
September 20, 2023
Põhimudelid (FM-id) tähistavad uue ajastu algust masinõpe (ML) ja tehisintellekt (AI), mis viib tehisintellekti kiirema arenguni, mida saab kohandada paljude allavoolu ülesannete jaoks ja peenhäälestada mitmesuguste rakenduste jaoks.
Kuna töö tegemisel andmete töötlemise tähtsus kasvab, võimaldab tehisintellekti mudelite teenindamine ettevõtte servas peaaegu reaalajas prognoosida, järgides samal ajal andmete suveräänsuse ja privaatsusnõudeid. Kombineerides IBM watsonx Andme- ja tehisintellekti platvormi võimalused servaarvutusega FM-seadmete jaoks, ettevõtted saavad kasutada tehisintellekti töökoormust FM-i peenhäälestamiseks ja järelduste tegemiseks tööserval. See võimaldab ettevõtetel AI juurutamist äärealadel skaleerida, vähendades kiirema reageerimisajaga juurutamiseks kuluvat aega ja kulusid.
Kontrollige kindlasti kõiki selle ajaveebi postituste sarja osamakseid äärearvutite kohta:
Mis on põhimudelid?
Põhimudelid (FM-id), mida koolitatakse laiaulatuslikult märgistamata andmete põhjal, juhivad tehisintellekti (AI) nüüdisaegseid rakendusi. Neid saab kohandada paljude järgnevate ülesannete jaoks ja peenhäälestada mitmesuguste rakenduste jaoks. Kaasaegsed tehisintellekti mudelid, mis täidavad konkreetseid ülesandeid ühes domeenis, annavad teed FM-idele, kuna nad õpivad üldisemalt ning töötavad üle valdkonna ja probleemide. Nagu nimigi ütleb, võib FM olla paljude AI-mudeli rakenduste aluseks.
FM-id käsitlevad kahte peamist väljakutset, mis on takistanud ettevõtetel tehisintellekti kasutuselevõttu skaleerimast. Esiteks toodavad ettevõtted suurel hulgal märgistamata andmeid, millest vaid murdosa on märgistatud tehisintellekti mudeli koolituseks. Teiseks on see sildistamise ja annoteerimise ülesanne äärmiselt inimmahukas, nõudes sageli mitusada tundi teemaeksperdi (VKE) aega. See muudab kasutusjuhtude ulatuses skaleerimise kulukaks, kuna selleks oleks vaja VKEde ja andmeekspertide armeed. Suure hulga märgistamata andmete neelamise ja mudelikoolituse enesejärelevalve tehnikate kasutamisega on FM-id need kitsaskohad kõrvaldanud ja avanud võimaluse tehisintellekti laialdaseks kasutuselevõtuks kogu ettevõttes. Need tohutud andmemahud, mis on olemas igas ettevõttes, ootavad vallandamist, et saada teadmisi.
Mis on suured keelemudelid?
Suured keelemudelid (LLM) on põhimudelite (FM) klass, mis koosneb kihtidest närvivõrgud keda on koolitatud nende tohutute märgistamata andmete koguste kohta. Nad kasutavad mitmesuguste toimingute tegemiseks iseseisvalt juhendatud õppealgoritme loomuliku keele töötlemine (NLP) ülesandeid viisil, mis on sarnane sellele, kuidas inimesed keelt kasutavad (vt joonis 1).
