En la era digital actual, los datos son la base del éxito de toda organización. Uno de los formatos más utilizados para intercambiar datos es XML. Analizar archivos XML es crucial por varias razones. En primer lugar, los archivos XML se utilizan en muchas industrias, incluidas las finanzas, la atención médica y el gobierno. El análisis de archivos XML puede ayudar a las organizaciones a obtener información sobre sus datos, permitiéndoles tomar mejores decisiones y mejorar sus operaciones. El análisis de archivos XML también puede ayudar en la integración de datos, porque muchas aplicaciones y sistemas utilizan XML como formato de datos estándar. Al analizar archivos XML, las organizaciones pueden integrar fácilmente datos de diferentes fuentes y garantizar la coherencia en sus sistemas. Sin embargo, los archivos XML contienen datos semiestructurados y altamente anidados, lo que dificulta el acceso y el análisis de la información, especialmente si el archivo es grande y tiene esquema complejo y altamente anidado.
Los archivos XML son adecuados para aplicaciones, pero es posible que no sean óptimos para motores de análisis. Para mejorar el rendimiento de las consultas y permitir un fácil acceso en motores de análisis posteriores, como Atenea amazónica, es fundamental preprocesar los archivos XML en un formato de columnas como Parquet. Esta transformación permite mejorar la eficiencia y la usabilidad en los flujos de trabajo de análisis. En esta publicación, mostramos cómo procesar datos XML usando Pegamento AWS y Atenea.
Resumen de la solución
Exploramos dos técnicas distintas que pueden optimizar su flujo de trabajo de procesamiento de archivos XML:
- Técnica 1: utilizar un rastreador de AWS Glue y el editor visual de AWS Glue – Puede utilizar la interfaz de usuario de AWS Glue junto con un rastreador para definir la estructura de la tabla para sus archivos XML. Este enfoque proporciona una interfaz fácil de usar y es particularmente adecuado para personas que prefieren un enfoque gráfico para administrar sus datos.
- Técnica 2: utilice AWS Glue DynamicFrames con esquemas inferidos y fijos – El rastreador tiene una limitación cuando se trata de procesar una sola fila en archivos XML de más de 1 MB. Para superar esta restricción, utilizamos un cuaderno de AWS Glue para construir AWS Glue.
DynamicFrames, utilizando esquemas tanto inferidos como fijos. Este método garantiza un manejo eficiente de archivos XML con filas que superan 1 MB de tamaño.
En ambos enfoques, nuestro objetivo final es convertir archivos XML al formato Apache Parquet, haciéndolos disponibles para consultas utilizando Athena. Con estas técnicas, puede mejorar la velocidad de procesamiento y la accesibilidad de sus datos XML, lo que le permitirá obtener información valiosa con facilidad.
Requisitos previos
Antes de comenzar este tutorial, complete los siguientes requisitos previos (se aplican a ambas técnicas):
- Descargue los archivos XML técnica1.xml y técnica2.xml.
- Sube los archivos a un Servicio de almacenamiento simple de Amazon (Amazon S3) cubo. Puede cargarlos en el mismo depósito de S3 en diferentes carpetas o en diferentes depósitos de S3.
- Crear una Gestión de identidades y accesos de AWS (IAM) para su trabajo ETL o cuaderno como se indica en Configurar permisos de IAM para AWS Glue Studio.
- Agregue una política en línea a su rol con el iam:PassRole acción:
- Agregue una política de permisos al rol con acceso a su depósito de S3.
Ahora que hemos terminado con los requisitos previos, pasemos a implementar la primera técnica.
Técnica 1: utilice un rastreador de AWS Glue y el editor visual
El siguiente diagrama ilustra la arquitectura simple que puede utilizar para implementar la solución.
