Estudio Amazon SageMaker proporciona una solución totalmente administrada para que los científicos de datos creen, entrenen e implementen de forma interactiva modelos de aprendizaje automático (ML). Trabajos del cuaderno de Amazon SageMaker Permita que los científicos de datos ejecuten sus cuadernos según demanda o según una programación con unos pocos clics en SageMaker Studio. Con este lanzamiento, puede ejecutar cuadernos mediante programación como trabajos utilizando las API proporcionadas por Canalizaciones de Amazon SageMaker, la función de orquestación del flujo de trabajo de ML de Amazon SageMaker. Además, puede crear un flujo de trabajo de aprendizaje automático de varios pasos con varios cuadernos dependientes utilizando estas API.
SageMaker Pipelines es una herramienta nativa de orquestación de flujo de trabajo para crear canales de aprendizaje automático que aprovechan la integración directa de SageMaker. Cada canal de SageMaker se compone de pasos, que corresponden a tareas individuales como procesamiento, capacitación o procesamiento de datos utilizando EMR de Amazon. Los trabajos del cuaderno de SageMaker ahora están disponibles como un tipo de paso integrado en las canalizaciones de SageMaker. Puede utilizar este paso de trabajo de cuaderno para ejecutar cuadernos fácilmente como trabajos con solo unas pocas líneas de código usando el SDK de Amazon SageMaker Python. Además, puede unir varios cuadernos dependientes para crear un flujo de trabajo en forma de gráficos acíclicos dirigidos (DAG). Luego puede ejecutar estos trabajos de cuadernos o DAG, y administrarlos y visualizarlos usando SageMaker Studio.
Actualmente, los científicos de datos utilizan SageMaker Studio para desarrollar interactivamente sus cuadernos Jupyter y luego utilizan los trabajos de cuadernos de SageMaker para ejecutar estos cuadernos como trabajos programados. Estos trabajos se pueden ejecutar inmediatamente o en un cronograma recurrente sin la necesidad de que los trabajadores de datos refactoricen el código como módulos de Python. Algunos casos de uso comunes para hacer esto incluyen:
- Ejecución de portátiles de larga duración en segundo plano
- Ejecución regular de inferencia de modelos para generar informes
- Pasar de preparar pequeños conjuntos de datos de muestra a trabajar con big data a escala de petabytes
- Reentrenamiento e implementación de modelos en cierta cadencia
- Programación de trabajos para la calidad del modelo o monitoreo de deriva de datos
- Explorando el espacio de parámetros para mejores modelos
Aunque esta funcionalidad facilita a los trabajadores de datos la automatización de cuadernos independientes, los flujos de trabajo de aprendizaje automático a menudo se componen de varios cuadernos, cada uno de los cuales realiza una tarea específica con dependencias complejas. Por ejemplo, un cuaderno que monitorea la desviación de los datos del modelo debe tener un paso previo que permita extraer, transformar y cargar (ETL) y procesar nuevos datos y un paso posterior de actualización y entrenamiento del modelo en caso de que se observe una desviación significativa. . Además, es posible que los científicos de datos quieran activar todo este flujo de trabajo de forma periódica para actualizar el modelo en función de nuevos datos. Para permitirle automatizar fácilmente sus cuadernos y crear flujos de trabajo tan complejos, los trabajos de cuadernos de SageMaker ahora están disponibles como un paso en SageMaker Pipelines. En esta publicación, mostramos cómo puedes resolver los siguientes casos de uso con unas pocas líneas de código:
- Ejecute programáticamente un cuaderno independiente de forma inmediata o periódica
- Cree flujos de trabajo de varios pasos de cuadernos como DAG para fines de integración y entrega continua (CI/CD) que se pueden administrar a través de la interfaz de usuario de SageMaker Studio.
Resumen de la solución
El siguiente diagrama ilustra la arquitectura de nuestra solución. Puede utilizar el SDK de SageMaker Python para ejecutar un único trabajo de cuaderno o un flujo de trabajo. Esta función crea un trabajo de capacitación de SageMaker para ejecutar el cuaderno.
