Estudio de pegamento de AWS es una interfaz gráfica que facilita la creación, ejecución y supervisión de trabajos de extracción, transformación y carga (ETL) en Pegamento AWS. Le permite componer visualmente flujos de trabajo de transformación de datos utilizando nodos que representan diferentes pasos de manejo de datos, que luego se convierten automáticamente en código para ejecutar.
Estudio de pegamento de AWS lanzado recientemente 10 transformaciones visuales más para permitir la creación de trabajos más avanzados de forma visual sin conocimientos de codificación. En esta publicación, discutimos casos de usos potenciales que reflejan las necesidades comunes de ETL.
Las nuevas transformaciones que se demostrarán en esta publicación son: Concatenar, Dividir cadena, Matriz a columnas, Agregar marca de tiempo actual, Pivotar filas a columnas, Despivotar columnas a filas, Buscar, Explotar matriz o mapa en columnas, Columna derivada y Procesamiento de autoequilibrio .
Resumen de la solución
En este caso de uso, tenemos algunos archivos JSON con operaciones de opciones sobre acciones. Queremos hacer algunas transformaciones antes de almacenar los datos para que sea más fácil de analizar, y también queremos producir un resumen del conjunto de datos por separado.
En este conjunto de datos, cada fila representa una operación de contratos de opciones. Las opciones son instrumentos financieros que otorgan el derecho, pero no la obligación, de comprar o vender acciones a un precio fijo (llamado precio del ejercicio) antes de una fecha de vencimiento definida.
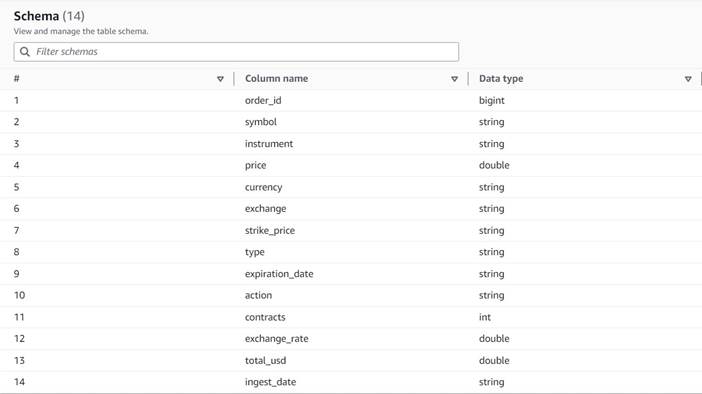
Datos de entrada
Los datos siguen el siguiente esquema:
- Solicitar ID – Una identificación única
- símbolo – Un código generalmente basado en unas pocas letras para identificar a la corporación que emite las acciones subyacentes
- instrumento – El nombre que identifica la opción específica que se compra o vende
- moneda – El código de moneda ISO en el que se expresa el precio
- precio – El monto que se pagó por la compra de cada contrato de opción (en la mayoría de los intercambios, un contrato le permite comprar o vender 100 acciones)
- Intercambio – El código del centro o recinto cambiario donde se negoció la opción
- vendido – Una lista de la cantidad de contratos que se asignaron para completar la orden de venta cuando se trata de una operación de venta
- compró – Una lista de la cantidad de contratos que se asignaron para completar la orden de compra cuando se trata de una operación de compra
La siguiente es una muestra de los datos sintéticos generados para esta publicación:
Requisitos ETL
Estos datos tienen una serie de características únicas, como se encuentran a menudo en los sistemas más antiguos, que hacen que los datos sean más difíciles de usar.
Los siguientes son los requisitos de ETL:
- El nombre del instrumento tiene información valiosa que está destinada a que los humanos la entiendan; queremos normalizarlo en columnas separadas para facilitar el análisis.
- Los atributos
boughtysoldson mutuamente excluyentes; podemos consolidarlos en una sola columna con los números de contrato y tener otra columna que indique si los contratos fueron comprados o vendidos en este orden. - Queremos mantener la información sobre las asignaciones de contratos individuales, pero como filas individuales en lugar de obligar a los usuarios a tratar con una serie de números. Podríamos sumar los números, pero perderíamos información sobre cómo se ejecutó la orden (lo que indica la liquidez del mercado). En su lugar, elegimos desnormalizar la tabla para que cada fila tenga un solo número de contratos, dividiendo los pedidos con varios números en filas separadas. En un formato de columna comprimido, el tamaño adicional del conjunto de datos de esta repetición suele ser pequeño cuando se aplica la compresión, por lo que es aceptable hacer que el conjunto de datos sea más fácil de consultar.
- Queremos generar una tabla resumen de volumen para cada tipo de opción (call y put) para cada acción. Esto proporciona una indicación del sentimiento del mercado para cada acción y el mercado en general (avaricia frente a miedo).
- Para habilitar los resúmenes comerciales generales, queremos proporcionar para cada operación el total general y estandarizar la moneda a dólares estadounidenses, utilizando una referencia de conversión aproximada.