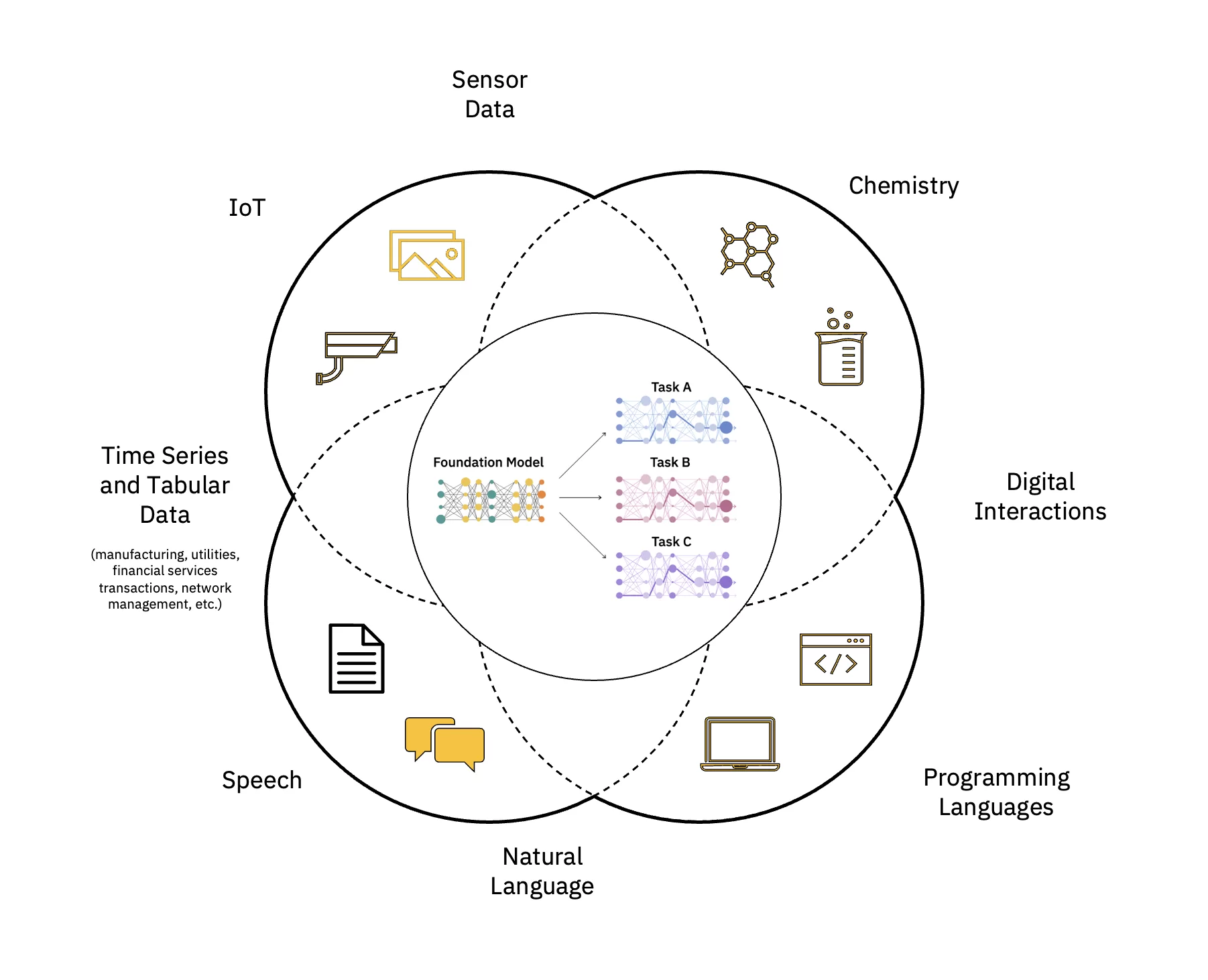
Skaleerige ja kiirendage tehisintellekti mõju
Põhimudeli (FM) loomiseks ja juurutamiseks on mitu sammu. Need hõlmavad andmete sissevõtmist, andmete valimist, andmete eeltöötlust, FM-i eelkoolitust, mudeli häälestamist ühe või mitme allavoolu ülesande jaoks, järelduste esitamist ning andmete ja tehisintellekti mudeli juhtimist ja elutsükli haldamist – kõike seda võib kirjeldada kui FMOps.
Selle kõige vastu abistamiseks pakub IBM ettevõtetele vajalikke tööriistu ja võimalusi nende FM-ide võimsuse kasutamiseks. IBM watsonx, ettevõtte jaoks valmis tehisintellekti- ja andmeplatvorm, mis on loodud tehisintellekti mõju mitmekordistamiseks kogu ettevõttes. IBM watsonx koosneb järgmistest osadest:
- IBM watsonx.ai toob uut generatiivne AI FM-i ja traditsioonilise masinõppe (ML) jõul töötavad võimsad stuudiod, mis hõlmavad AI elutsüklit.
- IBM watsonx.data on otstarbekohane andmesalv, mis on ehitatud avatud järvehoone arhitektuurile, et kohandada tehisintellekti töökoormust kõigi teie andmete jaoks kõikjal.
- IBM watsonx.governance on täielik automatiseeritud tehisintellekti elutsükli juhtimise tööriistakomplekt, mis on loodud vastutustundlike, läbipaistvate ja seletatavate tehisintellekti töövoogude võimaldamiseks.
