Sissejuhatus
Ühendamine tehisintellekti (AI) ja kunstilisus avavad uusi võimalusi loomingulises digitaalkunstis, silmapaistvalt difusioonimudelite kaudu. Need mudelid paistavad silma loomingulise AI kunsti põlvkonna seas, pakkudes tavapärastest närvivõrkudest erinevat lähenemist. See artikkel viib teid uurivale teekonnale difusioonimudelite sügavustesse, selgitades nende ainulaadset mehhanismi visuaalselt vapustavate ja loominguliselt rikkalike kunstiteoste meisterdamisel. Mõistke difusioonimudelite nüansse ja saage ülevaade nende rollist kunstilise väljenduse ümberdefineerimisel arenenud AI-tehnoloogiate objektiivi kaudu.

õppe eesmärgid
- Mõistke tehisintellekti difusioonimudelite põhikontseptsioone.
- Uurige difusioonimudelite ja traditsiooniliste närvivõrkude erinevust kunsti genereerimisel.
- Analüüsige kunsti loomise protsessi difusioonimudelite abil.
- Hinnake tehisintellekti loomingulist ja esteetilist mõju digitaalkunstis.
- Arutage tehisintellekti loodud kunstiteose eetilisi kaalutlusi.
See artikkel avaldati osana Andmeteaduse ajaveebi.
Sisukord
Difusioonimudelite mõistmine

Hajutusmudelid muudavad generatiivse tehisintellekti revolutsiooni, esitledes ainulaadset pildiloomemeetodit, mis erineb tavapärastest tehnikatest, nagu generatiivsed vastastikused võrgud (Generative Adversarial Networks, GAN). Alustades juhuslikust mürast, täiustavad need mudelid seda järk-järgult, meenutades maali peenhäälestavat kunstnikku, mille tulemuseks on keerukad ja ühtsed kujutised.
See järkjärguline täpsustamisprotsess peegeldab difusiooni metoodilist olemust. Siin muudab iga iteratsioon müra peenelt, tuues selle lõplikule kunstilisele visioonile lähemale. Väljund ei ole pelgalt juhuslikkuse produkt, vaid arenenud kunstiteos, mis erineb oma edenemise ja viimistluse poolest.
Difusioonimudelite kodeerimine nõuab närvivõrkude ja masinõpperaamistike, nagu TensorFlow või PyTorch, põhjalikku mõistmist. Saadud kood on keerukas ja nõuab ulatuslikku koolitust ekspansiivsete andmekogumite osas, et saavutada tehisintellekti loodud kunstis täheldatud nüansirikkad efektid.
Stabiilse difusiooni rakendamine art
AI kunstigeneraatorite, nagu stabiilsete difusioonimudelite, tulek nõuab keerukat kodeerimist sellistes platvormides nagu TensorFlow või PyTorch. Need mudelid paistavad silma oma võime poolest juhuslikkus metoodiliselt struktuuriks muuta, sarnaselt kunstnikule, kes lihvib esialgse visandi elavaks meistriteoseks.
Stabiilsed difusioonimudelid kujundavad AI-kunsti stseeni ümber, kujundades juhuslikkusest korrapäraseid pilte, vältides GAN-idele iseloomulikku konkurentsidünaamikat. Nad on suurepärased kontseptuaalsete juhiste tõlgendamisel visuaalseks kunstiks, soodustades sünergilist tantsu tehisintellekti võimaluste ja inimeste leidlikkuse vahel. PyTorchi rakendades jälgime, kuidas need mudelid viimistlevad kaose iteratiivselt selguseks, peegeldades kunstniku teekonda tärkavast ideest lihvitud loominguni.
Tehisintellekti loodud kunstiga katsetamine
See demonstratsioon süveneb AI-ga loodud kunsti põnevasse maailma, kasutades konvolutsioonilist närvivõrku, mida nimetatakse ConvDiffusionModel. See mudel on koolitatud erinevate kunstipiltide jaoks, mis hõlmavad jooniseid, maale, skulptuure ja graveeringuid, mis pärinevad see Kaggle'i andmestik. Meie eesmärk on uurida mudeli võimet tabada ja reprodutseerida nende kunstiteoste keerulist esteetikat.
