January 29 is National Puzzle Day, and in celebration, we’ve created a fun blog that details how to solve Sudoku using artificial intelligence (AI).
Sissejuhatus
enne sõnasõna, Sudoku pusle oli raev ja see on siiani väga populaarne. Viimastel aastatel on kasutatud optimeerimine mõistatuse lahendamise meetodid on olnud domineeriv teema. Vaata Sudoku mõistatuse lahendamine optimeerimise abil Arkievas".
In current times, the use of AI is focused on machine learning which encompasses a wide range of methods from lasso regression to reinforcement learning. The use of AI has tekkis uuesti komplekside lahendamiseks planeerimine väljakutseid. Tavaliselt kasutatakse ühte meetodit, otsimist tagasiteel, ja see sobib suurepäraselt Sudoku jaoks.
See ajaveeb annab üksikasjaliku kirjelduse selle meetodi kasutamise kohta Sudoku lahendamiseks. Nagu selgub, võib "tagasijätmist" leida optimeerimis- ja masinõppemootorites ning see on Arkieva poolt ajakava koostamiseks kasutatava täiustatud heuristika nurgakivi. Algoritm on rakendatud massiivi programmeerimiskeeles, funktsioonile orienteeritud programmeerimiskeeles, mis käsitleb rikkalik massiivistruktuuride komplekt.
Sudoku põhitõed
Vikipeedia keeles: Sudoku on loogikal põhinev kombineeritud arvude paigutuse mõistatus. Eesmärk on täita 9 × 9 ruudustik numbritega nii, et iga veerg, iga rida ja kõik üheksa 3 × 3 alamruudustikku, mis moodustavad ruudustiku (nimetatakse ka "kastideks", "plokkideks", "piirkondadeks", või alamruudud) sisaldab kõiki numbreid 1 kuni 9. Mõistatuse seadja pakub osaliselt täidetud ruudustikku, millel on tavaliselt ainulaadne lahendus. Lõpetatud mõistatused on alati teatud tüüpi ladina ruudud, mis piiravad üksikute piirkondade sisu. Näiteks ei pruugi sama täisarv esineda kaks korda samas 9 × 9 mängulaua real või veerus või üheski 3 × 3 mängulaua üheksast 9 × 9 alampiirkonnast.
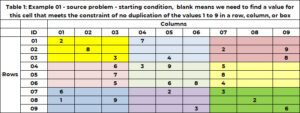
Tabelis 1 on näide probleemist. Seal on 9 rida ja 9 veergu kokku 81 lahtri jaoks. Igal neist võib olla üks ja ainult üks üheksast täisarvust vahemikus 1 kuni 9. Alglahenduses on lahtril kas üks väärtus – mis fikseerib selle lahtri väärtuse sellele väärtusele, või on lahter tühi, mis näitab, et meil on vaja selle lahtri väärtuse leidmiseks. Lahtri (1,1) väärtus on 2 ja lahtri (6,5) väärtus 6. Lahter (1,2) ja lahter (2,3) on tühjad ning algoritm leiab nende lahtrite jaoks väärtuse.
Komplikatsioon
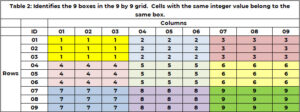
Lisaks sellele, et lahter kuulub ühte ja ainult ühte rida ja veergu, kuulub lahter ühte ja ainult ühte kasti. Kaste on 1 ja need on tabelis 9 tähistatud värviga. Tabel 1 kasutab iga kasti või ruudustiku tuvastamiseks ainulaadset täisarvu vahemikus 2 kuni 1. Lahtrid reaväärtusega (9, 1 või 2) ja veeru väärtusega (3, 1 või 2) kuuluvad kasti 3. Lahtris 1 on rea väärtused (6, 4, 5) ja veeru väärtused (6, 7) , 8). Kasti ID määratakse valemiga BOX_ID = {9x(põrand((ROW_ID-3) /1)} + lagi (COL_ID/3). Lahtri (3) puhul 5,7 = 6x(põrand(3-5) ))/1) + lagi (3/8)= 3×3 + 1 = 3+3.