Teine oluline tegur on andmetöötluse kasvav tähtsus ettevõtte servas, näiteks tööstuskohtades, tootmiskorrustes, jaemüügikauplustes, telco servades jne. Täpsemalt võimaldab tehisintellekt ettevõtte servas töödelda andmeid seal, kus tehakse tööd. peaaegu reaalajas analüüs. Ettevõtte eelis on see, kus genereeritakse tohutul hulgal ettevõtte andmeid ja kus tehisintellekt võib pakkuda väärtuslikku, õigeaegset ja teostatavat äriteavet.
AI-mudelite serveerimine võimaldab peaaegu reaalajas prognoosida, järgides samal ajal andmete suveräänsuse ja privaatsusnõudeid. See vähendab oluliselt kontrolliandmete hankimise, edastamise, teisendamise ja töötlemisega sageli seotud latentsust. Äärepealne töötamine võimaldab meil kaitsta tundlikke ettevõtteandmeid ja vähendada andmeedastuskulusid kiirema reageerimisajaga.
Tehisintellekti juurutuste skaleerimine äärealadel ei ole andmete (heterogeensus, maht ja regulatiivne) ja piiratud ressursside (arvutus, võrguühenduvus, salvestus- ja isegi IT-oskused) tõttu lihtne ülesanne. Neid võib laias laastus kirjeldada kahes kategoorias:
- Aeg/kulu juurutamiseks: Iga juurutamine koosneb mitmest riist- ja tarkvara kihist, mis tuleb enne juurutamist installida, konfigureerida ja testida. Tänapäeval võib hooldusspetsialistil paigaldamiseks kuluda kuni nädal või kaks igas kohas, piirab oluliselt seda, kui kiiresti ja kulutõhusalt saavad ettevõtted oma organisatsioonis kasutuselevõttu laiendada.
- 2. päeva juhtimine: Kasutusele võetud servade suur arv ja iga juurutuse geograafiline asukoht võivad sageli muuta igas asukohas kohaliku IT-toe pakkumise nende juurutuste jälgimiseks, hooldamiseks ja värskendamiseks ülemäära kulukaks.
Edge AI juurutamine
IBM töötas välja servaarhitektuuri, mis lahendab need väljakutsed, tuues integreeritud riistvara/tarkvara (HW/SW) seadme mudeli AI-juurutustesse. See koosneb mitmest võtmeparadigmast, mis aitavad AI juurutamise skaleeritavust:
- Poliitikapõhine kogu tarkvarapakki null-puutevaba varustamine.
- Servasüsteemi tervise pidev jälgimine
- Võimalus hallata ja edastada tarkvara/turbe/konfiguratsiooni värskendusi paljudesse servakohtadesse – kõike seda kesksest pilvepõhisest asukohast teise päeva haldamiseks.
Jaotatud jaoturi- ja kodaraarhitektuuri saab kasutada ettevõtte tehisintellekti juurutuste skaleerimiseks äärel, kus keskne pilve- või ettevõtte andmekeskus toimib jaoturina ja serv-in-a-box seade toimib servas kodarana.. See rummu- ja kodaramudel, mis ulatub üle hübriidpilve- ja servakeskkondade, illustreerib kõige paremini tasakaalu, mis on vajalik FM-toiminguteks vajalike ressursside optimaalseks kasutamiseks (vt joonis 2).