Mudeliarhitektuur ja koolitus
Arhitektuurne disain
ConvDiffusionModel on oma tuumaks närvitehnoloogia ime, mis sisaldab keerukat kodeerija-dekoodri arhitektuuri, mis on kohandatud kunsti genereerimise nõudmistele. Mudeli struktuur on keeruline närvivõrk, mis integreerib täiustatud kodeerija-dekoodri mehhanisme, mis on spetsiaalselt loodud kunsti genereerimiseks. Täiendavate keerdkihtide ja vahelejätmise ühendustega, mis jäljendavad kunstiintuitsiooni, saab mudel kunsti lahata ja uuesti kokku panna, mõistes kompositsiooni ja stiili nutikalt.
- Kodeerija: Kodeerija on mudeli analüütiline silm, mis uurib iga sisendpildi pisiasju. Kui kujutised läbivad kodeerija konvolutsioonikihte, surutakse need järk-järgult varjatud ruumi – originaalse kunstiteose kompaktseks kodeeritud esituseks. Meie kodeerija mitte ainult ei kontrolli sisendpilte, vaid teeb seda tänu täiendavatele kihtidele ja partii normaliseerimise tehnikatele täiustatud tajusügavusega. See laiendatud uurimine võimaldab varjatud ruumis rikkalikumat, tihendatud esitust, peegeldades kunstniku sügavat mõtisklust teema üle.
- Dekooder: Seevastu dekooder toimib modelli loomingulise käena, võttes kodeerijast abstraktsed visandid ja puhudes neile elu sisse. See rekonstrueerib kunstiteose varjatud ruumist kiht kihi haaval, detail detaili haaval, kuni tekib terviklik pilt. Meie dekooder saab kasu ühenduste vahelejätmisest ja suudab kunstiteoseid suurema täpsusega rekonstrueerida. See vaatab uuesti läbi sisendi abstraktse olemuse ja kaunistab seda järk-järgult, saavutades algmaterjalile truu esituse. Täiustatud kihid töötavad koos, tagamaks, et lõplik pilt on ergas ja keerukas tükk, mis peegeldab sisendi kunstilisust.
Koolitusprotsess
ConvDiffusionModeli koolitus on teekond läbi kunstimaastiku, mis hõlmab 150 epohhi. Iga epohh tähistab kogu andmestiku täielikku läbimist, kusjuures mudel püüab täiustada oma arusaamist ja parandada loodud piltide täpsust.
- Hübriidkao funktsioon: Treeningu keskmes on keskmise ruudu vea (MSE) kadufunktsioon. See funktsioon kvantifitseerib erinevuse algse meistriteose ja mudeli rekreatsiooni vahel, pakkudes selget mõõdikut minimeerimiseks. Tutvustame tajukao komponenti, mis on tuletatud eelkoolitatud VGG võrgust, mis täiendab keskmise ruudu vea (MSE) mõõdikut. See kahekaoline strateegia sunnib mudelit austama originaalide kunstilist terviklikkust, täiustades samal ajal nende detailide tehnilist reprodutseerimist.
- Optimeerija: Ajakavandaja poolt dünaamiliselt kohandatud õppimiskiirusega juhib Adam optimeerija mudeli õppimist suurema targasti. See adaptiivne lähenemine tagab, et mudeli edusammud kunsti reprodutseerimise ja uuendamise õppimisel on ühtaegu püsivad ja jõulised.
- Iteratsioon ja täpsustamine: Treeningiteratsioonid on tants kunstilise olemuse säilitamise ja tehnilise replikatsiooni poole püüdlemise vahel. Iga tsükliga läheneb mudel truuduse ja loovuse sünteesile.
- Edenemise visualiseerimine: mudeli edenemise visualiseerimiseks salvestatakse treeningu ajal korrapäraste ajavahemike järel pilte. Need hetktõmmised pakuvad akent mudeli õppimiskõverale, näidates, kuidas selle loodud kunst areneb, muutudes iga epohhiga selgemaks, üksikasjalikumaks ja kunstiliselt sidusamaks.