Mõistatuse süda
Et leida iga tundmatu lahtri jaoks üks täisarv vahemikus 1 kuni 9, nii et täisarve 1 kuni 9 kasutatakse iga veeru, iga rea ja iga kasti jaoks ainult üks kord.
Vaatame lahtrit (1,3), mis on tühi. 1. real on juba väärtused 2 ja 7. Need pole selles lahtris lubatud. 3. veerus on juba väärtused 3, 5,6, 7,9. Need ei ole lubatud. Lahtris 1 (kollane) on väärtused 2, 3 ja 8. Need ei ole lubatud. Järgmised väärtused ei ole lubatud (2,7); (3, 5, 6, 7, 9); (2, 3, 8). Lubatud unikaalsed väärtused on (2, 3, 5, 6, 7, 8, 9). Ainsad kandidaatväärtused on (1,4).
Üks lahendus oleks määrata lahtrile (1, 1,3) ajutiselt XNUMX ja seejärel proovida leida teise lahtri kandidaatväärtusi.
Lahendus tagasilöömiseks: komponentide käivitamine
Massiivi struktuur
Lähtekohaks on valida massiivi struktuur, mis salvestab lähteprobleemi ja toetab otsingut. Tabelis 3 on selline massiivi struktuur. 1. veerg on iga lahtri kordumatu täisarv. Väärtused on vahemikus 1 kuni 81. 2. veerg on lahtri rea ID. 3. veerg on lahtri veeru ID. 4. veerg on kasti ID. Veerg 5 on väärtus lahtris. Vaatlemine ilma väärtuseta lahtrile antakse tühja või nulli asemel väärtus null. See hoiab seda "ainult täisarvude massiivina" – jõudluse osas palju parem.

APL-is salvestatakse see massiiv 2-mõõtmelises massiivis, mille kuju on 81 x 5. Oletame, et tabeli 3 elemendid on salvestatud muutujasse MAT. Funktsioonide näide on:
Käsk MAT[1 2 3;] haarab MAT 3 esimest rida
1 1 1 1 2
2 1 2 1 0
3 1 3 1 0
MAT[1 2 3; 4 5] kindlustab read 1, 2, 3 ja ainult veerud 4 ja 5
1
1
1
(MAT[;5]=0)/MAT[;1] leiab kõik väärtust vajavad lahtrid.
LISAGE TABEL 3
Terve mõistuse kontroll: duplikaadid
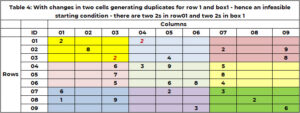
Enne otsingu alustamist on oluline kontrollida mõistust! See on lähtelahendus teostatav. Sudoku jaoks teostatav, kas igas reas, veerus või kastis on nüüd duplikaate. Praegune lähtelahendus, näiteks 1, on teostatav. Tabelis 4 on näide, kus lähtelahendusel on duplikaadid. 1. real on kaks väärtust 2. Alal 1 on kaks väärtust 2. Funktsioon "SANITY_DUPE" käsitleb seda loogikat.
Terve mõistuse kontroll: suvandid väärtusteta lahtrite jaoks
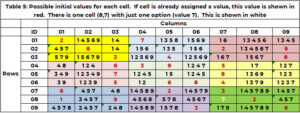
Väga kasulik teave oleks ilma väärtuseta lahtri kõik võimalikud väärtused. Kui kandidaate pole, siis see mõistatus ei ole lahendatav. Lahter ei saa omandada väärtust, mida tema naaber juba taotleb. Kasutades lahtri jaoks tabelit 1 (1,3, '1' – see viimane 1 on kast), on selle naabriteks rida 1, veerg 3 ja kast 1. Reas 1 on väärtused (2,7); veerus 3 on väärtused (3,5,6,7,9); kastis 1 on väärtused (2,3,8). Lahter (1,3.1) ei saa võtta järgmisi väärtusi (2,3,5,6,7,8,9). Lahtri (1,3,1) ainsad valikud on (1,4). Lahtri (4,1,2) jaoks on väärtused 1, 2, 3, 5, 6, 7, 9 juba kasutusel 4. reas, 1. veerus ja/või kastis 4. Ainsad kandidaatväärtused on (4,8) . Jaotis "SANITY_CAND" käsitleb seda loogikat.