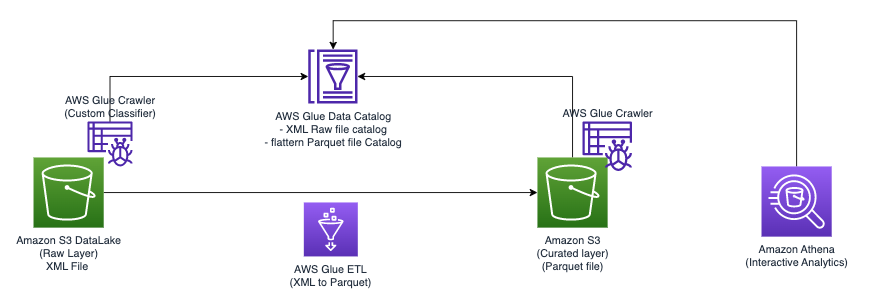
Para analizar archivos XML almacenados en Amazon S3 utilizando AWS Glue y Athena, completamos los siguientes pasos de alto nivel:
- Cree un rastreador de AWS Glue para extraer metadatos XML y crear una tabla en el catálogo de datos de AWS Glue.
- Procese y transforme datos XML en un formato (como Parquet) adecuado para Athena mediante un trabajo de extracción, transformación y carga (ETL) de AWS Glue.
- Configure y ejecute un trabajo de AWS Glue a través de la consola de AWS Glue o el Interfaz de línea de comandos de AWS (CLI de AWS).
- Utilice los datos procesados (en formato Parquet) con tablas de Athena, habilitando consultas SQL.
- Utilice la interfaz fácil de usar de Athena para analizar los datos XML con consultas SQL sobre sus datos almacenados en Amazon S3.
Esta arquitectura es una solución escalable y rentable para analizar datos XML en Amazon S3 utilizando AWS Glue y Athena. Puede analizar grandes conjuntos de datos sin una gestión de infraestructura compleja.
