Amazoni punane nihe on täielikult hallatav ja petabaitide mastaabis pilvandmeladu, mida kasutavad kümned tuhanded kliendid iga päev eksabaitide kaupa andmete töötlemiseks, et oma analüütika töökoormust suurendada. Dimensioonimudeli abil saate oma andmeid struktureerida, äriprotsesse mõõta ja väärtuslikku teavet kiiresti saada. Amazon Redshift pakub sisseehitatud funktsioone, mis kiirendavad mõõtmete mudeli modelleerimist, orkestreerimist ja aruandlust.
Selles postituses arutame, kuidas rakendada mõõtmete mudelit, täpsemalt Kimballi metoodika. Arutame mõõtmete ja faktide rakendamist Amazon Redshiftis. Näitame, kuidas teostada ekstrakti, teisendust ja laadimist (ELT) – integreerimisprotsessi, mis keskendub andmejärvest toorandmete saamisele modelleerimise läbiviimiseks etapikihti. Üldiselt annab postitus teile selge ülevaate mõõtmete modelleerimise kasutamisest Amazon Redshiftis.
Lahenduse ülevaade
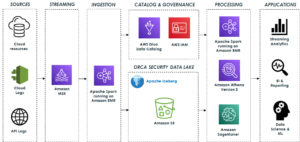
Järgnev diagramm illustreerib lahenduse arhitektuuri.

Järgmistes osades käsitleme esmalt mõõtmemudeli põhiaspekte ja demonstreerime neid. Pärast seda loome Amazon Redshifti abil andmemargi koos mõõtmete andmemudeliga, mis sisaldab mõõtmete ja faktitabeleid. Andmed laaditakse ja lavastati kasutades COPY käsku, laaditakse mõõtmete andmed kasutades ÜHENDAB avaldus ja faktid liidetakse dimensioonidega, millest arusaamad pärinevad. Ajastame mõõtmete ja faktide laadimise, kasutades Amazon Redshift Query Editor V2. Lõpuks kasutame Amazon QuickSight et saada ülevaadet modelleeritud andmetest QuickSighti armatuurlaua kujul.
Selle lahenduse jaoks kasutame sündmuste piletite müügiks Amazon Redshifti pakutavat näidisandmestikku (normaliseeritud). Selle postituse jaoks oleme andmestikku lihtsuse ja tutvustamise eesmärgil kitsendanud. Järgmistes tabelites on näiteid piletimüügi ja toimumiskohtade andmetest.


Vastavalt Kimballi mõõtmete modelleerimise metoodika, on mõõtmetega mudeli kujundamisel neli peamist sammu:
- Tuvastage äriprotsess.
- Deklareerige oma andmete tera.
- Tehke kindlaks ja rakendage mõõtmed.
- Tuvastage faktid ja rakendage neid.
Lisaks lisame tutvustamise eesmärgil viienda sammu, milleks on ärisündmuste aruandlus ja analüüsimine.
Eeldused
Selle ülevaate jaoks peaksid teil olema järgmised eeltingimused.
Tuvastage äriprotsess
Lihtsamalt öeldes tähendab äriprotsessi tuvastamine organisatsioonis andmeid genereeriva mõõdetava sündmuse tuvastamist. Tavaliselt on ettevõtetel mingi toimiv lähtesüsteem, mis genereerib nende andmed töötlemata kujul. See on hea lähtepunkt äriprotsessi erinevate allikate tuvastamiseks.
Seejärel jätkatakse äriprotsessi kui a andmed mart mõõtmete ja faktide näol. Vaadates meie varem mainitud näidisandmestikku, näeme selgelt, et äriprotsess on antud sündmuse jaoks tehtud müük.
Levinud viga on ettevõtte osakondade kasutamine äriprotsessina. Andmed (äriprotsess) tuleb integreerida erinevate osakondade vahel, sel juhul pääseb turundus müügiandmetele ligi. Õige äriprotsessi tuvastamine on kriitilise tähtsusega – selle sammu valesti sooritamine võib mõjutada kogu andmeturgu (see võib põhjustada tera dubleerimist ja valesid mõõdikuid lõpparuannetes).