- Queremos agregar la fecha en que se produjeron estas transformaciones. Esto podría ser útil, por ejemplo, para tener una referencia de cuándo se realizó la conversión de moneda.
Según esos requisitos, el trabajo producirá dos resultados:
- Un archivo CSV con un resumen de la cantidad de contratos para cada símbolo y tipo
- Una tabla de catálogo para llevar un histórico del pedido, después de hacer las transformaciones indicadas
Requisitos previos
Necesitará su propio depósito S3 para seguir este caso de uso. Para crear un nuevo depósito, consulte Crear un cubo.
Generar datos sintéticos
Para seguir esta publicación (o experimentar con este tipo de datos por su cuenta), puede generar este conjunto de datos sintéticamente. El siguiente script de Python se puede ejecutar en un entorno de Python con Boto3 instalado y acceso a Servicio de almacenamiento simple de Amazon (Amazon S3).
Para generar los datos, complete los siguientes pasos:
- En AWS Glue Studio, cree un nuevo trabajo con la opción Editor de secuencias de comandos de shell de Python.
- Asigne un nombre al trabajo y en la Detalles del trabajo pestaña, seleccione una papel adecuado y un nombre para el script de Python.
- En Detalles del trabajo sección, ampliar Propiedades avanzadas Y desplácese hacia abajo hasta Parámetros de trabajo.
- Ingrese un parámetro llamado
--buckety asigne como valor el nombre del depósito que desea usar para almacenar los datos de muestra. - Ingrese el siguiente script en el editor de shell de AWS Glue:
- Ejecute el trabajo y espere hasta que se muestre como completado con éxito en la pestaña Ejecuciones (debe tomar solo unos segundos).
Cada ejecución generará un archivo JSON con 1,000 filas bajo el depósito especificado y el prefijo transformsblog/inputdata/. Puede ejecutar el trabajo varias veces si desea probar con más archivos de entrada.
Cada línea de los datos sintéticos es una fila de datos que representa un objeto JSON como el siguiente:
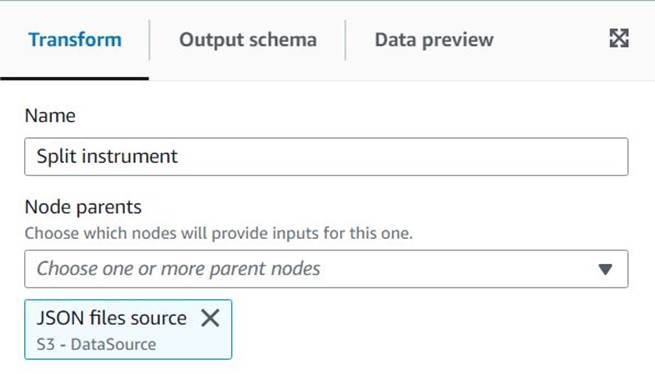
Cree el trabajo visual de AWS Glue
Para crear el trabajo visual de AWS Glue, complete los siguientes pasos:
- Vaya a AWS Glue Studio y cree un trabajo usando la opción Visual con un lienzo en blanco.
- Editar
Untitled jobpara darle un nombre y asignar un rol adecuado para AWS Glue en Detalles del trabajo . - Agregue una fuente de datos S3 (puede nombrarla
JSON files source) e ingrese la URL de S3 en la que se almacenan los archivos (por ejemplo,s3://<your bucket name>/transformsblog/inputdata/), luego seleccione JSON como formato de datos. - Seleccione Inferir esquema por lo que establece el esquema de salida en función de los datos.
Desde este nodo de origen, seguirás encadenando transformaciones. Al agregar cada transformación, asegúrese de que el nodo seleccionado sea el último agregado para que se asigne como principal, a menos que se indique lo contrario en las instrucciones.
Si no seleccionó el padre correcto, siempre puede editar el padre seleccionándolo y eligiendo otro padre en el panel de configuración.
Para cada nodo agregado, le dará un nombre específico (para que el propósito del nodo se muestre en el gráfico) y una configuración en el Transformar .
Cada vez que una transformación cambia el esquema (por ejemplo, agrega una nueva columna), el esquema de salida debe actualizarse para que sea visible para las transformaciones posteriores. Puede editar manualmente el esquema de salida, pero es más práctico y seguro hacerlo usando la vista previa de datos.
Además, de esa manera puede verificar que la transformación esté funcionando como se esperaba. Para ello, abra el Vista previa de datos pestaña con la transformación seleccionada e iniciar una sesión de vista previa. Después de haber verificado que los datos transformados se ven como se esperaba, vaya a la esquema de salida pestaña y elegir Usar esquema de vista previa de datos para actualizar el esquema automáticamente.
A medida que agrega nuevos tipos de transformaciones, la vista previa puede mostrar un mensaje sobre una dependencia que falta. Cuando esto suceda, elija Finalizar sesión y el inicio de uno nuevo, por lo que la vista previa recoge el nuevo tipo de nodo.
Extraer información del instrumento
Comencemos tratando con la información sobre el nombre del instrumento para normalizarlo en columnas a las que sea más fácil acceder en la tabla de salida resultante.
