Paljud organisatsioonid, nii väikesed kui ka suured, töötavad Amazon Web Services (AWS) analüütika töökoormuse üleviimise ja moderniseerimise nimel. Klientidel on AWS-ile üleminekuks palju põhjuseid, kuid üks peamisi põhjusi on võimalus kasutada täielikult hallatud teenuseid, mitte kulutada aega infrastruktuuri hooldamisele, paikamisele, jälgimisele, varukoopiatele ja muule. Juhtimis- ja arendusmeeskonnad saavad praeguse infrastruktuuri säilitamise asemel kulutada rohkem aega praeguste lahenduste optimeerimisele ja isegi uute kasutusjuhtumitega katsetamisele.
Kuna saate AWS-is kiiresti liikuda, peate skaleerimise jätkamisel vastutama ka saadavate ja töödeldavate andmete eest. Nende kohustuste hulka kuulub andmete privaatsust käsitlevate seaduste ja eeskirjade järgimine ning tundlike andmete, nagu isikut tuvastav teave (PII) või kaitstud terviseteave (PHI), säilitamine ega avalikustamine ülesvooluallikatest.
Selles postituses käsitleme kõrgetasemelist arhitektuuri ja konkreetset kasutusjuhtumit, mis näitab, kuidas saate jätkata oma organisatsiooni andmeplatvormi skaleerimist, ilma et peaksite kulutama andmekaitseprobleemide lahendamiseks palju arendusaega. Me kasutame AWS liim PII-andmete tuvastamiseks, maskeerimiseks ja redigeerimiseks enne nende laadimist Amazon OpenSearchi teenus.
Lahenduse ülevaade
Järgnev diagramm illustreerib kõrgtaseme lahenduse arhitektuuri. Oleme määratlenud kõik oma disaini kihid ja komponendid kooskõlas AWS-i hästi üles ehitatud raamistiku andmeanalüüsi objektiiv.
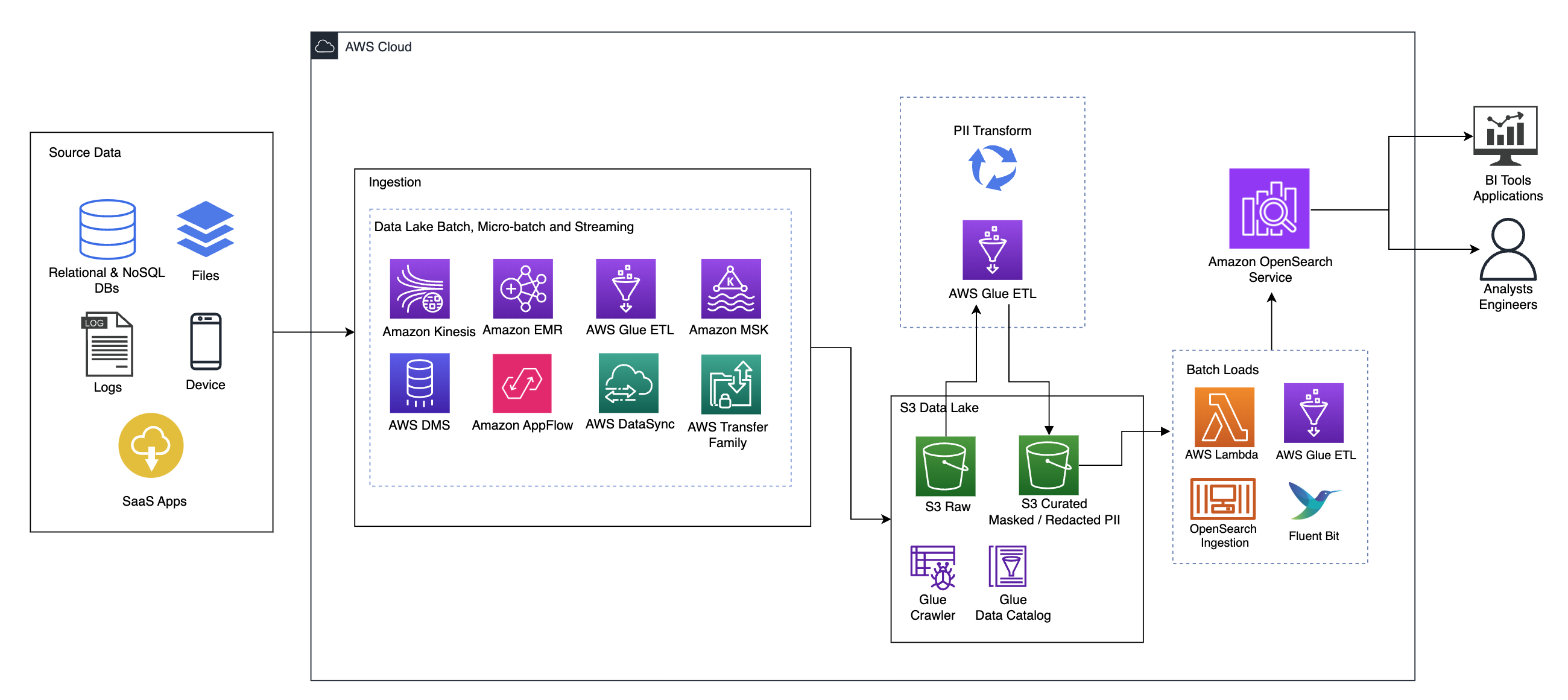
Arhitektuur koosneb mitmest komponendist:
Allikas andmete
Andmed võivad pärineda kümnetest kuni sadadest allikatest, sealhulgas andmebaasidest, failiedastustest, logidest, tarkvara kui teenuse (SaaS) rakendustest ja muust. Organisatsioonid ei pruugi alati omada kontrolli selle üle, millised andmed tulevad nende kanalite kaudu nende allavoolu salvestusruumi ja rakendustesse.