Deklareerige oma andmete tera
Teravilja deklareerimine on teie andmeallika kirje kordumatu tuvastamine. Tera kasutatakse faktitabelis, et mõõta andmeid täpselt ja võimaldada teil edasi kerida. Meie näites võib see olla müügiäriprotsessi reaartikkel.
Meie kasutusjuhul saab müügi üheselt tuvastada, vaadates tehingu aega, millal müük toimus; see on kõige atomaarsem tase.

Tehke kindlaks ja rakendage mõõtmed
Teie dimensioonitabel kirjeldab teie faktitabelit ja selle atribuute. Äriprotsessi kirjeldava konteksti tuvastamisel salvestate teksti eraldi tabelisse, pidades silmas faktitabelit. Dimensioonide tabeli ühendamisel faktitabeliga peaks faktitabeliga olema seotud ainult üks rida. Meie näites kasutame mõõtmete tabeliks eraldamiseks järgmist tabelit; need väljad kirjeldavad fakte, mida me mõõdame.
Mõõtmemudeli (skeemi) struktuuri kavandamisel saate luua a täht or lumehelves skeem. Struktuur peaks olema tihedalt kooskõlas äriprotsessiga; seetõttu sobib meie näite jaoks kõige paremini täheskeem. Järgmine joonis näitab meie olemisuhete diagrammi (ERD).

Järgmistes jaotistes kirjeldame üksikasjalikult mõõtmete rakendamise samme.
Lavastage lähteandmed
Enne mõõtmete tabeli loomist ja laadimist vajame lähteandmeid. Seetõttu lavastame lähteandmed etapiviisiliseks või ajutiseks tabelisse. Seda nimetatakse sageli lavastuskiht, mis on lähteandmete töötlemata koopia. Selleks kasutame Amazon Redshiftis COPY käsk andmete laadimiseks dimensioonide modelleerimine amazon-redshift avalikust S3 ämbrist, mis asub us-east-1 Piirkond. Pange tähele, et käsk COPY kasutab a AWS-i identiteedi- ja juurdepääsuhaldus (IAM) rolli koos juurdepääs Amazon S3-le. Roll peab olema klastriga seotud. Lähteandmete etapistamiseks tehke järgmised sammud.
- Loo
venuelähtetabel:
- Laadige koha andmed:
- Loo
saleslähtetabel:
- Laadige müügi lähteandmed:
- Loo
calendartabelis:
- Laadige kalendri andmed:
Loo mõõtmete tabel
Dimensioonide tabeli kujundamine võib sõltuda teie ettevõtte vajadustest – näiteks kas peate jälgima andmete muutumist aja jooksul? Seal on seitse erinevat mõõtmetüüpi. Meie näiteks kasutame tüüp 1 sest me ei pea jälgima ajaloolisi muutusi. Lisateavet tüübi 2 kohta leiate artiklist Lihtsustage andmete laadimist 2. tüüpi aeglaselt muutuvatesse mõõtmetesse Amazon Redshiftis. Mõõtmete tabel denormaliseeritakse primaarvõtme, asendusvõtme ja mõne lisatud väljaga, mis näitavad tabeli muudatusi. Vaadake järgmist koodi:
Mõned märkused mõõtmete tabeli loomise kohta:
- Väljanimed muudetakse ärisõbralikeks nimedeks
- Meie esmane võti on
VenueID, mida kasutame müügi toimumise koha unikaalseks tuvastamiseks - Lisatakse kaks täiendavat rida, mis näitavad, millal kirje sisestati ja seda värskendati (muudatuste jälgimiseks)
- Me kasutame an AUTOMAATNE levitamise stiil et anda Amazon Redshiftile vastutus levitamisstiili valimise ja kohandamise eest
Teine oluline tegur, mida mõõtmete modelleerimisel arvestada, on selle kasutamine asendusvõtmed. Asendusvõtmed on tehisvõtmed, mida kasutatakse mõõtmete modelleerimisel, et identifitseerida unikaalselt iga kirje dimensioonitabelis. Tavaliselt genereeritakse need järjestikuste täisarvudena ja neil pole ärivaldkonnas mingit tähendust. Need pakuvad mitmeid eeliseid, näiteks unikaalsuse tagamine ja liitumiste jõudluse parandamine, kuna need on tavaliselt väiksemad kui loomulikud võtmed ja asendusvõtmetena need aja jooksul ei muutu. See võimaldab meil olla järjepidev ning fakte ja mõõtmeid hõlpsamini ühendada.
