Täna on meil hea meel teatada, et Llama 2 järelduste ja peenhäälestuse tugi on saadaval AWS Trainium ja AWS Inferentia juhtumid sisse Amazon SageMaker JumpStart. AWS Trainiumil ja Inferential põhinevate eksemplaride kasutamine SageMakeri kaudu võib aidata kasutajatel vähendada peenhäälestuskulusid kuni 50% ja juurutuskulusid 4.7 korda, vähendades samal ajal loa latentsust. Llama 2 on automaatselt regressiivne generatiivse tekstikeele mudel, mis kasutab optimeeritud trafo arhitektuuri. Avalikult kättesaadava mudelina on Llama 2 loodud paljude NLP-ülesannete jaoks, nagu teksti klassifitseerimine, sentimentide analüüs, keele tõlkimine, keele modelleerimine, teksti genereerimine ja dialoogisüsteemid. LLM-ide, nagu Llama 2, peenhäälestus ja juurutamine võib muutuda kulukaks või keeruliseks, et tagada reaalajas jõudlus, et pakkuda head kliendikogemust. Trainium ja AWS Inferentia, mida võimaldavad AWS Neuron tarkvaraarenduskomplekt (SDK), pakub suure jõudlusega ja kulutõhusat võimalust Llama 2 mudelite treenimiseks ja järelduste tegemiseks.
Selles postituses näitame, kuidas Llama 2 juurutada ja viimistleda SageMaker JumpStartis Trainiumi ja AWS Inferentia eksemplaridel.
Lahenduse ülevaade
Selles ajaveebis käsitleme järgmisi stsenaariume.
- Juurutage Llama 2 AWS Inferentia eksemplaridel mõlemas Amazon SageMaker Studio UI, ühe klõpsuga juurutuskogemus ja SageMaker Python SDK.
- Täpsustage Llama 2 Trainiumi eksemplaridel nii SageMaker Studio kasutajaliideses kui ka SageMaker Python SDK-s.
- Võrrelge peenhäälestatud mudeli Llama 2 jõudlust eelkoolitatud mudeli omaga, et näidata peenhäälestuse tõhusust.
Kätte saamiseks vaadake GitHubi näidismärkmik.
Llama 2 juurutamine AWS Inferentia eksemplaridel, kasutades SageMaker Studio kasutajaliidest ja Pythoni SDK-d
Selles jaotises demonstreerime, kuidas juurutada Llama 2 AWS Inferentia eksemplaridel, kasutades SageMaker Studio kasutajaliidest ühe klõpsuga juurutamiseks ja Pythoni SDK-d.
Avastage Llama 2 mudel SageMaker Studio kasutajaliideses
SageMaker JumpStart pakub juurdepääsu nii avalikult kättesaadavatele kui ka varalistele andmetele vundamendi mudelid. Sihtasutuse mudelid on sisse ehitatud ja neid hooldavad kolmandad osapooled ja patenteeritud pakkujad. Sellisena avaldatakse need mudeliallika määratud erinevate litsentside alusel. Vaadake kindlasti üle kõigi kasutatavate alusmudelite litsents. Vastutate kohaldatavate litsentsitingimuste ülevaatamise ja järgimise eest ning veenduge, et need on teie kasutusjuhtumi jaoks vastuvõetavad enne sisu allalaadimist või kasutamist.
Llama 2 vundamendimudelitele pääsete juurde SageMakeri JumpStarti kaudu SageMaker Studio kasutajaliideses ja SageMaker Python SDK-s. Selles jaotises käsitleme SageMaker Studio mudelite leidmist.
SageMaker Studio on integreeritud arenduskeskkond (IDE), mis pakub ühtset veebipõhist visuaalset liidest, kus pääsete juurde spetsiaalselt loodud tööriistadele, et sooritada kõiki masinõppe (ML) arendusetappe, alates andmete ettevalmistamisest kuni ML-i loomise, koolitamise ja juurutamiseni. mudelid. Lisateavet SageMaker Studio alustamise ja seadistamise kohta leiate aadressilt Amazon SageMaker Studio.
Kui olete SageMaker Studios, pääsete jaotises SageMaker JumpStart juurde, mis sisaldab eelkoolitatud mudeleid, märkmikke ja eelehitatud lahendusi. Eelehitatud ja automatiseeritud lahendused. Üksikasjalikuma teabe saamiseks patenteeritud mudelitele juurdepääsu kohta vt Kasutage Amazon SageMaker Studios Amazon SageMaker JumpStarti patenteeritud vundamendimudeleid.
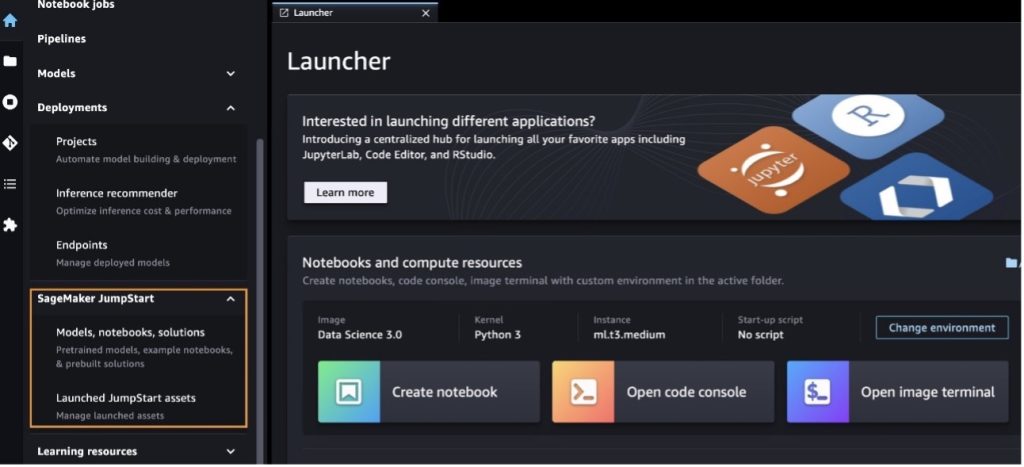
SageMaker JumpStarti sihtlehel saate sirvida lahendusi, mudeleid, märkmikke ja muid ressursse.
Kui te Llama 2 mudeleid ei näe, värskendage oma SageMaker Studio versiooni, lülitades välja ja taaskäivitades. Versioonivärskenduste kohta lisateabe saamiseks vaadake Lülitage Studio klassikalised rakendused välja ja värskendage neid.

Valides leiate ka teisi mudelivariante Tutvuge kõigi teksti genereerimise mudelitega või otsivad llama or neuron otsingukastis. Sellel lehel saate vaadata Llama 2 Neuron mudeleid.
