
Imagen creada con DALL-E3
La Inteligencia Artificial ha supuesto una completa revolución en el mundo tecnológico.
Su capacidad para imitar la inteligencia humana y realizar tareas que alguna vez se consideraron dominios exclusivamente humanos todavía nos sorprende a la mayoría de nosotros.
Sin embargo, no importa cuán buenos hayan sido estos últimos avances de la IA, siempre hay margen de mejora.
¡Y aquí es precisamente donde entra en juego la ingeniería rápida!
Ingrese a este campo que puede mejorar significativamente la productividad de los modelos de IA.
¡Descubrámoslo todos juntos!
La ingeniería rápida es un dominio de rápido crecimiento dentro de la IA que se centra en mejorar la eficiencia y eficacia de los modelos de lenguaje. Se trata de crear indicaciones perfectas para guiar a los modelos de IA y producir los resultados deseados.
Piense en ello como aprender a dar mejores instrucciones a alguien para asegurarse de que comprenda y ejecute una tarea correctamente.
Por qué es importante la ingeniería rápida
- Productividad mejorada: Al utilizar indicaciones de alta calidad, los modelos de IA pueden generar respuestas más precisas y relevantes. Esto significa menos tiempo dedicado a las correcciones y más tiempo aprovechando las capacidades de la IA.
- Eficiencia de costo: El entrenamiento de modelos de IA requiere muchos recursos. La ingeniería rápida puede reducir la necesidad de volver a capacitarse al optimizar el rendimiento del modelo a través de mejores indicaciones.
- Versatilidad: Un mensaje bien elaborado puede hacer que los modelos de IA sean más versátiles, permitiéndoles abordar una gama más amplia de tareas y desafíos.
Antes de sumergirnos en las técnicas más avanzadas, recordemos dos de las técnicas de ingeniería rápida más útiles (y básicas).
Pensamiento Secuencial con “Pensemos paso a paso”
Hoy en día es bien sabido que la precisión de los modelos LLM mejora significativamente al agregar la secuencia de palabras "Pensemos paso a paso".
¿Por qué… podrías preguntarte?
Bueno, esto se debe a que estamos obligando al modelo a dividir cualquier tarea en varios pasos, asegurándonos así de que el modelo tenga tiempo suficiente para procesar cada uno de ellos.
Por ejemplo, podría desafiar GPT3.5 con el siguiente mensaje:
Si John tiene 5 peras, luego come 2, compra 5 más y luego le da 3 a su amigo, ¿cuántas peras tiene?
El modelo me dará una respuesta de inmediato. Sin embargo, si agrego el final “Pensemos paso a paso”, estoy obligando al modelo a generar un proceso de pensamiento con múltiples pasos.
Indicaciones de pocos intentos
Mientras que las indicaciones de disparo cero se refieren a pedirle al modelo que realice una tarea sin proporcionar ningún contexto o conocimiento previo, la técnica de indicaciones de pocos disparos implica que presentamos al LLM algunos ejemplos de nuestro resultado deseado junto con alguna pregunta específica.
Por ejemplo, si queremos idear un modelo que defina cualquier término usando un tono poético, puede resultar bastante difícil de explicar. ¿Bien?
Sin embargo, podríamos utilizar las siguientes indicaciones de algunos disparos para dirigir el modelo en la dirección que queremos.
Su tarea es responder en un estilo consistente alineado con el siguiente estilo.
: Enséñame sobre la resiliencia.
: La resiliencia es como un árbol que se dobla con el viento pero nunca se rompe.
Es la capacidad de recuperarse de la adversidad y seguir avanzando.
: Su entrada aquí.
Si aún no lo has probado, puedes desafiar GPT.
Sin embargo, como estoy bastante seguro de que la mayoría de ustedes ya conocen estas técnicas básicas, intentaré desafiarlos con algunas técnicas avanzadas.
1. Incitación a la cadena de pensamiento (CoT)
Introducido por Google en 2022, este método implica ordenar al modelo que pase por varias etapas de razonamiento antes de entregar la respuesta final.
Suena familiar ¿verdad? Si es así, tienes toda la razón.