Amazon Redshiftis luuakse asendusvõtmed tavaliselt märksõna IDENTITY abil. Näiteks eelnev CREATE-lause loob dimensioonitabeli koos a-ga VenueSkey asendusvõti. The VenueSkey veerg täidetakse automaatselt kordumatute väärtustega, kui tabelisse lisatakse uusi ridu. Seda veergu saab seejärel kasutada toimumiskoha tabeli ühendamiseks FactSaleTransactions tabelis.
Mõned näpunäited asendusvõtmete kujundamiseks:
- Kasutage asendusvõtme jaoks väikest fikseeritud laiusega andmetüüpi. See parandab jõudlust ja vähendab salvestusruumi.
- Kasutage märksõna IDENTITY või genereerige asendusvõti, kasutades järjestikust või GUID-väärtust. See tagab, et asendusvõti on kordumatu ja seda ei saa muuta.
Laadige hämardamise tabel, kasutades MERGE
Hämarate tabeli laadimiseks on mitmeid viise. Arvesse tuleb võtta teatud tegureid, näiteks jõudlust, andmemahtu ja võib-olla SLA laadimisaegu. Koos ÜHENDAB avaldusega, teostame upsert ilma, et peaksime määrama mitut sisestamis- ja värskendamiskäsku. Saate seadistada ÜHENDAB avaldus a salvestatud protseduur andmete täitmiseks. Seejärel plaanite salvestatud protseduuri programmiliselt käivitada päringuredaktori kaudu, mida me hiljem postituses demonstreerime. Järgmine kood loob salvestatud protseduuri nimega SalesMart.DimVenueLoad:
Mõned märkused mõõtmete laadimise kohta:
- Kui kirje sisestatakse esimest korda, sisestatakse sisestatud kuupäev ja värskendatud kuupäev. Kui mis tahes väärtused muutuvad, värskendatakse andmeid ja värskendatud kuupäev kajastab nende muutmise kuupäeva. Sisestatud kuupäev jääb alles.
- Kuna andmeid kasutavad ärikasutajad, peame asendama NULL väärtused, kui neid on, ärile sobivamate väärtustega.
Tuvastage faktid ja rakendage neid
Nüüd, kui oleme kuulutanud oma teravilja konkreetsel ajal toimunud müügisündmuseks, salvestab meie faktitabel meie äriprotsessi numbrilised faktid.
Oleme mõõtmiseks tuvastanud järgmised arvulised faktid:
- Müüdud piletite kogus müügi kohta
- Vahendustasu müügi eest
Fakti rakendamine
Seal on kolme tüüpi faktitabeleid (tehingu faktitabel, perioodiline hetktõmmise faktitabel ja akumuleeruv hetktõmmise faktitabel). Igaüks neist pakub äriprotsessist erinevat vaadet. Meie näites kasutame tehingute faktide tabelit. Tehke järgmised sammud.
- Looge faktitabel
Lisatakse vaikeväärtusega sisestatud kuupäev, mis näitab, kas ja millal kirje laaditi. Saate seda kasutada faktitabeli uuesti laadimisel, et eemaldada juba laaditud andmed, et vältida dubleerimist.
Faktitabeli laadimine koosneb lihtsast sisestuslausest, mis ühendab teie seotud mõõtmed. Liitume alates DimVenue loodud tabel, mis kirjeldab meie fakte. See on parim tava, kuid see on vabatahtlik kalendri kuupäev dimensioonid, mis võimaldavad lõppkasutajal faktitabelis navigeerida. Andmeid saab laadida uue müügi korral või iga päev; siin tuleb kasuks sisestatud kuupäev või laadimiskuupäev.
Laadime faktitabeli salvestatud protseduuri abil ja kasutame kuupäeva parameetrit.
- Looge salvestatud protseduur järgmise koodiga. Sama andmete terviklikkuse säilitamiseks, mida kasutasime dimensioonide laadimisel, asendame NULL väärtused, kui neid on, ärile sobivamate väärtustega.
