Sarnaste veergude leidmine punktist a andmete järv sisaldab olulisi rakendusi andmete puhastamisel ja märkimisel, skeemi sobitamisel, andmete tuvastamisel ja analüüsimisel mitmes andmeallikas. Suutmatus erinevatest allikatest pärit andmeid täpselt leida ja analüüsida kujutab endast potentsiaalset tõhususe tapjat kõigile, alates andmeteadlastest, meditsiiniteadlastest, akadeemikutest kuni finants- ja valitsuse analüütikuteni.
Tavapärased lahendused hõlmavad leksikaalset märksõnaotsingut või regulaaravaldiste sobitamist, mis on vastuvõtlikud andmete kvaliteediprobleemidele, nagu puuduvad veergude nimed või erinevad veergude nimetamise kokkulepped erinevates andmekogumites (nt zip_code, zcode, postalcode).
Selles postituses demonstreerime lahendust sarnaste veergude otsimiseks veeru nime, veeru sisu või mõlema põhjal. Lahendus kasutab ligikaudsed lähimate naabrite algoritmid saadaval Amazon OpenSearchi teenus semantiliselt sarnaste veergude otsimiseks. Otsingu hõlbustamiseks loome andmejärve üksikute veergude jaoks funktsioonide esitused (manustused), kasutades eelkoolitatud Transformeri mudeleid lausemuundurite raamatukogu in Amazon SageMaker. Lõpuks, et meie lahendusega suhelda ja selle tulemusi visualiseerida, loome interaktiivse Vooluvalgus veebirakendus töötab AWS Fargate.
Lisame a koodi õpetus et saaksite juurutada ressursse, et käitada lahendus näidisandmetel või oma andmetel.
Lahenduse ülevaade
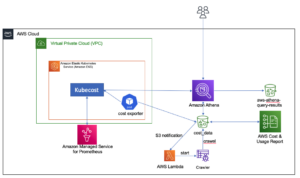
Järgmine arhitektuuriskeem illustreerib semantiliselt sarnaste veergude leidmise kaheetapilise töövoogu. Esimene etapp jookseb an AWS-i astmefunktsioonid töövoog, mis loob tabeliveergudest manuseid ja loob OpenSearch Service'i otsinguindeksi. Teine etapp ehk veebipõhine järeldusetapp käivitab Fargate'i kaudu Streamliti rakenduse. Veebirakendus kogub sisestatud otsingupäringud ja hangib OpenSearch Service'i indeksist päringule ligikaudsed k-kõige sarnasemad veerud.

Joonis 1. Lahenduse arhitektuur
Automatiseeritud töövoog toimub järgmiste sammudega.
- Kasutaja laadib tabelina olevad andmekogumid üles Amazoni lihtne salvestusteenus (Amazon S3) ämber, mis kutsub esile an AWS Lambda funktsioon, mis käivitab sammufunktsioonide töövoo.
- Töövoog algab tähega AWS liim töö, mis teisendab CSV-failid Apache parkett andmevormingus.
- SageMakeri töötlemistöö loob iga veeru jaoks manused, kasutades eelkoolitatud mudeleid või kohandatud veeru manustamismudeleid. SageMakeri töötlemistöö salvestab Amazon S3 iga tabeli veergude manused.
- Lambda-funktsioon loob OpenSearch Service'i domeeni ja klastri, et indekseerida eelmises etapis loodud veergude manuseid.
- Lõpuks juurutatakse Fargate'iga interaktiivne Streamliti veebirakendus. Veebirakendus pakub kasutajale liidest päringute sisestamiseks, et otsida OpenSearch Service'i domeenist sarnaseid veerge.
Koodiõpetuse saate alla laadida aadressilt GitHub proovida seda lahendust näidisandmete või oma andmete põhjal. Juhised selle õpetuse jaoks vajalike ressursside juurutamise kohta on saadaval aadressil Github.
Eeltingimused
Selle lahenduse rakendamiseks vajate järgmist.
- An AWS-i konto.
