Creemos que la IA generativa tiene el potencial de transformar con el tiempo prácticamente todas las experiencias de los clientes que conocemos. La cantidad de empresas que lanzan aplicaciones de IA generativa en AWS es sustancial y está aumentando rápidamente, incluidas adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy y LexisNexis Legal & Professional, por nombrar solo algunas. Nuevas empresas innovadoras como Perplexity AI están apostando por AWS en busca de IA generativa. Empresas líderes en inteligencia artificial como Anthropic han seleccionado a AWS como su principal proveedor de nube para cargas de trabajo de misión crítica y el lugar para entrenar sus modelos futuros. Y los proveedores globales de servicios y soluciones como Accenture están aprovechando los beneficios de las aplicaciones de IA generativa personalizadas a medida que empoderan a sus desarrolladores internos con Código de Amazon Whisperer.
Estos clientes eligen AWS porque estamos enfocados en hacer lo que siempre hemos hecho: adoptar tecnología compleja y costosa que puede transformar las experiencias de los clientes y los negocios y democratizarla para clientes de todos los tamaños y capacidades técnicas. Para hacer esto, estamos invirtiendo e innovando rápidamente para brindar el conjunto más completo de capacidades en las tres capas de la pila de IA generativa. La capa inferior es la infraestructura para entrenar modelos de lenguaje grande (LLM) y otros modelos básicos (FM) y producir inferencias o predicciones. La capa intermedia ofrece fácil acceso a todos los modelos y herramientas que los clientes necesitan para crear y escalar aplicaciones de IA generativa con la misma seguridad, control de acceso y otras características que los clientes esperan de un servicio de AWS. Y en la capa superior, hemos estado invirtiendo en aplicaciones innovadoras en áreas clave como la codificación generativa basada en IA. Además de ofrecerles opciones y, como esperan de nosotros, amplitud y profundidad de capacidades en todas las capas, los clientes también nos dicen que aprecian nuestro enfoque basado en los datos y confían en que hemos construido todo desde cero con soluciones empresariales. seguridad y privacidad de primer nivel.
Esta semana dimos un gran paso adelante al anunciar muchas capacidades nuevas e importantes en las tres capas de la pila para que a nuestros clientes les resulte fácil y práctico utilizar la IA generativa de manera generalizada en sus negocios.

Capa inferior de la pila: AWS Trainium2 es la última incorporación que ofrece la infraestructura de nube más avanzada para la IA generativa.
La capa inferior de la pila es la infraestructura (cómputo, redes, marcos, servicios) necesaria para capacitar y ejecutar LLM y otros FM. AWS innova para ofrecer la infraestructura más avanzada para ML. A través de nuestra colaboración de larga data con NVIDIA, AWS fue el primero en llevar GPU a la nube hace más de 12 años y, más recientemente, fuimos el primer proveedor importante de nube en ofrecer GPU NVIDIA H100 con nuestras instancias P5. Seguimos invirtiendo en innovaciones únicas que hacen de AWS la mejor nube para ejecutar GPU, incluidos los beneficios de precio-rendimiento del sistema de virtualización más avanzado (AWS Nitro), potentes redes a escala de petabit con Elastic Fabric Adapter (EFA) e hiper- escale la agrupación en clústeres con Amazon EC2 UltraClusters (miles de instancias aceleradas ubicadas conjuntamente en una zona de disponibilidad e interconectadas en una red sin bloqueo que puede ofrecer hasta 3,200 Gbps para capacitación de aprendizaje automático a escala masiva). También estamos facilitando que cualquier cliente acceda a la muy solicitada capacidad de cómputo de GPU para IA generativa con los bloques de capacidad de Amazon EC2 para aprendizaje automático, el primer y único modelo de consumo en la industria que permite a los clientes reservar GPU para uso futuro (hasta 500 implementado en EC2 UltraClusters) para cargas de trabajo de aprendizaje automático de corta duración.
Hace varios años, nos dimos cuenta de que para seguir superando los límites de la rentabilidad tendríamos que innovar hasta el silicio, y comenzamos a invertir en nuestros propios chips. Específicamente para ML, comenzamos con AWS Inferentia, nuestro chip de inferencia diseñado específicamente. Hoy, estamos en nuestra segunda generación de AWS Inferentia con instancias Amazon EC2 Inf2 que están optimizadas específicamente para aplicaciones de IA generativa a gran escala con modelos que contienen cientos de miles de millones de parámetros. Las instancias Inf2 ofrecen el costo más bajo para la inferencia en la nube y al mismo tiempo ofrecen un rendimiento hasta cuatro veces mayor y una latencia hasta diez veces menor en comparación con las instancias Inf1. Impulsadas por hasta 12 chips Inferentia2, Inf2 son las únicas instancias EC2 optimizadas para inferencia que tienen conectividad de alta velocidad entre aceleradores para que los clientes puedan ejecutar inferencias de manera más rápida y eficiente (a menor costo) sin sacrificar el rendimiento o la latencia mediante la distribución de modelos ultragrandes. a través de múltiples aceleradores. Clientes como Adobe, Deutsche Telekom y Leonardo.ai han obtenido excelentes resultados iniciales y están entusiasmados por implementar sus modelos a escala en Inf2.
En lo que respecta a la capacitación, las instancias Trn1, impulsadas por el chip de capacitación de aprendizaje automático especialmente diseñado de AWS, AWS Trainium, están optimizadas para distribuir la capacitación a través de múltiples servidores conectados con la red EFA. Clientes como Ricoh han formado a un LLM japonés con miles de millones de parámetros en apenas unos días. Databricks está obteniendo una relación precio-rendimiento hasta un 40 % mejor con instancias basadas en Trainium para entrenar modelos de aprendizaje profundo a gran escala. Pero con modelos nuevos y más capaces que salen prácticamente cada semana, seguimos superando los límites del rendimiento y la escala, y estamos emocionados de anunciar AWS Trainium2, diseñado para ofrecer una relación precio-rendimiento aún mejor para modelos de entrenamiento con cientos de miles de millones a billones de parámetros. Trainium2 debería ofrecer un rendimiento de entrenamiento hasta cuatro veces más rápido que el Trainium de primera generación y, cuando se utiliza en EC2 UltraClusters, debería ofrecer hasta 65 exaflops de cómputo agregado. Esto significa que los clientes podrán entrenar un LLM de 300 mil millones de parámetros en semanas en lugar de meses. El rendimiento, la escala y la eficiencia energética de Trainium2 son algunas de las razones por las que Anthropic ha elegido entrenar sus modelos en AWS y utilizará Trainium2 para sus modelos futuros. Y estamos colaborando con Anthropic en la innovación continua tanto con Trainium como con Inferentia. Esperamos que nuestras primeras instancias de Trainium2 estén disponibles para los clientes en 2024.
También hemos estado duplicando la cadena de herramientas de software para nuestro silicio ML, específicamente en el avance de AWS Neuron, el kit de desarrollo de software (SDK) que ayuda a los clientes a obtener el máximo rendimiento de Trainium e Inferentia. Desde que presentamos Neuron en 2019, hemos realizado importantes inversiones en tecnologías de compiladores y marcos, y hoy Neuron admite muchos de los modelos más populares disponibles públicamente, incluidos Llama 2 de Meta, MPT de Databricks y Stable Diffusion de Stability AI, así como 93 de los 100 mejores modelos en el popular repositorio de modelos Hugging Face. Neuron se conecta a marcos de aprendizaje automático populares como PyTorch y TensorFlow, y el soporte para JAX llegará a principios del próximo año. Los clientes nos dicen que Neuron les ha facilitado cambiar sus canales de inferencia y capacitación de modelos existentes a Trainium e Inferentia con solo unas pocas líneas de código.
Nadie más ofrece esta misma combinación de elección de los mejores chips de aprendizaje automático, redes súper rápidas, virtualización y clústeres de hiperescala. Por eso, no sorprende que algunas de las nuevas empresas de IA generativa más conocidas, como AI21 Labs, Anthropic, Hugging Face, Perplexity AI, Runway y Stability AI, se ejecuten en AWS. Pero aún necesita las herramientas adecuadas para aprovechar de manera efectiva esta computación para crear, capacitar y ejecutar LLM y otros FM de manera eficiente y rentable. Y para muchas de estas nuevas empresas, Amazon SageMaker es la respuesta. Ya sea construyendo y entrenando un nuevo modelo propietario desde cero o comenzando con uno de los muchos modelos populares disponibles públicamente, la capacitación es una tarea compleja y costosa. Tampoco es fácil ejecutar estos modelos de manera rentable. Los clientes deben adquirir grandes cantidades de datos y prepararlos. Por lo general, esto implica una gran cantidad de trabajo manual limpiando datos, eliminando duplicados, enriqueciéndolos y transformándolos. Luego, tienen que crear y mantener grandes grupos de GPU/aceleradores, escribir código para distribuir eficientemente el entrenamiento del modelo entre los grupos, controlar, pausar, inspeccionar y optimizar con frecuencia el modelo e intervenir y solucionar manualmente los problemas de hardware en el grupo. Muchos de estos desafíos no son nuevos, son algunas de las razones por las que lanzamos SageMaker hace seis años: para derribar las muchas barreras involucradas en la capacitación e implementación de modelos y brindarles a los desarrolladores una manera mucho más fácil. Decenas de miles de clientes utilizan Amazon SageMaker, y un número cada vez mayor de ellos, como LG AI Research, Perplexity AI, AI21, Hugging Face y Stability AI, están capacitando a LLM y otros FM en SageMaker. Recientemente, el Instituto de Innovación Tecnológica (creadores de los populares Falcon LLM) capacitó el modelo más grande disponible públicamente, Falcon 180B, en SageMaker. A medida que el tamaño y la complejidad de los modelos han aumentado, también lo ha hecho el alcance de SageMaker.