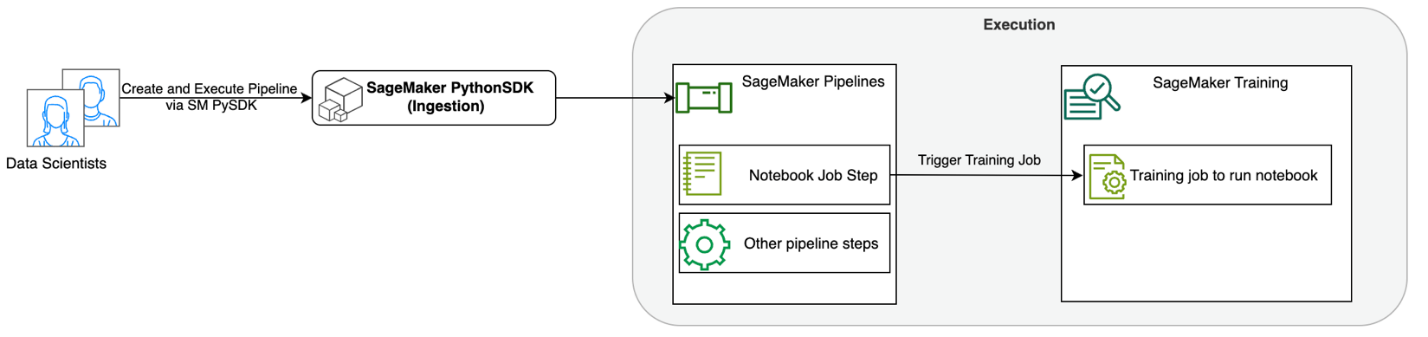
En las siguientes secciones, analizamos un caso de uso de aprendizaje automático de muestra y mostramos los pasos para crear un flujo de trabajo de trabajos de cuaderno, pasando parámetros entre diferentes pasos del cuaderno, programando su flujo de trabajo y monitoreándolo a través de SageMaker Studio.
Para nuestro problema de ML en este ejemplo, estamos creando un modelo de análisis de sentimientos, que es un tipo de tarea de clasificación de texto. Las aplicaciones más comunes del análisis de sentimientos incluyen el monitoreo de redes sociales, la gestión de atención al cliente y el análisis de los comentarios de los clientes. El conjunto de datos que se utiliza en este ejemplo es el conjunto de datos Stanford Sentiment Treebank (SST2), que consta de reseñas de películas junto con un número entero (0 o 1) que indica el sentimiento positivo o negativo de la reseña.
El siguiente es un ejemplo de data.csv archivo correspondiente al conjunto de datos SST2 y muestra valores en sus dos primeras columnas. Tenga en cuenta que el archivo no debe tener ningún encabezado.
| Columna 1 | Columna 2 |
| 0 | ocultar nuevas secreciones de las unidades parentales |
| 0 | no contiene ingenio, solo gags laboriosos |
| 1 | que ama a sus personajes y comunica algo bastante hermoso sobre la naturaleza humana |
| 0 | permanece completamente satisfecho de seguir siendo el mismo a lo largo |
| 0 | sobre los peores clichés de venganza de los nerds que los cineastas pudieron desenterrar |
| 0 | eso es demasiado trágico para merecer un tratamiento tan superficial |
| 1 | demuestra que el director de éxitos de taquilla de Hollywood como Patriot Games todavía puede producir una pequeña película personal con un golpe emocional. |
En este ejemplo de ML, debemos realizar varias tareas:
- Realice ingeniería de características para preparar este conjunto de datos en un formato que nuestro modelo pueda entender.
- Ingeniería posterior a la función, ejecute un paso de capacitación que utilice Transformers.
- Configure la inferencia por lotes con el modelo ajustado para ayudar a predecir el sentimiento de las nuevas reseñas que llegan.
- Configure un paso de monitoreo de datos para que podamos monitorear periódicamente nuestros nuevos datos para detectar cualquier variación en la calidad que pueda requerir que volvamos a entrenar los pesos del modelo.
Con este lanzamiento de un trabajo de cuaderno como paso en los procesos de SageMaker, podemos orquestar este flujo de trabajo, que consta de tres pasos distintos. Cada paso del flujo de trabajo se desarrolla en un cuaderno diferente, que luego se convierte en pasos de trabajos de cuaderno independientes y se conectan como una canalización:
- preprocesamiento – Descargue el conjunto de datos público SST2 desde Servicio de almacenamiento simple de Amazon (Amazon S3) y cree un archivo CSV para que se ejecute la computadora portátil en el Paso 2. El conjunto de datos SST2 es un conjunto de datos de clasificación de texto con dos etiquetas (0 y 1) y una columna de texto para categorizar.
- Formación – Tome el archivo CSV con forma y ejecute el ajuste con BERT para la clasificación de texto utilizando las bibliotecas de Transformers. Usamos un cuaderno de preparación de datos de prueba como parte de este paso, que es una dependencia para el paso de ajuste fino e inferencia por lotes. Cuando se completa el ajuste, este cuaderno se ejecuta usando Run Magic y prepara un conjunto de datos de prueba para la inferencia de muestra con el modelo ajustado.