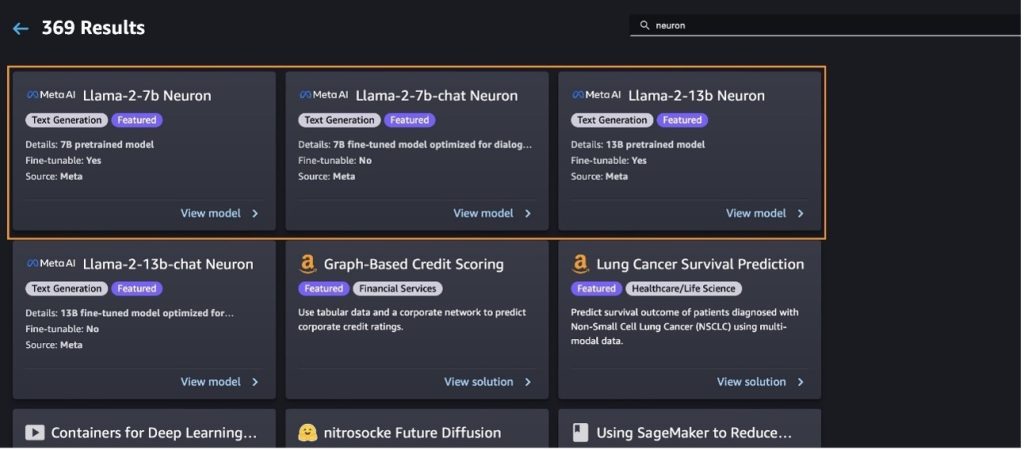
Rakendage mudelit Llama-2-13b SageMaker Kiirstardi abil
Saate valida mudelikaardi, et vaadata mudeli üksikasju, nagu litsents, koolituseks kasutatud andmed ja selle kasutamine. Samuti võite leida kaks nuppu, juurutada ja Ava märkmik, mis aitavad teil seda koodivaba näidet kasutades mudelit kasutada.
Kui valite kummagi nupu, kuvatakse hüpikaknas lõppkasutaja litsentsileping ja vastuvõetava kasutuse poliitika (AUP), mida peate kinnitama.
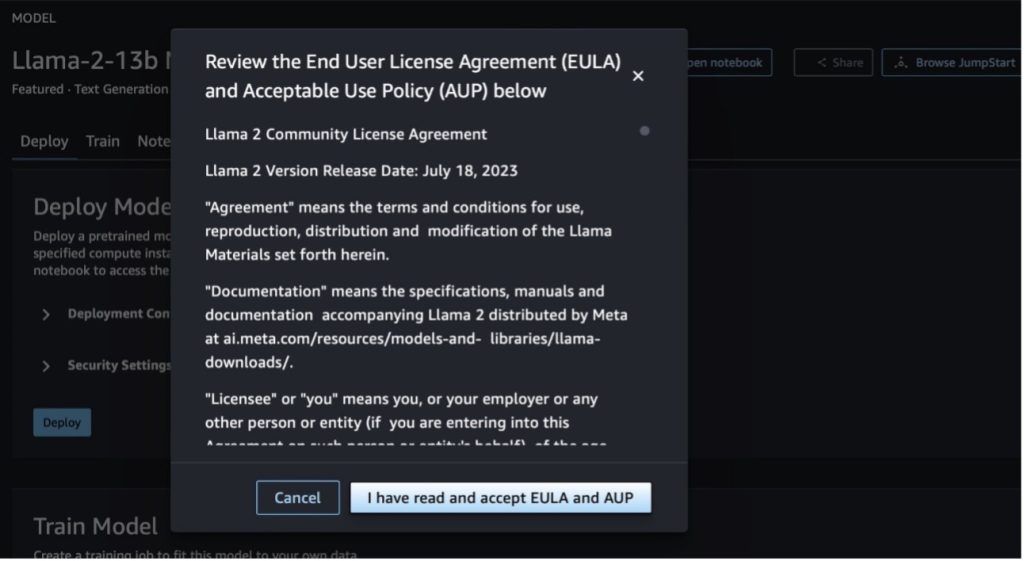
Pärast poliitikate kinnitamist saate juurutada mudeli lõpp-punkti ja kasutada seda järgmises jaotises toodud juhiste järgi.
Juurutage Llama 2 Neuron mudel Pythoni SDK kaudu
Kui valite juurutada ja tunnistage tingimused, algab mudeli juurutamine. Teise võimalusena saate juurutada näidismärkmiku kaudu, valides Ava märkmik. Näidismärkmik pakub täielikke juhiseid selle kohta, kuidas mudelit järelduste tegemiseks ja ressursside puhastamiseks kasutada.
Mudeli juurutamiseks või viimistlemiseks Trainiumi või AWS Inferentia eksemplaridel peate esmalt kutsuma PyTorch Neuron (tõrvik-neuronx), et koostada mudel Neuron-spetsiifiliseks graafikuks, mis optimeerib selle Inferentia NeuronCoresi jaoks. Kasutajad saavad anda kompilaatorile käsu optimeerida väikseima latentsusaja või suurima läbilaskevõime jaoks, olenevalt rakenduse eesmärkidest. KiirStartis koostasime Neuroni graafikud erinevate konfiguratsioonide jaoks, et kasutajad saaksid kompileerimise etappe lonksata, võimaldades mudelite kiiremat peenhäälestamist ja juurutamist.
Pange tähele, et Neuroni eelkompileeritud graafik luuakse Neuron Compileri versiooni konkreetse versiooni alusel.
LIama 2 juurutamiseks AWS Inferentia-põhistel eksemplaridel on kaks võimalust. Esimene meetod kasutab eelehitatud konfiguratsiooni ja võimaldab teil mudelit juurutada vaid kahe koodireaga. Teises on teil suurem kontroll konfiguratsiooni üle. Alustame esimesest meetodist, eelseadistatud konfiguratsioonist, ja kasutame näitena eelkoolitatud Llama 2 13B Neuron mudelit. Järgmine kood näitab, kuidas Llama 13B juurutada vaid kahe reaga:
Nende mudelite põhjal järelduste tegemiseks peate määrama argumendi accept_eula olla True osana model.deploy() helistama. Selle argumendi õigeks määramine kinnitab, et olete mudeli EULA-ga tutvunud ja sellega nõustunud. EULA leiate mudelikaardi kirjeldusest või aadressilt Meta veebisait.
Llama 2 13B vaikeeksemplari tüüp on ml.inf2.8xlarge. Võite proovida ka teisi toetatud mudelite ID-sid:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(vestlusmudel)meta-textgenerationneuron-llama-2-13b-f(vestlusmudel)
Teise võimalusena, kui soovite juurutuskonfiguratsioone, nagu konteksti pikkus, tensori paralleelaste ja maksimaalne jooksva partii suurus, rohkem juhtida, saate neid keskkonnamuutujate kaudu muuta, nagu on näidatud selles jaotises. Juurutamise aluseks olev süvaõppekonteiner (DLC) on Large Model Inference (LMI) NeuronX DLC. Keskkonnamuutujad on järgmised:
- OPTION_N_POSITIONS – Sisend- ja väljundmärkide maksimaalne arv. Näiteks kui koostate mudeli koos
OPTION_N_POSITIONSkui 512, siis saate kasutada sisendmärki 128 (sisendviipa suurus) maksimaalse väljundmärgiga 384 (sisend- ja väljundmärke peab kokku olema 512). Maksimaalse väljundmärgi puhul sobivad kõik väärtused alla 384, kuid te ei saa sellest kaugemale minna (näiteks sisend 256 ja väljund 512). - OPTION_TENSOR_PARALLEL_DEGREE – NeuronCore’ide arv mudeli laadimiseks AWS Inferentia eksemplarides.