- Agrega una Cadena dividida nodo y nombrarlo
Split instrument, que tokenizará la columna del instrumento usando una expresión regular de espacio en blanco:s+(un solo espacio serviría en este caso, pero de esta manera es más flexible y visualmente más claro). - Queremos mantener la información del instrumento original como está, así que ingrese un nuevo nombre de columna para la matriz dividida:
instrument_arr.
- Añadir un Matriz a columnas nodo y nombrarlo
Instrument columnspara convertir la columna de matriz recién creada en nuevos campos, a excepción desymbol, para el que ya tenemos una columna. - Seleccione la columna
instrument_arr, omita el primer token y dígale que extraiga las columnas de salidamonth, day, year, strike_price, typeusando índices2, 3, 4, 5, 6(los espacios después de las comas son para facilitar la lectura, no afectan la configuración).
El año extraído se expresa con sólo dos dígitos; pongamos un recurso provisional para suponer que es en este siglo si solo usan dos dígitos.
- Agrega una Columna derivada nodo y nombrarlo
Four digits year. - Participar
yearcomo la columna derivada para que la anule e ingrese la siguiente expresión SQL:CASE WHEN length(year) = 2 THEN ('20' || year) ELSE year END
Para mayor comodidad, construimos un expiration_date campo que un usuario puede tener como referencia de la última fecha en que puede ejercer la opción.
- Agrega una Concatenar columnas nodo y nombrarlo
Build expiration date. - Nombra la nueva columna
expiration_date, seleccione las columnasyear,monthyday(en ese orden), y un guión como espaciador.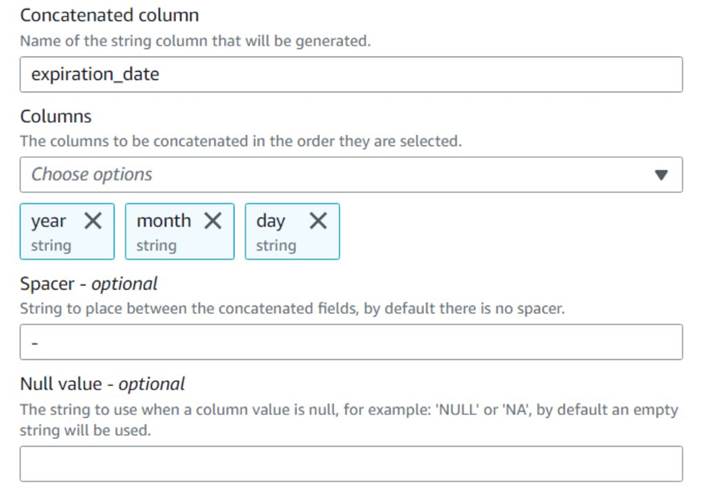
El diagrama hasta ahora debería parecerse al siguiente ejemplo.
![]()
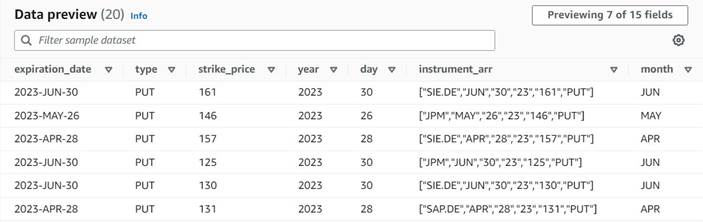
La vista previa de datos de las nuevas columnas hasta el momento debería parecerse a la siguiente captura de pantalla.
Normalizar el número de contratos
Cada una de las filas de los datos indica el número de contratos de cada opción que se compraron o vendieron y los lotes en los que se completaron las órdenes. Sin perder la información sobre los lotes individuales, queremos tener cada cantidad en una fila individual con un solo valor de cantidad, mientras que el resto de la información se replica en cada fila producida.
Primero, combinemos las cantidades en una sola columna.
- Añadir un Deshacer el pivote de columnas en filas nodo y nombrarlo
Unpivot actions. - Elige las columnas
boughtysoldpara anular el pivote y almacenar los nombres y valores en columnas denominadasactionycontracts, respectivamente.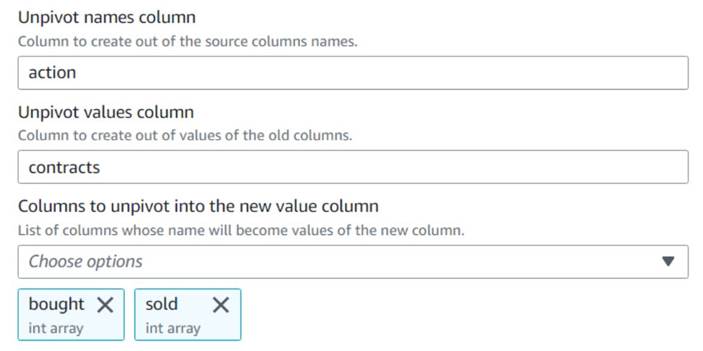
Observe en la vista previa que la nueva columnacontractssigue siendo una matriz de números después de esta transformación.