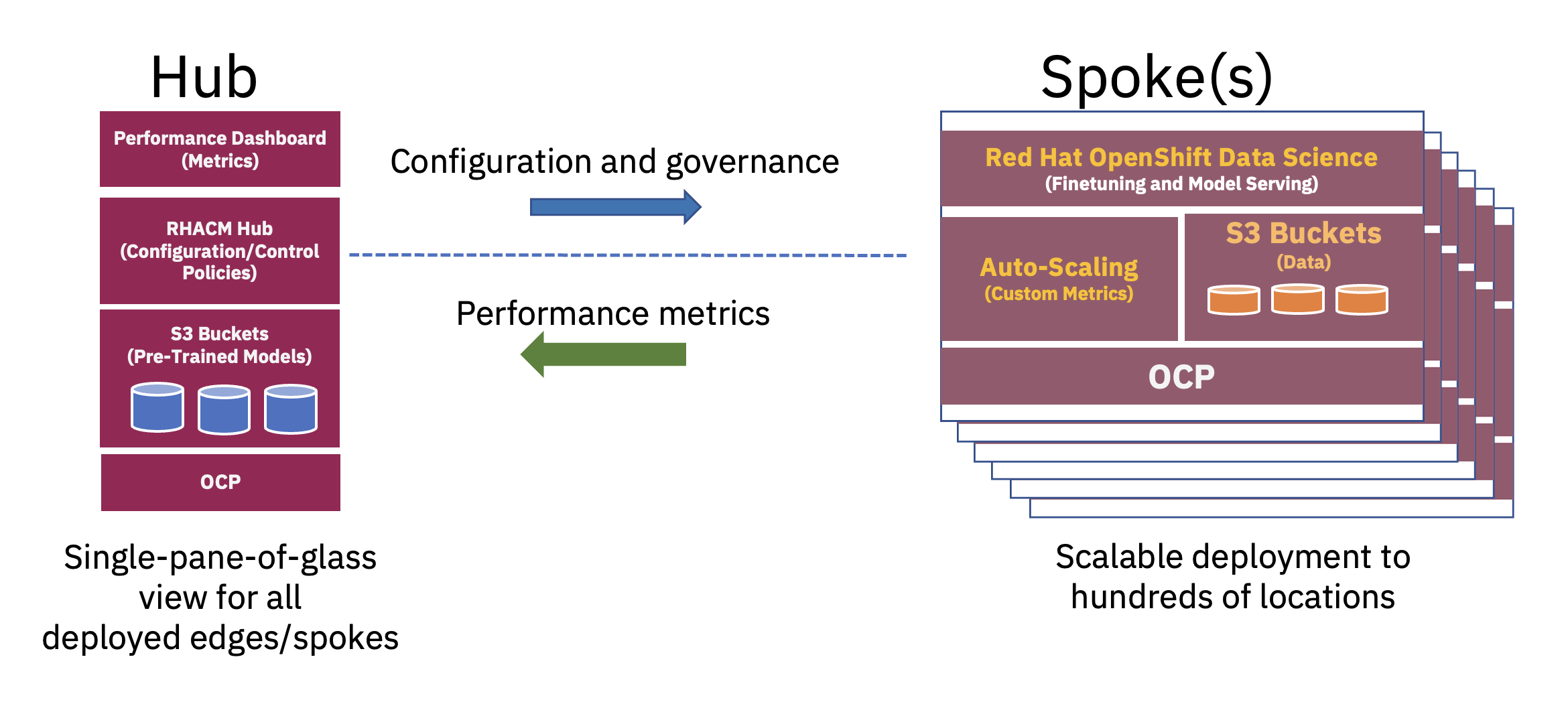
Nende suurte põhikeelemudelite (LLM) ja muud tüüpi alusmudelite eelkoolitus, mis kasutab enesejärelevalve tehnikaid suurtes märgistamata andmekogumites, nõuab sageli märkimisväärseid arvutusressursse (GPU) ja seda on kõige parem teostada keskuses. Peaaegu piiramatud arvutusressursid ja sageli pilves talletatavad suured andmekuhjad võimaldavad suurte parameetrite mudelite eelkoolitamist ja nende baasmudelite täpsuse pidevat parandamist.
Teisest küljest saab nende põhi-FM-ide häälestada allavoolu ülesannete jaoks – mis nõuavad vaid mõnda kümneid või sadu märgistatud andmenäidiseid ja järelduste esitamist – ainult mõne ettevõtte servas asuva GPU-ga. See võimaldab tundlikel märgistatud andmetel (või ettevõtte kroonijuveeli andmetel) ettevõtte töökeskkonnas turvaliselt püsida, vähendades samal ajal andmeedastuskulusid.
Kasutades täielikku lähenemist rakenduste juurutamiseks äärealadel, saab andmeteadlane mudeleid peenhäälestada, testida ja juurutada. Seda on võimalik saavutada ühes keskkonnas, vähendades samal ajal uute tehisintellekti mudelite lõppkasutajatele pakkumise arendustsüklit. Platvormid nagu Red Hat OpenShift Data Science (RHODS) ja hiljuti välja kuulutatud Red Hat OpenShift AI pakuvad tööriistu tootmisvalmis tehisintellekti mudelite kiireks arendamiseks ja juurutamiseks. hajutatud pilv ja äärekeskkonnad.
Lõpuks vähendab peenhäälestatud tehisintellekti mudeli teenindamine ettevõtte servas oluliselt andmete hankimise, edastamise, teisendamise ja töötlemisega sageli seotud latentsust. Pilves toimuva eelkoolituse lahtisidumine peenhäälestusest ja äärepealt järelduste tegemisest alandab üldisi tegevuskulusid, vähendades mis tahes järeldustoiminguga seotud aega ja andmete liikumise kulusid (vt joonis 3).
