Un sistema de inteligencia artificial (IA) recién creado basado en el aprendizaje de refuerzo profundo (DRL) puede reaccionar ante los atacantes en un entorno simulado y bloquear el 95 % de los ciberataques antes de que se intensifiquen.
Eso es según los investigadores del Laboratorio Nacional del Noroeste del Pacífico del Departamento de Energía que construyeron una simulación abstracta del conflicto digital entre atacantes y defensores en una red y entrenaron cuatro redes neuronales DRL diferentes para maximizar las recompensas en función de prevenir compromisos y minimizar la interrupción de la red.
Los atacantes simulados utilizaron una serie de tácticas basadas en la MITRE ATT & CK clasificación del framework para pasar de la fase inicial de acceso y reconocimiento a otras fases de ataque hasta llegar a su objetivo: la fase de impacto y exfiltración.
El entrenamiento exitoso del sistema de IA en el entorno de ataque simplificado demuestra que un modelo de IA podría manejar las respuestas defensivas a los ataques en tiempo real, dice Samrat Chatterjee, un científico de datos que presentó el trabajo del equipo en la reunión anual de la Asociación para el Avance de la Inteligencia Artificial en Washington, DC el 14 de febrero.
“No desea pasar a arquitecturas más complejas si ni siquiera puede mostrar la promesa de estas técnicas”, dice. “Queríamos demostrar primero que en realidad podemos entrenar un DRL con éxito y mostrar algunos buenos resultados de prueba, antes de seguir adelante”.
La aplicación de técnicas de aprendizaje automático e inteligencia artificial a diferentes campos dentro de la ciberseguridad se ha convertido en una tendencia candente durante la última década, desde la integración temprana del aprendizaje automático en las puertas de enlace de seguridad del correo electrónico. en los primeros 2010s a los esfuerzos más recientes para usa ChatGPT para analizar el código o realizar análisis forenses. Ahora, la mayoría de los productos de seguridad tienen - o afirma tener - algunas características impulsadas por algoritmos de aprendizaje automático entrenados en grandes conjuntos de datos.
Sin embargo, la creación de un sistema de inteligencia artificial capaz de una defensa proactiva sigue siendo una aspiración, más que una práctica. Si bien quedan una variedad de obstáculos para los investigadores, la investigación de PNNL muestra que un defensor de IA podría ser posible en el futuro.
“La evaluación de múltiples algoritmos DRL entrenados en diversos entornos adversarios es un paso importante hacia soluciones prácticas de ciberdefensa autónomas”, dijo el equipo de investigación de PNNL. declarado en su papel. “Nuestros experimentos sugieren que los algoritmos DRL sin modelo se pueden entrenar de manera efectiva bajo perfiles de ataque de múltiples etapas con diferentes niveles de habilidad y persistencia, lo que produce resultados de defensa favorables en entornos disputados”.
Cómo utiliza el sistema MITRE ATT&CK
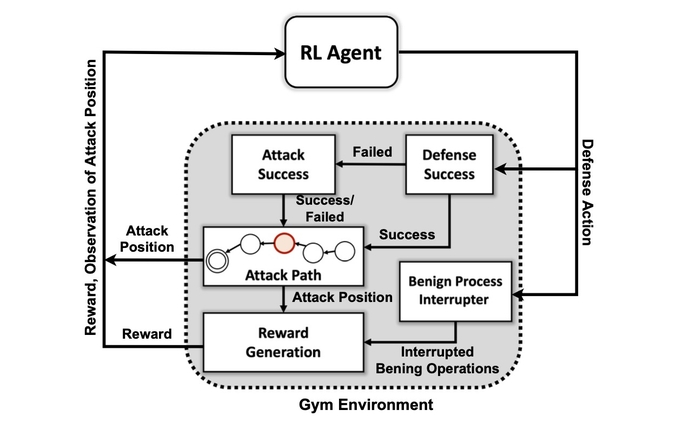
El primer objetivo del equipo de investigación fue crear un entorno de simulación personalizado basado en un conjunto de herramientas de código abierto conocido como Gimnasio abierto de IA. Utilizando ese entorno, los investigadores crearon entidades atacantes de diferentes niveles de habilidad y persistencia con la capacidad de usar un subconjunto de 7 tácticas y 15 técnicas del marco MITRE ATT&CK.
Los objetivos de los agentes atacantes son moverse a través de los siete pasos de la cadena de ataque, desde el acceso inicial hasta la ejecución, desde la persistencia hasta el comando y control, y desde la recolección hasta el impacto.
Para el atacante, adaptar sus tácticas al estado del entorno y las acciones actuales del defensor puede ser complejo, dice Chatterjee de PNNL.
“El adversario tiene que navegar desde un estado inicial de reconocimiento hasta algún estado de exfiltración o impacto”, dice. “No estamos tratando de crear una especie de modelo para detener a un adversario antes de que ingrese al entorno; asumimos que el sistema ya está comprometido”.
Los investigadores utilizaron cuatro enfoques para las redes neuronales basados en el aprendizaje por refuerzo. El aprendizaje por refuerzo (RL) es un enfoque de aprendizaje automático que emula el sistema de recompensa del cerebro humano. Una red neuronal aprende fortaleciendo o debilitando ciertos parámetros para que las neuronas individuales recompensen las mejores soluciones, según lo medido por una puntuación que indica qué tan bien funciona el sistema.
El aprendizaje por refuerzo esencialmente permite que la computadora cree un enfoque bueno, pero no perfecto, para el problema en cuestión, dice Mahantesh Halappanavar, investigador de PNNL y autor del artículo.