- Añadir un Explotar matriz o mapa en filas fila nombrada
Explode contracts. - Elija el
contractscolumna y entrarcontractscomo la nueva columna para anularla (no es necesario mantener la matriz original).
La vista previa ahora muestra que cada fila tiene un solo contracts cantidad, y el resto de los campos son iguales.
Esto también significa que order_id ya no es una clave única. Para sus propios casos de uso, debe decidir cómo modelar sus datos y si desea desnormalizarlos o no.
La siguiente captura de pantalla es un ejemplo de cómo se ven las nuevas columnas después de las transformaciones hasta el momento.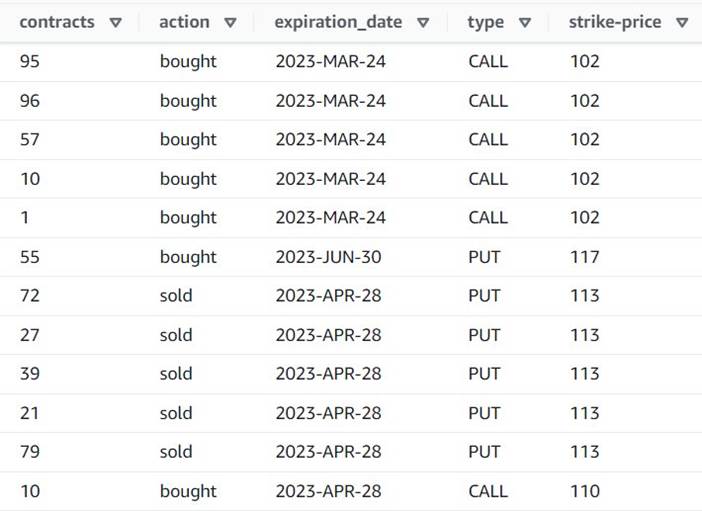
Crear una tabla de resumen
Ahora crea una tabla de resumen con la cantidad de contratos negociados para cada tipo y cada símbolo bursátil.
Supongamos con fines ilustrativos que los archivos procesados pertenecen a un solo día, por lo que este resumen brinda a los usuarios comerciales información sobre cuál es el interés y el sentimiento del mercado ese día.
- Agrega una Seleccionar campos y seleccione las siguientes columnas para conservar el resumen:
symbol,typeycontracts.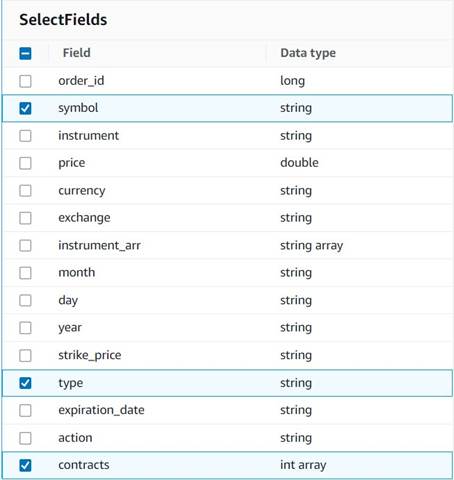
- Agrega una Pivotar filas en columnas nodo y nombrarlo
Pivot summary. - agregado en el
contractscolumna usandosumy elija convertir eltypecolumna.
Normalmente, lo almacenaría en alguna base de datos o archivo externo como referencia; en este ejemplo, lo guardamos como un archivo CSV en Amazon S3.
- Añadir un Procesamiento de autoequilibrado nodo y nombrarlo
Single output file. - Aunque ese tipo de transformación se usa normalmente para optimizar el paralelismo, aquí lo usamos para reducir la salida a un solo archivo. Por lo tanto, ingrese
1en la configuración del número de particiones.
- Agregue un destino S3 y asígnele un nombre
CSV Contract summary. - Elija CSV como formato de datos e ingrese una ruta de S3 donde el rol de trabajo puede almacenar archivos.
La última parte del trabajo ahora debería parecerse al siguiente ejemplo.![]()
- Guarde y ejecute el trabajo. Utilizar el Ron pestaña para verificar cuando ha terminado con éxito.
Encontrará un archivo en esa ruta que es un CSV, a pesar de no tener esa extensión. Probablemente necesitará agregar la extensión después de descargarla para abrirla.
En una herramienta que puede leer el CSV, el resumen debería parecerse al siguiente ejemplo.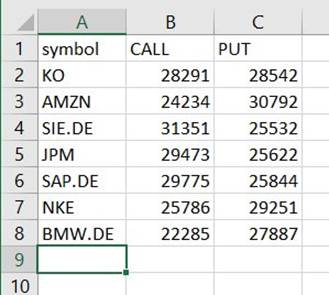
Limpiar columnas temporales
En preparación para guardar los pedidos en una tabla histórica para un análisis futuro, limpie algunas columnas temporales creadas en el camino.