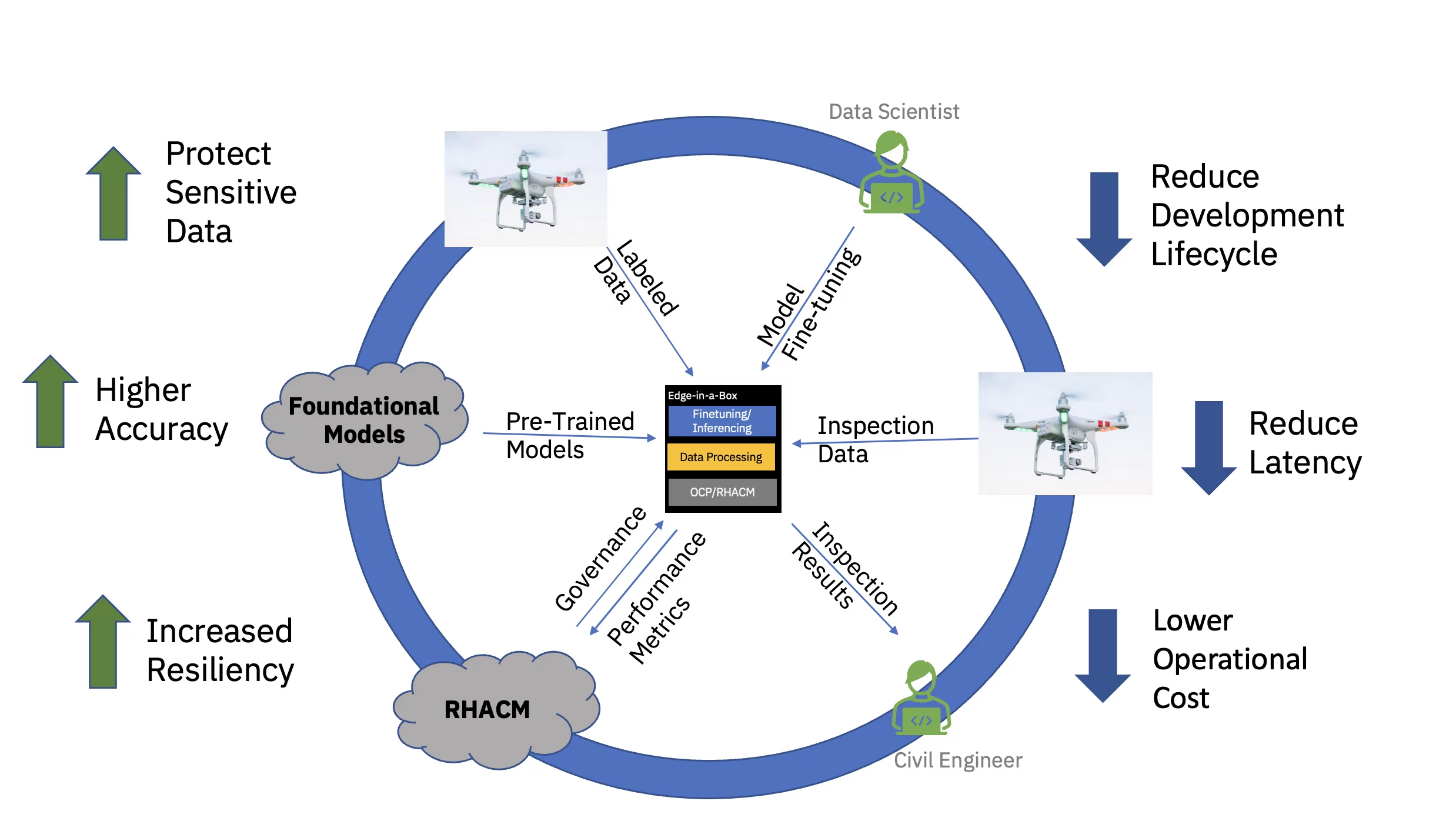
Selle väärtuspakkumise täielikuks demonstreerimiseks viimistleti tsiviilinfrastruktuuri näidisnägemus-trafol põhinev alusmudel (eelkoolitatud, kasutades avalikke ja kohandatud tööstusharuspetsiifilisi andmekogumeid) ja kasutati järelduste tegemiseks kolme sõlme serval. (kodara) kobar. Tarkvarapakk sisaldas Red Hat OpenShift Container Platformi ja Red Hat OpenShift Data Science'i. See servaklaster oli ühendatud ka Red Hat Advanced Cluster Management for Kubernetes (RHACM) jaoturiga, mis töötab pilves.