Ülaltoodut demonstreeritakse järgmise koodilõigu kaudu:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from torchvision.models import vgg16
from PIL import Image
# Defining a function to check for valid images
def is_valid_image(image_path):
try:
with Image.open(image_path) as img:
img.verify()
return True
except (IOError, SyntaxError) as e:
# Printing out the names of all corrupt files
print(f'Bad file:', image_path)
return False
# Defining the neural network
class ConvDiffusionModel(nn.Module):
def __init__(self):
super(ConvDiffusionModel, self).__init__()
# Encoder
self.enc1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc2 = nn.Sequential(nn.Conv2d(64, 128,
kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3,
padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2,
stride=2))
# Decoder
self.dec1 = nn.Sequential(nn.ConvTranspose2d(256, 128,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(128))
self.dec2 = nn.Sequential(nn.ConvTranspose2d(128, 64,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(64))
self.dec3 = nn.Sequential(nn.ConvTranspose2d(64, 3,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid())
def forward(self, x):
# Encoder
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
# Decoder with skip connections
dec1 = self.dec1(enc3) + enc2
dec2 = self.dec2(dec1) + enc1
dec3 = self.dec3(dec2)
return dec3
# Using a pre-trained VGG16 model to compute perceptual loss
class VGGLoss(nn.Module):
def __init__(self):
super(VGGLoss, self).__init__()
self.vgg = vgg16(pretrained=True).features[:16].cuda()
.eval() # Only the first 16 layers
for param in self.vgg.parameters():
param.requires_grad = False
def forward(self, input, target):
input_vgg = self.vgg(input)
target_vgg = self.vgg(target)
loss = torch.nn.functional.mse_loss(input_vgg,
target_vgg)
return loss
# Checking if CUDA is available and set device to GPU if it is.
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
# Initializing the model and perceptual loss
model = ConvDiffusionModel().to(device)
vgg_loss = VGGLoss().to(device)
mse_loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30,
gamma=0.1)
# Dataset and DataLoader setup
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(root='/content/Images',
transform=transform, is_valid_file=is_valid_image)
dataloader = DataLoader(dataset, batch_size=32,
shuffle=True)
# Training loop
num_epochs = 150
for epoch in range(num_epochs):
for i, (inputs, _) in enumerate(dataloader):
inputs = inputs.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
# Calculate losses
mse = mse_loss(outputs, inputs)
perceptual = vgg_loss(outputs, inputs)
loss = mse + perceptual
# Backward pass and optimize
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}],
Step [{i+1}/{len(dataloader)}], Loss: {loss.item()},
Perceptual Loss: {perceptual.item()}, MSE Loss:
{mse.item()}')
# Saving the generated image for visualization
save_image(outputs, f'output_epoch_{epoch+1}
_step_{i+1}.png')
# Updating the learning rate
scheduler.step()
# Saving model checkpoints
if (epoch + 1) % 10 == 0:
torch.save(model.state_dict(),
f'/content/model_epoch_{epoch+1}.pth')
print('Training Complete')
Loodud kunstiteose visualiseerimine
Avaldades tehisintellektiga loodud kunsti
Kuna ConvDiffusionModel on nüüd täielikult koolitatud, nihkub fookus abstraktselt konkreetsele – potentsiaalilt AI-ga loodud kunsti tegelikustamisele. Järgnev koodilõik realiseerib mudeli õpitud kunstilised võimalused, muutes sisendandmed digitaalseks väljenduslõuendiks.
import os
import matplotlib.pyplot as plt
# Loading the trained model
model = ConvDiffusionModel().to(device)
model.load_state_dict(torch.load('/content/model_epoch_150.pth'))
model.eval() # Set the model to evaluation mode
# Transforming for the input image
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Function to de-normalize the image for viewing
def denormalize(tensor):
mean = torch.tensor([0.485, 0.456, 0.406]).
to(device).view(-1, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).