- Agrega una Soltar campos nodo con el
Explode contractsnodo seleccionado como su padre (estamos ramificando la canalización de datos para generar una salida separada). - Seleccione los campos a descartar:
instrument_arr,month,dayyyear.
El resto lo queremos conservar para que quede guardado en la tabla histórica que crearemos más adelante.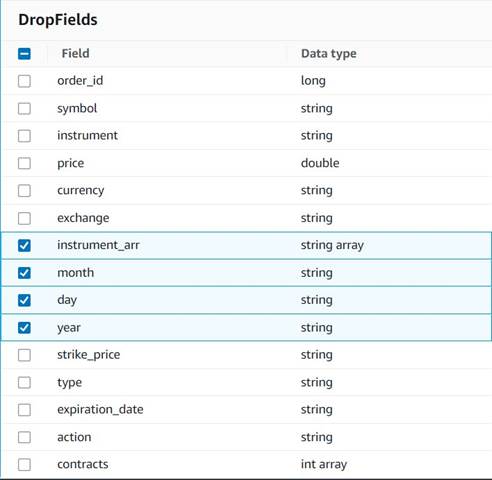
Estandarización de moneda
Estos datos sintéticos contienen operaciones ficticias en dos monedas, pero en un sistema real podría obtener monedas de mercados de todo el mundo. Es útil estandarizar las monedas manejadas en una sola moneda de referencia para que puedan compararse y agregarse fácilmente para informes y análisis.
Utilizamos Atenea amazónica para simular una tabla con conversiones de divisas aproximadas que se actualiza periódicamente (aquí asumimos que procesamos las órdenes lo suficientemente a tiempo como para que la conversión sea un representante razonable para propósitos de comparación).
- Abra la consola de Athena en la misma región en la que utiliza AWS Glue.
- Ejecute la siguiente consulta para crear la tabla configurando una ubicación de S3 donde sus roles de Athena y AWS Glue puedan leer y escribir. Además, es posible que desee almacenar la tabla en una base de datos diferente a la
default(si lo hace, actualice el nombre completo de la tabla según corresponda en los ejemplos proporcionados). - Ingrese algunas conversiones de muestra en la tabla:
INSERT INTO default.exchange_rates VALUES ('usd', 1.0), ('eur', 1.09), ('gbp', 1.24); - Ahora debería poder ver la tabla con la siguiente consulta:
SELECT * FROM default.exchange_rates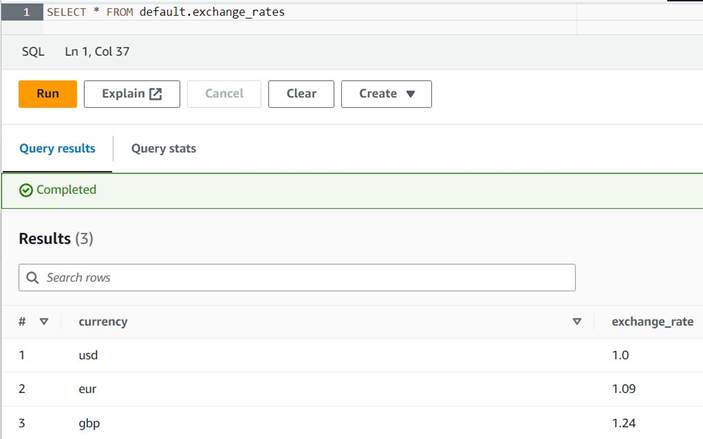
- De vuelta en el trabajo visual de AWS Glue, agregue un Lookup nodo (como hijo de
Drop Fields) y llámaloExchange rate. - Ingrese el nombre calificado de la tabla que acaba de crear, usando
currencycomo tecla y seleccione laexchange_ratecampo a utilizar.