Nullpuutevarustamine
Poliitikapõhine null-touch etteandmine viidi läbi Red Hat Advanced Cluster Management for Kubernetes (RHACM) abil poliitikate ja paigutusmärgendite kaudu, mis seovad konkreetsed servaklastrid tarkvarakomponentide ja konfiguratsioonide komplektiga. Need tarkvarakomponendid, mis ulatuvad üle kogu virna ja katavad arvutusi, salvestust, võrku ja tehisintellekti töökoormust, installiti erinevate OpenShift-operaatorite, vajalike rakendusteenuste ja S3 ämbri (salvestusruumi) abil.
Tsiviilinfrastruktuuri eelkoolitatud alusmudel (FM) viidi läbi Red Hat OpenShift Data Science'i (RHODS) Jupyteri sülearvuti abil, kasutades märgistatud andmeid, et klassifitseerida kuut tüüpi betoonsildadel leitud defekte. Selle peenhäälestatud FM-i järelduste edastamist demonstreeriti ka Tritoni serveriga. Lisaks sai selle servasüsteemi seisundi jälgimise võimalikuks, koondades vaadeldavuse mõõdikud riist- ja tarkvarakomponentidest Prometheuse kaudu pilves asuvasse RHACM-i kesksele armatuurlauale. Tsiviilinfrastruktuuri ettevõtted saavad neid FM-e juurutada oma servades ja kasutada droonipilte, et tuvastada peaaegu reaalajas defekte, kiirendades ülevaate saamiseks kuluvat aega ja vähendades suure hulga kõrglahutusega andmete pilve ja sealt teisaldamise kulusid.
kokkuvõte
Kombineerimine IBM watsonx Andme- ja tehisintellekti platvormi võimalused alusmudelite (FM) jaoks koos serv-in-a-box seadmega võimaldavad ettevõtetel käitada tehisintellekti töökoormust FM-i peenhäälestamiseks ja järelduste tegemiseks tööserval. See seade saab hakkama keerukate kasutusjuhtudega ja loob tsentraliseeritud halduse, automatiseerimise ja iseteeninduse jaoturi ja kodaraga raamistiku. Edge FM-i juurutamist saab vähendada nädalatelt tundideni, saavutades korduva edu, suurema vastupidavuse ja turvalisuse.
Kontrollige kindlasti kõiki selle ajaveebi postituste sarja osamakseid äärearvutite kohta:
Rohkem Cloudist




- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://www.ibm.com/blog/foundational-models-at-the-edge/
- :on
- :on
- :mitte
- : kus
- $ UP
- 08
- 1
- 10
- 13
- 15%
- 20
- 2023
- 22
- 28
- 29
- 30
- 300
- 39
- 400
- 41
- 7
- 70
- 9
- a
- MEIST
- kiirendama
- juurdepääs
- saavutatud
- täpsus
- omandamine
- üle
- õigusaktid
- kohandatud
- Lisaks
- aadress
- aadressid
- Vastuvõtmine
- edasijõudnud
- edusammud
- reklaam
- AI
- AI lapsendamine
- AI mudelid
- AI platvorm
- Abi
- algoritme
- Materjal: BPA ja flataatide vaba plastik
- võimaldama
- võimaldab
- Ka
- Keset
- summa
- summad
- amp
- an
- analüüs
- analytics
- ja
- teatas
- mistahes
- kuskil
- taotlus
- rakendused
- lähenemine
- arhitektuur
- OLEME
- Array
- artikkel
- kunstlik
- tehisintellekti
- Tehisintellekt (AI)
- AS
- seotud
- At
- autor
- Automatiseeritud
- Automaatika
- saadaval
- Puiestee
- tagasi
- Saldo
- Pank
- Pangad
- baas
- BE
- sest
- muutuma
- saada
- olnud
- Algus
- on
- Uskuma
- BEST
- siduda
- Blogi
- Blogi postitused
- blogid
- mõlemad
- Kast
- sillad
- Toomine
- Toob
- lai
- üldjoontes
- Ehitus
- Ehitab
- ehitatud
- äri
- by
- CAN
- võimeid
- kapital
- Püüdmine
- süsinik