- Transformar y monitorear – Realice inferencias por lotes y configure la calidad de los datos con monitoreo de modelos para tener una sugerencia de conjunto de datos de referencia.
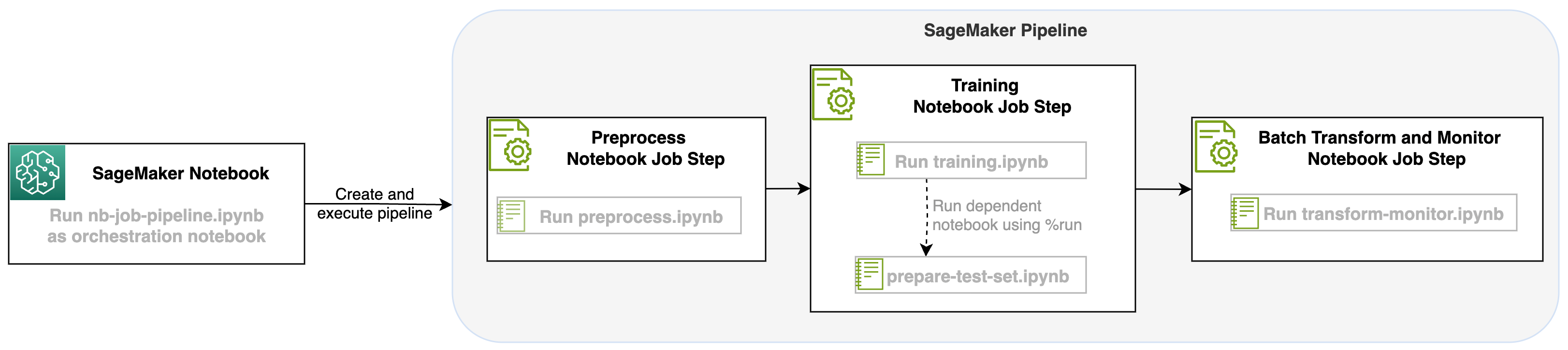
ejecutar los cuadernos
El código de muestra para esta solución está disponible en GitHub.
Crear un paso de trabajo de cuaderno de SageMaker es similar a crear otros pasos de SageMaker Pipeline. En este ejemplo de cuaderno, utilizamos el SDK de Python de SageMaker para organizar el flujo de trabajo. Para crear un paso de cuaderno en SageMaker Pipelines, puede definir los siguientes parámetros:
- Cuaderno de entrada – El nombre del cuaderno que orquestará este paso del cuaderno. Aquí puede pasar la ruta local al cuaderno de entrada. Opcionalmente, si esta computadora portátil tiene otras computadoras portátiles en ejecución, puede pasarlas en el
AdditionalDependenciesparámetro para el paso del trabajo del cuaderno. - URI de imagen – La imagen de Docker detrás del paso del trabajo del cuaderno. Estas pueden ser las imágenes predefinidas que SageMaker ya proporciona o una imagen personalizada que haya definido y enviado a Registro de contenedores elásticos de Amazon (Amazon ECR). Consulte la sección de consideraciones al final de esta publicación para ver las imágenes compatibles.
- Nombre del kernel – El nombre del kernel que está utilizando en SageMaker Studio. Esta especificación del kernel está registrada en la imagen que proporcionó.
- Tipo de instancia (opcional) - El Nube informática elástica de Amazon (Amazon EC2) tipo de instancia detrás del trabajo del cuaderno que ha definido y que se ejecutará.
- Parámetros (opcional) – Parámetros que puede pasar y que serán accesibles para su computadora portátil. Estos se pueden definir en pares clave-valor. Además, estos parámetros se pueden modificar entre varias ejecuciones de trabajos de notebook o ejecuciones de canalización.
Nuestro ejemplo tiene un total de cinco cuadernos:
- nb-job-pipeline.ipynb – Este es nuestro cuaderno principal donde definimos nuestro proceso y flujo de trabajo.
- preproceso.ipynb – Este cuaderno es el primer paso de nuestro flujo de trabajo y contiene el código que extraerá el conjunto de datos público de AWS y creará un archivo CSV a partir de él.
- entrenamiento.ipynb – Este cuaderno es el segundo paso de nuestro flujo de trabajo y contiene código para tomar el CSV del paso anterior y realizar capacitación y ajustes locales. Este paso también tiene una dependencia del
prepare-test-set.ipynbnotebook para desplegar un conjunto de datos de prueba para la inferencia de muestras con el modelo ajustado. - preparar-test-set.ipynb – Este cuaderno crea un conjunto de datos de prueba que nuestro cuaderno de capacitación usará en el segundo paso del proceso y lo usará para la inferencia de muestra con el modelo ajustado.