Debido a que el campo tiene el mismo nombre tanto en los datos como en la tabla de búsqueda, solo podemos ingresar el nombrecurrencyy no es necesario definir una asignación.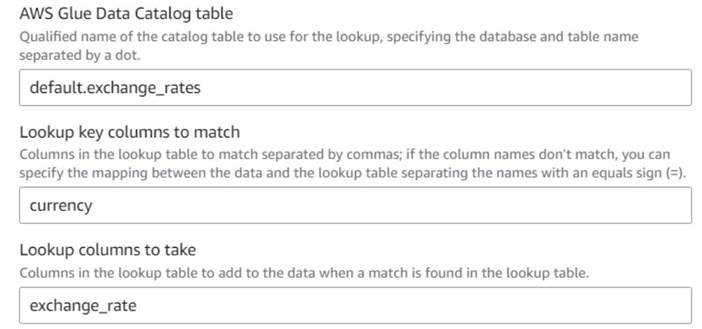
En el momento de escribir este artículo, la transformación de búsqueda no se admite en la vista previa de datos y mostrará un error de que la tabla no existe. Esto es solo para la vista previa de datos y no impide que el trabajo se ejecute correctamente. Los pocos pasos restantes de la publicación no requieren que actualice el esquema. Si necesita ejecutar una vista previa de datos en otros nodos, puede eliminar el nodo de búsqueda temporalmente y luego volver a colocarlo. - Agrega una Columna derivada nodo y nombrarlo
Total in usd. - Asigne un nombre a la columna derivada
total_usdy utilice la siguiente expresión SQL:round(contracts * price * exchange_rate, 2)
- Agrega una Agregar marca de tiempo actual nodo y nombre la columna
ingest_date. - Usa el formato
%Y-%m-%dpara su marca de tiempo (para fines de demostración, solo estamos usando la fecha; puede hacerlo más preciso si lo desea).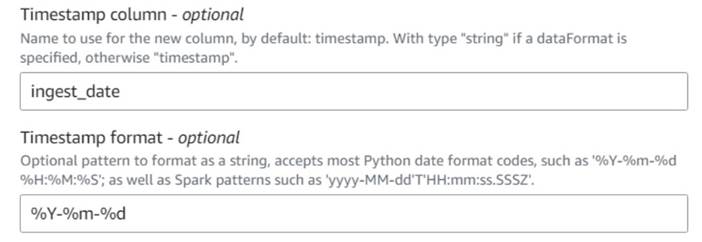
Guardar la tabla histórica de pedidos
Para guardar la tabla de pedidos históricos, complete los siguientes pasos:
- Agregue un nodo de destino de S3 y asígnele un nombre
Orders table. - Configure el formato Parquet con una compresión rápida y proporcione una ruta de destino de S3 bajo la cual almacenar los resultados (separados del resumen).
- Seleccione Cree una tabla en el catálogo de datos y, en ejecuciones posteriores, actualice el esquema y agregue nuevas particiones.
- Introduzca una base de datos de destino y un nombre para la nueva tabla, por ejemplo:
option_orders.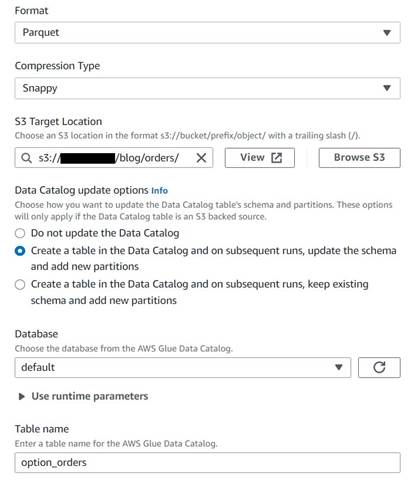
La última parte del diagrama ahora debería verse similar a la siguiente, con dos ramas para las dos salidas separadas.![]()
Después de ejecutar el trabajo correctamente, puede usar una herramienta como Athena para revisar los datos que ha producido el trabajo consultando la nueva tabla. Puede encontrar la tabla en la lista de Athena y elegir Tabla de vista previa o simplemente ejecute una consulta SELECT (actualizando el nombre de la tabla al nombre y catálogo que usó):
SELECT * FROM default.option_orders limit 10
El contenido de su tabla debe ser similar a la siguiente captura de pantalla.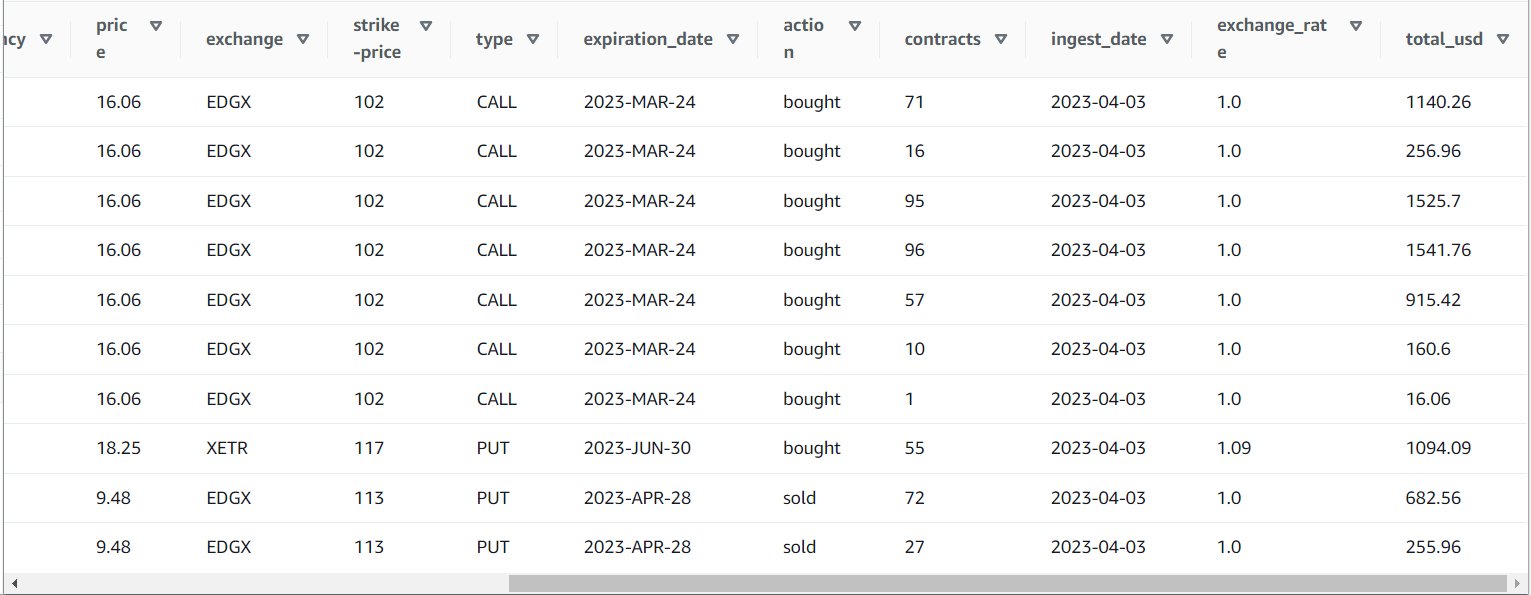
Limpiar
Si no desea mantener este ejemplo, elimine los dos trabajos que creó, las dos tablas en Athena y las rutas de S3 donde se almacenaron los archivos de entrada y salida.