- kaart
- Kaardid
- juhtudel
- CAT
- kategooriad
- Põhjus
- keskus
- kesk-
- Keskpank
- keskpanga digitaalsed valuutad
- tsentraliseeritud
- kett
- väljakutseid
- muutma
- muutuv
- kontrollima
- valikuid
- ringid
- SRÜ
- tsiviil-
- klass
- Klassifitseerige
- selge
- kliendid
- lähedalt
- Cloud
- Cluster
- värv
- värvikas
- kombineerimine
- konkurentsivõimeline
- keeruline
- keerukus
- Vastavus
- komponendid
- Arvutama
- arvutustehnika
- konfiguratsioon
- konfigureeritud
- seotud
- Side
- koosneb
- Konteiner
- jätkama
- kontrollida
- Maksma
- kulud
- võiks
- kattes
- cryptocurrency
- CSS
- valuutade
- tava
- klient
- Kliendi kogemus
- Kliendid
- armatuurlaud
- andmed
- Andmekeskus
- Andmeplatvorm
- andmeteadus
- andmeteadlane
- andmekogumid
- kuupäev
- pühendunud
- vaikimisi
- mõisted
- tarnima
- näitama
- Näidatud
- juurutada
- lähetatud
- juurutamine
- kasutuselevõtu
- kasutuselevõtt
- kirjeldatud
- kirjeldus
- kavandatud
- arendama
- arenenud
- & Tarkvaraarendus
- digitaalne
- digitaalsed valuutad
- digiteerimine
- Katkestus
- segav
- Häirijad
- jagatud
- piirkond
- domeen
- Domeenid
- tehtud
- ajam
- sõidu
- undamine
- iga
- lihtne
- ökosüsteemi
- serv
- servaarvutus
- ELEVATE
- kõrgendatud
- võimaldama
- võimaldab
- lõpp
- Lõpuks-lõpuni
- insener
- Inseneriteadus
- sisene
- ettevõte
- ettevõtete
- sissetulev
- keskkond
- keskkondades
- Ajastu
- eriti
- jms
- Eeter (ETH)
- Isegi
- sündmused
- Iga
- arenenud
- Uurimine
- näited
- täitma
- eksisteerima
- Väljapääs
- kallis
- kogemus
- ekspertide
- Seletatav tehisintellekt
- selgitades
- laiendades
- äärmiselt
- tegurid
- KIIRE
- kiiremini
- vähe
- väli
- Joonis
- finants-
- Finants institutsioonid
- finantseerimine
- esimene
- põrandad
- järgima
- Järel
- fonte
- eest
- esirinnas
- avastatud
- Sihtasutus
- murdosa
- Raamistik
- Alates
- täis
- Täis virna
- Pealegi
- üldiselt
- loodud
- generaator
- geograafiline
- Geopoliitika
- andmine
- Globaalne
- maailmakaubanduse
- valitsemistava
- GPU
- GPU
- võre
- käsi
- käepide
- riistvara
- müts
- Olema
- Tervis
- kõrgus
- aitama
- aidates
- aitab
- kõrglahutus
- rohkem
- kõrgelt
- ajalugu
- võõrustaja
- Lahtiolekuajad
- Kuidas
- Kuidas
- aga
- HTTPS
- Keskus
- Inimestel
- sajad
- hübriid
- Hübriidne pilv
- IBM
- IBM Cloud
- ICO
- ICON
- illustreerib
- pilt
- mõju
- tähtsus
- paranemine
- in
- sisaldama
- lisatud
- kasvav
- üha rohkem
- indeks
- tööstus-
- tööstusharudes
- tööstus
- tööstusharuspetsiifiline
- inflatsioon
- Inflekt
- Pöördepunkt
- mõjutatud
- Infrastruktuur
- algatus
- Innovatsioon
- uuenduslik
- sisendite
- teadmisi
- Näiteks
- institutsioonid
- integreeritud
- Intelligentsus
- sisemine
- sisse
- IT
- IT-tugi
- Reisid
- jpg
- hüppama
- Jupyteri sülearvuti
- lihtsalt
- ainult üks
- hoitakse
- Võti
- Kubernetes
- märgistamine
- keel
- suur
- suurelt jaolt
- Hilinemine
- hiljemalt
- kihid
- juhtivate
- Õppida
- õppimine
- Finantsvõimendus
- eluring
- nagu
- piiramatu
- Linux
- kohalik
- locale
- liising
- kohad
- Pikk
- Vaata
- masin
- masinõpe
- tehtud
- säilitada
- tegema
- TEEB
- juhtima
- juhtimine
- tootmine
- palju