A lo largo de los años, hemos agregado más de 380 funciones y capacidades innovadoras a Amazon SageMaker, como ajuste automático de modelos, capacitación distribuida, opciones flexibles de implementación de modelos, herramientas para operaciones de aprendizaje automático, herramientas para la preparación de datos, almacenes de funciones, cuadernos e integración perfecta. con evaluaciones humanas en todo el ciclo de vida del aprendizaje automático y funciones integradas para una IA responsable. Seguimos innovando rápidamente para asegurarnos de que los clientes de SageMaker puedan seguir creando, entrenando y ejecutando inferencias para todos los modelos, incluidos los LLM y otros FM. Y estamos haciendo que sea aún más fácil y rentable para los clientes entrenar e implementar modelos grandes con dos nuevas capacidades. Primero, para simplificar la capacitación estamos Presentamos HiperPod de Amazon SageMaker que automatiza más procesos necesarios para la capacitación distribuida tolerante a fallas a gran escala (por ejemplo, configurar bibliotecas de capacitación distribuidas, escalar cargas de trabajo de capacitación en miles de aceleradores, detectar y reparar instancias defectuosas), acelerando la capacitación hasta en un 40 %. Como resultado, clientes como Perplexity AI, Hugging Face, Stability, Hippocratic, Alkaid y otros están utilizando SageMaker HyperPod para construir, entrenar o evolucionar modelos. Segundo, Estamos introduciendo nuevas capacidades para hacer que la inferencia sea más rentable y al mismo tiempo reducir la latencia. SageMaker ahora ayuda a los clientes a implementar múltiples modelos en la misma instancia para que puedan compartir recursos informáticos, lo que reduce el costo de inferencia en un 50 % (en promedio). SageMaker también monitorea activamente las instancias que procesan solicitudes de inferencia y enruta de manera inteligente las solicitudes según las instancias que están disponibles, logrando una latencia de inferencia un 20 % menor (en promedio). Conjecture, Salesforce y Slack ya están utilizando SageMaker para alojar modelos debido a estas optimizaciones de inferencia.
Capa intermedia de la pila: Amazon Bedrock agrega nuevos modelos y una ola de nuevas capacidades facilita aún más a los clientes la creación y escalamiento seguro de aplicaciones de IA generativa.
Si bien varios clientes crearán sus propios LLM y otros FM, o desarrollarán cualquier cantidad de opciones disponibles públicamente, muchos no querrán gastar los recursos y el tiempo para hacerlo. Para ellos, la capa intermedia de la pila ofrece estos modelos como servicio. Nuestra solución aquí, lecho rocoso del amazonas, permite a los clientes elegir entre modelos líderes en la industria de Anthropic, Stability AI, Meta, Cohere, AI21 y Amazon, personalizarlos con sus propios datos y aprovechar las mismas funciones, controles de acceso y seguridad líderes a los que están acostumbrados. en AWS, todo a través de un servicio administrado. Hicimos que Amazon Bedrock estuviera disponible de forma generalizada a finales de septiembre y la respuesta de los clientes ha sido abrumadoramente positiva. Los clientes de todo el mundo y de prácticamente todos los sectores están entusiasmados de utilizar Amazon Bedrock. adidas permite a los desarrolladores obtener respuestas rápidas sobre todo, desde información de “primeros pasos” hasta preguntas técnicas más profundas. Booking.com tiene la intención de utilizar IA generativa para redactar recomendaciones de viajes personalizadas para cada cliente. Bridgewater Associates está desarrollando un asistente de analista de inversiones basado en un LLM para ayudar a generar gráficos, calcular indicadores financieros y resumir resultados. Carrier está poniendo a disposición de los clientes análisis e información sobre energía más precisos para que reduzcan el consumo de energía y las emisiones de carbono. Clariant está dotando a los miembros de su equipo de un chatbot interno de IA generativa para acelerar los procesos de I+D, apoyar a los equipos de ventas en la preparación de reuniones y automatizar los correos electrónicos de los clientes. GoDaddy ayuda a los clientes a configurar fácilmente sus negocios en línea mediante el uso de IA generativa para crear sus sitios web, encontrar proveedores, conectarse con clientes y más. Lexis Nexis Legal & Professional está transformando el trabajo legal de los abogados y aumentando su productividad con las capacidades de búsqueda conversacional, resúmenes y redacción de documentos y análisis de Lexis+ AI. Nasdaq está ayudando a automatizar los flujos de trabajo de investigación sobre transacciones sospechosas y fortalecer sus capacidades de vigilancia y lucha contra los delitos financieros. Todas estas (y muchas más) diversas aplicaciones de IA generativa se ejecutan en AWS.

Estamos entusiasmados con el impulso de Amazon Bedrock, pero aún es temprano. Lo que hemos visto al trabajar con los clientes es que todos avanzan rápido, pero la evolución de la IA generativa continúa a un ritmo rápido con nuevas opciones e innovaciones que ocurren prácticamente a diario. Los clientes descubren que existen diferentes modelos que funcionan mejor para diferentes casos de uso o con diferentes conjuntos de datos. Algunos modelos son excelentes para resumir, otros son excelentes para el razonamiento y la integración, y otros tienen un soporte de lenguaje realmente increíble. Y luego está la generación de imágenes, casos de uso de búsqueda y más, todos provenientes tanto de modelos propietarios como de modelos que están disponibles públicamente para cualquier persona. Y en tiempos en los que hay tantas cosas que son incognoscibles, la capacidad de adaptación es posiblemente la herramienta más valiosa de todas. No habrá un modelo que los gobierne a todos. Y ciertamente no es solo una empresa de tecnología la que proporciona los modelos que todos usan. Los clientes deben probar diferentes modelos. Deben poder alternar entre ellos o combinarlos dentro del mismo caso de uso. Esto significa que necesitan una verdadera elección de proveedores modelo (lo que los acontecimientos de los últimos diez días han dejado aún más claro). Es por eso que inventamos Amazon Bedrock, por qué resuena tan profundamente entre los clientes y por qué continuamos innovando e iterando rápidamente para que construir con (y moverse entre) una variedad de modelos sea tan fácil como una llamada API, con las últimas técnicas. para la personalización del modelo en manos de todos los desarrolladores y mantener a los clientes seguros y sus datos privados. Nos complace presentar varias capacidades nuevas que harán que sea aún más fácil para los clientes crear y escalar aplicaciones de IA generativa:
- Ampliación de la elección de modelos con Anthropic Claude 2.1, Meta Llama 2 70B y adiciones a la familia Amazon Titan. En estos primeros días, los clientes todavía están aprendiendo y experimentando con diferentes modelos para determinar cuáles quieren utilizar para diversos fines. Quieren poder probar fácilmente los últimos modelos y también probar qué capacidades y características les brindarán los mejores resultados y características de costos para sus casos de uso. Con Amazon Bedrock, los clientes están a solo una llamada API de un nuevo modelo. Algunos de los resultados más impresionantes que los clientes han experimentado en los últimos meses provienen de LLM como El modelo Claude de Anthropic, que destaca en una amplia gama de tareas, desde diálogos sofisticados y generación de contenido hasta razonamientos complejos, manteniendo al mismo tiempo un alto grado de confiabilidad y previsibilidad. Los clientes informan que es mucho menos probable que Claude produzca resultados dañinos, es más fácil conversar con ellos y es más manejable en comparación con otros FM, por lo que los desarrolladores pueden obtener los resultados deseados con menos esfuerzo. El modelo de última generación de Anthropic, Claude 2, obtiene puntuaciones superiores al percentil 90 en los exámenes GRE de lectura y escritura, y de manera similar en razonamiento cuantitativo. Y Ahora, el modelo Claude 2.1 recién lanzado está disponible en Amazon Bedrock. Claude 2.1 ofrece capacidades clave para empresas, como una ventana de contexto de 200 tokens líder en la industria (el doble del contexto de Claude 2), tasas reducidas de alucinaciones y mejoras significativas en la precisión, incluso en contextos de muy larga duración. Claude 2.0 también incluye indicaciones mejoradas del sistema, que son instrucciones modelo que brindan una mejor experiencia para los usuarios finales, al tiempo que reduce el costo de las indicaciones y las completaciones en un 2.1 %.