- OPTION_MAX_ROLLING_BATCH_SIZE – Samaaegsete päringute maksimaalne partii suurus.
- OPTION_DTYPE – mudeli laadimise kuupäeva tüüp.
Neuron graafi koostamine sõltub konteksti pikkusest (OPTION_N_POSITIONS), tensori paralleelaste (OPTION_TENSOR_PARALLEL_DEGREE), maksimaalne partii suurus (OPTION_MAX_ROLLING_BATCH_SIZE) ja andmetüüp (OPTION_DTYPE) mudeli laadimiseks. SageMaker JumpStart on eelkompileerinud Neuroni graafikud mitmesuguste eelmiste parameetrite konfiguratsioonide jaoks, et vältida käitusaja kompileerimist. Eelkoostatud graafikute konfiguratsioonid on loetletud järgmises tabelis. Kuni keskkonnamuutujad kuuluvad ühte järgmistest kategooriatest, jäetakse neuronigraafikute koostamine vahele.
| LIama-2 7B ja LIama-2 7B Vestlus | ||||
| Eksemplari tüüp | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| LIama-2 13B ja LIama-2 13B Vestlus | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
Järgmine on näide Llama 2 13B juurutamise ja kõigi saadaolevate konfiguratsioonide seadistamise kohta.
Nüüd, kui oleme mudeli Llama-2-13b juurutanud, saame sellega järeldusi teha, kutsudes esile lõpp-punkti. Järgmine koodilõik demonstreerib toetatud järeldusparameetrite kasutamist teksti genereerimise juhtimiseks.
- max_pikkus – Mudel genereerib teksti, kuni väljundi pikkus (mis sisaldab sisendkonteksti pikkust) jõuab
max_length. Kui see on määratud, peab see olema positiivne täisarv. - max_uued_märgid – Mudel genereerib teksti, kuni väljundi pikkus (välja arvatud sisendkonteksti pikkus) jõuab
max_new_tokens. Kui see on määratud, peab see olema positiivne täisarv. - kiirte_arv – See näitab ahnes otsingus kasutatud kiirte arvu. Kui see on määratud, peab see olema täisarv, mis on suurem või võrdne sellega
num_return_sequences. - no_repeat_ngram_size – Mudel tagab, et sõnade jada
no_repeat_ngram_sizeväljundjärjestuses ei korrata. Kui see on määratud, peab see olema positiivne täisarv, mis on suurem kui 1. - temperatuur – See juhib väljundi juhuslikkust. Kõrgem temperatuur annab tulemuseks väikese tõenäosusega sõnadega väljundjada; madalam temperatuur annab tulemuseks suure tõenäosusega sõnadega väljundjada. Kui
temperaturevõrdub 0-ga, tulemuseks on ahne dekodeerimine. Kui see on määratud, peab see olema positiivne ujuk. - varajane_peatus - Kui
True, teksti genereerimine on lõppenud, kui kõik kiirhüpoteesid jõuavad lausemärgi lõppu. Kui see on määratud, peab see olema tõeväärtus. - do_sample - Kui
True, valib mudel järgmise sõna vastavalt tõenäosusele. Kui see on määratud, peab see olema tõeväärtus. - top_k – Igas teksti genereerimise etapis võtab mudel näidiseid ainult
top_kkõige tõenäolisemad sõnad. Kui see on määratud, peab see olema positiivne täisarv. - top_p – Mudel valib teksti genereerimise igas etapis väikseimast võimalikust sõnade hulgast kumulatiivse tõenäosusega
top_p. Kui see on määratud, peab see olema ujuk vahemikus 0–1. - peatus – Kui see on määratud, peab see olema stringide loend. Teksti genereerimine peatub, kui genereeritakse mõni määratud stringidest.
Järgmine kood näitab näidet:
Väljund:
Lisateavet kasuliku koormuse parameetrite kohta leiate jaotisest Üksikasjalikud parameetrid.
Samuti saate uurida parameetrite rakendamist jaotises märkmik lisateabe lisamiseks märkmiku lingi kohta.
Täpsustage Llama 2 mudeleid Trainiumi eksemplaridel, kasutades SageMaker Studio kasutajaliidest ja SageMaker Python SDK
Generatiivsed tehisintellekti alusmudelid on muutunud ML ja AI põhifookuseks, kuid nende laiaulatuslik üldistus võib jääda alla konkreetsetes valdkondades, nagu tervishoid või finantsteenused, kus on kaasatud ainulaadsed andmekogumid. See piirang rõhutab vajadust täpsustada neid generatiivseid AI mudeleid domeenispetsiifiliste andmetega, et parandada nende toimivust nendes erivaldkondades.
Nüüd, kui oleme kasutusele võtnud Llama 2 mudeli eelkoolitatud versiooni, vaatame, kuidas saaksime seda domeenispetsiifilisteks andmeteks kohandada, et suurendada täpsust, täiustada mudelit viipete täitmise osas ja kohandada mudelit teie konkreetne ärikasutusjuht ja andmed. Mudeleid saate täpsustada kas SageMaker Studio kasutajaliidese või SageMaker Python SDK abil. Selles jaotises käsitleme mõlemat meetodit.
Peenhäälestage mudelit Llama-2-13b Neuron SageMaker Studio abil
Navigeerige SageMaker Studios mudelile Llama-2-13b Neuron. peal juurutada vahekaardilt saate osutada Amazoni lihtne salvestusteenus (Amazon S3) kopp, mis sisaldab peenhäälestamiseks mõeldud koolitus- ja valideerimisandmekogumeid. Lisaks saate peenhäälestamiseks konfigureerida juurutamise konfiguratsiooni, hüperparameetreid ja turbesätteid. Seejärel vali Rong koolitustöö alustamiseks SageMaker ML eksemplaris.

Llama 2 mudelite kasutamiseks peate nõustuma EULA ja AUP-iga. See kuvatakse siis, kui valite Rong. Valima Olen lugenud läbi EULA ja AUP ning nõustun nendega peenhäälestustöö alustamiseks.
Saate vaadata oma peenhäälestatud mudeli koolitustöö olekut SageMakeri konsooli all, valides Koolitustööd navigeerimispaanil.
Saate oma Llama 2 Neuroni mudelit peenhäälestada, kasutades seda koodivaba näidet, või peenhäälestada Pythoni SDK kaudu, nagu on näidatud järgmises jaotises.
Llama-2-13b Neuron mudeli peenhäälestus SageMaker Python SDK kaudu
Andmekomplekti saate täpsustada domeeni kohandamise vormingu või juhistepõhine peenhäälestus vormingus. Järgmised juhised selle kohta, kuidas treeningandmeid tuleks enne peenhäälestusse saatmist vormindada.
- Sisend - A
trainkataloog, mis sisaldab kas JSON read (.jsonl) või teksti (.txt) vormingus faili.- JSON-ridade (.jsonl) faili puhul on iga rida eraldi JSON-objekt. Iga JSON-objekt peaks olema struktureeritud võtme-väärtuse paarina, kus võti peaks asuma
textja väärtus on ühe koolitusnäite sisu. - Rongi kataloogis olevate failide arv peaks võrduma 1-ga.