Allaneelamine: Data Lake'i partii, mikropartii ja voogesitus
Paljud organisatsioonid suunavad oma lähteandmed oma andmejärve mitmel viisil, sealhulgas pakett-, mikropartii- ja voogesitustööd. Näiteks, Amazon EMR, AWS liimja AWS-i andmebaasi migratsiooniteenus (AWS DMS) saab kõiki kasutada pakett- ja/või voogedastustoimingute tegemiseks, mis vajuvad andmejärve Amazoni lihtne salvestusteenus (Amazon S3). Amazon App Flow saab kasutada andmete edastamiseks erinevatest SaaS-i rakendustest andmejärve. AWS DataSync ja AWS-i ülekandeperekond võib aidata failide teisaldamisel andmejärve ja sealt välja mitme erineva protokolli kaudu. Amazon kinesis ja Amazon MSK-l on ka võimalus voogesitada andmeid otse Amazon S3 andmejärve.
S3 andmejärv
Amazon S3 kasutamine andmejärve jaoks on tänapäevase andmestrateegiaga kooskõlas. See pakub odavat salvestusruumi jõudlust, töökindlust või kättesaadavust ohverdamata. Selle lähenemisviisi abil saate oma andmetesse arvutada vastavalt vajadusele ja maksta ainult nende tööks vajamineva võimsuse eest.
Selles arhitektuuris võivad algandmed pärineda erinevatest allikatest (sisemised ja välised), mis võivad sisaldada tundlikke andmeid.
Kasutades AWS Glue roomajaid, saame avastada ja kataloogida andmed, mis loovad meie jaoks tabeliskeemid, ning lõppkokkuvõttes on lihtne kasutada AWS Glue ETL-i koos PII-teisendusega, et tuvastada ja maskeerida või redigeerida mis tahes tundlikke andmeid, mis võisid maanduda. andmejärves.
Ärikontekst ja andmestikud
Et näidata meie lähenemisviisi väärtust, kujutame ette, et kuulute finantsteenuste organisatsiooni andmetöötlusmeeskonda. Teie nõuded on tuvastada ja maskeerida tundlikke andmeid, kui need teie organisatsiooni pilvekeskkonda sisenevad. Andmeid tarbivad järgnevad analüütilised protsessid. Teie kasutajad saavad tulevikus turvaliselt otsida ajaloolisi maksetehinguid sisemistest pangasüsteemidest kogutud andmevoogude põhjal. Töörühmade, klientide ja liideserakenduste otsingutulemused peavad olema tundlikel väljadel maskeeritud.
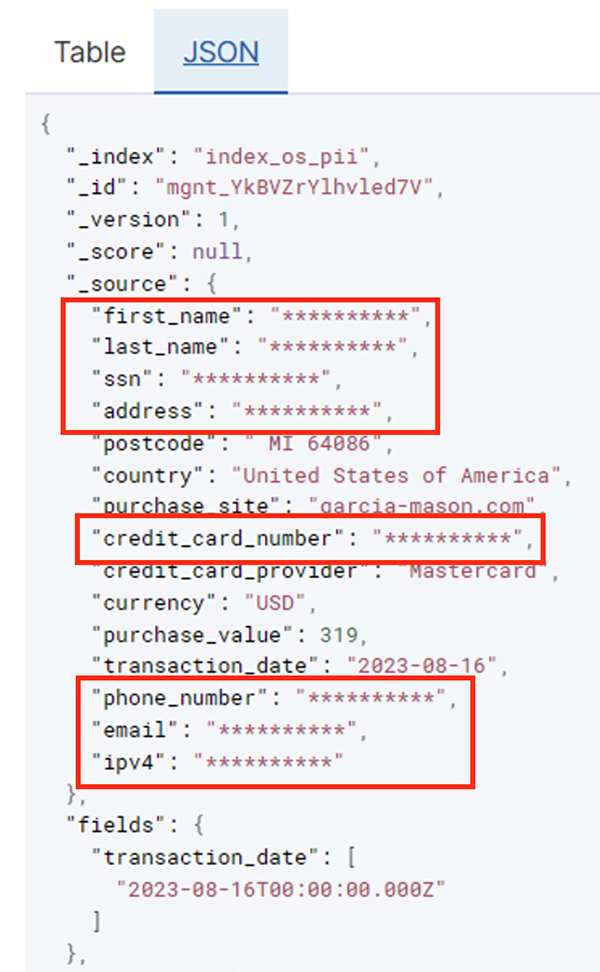
Järgmises tabelis on näidatud lahenduse jaoks kasutatud andmestruktuur. Selguse huvides oleme vastendanud töötlemata veergude nimed. Märkate, et selle skeemi mitut välja loetakse tundlikeks andmeteks, nagu eesnimi, perekonnanimi, sotsiaalkindlustuse number (SSN), aadress, krediitkaardi number, telefoninumber, e-posti aadress ja IPv4-aadress.
| Toores veeru nimi | Kureeritud veeru nimi | KASUTUSALA |
| c0 | eesnimi | nöör |
| c1 | perekonnanimi | nöör |
| c2 | ssn | nöör |
| c3 | aadress | nöör |
| c4 | postiindeks | nöör |
| c5 | riik | nöör |
| c6 | ostu_sait | nöör |
| c7 | krediit kaardi number | nöör |
| c8 | krediitkaardi_pakkuja | nöör |
| c9 | raha | nöör |
| c10 | ostu_väärtus | täisarv |
| c11 | tehingu kuupäev | andmed |
| c12 | telefoninumber | nöör |
| c13 | nöör | |
| c14 | ipv4 | nöör |
Kasutusjuhtum: PII partii tuvastamine enne OpenSearchi teenusesse laadimist
Kliendid, kes rakendavad järgmist arhitektuuri, on loonud oma andmejärve Amazon S3-le, et käitada erinevat tüüpi analüütikat ulatuslikult. See lahendus sobib klientidele, kes ei vaja OpenSearch Service'i reaalajas sisenemist ja kavatsevad kasutada andmete integreerimise tööriistu, mis töötavad ajakava järgi või käivituvad sündmuste kaudu.