Es como fusionar el pensamiento secuencial y las indicaciones breves.
¿Cómo?
Básicamente, las indicaciones de CoT dirigen al LLM para que procese la información de forma secuencial. Esto significa que ejemplificamos cómo resolver un primer problema con razonamiento de múltiples pasos y luego enviamos al modelo nuestra tarea real, esperando que emule una cadena de pensamiento comparable al responder a la consulta real que queremos que resuelva.
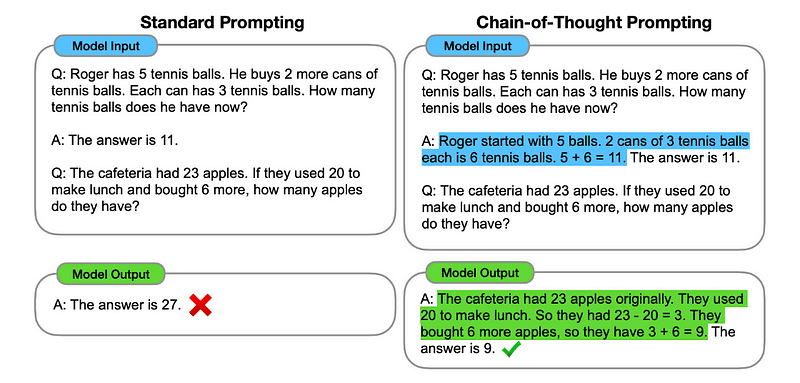
Entonces, siguiendo el primer ejemplo, podríamos proporcionar un mensaje con el primer problema y una explicación secuencial de cómo resolverlo. Luego, podremos enviar nuestros comentarios y ver cómo sucede la magia.
Si John tiene 5 peras, luego come 2, compra 5 más y luego le da 3 a su amigo, ¿cuántas peras tiene? Pensemos paso a paso.
Vayamos paso a paso. John comienza con 5 peras. Se come 2 peras, por lo que le quedan 5–2 = 3 peras. Luego compra 5 peras más. Entonces ahora tiene 3 + 5 = 8 peras. Finalmente le regala 3 peras a su amigo. Por lo tanto, le quedan 8–3 = 5 peras. Entonces, después de todos estos pasos, John tiene 5 peras.
Tu entrada aquí.
Sin embargo, la mayoría de ustedes deben estar pensando… ¿Tengo que pensar en una forma secuencial de resolver cualquier problema cada vez que quiero preguntar algo en ChatGPT?
Bueno… ¡no eres el primero! Y esto nos lleva a…
2. Cadena de pensamiento automática (Auto-CoT)
En 2022, Zhang y sus colegas introdujeron un método para evitar este proceso manual. Hay dos razones principales para evitar cualquier tarea manual:
- Puede resultar aburrido.
- Puede producir malos resultados, por ejemplo, cuando nuestro proceso mental es incorrecto.
Sugirieron utilizar LLM combinados con el mensaje "Pensemos paso a paso" para producir secuencialmente cadenas de razonamiento para cada demostración.
Esto significa preguntarle a ChatGPT cómo resolver cualquier problema de forma secuencial y luego usar este mismo ejemplo para entrenarlo sobre cómo resolver cualquier otro problema.
3. Autoconsistencia
La autoconsistencia es otra técnica de estimulación interesante que tiene como objetivo mejorar la cadena de pensamiento que induce a problemas de razonamiento más complejos.
Entonces… ¿cuál es la principal diferencia?
La idea principal de la autoconsistencia es ser conscientes de que podemos entrenar el modelo con un ejemplo incorrecto. Imagínense que resuelvo el problema anterior con un proceso mental incorrecto:
Si John tiene 5 peras, luego come 2, compra 5 más y luego le da 3 a su amigo, ¿cuántas peras tiene? Pensemos paso a paso.
Comienza con 5 peras. John come 2 peras. Luego le regala 3 peras a su amigo. Estas acciones se pueden combinar: 2 (comidas) + 3 (dadas) = 5 peras en total afectadas. Ahora, resta el total de peras afectadas de las 5 peras iniciales: 5 (inicial) – 5 (afectadas) = 0 peras restantes.