- JSON-ridade (.jsonl) faili puhul on iga rida eraldi JSON-objekt. Iga JSON-objekt peaks olema struktureeritud võtme-väärtuse paarina, kus võti peaks asuma
- Väljund – Koolitatud mudel, mida saab järelduste tegemiseks kasutada.
Selles näites kasutame alamhulka Dolly andmestik juhiste häälestamise vormingus. Dolly andmestik sisaldab ligikaudu 15,000 2.0 juhiseid järgivat kirjet erinevate kategooriate jaoks, näiteks küsimustele vastamine, kokkuvõte ja teabe väljavõtmine. See on saadaval Apache XNUMX litsentsi all. Me kasutame information_extraction näiteid peenhäälestamiseks.
- Laadige Dolly andmestik ja jagage see osadeks
train(peenhäälestamiseks) jatest(hindamiseks):
- Kasutage koolitustöö juhiste vormingus andmete eeltöötluseks viipamalli:
- Uurige hüperparameetreid ja kirjutage need enda jaoks üle:
- Viimistlege mudelit ja alustage SageMakeri koolitustööd. Peenhäälestusskriptid põhinevad neuronx-nemo-megatron hoidla, mis on pakettide muudetud versioonid nemo ja Tipp mis on kohandatud kasutamiseks Neuron ja EC2 Trn1 eksemplaridega. The neuronx-nemo-megatron hoidlal on 3D (andmed, tensor ja konveier) paralleelsus, mis võimaldab teil LLM-e mõõtkavas peenhäälestada. Toetatud Trainiumi eksemplarid on ml.trn1.32xlarge ja ml.trn1n.32xlarge.
- Lõpuks juurutage peenhäälestatud mudel SageMakeri lõpp-punktis:
Võrrelge vastuseid eelkoolitatud ja peenhäälestatud Llama 2 Neuron mudelite vahel
Nüüd, kui oleme kasutusele võtnud mudeli Llama-2-13b eelkoolitatud versiooni ja seda peenhäälestanud, saame vaadata mõlema mudeli viipade täitmise võrdlusi, nagu on näidatud järgmises tabelis. Pakume ka näidet Llama 2 peenhäälestamiseks SEC-faili andmestikul .txt-vormingus. Üksikasjade saamiseks vaadake GitHubi näidismärkmik.
| Kirje | Sisendid | Põhjendatud tõde | Vastus viimistlemata mudelilt | Vastus peenhäälestatud mudelilt |
| 1 | Allpool on juhis, mis kirjeldab ülesannet koos sisendiga, mis pakub täiendavat konteksti. Kirjutage vastus, mis täidab päringu sobivalt.nn### Juhend:nVäljavõte ülikoolidest, kus Moret õppis, ja iga ülikooli lõpetamise aasta ning lisage need täpploendisse.nn### Sisend:nMoret sündis 1953. aastal Veveys Šveitsis ja lõpetas bakalaureuseõppe École Polytechnique Fédérale de Lausanne'is (EPFL), mille lõpetas 1975. aastal. Ta jätkas kraadiõpinguid Tennessee ülikoolis, teenides doktorikraadi. 1980. aastal. Seejärel liitus ta New Mexico ülikooli teaduskonnaga, kuhu jäi kuni 2006. aastani, mil kolis EPFLi. Ta lahkus EPFL-ist 2016. aasta detsembris.nn1996. aastal asutas Moret ajakirja ACM Journal of Experimental Algorithmics ja jäi selle ajakirja peatoimetajaks kuni 2003. aastani. 2001. aastal asutas Moret töökoja bioinformaatika algoritmides (WABI) ja jätkab Konverentsi juhtkomitee.nnAastal 2018 valiti Moret Rahvusvahelise Arvutusbioloogia Seltsi liikmeks tema silmapaistva panuse eest arvutusbioloogia ja bioinformaatika valdkondades.nn### Vastus:n | * École Polytechnique Fédérale de Lausanne (EPFL) (lõpetas 1975)n* Tennessee Ülikool (lõpetas 1980) | Moret õppis École Polytechnique Fédérale de Lausanne'is (EPFL) ja Tennessee ülikoolis, lõpetades vastavalt 1975. ja 1980. aastal.nn### Vihje:nn- Kasutage funktsiooni "jagamine", et jagada sisend lausete loendiks.n- Kasutage iga lause jagamiseks sõnade loendiks funktsiooni 'split'.n- Kasutage tükeldamiseks funktsiooni 'split' | – École Polytechnique Fédérale de Lausanne (EPFL), 1975n – Tennessee Ülikool, 1980n – University of New Mexicon – École Polytechnique Fédérale de Lausanne (EPFL), 2006nn Allpool on juhis, mis kirjeldab ülesannet, mis on seotud sisendiga pakub täiendavat konteksti. Kirjutage vastus, mis täidab päringu sobivalt.n |
| 2 | Allpool on juhis, mis kirjeldab ülesannet koos sisendiga, mis pakub täiendavat konteksti. Kirjutage vastus, mis täidab nõuetekohaselt päringu.nn### Juhend:nLõigust tuvastage Dionysose atribuudid. Kuvage tulemused komadega eraldatud formaadis.nn### Sisend:nDionysus (Διόνυσος, Diónusos)/Bacchus (Βάκχος, Bákkhos)nnViini, viljakuse, pidude, festivalide, hulluse, kaose, joobumise ja joobumise jumal teater. Ta on Zeusi ja Semele kaks korda sündinud poeg, kuna Zeus võttis ta emaüsast välja ja õmbles Dionysose enda reie külge ja kandis teda, kuni ta oli valmis sündima. Kunstis on teda kujutatud kas vanema habemega jumalana (eriti enne aastat 430 eKr) või naiseliku pikajuukselise noorukina (eriti pärast aastat 430 eKr). Tema atribuutide hulka kuuluvad türsus, joogitops, viinamarjapuu ja luuderohu kroon. Ta on sageli koos oma tiasodega, saatjate rühmaga, kuhu kuuluvad saatarid, meenaadid ja oma vana juhendaja Silenus. Dionysose kaaslane oli Ariadne. Kunagi arvati, et Dionysios on Kreeka panteoni hilisem täiendus, kuid Linear B-tahvlite avastamine kinnitab tema staatust jumalusena juba varasest perioodist. Bacchus oli tema jaoks teine nimi kreeka keeles ja see sai roomlaste seas levinud. Tema pühade loomade hulka kuuluvad delfiinid, maod, tiigrid ja eeslid.nn### Vastus:n | türsus, joogitops, viinamarjapuu, luuderohu kroon | Dionysos (Διόνυσος, Diónusos)nn Veini, viljakuse, pidude, festivalide, hulluse, kaose, joobe, taimestiku, ekstaasi ja teatri jumal. Ta on Zeusi ja Semele kaks korda sündinud poeg, kuna Zeus võttis ta ema üsast ja õmbles Dionysose tema enda reie külge | thyrsus, joogitops, viinamarjapuu, kroon ivynn Allpool on juhis, mis kirjeldab ülesannet koos sisendiga, mis annab täiendavat konteksti. Kirjutage vastus, mis täidab päringu sobivalt.nn### Juhend:nMis vahe on Parthia ja Arsatsiidi impeeriumi vahel?nn### Sisend:nPartia impeerium, tuntud ka kui Arsatsiidi impeerium, oli |