- Laadige andmed, kutsudes protseduuri järgmise käsuga:
Ajastage andmete laadimine
Nüüd saame modelleerimisprotsessi automatiseerida, ajastades salvestatud protseduurid Amazon Redshift Query Editor V2-s. Tehke järgmised sammud.
- Esmalt kutsume välja mõõtmekoormuse ja pärast mõõtmete koormuse edukat käivitamist algab faktikoormus:
Kui mõõtmete laadimine ebaõnnestub, faktikoormust ei käivitata. See tagab andmete järjepidevuse, sest me ei soovi laadida faktitabelit aegunud mõõtmetega.
- Laadimise ajastamiseks valige Ajakava päringuredaktoris V2.

- Ajastame päringu käivitumise iga päev kell 5.
- Soovi korral saate lubades lisada tõrketeateid Amazoni lihtne teavitusteenus (Amazon SNS) teatised.

Teatage ja analüüsige andmeid Amazon Quicksightis
QuickSight on äriteabe teenus, mis muudab ülevaate edastamise lihtsaks. Täielikult hallatava teenusena võimaldab QuickSight hõlpsasti luua ja avaldada interaktiivseid armatuurlaudu, millele pääseb juurde mis tahes seadmest ja mis on manustatud teie rakendustesse, portaalidesse ja veebisaitidele.
Kasutame oma andmemarti faktide visuaalseks esitamiseks armatuurlaua kujul. QuickSighti alustamiseks ja seadistamiseks vaadake Andmestiku loomine andmebaasi abil, mida pole automaatselt tuvastatud.
Kui olete QuickSightis andmeallika loonud, ühendame modelleeritud andmed (data mart) meie asendusvõtme alusel kokku skey. Kasutame seda andmestikku andmeturu visualiseerimiseks.

Meie lõpu armatuurlaud sisaldab andmeturu teadmisi ja vastuseid kriitilistele äriküsimustele, nagu kogu komisjonitasu koha kohta ja suurima müügiga kuupäevad. Järgmine ekraanipilt näitab andmemargi lõpptoodet.

Koristage
Edaspidiste tasude vältimiseks kustutage kõik selle postituse raames loodud ressursid.
Järeldus
Oleme nüüd edukalt juurutanud andmemargi, kasutades meie DimVenue, DimCalendarja FactSaleTransactions tabelid. Meie ladu ei ole täielik; kui saame laiendada andmeturgu rohkemate faktidega ja juurutada rohkem marte, ning äriprotsesside ja nõuete kasvades aja jooksul kasvab ka andmeladu. Selles postituses andsime täieliku ülevaate mõõtmete modelleerimise mõistmisest ja rakendamisest Amazon Redshiftis.
Alustage oma Amazoni punane nihe mõõtmetega mudel tänapäeval.
Autoritest
 Bernard Verster on kogenud pilveinsener, kes on aastaid kokku puutunud skaleeritavate ja tõhusate andmemudelite loomisega, andmete integreerimise strateegiate määratlemisega ning andmete haldamise ja turvalisuse tagamisega. Ta on kirglik andmete kasutamise vastu, et koguda teadmisi, ühildades samal ajal ärinõuete ja eesmärkidega.
Bernard Verster on kogenud pilveinsener, kes on aastaid kokku puutunud skaleeritavate ja tõhusate andmemudelite loomisega, andmete integreerimise strateegiate määratlemisega ning andmete haldamise ja turvalisuse tagamisega. Ta on kirglik andmete kasutamise vastu, et koguda teadmisi, ühildades samal ajal ärinõuete ja eesmärkidega.
 Abhishek Pan on WWSO spetsialist SA-Analytics, kes töötab AWS India avaliku sektori klientidega. Ta suhtleb klientidega, et määratleda andmepõhise strateegia, korraldada analüütika kasutusjuhtude põhjalikke sukeldumise seansse ning kavandada skaleeritavaid ja tõhusaid analüütilisi rakendusi. Tal on 12-aastane kogemus ja ta on kirglik andmebaaside, analüütika ja AI/ML-i vastu. Ta on innukas reisija ja püüab jäädvustada maailma läbi oma kaameraobjektiivi.