Enne andmekirjete jõudmist Amazon S3-le rakendame sisestuskihi, et tuua kõik andmevood usaldusväärselt ja turvaliselt andmejärve. Kinesise andmevoogusid kasutatakse sisestuskihina struktureeritud ja poolstruktureeritud andmevoogude kiirendamiseks. Nende näideteks on relatsioonilise andmebaasi muudatused, rakendused, süsteemilogid või klikivood. Muudatuste andmehõive (CDC) kasutusjuhtudel saate AWS-i DMS-i sihtmärgina kasutada Kinesise andmevooge. Tundlikke andmeid sisaldavaid vooge genereerivad rakendused või süsteemid saadetakse Kinesise andmevoogu ühe kolmest toetatud meetodist: Amazon Kinesis Agent, AWS SDK Java jaoks või Kinesise tootjateek. Viimase sammuna Amazon Kinesis Data Firehose aitab meil usaldusväärselt laadida peaaegu reaalajas andmepakette meie S3 andmejärve sihtkohta.
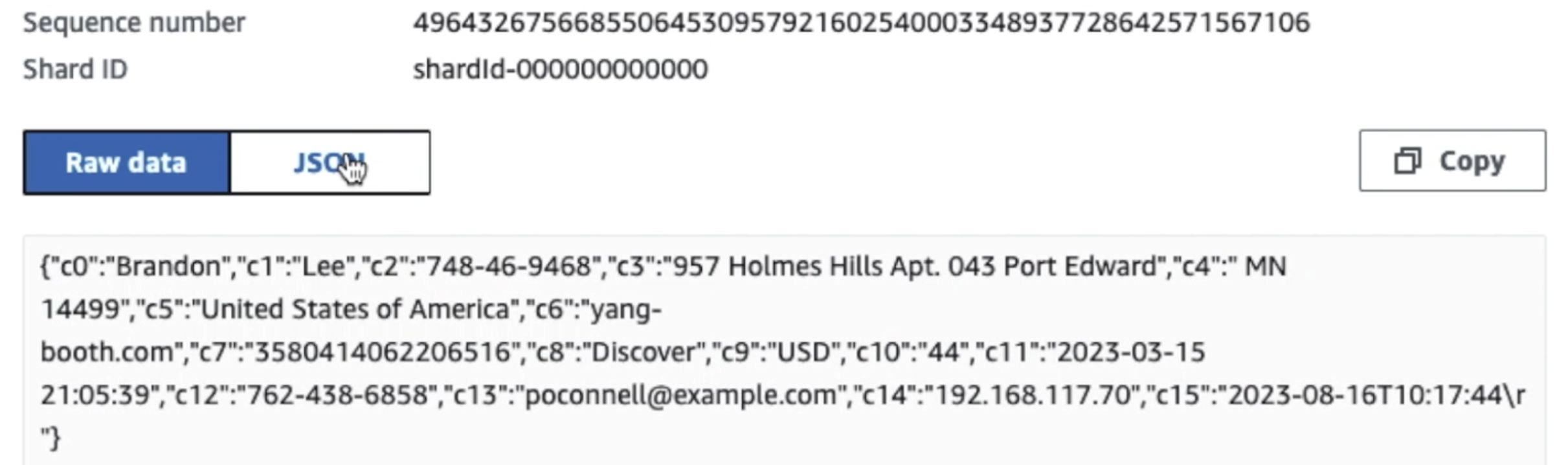
Järgmine ekraanipilt näitab, kuidas andmed liiguvad läbi Kinesise andmevoogude kaudu Andmevaatur ja hangib näidisandmed, mis maanduvad töötlemata S3 prefiksile. Selle arhitektuuri puhul järgisime S3 eesliidete andmete elutsüklit, nagu on soovitatud Data järve sihtasutus.
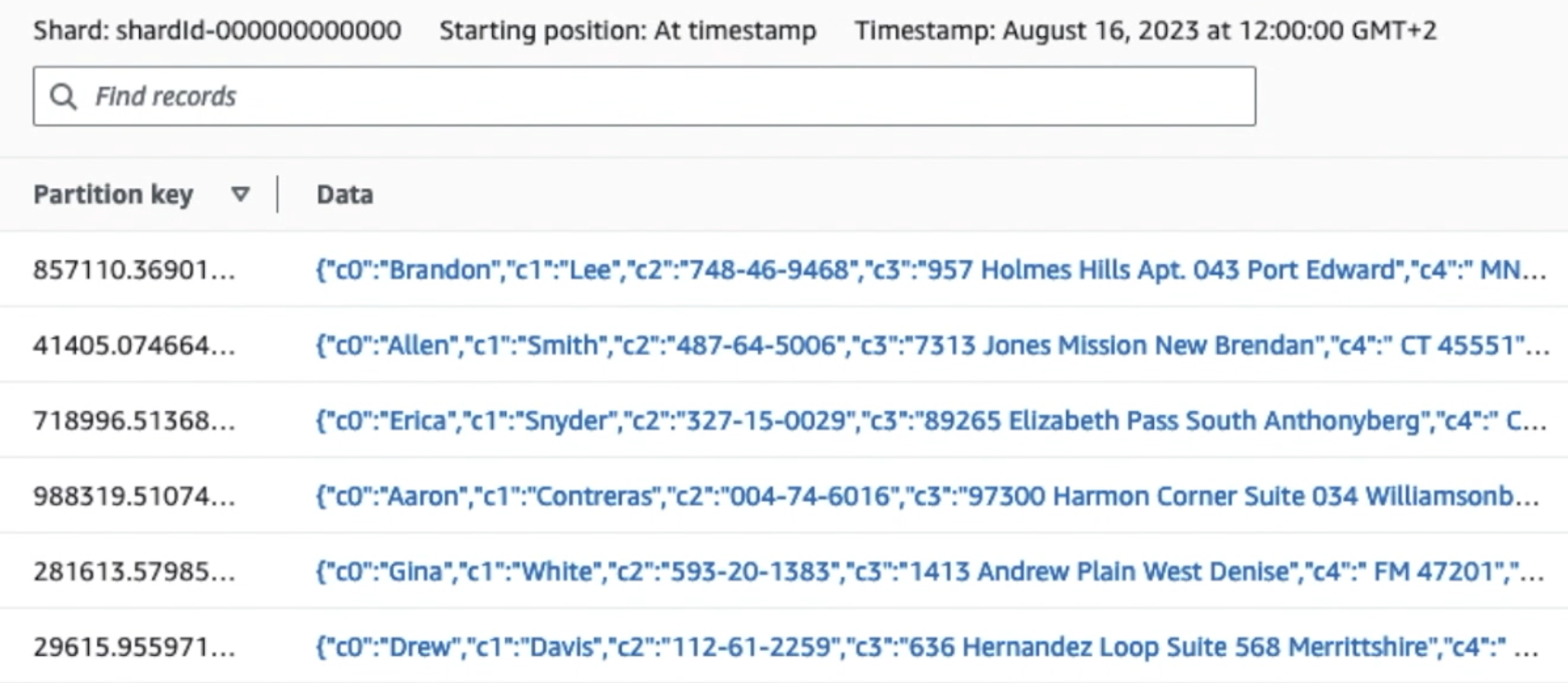
Nagu näete järgmise ekraanipildi esimese kirje üksikasjadest, järgib JSON-i kasulik koormus sama skeemi nagu eelmises jaotises. Näete redigeerimata andmeid, mis voolavad Kinesise andmevoogu, mis hiljem järgmistes etappides hägustatakse.