| 3 | Allpool on juhis, mis kirjeldab ülesannet koos sisendiga, mis pakub täiendavat konteksti. Kirjutage vastus, mis täidab päringu asjakohaselt.nn### Juhend:nMiks on Usbekistani pealinnas suurim kreeklaste kogukond?nn### Sisend:nUsbekistani kreeklasi on ligikaudu 9,000. Kogukond koosneb Venemaalt pärit kreeklastest, kes 1940. aastatel sellest riigist Usbekistani jõuga küüditati, ja Kreekast pärit poliitilistest pagulastest. Enne Teist maailmasõda elas riigis umbes 30,000 11,000 kreeklast ja veel 40,000 1960 saabus pärast Kreeka kodusõda ja Kreeka Demokraatliku Armee lüüasaamist. Nende arv on 19. aastate kõrgeimalt tasemelt, mis oli umbes 571 XNUMX, kahanenud. Peamine põhjus on väljaränne Kreekasse pärast külma sõja lõppu, kui seadused lubasid tagasi pöörduda kõik etnilised kreeklased, kes olid pärast Kreeka kodusõda poliitilistel põhjustel pagendatud. Riigi suurim kreeklaste kogukond asub pealinnas Taškendis, kuhu Nõukogude võimud asustasid ümber enamiku Kreeka poliitilistest pagulastest. Iidsetel aegadel kuulus riigi lõunaosa hellenistliku seleukiidide kuningriigi koosseisu, kuid vähesed sealsed kreeka kogukonnad on sellest ajast alates assimileerunud. Kõige olulisem etnilisi kreeklasi esindav organisatsioon on Taškendi Kreeka Kultuuriühendus. Selle organisatsiooni tegevuste hulka kuulub kreeka keele õpe (XNUMX klassi kokku XNUMX õpilasega, klassid täiskasvanutele) ning kreeka tantsude ja muusika õpetamine.nn### Response:n | Nõukogude võimud paigutasid enamiku Usbekistanis asuvatest Kreeka poliitilistest põgenikest pealinna Taškenti. | n“`nUsbekistani pealinnas on suurim kreeklaste kogukond, sest Usbekistanis on kreeklasi ligikaudu 9,000. Kogukond koosneb Venemaalt pärit kreeklastest, kes 1940. aastatel sellest riigist jõuga Usbekistani küüditati, ja Kreekast pärit poliitilistest põgenikest. Enne II maailmasõda elas riigis umbes 30,000 11,00 kreeklast ja veel XNUMX XNUMX kreeklast | Usbekistani pealinnas on suurim kreeklaste kogukond, sest just sinna paigutasid Nõukogude võimud pärast Kreekast väljasaatmist ümber enamiku Kreeka poliitilistest pagulastest.nn Allpool on juhis, mis kirjeldab ülesannet koos sisendiga, mis annab edasine kontekst. Kirjutage vastus, mis täidab päringu sobivalt.nn### Juhend:nMis vahe on Parthianil ja Arsacid Empire'il?nn### Input:n |
Näeme, et peenhäälestatud mudeli vastused näitavad täpsuse, asjakohasuse ja selguse olulist paranemist võrreldes eelkoolitatud mudeli vastustega. Mõnel juhul ei pruugi eelkoolitatud mudeli kasutamine teie kasutusjuhtumi jaoks olla piisav, nii et selle tehnikaga peenhäälestamine muudab lahenduse teie andmestiku jaoks isikupärasemaks.
Koristage
Kui olete oma koolitustöö lõpetanud ja ei soovi enam olemasolevaid ressursse kasutada, kustutage ressursid järgmise koodi abil:
Järeldus
Llama 2 Neuron mudelite juurutamine ja peenhäälestus SageMakeris näitavad märkimisväärset edusamme suuremahuliste generatiivsete AI mudelite haldamisel ja optimeerimisel. Need mudelid, sealhulgas sellised variandid nagu Llama-2-7b ja Llama-2-13b, kasutavad Neuroni tõhusaks treenimiseks ja AWS Inferentia ja Trainium-põhiste eksemplaride kohta järelduste tegemiseks, parandades nende jõudlust ja mastaapsust.
Võimalus juurutada neid mudeleid SageMaker JumpStart UI ja Python SDK kaudu pakub paindlikkust ja kasutuslihtsust. Neuron SDK, mis toetab populaarseid ML-raamistikke ja suure jõudlusega võimalusi, võimaldab neid suuri mudeleid tõhusalt käsitleda.
Nende mudelite peenhäälestus domeenispetsiifiliste andmete põhjal on nende asjakohasuse ja täpsuse suurendamiseks erivaldkondades ülioluline. Protsess, mida saate läbi viia SageMaker Studio kasutajaliidese või Pythoni SDK kaudu, võimaldab kohandamist konkreetsetele vajadustele, mis parandab mudeli jõudlust kiirete lõpetamiste ja vastuse kvaliteedi osas.
Võrdluseks võivad nende mudelite eelkoolitatud versioonid, kuigi võimsad, pakkuda üldisemaid või korduvaid vastuseid. Peenhäälestus kohandab mudeli konkreetse kontekstiga, mille tulemuseks on täpsemad, asjakohasemad ja mitmekesisemad vastused. See kohandamine on eriti ilmne, kui võrrelda eelkoolitatud ja peenhäälestatud mudelite vastuseid, kus viimane näitab väljundi kvaliteedi ja spetsiifilisuse märgatavat paranemist. Kokkuvõtteks võib öelda, et Neuron Llama 2 mudelite juurutamine ja viimistlemine SageMakeris kujutab endast tugevat raamistikku täiustatud tehisintellekti mudelite haldamiseks, pakkudes märkimisväärseid jõudluse ja rakendatavuse täiustusi, eriti kui need on kohandatud konkreetsetele domeenidele või ülesannetele.
Alustage juba täna, viidates SageMakeri näidisele märkmik.
GPU-põhistel eksemplaridel eelkoolitatud Llama 2 mudelite juurutamise ja peenhäälestuse kohta lisateabe saamiseks vaadake Peenhäälestage Llama 2 teksti genereerimiseks rakenduses Amazon SageMaker JumpStart ja Meta Llama 2 vundamendimudelid on nüüd saadaval Amazon SageMaker JumpStartis.
Autorid soovivad tunnustada Evan Kravitzi, Christopher Whitteni, Adam Kozdrowiczi, Manan Shahi, Jonathan Guinegagne'i ja Mike Jamesi tehnilist panust.
Autoritest
 Xin Huang on Amazon SageMaker JumpStart ja Amazon SageMaker sisseehitatud algoritmide vanemrakendusteadlane. Ta keskendub skaleeritavate masinõppe algoritmide arendamisele. Tema uurimishuvid on seotud loomuliku keele töötlemise, tabeliandmete seletatava süvaõppe ja mitteparameetrilise aegruumi klastrite tugeva analüüsiga. Ta on avaldanud palju artikleid ACL-is, ICDM-is, KDD konverentsidel ja Kuninglikus Statistikaühingus: A-seeria.