Abhishek Pan on WWSO spetsialist SA-Analytics, kes töötab AWS India avaliku sektori klientidega. Ta suhtleb klientidega, et määratleda andmepõhise strateegia, korraldada analüütika kasutusjuhtude põhjalikke sukeldumise seansse ning kavandada skaleeritavaid ja tõhusaid analüütilisi rakendusi. Tal on 12-aastane kogemus ja ta on kirglik andmebaaside, analüütika ja AI/ML-i vastu. Ta on innukas reisija ja püüab jäädvustada maailma läbi oma kaameraobjektiivi.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Autod/elektrisõidukid, Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- BlockOffsets. Keskkonnakompensatsiooni omandi ajakohastamine. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- :on
- :on
- :mitte
- : kus
- $ UP
- 1
- 100
- 12
- 15%
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- MEIST
- kiirendama
- juurdepääs
- pääses
- täpselt
- üle
- tegu
- lisama
- lisatud
- Täiendavad lisad
- pärast
- AI / ML
- viia
- joondamine
- võimaldama
- võimaldab
- juba
- am
- Amazon
- Amazon Web Services
- an
- analüüs
- Analüütiline
- analytics
- analüüsima
- ja
- vastus
- mistahes
- rakendused
- rakendatud
- asjakohane
- arhitektuur
- OLEME
- kunstlik
- AS
- aspektid
- seotud
- At
- atribuudid
- auto
- automatiseerima
- automaatselt
- vältima
- AWS
- b
- põhineb
- BE
- sest
- alustama
- Kasu
- BEST
- sisseehitatud
- äri
- ärianalüüsi
- Äriprotsess
- äriprotsessid
- kuid
- by
- kalender
- helistama
- kutsutud
- kutsudes
- kaamera
- CAN
- lüüa
- juhul
- juhtudel
- Põhjus
- kindel
- muutma
- muutunud
- Vaidluste lahendamine
- muutuv
- iseloom
- koormuste
- Vali
- selge
- selgelt
- lähedalt
- Cloud
- kood
- Veerg
- tuleb
- komisjonitasu
- ühine
- Ettevõtted
- ettevõte
- täitma
- Arvestama
- järjepidev
- koosneb
- kontekst
- parandada
- võiks
- looma
- loodud
- loob
- loomine
- loomine
- kriitiline
- Kliendid
- iga päev
- armatuurlaud
- armatuurlauad
- andmed
- andmete integreerimine
- andmejärv
- andmekogus
- andmepõhistele
- Andmepõhine strateegia
- andmebaas
- andmebaasid
- kuupäev
- Kuupäevad
- kuupäev Kellaaeg
- päev
- sügav
- sügav sukeldumine
- vaikimisi
- määratlemisel
- tarnima
- näitama
- osakonnad
- Tuletatud
- kirjeldama
- Disain
- projekteerimine
- detail
- seade
- erinev
- mõõde
- mõõdud
- arutama
- eristatav
- jaotus
- do
- domeen
- tehtud
- Ära
- alla
- ajam
- duplikaadid
- iga
- Ajalugu
- kergesti
- lihtne
- toimetaja
- tõhus
- kumbki
- varjatud
- võimaldama
- võimaldades
- lõpp
- Lõpuks-lõpuni
- haarab
- insener
- tagama
- tagab
- tagades
- Kogu
- üksus
- Eeter (ETH)
- sündmus
- sündmused
- Iga
- iga päev
- näide
- näited
- Laiendama
- kogemus
- kogenud
- Säritus
- väljavõte
- asjaolu
- faktor
- tegurid
- andmed
- ei
- ebaedu
- FUNKTSIOONID
- vähe
- väli
- Valdkonnad
- viies
- Joonis
- filtreerida
- lõplik
- esimene
- Esimest korda
- sobima
- keskendunud
- Järel
- eest
- vorm
- formaat
- neli
- Alates
- täielikult
- edasi
- tulevik
- kasu
- tekitama
- loodud
- genereerib
- saama
- saamine
- Andma
- antud
- hea
- valitsemistava
- Kasvama
- mugav
- Olema
- he
- kõrgeim