to(device).view(-1, 1, 1)
tensor = tensor * std + mean # De-normalize
tensor = tensor.clamp(0, 1) # Clamp to the valid image range
return tensor
# Loading and transforming the image
input_image_path = '/content/Validation/0006.jpg'
input_image = Image.open(input_image_path).convert('RGB')
input_tensor = transform(input_image).unsqueeze(0).to(device)
# Adding a batch dimension
# Generating the image
with torch.no_grad():
generated_tensor = model(input_tensor)
# Converting the generated image tensor to an image
generated_image = denormalize(generated_tensor.squeeze(0))
# Removing the batch dimension and de-normalizing
generated_image = generated_image.cpu() # Move to CPU
# Saving the generated image
save_image(generated_image, '/content/generated_image.png')
print("Generated image saved to '/content/generated_image.png'")
# Displaying the generated image using matplotlib
plt.figure(figsize=(8, 8))
plt.imshow(generated_image.permute(1, 2, 0))
# Rearrange the channels for plotting
plt.axis('off') # Hide the axes
plt.show()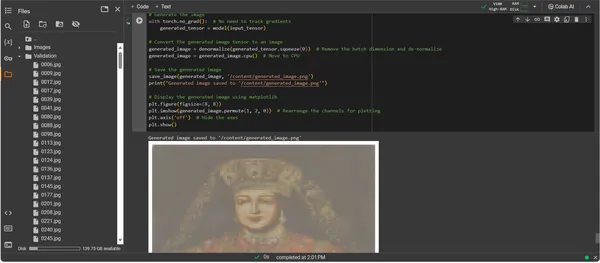

Kunstiteose genereerimise koodi tutvustus
- Ülestõusmise mudel: Esimene samm kunstiteoste loomisel on meie koolitatud ConvDiffusionModeli taaselustamine. Mudeli õpitud kaalud laaditakse ja viiakse hindamisrežiimi, seadistades loomiseks ilma selle parameetreid täiendavalt muutmata.
- Pildi teisendus: Treeningrežiimiga kooskõla tagamiseks töödeldakse sisendpilte sama teisenduste jada kaudu. See hõlmab suuruse muutmist, et see vastaks mudeli sisendmõõtmetele, tensori teisendamist PyTorchi ühilduvuse jaoks ja treeningandmete statistilisel profiilil põhinevat normaliseerimist.
- Denormaliseerimise utiliit: Kohandatud funktsioon pöörab eeltöötluse efektid ümber, skaleerides tensori ümber algse pildi värvivahemiku järgi. See samm on hädavajalik genereeritud väljundi visuaalselt täpseks esituseks.
- Sisestuse ettevalmistamine: Pilt laaditakse ja sellele tehakse eelnimetatud teisendused. Oluline on märkida, et see pilt on muusa, millest AI inspiratsiooni ammutab – vaikne sosin sütitab mudeli sünteetilise kujutlusvõime.
- Kunstiteose süntees: Edasiliikumise õrnas tantsus tõlgendab mudel sisendtensorit, võimaldades selle kihtidel teha koostööd uue kunstilise visiooni loomisel. Tehke seda protsessi ilma gradiente jälgimata, kuna oleme nüüd rakenduse, mitte koolituse valdkonnas.
- Pildi teisendamine: Mudeli tensorväljund, mis hoiab nüüd digitaalselt sündinud kunstiteoseid, on denormaliseeritud, tõlgides mudeli loomingu tagasi tuttavasse värvi- ja valgusruumi, mida meie silmad oskavad hinnata.
- Kunstiteose ilmutus: Teisendatud tensor asetatakse digitaalsele lõuendile, mis kulmineerub salvestatud pildifailiga. See fail on aken tehisintellekti loomingulisse hinge, sellele elu andnud dünaamilise protsessi staatiline kaja.
- Kunstiteose otsimine: Skript lõpetab loodud pildi salvestamisega määratud teele ja teatab selle valmimisest. Salvestatud pilt, õpitud kunstiliste põhimõtete ja tärkava loovuse süntees, on eksponeerimiseks ja mõtisklemiseks valmis.
Väljundi analüüsimine
ConvDiffusionModeli väljund kujutab endast kujundit, millel on selge suund ajaloolisele kunstile. Viimistletud riietusega AI-ga renderdatud pilt peegeldab klassikaliste portreede suurejoonelisust, kuid samas on see eristuva ja kaasaegse puudutusega. Katsealuse riietus on tekstuurirohke, segades modelli õpitud mustreid uudse tõlgendusega. Õrnad näojooned ning valguse ja varju peen koosmäng demonstreerivad tehisintellekti nüansirikkaid arusaamu traditsioonilistest kunstitehnikatest. See kunstiteos annab tunnistust mudeli keerukast väljaõppest, peegeldades elegantset ajaloolise kunsti sünteesi läbi täiustatud masinõppe prisma. Sisuliselt on see digitaalne kummardus minevikule, mis on meisterdatud oleviku algoritmidega.