- transformar-monitor.ipynb – Este cuaderno es el tercer paso de nuestro flujo de trabajo y toma el modelo BERT base y ejecuta un trabajo de transformación por lotes de SageMaker, al mismo tiempo que configura la calidad de los datos con el monitoreo del modelo.
A continuación, recorremos el cuaderno principal. nb-job-pipeline.ipynb, que combina todos los subcuadernos en una canalización y ejecuta el flujo de trabajo de un extremo a otro. Tenga en cuenta que, aunque el siguiente ejemplo solo ejecuta el cuaderno una vez, también puede programar la canalización para ejecutar el cuaderno repetidamente. Referirse a Documentación de SageMaker para obtener instrucciones detalladas.
Para nuestro primer paso del trabajo del cuaderno, pasamos un parámetro con un depósito S3 predeterminado. Podemos usar este depósito para volcar cualquier artefacto que queramos que esté disponible para nuestros otros pasos de la canalización. Para el primer cuaderno (preprocess.ipynb), extraemos el conjunto de datos del tren SST2 público de AWS y creamos un archivo CSV de entrenamiento a partir de él que enviamos a este depósito S3. Vea el siguiente código:
Luego podemos convertir este cuaderno en un NotebookJobStep con el siguiente código en nuestro cuaderno principal:
Ahora que tenemos un archivo CSV de muestra, podemos comenzar a entrenar nuestro modelo en nuestro cuaderno de entrenamiento. Nuestro cuaderno de entrenamiento toma el mismo parámetro con el depósito S3 y extrae el conjunto de datos de entrenamiento desde esa ubicación. Luego realizamos un ajuste fino utilizando el objeto de entrenamiento Transformers con el siguiente fragmento de código:
Después del ajuste, queremos ejecutar alguna inferencia por lotes para ver cómo se está desempeñando el modelo. Esto se hace usando un cuaderno separado (prepare-test-set.ipynb) en la misma ruta local que crea un conjunto de datos de prueba para realizar inferencias sobre el uso de nuestro modelo entrenado. Podemos ejecutar el cuaderno adicional en nuestro cuaderno de entrenamiento con la siguiente celda mágica:
Definimos esta dependencia adicional del cuaderno en el AdditionalDependencies parámetro en nuestro segundo paso del trabajo del cuaderno:
También debemos especificar que el paso del trabajo del cuaderno de capacitación (Paso 2) depende del paso del trabajo del cuaderno de preprocesamiento (Paso 1) mediante el uso del add_depends_on Llamada a la API de la siguiente manera:
Nuestro último paso será que el modelo BERT ejecute una transformación por lotes de SageMaker y, al mismo tiempo, configure la captura y calidad de datos a través de SageMaker Model Monitor. Tenga en cuenta que esto es diferente a usar la función incorporada. Transformar or Capturar pasos a través de Pipelines. Nuestro cuaderno para este paso ejecutará esas mismas API, pero se realizará un seguimiento como un paso de trabajo del cuaderno. Este paso depende del paso del trabajo de capacitación que definimos previamente, por lo que también lo capturamos con el indicador depend_on.
Una vez definidos los distintos pasos de nuestro flujo de trabajo, podemos crear y ejecutar el proceso de un extremo a otro:
Monitorear las ejecuciones de la tubería
Puede realizar un seguimiento y monitorear la ejecución de los pasos del cuaderno a través de SageMaker Pipelines DAG, como se ve en la siguiente captura de pantalla.