Entonces, cualquier otra tarea que envíe al modelo será incorrecta.
Es por eso que la autoconsistencia implica tomar muestras de varios caminos de razonamiento, cada uno de los cuales contiene una cadena de pensamiento, y luego dejar que el LLM elija el mejor y más consistente camino para resolver el problema.
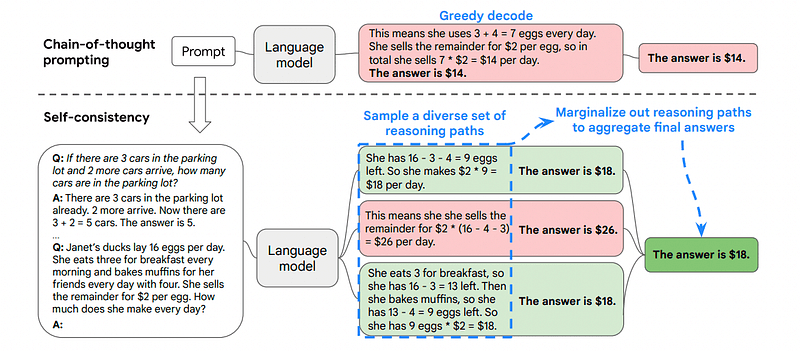
En este caso, y siguiendo nuevamente el primer ejemplo, podemos mostrarle al modelo diferentes formas de resolver el problema.
Si John tiene 5 peras, luego come 2, compra 5 más y luego le da 3 a su amigo, ¿cuántas peras tiene?
Comienza con 5 peras. John come 2 peras, lo que le deja con 5–2 = 3 peras. Compra 5 peras más, lo que eleva el total a 3 + 5 = 8 peras. Finalmente, le da 3 peras a su amigo, por lo que le quedan 8–3 = 5 peras.
Si John tiene 5 peras, luego come 2, compra 5 más y luego le da 3 a su amigo, ¿cuántas peras tiene?
Comienza con 5 peras. Luego compra 5 peras más. John come 2 peras ahora. Estas acciones se pueden combinar: 2 (comidas) + 5 (compradas) = 7 peras en total. Resta la pera que Jon ha comido de la cantidad total de peras 7 (cantidad total) – 2 (comidas) = quedan 5 peras.
Tu entrada aquí.
Y aquí viene la última técnica.
4. Indicaciones de conocimientos generales
Una práctica común de ingeniería rápida es aumentar una consulta con conocimientos adicionales antes de enviar la llamada API final a GPT-3 o GPT-4.
Según la Jiacheng Liu y compañía, siempre podemos agregar algo de conocimiento a cualquier solicitud para que el LLM conozca mejor la pregunta.
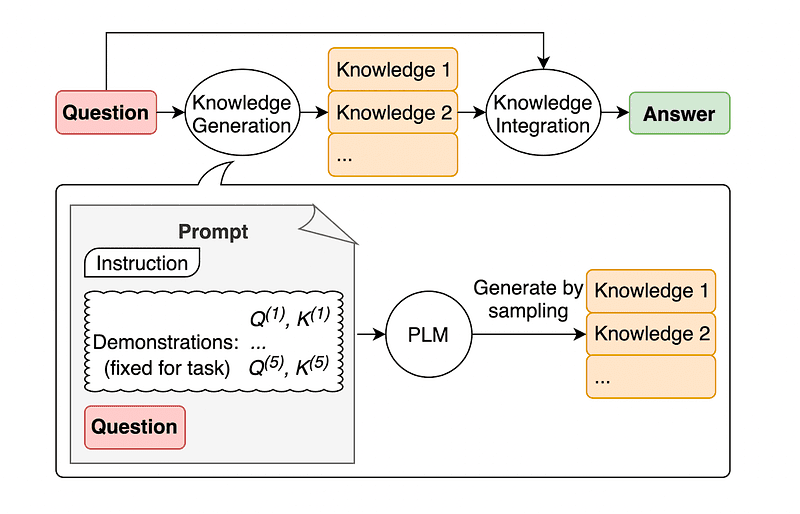
Entonces, por ejemplo, cuando le preguntamos a ChatGPT si una parte del golf intenta obtener un total de puntos más alto que otras, nos validará. Pero el objetivo principal del golf es todo lo contrario. Es por esto que podemos agregar algunos conocimientos previos diciendo “El jugador con menor puntuación gana”.