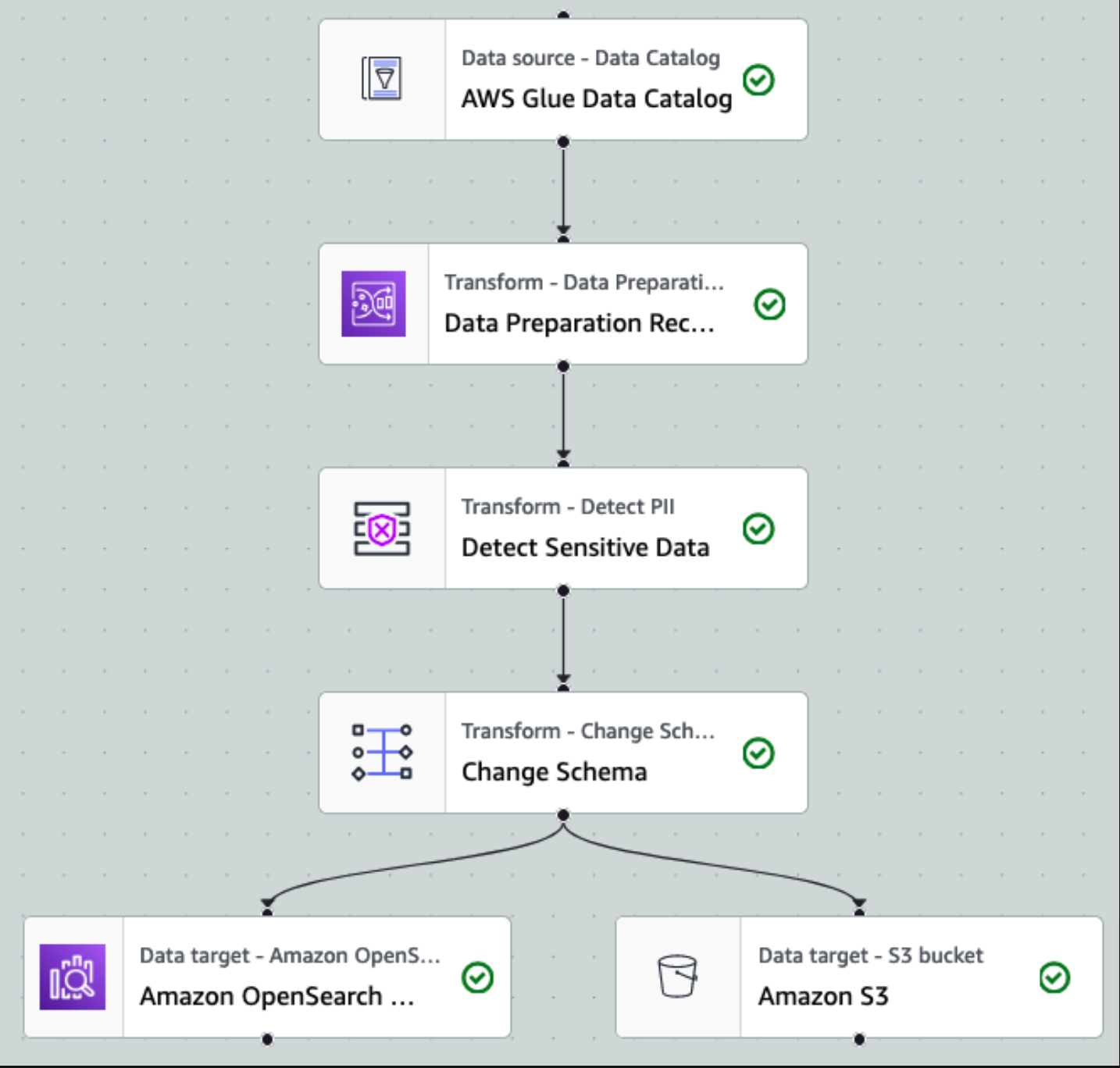
Pärast andmete kogumist ja Kinesise andmevoogudesse neelamist ning Kinesis Data Firehose'i abil S3 ämbrisse edastamist võtab arhitektuuri töötlemiskiht üle. Kasutame AWS Glue PII teisendust, et automatiseerida tundlike andmete tuvastamist ja maskeerimist. Nagu on näidatud järgmises töövoo diagrammis, kasutasime AWS Glue Studios teisendustöö rakendamiseks koodivaba visuaalset ETL-i lähenemisviisi.