- tema
- ajalooline
- puhkus
- Kuidas
- Kuidas
- HTML
- http
- HTTPS
- IAM
- tuvastatud
- identifitseerima
- identifitseerimiseks
- Identity
- if
- illustreerib
- mõju
- rakendada
- rakendatud
- rakendamisel
- oluline
- parandama
- Paranemist
- in
- Kaasa arvatud
- India
- näitama
- Näitab
- info
- teadmisi
- integreeritud
- integratsioon
- terviklikkuse
- Intelligentsus
- interaktiivne
- sisse
- IT
- ITS
- liituma
- liitunud
- liitumine
- Liita
- jpg
- hoidma
- pidamine
- Võti
- võtmed
- järv
- keel
- pärast
- hiljemalt
- kiht
- lahkus
- KLAAS
- Lets
- Tase
- joon
- koormus
- laadimine
- saadetised
- asub
- otsin
- tehtud
- TEEB
- juhitud
- Turundus
- sobitatud
- tähendus
- mõõtma
- mainitud
- Merge
- Meetrika
- meeles
- viga
- mudel
- modelleerimine
- modelleerimine
- mudelid
- kuu
- rohkem
- kõige
- mitmekordne
- nimed
- Natural
- Navigate
- Vajadus
- vajav
- vajadustele
- Uus
- märkused
- teade
- teated
- nüüd
- arvukad
- eesmärgid
- of
- pakkuma
- sageli
- on
- ainult
- töökorras
- or
- organisatsioon
- meie
- üle
- üldine
- parameeter
- osa
- kirglik
- kohta
- täitma
- jõudlus
- ehk
- perioodiline
- Koht
- Platon
- Platoni andmete intelligentsus
- PlatoData
- Punkt
- asustatud
- post
- võim
- tava
- eeldused
- esitada
- esmane
- menetlus
- menetlused
- protsess
- Protsessid
- Toode
- anda
- tingimusel
- annab
- avalik
- avaldama
- eesmärkidel
- Küsimused
- kiiresti
- tõstma
- Töötlemata
- algandmed
- rekord
- andmed
- vähendama
- nimetatud
- peegeldab
- piirkond
- suhe
- jäänused
- kõrvaldama
- asendama
- aru
- Aruandlus
- Aruanded
- Nõuded
- Vahendid
- vastutus
- Roll
- Rull
- ROW
- jooks
- jookseb
- müük
- müük
- sama
- Näidisandmekogum
- skaalautuvia
- ajakava
- planeerimine
- lõigud
- sektor
- turvalisus
- vaata
- eri
- teenib
- teenus
- Teenused
- istungid
- komplekt
- mitu
- peaks
- näitama
- Näitused
- lihtne
- lihtsus
- ühekordne
- Aeglaselt
- väike
- väiksem
- Snapshot
- So
- müüdud
- lahendus
- mõned
- allikas
- Allikad
- Ruum
- spetsialist
- konkreetse
- eriti
- Stage
- matkimine
- täht
- alustatud
- Käivitus
- väljavõte
- Samm
- Sammud
- ladustamine
- salvestada
- ladustatud
- strateegiad
- Strateegia
- struktuur
- edukas
- Edukalt
- selline
- süsteem
- tabel
- ajutine
- kümneid
- tingimused
- kui
- et
- .
- Allikas
- maailm
- oma
- SIIS
- Seal.
- seetõttu
- Need
- nad
- see
- tuhandeid
- Läbi
- pilet
- piletimüük
- piletid
- aeg
- korda
- ajatempel
- nõuanded
- et
- täna
- kokku
- võttis
- Summa
- jälgida
- tehing
- Muutma
- ümber
- reisija
- tüüp
- liigid
- tüüpiliselt
- mõistmine
- ainulaadne
- ainulaadselt
- unikaalsus
- tundmatu
- Värskendused
- ajakohastatud
- us
- Kasutus
- kasutama
- kasutage juhtumit
- Kasutatud
- Kasutajad
- kasutusalad
- kasutamine
- tavaliselt
- väärtuslik
- väärtus
- Väärtused
- eri
- Tegevuskoht
- juhtumused
- kaudu
- vaade
- maht
- läbikäiguks
- tahan
- Ladu
- oli
- kuidas
- we
- web
- veebiteenused
- veebilehed
- nädal
- millal
- mis
- kuigi
- will
- koos
- jooksul
- ilma
- töö
- maailm
- Vale
- aasta
- aastat
- sa
- Sinu
- sephyrnet