Entonces... ¿cuál es la parte divertida si le decimos al modelo exactamente la respuesta?
En este caso, esta técnica se utiliza para mejorar la forma en que LLM interactúa con nosotros.
Entonces, en lugar de extraer contexto complementario de una base de datos externa, los autores del artículo recomiendan que el LLM produzca su propio conocimiento. Este conocimiento autogenerado luego se integra en el mensaje para reforzar el razonamiento de sentido común y brindar mejores resultados.
¡Así es como se pueden mejorar los LLM sin aumentar su conjunto de datos de capacitación!
La ingeniería rápida se ha convertido en una técnica fundamental para mejorar las capacidades de LLM. Al iterar y mejorar las indicaciones, podemos comunicarnos de una manera más directa con los modelos de IA y así obtener resultados más precisos y contextualmente relevantes, ahorrando tiempo y recursos.
Para los entusiastas de la tecnología, los científicos de datos y los creadores de contenido, comprender y dominar la ingeniería rápida puede ser un activo valioso para aprovechar todo el potencial de la IA.
Al combinar indicaciones de entrada cuidadosamente diseñadas con estas técnicas más avanzadas, tener el conjunto de habilidades de ingeniería de indicaciones sin duda le brindará una ventaja en los próximos años.
Josep Ferrer es un ingeniero analítico de Barcelona. Se graduó en ingeniería física y actualmente trabaja en el campo de la Ciencia de Datos aplicada a la movilidad humana. Es un creador de contenido a tiempo parcial centrado en la ciencia y la tecnología de datos. Puedes contactarlo en Etiqueta LinkedIn, Twitter or Medio.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models?utm_source=rss&utm_medium=rss&utm_campaign=some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models
- :posee
- :es
- :no
- :dónde
- $ UP
- 10
- 11
- 2022
- 29
- 7
- 8
- a
- capacidad
- Nuestra Empresa
- la exactitud
- preciso
- acciones
- real
- add
- la adición de
- Adicionales
- avanzado
- Después
- de nuevo
- AI
- Modelos AI
- paquete de capacitación DWoVH
- alineado
- igual
- Todos
- Permitir
- a lo largo de
- ya haya utilizado
- hacerlo
- am
- cantidad
- an
- Analytics
- y
- Otra
- https://www.youtube.com/watch?v=xB-eutXNUMXJtA&feature=youtu.be
- cualquier
- abejas
- aplicada
- somos
- AS
- contacta
- pidiendo
- activo
- Autorzy
- Automático
- evitar
- conscientes
- lejos
- Atrás
- Malo
- Barcelona
- básica
- BE
- porque
- esto
- antes
- "Ser"
- MEJOR
- mejores
- reforzar
- empujón
- Aburrido
- ambas
- compró
- Rebotar
- Descanso
- rompe
- Trae
- más amplio
- pero
- Compra
- by
- llamar al
- PUEDEN
- capacidades
- estudiar cuidadosamente
- case
- cadena
- cadenas
- Reto
- retos
- ChatGPT
- Elige
- personal
- combinado
- combinar
- cómo
- proviene
- viniendo
- Algunos
- Comunicarse
- comparable
- completar
- integraciones
- considerado
- consistente
- contacte
- contenido
- creadores de contenido
- contexto
- correcciones
- correctamente
- podría
- creado
- creador
- creadores
- En la actualidad
- datos
- Ciencia de los datos
- Base de datos
- Define
- entregar
- diseñado
- deseado
- un cambio
- una experiencia diferente
- de reservas
- dirección
- descrubrir
- Cursos de Buceo
- do
- sí
- dominio
- dominios
- DE INSCRIPCIÓN
- cada una
- Southern Implants
- eficacia