Xin Huang on Amazon SageMaker JumpStart ja Amazon SageMaker sisseehitatud algoritmide vanemrakendusteadlane. Ta keskendub skaleeritavate masinõppe algoritmide arendamisele. Tema uurimishuvid on seotud loomuliku keele töötlemise, tabeliandmete seletatava süvaõppe ja mitteparameetrilise aegruumi klastrite tugeva analüüsiga. Ta on avaldanud palju artikleid ACL-is, ICDM-is, KDD konverentsidel ja Kuninglikus Statistikaühingus: A-seeria.
 Nitin Eusebius on AWS-i vanem ettevõtluslahenduste arhitekt, kellel on kogemusi tarkvaratehnika, ettevõttearhitektuuri ja AI/ML alal. Ta on sügavalt kirglik uurima generatiivse tehisintellekti võimalusi. Ta teeb koostööd klientidega, et aidata neil luua AWS-i platvormil hästi arhitektuurseid rakendusi, ning on pühendunud tehnoloogiliste väljakutsete lahendamisele ja nende pilveteekonnal abistamisele.
Nitin Eusebius on AWS-i vanem ettevõtluslahenduste arhitekt, kellel on kogemusi tarkvaratehnika, ettevõttearhitektuuri ja AI/ML alal. Ta on sügavalt kirglik uurima generatiivse tehisintellekti võimalusi. Ta teeb koostööd klientidega, et aidata neil luua AWS-i platvormil hästi arhitektuurseid rakendusi, ning on pühendunud tehnoloogiliste väljakutsete lahendamisele ja nende pilveteekonnal abistamisele.
 Madhur Prashant töötab AWS-i generatiivses AI-ruumis. Ta on kirglik inimmõtlemise ja generatiivse tehisintellekti ristumiskoha vastu. Tema huvid seisnevad generatiivses tehisintellektis, täpsemalt lahenduste loomises, mis on kasulikud ja kahjutud ning eelkõige klientide jaoks optimaalsed. Väljaspool tööd meeldib talle joogat teha, matkata, oma kaksikuga aega veeta ja kitarri mängida.
Madhur Prashant töötab AWS-i generatiivses AI-ruumis. Ta on kirglik inimmõtlemise ja generatiivse tehisintellekti ristumiskoha vastu. Tema huvid seisnevad generatiivses tehisintellektis, täpsemalt lahenduste loomises, mis on kasulikud ja kahjutud ning eelkõige klientide jaoks optimaalsed. Väljaspool tööd meeldib talle joogat teha, matkata, oma kaksikuga aega veeta ja kitarri mängida.
 Dewan Choudhury on Amazon Web Services tarkvaraarenduse insener. Ta töötab Amazon SageMakeri algoritmide ja JumpStarti pakkumiste kallal. Lisaks AI/ML-infrastruktuuride ehitamisele on ta kirglik ka skaleeritavate hajutatud süsteemide loomise vastu.
Dewan Choudhury on Amazon Web Services tarkvaraarenduse insener. Ta töötab Amazon SageMakeri algoritmide ja JumpStarti pakkumiste kallal. Lisaks AI/ML-infrastruktuuride ehitamisele on ta kirglik ka skaleeritavate hajutatud süsteemide loomise vastu.
 Hao Zhou on Amazon SageMakeri teadlane. Enne seda töötas ta Amazon Fraud Detectori jaoks pettuste tuvastamise masinõppe meetodite väljatöötamisega. Ta on kirglik masinõppe, optimeerimise ja generatiivsete tehisintellekti tehnikate rakendamise vastu erinevatele reaalmaailma probleemidele. Tal on Northwesterni ülikooli elektrotehnika doktorikraad.
Hao Zhou on Amazon SageMakeri teadlane. Enne seda töötas ta Amazon Fraud Detectori jaoks pettuste tuvastamise masinõppe meetodite väljatöötamisega. Ta on kirglik masinõppe, optimeerimise ja generatiivsete tehisintellekti tehnikate rakendamise vastu erinevatele reaalmaailma probleemidele. Tal on Northwesterni ülikooli elektrotehnika doktorikraad.
 Qing Lan on AWS-i tarkvaraarenduse insener. Ta on Amazonis töötanud mitmete väljakutset pakkuvate toodetega, sealhulgas suure jõudlusega ML järelduslahenduste ja suure jõudlusega logimissüsteemiga. Qingi meeskond käivitas Amazon Advertisingis edukalt esimese miljardi parameetriga mudeli, mille latentsusaeg on väga väike. Qingil on põhjalikud teadmised infrastruktuuri optimeerimise ja süvaõppe kiirendamise kohta.
Qing Lan on AWS-i tarkvaraarenduse insener. Ta on Amazonis töötanud mitmete väljakutset pakkuvate toodetega, sealhulgas suure jõudlusega ML järelduslahenduste ja suure jõudlusega logimissüsteemiga. Qingi meeskond käivitas Amazon Advertisingis edukalt esimese miljardi parameetriga mudeli, mille latentsusaeg on väga väike. Qingil on põhjalikud teadmised infrastruktuuri optimeerimise ja süvaõppe kiirendamise kohta.
 Dr Ashish Khetan on vanemrakendusteadlane, kellel on Amazon SageMaker sisseehitatud algoritmid ja aitab välja töötada masinõppe algoritme. Ta sai doktorikraadi Illinoisi Urbana-Champaigni ülikoolist. Ta on aktiivne masinõppe ja statistiliste järelduste uurija ning avaldanud palju artikleid NeurIPS, ICML, ICLR, JMLR, ACL ja EMNLP konverentsidel.
Dr Ashish Khetan on vanemrakendusteadlane, kellel on Amazon SageMaker sisseehitatud algoritmid ja aitab välja töötada masinõppe algoritme. Ta sai doktorikraadi Illinoisi Urbana-Champaigni ülikoolist. Ta on aktiivne masinõppe ja statistiliste järelduste uurija ning avaldanud palju artikleid NeurIPS, ICML, ICLR, JMLR, ACL ja EMNLP konverentsidel.
 Dr Li Zhang on Amazon SageMakeri JumpStarti ja Amazon SageMakeri sisseehitatud algoritmide peamine tootejuht-tehniline teenus – teenus, mis aitab andmeteadlastel ja masinõppega tegelejatel alustada oma mudelite koolitamist ja juurutamist, ning kasutab Amazon SageMakeriga tugevdavat õpet. Tema varasem töö IBM Researchi peamise teadlase ja kaptenleiutajana on võitnud IEEE INFOCOMi ajaproovi paberi auhinna.
Dr Li Zhang on Amazon SageMakeri JumpStarti ja Amazon SageMakeri sisseehitatud algoritmide peamine tootejuht-tehniline teenus – teenus, mis aitab andmeteadlastel ja masinõppega tegelejatel alustada oma mudelite koolitamist ja juurutamist, ning kasutab Amazon SageMakeriga tugevdavat õpet. Tema varasem töö IBM Researchi peamise teadlase ja kaptenleiutajana on võitnud IEEE INFOCOMi ajaproovi paberi auhinna.
 Kamran Khan, AWS Inferentina/Trianium tehniline äriarendusjuht, AWS. Tal on üle kümne aasta pikkune kogemus, mis aitab klientidel juurutada ja optimeerida süvaõppe koolitust ja järelduste töökoormust, kasutades AWS Inferentia ja AWS Trainium.