- Põhiteadmised AWS-i teenustega, nagu AWS pilvearenduskomplekt (AWS CDK), Lambda, OpenSearch Service ja SageMaker Processing.
- Tabeliandmekogum otsinguindeksi loomiseks. Saate tuua oma tabeliandmed või laadida alla näidisandmed GitHub.
Looge otsinguregister
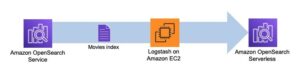
Esimeses etapis koostatakse veeru otsingumootori register. Järgmine joonis illustreerib sammufunktsioonide töövoogu, mis seda etappi käivitab.

Joonis 2 – Sammufunktsioonide töövoog – mitu manustamismudelit
Andmekogumid
Selles postituses koostame otsinguindeksi, mis sisaldab enam kui 400 veergu enam kui 25 tabeliandmestikust. Andmekogumid pärinevad järgmistest avalikest allikatest:
Indeksis sisalduvate tabelite täieliku loendi leiate koodiõpetusest GitHub.
Näidisandmete täiendamiseks või oma otsinguindeksi loomiseks saate kaasa võtta oma tabeliandmestiku. Lisame kaks Lambda funktsiooni, mis käivitavad Step Functions töövoo, et luua vastavalt üksikute CSV-failide või CSV-failide partii otsinguindeks.
Muuda CSV parketiks
Toores CSV-failid teisendatakse AWS-liimi abil Parketi andmevormingusse. Parkett on suurandmete analüüsis eelistatud veerule orienteeritud vormingus failivorming, mis tagab tõhusa tihendamise ja kodeerimise. Meie katsetes vähendas Parketi andmevorming salvestusmahtu oluliselt võrreldes töötlemata CSV-failidega. Kasutasime Parketi ka tavalise andmevorminguna muude andmevormingute (nt JSON ja NDJSON) teisendamiseks, kuna see toetab täiustatud pesastatud andmestruktuure.
Looge tabelite veergude manused
Selle postituse tabelinäidiste andmekogumite üksikute tabeli veergude manustuste eraldamiseks kasutame järgmisi eelkoolitatud mudeleid sentence-transformers raamatukogu. Täiendavate mudelite kohta vt Eelkoolitatud modellid.
SageMakeri töötlemistöö käivitub create_embeddings.py(kood) ühe mudeli jaoks. Manustuste eraldamiseks mitmest mudelist käitab töövoog paralleelselt SageMakeri töötlemistöid, nagu on näidatud etapifunktsioonide töövoos. Kasutame mudelit kahe manustamiskomplekti loomiseks:
- veeru_nimi_manused – veergude nimede (päiste) manustamine
- veeru_sisu_manused – kõigi veeru ridade keskmine manustamine
Veeru manustamise protsessi kohta lisateabe saamiseks vaadake koodiõpetust GitHub.
SageMakeri töötlemisetapi alternatiiviks on luua SageMakeri pakkteisendus, et saada veergude manustamist suurtele andmehulkadele. See nõuaks mudeli juurutamist SageMakeri lõpp-punktis. Lisateabe saamiseks vt Kasutage partii teisendust.
Manustamise indekseerimine OpenSearchi teenusega
Selle etapi viimases etapis lisab Lambda funktsioon veeru manustused OpenSearch Service ligikaudsele k-lähimale naabrile (kNN) otsinguindeks. Igale mudelile on määratud oma otsinguregister. Lisateabe saamiseks ligikaudsete kNN-i otsinguindeksi parameetrite kohta vt k-NN.
Veebipõhised järeldused ja semantiline otsing veebirakendusega
Töövoo teine etapp jookseb a Vooluvalgus veebirakendus, kus saate sisestada ja otsida semantiliselt sarnaseid OpenSearch Service'is indekseeritud veerge. Rakenduskiht kasutab an Rakenduse koormuse tasakaalustaja, Fargate ja Lambda. Rakenduste infrastruktuur juurutatakse automaatselt lahenduse osana.