Conclusión
En esta publicación, mostramos cómo las nuevas transformaciones en AWS Glue Studio pueden ayudarlo a realizar transformaciones más avanzadas con una configuración mínima. Esto significa que puede implementar más casos de uso de ETL sin tener que escribir ni mantener ningún código. Las nuevas transformaciones ya están disponibles en AWS Glue Studio, por lo que puede usar las nuevas transformaciones hoy en sus trabajos visuales.
Acerca del autor.
![]() gonzalo herreros es Arquitecto Senior de Big Data en el equipo de AWS Glue.
gonzalo herreros es Arquitecto Senior de Big Data en el equipo de AWS Glue.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Compra y Vende Acciones en Empresas PRE-IPO con PREIPO®. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/ten-new-visual-transforms-in-aws-glue-studio/
- :posee
- :es
- :no
- :dónde
- $ UP
- 000
- 1
- 10
- 100
- 102
- 11
- 12
- 13
- 14
- 15%
- 20
- 23
- 24
- 26
- 28
- 30
- 49
- 67
- 7
- 8
- 9
- 937
- 98
- a
- Poder
- Nuestra Empresa
- aceptable
- de la máquina
- en consecuencia
- add
- adicional
- la adición de
- avanzado
- Después
- Todos
- asignado
- asignaciones
- permitir
- permite
- a lo largo de
- ya haya utilizado
- también
- hacerlo
- Amazon
- cantidad
- cantidades
- an
- análisis
- analizar
- y
- Otra
- cualquier
- aplicada
- aproximado
- abr
- somos
- argumento
- Formación
- AS
- asigna
- At
- atributos
- automáticamente
- Hoy Disponibles
- AWS
- Pegamento AWS
- Atrás
- basado
- BE
- antes
- "Ser"
- Big
- Big Data
- en blanco
- BMW
- ambas
- compró
- sucursales
- build
- pero
- comprar
- by
- llamar al
- PUEDEN
- case
- cases
- catalogar
- Reubicación
- Siglo
- Cambios
- características
- comprobar
- sus hijos
- Elige
- la elección de
- más clara
- código
- Codificación
- Columna
- Columnas
- Algunos
- en comparación con
- comparación
- completar
- Completado
- Configuración
- Consola
- consolidar
- contiene
- contenido
- contrato
- contratos
- comodidad
- Conversión
- conversiones
- convertir
- convertido
- CORPORACIÓN
- podría
- Para crear
- creado
- Creamos
- monedas
- Moneda
- Current
- DÍA
- datos
- Base de datos
- Fecha
- Fechas
- datetime
- día
- acuerdo
- tratar
- decidir
- Predeterminado
- se define
- demostrado
- Dependencia
- Derivado
- A pesar de las
- detalles
- una experiencia diferente
- dígitos
- discutir
- do
- No
- "Hacer"
- dólares
- No
- doble
- DE INSCRIPCIÓN
- Soltar
- caído
- cada una
- más fácil
- pasan fácilmente
- de forma sencilla
- editor
- habilitar
- suficientes
- Participar
- Entorno
- error
- Éter (ETH)
- EUR
- ejemplo
- ejemplos
- Excepto
- Intercambio
- Cambios
- Exclusiva
- existe
- Expandir
- esperado
- experimento
- caducidad
- expresados
- extensión
- externo
- extra
- extraerlos
- muchos
- miedo
- pocos
- ficticio
- campo
- Terrenos
- Archive
- archivos
- llenar
- lleno
- financiero
- Instrumentos financieros
- Encuentre
- Nombre
- fijas
- flexible
- seguir
- siguiendo
- siguiente
- formato
- encontrado
- en
- futuras
- GBP
- General
- en general
- generar
- generado
- obtener
- Donar
- da
- Go
- gráfica
- Codicia
- Manejo
- que sucede
- Tienen
- es
- ayuda
- esta página
- histórico
- historia
- Cómo
- Como Hacer
- HTML
- http
- HTTPS
- Humanos
- i
- identifica
- Identifique
- if
- Impacto
- implementar
- importar
- in
- índices
- indicado
- Indica
- indicando
- indicación
- INSTRUMENTO individual
- información
- Las opciones de entrada
- ejemplo
- Instrucciones
- instrumento
- instrumentos
- intereses
- Interfaz
- dentro
- ISO
- IT
- SUS
- Trabajos
- Empleo
- jpg
- json
- solo
- Guardar
- Clave
- Tipo
- Apellido
- luego
- como
- LIMITE LAS
- línea
- Liquidez
- Lista
- carga
- Ubicación
- por más tiempo
- Mira
- parece
- MIRADAS
- búsqueda
- perder
- no logras
- hecho
- mantener
- para lograr
- HACE
- a mano
- mapa
- cartografía
- Mercado
- el sentimiento del mercado
- Industrias
- Puede..