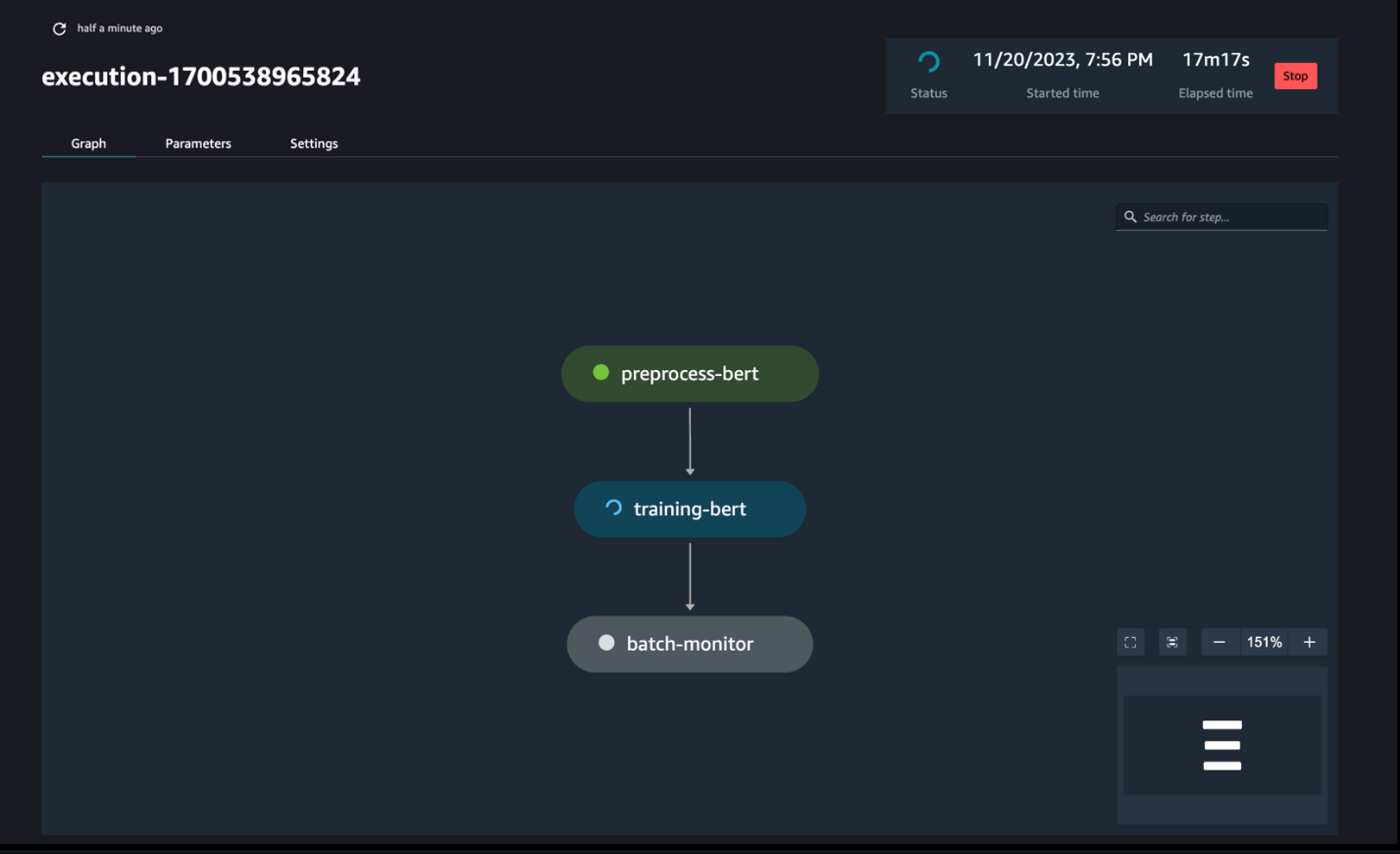
Opcionalmente, también puede monitorear las ejecuciones del cuaderno individual en el panel de trabajo del cuaderno y alternar los archivos de salida que se han creado a través de la interfaz de usuario de SageMaker Studio. Al utilizar esta funcionalidad fuera de SageMaker Studio, puede definir los usuarios que pueden realizar un seguimiento del estado de ejecución en el panel de trabajo del cuaderno mediante etiquetas. Para obtener más detalles sobre las etiquetas que se deben incluir, consulte Vea los trabajos de su cuaderno y descargue los resultados en el panel de la interfaz de usuario de Studio.