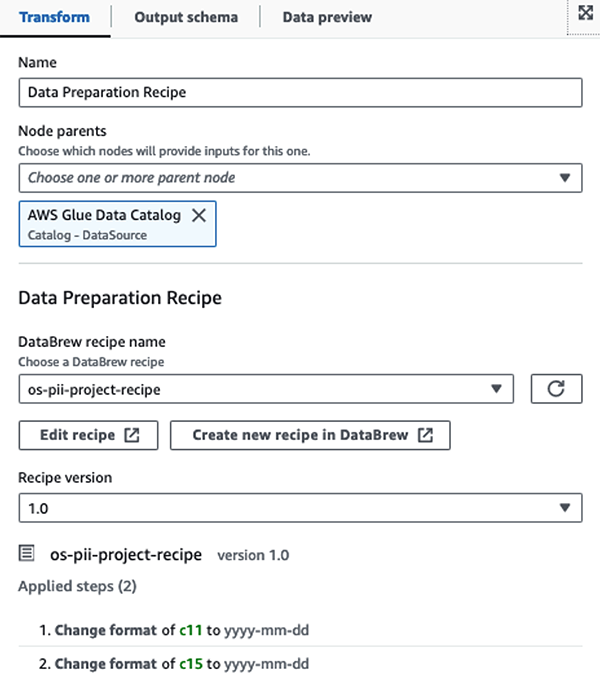
Esiteks pääseme lähteandmete kataloogi tabelile töötlemata pii_data_db andmebaasi. Tabelis on eelmises jaotises esitatud skeemi struktuur. Töödeldud töötlemata andmete jälgimiseks kasutasime töö järjehoidjad.

Me kasutame AWS Glue DataBrew retseptid AWS Glue Studio visuaalses ETL töös et muuta kaks kuupäevaatribuuti, et need ühilduksid eeldatava OpenSearchiga vormid. See võimaldab meil täielikku koodivaba kogemust.
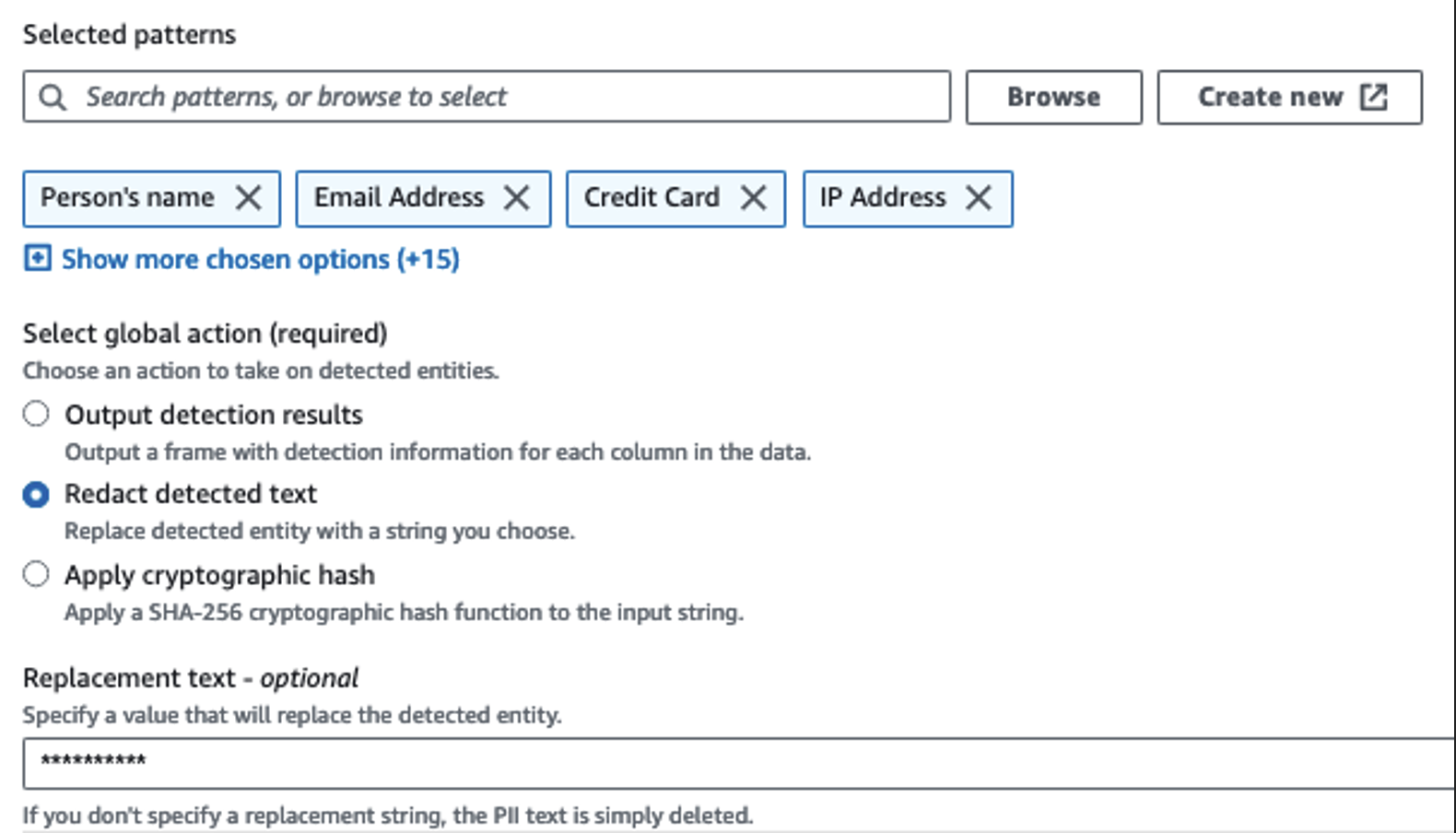
Tundlike veergude tuvastamiseks kasutame toimingut Tuvasta PII. Lasime AWS Glue'il selle kindlaks määrata valitud mustrite, tuvastamisläve ja andmestiku ridade näidisosa põhjal. Meie näites kasutasime mustreid, mis kehtivad spetsiaalselt Ameerika Ühendriikide kohta (nt SSN-id) ja ei pruugi tuvastada teistest riikidest pärit tundlikke andmeid. Võite otsida saadaolevaid kategooriaid ja asukohti, mis sobivad teie kasutusjuhtumiga, või kasutada AWS Glue'is regulaaravaldisi (regex), et luua teistest riikidest pärit tundlike andmete tuvastamise üksusi.
Oluline on valida õige proovivõtumeetod, mida AWS Glue pakub. Selles näites on teada, et voost tulevatel andmetel on igal real tundlikud andmed, seega pole vaja 100% andmestiku ridadest valimit võtta. Kui teil on nõue, et allavoolu allikatesse ei tohi tundlikke andmeid edastada, kaaluge 100% andmete proovivõtmist valitud mustrite jaoks või skannige kogu andmestik ja toimige iga üksiku lahtriga, et tagada kõigi tundlike andmete tuvastamine. Proovivõtmisest saadav kasu on kulude vähenemine, kuna te ei pea nii palju andmeid skannima.