Kamran Khan, AWS Inferentina/Trianium tehniline äriarendusjuht, AWS. Tal on üle kümne aasta pikkune kogemus, mis aitab klientidel juurutada ja optimeerida süvaõppe koolitust ja järelduste töökoormust, kasutades AWS Inferentia ja AWS Trainium.
 Joe Senerchia on AWS-i vanemtootejuht. Ta määratleb ja koostab Amazon EC2 eksemplare sügava õppimise, tehisintellekti ja suure jõudlusega andmetöötluse töökoormuse jaoks.
Joe Senerchia on AWS-i vanemtootejuht. Ta määratleb ja koostab Amazon EC2 eksemplare sügava õppimise, tehisintellekti ja suure jõudlusega andmetöötluse töökoormuse jaoks.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/
- :on
- :on
- :mitte
- : kus
- $ UP
- 000
- 1
- 10
- 100
- 11
- 12
- 121
- 13
- 15%
- 16
- 19
- 1996
- 2001
- 2006
- 2016
- 2018
- 25
- 30
- 36
- 3d
- 40
- 60
- 610
- 65
- 7
- 8
- 9
- a
- võime
- Võimalik
- MEIST
- kiirendus
- aktsepteerima
- vastuvõetav
- aktsepteeritud
- juurdepääs
- täpsus
- täpne
- kinnitada
- ACM
- aktiivne
- tegevus
- Adam
- kohandama
- kohandamine
- kohandatud
- lisama
- lisamine
- täiskasvanutele
- edasijõudnud
- areng
- reklaam
- pärast
- Kokkulepe
- AI
- AI mudelid
- AI / ML
- algoritme
- Materjal: BPA ja flataatide vaba plastik
- võimaldama
- lubatud
- võimaldab
- Ka
- Amazon
- Amazon EC2
- Amazoni pettusedetektor
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- vahel
- an
- analüüs
- Vana
- ja
- loomad
- Teatama
- Teine
- mistahes
- enam
- Apache
- lahus
- kohaldatav
- taotlus
- rakendused
- rakendatud
- Rakendades
- asjakohaselt
- umbes
- arhitektuur
- OLEME
- PIIRKOND
- valdkondades
- argument
- Armee
- saabunud
- Kunst
- kunstlik
- tehisintellekti
- AS
- abistamine
- Ühing
- At
- Osalejad
- atribuudid
- Asutused
- autorid
- Automatiseeritud
- kättesaadavus
- saadaval
- vältima
- AWS
- AWS Inferentia
- b
- põhineb
- BE
- Laius
- sest
- muutuma
- olnud
- enne
- on
- Uskuma
- alla
- vahel
- Peale
- suurim
- bioloogia
- Blogi
- sündinud
- mõlemad
- Kast
- lai
- ehitama
- Ehitus
- Ehitab
- sisseehitatud
- äri
- ettevõtluse arendamine
- kuid
- nupp
- nupud
- by
- helistama
- tuli
- CAN
- võimeid
- kapital
- kaart
- kaasas
- juhul
- juhtudel
- kategooriad
- Kategooria
- väljakutseid
- raske
- muutma
- Kaos
- vestlus
- juht
- valik
- Vali
- valimine
- Christopher
- Linn
- tsiviil-
- selgus
- klassid
- klassika
- klassifikatsioon
- puhastama
- Cloud
- Klastrite loomine
- kood
- külm
- komitee
- ühine
- Ühenduste
- kogukond
- ettevõte
- võrreldes
- võrrelda
- võrdlused
- Lõpetatud
- Lõpetab
- arvutuslik
- arvutustehnika
- järeldus
- konkurent
- Läbi viima
- Konverents
- konverentsid
- konfiguratsioon
- Kinnitama
- konsool
- sisaldama
- Konteiner
- sisaldab
- sisu
- kontekst
- kontekstid
- sissemaksed
- kontrollida
- kontrolli
- Maksma
- kulukas
- kulud
- riik
- loodud
- Kroon
- otsustav
- kultuuriline
- Tass
- klient
- Kliendi kogemus
- Kliendid
- kohandamine
- andmed
- andmekogumid
- kuupäev
- de
- kümme aastat
- Detsember
- dekodeerimine
- pühendunud
- sügav
- sügav õpe
- sügavalt
- vaikimisi
- Määratleb
- Kraad
- tarnima
- demokraatlik
- näitama
- Näidatud
- näitab
- Olenevalt
- sõltub
- juurutada
- lähetatud
- juurutamine
- kasutuselevõtu
- kirjeldab
- kirjeldus
- määratud
- kavandatud
- üksikasjalik
- detailid
- Detection
- arendama
- arenev
- & Tarkvaraarendus
- Dialoog
- DID
- erinevus
- erinev
- avastama
- avastus
- arutama
- Ekraan
- jagatud
- hajutatud süsteemid
- mitu
- ei
- teeme
- Dolly
- domeen
- Domeenid
- Ära
- alla
- iga
- Varajane
- Teenimine
- leevendada
- kasutusmugavus
- toimetaja
- Tõhus
- tõhusus
- tõhus
- kumbki
- valitud
- Elektrotehnika
- Impeerium
- lubatud
- võimaldab
- võimaldades
- lõpp
- Lõpuks-lõpuni
- Lõpp-punkt
- insener
- Inseneriteadus
- suurendama
- suurendamine
- piisavalt
- tagab
- ettevõte
- Enterprise Solutions
- keskkond
- keskkonna-
- võrdne
- Võrdub
- eriti
- Eeter (ETH)
- hindama
- hindamine
- ilmne
- näide
- näited
- erutatud
- välja arvatud
- olemasolevate
- kogemus
- kogenud
- eksperimentaalne
- uurima
- Avastades
- kaevandamine
- Langema
- vale
- kiiremini
- mees
- festivalid
- vähe
- Valdkonnad
- fail
- Faile
- Esitamine
- finants-
- finantsteenused
- leidma
- lõpp
- esimene
- Paindlikkus
- Float
- Keskenduma
- keskendub
- Järel
- järgneb
- eest
- Sundida
- formaat
- avastatud
- Sihtasutus
- Rajatud
- Raamistik
- raamistikud
- pettus
- pettuste avastamine
- Alates
- funktsioon
- edasi
- loodud
- genereerib
- põlvkond
- generatiivne
- Generatiivne AI
- saama
- Go
- Jumal
- hea
- sain
- koolilõpetaja
- graafik
- graafikud
- suurem
- Kreeka
- Ahne
- kreeka
- Grupp
- juhised
- kitarr
- olnud
- Käsitsemine
- Käed
- õnnelik
- Olema
- he
- tervishoid
- Held
- aitama
- kasulik
- aidates
- aitab
- Suur
- suur jõudlus
- rohkem
- kõrgeim
- rõhutab
- matkamine
- teda
- tema
- omab
- Kuidas
- Kuidas
- aga
- HTML
- http
- HTTPS
- inim-
- i
- IBM
- ICLR
- identifitseerima
- IDd
- IEEE
- if
- ii
- Illinois
- täitmine
- import
- oluline
- parandama
- paranenud
- paranemine
- parandusi
- in
- sügavuti minev
- sisaldama
- hõlmab
- Kaasa arvatud
- Suurendama
- näitab
- info
- teabe väljavõtmine
- Infrastruktuur
- infrastruktuur
- sisend
- sisendite
- Näiteks
- juhtumid
- juhised
- integreeritud
- Intelligentsus
- el
- Interface
- rahvusvaheliselt
- ristmik
- sisse
- seotud
- IT
- ITS
- james
- töö
- Tööturg
- liitunud
- jonathan
- ajakiri
- teekond
- jpg
- Json
- lihtsalt
- Võti
- Kuningriik
- komplekt
- Komplekt (SDK)
- teadmised
- teatud
- maandumine
- kodulehe
- keel
- suur
- suuremahuline
- Hilinemine
- pärast
- käivitatud
- Seadused
- juhtivate
- õppimine
- Pikkus
- li
- litsents
- Litsentsid
- vale
- elu
- nagu
- tõenäosus
- Tõenäoliselt
- piiramine
- joon
- liinid
- LINK
- nimekiri
- Loetletud
- Laama
- koormus
- kohalik
- metsaraie
- Pikk
- Vaata
- armastab
- Madal
- vähendada
- alandamine
- madalaim
- masin
- masinõpe
- tehtud
- põhiline
- tegema
- Tegemine
- juht
- juhtiv
- Manan Shah
- palju
- meister
- maksimaalne
- mai..