Para un número cada vez mayor de clientes que desean utilizar una versión administrada del modelo Llama 2 disponible públicamente de Meta, Amazon Bedrock ofrece Llama 2 13B y estamos agregando Llama 2 70B. Llama 2 70B es adecuado para tareas a gran escala como modelado de lenguaje, generación de texto y sistemas de diálogo. Los modelos Llama disponibles públicamente se han descargado más de 30 millones de veces y a los clientes les encanta que Amazon Bedrock los ofrezca como parte de un servicio administrado en el que no necesitan preocuparse por la infraestructura ni tener una profunda experiencia en aprendizaje automático en sus equipos. Además, para la generación de imágenes, Stability AI ofrece un conjunto de modelos populares de conversión de texto a imagen. Stable Diffusion XL 1.0 (SDXL 1.0) es el más avanzado de ellos y ahora está disponible de forma generalizada en Amazon Bedrock.. La última edición de este popular modelo de imagen tiene mayor precisión, mejor fotorrealismo y mayor resolución.
Los clientes también están usando Titán Amazonas modelos, que AWS crea y entrena previamente para ofrecer capacidades poderosas con gran economía para una variedad de casos de uso. Amazon tiene una trayectoria de 25 años en ML e IA (tecnología que utilizamos en todos nuestros negocios) y hemos aprendido mucho sobre la creación e implementación de modelos. Hemos elegido cuidadosamente cómo entrenamos nuestros modelos y los datos que utilizamos para hacerlo. Indemnizamos a los clientes contra reclamaciones de que nuestros modelos o sus resultados infrinjan los derechos de autor de cualquier persona. Presentamos nuestros primeros modelos Titan en abril de este año. Titán Texto Lite—ahora disponible de forma generalizada—es un modelo conciso y rentable para casos de uso como chatbots, resúmenes de texto o redacción publicitaria, y también resulta atractivo realizar ajustes. Titan Text Express: ahora también disponible de forma generalizada—es más amplio y se puede utilizar para una gama más amplia de tareas basadas en texto, como la generación de texto abierto y el chat conversacional. Ofrecemos estas opciones de modelo de texto para brindar a los clientes la capacidad de optimizar la precisión, el rendimiento y el costo según su caso de uso y los requisitos comerciales. Clientes como Nexxiot, PGA Tour y Ryanair utilizan nuestros dos modelos Titan Text. También contamos con un modelo de incrustaciones, Titan Text Embeddings, para casos de uso de búsqueda y personalización. Clientes como Nasdaq están viendo excelentes resultados al utilizar Titan Text Embeddings para mejorar las capacidades de Nasdaq IR Insight para generar información a partir de documentos de más de 9,000 empresas globales para los equipos de sostenibilidad, legales y contables. Y continuaremos agregando más modelos a la familia Titan con el tiempo. Presentamos un nuevo modelo de incrustaciones, Titan Multimodal Embeddings, para impulsar experiencias de búsqueda y recomendación multimodal para usuarios que utilizan imágenes y texto (o una combinación de ambos) como entradas. Y somos presentamos un nuevo modelo de conversión de texto a imagen, Amazon Titan Image Generator. Con Titan Image Generator, los clientes de industrias como la publicidad, el comercio electrónico y los medios y el entretenimiento pueden utilizar una entrada de texto para generar imágenes realistas con calidad de estudio en grandes volúmenes y a bajo costo. Estamos entusiasmados con la forma en que los clientes están respondiendo a Titan Models y puede esperar que continuaremos innovando aquí.
- Nuevas capacidades para personalizar su aplicación de IA generativa de forma segura con sus datos patentados: Una de las capacidades más importantes de Amazon Bedrock es lo fácil que es personalizar un modelo. Esto resulta realmente emocionante para los clientes porque es donde la IA generativa se encuentra con su principal diferenciador: sus datos. Sin embargo, es realmente importante que sus datos permanezcan seguros, que tengan control sobre ellos a lo largo del camino y que las mejoras del modelo sean privadas para ellos. Hay varias formas de hacerlo y Amazon Bedrock ofrece la más amplia selección de opciones de personalización en varios modelos). El primero es el ajuste fino. Ajustar un modelo en Amazon Bedrock es fácil. Simplemente selecciona el modelo y Amazon Bedrock hace una copia del mismo. Luego, señala algunos ejemplos etiquetados (p. ej., una serie de buenos pares de preguntas y respuestas) que almacena en Amazon Simple Storage Service (Amazon S3) y Amazon Bedrock “entrena incrementalmente” (aumenta el modelo copiado con la nueva información). sobre estos ejemplos, y el resultado es un modelo privado, más preciso y ajustado que ofrece respuestas más relevantes y personalizadas. Nos complace anunciar que el ajuste fino está disponible de forma general para Cohere Command, Meta Llama 2, Amazon Titan Text (Lite y Express), Amazon Titan Multimodal Embeddings y en versión preliminar para Amazon Titan Image Generator. Y, a través de nuestra colaboración con Anthropic, pronto brindaremos a los clientes de AWS acceso temprano a características únicas para la personalización del modelo y el ajuste de su modelo Claude de última generación.
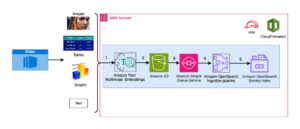
Una segunda técnica para personalizar LLM y otros FM para su negocio es la generación aumentada de recuperación (RAG), que le permite personalizar las respuestas de un modelo aumentando sus indicaciones con datos de múltiples fuentes, incluidos repositorios de documentos, bases de datos y API. En septiembre, presentamos una capacidad RAG, Knowledge Bases for Amazon Bedrock, que conecta de forma segura modelos con sus fuentes de datos patentadas para complementar sus solicitudes con más información para que sus aplicaciones brinden respuestas más relevantes, contextuales y precisas. Bases de conocimiento ahora está disponible de forma general con una API que realiza todo el flujo de trabajo de RAG desde buscar el texto necesario para aumentar un mensaje, hasta enviar el mensaje al modelo y devolver la respuesta. Knowledge Bases admite bases de datos con capacidades vectoriales que almacenan representaciones numéricas de sus datos (incrustaciones) que los modelos utilizan para acceder a estos datos para RAG, incluido Amazon OpenSearch Service y otras bases de datos populares como Pinecone y Redis Enterprise Cloud (próximamente soporte vectorial de Amazon Aurora y MongoDB). pronto).
La tercera forma de personalizar modelos en Amazon Bedrock es mediante una capacitación previa continua. Con este método, el modelo se basa en su entrenamiento previo original para la comprensión general del lenguaje para aprender lenguaje y terminología específicos de un dominio. Este enfoque es para clientes que tienen una gran cantidad de información sin etiquetar y específica de un dominio y desean permitir que sus LLM comprendan el lenguaje, las frases, las abreviaturas, los conceptos, las definiciones y la jerga exclusiva de su mundo (y negocio). A diferencia del ajuste fino, que requiere una cantidad bastante pequeña de datos, el entrenamiento previo continuo se realiza en grandes conjuntos de datos (por ejemplo, miles de documentos de texto). Ahora, las capacidades de capacitación previa están disponibles en Amazon Bedrock para Titan Text Lite y Titan Text Express.
- Disponibilidad general de Agentes de Amazon Bedrock para ayudar a ejecutar tareas de varios pasos utilizando sistemas, fuentes de datos y conocimiento de la empresa. Los LLM son excelentes para mantener conversaciones y generar contenido, pero los clientes quieren que sus aplicaciones puedan do incluso más, como tomar medidas, resolver problemas e interactuar con una variedad de sistemas para completar tareas de varios pasos, como reservar viajes, presentar reclamaciones de seguros o solicitar piezas de repuesto. Y Amazon Bedrock puede ayudar con este desafío. Con los agentes, los desarrolladores seleccionan un modelo, escriben algunas instrucciones básicas como "usted es un agente de servicio al cliente alegre" y "verifique la disponibilidad del producto en el sistema de inventario", señalan el modelo seleccionado a las fuentes de datos y sistemas empresariales correctos (por ejemplo, CRM o aplicaciones ERP) y escribir algunas funciones de AWS Lambda para ejecutar las API (por ejemplo, verificar la disponibilidad de un elemento en el inventario de ERP). Amazon Bedrock analiza automáticamente la solicitud y la divide en una secuencia lógica utilizando las capacidades de razonamiento del modelo seleccionado para determinar qué información se necesita, qué API llamar y cuándo llamarlas para completar un paso o resolver una tarea. Ahora disponibles de forma generalizada, los agentes pueden planificar y realizar la mayoría de las tareas comerciales, desde responder preguntas de los clientes sobre la disponibilidad de su producto hasta tomar sus pedidos, y los desarrolladores no necesitan estar familiarizados con el aprendizaje automático, las indicaciones de ingeniería, los modelos de entrenamiento o los sistemas conectados manualmente. Y Bedrock hace todo esto de forma segura y privada, y clientes como Druva y Athene ya los están utilizando para mejorar la precisión y la velocidad de desarrollo de sus aplicaciones de IA generativa.