Tabelis 5 on näidatud kandidaadid, näiteks 1 otsinguprotsessi alguses. Kui lahtrile on lähtetingimustes juba väärtus määratud (tabel 1), siis seda väärtust korratakse ja näidatakse punaselt. Kui väärtust vajaval lahtril on ainult üks valik, kuvatakse see valgena. Lahtri (8,7,9, 7, 2,5,8,4,3) üks väärtus 7 on valge. (1) on nõutud naaberveeru 2 järgi. (9, 8, 3,2,6) rea 9 järgi. (7) kasti XNUMX järgi. Ainult väärtus XNUMX on nõudmata.
Terve mõistuse kontroll: konfliktide otsimine
Teave, mis tuvastab kõiki väärtust vajavate lahtrite valikuid (postitatud tabelis 4), võimaldab meil enne otsinguprotsessi alustamist tuvastada konflikti. Konflikt tekib siis, kui kahel väärtust vajaval lahtril on ainult üks kandidaat, kandidaatväärtus on sama ja kaks lahtrit on naabrid. Tabelist 4 teame, et ainus lahter, mis vajab väärtust ja millel on ainult üks kandidaat, on lahter (8,7,9). Näiteks 1 pole konflikti.
Mis oleks konflikt? Kui lahtri (3,7,3) ainus võimalik väärtus oli 7 (1, 6, 7 asemel), siis on konflikt. Lahter (8,7) ja lahter (3,7) on naabrid – sama veerg. Kui aga lahtri (4,9,2) ainus võimalik väärtus oleks 7 (1, 2, 7 asemel), ei oleks see konflikt. Need rakud ei ole naabrid.
Terve mõistuse kontrolli kokkuvõte
- Duplikaatide olemasolul pole lähtelahendus teostatav.
- Kui lahtril, mis vajab väärtust, pole kandidaate, pole sellele mõistatusele võimalikku lahendust. Iga lahtri kandidaatväärtuste loendit saab kasutada otsinguruumi vähendamiseks – nii tagasisuunamiseks kui ka optimeerimiseks.
- Konfliktide leidmise võime tuvastab, et mõistatus pole ilma otsinguprotsessita teostatav – puudub lahendus. Lisaks tuvastab see "probleemsed rakud".
Tagasipöördumislahendus: otsinguprotsess
Kuna põhiandmestruktuurid ja mõistuse kontroll on paigas, pöörame tähelepanu otsinguprotsessile. Korduv teema on jällegi otsingut toetavate andmestruktuuride paika panemine.
Otsingu jälgimine
Massiiv Jälitaja peab arvet tehtud ülesannete üle
- 1. veerg on loendur
- 2. veerg on sellele lahtrile määratavate valikute arv
- 1 tähendab, et saadaval on 1 valik, 2 tähendab kahte võimalust jne.
- 0 tähendab – valikut pole saadaval või lähtestamine 0-le (määratud väärtus puudub) ja tagasiliikumine
- 3. veerg on lahter, millele on määratud väärtuse indeksi number (1 kuni 81)
- 4. veerg on raja ajaloos lahtrile määratud väärtus
- Väärtus 9999 tähendab, et see lahter oli siis, kui ummik leiti
- Täisarvu väärtus vahemikus 1 kuni 9 (kaasa arvatud) on sellele lahtrile antud otsinguprotsessi hetkel määratud väärtus.
- Väärtus 0 tähendab, et see lahter vajab määramist
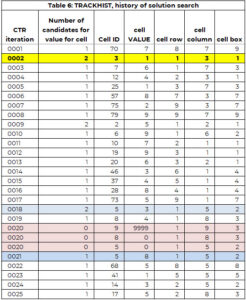
Jälgimismassiivi kasutatakse otsinguprotsessi toetamiseks. Massiiv TRACKHIIST on sama struktuuriga kui jälgijal, kuid säilitab kogu otsinguprotsessi ajaloo. Tabelis 6 on osa näiteks TRACKHISTist 1. Seda selgitatakse üksikasjalikumalt hilisemas osas.