Toiming PII tuvastamine võimaldab teil tundlike andmete varjamisel valida vaikestringi. Meie näites kasutame stringi **********.
Kasutame kaardistamise rakenduse toimingut ebavajalike veergude ümbernimetamiseks ja eemaldamiseks ingestion_year, ingestion_monthja ingestion_day. See samm võimaldab meil muuta ka ühe veeru andmetüüpi (purchase_value) stringist täisarvuni.

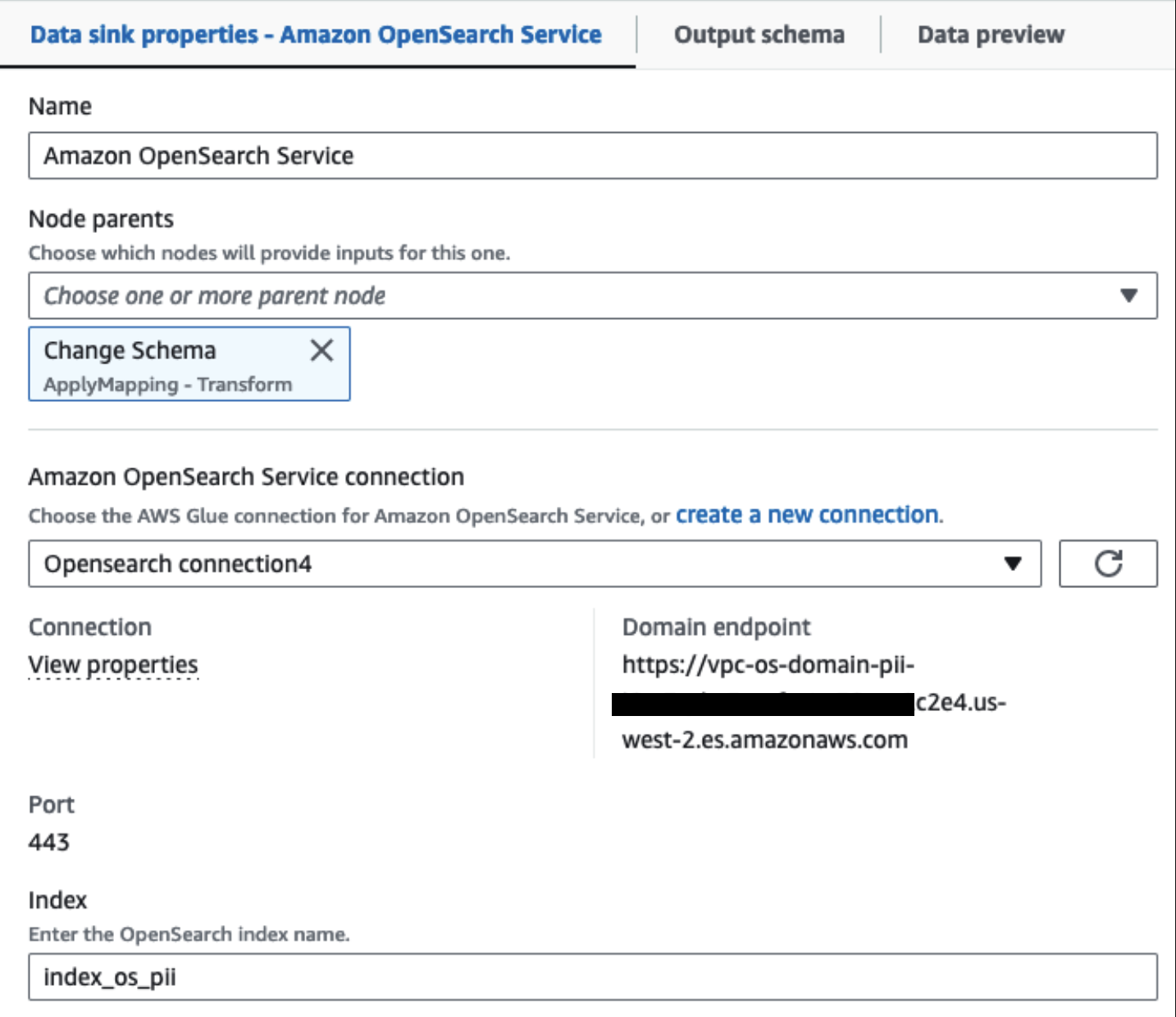
Sellest hetkest alates jaguneb töö kaheks väljundsihtkohaks: OpenSearch Service ja Amazon S3.
Meie varustatud OpenSearch teenuse klaster on ühendatud kaudu OpenSearchi sisseehitatud pistik liimi jaoks. Määrame OpenSearchi indeksi, kuhu soovime kirjutada, ja konnektor haldab mandaate, domeeni ja porti. Alloleval ekraanipildil kirjutame määratud registrisse index_os_pii.
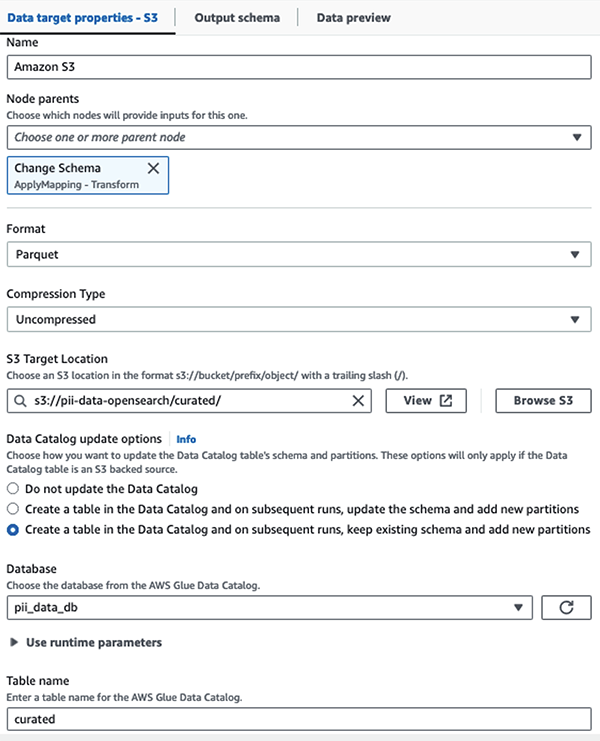
Salvestame maskeeritud andmestiku kureeritud S3 prefiksis. Seal on meil andmeid, mis on normaliseeritud konkreetse kasutusjuhtumi järgi ja andmeteadlaste poolt ohutuks tarbimiseks või ad hoc aruandlusvajadusteks.