- Presentamos: Barandillas para Amazon Bedrock para que pueda aplicar salvaguardas basadas en los requisitos de su caso de uso y las políticas de IA responsables. Los clientes quieren estar seguros de que las interacciones con sus aplicaciones de IA sean seguras, evitar lenguaje tóxico u ofensivo, seguir siendo relevantes para su negocio y alinearse con sus políticas de IA responsable. Con las barreras de seguridad, los clientes pueden especificar temas a evitar y Amazon Bedrock solo proporcionará a los usuarios respuestas aprobadas a las preguntas que se encuentren en esas categorías restringidas. Por ejemplo, se puede configurar una aplicación de banca en línea para evitar brindar asesoramiento sobre inversiones y eliminar contenido inapropiado (como discursos de odio y violencia). A principios de 2024, los clientes también podrán redactar información de identificación personal (PII) en las respuestas de los modelos. Por ejemplo, después de que un cliente interactúa con un agente del centro de llamadas, la conversación de servicio al cliente a menudo se resume para el mantenimiento de registros, y las barreras de seguridad pueden eliminar la PII de esos resúmenes. Guardrails se puede utilizar en todos los modelos de Amazon Bedrock (incluidos los modelos optimizados) y con Agents for Amazon Bedrock para que los clientes puedan brindar un nivel constante de protección a todas sus aplicaciones de IA generativa.
Capa superior de la pila: la innovación continua hace que la IA generativa sea accesible a más usuarios
En la capa superior de la pila se encuentran aplicaciones que aprovechan los LLM y otros FM para que usted pueda aprovechar la IA generativa en el trabajo. Un área donde la IA generativa ya está cambiando el juego es la codificación. El año pasado, presentamos Amazon CodeWhisperer, que le ayuda a crear aplicaciones de forma más rápida y segura generando sugerencias y recomendaciones de código casi en tiempo real. Clientes como Accenture, Boeing, Bundesliga, The Cigna Group, Kone y Warner Music Group están utilizando CodeWhisperer para aumentar la productividad de los desarrolladores, y Accenture está habilitando hasta 50,000 XNUMX de sus desarrolladores de software y profesionales de TI con Amazon CodeWhisperer. Queremos que la mayor cantidad posible de desarrolladores puedan obtener los beneficios de productividad de la IA generativa, razón por la cual CodeWhisperer ofrece recomendaciones gratuitas para todas las personas.
Sin embargo, si bien las herramientas de codificación de IA hacen mucho para facilitar la vida de los desarrolladores, sus beneficios de productividad están limitados por su falta de conocimiento de las bases de código interno, las API internas, las bibliotecas, los paquetes y las clases. Una forma de pensar en esto es que si contrata a un nuevo desarrollador, incluso si es de clase mundial, no será tan productivo en su empresa hasta que comprenda sus mejores prácticas y su código. Las herramientas de codificación actuales basadas en IA son como ese desarrollador recién contratado. Para ayudar con esto, recientemente presentamos una vista previa de un nuevo capacidad de personalización en Amazon CodeWhisperer que aprovecha de forma segura la base de código interno de un cliente para proporcionar recomendaciones de código más relevantes y útiles. Con esta capacidad, CodeWhisperer es un experto en su proveedor código y proporciona recomendaciones que son más relevantes para ahorrar aún más tiempo. En un estudio que realizamos con Persistent, una empresa global de ingeniería digital y modernización empresarial, descubrimos que las personalizaciones ayudan a los desarrolladores a completar tareas hasta un 28% más rápido que con las capacidades generales de CodeWhisperer. Ahora, un desarrollador de una empresa de tecnología sanitaria puede pedirle a CodeWhisperer que "importe imágenes de resonancia magnética asociadas con la identificación del cliente y las ejecute a través del clasificador de imágenes" para detectar anomalías. Debido a que CodeWhisperer tiene acceso al código base, puede proporcionar sugerencias mucho más relevantes que incluyen las ubicaciones de importación de las imágenes de resonancia magnética y las identificaciones de los clientes. CodeWhisperer mantiene las personalizaciones completamente privadas y el FM subyacente no las utiliza para capacitación, lo que protege la valiosa propiedad intelectual de los clientes. AWS es el único proveedor importante de nube que ofrece una capacidad como esta para todos.
Presentamos: Amazonas Q, el asistente generativo impulsado por IA diseñado para el trabajo
Ciertamente, los desarrolladores no son los únicos que se están poniendo manos a la obra con la IA generativa: millones de personas están utilizando aplicaciones de chat de IA generativa. Lo que los primeros proveedores han hecho en este espacio es emocionante y muy útil para los consumidores, pero en muchos sentidos no “funcionan” del todo en el trabajo. Sus conocimientos y capacidades generales son excelentes, pero no conocen su empresa, sus datos, sus clientes, sus operaciones ni su negocio. Eso limita cuánto pueden ayudarte. Tampoco saben mucho sobre su función: qué trabajo hace, con quién trabaja, qué información utiliza y a qué tiene acceso. Estas limitaciones son comprensibles porque estos asistentes no tienen acceso a la información privada de su empresa y no fueron diseñados para cumplir con los requisitos de seguridad y privacidad de datos que las empresas necesitan para brindarles este acceso. Es difícil reforzar la seguridad después del hecho y esperar que funcione bien. Creemos que tenemos una mejor manera, que permitirá a todas las personas de cada organización utilizar la IA generativa de forma segura en su trabajo diario.
WEstamos emocionados de presentar Amazon Q, un nuevo tipo de asistente generativo impulsado por IA que es específicamente para el trabajo y puede adaptarse a su negocio. Q puede ayudarle a obtener respuestas rápidas y relevantes a preguntas urgentes, resolver problemas, generar contenido y tomar medidas utilizando los datos y la experiencia que se encuentran en los repositorios de información, el código y los sistemas empresariales de su empresa. Cuando chatea con Amazon Q, proporciona información y consejos inmediatos y relevantes para ayudar a agilizar las tareas, acelerar la toma de decisiones y ayudar a estimular la creatividad y la innovación en el trabajo. Hemos creado Amazon Q para que sea seguro y privado, y pueda comprender y respetar sus identidades, roles y permisos existentes y utilizar esta información para personalizar sus interacciones. Si un usuario no tiene permiso para acceder a ciertos datos sin Q, tampoco podrá acceder a ellos usando Q. Hemos diseñado Amazon Q para cumplir con los estrictos requisitos de los clientes empresariales desde el primer día: ninguno de sus contenidos se utiliza para mejorar los modelos subyacentes.

Amazon Q es su asistente experto para construir en AWS: Hemos capacitado a Amazon Q con 17 años de conocimiento y experiencia en AWS para que pueda transformar la forma en que crea, implementa y opera aplicaciones y cargas de trabajo en AWS. Amazon Q tiene una interfaz de chat en la consola de administración y documentación de AWS, su IDE (a través de CodeWhisperer) y las salas de chat de su equipo en Slack u otras aplicaciones de chat. Amazon Q puede ayudarlo a explorar nuevas capacidades de AWS, comenzar más rápido, aprender tecnologías desconocidas, diseñar soluciones, solucionar problemas, actualizar y mucho más: es un experto en patrones bien diseñados, mejores prácticas, documentación e implementaciones de soluciones de AWS. A continuación se muestran algunos ejemplos de lo que puede hacer con su nuevo asistente experto de AWS:
- Obtenga respuestas claras y orientación sobre las capacidades, servicios y soluciones de AWS: Pídale a Amazon Q que me informe sobre los agentes de Amazon Bedrock y Q le brindará una descripción de la función además de enlaces a materiales relevantes. También puede hacerle a Amazon Q prácticamente cualquier pregunta sobre cómo funciona un servicio de AWS (por ejemplo, "¿Cuáles son los límites de escala en una tabla de DynamoDB?", "¿Qué es el almacenamiento administrado de Redshift?") o cómo diseñar mejor cualquier cantidad de soluciones ( "¿Cuáles son las mejores prácticas para construir arquitecturas basadas en eventos?"). Y Amazon Q reunirá respuestas concisas y siempre citará (y vinculará) sus fuentes.