- significa
- ir
- mensaje
- podría
- mínimo
- que falta
- modelo
- Monitorear
- más,
- MEJOR DE TU
- múltiples
- mutuamente
- nombre
- Llamado
- nombres
- ¿ Necesita ayuda
- Nuevo
- no
- nodo
- nodos
- normalmente
- ahora
- número
- números
- objeto
- of
- a menudo
- on
- ONE
- , solamente
- habiertos
- Inteligente
- Operaciones
- Optimización
- Optión
- Opciones
- or
- solicite
- en pedidos de venta.
- reconocida por
- Otro
- de otra manera
- salida
- Más de
- total
- anular
- EL DESARROLLADOR
- dinero
- cristal
- parámetro
- parte
- camino
- Selecciones
- industrial
- Pivot
- Colocar
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- Publicación
- posible
- Metodología
- necesidad
- evitar
- Vista previa
- precio
- probablemente
- tratamiento
- producir
- producido
- proporcionar
- previsto
- proporciona un
- comprar
- propósito
- fines
- poner
- Python
- calificado
- aumento
- azar
- Leer
- real
- mejor
- reducir
- reflejar
- región
- restante
- remove
- replicado
- Informes
- representar
- representante
- que representa
- representa
- exigir
- Requisitos
- requiere
- respectivamente
- RESTO
- resultante
- Resultados
- una estrategia SEO para aparecer en las búsquedas de Google.
- Función
- También soy miembro del cuerpo docente de World Extreme Medicine (WEM) y embajadora europea de igualdad para The Transformational Travel Council (TTC). En mi tiempo libre, soy una incansable aventurera, escaladora, patrona de día, buceadora y defensora de la igualdad de género en el deporte y la aventura. En XNUMX, fundé Almas Libres, una ONG nacida para involucrar, educar y empoderar a mujeres y niñas a través del deporte urbano, la cultura y la tecnología.
- FILA
- Ejecutar
- correr
- Safer
- mismo
- savia
- Guardar
- ahorro
- mover
- segundos
- seleccionado
- seleccionar
- venta
- mayor
- sentimiento
- separado
- Sesión
- Sets
- pólipo
- Acciones
- Cáscara
- tienes
- Mostrar
- Shows
- similares
- sencillos
- soltero
- Tamaño
- habilidades
- chica
- So
- hasta aquí
- vendido
- algo
- algo
- Fuente
- Espacio
- espacios
- soluciones y
- especificado
- dividido
- Hoja de cálculo
- SQL
- comienzo
- pasos
- Sin embargo
- en stock
- STORAGE
- tienda
- almacenados
- Cordón
- estudio
- posterior
- Con éxito
- adecuado
- RESUMEN
- Soportado
- símbolo
- sintético
- datos sintéticos
- sintéticamente
- te
- Todas las funciones a su disposición
- mesa
- ¡Prepárate!
- Target
- equipo
- les digas
- temporal
- diez
- test
- que
- esa
- El
- La gráfica
- la información
- el mundo
- Les
- luego
- por lo tanto
- Estas
- ellos
- así
- aquellos
- equipo
- veces
- fecha y hora
- a
- hoy
- ficha
- tokenize
- se
- del IRS
- Total
- comercio
- negocian
- Transformar
- transformaciones
- transformado
- dos
- tipo
- bajo
- subyacente
- entender
- único
- hasta
- Actualizar
- actualizado
- actualización
- Enlance
- us
- Dólares estadounidenses
- USD
- utilizan el
- caso de uso
- usado
- Usuario
- usuarios
- usando
- Valioso
- Información valiosa
- propuesta de
- Valores
- Información
- verificadas
- verificar
- Ver
- visibles
- volumen
- vs
- esperar
- quieres
- fue
- Camino..
- we
- tuvieron
- ¿
- cuando
- que
- mientras
- seguirá
- sin
- flujos de trabajo
- trabajando
- mundo
- se
- escribir
- la escritura
- año
- Usted
- tú
- zephyrnet