Lisaks massiiv PAV (vektori vektor), jälgib sellele lahtrile varem määratud väärtusi. See tagab, et me ei vaata ebaõnnestunud lahendust uuesti – sarnaselt sellega, mida tehakse TABU-s.
Valikuline logiprotsess, kus otsinguprotsess kirjutab välja iga sammu.
Otsingu alustamine
Kui raamatupidamine ja mõistuse kontroll on tehtud, saame nüüd alustada otsinguprotsessi. Toimingud on järgmised:
- Kas on jäänud lahtreid, mis vajavad väärtust? – kui ei, siis oleme valmis.
- Iga väärtust vajava lahtri jaoks leidke iga lahtri jaoks kõik kandidaatvalikud. Tabelis 4 on need väärtused lahendusprotsessi alguses. Iga iteratsiooni korral värskendatakse seda lahtritele määratud väärtuste jaoks.
- Hinnake valikuid selles järjekorras.
- Kui lahtril on NULL valikut, käivitage tagasiminek
- Otsige üles kõik ühe valikuga lahtrid, valige üks nendest lahtritest, tehke see ülesanne,
- ja värskendage jälgimistabelit, praegust lahendust ja PAV-i.
- Kui kõigil lahtritel on rohkem kui üks valik, valige üks lahter ja üks väärtus ning värskendage
- ja värskendage jälgimistabelit, praegust lahendust ja PAV-i
Iga sammu illustreerimiseks kasutame tabelit 6, mis on osa lahendusprotsessi ajaloost (nimega TRACKHIST).
Esimeses iteratsioonis (CTR=1) valitakse väärtuse määramiseks lahter 70 (rida 8, veerg 7, kast 9). On just kandidaat (7) ja see väärtus määratakse lahtrile 70. Lisaks lisatakse väärtus 7 lahtri 70 varem määratud väärtuste (PAV) vektorile.
Teises iteratsioonilahtris 30 omistatakse väärtus 1. Sellel lahtril oli kaks kandidaatväärtust. Lahtrile määratakse väikseim kandidaadiväärtus (lihtsalt suvaline reegel, et loogikat oleks lihtne järgida).
Väärtust vajava lahtri tuvastamise ja väärtuse määramise protsess toimib hästi kuni iteratsioonini (CTR) 20. Lahter 9 vajab väärtust, kuid kandidaatide arv on NULL. On kaks võimalust.
- Sellel mõistatusel pole lahendust.
- Me tühistame (tagasime) mõned ülesanded ja võtame teise tee.
Otsisime sellele lähima lahtri määramise, kus oli rohkem kui üks võimalus. Selles näites juhtus see iteratsioonil 18, kus lahtrile 5 on määratud väärtus 3, kuid lahtri 5 jaoks oli kaks kandidaatväärtust – väärtused 3 ja 8.
Lahtri 5 (CTR = 18) ja 9 (CTR = 20) vahel omistatakse lahtrile 8 väärtus 4 (CTR = 19). Panime lahtrid 8 ja 5 tagasi loendisse "vaja on väärtust". See salvestatakse teises ja kolmandas CTR=20 kirjes, kus väärtuseks on seatud 0. Väärtust 3 säilitatakse lahtri 5 PAV-vektoris. See tähendab, et otsingumootor ei saa määrata lahtrile 3 väärtust 5.
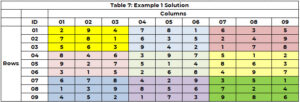
Otsingumootor käivitub uuesti, et tuvastada lahtri 5 väärtus (kus 3 pole enam võimalik) ja määrab lahtrile 8 väärtuse 5 (CTR=21). See jätkub seni, kuni kõigil lahtritel on väärtus või on lahter, millel pole valikut ja tagasiteed pole. Lahendus on avaldatud tabelis 7.