- Elija el mejor servicio de AWS para su caso de uso y comience rápidamente: Pregúntele a Amazon P “¿Cuáles son las formas de crear una aplicación web en AWS? ” y proporcionará una lista de servicios potenciales como AWS amplificar, AWS Lambday Amazon EC2 con las ventajas de cada uno. A partir de ahí, puede reducir las opciones ayudando a Q a comprender sus requisitos, preferencias y restricciones (por ejemplo, "¿Cuál de estas sería mejor si quiero usar contenedores?" o "¿Debería usar una base de datos relacional o no relacional?" ”). Termine con "¿Cómo empiezo?" y Amazon Q describirá algunos pasos básicos y le indicará recursos adicionales.
- Optimice sus recursos informáticos: Amazon Q puede ayudarle a seleccionar instancias de Amazon EC2. Si le pide "Ayúdeme a encontrar la instancia EC2 adecuada para implementar una carga de trabajo de codificación de video para mi aplicación de juegos con el mayor rendimiento", Q le dará una lista de familias de instancias con los motivos de cada sugerencia. Y puede hacer cualquier cantidad de preguntas de seguimiento para ayudarlo a encontrar la mejor opción para su carga de trabajo.
- Obtenga ayuda para depurar, probar y optimizar su código: Si encuentra un error mientras codifica en su IDE, puede pedirle ayuda a Amazon Q diciendo: "Mi código tiene un error de IO, ¿pueden proporcionarme una solución?". y Q generará el código por usted. Si le gusta la sugerencia, puede pedirle a Amazon Q que agregue la solución a su aplicación. Dado que Amazon Q está en su IDE, comprende el código en el que está trabajando y sabe dónde insertar la solución. Amazon Q también puede crear pruebas unitarias (“Escribir pruebas unitarias para la función seleccionada”) que puede insertar en su código y usted puede ejecutar. Finalmente, Amazon Q puede indicarle formas de optimizar su código para lograr un mayor rendimiento. Pídale a Q que "Optimice mi consulta de DynamoDB seleccionada" y utilizará su comprensión de su código para proporcionar una sugerencia en lenguaje natural sobre qué corregir junto con el código adjunto que puede implementar con un solo clic.
- Diagnosticar y solucionar problemas: Si encuentra problemas en la Consola de administración de AWS, como errores de permisos EC2 o errores de configuración de Amazon S3, simplemente presione el botón "Solucionar problemas con Amazon Q" y utilizará su comprensión del tipo de error y el servicio donde se encuentra el error. para darle sugerencias para una solución. Incluso puede pedirle a Amazon Q que solucione los problemas de su red (p. ej., "¿Por qué no puedo conectarme a mi instancia EC2 usando SSH?") y Q analizará su configuración de extremo a extremo y proporcionará un diagnóstico (p. ej., "Esta instancia parece estar en una subred privada, por lo que es posible que sea necesario establecer la accesibilidad pública”).
- Desarrolla una nueva base de código en poco tiempo: Cuando chatea con Amazon Q en su IDE, combina su experiencia en la creación de software con la comprensión de su código: ¡una combinación poderosa! Anteriormente, si tomabas el control de un proyecto de otra persona o eras nuevo en el equipo, es posible que tuvieras que pasar horas revisando manualmente el código y la documentación para comprender cómo funciona y qué hace. Ahora, dado que Amazon Q comprende el código de su IDE, simplemente puede pedirle a Amazon Q que le explique el código (“Brindeme una descripción de lo que hace esta aplicación y cómo funciona”) y Q le dará detalles como qué servicios ofrece. usos del código y qué hacen las diferentes funciones (por ejemplo, Q podría responder con algo como: "Esta aplicación está creando un sistema de tickets de soporte básico utilizando Python Flask y AWS Lambda" y continuar describiendo cada una de sus capacidades principales, cómo se implementan, y mucho más).
- Borre su acumulación de funciones más rápido: Incluso puede pedirle a Amazon Q que lo guíe y automatice gran parte del proceso de extremo a extremo para agregar una función a su aplicación en Amazon CodeCatalyst, nuestro servicio unificado de desarrollo de software para equipos. Para hacer esto, simplemente asigne a Q una tarea pendiente de su lista de problemas, tal como lo haría con un compañero de equipo, y Q genera un plan paso a paso sobre cómo construirá e implementará la característica. Una vez que apruebe el plan, Q escribirá el código y le presentará los cambios sugeridos como una revisión del código. ¡Puede solicitar reelaboración (si es necesario), aprobar y/o implementar!
- Actualice su código en una fracción del tiempo: En realidad, la mayoría de los desarrolladores solo dedican una fracción de su tiempo a escribir código nuevo y crear nuevas aplicaciones. Dedican una mayor parte de sus ciclos a áreas dolorosas y difíciles, como mantenimiento y actualizaciones. Realice actualizaciones de versiones de idiomas. Una gran cantidad de clientes continúan usando versiones anteriores de Java porque la actualización llevará meses (incluso años) y miles de horas de tiempo de desarrollador. Posponer esto conlleva costos y riesgos reales: se pierden mejoras de rendimiento y se es vulnerable a problemas de seguridad. Creemos que Amazon Q puede cambiar las reglas del juego aquí y estamos entusiasmados con Transformación del código Q de Amazon, una característica que puede eliminar gran parte de este trabajo pesado y reducir el tiempo que lleva actualizar las aplicaciones de días a minutos. Simplemente abra el código que desea actualizar en su IDE y solicite a Amazon Q que “/transforme” su código. Amazon Q analizará todo el código fuente de la aplicación, generará el código en el idioma y la versión de destino y ejecutará pruebas, lo que le ayudará a obtener las mejoras de seguridad y rendimiento de las últimas versiones del idioma. Recientemente, un equipo muy pequeño de desarrolladores de Amazon utilizó Amazon Q Code Transformation para actualizar 1,000 aplicaciones de producción de Java 8 a Java 17 en solo dos días. El tiempo medio por aplicación fue inferior a 10 minutos. Hoy en día, Amazon Q Code Transformation realiza actualizaciones del lenguaje Java de Java 8 o Java 11 a Java 17. Lo próximo (y pronto) es la capacidad de transformar .NET Framework a .NET multiplataforma (con aún más transformaciones en el futuro). .
Amazon Q es su experto en negocios: Puede conectar Amazon Q a los datos, la información y los sistemas de su empresa para que pueda sintetizar todo y brindar asistencia personalizada para ayudar a las personas a resolver problemas, generar contenido y tomar acciones que sean relevantes para su negocio. Llevar Amazon Q a su negocio es fácil. Tiene más de 40 conectores integrados para sistemas empresariales populares como Amazon S3, Microsoft 365, Salesforce, ServiceNow, Slack, Atlassian, Gmail, Google Drive y Zendesk. También puede conectarse a su intranet interna, wikis y libros de ejecución, y con Amazon Q SDK, puede crear una conexión con cualquier aplicación interna que desee. Apunte Amazon Q a estos repositorios y "acelerará" su negocio, capturando y comprendiendo la información semántica que hace que su empresa sea única. Luego, obtendrá su propia aplicación web Amazon Q sencilla y amigable para que los empleados de su empresa puedan interactuar con la interfaz conversacional. Amazon Q también se conecta a su proveedor de identidad para comprender a un usuario, su función y a qué sistemas puede acceder, de modo que los usuarios puedan hacer preguntas detalladas y matizadas y obtener resultados personalizados que incluyan solo la información que están autorizados a ver. Amazon Q genera respuestas e información que son precisas y fieles al material y conocimiento que usted le proporciona, y puede restringir temas delicados, bloquear palabras clave o filtrar preguntas y respuestas inapropiadas. A continuación se muestran algunos ejemplos de lo que puede hacer con el nuevo asistente experto de su empresa:
- Obtenga respuestas nítidas y súper relevantes basadas en la información y los datos de su negocio: Los empleados pueden preguntarle a Amazon Q sobre cualquier cosa que hayan tenido que buscar anteriormente en todo tipo de fuentes. Pregunte "¿Cuáles son las pautas más recientes para el uso de logotipos?" o "¿Cómo solicito una tarjeta de crédito de empresa?", y Amazon Q sintetizará todo el contenido relevante que encuentre y le brindará respuestas rápidas además de enlaces a los sitios relevantes. fuentes (por ejemplo, portales de marcas y repositorios de logotipos, políticas de viajes y gastos de la empresa y aplicaciones de tarjetas).
- Agilice las comunicaciones del día a día: Simplemente pregunte y Amazon Q podrá generar contenido (“Crear una publicación de blog y tres titulares de redes sociales que anuncien el producto descrito en esta documentación”), crear resúmenes ejecutivos (“Escribir un resumen de la transcripción de nuestra reunión con una lista con viñetas de elementos de acción” ), proporcionar actualizaciones por correo electrónico (“Redactar un correo electrónico destacando nuestros programas de capacitación del tercer trimestre para clientes en India”) y ayudar a estructurar reuniones (“Crear una agenda de reuniones para hablar sobre el último informe de satisfacción del cliente”).