- märgistus
- suur
- meister
- küsimus
- max laiuse
- mehhanismid
- meetodid
- Meetrika
- minutit
- minimeerimine
- protokoll
- ML
- mobiilne
- mudel
- mudelid
- Kaasaegne
- moderniseerimine
- kaasajastama
- Jälgida
- järelevalve
- rohkem
- liikumine
- liikuv
- nimi
- NAVIGATSIOON
- Lähedal
- vajalik
- Vajadus
- vaja
- vajadustele
- võrk
- Uus
- järgmine
- nlp
- märkmik
- mitte midagi
- nüüd
- number
- arvukad
- of
- pakkumine
- sageli
- on
- ONE
- ainult
- avatud
- avatud
- töökorras
- Operations
- ettevõtjad
- optimeeritud
- or
- organisatsioon
- Muu
- meie
- välja
- üldine
- pakette
- lehekülg
- parameeter
- makse
- makseviisid
- maksed
- täitma
- teostatud
- PHP
- paigutus
- inimesele
- Platvormid
- Platon
- Platoni andmete intelligentsus
- PlatoData
- plugin
- Punkt
- Poliitika
- poliitika
- positsioon
- võimalik
- post
- Postitusi
- potentsiaal
- võim
- võimas
- Ennustused
- Eelnev
- privaatsus
- era-
- probleeme
- töötlemine
- tootma
- professionaalne
- ettepanek
- anda
- avalik
- Lükkama
- valik
- kiiresti
- Lugemine
- reaalajas
- hiljuti
- rekord
- salvestamine
- Red
- Red Hat
- vähendama
- Lühendatud
- vähendab
- vähendamine
- määrused
- Regulaatorid
- regulatiivne
- seotud
- Eemaldatud
- korratav
- nõudma
- nõutav
- Nõuded
- vajalik
- teadustöö
- Vahendid
- vastus
- vastutav
- tundlik
- jaemüük
- Tõusma
- robotid
- jooks
- jooksmine
- ohutult
- sama
- Skaalautuvus
- Skaala
- skaala ai
- ketendamine
- teadus
- teadlane
- Ekraan
- skripte
- Teine
- kindlalt
- turvalisus
- vaata
- nägemine
- valik
- Iseteenindus
- tundlik
- seo
- September
- Seeria
- server
- teenus
- Teenused
- teenindavad
- istung
- istungid
- komplekt
- mitu
- Jaga
- näitama
- märkimisväärne
- märgatavalt
- sarnane
- alates
- Singapur
- ühekordne
- ühtne keskkond
- site
- Saidid
- SIX
- oskused
- väike
- EMS
- VKEde
- tarkvara
- tarkvara komponendid
- lahendus
- suveräänsus
- Ruum
- Pinge
- konkreetse
- eriti
- Sponsorite
- Kestab
- algus
- modernne
- jääma
- Sammud
- ladustamine
- salvestada
- ladustatud
- kauplustes
- torm
- stuudio
- teema
- edu
- selline
- Soovitab
- varustama
- tarneahelas
- toetama
- kindel
- süsteem
- Võtma
- võtnud
- Ülesanne
- ülesanded
- tehnikat
- Tehnoloogia
- Telco
- Temenos
- kümneid
- Terraform
- katsetatud
- Testimine
- et
- .
- oma
- teema
- Seal.
- Need
- nad
- see
- Läbi
- aeg
- õigeaegne
- korda
- Kapslid
- et
- täna
- kokku
- Käsiraamat
- töövahendid
- ülemine
- kaubelda
- traditsiooniline
- Rong
- koolitatud
- koolitus
- üle
- Muutma
- Transformation
- muundumised
- läbipaistev
- Lõitkodalane
- puperdama
- kaks
- tüüp
- liigid
- lahti lastud
- Värskendused
- Uudised
- URL
- us
- kasutama
- Kasutatud
- Kasutajad
- kasutamine
- ära kasutama
- kasutatud
- väärtuslik
- väärtus
- väärtusepakkumine
- sort
- eri
- suur
- kaudu
- vaade
- praktiliselt
- maht
- mahud
- W
- ootamine
- rahakott
- oli
- Wave
- Tee..
- kuidas
- we
- nädal
- nädalat
- M
- Mis on
- millal
- mis
- kuigi
- WHO
- miks
- lai
- Lai valik
- koos
- jooksul
- naine
- WordPress
- Töö
- Töövoogud
- töö
- oleks
- kirjalik
- Sinu
- sephyrnet