Rakendus võimaldab teil sisestada ja otsida semantiliselt sarnaseid veergude nimesid, veeru sisu või mõlemat. Lisaks saate otsingust naasmiseks valida manustamismudeli ja lähimate naabrite arvu. Rakendus võtab vastu sisendeid, manustab sisendi määratud mudeliga ja kasutab kNN-i otsing OpenSearch Service'is indekseeritud veergude manuste otsimiseks ja antud sisendiga kõige sarnasemate veergude leidmiseks. Kuvatavad otsingutulemused sisaldavad tuvastatud veergude tabelinimesid, veergude nimesid ja sarnasusskoore, samuti Amazon S3 andmete asukohti edasiseks uurimiseks.
Järgmine joonis näitab veebirakenduse näidet. Selles näites otsisime oma andmejärvest sarnaseid veerge Column Names (kasuliku koorma tüüp) Kuni district (kasulik koormus). Kasutatud rakendus all-MiniLM-L6-v2 kui manustamismudel ja naasis 10 (k) lähimad naabrid meie OpenSearch Service'i registrist.
Taotlus tagastati transit_district, city, boroughja location kui neli kõige sarnasemat veergu, mis põhinevad OpenSearch Service'is indekseeritud andmetel. See näide demonstreerib otsingu lähenemisviisi võimet tuvastada semantiliselt sarnaseid veerge andmekogumites.

Joonis 3: Veebirakenduse kasutajaliides
Koristage
Selles õpetuses AWS CDK loodud ressursside kustutamiseks käivitage järgmine käsk:
cdk destroy --allJäreldus
Selles postituses tutvustasime täielikku töövoogu tabeliveergude semantilise otsingumootori loomiseks.
Alustage juba täna oma andmetega meie koodiõpetuse abil, mis on saadaval aadressil GitHub. Kui soovite abi ML-i kasutamise kiirendamisel oma toodetes ja protsessides, võtke ühendust Amazoni masinõppelahenduste labor.
Autoritest
![]() Kachi Odoemene on AWS AI rakendusteadlane. Ta ehitab AI/ML-lahendusi, et lahendada AWS-i klientide äriprobleeme.
Kachi Odoemene on AWS AI rakendusteadlane. Ta ehitab AI/ML-lahendusi, et lahendada AWS-i klientide äriprobleeme.
![]() Taylor McNally on Amazon Machine Learning Solutions Labi süvaõppe arhitekt. Ta aitab klientidel erinevatest tööstusharudest luua lahendusi, mis kasutavad AI/ML-i AWS-is. Ta naudib tassi head kohvi, õues olemist ning pere ja energilise koeraga koosolemist.
Taylor McNally on Amazon Machine Learning Solutions Labi süvaõppe arhitekt. Ta aitab klientidel erinevatest tööstusharudest luua lahendusi, mis kasutavad AI/ML-i AWS-is. Ta naudib tassi head kohvi, õues olemist ning pere ja energilise koeraga koosolemist.
![]() Austin Welch on andmeteadlane Amazon ML Solutions Labis. Ta töötab välja kohandatud süvaõppemudeleid, et aidata AWS-i avaliku sektori klientidel kiirendada nende tehisintellekti ja pilve kasutuselevõttu. Vabal ajal naudib ta lugemist, reisimist ja jiu-jitsut.
Austin Welch on andmeteadlane Amazon ML Solutions Labis. Ta töötab välja kohandatud süvaõppemudeleid, et aidata AWS-i avaliku sektori klientidel kiirendada nende tehisintellekti ja pilve kasutuselevõttu. Vabal ajal naudib ta lugemist, reisimist ja jiu-jitsut.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- Platoblockchain. Web3 metaversiooni intelligentsus. Täiustatud teadmised. Juurdepääs siia.