Usamos el rastreador de AWS Glue para extraer metadatos de archivos XML. Puede elegir el clasificador predeterminado de AWS Glue para la clasificación XML de uso general. Detecta automáticamente la estructura y el esquema de datos XML, lo que resulta útil para formatos comunes.
También utilizamos un clasificador XML personalizado en esta solución. Está diseñado para esquemas o formatos XML específicos, lo que permite una extracción precisa de metadatos. Esto es ideal para formatos XML no estándar o cuando necesita un control detallado sobre la clasificación. Un clasificador personalizado garantiza que solo se extraigan los metadatos necesarios, lo que simplifica las tareas de análisis y procesamiento posteriores. Este enfoque optimiza el uso de sus archivos XML.
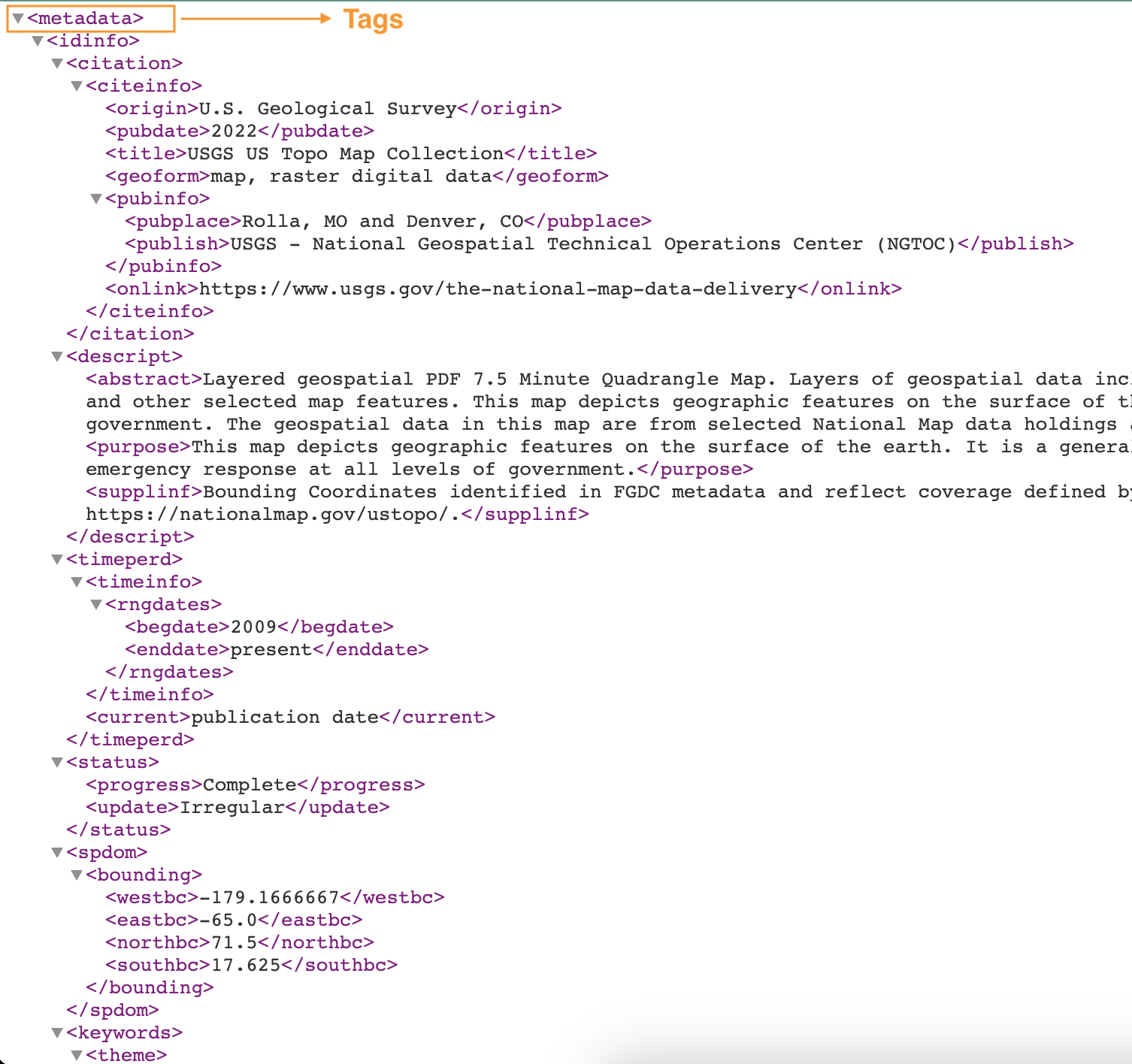
La siguiente captura de pantalla muestra un ejemplo de un archivo XML con etiquetas.
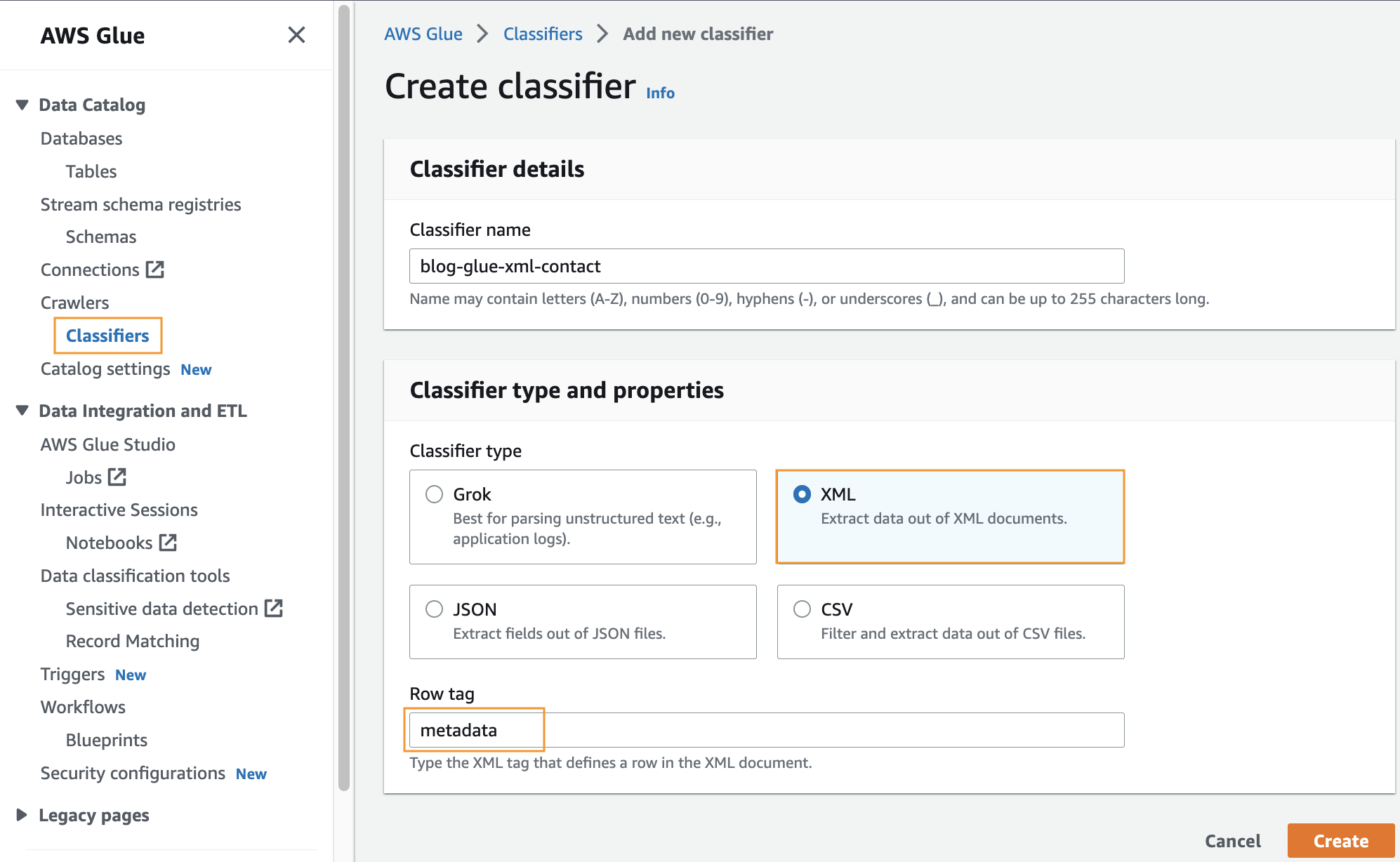
Crear un clasificador personalizado
En este paso, creará un clasificador de AWS Glue personalizado para extraer metadatos de un archivo XML. Complete los siguientes pasos:
- En la consola de AWS Glue, debajo de Rastreadores en el panel de navegación, elija Clasificadores.