Väljakutsed ja eetilised kaalutlused
Kunsti genereerimise difusioonimudelite rakendamine toob endaga kaasa mitmeid väljakutseid ja eetilisi kaalutlusi, mida peaksite kaaluma:
- Andmete päritolu: Koolituse andmekogumeid tuleb vastutustundlikult kureerida. Oluline on kontrollida, et levitusmudelite koolitamiseks kasutatavad andmed ei sisaldaks autoriõigusega kaitstud või kaitstud teoseid ilma nõuetekohase loata.
- Eelarvamus ja esindus: AI mudelid võivad oma treeningandmetes säilitada eelarvamusi. Mitmekesiste ja kaasavate andmekogumite tagamine on oluline, et vältida stereotüüpide tugevdamist tehisintellekti loodud kunstis.
- Väljundi juhtimine: Kuna difusioonimudelid võivad genereerida laia valikut väljundeid, on vaja seada piirid, et vältida sobimatu või solvava sisu loomist.
- Õiguslik raamistik: Tugeva õigusraamistiku puudumine AI nüansside käsitlemiseks loomeprotsessis on väljakutse. Seadusandlus peab arenema, et kaitsta kõigi asjaosaliste õigusi.
Järeldus
Difusioonimudelite tõus AI-s ja kunstis tähistab transformatiivset ajastut, mis ühendab arvutustäpsuse esteetilise uurimisega. Nende teekond kunstimaailmas toob esile märkimisväärse innovatsioonipotentsiaali, kuid sellega kaasneb ka keerukus. Originaalsuse, mõju, eetilise loomingu ja olemasolevate teoste austamise tasakaalustamine on kunstiprotsessi lahutamatu osa.
Võtme tagasivõtmine
- Hajutusmudelid on kunstiloomingu transformatiivse nihke esirinnas. Nad pakuvad uusi digitaalseid tööriistu, mis laiendavad kunstilise väljenduse lõuendit väljaspool traditsioonilisi piire.
- Tehisintellektiga täiustatud kunstis on digitaalse kunsti terviklikkuse säilitamiseks hädavajalik seada esikohale koolitusandmete eetiline kogumine ja austada loojate intellektuaalomandit.
- Kunstilise nägemuse ja tehnoloogilise innovatsiooni lähenemine avab uksed sümbiootilisele suhtele kunstnike ja tehisintellekti arendajate vahel. Edendada koostöökeskkonda, mis võib luua murrangulise kunsti.
- Oluline on tagada, et tehisintellekti loodud kunst esindaks laia valikut vaatenurki. Kaasake mitmesuguseid andmeid, mis kajastavad erinevate kultuuride ja seisukohtade rikkust, edendades seega kaasatust.
- Kasvav huvi tehisintellektiga loodud kunsti vastu nõuab tugeva õigusraamistiku loomist. Need raamistikud peaksid selgitama autoriõigustega seotud küsimusi, tunnustama kaastöid ja reguleerima tehisintellektiga loodud kunstiteoste ärilist kasutamist.
Selle kunstilise evolutsiooni koidik pakub teed, mis on täis loomingulist potentsiaali, kuid nõuab tähelepanelikku eestkostet. Meie kohus on kasvatada maastikku, kus tehisintellekti ja kunsti sulandumine areneb, juhindudes vastutustundlikest ja kultuuritundlikest tavadest.
Korduma kippuvad küsimused
A. Difusioonmudelid on generatiivsed ML-algoritmid, mis loovad kujutisi, alustades juhusliku müra mustrist ja kujundades selle järk-järgult sidusaks pildiks. See protsess sarnaneb kunstnikule, kes alustab tühja lõuendiga ja lisab aeglaselt detailikihte.
V. GAN-id, difusioonimudelid ei vaja väljundi hindamiseks eraldi võrku. Need töötavad, lisades ja eemaldades müra iteratiivselt, mille tulemuseks on sageli üksikasjalikumad ja nüansirikkamad pildid.