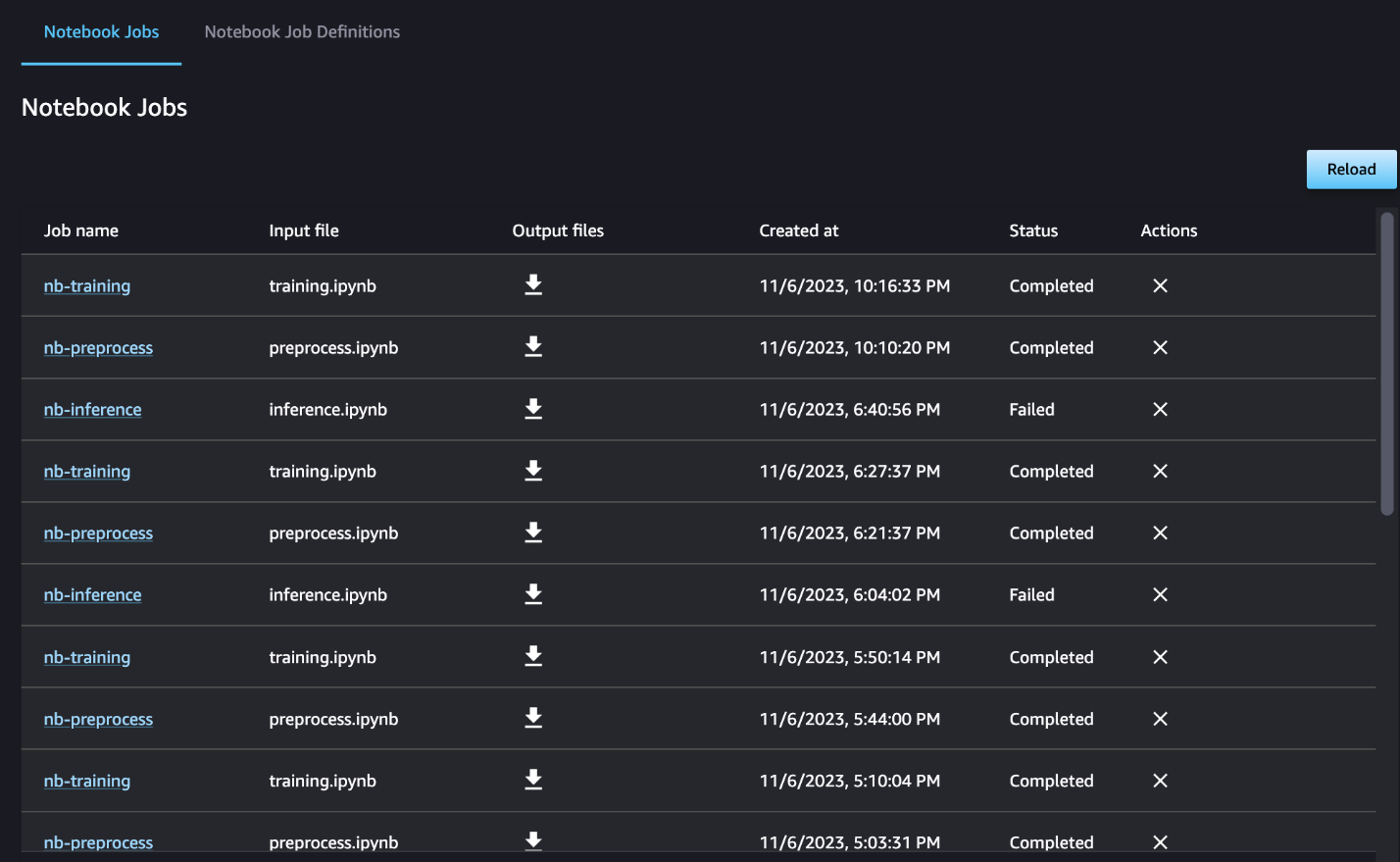
Para este ejemplo, enviamos los trabajos del cuaderno resultantes a un directorio llamado outputs en su ruta local con su código de ejecución de canalización. Como se muestra en la siguiente captura de pantalla, aquí puede ver el resultado de su cuaderno de entrada y también cualquier parámetro que haya definido para ese paso.
Limpiar
Si siguió nuestro ejemplo, asegúrese de eliminar la canalización creada, los trabajos del cuaderno y los datos s3 descargados por los cuadernos de muestra.
Consideraciones
Las siguientes son algunas consideraciones importantes para esta característica:
- Restricciones del SDK – El paso del trabajo del cuaderno solo se puede crear a través del SDK de SageMaker Python.
- Restricciones de imagen –El paso del trabajo del cuaderno admite las siguientes imágenes:
Conclusión
Con este lanzamiento, los trabajadores de datos ahora pueden ejecutar sus portátiles mediante programación con unas pocas líneas de código utilizando el SDK de SageMaker Python. Además, puede crear flujos de trabajo complejos de varios pasos utilizando sus portátiles, lo que reduce significativamente el tiempo necesario para pasar de un portátil a una canalización de CI/CD. Después de crear la canalización, puede usar SageMaker Studio para ver y ejecutar DAG para sus canalizaciones y administrar y comparar las ejecuciones. Ya sea que esté programando flujos de trabajo de aprendizaje automático de un extremo a otro o parte de ellos, le recomendamos que lo pruebe flujos de trabajo basados en portátiles.