Pange tähele, kui lahtrisse on rohkem kui üks kandidaat, on see võimalus paralleelseks töötlemiseks.
Võrdlus MILP optimeerimislahendusega
Pinnatasandil on Sudoku pusle esitus dramaatiliselt erinev. AI-lähenemine kasutab täisarve ja on mis tahes mõõdiku järgi tihedam ja intuitiivsem esitus. Lisaks pakuvad mõistuse kontrollijad kasulikku teavet tugevama koostise loomiseks. MILP-i esitus on lõputu binaarfailid (0/1). Arvestades tänapäevaste MILP-lahendajate tugevust, on kahendkoodid aga võimsad esitused.
Kuid sisemiselt ei säilita MILP-lahendaja binaarfaile, vaid kasutab kõigi nullide salvestamise välistamiseks hõreda massiivi meetodit. Lisaks tekkisid binaarfailide lahendamise algoritmid alles 1980. ja 1990. aastatel. 1983. aasta leht Crowder, Johnson ja Padberg aruanded ühest esimesest praktilisest binaarfailidega optimeerimise lahendusest. Nad märgivad nutika eeltöötluse ning haru- ja sidumismeetodite tähtsust, mis on eduka lahenduse jaoks üliolulised.
Hiljutine plahvatuslik piirangute programmeerimine ja tarkvara, nagu näiteks kohalik lahendaja on teinud selgeks tehisintellekti meetodite kasutamise olulisuse algsete optimeerimismeetoditega, nagu lineaarne programmeerimine ja vähimruutud.
- SEO-põhise sisu ja PR-levi. Võimenduge juba täna.
- PlatoData.Network Vertikaalne generatiivne Ai. Jõustage ennast. Juurdepääs siia.
- PlatoAiStream. Web3 luure. Täiustatud teadmised. Juurdepääs siia.
- PlatoESG. Süsinik, CleanTech, Energia, Keskkond päikeseenergia, Jäätmekäitluse. Juurdepääs siia.
- PlatoTervis. Biotehnoloogia ja kliiniliste uuringute luureandmed. Juurdepääs siia.
- Allikas: https://blog.arkieva.com/an-artificial-intelligence-based-solution-to-sudoku/?utm_source=rss&utm_medium=rss&utm_campaign=an-artificial-intelligence-based-solution-to-sudoku
- :on
- :on
- :mitte
- : kus
- $ UP
- 1
- 20
- 29
- 30
- 31
- 600
- 7
- 70
- 8
- 9
- a
- võime
- majutada
- lisatud
- lisamine
- Täiendavad lisad
- Lisaks
- edasijõudnud
- jälle
- AI
- algoritm
- algoritme
- Materjal: BPA ja flataatide vaba plastik
- lubatud
- juba
- Ka
- alati
- Amazon
- an
- ja
- Teine
- mistahes
- ilmuma
- lähenemine
- omavoliline
- OLEME
- PIIRKOND
- Array
- kunstlik
- tehisintellekti
- Tehisintellekt (AI)
- AS
- määratud
- eeldab
- At
- tähelepanu
- saadaval
- tagasi
- BE
- olnud
- enne
- kuulumine
- kuulub
- vahel
- tühi
- Blogi
- juhatus
- mõlemad
- seotud
- Kast
- karbid
- Filiaal
- kuid
- by
- kutsutud
- CAN
- kandidaat
- kandidaadid
- ei saa
- pildistatud
- lagi
- Pidu
- rakk
- Rakke
- väljakutseid
- võimalus
- kontrollima
- kontroll
- väitis
- selge
- värv
- Veerg
- Veerud
- tavaliselt
- Lõpetatud
- keeruline
- Tingimused
- konflikt
- Konfliktid
- sisaldab
- sisu
- pidev
- tuum
- nurgakivi
- loodud
- kriitiline
- Praegune
- andmed
- päev
- surnud
- otsustama
- kirjeldus
- detail
- üksikasjalik
- detailid
- kindlaksmääratud