- Tareas completas: Amazon Q puede ayudar a completar ciertas tareas, reduciendo la cantidad de tiempo que los empleados dedican a trabajos repetitivos como presentar tickets. Pídale a Amazon Q que "resuma los comentarios de los clientes sobre la nueva oferta de precios en Slack" y luego solicite que Q tome esa información y abra un ticket en Jira para actualizar al equipo de marketing. Puede pedirle a Q que "Resuma la transcripción de esta llamada" y luego "Abra un nuevo caso para el Cliente A en Salesforce". Amazon Q admite otras herramientas populares de automatización del trabajo como Zendesk y Service Now.
Amazon Q está en Amazon QuickSight: Con Amazon Q en QuickSight, el servicio de inteligencia empresarial de AWS, los usuarios pueden hacer en sus paneles preguntas como "¿Por qué aumentó el número de pedidos el mes pasado?" y obtenga visualizaciones y explicaciones de los factores que influyeron en el aumento. Además, los analistas pueden utilizar Amazon Q para reducir el tiempo que les lleva crear paneles de control de días a minutos con un mensaje simple como "Muéstrame las ventas por región por mes como un gráfico de barras apiladas". Q regresa con ese diagrama y puede agregarlo fácilmente a un panel o conversar más con Q para refinar la visualización (por ejemplo, "Cambiar el gráfico de barras a un diagrama de Sankey" o "Mostrar países en lugar de regiones"). Amazon Q en QuickSight también facilita el uso de paneles existentes para informar a las partes interesadas del negocio, extraer información clave y simplificar la toma de decisiones mediante historias de datos. Por ejemplo, los usuarios pueden solicitar a Amazon Q que "cree una historia sobre cómo ha cambiado el negocio durante el último mes para una revisión del negocio con los altos directivos" y, en segundos, Amazon Q ofrece una historia basada en datos que es visualmente convincente y completamente personalizable. Estas historias se pueden compartir de forma segura en toda la organización para ayudar a alinear a las partes interesadas e impulsar mejores decisiones.
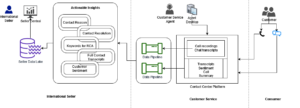
Amazon Q está en Amazon Connect: En Amazon Connect, nuestro servicio de centro de contacto, Amazon Q ayuda a sus agentes de servicio al cliente a brindar un mejor servicio al cliente. Amazon Q aprovecha los repositorios de conocimientos que sus agentes suelen utilizar para obtener información para los clientes y luego los agentes pueden chatear con Amazon Q directamente en Connect para obtener respuestas que les ayuden a responder más rápidamente a las solicitudes de los clientes sin necesidad de buscar ellos mismos en la documentación. Y, si bien chatear con Amazon Q para obtener respuestas súper rápidas es fantástico, en el servicio de atención al cliente no existe lo demasiado rápido. Es por eso Amazon Q en conexión convierte una conversación en vivo de un cliente con un agente en un aviso y le proporciona automáticamente al agente posibles respuestas, acciones sugeridas y enlaces a recursos. Por ejemplo, Amazon Q puede detectar que un cliente se está comunicando con una empresa de alquiler de automóviles para cambiar su reserva, generar una respuesta para que el agente comunique rápidamente cómo se aplican las políticas de cargos por cambio de la empresa y guiar al agente a través de los pasos que necesita para actualizar la reserva.
Amazon Q está en AWS Supply Chain (próximamente): En AWS Supply Chain, nuestro servicio de información sobre la cadena de suministro, Amazon Q ayuda a los planificadores de oferta y demanda, administradores de inventario y socios comerciales a optimizar su cadena de suministro al resumir y resaltar los posibles riesgos de desabastecimiento o exceso de existencias, y visualizar escenarios para resolver el problema. Los usuarios pueden hacerle a Amazon Q preguntas de “qué”, “por qué” y “qué pasaría si” sobre los datos de su cadena de suministro y conversar sobre escenarios complejos y las compensaciones entre diferentes decisiones de la cadena de suministro. Por ejemplo, un cliente puede preguntar: "¿Qué está causando el retraso en mis envíos y cómo puedo acelerar las cosas?" a lo que Amazon Q puede responder: “El 90% de sus pedidos están en la costa este y una gran tormenta en el sureste está provocando un retraso de 24 horas. Si realiza envíos al puerto de Nueva York en lugar de Miami, acelerará las entregas y reducirá los costos en un 50 %”.
Nuestros clientes están adoptando IA generativa rápidamente: están entrenando modelos innovadores en AWS, están desarrollando aplicaciones de IA generativa a una velocidad récord utilizando Amazon Bedrock y están implementando aplicaciones innovadoras en sus organizaciones, como Amazon Q. Con nuestros últimos anuncios, AWS está brindando a los clientes aún más rendimiento, opciones e innovación en cada capa de la pila. El impacto combinado de todas las capacidades que ofrecemos en re:Invent marca un hito importante hacia el logro de un objetivo emocionante y significativo: estamos haciendo que la IA generativa sea accesible para clientes de todos los tamaños y habilidades técnicas para que puedan reinventar y transformar lo que es posible.
Recursos
Sobre la autora
 Swami Sivasubramanian es vicepresidente de datos y aprendizaje automático en AWS. En este rol, Swami supervisa todos los servicios de AWS Database, Analytics, AI & Machine Learning. La misión de su equipo es ayudar a las organizaciones a poner sus datos a trabajar con una solución de datos completa e integral para almacenar, acceder, analizar, visualizar y predecir.
Swami Sivasubramanian es vicepresidente de datos y aprendizaje automático en AWS. En este rol, Swami supervisa todos los servicios de AWS Database, Analytics, AI & Machine Learning. La misión de su equipo es ayudar a las organizaciones a poner sus datos a trabajar con una solución de datos completa e integral para almacenar, acceder, analizar, visualizar y predecir.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/welcome-to-a-new-era-of-building-in-the-cloud-with-generative-ai-on-aws/
- :posee
- :es
- :no
- :dónde
- $ UP
- 000
- 1
- 10
- 100
- 11
- 12
- 17
- 200
- 2019
- 2024
- 25
- 30
- 300
- 35%
- 40
- 50
- 500
- 65
- 8
- 9
- a
- <del>
- capacidad
- Poder
- Nuestra Empresa
- arriba
- acelerar
- acelerado
- aceleradores
- Accenture
- de la máquina
- accesibilidad
- accesible
- Contabilidad
- la exactitud
- preciso
- adquirir
- a través de
- la columna Acción
- acciones
- activamente
- adaptar
- add
- adicional
- la adición de
- adición
- Adicionales
- Adicionalmente
- Adiciones
- Añade
- Adidas
- adobe
- Adopción
- avanzado
- seguir
- Ventaja
- ventajas
- Publicidad
- consejos
- Después
- en contra
- agenda
- Agente
- agentes
- agregar
- .
- AI
- IA y aprendizaje automático
- Chat de AI
- ai investigación
- Alimentado por IA
- alinear
- Todos
- permitir
- permite
- a lo largo de
- ya haya utilizado
- también
- hacerlo
- Amazon
- Código de Amazon Whisperer
- Amazon EC2
- Amazon QuickSight
- Amazon SageMaker
- Amazon Web Services
- cantidad
- cantidades
- an
- análisis
- analista
- Analistas
- Analytics
- analizar
- análisis
- y
- Anunciar
- Anuncios
- Anunciando
- https://www.youtube.com/watch?v=xB-eutXNUMXJtA&feature=youtu.be
- respuestas
- Antrópico
- cualquier
- nadie
- cualquier cosa
- abejas
- API
- applicación
- aparece
- Aplicación
- aplicaciones
- Aplicá
- apreciar
- enfoque
- aprobar
- aprobado
- aplicaciones
- Abril
- somos
- Reservada
- áreas
- sin duda
- en torno a
- AS
- contacta
- Ayuda
- Legal
- asistentes
- asociado
- asociados
- At
- atlassian
- aumentar
- aumentado
- Augments
- Aurora
- autorizado
- automatizado
- automatiza
- Automático
- automáticamente
- Automatización
- automotor
- disponibilidad
- Hoy Disponibles
- promedio
- evitar
- lejos
- AWS
- Inferencia de AWS
- AWS Lambda
- Consola de administración de AWS
- Atrás
- Bancario
- de caramelos
- las barreras
- bases
- basado
- básica
- BE
- porque
- se convierte en
- esto
- comenzó
- CREEMOS
- beneficios
- MEJOR
- y las mejores prácticas
- mejores
- entre
- Big
- mil millones
- miles de millones
- Bloquear
- Bloques
- Blog
- Boeing
- Bolt
- Booking
- Booking.com
- Libros
- ambas
- Fondo
- límites
- marca
- Descanso
- rompe
- llevar
- Trayendo
- build
- Construir la
- construye
- construido
- incorporado
- inteligencia empresarial
- negocios
- pero
- .