Sobre los autores
 Anchit Gupta es gerente senior de productos de Amazon SageMaker Studio. Se centra en habilitar flujos de trabajo interactivos de ciencia e ingeniería de datos desde el IDE de SageMaker Studio. En su tiempo libre, le gusta cocinar, jugar juegos de mesa y de cartas y leer.
Anchit Gupta es gerente senior de productos de Amazon SageMaker Studio. Se centra en habilitar flujos de trabajo interactivos de ciencia e ingeniería de datos desde el IDE de SageMaker Studio. En su tiempo libre, le gusta cocinar, jugar juegos de mesa y de cartas y leer.
 Ram Vegiraju es un arquitecto de ML en el equipo de servicio Sagemaker. Se enfoca en ayudar a los clientes a construir y optimizar sus soluciones AI/ML en Amazon Sagemaker. En su tiempo libre, le encanta viajar y escribir.
Ram Vegiraju es un arquitecto de ML en el equipo de servicio Sagemaker. Se enfoca en ayudar a los clientes a construir y optimizar sus soluciones AI/ML en Amazon Sagemaker. En su tiempo libre, le encanta viajar y escribir.
 eduardo sol es un SDE sénior que trabaja para SageMaker Studio en Amazon Web Services. Se centra en crear una solución de aprendizaje automático interactivo y en simplificar la experiencia del cliente para integrar SageMaker Studio con tecnologías populares en la ingeniería de datos y el ecosistema de aprendizaje automático. En su tiempo libre, Edward es un gran aficionado a acampar, hacer caminatas y pescar, y disfruta el tiempo que pasa con su familia.
eduardo sol es un SDE sénior que trabaja para SageMaker Studio en Amazon Web Services. Se centra en crear una solución de aprendizaje automático interactivo y en simplificar la experiencia del cliente para integrar SageMaker Studio con tecnologías populares en la ingeniería de datos y el ecosistema de aprendizaje automático. En su tiempo libre, Edward es un gran aficionado a acampar, hacer caminatas y pescar, y disfruta el tiempo que pasa con su familia.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/schedule-amazon-sagemaker-notebook-jobs-and-manage-multi-step-notebook-workflows-using-apis/
- :posee
- :es
- :dónde
- $ UP
- 1
- 100
- 116
- 125
- 15%
- 17
- 20
- 500
- 7
- 8
- a
- Nuestra Empresa
- accesible
- acíclico
- Adicionales
- Adicionalmente
- Ventaja
- Después
- AI / ML
- Todos
- permite
- a lo largo de
- ya haya utilizado
- también
- Aunque
- Amazon
- Amazon EC2
- Amazon SageMaker
- Estudio Amazon SageMaker
- Amazon Web Services
- an
- análisis
- el análisis de
- y
- cualquier
- abejas
- API
- aplicaciones
- arquitectura
- somos
- AS
- At
- automatizado
- Hoy Disponibles
- AWS
- bases
- basado
- Base
- BE
- hermosos
- esto
- detrás de
- "Ser"
- mejores
- entre
- Big
- build
- Construir la
- incorporado
- pero
- by
- llamar al
- , que son
- ir de camping
- PUEDEN
- capturar
- case
- cases
- (SCD por sus siglas en inglés),
- personajes
- clasificación
- código
- Columna
- Columnas
- combina
- cómo
- Algunos
- comparar
- completar
- integraciones
- compuesto
- Compuesto
- Calcular
- Conducir
- conectado
- consideraciones
- consiste
- Envase
- contiene
- continuo
- convertir
- convertido
- cocinar
- Correspondiente
- podría
- Para crear
- creado
- crea
- Creamos
- En la actualidad
- personalizado
- cliente
- experiencia del cliente
- Atención al cliente
- Clientes
- DÍA
- página de información de sus operaciones
- datos
- monitoreo de datos
- Preparación de datos
- proceso de datos
- calidad de los datos
- Ciencia de los datos
- conjuntos de datos
- Predeterminado
- definir
- se define
- entrega
- Demanda
- dependencias
- Dependencia
- dependiente
- depende
- desplegar
- Desplegando
- detallado
- detalles
- desarrollar
- desarrollado
- una experiencia diferente
- de reservas
- que dirigieron
- Director
- distinto
- Docker
- "Hacer"
- hecho
- DE INSCRIPCIÓN
- descargar
- arrojar
- cada una
- pasan fácilmente
