimasolevad päringud suhtlevad töökoormusega.
- Amazon Redshift ATO säilitab mitmemõõtmelise andmepaigutuse sortimisvõtmed samamoodi nagu praegu olemasolevate sortimisvõtmete puhul. Viitama Töötamine automaatse tabeli optimeerimisega ATO kohta lisateabe saamiseks.
- Mitmemõõtmelise andmepaigutuse sortimisvõtmed töötavad nii ette nähtud klastritega kui ka serverita töörühmadega.
- Mitmemõõtmelised andmepaigutuse sortimisklahvid töötavad teie olemasolevate andmetega seni, kuni AUTOMAATNE SORTEERIMINE on teie tabelis lubatud ja tuvastatakse korduvate skannimisfiltritega töökoormus. Tabel korraldatakse ümber mitmemõõtmelise sortimisfunktsiooni tulemuste põhjal.
- Tabeli mitmemõõtmelise andmepaigutuse sortimisvõtmete keelamiseks kasutage muud tabelit:
ALTER TABLE table_name ALTER SORTKEY NONE. See keelab tabelis automaatse sortimisklahvi funktsiooni. - Mitmemõõtmelise andmepaigutuse sortimisvõtmed säilitatakse teie ette nähtud klastri taastamisel või üleviimisel serverita klastrisse või vastupidi.
Järeldus
Selles postituses näitasime, et mitmemõõtmelised andmepaigutuse sortimisvõtmed võivad oluliselt parandada päringu käitusaja jõudlust töökoormuste puhul, kus domineerivatel päringutel on korduvad skannimisfiltrid.
Amazon Redshift konsoolist eelvaateklastri loomiseks navigeerige Klastrid leht ja vali Loo eelvaateklaster. Saate luua klastri USA idaosas (Ohio), USA idaosas (N. Virginia), USA lääneosas (Oregon), Aasia Vaikse ookeani piirkonnas (Tokyo), Euroopas (Iirimaa) ja Euroopas (Stockholm) ning testida oma töökoormust.
Meile meeldiks kuulda teie tagasisidet selle uue funktsiooni kohta ja ootame teie kommentaare selle postituse kohta.
Autoritest
 Milind Oke on New Yorgis asuv andmelaospetsialisti lahenduste arhitekt. Ta on andmelaolahendusi ehitanud üle 15 aasta ja on spetsialiseerunud Amazon Redshiftile.
Milind Oke on New Yorgis asuv andmelaospetsialisti lahenduste arhitekt. Ta on andmelaolahendusi ehitanud üle 15 aasta ja on spetsialiseerunud Amazon Redshiftile.
 Jialin Ding on Learned Systems Groupi rakendusteadlane, kes on spetsialiseerunud masinõppe- ja optimeerimistehnikate rakendamisele, et parandada andmesüsteemide, nagu Amazon Redshift, jõudlust.
Jialin Ding on Learned Systems Groupi rakendusteadlane, kes on spetsialiseerunud masinõppe- ja optimeerimistehnikate rakendamisele, et parandada andmesüsteemide, nagu Amazon Redshift, jõudlust.
 Yanzhu Ji on Amazon Redshifti meeskonna tootejuht. Tal on kogemusi tootevisiooni ja strateegia alal valdkonna juhtivate andmetoodete ja platvormide alal. Tal on silmapaistvad oskused oluliste tarkvaratoodete loomisel, kasutades veebiarendust, süsteemikujundust, andmebaasi ja hajutatud programmeerimistehnikaid. Isiklikus elus meeldib Yanzhule maalida, fotograafia ja tennist mängida.