Kõigi andmekogumite ja andmekataloogi tabelite ühtseks juhtimiseks, juurdepääsukontrolliks ja kontrolljälgedeks saate kasutada AWS järve kihistu. See aitab teil piirata juurdepääsu AWS-i liimiandmete kataloogi tabelitele ja nende aluseks olevatele andmetele ainult nende kasutajate ja rollidega, kellele on antud selleks vajalikud õigused.
Pärast paketttöö edukat käitamist saate kasutada OpenSearch Service'i otsingupäringute või aruannete käitamiseks. Nagu on näidatud järgmisel ekraanipildil, maskeeris konveier tundlikud väljad automaatselt ilma koodiarenduseta.

Tegevusandmete põhjal saate tuvastada suundumusi, näiteks krediitkaardipakkuja poolt filtreeritud tehingute arvu päevas, nagu on näidatud eelmisel ekraanipildil. Samuti saate määrata asukohad ja domeenid, kus kasutajad oste sooritavad. The transaction_date atribuut aitab meil neid suundumusi aja jooksul näha. Järgmine ekraanipilt näitab kirjet, kus kogu tehinguteave on asjakohaselt redigeeritud.
Alternatiivsete meetodite kohta andmete Amazon OpenSearchi laadimiseks vaadake jaotist Voogesituse andmete laadimine Amazon OpenSearch Service'i.
Lisaks saab tundlikke andmeid avastada ja maskeerida ka teiste AWS-lahenduste abil. Näiteks võite kasutada Amazon Macie tundlike andmete tuvastamiseks S3 ämbris ja seejärel kasutada Amazoni mõistmine tuvastatud tundlike andmete eemaldamiseks. Lisateabe saamiseks vaadake Levinud tehnikad PHI- ja PII-andmete tuvastamiseks AWS-teenuste abil.
Järeldus
Selles postituses käsitleti delikaatsete andmete käitlemise tähtsust teie keskkonnas ning erinevaid meetodeid ja arhitektuure, et need vastaksid nõuetele, võimaldades samal ajal teie organisatsioonil kiiresti skaleerida. Peaksite nüüd hästi teadma, kuidas oma andmeid tuvastada, maskeerida või redigeerida ning Amazon OpenSearch Service'i laadida.
Autoritest
 Michael Hamilton on Sr Analytics Solutions Arhitekt, kes keskendub ettevõtte klientide abistamisele AWS-i analüüsi töökoormuse ajakohastamisel ja lihtsustamisel. Talle meeldib mägirattaga sõita ning veeta aega oma naise ja kolme lapsega, kui ta ei tööta.
Michael Hamilton on Sr Analytics Solutions Arhitekt, kes keskendub ettevõtte klientide abistamisele AWS-i analüüsi töökoormuse ajakohastamisel ja lihtsustamisel. Talle meeldib mägirattaga sõita ning veeta aega oma naise ja kolme lapsega, kui ta ei tööta.
 Daniel Rozo on vanemlahenduste arhitekt, kelle AWS toetab kliente Hollandis. Tema kirg on lihtsate andme- ja analüüsilahenduste väljatöötamine ning klientide abistamine kaasaegsete andmearhitektuuride juurde. Väljaspool tööd meeldib talle tennist mängida ja jalgrattaga sõita.
Daniel Rozo on vanemlahenduste arhitekt, kelle AWS toetab kliente Hollandis. Tema kirg on lihtsate andme- ja analüüsilahenduste väljatöötamine ning klientide abistamine kaasaegsete andmearhitektuuride juurde. Väljaspool tööd meeldib talle tennist mängida ja jalgrattaga sõita.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/
- :on
- :on
- :mitte
- : kus
- 07
- 100
- 28
- 300
- 31
- 32
- 39
- 40
- 46
- 50
- 51
- 600
- 90
- 970
- a
- võime
- Võimalik
- kiirendatud
- juurdepääs
- tegu
- tegevus
- Ad
- aadress
- Agent
- Materjal: BPA ja flataatide vaba plastik
- lubatud
- Lubades
- võimaldab
- Ka
- alati
- Amazon
- Amazon kinesis
- Amazon Web Services
- Amazon Web Services (AWS)
- summa
- summad
- an
- Analüütiline
- analytics
- ja
- mistahes
- kohaldatav
- rakendused
- kehtima
- lähenemine
- asjakohaselt
- arhitektuur
- OLEME
- AS
- At
- atribuudid
- audit
- automatiseerima
- automaatselt
- kättesaadavus
- saadaval
- AWS
- AWS liim
- varukoopiaid
- Pangandus
- Pangasüsteemid
- põhineb
- BE
- sest
- olnud
- enne
- on
- alla
- kasu
- tooma
- ehitama
- ehitatud
- sisseehitatud
- kuid
- by
- CAN
- võimeid
- Võimsus
- lüüa
- kaart
- juhul
- juhtudel
- kataloog
- kategooriad
- CDC
- rakk
- muutma
- Vaidluste lahendamine
- kanalid
- Lapsed
- Valisin
- selgus
- Cloud
- Cluster
- kood
- Veerg
- Veerud
- Tulema
- tuleb
- tulevad
- kokkusobiv
- Nõuetele vastav
- komponendid
- Koosneb
- Arvutama
- Murettekitav
- seotud
- Arvestama
- kaaluda
- tarbitud
- tarbimine
- sisaldama
- kontekst
- jätkama
- kontrollida
- parandada
- kulud
- võiks
- riikides
- looma
- volikiri
- krediit
- krediitkaart
- kureeritud
- Praegune