V. Jah, difusioonimudelid võivad luua originaalseid kunstiteoseid, õppides piltide andmekogumist. Originaalsust mõjutab aga koolitusandmete mitmekesisus ja ulatus. Käimas on arutelu olemasolevate kunstiteoste kasutamise eetika üle nende mudelite koolitamiseks.
A. Eetilised probleemid hõlmavad tehisintellekti loodud kunsti autoriõiguste rikkumise vältimist. Inimkunstnike originaalsuse austamine, eelarvamuste püsimise vältimine ja tehisintellekti loomeprotsessi läbipaistvuse tagamine.
V. Tehisintellektiga loodud kunsti tulevik tundub paljutõotav, kuna difusioonmudelid pakuvad kunstnikele ja loojatele uusi tööriistu. Võime eeldada, et tehnoloogia arenedes näeme keerukamaid ja keerukamaid kunstiteoseid. Loominguline kogukond peab aga orienteeruma eetilistes kaalutlustes ning töötama selgete juhiste ja parimate tavade suunas.
Selles artiklis näidatud meedia ei kuulu Analytics Vidhyale ja seda kasutatakse autori äranägemisel.
seotud
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://www.analyticsvidhya.com/blog/2023/12/implementing-diffusion-models-for-creative-ai-art-generation/
- :on
- :mitte
- : kus
- 001
- 1
- 10
- 100
- 11
- 12
- 15%
- 150
- 16
- 19
- 224
- 225
- 8
- 9
- a
- võime
- MEIST
- üle
- ABSTRACT
- täpne
- Saavutada
- saavutamisel
- Adam
- adaptiivne
- lisades
- Täiendavad lisad
- aadress
- Kohandatud
- edasijõudnud
- ettemaksed
- Advent
- võistlev
- AI
- ai kunst
- sarnane
- algoritme
- Materjal: BPA ja flataatide vaba plastik
- Lubades
- võimaldab
- an
- Analüütiline
- analytics
- Analüütika Vidhya
- ja
- Kuulutades
- taotlus
- hindama
- lähenemine
- arhitektuur
- OLEME
- Kunst
- artikkel
- kunstnik
- kunstiline
- kunstiliselt
- kunstnikud
- Kunstnikud
- kunstiteoseid
- kunstiteosed
- AS
- At
- suurendatud
- luba
- saadaval
- teed
- vältima
- vältides
- TELGED
- tagasi
- Halb
- tasakaalustamine
- põhineb
- BE
- saada
- Kasu
- BEST
- parimaid tavasid
- vahel
- Peale
- erapoolikus
- kalduvusi
- tühi
- segunemine
- ajaveebi
- sündinud
- mõlemad
- piirid
- hingamine
- tulvil
- Toob
- lai
- tõi kaasa
- kasvav
- kuid
- by
- arvutama
- kutsutud
- CAN
- lõuend
- võimeid
- võime
- lüüa
- väljakutse
- väljakutseid
- kanalid
- Kaos
- iseloomulik
- kontrollima
- kontroll
- klamber
- selgus
- klass
- selge
- selgemaks
- lähemale
- kood
- Kodeerimine
- SIDUS
- Teevad koostööd
- koostööl
- värv
- tuleb
- kaubandus-
- kogukond
- kompaktne
- ühilduvus
- konkurentsivõimeline
- täitma
- lõpetamist
- keeruline
- keerukust
- komponent
- koostis
- arvutuslik
- Arvutama
- mõisted
- kontseptuaalne
- Murettekitav
- kontsert
- järeldab
- Side
- Arvestama
- kaalutlused
- sisaldama
- sisu
- kontrast
- sissemaksed
- tavaline
- Lähenemine
- Konverteerimine
- konverteeriva
- konvolutsioonneuraalvõrk
- autoriõigus
- autoriõiguse rikkumine
- tuum
- korrumpeerunud
- Protsessor
- meisterdatud
- looma
- loomine
- loomine
- Loominguline
- Loominguliselt
- loovus
- loojad
- otsustav
- kulmineerudes
- Kasvatada
- kultuuriliselt