"Sin usar ningún aprendizaje de refuerzo, aún podríamos hacerlo, pero sería un problema realmente grande que no tendrá suficiente tiempo para encontrar un buen mecanismo", dice. "Nuestra investigación... nos brinda este mecanismo en el que el aprendizaje de refuerzo profundo imita en cierto modo parte del comportamiento humano en sí mismo, hasta cierto punto, y puede explorar este vasto espacio de manera muy eficiente".
No está listo para el horario de máxima audiencia
Los experimentos encontraron que un método de aprendizaje de refuerzo específico, conocido como Deep Q Network, creó una solución sólida al problema defensivo, atrapar al 97% de los atacantes en el conjunto de datos de prueba. Sin embargo, la investigación es solo el comienzo. Los profesionales de la seguridad no deben buscar un compañero de IA para ayudarlos a responder a incidentes y análisis forense en el corto plazo.
Entre los muchos problemas que quedan por resolver está lograr que el aprendizaje por refuerzo y las redes neuronales profundas expliquen los factores que influyeron en sus decisiones, un área de investigación llamada aprendizaje por refuerzo explicable (XRL).
Además, la solidez de los algoritmos de IA y la búsqueda de formas eficientes de entrenar las redes neuronales son problemas que deben resolverse, dice Chatterjee de PNNL.
“Crear un producto, esa no fue la principal motivación para esta investigación”, dice. “Esto fue más sobre experimentación científica y descubrimiento algorítmico”.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.darkreading.com/emerging-tech/researchers-create-ai-cyber-defender-that-reacts-to-attackers
- 7
- 95%
- a
- capacidad
- Nuestra Empresa
- RESUMEN
- de la máquina
- Conforme
- acciones
- adición
- avance
- adversario
- agentes
- AI
- Alimentado por IA
- algorítmico
- algoritmos
- Todos
- permite
- ya haya utilizado
- análisis
- analizar
- y
- anual
- Aplicación
- enfoque
- enfoques
- Reservada
- artificial
- inteligencia artificial
- Inteligencia Artificial (AI)
- Asociación
- atacar
- ataques
- autor
- autónomo
- basado
- a las que has recomendado
- antes
- mejores
- entre
- Big
- Bloquear
- Cerebro
- construido
- , que son
- no puede
- capaz
- a ciertos
- cadena
- ChatGPT
- reclamo
- clasificación
- --
- cómo
- integraciones
- Comprometida
- computadora
- Conducir
- el conflicto
- continúa
- control
- podría
- Para crear
- creado
- Creamos
- Current
- personalizado
- ciber
- Ataques ciberneticos
- La Ciberseguridad
- datos
- científico de datos
- conjunto de datos
- conjuntos de datos
- dc
- década
- Koops
- decisiones
- profundo
- redes neuronales profundas
- los defensores
- Defensa
- defensiva
- demostrar
- demuestra
- Departamento
- Departamento de Energía
- una experiencia diferente
- digital
- descubrimiento
- Interrupción
- diverso
- DOE
- Temprano en la
- de manera eficaz
- eficiente
- eficiente.
- esfuerzos
- seguridad de correo electrónico
- energía
- suficientes
- entidades
- Entorno
- esencialmente
- Éter (ETH)
- evaluación
- Incluso
- ejecución
- exfiltración
- Explicar
- explorar
- factores importantes
- Caracteristicas
- pocos
- Terrenos
- la búsqueda de
- Nombre
- de tus señales
- Entrevistas
- forense
- adelante
- encontrado
- Marco conceptual
- Desde
- futuras
- obtener
- conseguir
- da
- objetivo
- Goals
- candidato
- mano
- ayuda
- HOT
- Cómo
- HTTPS
- humana
- Obstáculos
- Impacto
- importante
- in
- incidente
- respuesta al incidente
- indicando
- INSTRUMENTO individual
- influenciado
- inicial
- integración
- Intelligence
- IT
- sí mismo
- Tipo
- conocido
- laboratorio
- large
- aprendizaje
- Mira
- máquina
- máquina de aprendizaje
- Inicio
- muchos
- max-ancho
- Maximizar
- mecanismo
- reunión
- Método
- minimizando
- modelo
- más,
- Motivación
- movimiento
- emocionante
- múltiples
- Nacional
- Navegar
- ¿ Necesita ayuda
- del sistema,
- telecomunicaciones
- Neural
- red neural
- redes neuronales
- Neuronas
- habiertos
- de código abierto
- Otro
- Costa
- Papel
- parámetros
- pasado
- perfecto
- realiza
- persistencia
- fase
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- posible
- alimentado
- Metodología
- presentó
- la prevención
- Prime
- Proactiva
- Problema
- problemas
- Productos
- profesionales
- Perfiles
- PROMETEMOS
- RE
- alcanzado
- Reaccionar
- Reacciona
- ready
- real
- en tiempo real
- reciente
- aprendizaje reforzado
- permanecer
- la investigación
- investigador
- investigadores
- respuesta
- Gana dinero
- Recompensas
- robustez
- dice
- Científico
- EN LINEA
- Serie
- set
- ajustes
- siete
- tienes
- Mostrar
- Shows
- simplificado
- simulación
- habilidad
- a medida
- Soluciones
- algo
- Pronto
- Fuente
- Espacio
- soluciones y
- comienzo
- Estado
- paso
- pasos
- Sin embargo
- Detener
- fortalecimiento
- fuerte
- exitosos
- Con éxito
- te
- táctica
- equipo
- técnicas
- Pruebas
- La
- El futuro de las
- El Estado
- su
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- a
- caja de herramientas
- hacia
- Entrenar
- entrenado
- Formación
- Tendencia
- bajo
- us
- utilizan el
- variedad
- Vasto
- deseado
- Washington
- formas
- mientras
- QUIENES
- seguirá
- dentro de
- sin
- Actividades:
- se
- flexible
- zephyrnet