- Allikas: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- võime
- MEIST
- puudub
- kiirendama
- kiirendades
- täpselt
- üle
- Täiendavad lisad
- Lisaks
- Lisab
- Vastuvõtmine
- edasijõudnud
- AI
- AI / ML
- Materjal: BPA ja flataatide vaba plastik
- võimaldab
- alternatiiv
- Amazon
- Amazoni masinõpe
- Amazon ML Solutions Lab
- Analüütikud
- analytics
- analüüsima
- ja
- Apache
- taotlus
- rakendused
- rakendatud
- lähenemine
- arhitektuur
- määratud
- Automatiseeritud
- automaatselt
- saadaval
- keskmine
- AWS
- AWS liim
- põhineb
- sest
- Suur
- Big andmed
- tooma
- ehitama
- Ehitus
- Ehitab
- äri
- puhastamine
- Cloud
- pilve adopteerimine
- Cluster
- kood
- Kohv
- kogub
- Veerg
- Veerud
- ühine
- võrreldes
- kontakt
- sisu
- Konventsioonid
- muutma
- ümber
- looma
- loodud
- loob
- Tass
- tava
- Kliendid
- andmed
- Andmete analüüs
- andmejärv
- andmete kvaliteedi
- andmeteadlane
- andmekogumid
- sügav
- sügav õpe
- näitama
- näitab
- juurutada
- lähetatud
- juurutamine
- hävitama
- & Tarkvaraarendus
- arendab
- erinev
- avastus
- erinevad
- mitu
- koer
- domeen
- lae alla
- iga
- efektiivsus
- tõhus
- Lõpuks-lõpuni
- Lõpp-punkt
- Mootor
- Eeter (ETH)
- igaüks
- näide
- uurimine
- väljavõte
- hõlbustada
- Tuttav
- pere
- FUNKTSIOONID
- Joonis
- fail
- Faile
- lõplik
- Lõpuks
- finants-
- leidma
- leidmine
- esimene
- Järel
- formaat
- Alates
- täis
- funktsioon
- funktsioonid
- edasi
- saama
- antud
- hea
- Valitsus
- päised
- aitama
- aitab
- Kuidas
- Kuidas
- HTML
- HTTPS
- tuvastatud
- identifitseerima
- rakendada
- oluline
- in
- võimetus
- sisaldama
- lisatud
- indeks
- eraldi
- tööstusharudes
- info
- Infrastruktuur
- algatama
- Algatab
- sisend
- juhised
- suhelda
- interaktiivne
- Interface
- kutsub
- kaasama
- küsimustes
- IT
- töö
- Tööturg
- Json
- labor
- järv
- suur
- kiht
- õppimine
- võimendav
- Raamatukogu
- nimekiri
- koormus
- kohad
- masin
- masinõpe
- sobitamine
- meditsiini-
- ML
- mudel
- mudelid
- rohkem
- kõige
- mitmekordne
- nimi
- nimed
- nimetamine
- Vajadus
- naabrid
- number
- pakutud
- Internetis
- Muu
- väljas
- enda
- Parallel
- parameetrid
- osa
- Platon
- Platoni andmete intelligentsus
- PlatoData
- palun
- post
- potentsiaal
- eelistatud
- esitatud
- eelmine
- probleeme
- tulu
- protsess
- Protsessid
- töötlemine
- Toodetud
- Toodet
- anda
- annab
- avalik
- kvaliteet
- Töötlemata
- Lugemine
- saab
- regulaarne
- esindab
- nõudma
- nõutav
- Teadlased
- Vahendid
- vastavalt
- Tulemused
- tagasipöördumine
- jooks
- jooksmine
- salveitegija
- teadlane
- teadlased
- Otsing
- otsingumootor
- otsimine
- Teine
- sektor
- teenus
- Teenused
- Komplektid
- näidatud
- Näitused
- märkimisväärne
- sarnane
- lihtne
- ühekordne
- SUURUS
- lahendus
- Lahendused
- LAHENDAGE
- Allikad
- määratletud
- Stage
- alustatud
- Samm
- Sammud
- ladustamine
- selline
- Toetab
- vastuvõtlik
- tabel
- .
- oma
- Läbi
- aeg
- et
- täna
- Muutma
- trafod
- Reisimine
- juhendaja
- kasutama
- Kasutaja
- Kasutajaliides
- eri
- web
- Veebirakendus
- mis
- töövoog
- oleks
- Sinu
- sephyrnet