- kureeritud
- kõver
- tava
- tsükkel
- tants
- andmed
- andmekogumid
- arutelu
- sügav
- määratlemisel
- nõudmisi
- Näidatud
- sügavus
- Sügavused
- Tuletatud
- määratud
- detail
- üksikasjalik
- detailid
- Arendajad
- seade
- erinevad
- erinevus
- erinev
- Diffusion
- digitaalne
- digital Art
- digitaalselt
- mõõde
- mõõdud
- äranägemisel
- Ekraan
- väljapanek
- eristatav
- eristamine
- mitu
- mitmekesisus
- do
- ei
- uksed
- juhtida
- Joonistused
- ajal
- dünaamiline
- dünaamiliselt
- dünaamika
- e
- iga
- miss
- kajab
- mõju
- Töötage välja
- teine
- tekib
- kodeeritud
- hõlmab
- haarav
- Inseneriteadus
- tõhustatud
- tagama
- tagab
- tagades
- Kogu
- keskkond
- epohh
- ajajärgud
- Ajastu
- viga
- olemus
- oluline
- asutamine
- Eeter (ETH)
- eetiline
- eetika
- hindamine
- Iga
- evolutsioon
- arenema
- arenenud
- areneb
- läbivaatamine
- Excel
- Välja arvatud
- olemasolevate
- Laiendama
- laiendav
- ootama
- uurimine
- uurima
- väljend
- pikendatud
- ulatuslik
- silm
- silmad
- näo-
- truu
- vale
- tuttav
- lummav
- FUNKTSIOONID
- Lisaks
- truudus
- Joonis
- fail
- Faile
- lõplik
- lõpetama
- esimene
- Keskenduma
- Järel
- eest
- esirinnas
- edasi
- Soodustama
- edendamine
- Raamistik
- raamistikud
- Alates
- täielikult
- funktsioon
- funktsionaalne
- põhiline
- edasi
- fusioon
- tulevik
- kasu
- GANid
- kogumine
- andis
- tekitama
- loodud
- teeniva
- põlvkond
- generatiivne
- generatiivsed võistlusvõrgustikud
- Generatiivne AI
- generaatorid
- Andma
- eesmärk
- GPU
- kalded
- järk-järgult
- suursugusus
- haarake
- suurem
- murranguline
- juhitud
- suunised
- juhendid
- käsi
- Kasutamine
- süda
- siin
- varjama
- rõhutab
- ajalooline
- omamine
- austusavaldus
- au
- Kuidas
- aga
- HTTPS
- inim-
- i
- idee
- if
- süttib
- pilt
- pildid
- kujutlusvõime
- hädavajalik
- rakendamisel
- mõjud
- import
- oluline
- parandama
- in
- hõlmab
- Kaasa arvatud
- Kaasamine
- lisada
- kasvanud
- kasvav
- Ametisolev
- mõju
- mõjutatud
- rikkumine
- leidlikkus
- uuendama
- Innovatsioon
- sisend
- sisendite
- ülevaade
- lahutamatu
- Integreerimine
- terviklikkuse
- intellektuaalne
- intellektuaalomandi
- huvi
- tõlgendus
- sisse
- keerukas
- kehtestama
- intuitsioon
- seotud
- küsimustes
- IT
- iteratsioon
- kordused
- ITS
- teekond
- jpg
- kohtunik
- puudus
- maastik
- kiht
- kihid
- õppinud
- õppimine
- Õigus
- õigusliku raamistiku
- Seadusandlus
- KLAAS
- peitub
- elu
- valgus
- nagu
- laadimine
- välimus
- kaotus
- kaod
- masin
- masinõpe
- säilitada
- imelugu
- meistriteos
- Vastama
- materjal
- matplotlib
- keskmine
- mehhanism
- mehhanismid
- Meedia
- ainult
- ühinevad
- meetod
- metoodiline
- meetriline
- minimeerima
- minut
- peegeldamine
- ML
- ML algoritmid
- viis
- mudel
- mudelid
- Kaasaegne
- moodul
- rohkem
- liikuma
- palju
- MUUSA
- peab
- nimed
- tärkav
- loodus
- Navigate
- vajalik
- vajadustele
- võrk
- võrgustikud
- Neural
- Närvitehnoloogia
- Närvivõrgus
- närvivõrgud
- Uus
- müra
- meeles