- eficiencia
- surgido
- ingeniero
- Ingeniería
- mejorar
- mejorar
- suficientes
- garantizar
- entusiastas
- exactamente
- ejemplo
- ejemplos
- ejecutar
- esperando
- Explicar
- explicación
- familiar
- pocos
- campo
- final
- Finalmente
- Nombre
- centrado
- se centra
- siguiendo
- obligando a
- adelante
- Amigo
- Desde
- ser completados
- gracioso
- General
- generar
- obtener
- Donar
- dado
- da
- Go
- objetivo
- golf
- candidato
- guía
- Difícil
- Aprovechamiento
- Tienen
- es
- he
- esta página
- alta calidad
- más alto
- su
- Cómo
- Como Hacer
- Sin embargo
- HTTPS
- humana
- Inteligencia humana
- i
- idea
- if
- imagen
- mejorar
- mejorado
- es la mejora continua
- la mejora de
- in
- creciente
- información
- inicial
- Las opciones de entrada
- ejemplo
- Instrucciones
- COMPLETAMENTE
- Intelligence
- interactúa
- interesante
- dentro
- Introducido
- implica
- IT
- SUS
- Juan
- jon
- solo
- nuggets
- Guardar
- patear
- Patadas
- Saber
- especialistas
- sabe
- idioma
- Apellido
- Tarde
- Prospectos
- Saltar
- aprendizaje
- dejarlo
- izquierda
- menos
- dejar
- dejando
- aprovechando
- como
- Etiqueta LinkedIn
- inferior
- magic
- Inicio
- para lograr
- Realizar
- manera
- manual
- muchos
- masterización
- Materia
- me
- significa
- mental
- la fusión de
- Método
- podría
- movilidad
- modelo
- modelos
- más,
- MEJOR DE TU
- emocionante
- múltiples
- debe
- ¿ Necesita ayuda
- nunca
- no
- ahora
- obtener
- of
- on
- una vez
- opuesto
- optimizando
- or
- Otro
- Otros
- nuestros
- salir
- salida
- salidas
- afuera
- EL DESARROLLADOR
- Papel
- parte
- camino
- (PDF)
- perfecto
- realizar
- actuación
- Física
- esencial
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- jugador
- punto
- posible
- precisamente
- presente
- bastante
- anterior
- Problema
- problemas
- producir
- productividad
- proporcionar
- proporcionando
- tracción
- pregunta
- exactamente
- distancia
- más bien
- real
- razones
- recomiendan
- reducir
- se refiere
- solicita
- resiliencia y se la estamos enseñando a nuestro hijos e hijas.
- muchos recursos
- Recursos
- responder
- respuesta
- respuestas
- Resultados
- reentrenamiento
- Revolution
- Derecho
- Conferencia
- s
- mismo
- ahorro
- Ciencia:
- Ciencia y Tecnología
- los científicos
- Puntuación
- ver
- envío
- enviando
- Secuencia
- set
- Varios
- Mostrar
- significativamente
- habilidad
- So
- únicamente
- RESOLVER
- Resolver
- algo
- Alguien
- algo
- soluciones y
- gastado
- etapas
- comienzo
- comienza
- dirigir
- paso
- pasos
- Sin embargo
- papa
- seguro
- entrada
- toma
- Tarea
- tareas
- tecnología
- la técnica
- técnicas
- Tecnología
- narración
- término
- que
- esa
- La
- Les
- luego
- Ahí.
- por lo tanto
- Estas
- ellos
- pensar
- Ideas
- así
- pensamiento
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- Así
- equipo
- a
- TONO
- Total
- TOTALMENTE
- Entrenar
- Formación
- árbol
- probado
- try
- tratando de
- dos
- superior
- bajo
- someterse
- entender
- comprensión
- indudablemente
- us
- utilizan el
- usado
- usando
- VALIDAR
- Valioso
- diversos
- versátil
- muy
- quieres
- Camino..
- formas
- we
- bien conocido
- tuvieron
- cuando
- que
- porque
- seguirá
- viento
- dentro de
- sin
- Palabra
- trabajando
- mundo
- Mal
- años
- aún
- Rendimiento
- Usted
- tú
- zephyrnet