- ecosistema
- Edward
- habilitar
- permitiendo
- fomentar
- final
- de extremo a extremo
- Ingeniería
- Todo
- época
- Éter (ETH)
- ejemplo
- ejecutar
- ejecución
- experience
- extra
- extraerlos
- familia
- ventilador
- muchos
- Feature
- realimentación
- pocos
- Archive
- archivos
- Film
- cineastas
- Nombre
- Pesca deportiva
- Digital XNUMXk
- centrado
- se centra
- seguido
- siguiendo
- siguiente
- formulario
- formato
- Desde
- completamente
- a la fatiga
- Además
- Juegos
- generar
- gráficos
- Tienen
- he
- ayuda
- ayudando
- aquí
- esta página
- excursionismo
- su
- Hollywood
- Cómo
- HTML
- http
- HTTPS
- humana
- if
- ilustra
- imagen
- imágenes
- inmediatamente
- importar
- importante
- in
- incluir
- independientes
- Indica
- INSTRUMENTO individual
- Las opciones de entrada
- ejemplo
- Instrucciones
- integrar
- integración
- interactivo
- dentro
- IT
- SUS
- Trabajos
- Empleo
- jpg
- solo
- Label
- Etiquetas
- Apellidos
- lanzamiento
- aprendizaje
- bibliotecas
- línea
- líneas
- carga
- local
- Ubicación
- Largo
- ama
- máquina
- máquina de aprendizaje
- magic
- Inicio
- HACE
- gestionan
- gestionado
- Management
- gerente
- Medios
- Mérito
- podría
- ML
- modelo
- modelos
- modificado
- Módulos
- Monitorear
- monitoreo
- monitores
- más,
- MEJOR DE TU
- movimiento
- película
- múltiples
- debe
- nombre
- nativo
- ¿ Necesita ayuda
- negativas
- Nuevo
- no
- nota
- cuaderno
- ordenadores portátiles
- ahora
- objeto
- of
- a menudo
- on
- ONE
- , solamente
- Optimización
- or
- orquestación
- Otro
- "nuestr
- salir
- salida
- salidas
- afuera
- pares
- parámetro
- parámetros
- parte
- pass
- Pasando (Paso)
- camino
- realizar
- realizar
- con
- industrial
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- jugando
- Popular
- positivo
- Publicación
- predecir
- preparación
- Preparar
- Prepara
- preparación
- anterior
- previamente
- Problema
- tratamiento
- Producto
- gerente de producto
- proporcionar
- previsto
- proporciona un
- público
- Tira
- fines
- Push
- empujó
- Python
- calidad
- más rápido
- R
- más bien
- Leer
- Reading
- periódico
- la reducción de
- Refactorizar
- remitir
- registrado
- regularmente
- permanecer
- REPETIDAMENTE
- exigir
- resultante
- una estrategia SEO para aparecer en las búsquedas de Google.
- Reseñas
- Ejecutar
- correr
- corre
- sabio
- Tuberías de SageMaker
- mismo
- satisfecho
- programa
- programada
- Trabajos programados
- programación
- Ciencia:
- los científicos
- Sdk
- Segundo
- Sección
- (secciones)
- ver
- visto
- mayor
- sentimiento
- separado
- de coches
- Servicios
- Sesión
- set
- pólipo
- Varios
- en forma de
- ella
- tienes
- Mostrar
- mostrar
- mostrado
- Shows
- importante
- significativamente
- similares
- sencillos
- simplificando
- soltero
- chica
- menores
- retazo
- So
- Social
- redes sociales
- a medida
- Soluciones
- RESOLVER
- algo
- algo
- Espacio
- soluciones y
- Gastos
- independiente
- stanford
- comienzo
- Estado
- paso
- pasos
- Sin embargo
- STORAGE
- sencillo
- estudio
- tal
- Dom
- SOPORTE
- Soportado
- soportes
- seguro
- ¡Prepárate!
- toma
- Tarea
- tareas
- equipo
- Tecnologías
- test
- texto
- Clasificación de texto
- esa
- La
- su
- Les
- luego
- Estas
- Código
- así
- aquellos
- Tres
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- a
- juntos
- demasiado
- del IRS
- Total
- seguir
- Entrenar
- entrenado
- Formación
- Transformar
- transformers
- Viajar
- detonante
- GIRO
- dos
- tipo
- ui
- entender
- Actualizar
- us
- utilizan el
- caso de uso
- usado
- usuarios
- usos
- usando
- Utilizando
- Valores
- diversos
- vía
- Ver
- visualizar
- caminar
- quieres
- we
- web
- servicios web
- cuando
- sean
- que
- mientras
- QUIENES
- seguirá
- dentro de
- sin
- los trabajadores.
- flujo de trabajo
- flujos de trabajo
- trabajando
- Peor
- la escritura
- Usted
- tú
- zephyrnet