- romaan
- nüüd
- varjutamine
- jälgima
- vaadeldud
- of
- maha
- solvav
- pakkuma
- pakkumine
- Pakkumised
- sageli
- on
- jätkuv
- ainult
- Avaneb
- optimeerima
- or
- originaal
- Originaalsus
- Originaalid
- OS
- Muu
- meie
- välja
- väljund
- väljundid
- üle
- omanikuks
- maali
- maalid
- parameeter
- parameetrid
- osa
- isikutele
- sooritama
- minevik
- tee
- Muster
- mustrid
- taju
- täiustamine
- täitma
- perspektiivid
- pilt
- tükk
- tükki
- Platvormid
- Platon
- Platoni andmete intelligentsus
- PlatoData
- portreed
- potentsiaal
- tavad
- Täpsus
- esialgne
- esitada
- kingitusi
- säilitamine
- vältida
- ennetada
- põhimõtted
- trükkimine
- prioriteetsuse
- protsess
- töödeldud
- tootmine
- Toode
- profiil
- sügav
- Edu
- progressioon
- järk-järgult
- paljutõotav
- Edendamine
- küsib
- paljundamine
- korralik
- kinnisvara
- kaitsma
- kaitstud
- päritolu
- pakkudes
- avaldatud
- jätkates
- pütorch
- kvantifitseerib
- juhuslik
- juhuslikkus
- valik
- määr
- valmis
- realm
- tunnistama
- Ümberdefineerimine
- filtreeri
- puhastatud
- peegeldav
- peegeldab
- kord
- regulaarne
- suhe
- eemaldades
- rendering
- replikatsioon
- esindamine
- esindab
- paljunemine
- nõudma
- Vajab
- sarnane
- ümber kujundada
- suhtes
- austades
- vastutav
- vastutustundlikult
- tulemuseks
- tagasipöördumine
- ilmutus
- Taaselustama
- murranguliseks muuta
- RGB
- Rikas
- õigusi
- Tõusma
- jõuline
- Roll
- sama
- salvestatud
- säästmine
- stseen
- teadus
- ulatus
- käsikiri
- vaata
- SELF
- tundlik
- eri
- Jada
- teenib
- komplekt
- kehtestamine
- seade
- mitu
- vari
- vormimine
- suunata
- Vahetused
- peaks
- presentatsioon
- esitlus
- näidatud
- märkimisväärne
- alates
- Aeglaselt
- jupp
- So
- keeruline
- hing
- allikas
- hangitud
- Ruum
- Pinge
- eriti
- spekter
- ruuduline
- stabiilne
- Stage
- seisma
- Käivitus
- statistiline
- stabiilne
- Samm
- Strateegia
- püüdlemine
- struktuur
- Uimastamine
- stiil
- teema
- järgnev
- selline
- Sümbiootiline
- sünergiline
- süntees
- sünteetiline
- kohandatud
- võtab
- võtmine
- sihtmärk
- Tehniline
- tehnikat
- tehnoloogiline
- Tehnoloogiad
- Tehnoloogia
- tensorivool
- testament
- et
- .
- Tulevik
- Allikas
- oma
- Neile
- Seal.
- Need
- nad
- see
- edeneb
- Läbi
- Seega
- et
- töövahendid
- tõrvik
- Torchvision
- puudutama
- suunas
- Jälgimine
- traditsiooniline
- Rong
- koolitatud
- koolitus
- Muutma
- Transformation
- muundumised
- muundav
- ümber
- transformeerivate
- muudab
- läbipaistvus
- tõsi
- püüdma
- mõistma
- mõistmine
- ainulaadne
- kuni
- Avalikustab
- ajakohastamine
- peale
- us
- kasutama
- Kasutatud
- kasutamine
- kasulikkus
- kehtiv
- kontrollimine
- kaudu
- vaatamine
- seisukohti
- nägemus
- visuaalne
- visuaalne kunst
- visualiseerimine
- visualiseeri
- visuaalselt
- tähtis
- oli
- we
- webp
- M
- Mis on
- mis
- kuigi
- Sosin
- WHO
- lai
- Lai valik
- will
- aken
- koos
- jooksul
- ilma
- Töö
- töötab
- maailm
- X
- jah
- veel
- sa
- sephyrnet
- null