- Kliendid
- andmed
- Andmete analüüs
- andmete integreerimine
- andmejärv
- Andmeplatvorm
- andmekaitse
- andmestrateegia
- andmebaas
- andmebaasid
- andmekogumid
- kuupäev
- päev
- vaikimisi
- määratletud
- esitatud
- näitama
- näitab
- lähetatud
- Disain
- sihtkoht
- sihtkohtadesse
- detailid
- avastama
- tuvastatud
- Detection
- Määrama
- & Tarkvaraarendus
- arendusmeeskonnad
- erinev
- otse
- avastama
- avastasin
- arutatud
- do
- domeen
- Domeenid
- Ära
- iga
- jõupingutusi
- Inseneriteadus
- tagama
- ettevõte
- ettevõtte kliendid
- Kogu
- üksuste
- keskkond
- Eeter (ETH)
- Isegi
- sündmused
- Iga
- näide
- näited
- oodatav
- kogemus
- väljendeid
- väline
- KIIRE
- Valdkonnad
- fail
- Faile
- finants-
- finantsteenused
- esimene
- Voolav
- Voolud
- keskendumine
- Järgneb
- Järel
- järgneb
- eest
- Raamistik
- Alates
- täis
- täielikult
- tulevik
- teeniva
- saama
- hea
- valitsemistava
- antud
- Varred
- Käsitsemine
- Olema
- he
- Tervis
- terviseinfo
- aitama
- aidates
- aitab
- kõrgetasemeline
- tema
- ajalooline
- Kuidas
- Kuidas
- HTML
- http
- HTTPS
- sajad
- identifitseerima
- if
- illustreerib
- kujutage ette
- rakendada
- tähtsus
- oluline
- in
- sisaldama
- Kaasa arvatud
- indeks
- eraldi
- info
- Infrastruktuur
- sees
- integratsioon
- sisemine
- sisse
- IT
- Java
- töö
- Tööturg
- jpg
- Json
- hoidma
- Kinesis Data Firehose
- Kinesise andmevood
- teatud
- järv
- maa
- maad
- suur
- viimane
- pärast
- Seadused
- Seadused ja määrused
- kiht
- kihid
- Juhtimine
- laskma
- Raamatukogu
- eluring
- nagu
- joon
- koormus
- laadimine
- kohad
- Vaata
- odava
- põhiline
- säilitamine
- tegema
- juhitud
- palju
- kaardistus
- mask
- mai..
- meetod
- meetodid
- rännanud
- ränne
- Kaasaegne
- kaasajastama
- järelevalve
- rohkem
- Mountain
- liikuma
- liikuv
- palju
- mitmekordne
- peab
- nimi
- nimed
- vajalik
- Vajadus
- vaja
- vajav
- vajadustele
- Holland
- Uus
- ei
- sõlmed
- Märka..
- nüüd
- number
- of
- Pakkumised
- on
- ONE
- ainult
- töö
- töökorras
- Operations
- optimeerimine
- Valikud
- or
- organisatsioon
- organisatsioonid
- Muu
- meie
- väljund
- väljaspool
- üle
- osa
- kirg
- Lappimine
- mustrid
- Maksma
- makse
- kohta
- täitma
- jõudlus
- Õigused
- Isiklikult
- telefon
- pii
- torujuhe
- kava
- inimesele
- Platon
- Platoni andmete intelligentsus
- PlatoData
- mängimine
- Punkt
- osa
- post
- eelnev
- esitatud
- eelmine
- privaatsus
- privaatsusseadused
- töödeldud
- Protsessid
- töötlemine
- tootja
- kaitstud
- protokollid
- tarnija
- annab
- Ostud
- päringud
- kiiresti
- pigem
- Töötlemata
- algandmed
- reaalajas
- põhjustel
- vastuvõtmine
- Retseptid
- soovitatav
- rekord
- andmed
- Lühendatud
- viitama
- regulaarne
- määrused
- usaldusväärsus
- jääma
- kõrvaldama
- Aruandlus
- Aruanded
- nõudma
- nõue
- Nõuded
- kohustused
- vastutav
- piirata
- Tulemused
- rollid
- ROW
- jooks
- jookseb
- SaaS
- ohverdama
- ohutu
- ohutult
- sama
- Skaala
- skaneerida
- ajakava
- teadlased
- Ekraan
- SDK
- Otsing
- Osa
- kindlalt
- turvalisus
- vaata
- valima
- väljavalitud
- vanem
- tundlik
- Saadetud
- teenus
- teenused
- lask
- peaks
- näidatud
- Näitused
- lihtne
- lihtsustama
- väike
- So
- sotsiaalmeedia
- tarkvara
- tarkvara
- lahendus
- Lahendused
- allikas
- Allikad
- konkreetse
- eriti
- määratletud
- kulutama
- Kulutused
- Poolitab
- etappidel
- Ühendriigid
- Samm
- ladustamine
- salvestada
- lihtne
- Strateegia
- oja
- streaming
- ojad
- nöör
- struktuur
- struktureeritud
- stuudio
- järgnev
- Edukalt
- selline
- sobiv
- Toetatud
- Toetamine
- süsteem
- süsteemid
- tabel
- võtab
- sihtmärk
- meeskond
- meeskonnad
- tehnikat
- tennis
- kümneid
- kui
- et
- .
- Tulevik
- Holland
- Allikas
- oma
- SIIS
- Seal.
- Need
- see
- need
- kolm
- künnis
- Läbi
- aeg
- et
- võttis
- töövahendid
- jälgida
- Tehingud
- üle
- ülekandeid
- Muutma
- Transformation
- Trends
- vallandas
- kaks
- tüüp
- liigid
- lõpuks
- aluseks
- mõistmine
- ühtne
- Ühendatud
- Ühendriigid
- us
- kasutama
- kasutage juhtumit
- Kasutatud
- Kasutajad
- kasutamine
- väärtus
- sort
- eri
- kaudu
- visuaalne
- kõndima
- oli
- kuidas
- we
- web
- veebiteenused
- M
- millal
- mis
- kuigi
- WHO
- naine
- will
- koos
- jooksul
- ilma
- Töö
- töövoog
- töö
- kirjutama
- sa
- Sinu
- sephyrnet