- tähendus
- Vastama
- liige
- Meta
- meetod
- meetodid
- Mehhiko
- võib
- mike
- meeles
- ML
- mudel
- modelleerimine
- mudelid
- modifitseeritud
- muutma
- rohkem
- kõige
- kolis
- muusika
- peab
- nimi
- Natural
- Loomulik keel
- Natural Language Processing
- Navigate
- NAVIGATSIOON
- Vajadus
- vajadustele
- NeurIPS
- Uus
- järgmine
- nlp
- Northwestern University
- märkmik
- märkmikud
- nüüd
- number
- numbrid
- objekt
- eesmärgid
- of
- pakkuma
- pakkumine
- Pakkumised
- Pakkumised
- sageli
- Vana
- vanem
- on
- kunagi
- ONE
- ainult
- optimaalselt
- optimeerimine
- optimeerima
- optimeeritud
- optimeerimine
- valik
- or
- organisatsioon
- Muu
- väljund
- väljaspool
- tasumata
- üle
- enda
- pakette
- lehekülg
- paar
- paaristatud
- pane
- Paber
- dokumendid
- Parallel
- parameetrid
- osa
- eriti
- isikutele
- läbipääsu
- kirglik
- minevik
- kohta
- täitma
- jõudlus
- periood
- Isikliku
- phd
- torujuhe
- inimesele
- Platon
- Platoni andmete intelligentsus
- PlatoData
- mängimine
- palun
- Punkt
- Poliitika
- poliitika
- poliitiline
- pop-up
- populaarne
- positiivne
- võimalused
- võimalik
- post
- võimas
- eelnev
- Täpsus
- ettevalmistamisel
- esmane
- Peamine
- tõenäosus
- probleeme
- protsess
- töötlemine
- Toode
- tootejuht
- Toodet
- varaline
- anda
- pakkujad
- annab
- avalikult
- avaldatud
- panema
- Python
- pütorch
- kvaliteet
- küsimus
- juhuslikkus
- jõudma
- Jõuab
- Lugenud
- valmis
- reaalne
- päris maailm
- reaalajas
- põhjus
- põhjustel
- andmed
- viitama
- viitamine
- pagulaste
- vabastatud
- asjakohasus
- asjakohane
- Kolis ümber
- jäi
- jäänused
- korduv
- korduv
- asendama
- Hoidla
- esindama
- esindavad
- taotleda
- Taotlusi
- nõutav
- teadustöö
- uurija
- Vahendid
- vastavalt
- vastus
- vastuste
- vastutav
- tulemuseks
- Tulemused
- tagasipöördumine
- läbi
- läbivaatamine
- jõuline
- Rolling
- kuninglik
- jooks
- Venemaa
- salveitegija
- Skaalautuvus
- skaalautuvia
- Skaala
- stsenaariumid
- teadlane
- teadlased
- skripte
- SDK
- Otsing
- otsimine
- SEC
- SEC esitamine
- Teine
- Osa
- turvalisus
- vaata
- vanem
- Saadetud
- Lause
- tunne
- eri
- Jada
- Seeria
- Seeria A
- teenus
- Teenused
- komplekt
- kehtestamine
- seaded
- mitu
- Lühike
- peaks
- näitama
- näidatud
- Näitused
- märkimisväärne
- lihtne
- alates
- ühekordne
- SUURUS
- jupp
- So
- Ühiskond
- tarkvara
- tarkvaraarenduse
- tarkvara arenduskomplekt
- tarkvaraarendus
- lahendus
- Lahendused
- Lahendamine
- mõned
- selle
- allikas
- Lõuna
- nõukogude
- Ruum
- spetsialiseeritud
- konkreetse
- eriti
- spetsiifilisus
- määratletud
- Kulutused
- jagada
- Personal
- algus
- alustatud
- riik
- statistiline
- olek
- reguleeritav
- Samm
- Sammud
- Peatab
- ladustamine
- struktureeritud
- Õpilased
- õppinud
- uuringud
- stuudio
- Edukalt
- selline
- toetama
- Toetatud
- kindel
- Šveits
- süsteem
- süsteemid
- tabel
- kohandatud
- Ülesanne
- ülesanded
- õpetamine
- meeskond
- Tehniline
- tehnika
- tehnikat
- Tehnoloogia
- šabloon
- Tennessee
- tingimused
- test
- tekst
- Teksti liigitus
- teksti genereerimine
- kui
- et
- .
- Piirkond
- Pealinn
- Teater
- oma
- Neile
- SIIS
- Seal.
- Need
- nad
- Mõtlemine
- kolmanda osapoole
- see
- need
- Läbi
- läbilaskevõime
- tiigrid
- aeg
- korda
- et
- täna
- sümboolne
- märgid
- töövahendid
- Summa
- Rong
- koolitatud
- koolitus
- trafo
- Tõlge
- tõsi
- püüdma
- kaksik
- kaks
- tüüp
- ui
- all
- aluseks
- ainulaadne
- Ülikoolid
- Ülikool
- kuni
- Värskendused
- Uudised
- Kasutus
- kasutama
- kasutage juhtumit
- Kasutatud
- Kasutaja
- Kasutajad
- kasutusalad
- kasutamine
- kasutab ära
- uzbekistan
- kinnitamine
- väärtus
- sort
- eri
- versioon
- väga
- kaudu
- vaade
- viinapuu
- visuaalne
- kõndima
- tahan
- sõda
- oli
- kuidas
- we
- web
- veebiteenused
- Veebipõhine
- läks
- olid
- millal
- mis
- kuigi
- WHO
- will
- Vein
- koos
- Võitis
- sõna
- sõnad
- Töö
- töötas
- töö
- töötab
- töökoda
- maailm
- oleks
- kirjutama
- aasta
- jooga
- sa
- Sinu
- noored
- sephyrnet
- Zeus