- by
- llamar al
- centro de llamadas
- PUEDEN
- Puede conseguir
- capacidades
- capacidad
- capaz
- Capacidad
- Capturando
- de
- carbono
- las emisiones de carbono
- tarjeta
- estudiar cuidadosamente
- case
- cases
- categoría
- causando
- Reubicación
- a ciertos
- ciertamente
- cadena
- Reto
- retos
- el cambio
- cambiado
- Cambiador
- Cambios
- cambio
- características
- Tabla
- Gráficas
- salas de chat
- chatterbot
- Chatbots
- en el chat
- comprobar
- chip
- Papas fritas
- manera?
- Elige
- la elección de
- elegido
- reclamaciones
- privadas
- Limpieza
- limpiar
- clic
- Soluciones
- infraestructura de nube
- Médico
- clustering
- Pacífica
- código
- base de código
- Revisión de código
- Codificación
- colaborar
- colaboración
- COM
- combinación
- combinar
- combinado
- combina
- cómo
- proviene
- viniendo
- Próximamente
- Comunicarse
- Comunicaciónes
- Empresas
- compañía
- De la empresa
- en comparación con
- irresistible
- completar
- completamente
- integraciones
- complejidad
- exhaustivo
- Calcular
- conceptos
- Configuración
- Configurando
- conjetura
- Contacto
- conectado
- conexión
- Conectividad
- conecta
- consistente
- Consola
- restricciones
- Clientes
- consumo
- contacte
- contact center
- Contenedores
- contenido
- contexto
- contextual
- continue
- continuado
- continúa
- continuo
- control
- controles
- Conversación
- conversacional
- conversaciones
- derechos de autor,
- redacción publicitaria
- Core
- Cost
- rentable
- Precio
- países
- Timonel
- Para crear
- creado
- creatividad
- creadores
- crédito
- .
- Delito
- CRUJIENTE
- CRM
- multi-plataforma
- cliente
- experiencia del cliente
- Satisfacción del cliente
- Servicio al Cliente
- Clientes
- personalizable
- personalización
- personalizan
- se adaptan
- Corte
- de ciclos
- todos los días
- página de información de sus operaciones
- de los tableros
- datos
- Preparación de datos
- privacidad de datos
- Privacidad y seguridad de datos
- conjuntos de datos
- basada en datos
- Base de datos
- bases de datos
- Databricks
- día
- día a día
- Días
- Toma de Decisiones
- decisiones
- profundo
- deep learning
- más profundo
- Definiciones
- Grado
- retrasar
- entregamos
- Las entregas
- entregar
- entrega
- Demanda
- Democratizando
- Dependiente
- desplegar
- desplegado
- Desplegando
- despliegue
- profundidad
- describir
- descrito
- descripción
- diseñado
- deseado
- detallado
- detalles
- detectar
- Determinar
- TELEKOM DEUTSCHE
- Developer
- desarrolladores
- el desarrollo
- Desarrollo
- diagnóstico
- diálogo
- Diálogo
- HIZO
- una experiencia diferente
- Difusión
- digital
- directamente
- distribuir
- distribuidos
- entrenamiento distribuido
- distribuido
- do
- documento
- documentación
- documentos
- sí
- No
- "Hacer"
- hecho
- No
- duplicación
- DE INSCRIPCIÓN
- el lado de la transmisión
- dos
- duplicados
- duración
- e
- comercio electrónico
- cada una
- Temprano en la
- más fácil
- pasan fácilmente
- Este
- Costa este
- de forma sencilla
- Ciencias económicas
- edición
- de manera eficaz
- eficiencia
- eficiente.
- esfuerzo
- ya sea
- más
- correo
- emisiones
- personas
- empoderar a
- empoderamiento
- habilitar
- permitiendo
- codificación
- encuentro
- final
- de extremo a extremo
- energía
- Consumo de energía
- eficiencia energética
- ingeniero
- Ingeniería
- mejorar
- mejoras
- enriquecedor
- Empresa
- grado empresarial
- empresas
- Entretenimiento
- Todo
- sobre
- Era
- ERP
- error
- Errores
- Éter (ETH)
- evaluaciones
- Incluso
- Eventos
- NUNCA
- Cada
- todos
- todo
- evolución
- evoluciona
- ejemplo
- ejemplos
- excitado
- emocionante
- ejecutar
- ejecutivos
- existente
- expansivo
- esperar
- acelerar
- costoso
- experience
- experimentado
- Experiencias
- experto
- Experiencia
- Explicar
- explorar
- expreso
- material
- Cara
- hecho
- factores importantes
- bastante
- fiel
- halcón
- Otoño
- familiar
- familias
- familia
- RÁPIDO
- más rápida
- defectuoso
- Feature
- Caracteristicas
- cuota
- realimentación
- pocos
- Presentación
- filtrar
- Finalmente
- financiero
- Encuentre
- la búsqueda de
- encuentra
- en fin
- acabado
- Nombre
- Fijar
- flexible
- centrado
- seguir
- Para consumidores
- adelante
- encontrado
- Fundación
- Digital XNUMXk
- fracción
- Marco conceptual
- marcos
- Gratuito
- frecuentemente
- amigable
- Desde
- funciones
- promover
- futuras
- juego
- cambio de juego
- juego de azar
- General
- en general
- generar
- genera
- la generación de
- generación de AHSS
- generativo
- IA generativa
- generador
- obtener
- conseguir
- Donar
- Buscar
- digitales globales
- gmail
- Go
- objetivo
- va
- candidato
- GPU
- GPU
- maravillosa
- Polo a Tierra
- innovador
- Grupo procesos
- Creciendo
- crecido
- guía
- guía
- orientaciones
- tenido
- Manos
- En Curso
- Difícil
- Materiales
- perjudicial
- odio
- el discurso del odio
- Tienen
- es
- Titulares
- la salud
- pesado
- levantar objetos pesados
- ayuda
- ayudando
- ayuda
- esta página
- Alta
- más alto
- más alto
- destacando
- altamente
- alquiler
- su
- hosting
- HORAS
- Cómo
- Como Hacer
- Sin embargo
- HTTPS
- Cientos
- i
- ID
- identidades
- Identidad
- ids
- if
- imagen
- generación de imágenes
- imágenes
- inmediata
- Impacto
- implementar
- implementaciones
- implementado
- importar
- importante
- impresionante
- mejorar
- mejorado
- mejoras
- in
- incluir
- incluye
- Incluye
- aumente
- aumentado
- creciente
- indicadores
- individuos
- industrias
- energético
- líderes en la industria
- influenciado
- info
- informar
- información
- EN LA MINA
- innovar
- innovando
- Innovation
- innovaciones
- originales
- Las opciones de entrada
- entradas
- penetración
- Insights
- ejemplo
- instancias
- Innovadora
- Instrucciones
- aseguradora
- integración
- propiedad
- la propiedad intelectual
- Intelligence
- tiene la intención
- interactuar
- interacciones
- interactúa
- interconectado
- Interfaz
- interno
- intervenir
- dentro
- introducir
- Introducido
- Presentamos
- inventado
- inventario
- Invertir
- investigador
- metas de
- inversión extranjera
- Inversiones
- involucra
- implica
- cuestiones
- IT
- Los profesionales de TI
- SUS
- Japonés
- jerga
- Java
- jpg
- solo
- tan siquiera solo una
- Guardar
- acuerdo
- Clave
- Areas clave
- las palabras claves
- kit
- Kit (SDK)
- Saber
- especialistas
- sabe
- labs
- Falta
- idioma
- large
- Gran escala
- mayor
- Apellido
- El año pasado
- Tarde
- Estado latente
- más reciente
- lanzado
- lanzamiento
- empresas
- .
- ponedoras
- Liderazgo
- líder
- APRENDE:
- aprendido
- aprendizaje
- Legal
- menos
- Permíteme
- Nivel
- Apalancamiento
- apalancamientos
- LexisNexis
- LG
- bibliotecas
- ciclo de vida
- cirugía estética
- como
- que otros
- limitaciones
- Limitada
- límites
- líneas
- LINK
- enlaces
- Lista
- para vivir
- Vidas
- Llama
- situados
- Ubicaciones
- lógico
- logo
- Largo
- de larga data
- Lote
- amar
- Baja
- inferior
- más bajo
- máquina
- máquina de aprendizaje
- hecho
- mantener
- el mantenimiento de
- un mejor mantenimiento.
- gran
- para lograr
- HACE
- Realizar
- gestionado
- Management
- Managers
- manual
- trabajo manual
- a mano
- muchos
- Marketing
- materiales
- materiales
- máximas
- Puede..