Yanzhu Ji on Amazon Redshifti meeskonna tootejuht. Tal on kogemusi tootevisiooni ja strateegia alal valdkonna juhtivate andmetoodete ja platvormide alal. Tal on silmapaistvad oskused oluliste tarkvaratoodete loomisel, kasutades veebiarendust, süsteemikujundust, andmebaasi ja hajutatud programmeerimistehnikaid. Isiklikus elus meeldib Yanzhule maalida, fotograafia ja tennist mängida.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- :on
- :on
- :mitte
- : kus
- 1
- 100
- 15 aastat
- 15%
- 152
- 7
- 8
- 9
- a
- kiirendama
- pääses
- Täiendavad lisad
- nõuandja
- pärast
- vastu
- algoritm
- Materjal: BPA ja flataatide vaba plastik
- juba
- Amazon
- Amazon Web Services
- an
- analüüsima
- analüüsides
- ja
- Teine
- rakendatud
- Rakendades
- OLEME
- AS
- Aasia
- Aasia ja Vaikse ookeani
- auto
- Automaatne
- automaatselt
- saadaval
- AWS
- põhineb
- BE
- sest
- olnud
- võrrelda
- kasu
- BEST
- Parem
- vahel
- Blokeerima
- Plokid
- sinine
- mõlemad
- Ehitus
- kuid
- by
- CAN
- võime
- kontrollima
- Vali
- Cloud
- Cluster
- Veerg
- Veerud
- kombinatsioon
- kommentaarid
- tavaliselt
- võrreldes
- võrdlus
- konkurendid
- keeruline
- mõiste
- Arvestama
- koosneb
- konsool
- ehitama
- sisaldab
- Maksma
- kaaned
- looma
- Praegu
- andmed
- andmekogus
- andmebaas
- otsustama
- pühendunud
- määratlema
- Nõudlus
- nõudlik
- Disain
- detailid
- tuvastatud
- Määrama
- & Tarkvaraarendus
- jagatud
- jaotus
- ei
- domineeriv
- Ära
- ajal
- iga
- Ida
- kumbki
- lubatud
- Kogu
- võrdne
- eriti
- Eeter (ETH)
- Euroopa
- hindamine
- Isegi
- arenenud
- näide
- olemasolevate
- kogemus
- väljendeid
- tunnusjoon
- tagasiside
- filtreerida
- Filtrid
- Järel
- järgneb
- eest
- edasi
- neli
- Alates
- funktsioon
- Grupp
- käsi
- Olema
- võttes
- he
- kuulama
- siin
- ajalooline
- ajalugu
- aga
- HTML
- HTTPS
- ID
- if
- kohe
- parandama
- parandab
- in
- hõlmab
- eraldi
- juhtivad
- selle asemel
- suhelda
- sisemine
- sekkumine
- sisse
- kehtestama
- sisse
- Sissejuhatus
- Iirimaa
- IT
- kirjed
- Võti
- võtmed
- suur
- Layout
- õppinud
- õppimine
- elu
- nagu
- meeldib
- Pikk
- Vaata
- näeb välja
- armastus
- masin
- masinõpe
- jääb
- juht
- viis
- maksimaalne
- Vastama
- Metaandmed
- võib
- rändavad
- meeles
- miinimum
- rohkem
- kõige
- mitmekordne
- Navigate
- Vajadus
- Uus
- uus funktsioon
- New York
- ei
- nüüd
- numbrid
- esineb
- of
- maha
- pakutud
- Ohio
- on
- ONE
- jätkuv
- ainult
- ettevõtjad
- optimeerimine
- Optimeerib
- valik
- or
- et
- Oregon
- originaal
- Muu
- välja
- tasumata
- üle
- Vaikne ookean
- maali
- osa
- eriline
- Muster
- jõudlus
- teostatud
- isiklik
- fotograafia
- füüsiline
- Platvormid
- Platon
- Platoni andmete intelligentsus
- PlatoData
- mängimine
- post
- võimas
- Säilinud
- Eelvaade
- Toodetud
- Toode
- tootejuht
- Toodet
- Programming
- omadused
- annab
- päringud
- kiiresti
- Lugenud
- vähendamine
- viitama
- piirkond
- piirkondades
- korduv
- Nõuded
- taastamine
- kaasa
- Tulemused
- jooks
- jooksmine
- jookseb
- sama
- skaneerida
- skaneerimine
- skaneerib
- teadlane
- hooaeg
- vaata
- valima
- väljavalitud
- valik
- Serverita
- Teenused
- komplekt
- ta
- näitama
- presentatsioon
- näitas
- näidatud
- Näitused
- märgatavalt
- ühekordne
- oskus
- So
- tarkvara
- Lahendused
- spetsialist
- spetsialiseerunud
- spetsialiseerunud
- kauplustes
- Strateegia
- Järgnevalt
- mahukas
- selline
- sobiv
- Toetamine
- süsteem
- süsteemid
- tabel
- Võtma
- meeskond
- tehnikat
- tennis
- test
- Testimine
- kui
- et
- .
- oma
- seetõttu
- nad
- see
- aeg
- pealkirjad
- et
- Tokyo
- ülemine
- Summa
- traditsiooniline
- kaks
- tüüp
- tüüpiliselt
- us
- kasutama
- Kasutatud
- Kasutaja
- Kasutajad
- kasutusalad
- kasutamine
- väärtus
- Väärtused
- pahe
- vaade
- virginia
- nägemus
- Ladu
- oli
- Tee..
- we
- web
- Veebidisain
- veebiteenused
- Läände
- millal
- kas
- mis
- laialdaselt
- will
- koos
- ilma
- Töö
- oleks
- aastat
- york
- sa
- Sinu
- sephyrnet