- erinev
- numbrit
- do
- ei
- domineeriv
- tehtud
- Ära
- dramaatiliselt
- duplikaadid
- iga
- lihtne
- kumbki
- elemendid
- kõrvaldama
- tekkima
- võimaldab
- hõlmab
- lõpp
- Lõputu
- Mootor
- Mootorid
- tagab
- Kogu
- jms
- näide
- selgitas
- plahvatus
- Ebaõnnestunud
- kaugele
- teostatav
- täitma
- leidma
- leiab
- lõpp
- esimene
- parandused
- keskendunud
- järgima
- Järel
- eest
- valem
- sõnastus
- avastatud
- Alates
- lõbu
- funktsioon
- funktsioonid
- saamine
- antud
- võre
- olnud
- Varred
- Olema
- süda
- kasulik
- ajalugu
- Kuidas
- Kuidas
- aga
- HTML
- HTTPS
- ID
- identifitseerib
- identifitseerima
- identifitseerimiseks
- if
- Illustreerima
- rakendatud
- tähtsus
- in
- Kaasa arvatud
- indeks
- osutatud
- Näitab
- eraldi
- info
- teatab
- sees
- selle asemel
- Instituut
- Intelligentsus
- sisemiselt
- intuitiivne
- IT
- iteratsioon
- ITS
- Johnson
- jpg
- lihtsalt
- hoidma
- hoitakse
- Teadma
- keel
- viimane
- pärast
- ladina
- õppimine
- kõige vähem
- lahkus
- Tase
- sirgjooneline
- nimekiri
- logi
- loogika
- enam
- Vaata
- Vaatasin
- otsin
- masin
- masinõpe
- tehtud
- tegema
- max laiuse
- mai..
- vahendid
- mõõtma
- meetod
- meetodid
- Kaasaegne
- rohkem
- riiklik
- Vajadus
- vajadustele
- naabrid
- üheksa
- ei
- meeles
- nüüd
- number
- eesmärk
- jälgima
- toimunud
- of
- on
- kunagi
- ONE
- ainult
- optimeerimine
- valik
- Valikud
- or
- et
- originaal
- meie
- välja
- Paber
- Parallel
- osa
- tee
- täiuslik
- jõudlus
- tükk
- Koht
- Platon
- Platoni andmete intelligentsus
- PlatoData
- mängimine
- Punkt
- populaarne
- võimalik
- postitanud
- võimas
- Praktiline
- varem
- Probleem
- protsess
- töötlemine
- Programming
- anda
- annab
- panema
- mõistatus
- Pusled
- Raev
- valik
- hiljuti
- korduv
- Red
- vähendama
- piirkondades
- regressioon
- tugevdamise õppimine
- korduv
- Aruanded
- esindamine
- ROW
- Eeskiri
- sama
- planeerimine
- Otsing
- otsingumootor
- Teine
- Osa
- Tagab
- vaata
- valima
- väljavalitud
- komplekt
- kuju
- näidatud
- Näitused
- sarnane
- ühekordne
- So
- tarkvara
- lahendus
- Lahendused
- LAHENDAGE
- mõned
- allikas
- Ruum
- ruut
- väljakud
- algus
- Käivitus
- algab
- Samm
- Sammud
- Veel
- salvestada
- ladustatud
- tugevus
- tugevam
- struktuur
- struktuuride
- edukas
- selline
- parem
- toetama
- Pind
- tabel
- lahendada
- Võtma
- kui
- et
- .
- Allikas
- teema
- SIIS
- Seal.
- Need
- nad
- Kolmas
- see
- tihedam
- korda
- et
- Summa
- jälgida
- Jälgimine
- püüdma
- Pöörake
- lülitub
- Kaks korda
- kaks
- tüüp
- tüüpiliselt
- ainulaadne
- tundmatu
- kuni
- Värskendused
- ajakohastatud
- us
- kasutama
- Kasutatud
- kasutusalad
- kasutamine
- väärtus
- Väärtused
- muutuja
- väga
- oli
- we
- olid
- M
- Mis on
- millal
- mis
- valge
- lai
- Lai valik
- Wikipedia
- will
- koos
- ilma
- töötab
- oleks
- aastat
- kollane
- sephyrnet
- null