- me
- significativo
- significa
- Medios
- Conoce a
- reunión
- reuniones
- se une a la
- Miembros
- mero
- Meta
- Método
- Miami
- Microsoft
- Microsoft 365
- Ed. Media
- podría
- hito
- minutos
- perder
- misión
- ML
- modelo
- modelado
- modelos
- modernización
- Momentum
- MongoDB
- monitores
- Mes
- meses
- más,
- MEJOR DE TU
- Más popular
- emocionante
- MRI
- mucho más
- múltiples
- Música
- debe
- my
- nombre
- Nasdaq
- Natural
- Lenguaje natural
- Cerca
- necesario
- ¿ Necesita ayuda
- necesidad
- red
- del sistema,
- red
- Nuevo
- New York
- recién
- Next
- Nitro
- no
- ordenadores portátiles
- ahora
- número
- Nvidia
- of
- off
- ofensiva
- LANZAMIENTO
- que ofrece
- Ofertas
- a menudo
- mayor
- on
- una vez
- ONE
- las
- en línea
- banca en línea
- , solamente
- habiertos
- funcionar
- Operaciones
- Optimización
- optimizado
- optimizando
- Opciones
- or
- en pedidos de venta.
- organización
- para las fiestas.
- reconocida por
- Otro
- Otros
- nuestros
- salir
- contorno
- salida
- salidas
- Más de
- Abarrotar
- abrumadoramente
- EL DESARROLLADOR
- Paz
- paquetes
- doloroso
- pares
- parámetro
- parámetros
- parte
- socios
- partes
- pasado
- .
- pausa
- Personas
- para
- realizar
- actuación
- realizado
- realiza
- permiso
- permisos
- persona
- personalización
- personalizar
- Personalmente
- PGA Tour
- frases
- pii
- Colocar
- plan
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- más
- punto
- políticas
- Popular
- positivo
- posible
- Publicación
- posible
- industria
- alimentado
- poderoso
- Metodología
- prácticamente
- prácticas
- necesidad
- predecir
- Predicciones
- preferencias
- preparación
- Preparar
- presente
- presidente
- prensa
- prensado
- Vista previa
- previamente
- precio
- cotización
- primario
- política de privacidad
- Privacidad y Seguridad
- privada
- información privada
- Problema
- problemas
- en costes
- tratamiento
- producir
- Producto
- Producción
- productivo
- productividad
- Profesional
- profesionales
- Programas
- proyecto
- ideas
- perfecta
- propietario
- protector
- Protección
- proporcionar
- proveedor
- los proveedores
- proporciona un
- proporcionando
- público
- en público
- fines
- Push
- Emprendedor
- poner
- Poniendo
- Python
- piñón
- Q3
- XNUMX% automáticos
- pregunta
- Preguntas
- Búsqueda
- con rapidez
- exactamente
- I + D
- distancia
- rápido
- rápidamente
- Tarifas
- RE
- Reading
- real
- en tiempo real
- realista
- darse cuenta de
- realizado
- realmente
- siega
- razones
- recientemente
- Recomendación
- recomendaciones
- grabar
- reducir
- Reducción
- la reducción de
- FILTRO
- región
- liberado
- fiabilidad
- permanece
- remove
- la eliminación de
- reparación
- repetitivo
- reemplazo
- responder
- reporte
- repositorio
- solicita
- solicitudes
- Requisitos
- Requisitos
- la investigación
- reserva
- Reservar
- Resolución
- Resuena
- Recursos
- respeto
- Responder
- responder
- respuesta
- respuestas
- responsable
- restringir
- límite
- resultado
- Resultados
- volver
- una estrategia SEO para aparecer en las búsquedas de Google.
- la revisión
- Derecho
- riesgos
- Función
- También soy miembro del cuerpo docente de World Extreme Medicine (WEM) y embajadora europea de igualdad para The Transformational Travel Council (TTC). En mi tiempo libre, soy una incansable aventurera, escaladora, patrona de día, buceadora y defensora de la igualdad de género en el deporte y la aventura. En XNUMX, fundé Almas Libres, una ONG nacida para involucrar, educar y empoderar a mujeres y niñas a través del deporte urbano, la cultura y la tecnología.
- Habitaciones
- rutas
- Regla
- Ejecutar
- correr
- pista
- sacrificando
- ambiente seguro
- salvaguardias
- de manera segura
- sabio
- ventas
- fuerza de ventas
- mismo
- satisfacción
- Guardar
- decir
- Escala
- la ampliación
- escenarios
- alcance
- puntuaciones
- rayar
- Sdk
- sin costura
- Buscar
- Segundo
- Segunda generación
- segundos
- seguro
- segura
- EN LINEA
- ver
- ver
- visto
- selecciona
- seleccionado
- selección
- enviando
- mayor
- liderazgo experimentado
- sensible
- Septiembre
- Secuencia
- Serie
- servidores
- de coches
- Servicios
- set
- Sets
- Varios
- Compartir
- compartido
- enviar
- En Corto
- tienes
- lado
- importante
- Silicio
- Del mismo modo
- sencillos
- simplificar
- simplemente
- desde
- SEIS
- tamaños
- flojo
- chica
- So
- Social
- redes sociales
- Software
- Desarrolladores de software
- Desarrollo de software ad-hoc
- Kit de desarrollo de software
- a medida
- Soluciones
- RESOLVER
- algo
- Alguien
- algo
- Pronto
- sofisticado
- Fuente
- código fuente
- Fuentes
- sudeste
- Espacio
- Spark
- específicamente
- habla
- velocidad
- pasar
- Estabilidad
- estable
- montón
- apilado
- las partes interesadas
- fundó
- Comience a
- Startups
- el estado de la técnica
- quedarse
- paso
- pasos
- Sin embargo
- STORAGE
- tienda
- tiendas
- Historias
- Storm
- Historia
- aerodinamizar
- FORTALECIMIENTO
- riguroso
- estructura
- ESTUDIO
- subred
- sustancial
- tal
- adecuado
- suite
- resumir
- RESUMEN
- súper
- complementar
- proveedores
- suministro
- Oferta y demanda
- cadena de suministro
- SOPORTE
- soportes
- seguro
- sorprendente
- vigilancia
- suspicaz
- Sostenibilidad
- Switch
- sintetizar
- te
- Todas las funciones a su disposición
- mesa
- adaptado
- ¡Prepárate!
- toma
- toma
- escuchar
- Target
- Tarea
- tareas
- equipo
- Miembros del equipo
- equipos
- Técnico
- la técnica
- técnicas
- Tecnologías
- Tecnología
- innovación tecnológica
- les digas
- narración
- diez
- tener
- tensorflow
- terminología
- test
- Pruebas
- pruebas
- texto
- generación de texto
- que
- esa
- La
- El futuro de las
- el mundo
- su
- Les
- sí mismos
- luego
- Ahí.
- Estas
- ellos
- cosa
- cosas
- pensar
- Código
- así
- este año
- aquellos
- miles
- Tres
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- a lo largo de
- rendimiento
- boleto
- entradas
- equipo
- veces
- titán
- a
- hoy
- de hoy
- juntos
- ficha
- demasiado
- se
- del IRS
- parte superior
- Temas
- TOURS
- hacia
- hacia
- seguir
- Plataforma de
- Entrenar
- entrenado
- Formación
- Transacciones
- Expediente académico
- Transformar
- transformaciones
- transformadora
- viajes
- billones
- viaje
- verdaderamente
- Confía en
- try
- tratando de
- se convierte
- dos
- tipo
- típicamente
- subyacente
- entender
- comprensible
- comprensión
- entiende
- desconocido
- unificado
- único
- características unicas
- unidad
- diferente a
- hasta
- Actualizar
- Actualizaciones
- actualizar
- actualizaciones
- us
- Uso
- utilizan el
- caso de uso
- usado
- Usuario
- usuarios
- usos
- usando
- Valioso
- variedad
- diversos
- versión
- Versus
- muy
- vía
- vicio
- Vice Presidenta
- Video
- virtualmente
- visualización
- visualizar
- visualmente
- volúmenes
- Vulnerable
- quieres
- Warner
- grupo de musica warner
- fue
- Trenzado
- Camino..
- formas
- we
- web
- Aplicación web
- servicios web
- sitios web
- semana
- Semanas
- bienvenido
- WELL
- bien conocido
- tuvieron
- ¿
- Que es
- cuando
- sean
- que
- mientras
- QUIENES
- porque
- amplio
- Amplia gama
- más ancho
- seguirá
- ventana
- dentro de
- sin
- Actividades:
- trabajado
- flujos de trabajo
- trabajando
- funciona
- mundo
- clase mundial
- preocuparse
- valor
- se
- escribir
- escribir código
- la escritura
- año
- años
- york
- Usted
- tú
- Zendesk
- zephyrnet