- Elige Agregar clasificador.
- Seleccione XML como tipo de clasificador.
- Introduzca un nombre para el clasificador, como por ejemplo
blog-glue-xml-contact. - etiqueta de fila, ingrese el nombre de la etiqueta raíz que contiene los metadatos (por ejemplo,
metadata). - Elige Crear.
Cree un rastreador de AWS Glue para rastrear archivos xml
En esta sección, estamos creando un Glue Crawler para extraer los metadatos del archivo XML utilizando el clasificador de clientes creado en el paso anterior.
Crea una base de datos
- Visite la Consola de AWS Glue, escoger Bases de datos en el panel de navegación.
- Haga clic en Agregar base de datos.
- Proporcione un nombre como
blog_glue_xml - Elige Crear Base de datos
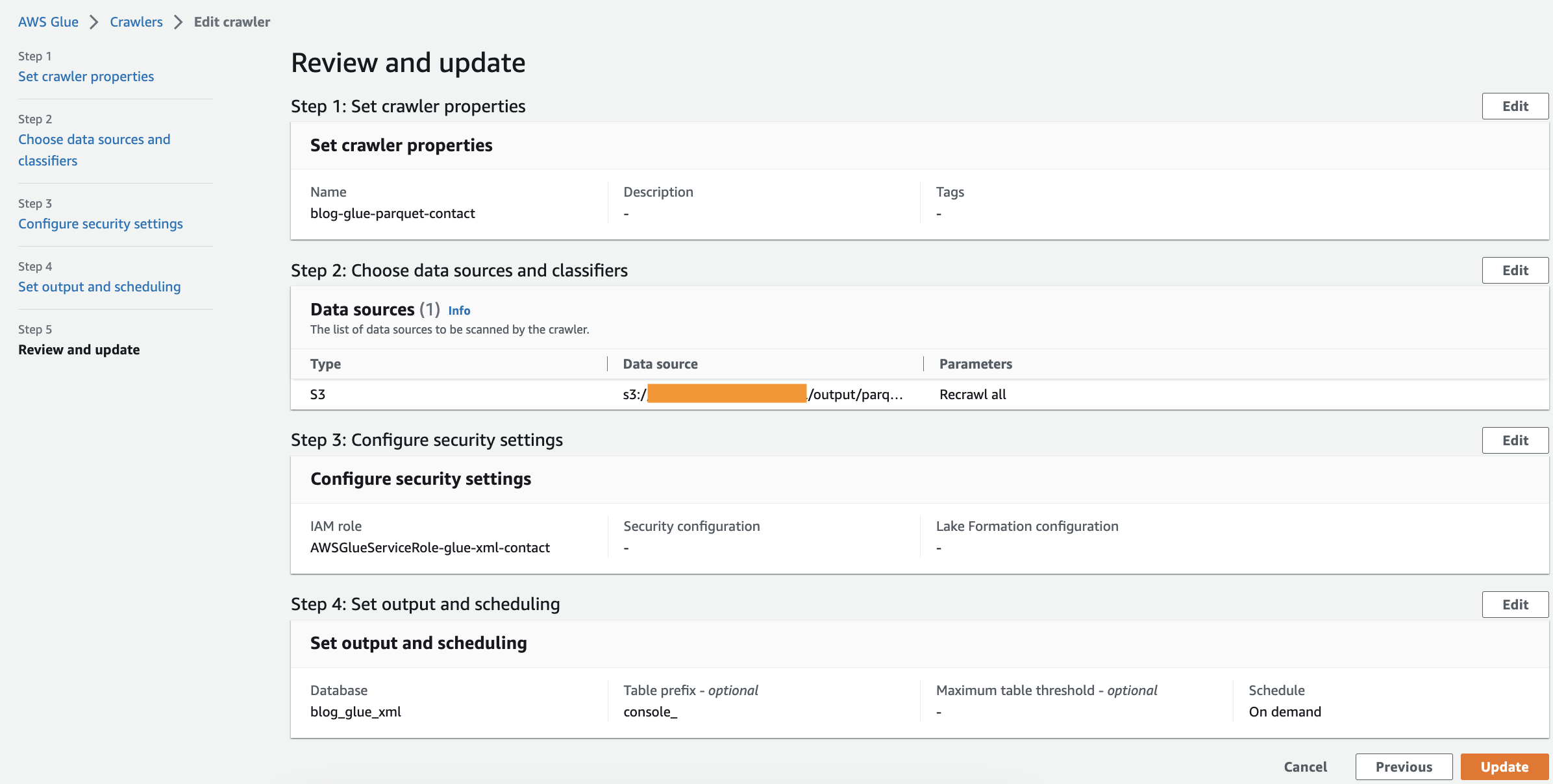
Crear un rastreador
Complete los siguientes pasos para crear su primer rastreador:
- En la consola de AWS Glue, elija Rastreadores en el panel de navegación.
- Elige Crear rastreador.
- En Establecer propiedades del rastreador página, proporcione un nombre para el nuevo rastreador (como
blog-glue-parquet), entonces escoge Siguiente. - En Elija fuentes de datos y clasificadores página, seleccione Aún no bajo Configuración de la fuente de datos.
- Elige Agregar un almacén de datos.
- ruta S3, navegar a
s3://${BUCKET_NAME}/input/geologicalsurvey/.
Asegúrese de elegir la carpeta XML en lugar del archivo dentro de la carpeta.
- Deje el resto de opciones por defecto y elija Agregar una fuente de datos S3.
- Expandir Clasificadores personalizados – opcional, elija blog-glue-xml-contact y luego elija Siguiente y mantener el resto de opciones por defecto.
- Elija su rol de IAM o elija Crear una nueva función de IAM, agrega el sufijo
glue-xml-contact(por ejemplo,AWSGlueServiceNotebookRoleBlog), y elige Siguiente. - En Establecer salida y programación página, debajo Configuración de salida, escoger
blog_glue_xmlpara Base de datos de destino. - Participar
console_como prefijo agregado a las tablas (opcional) y debajo Horario del rastreador, mantenga la frecuencia establecida en BAJO DEMANDA . - Elige Siguiente.
- Revise todos los parámetros y elija Crear rastreador.
Ejecute el rastreador
Después de crear el rastreador, complete los siguientes pasos para ejecutarlo:
- En la consola de AWS Glue, elija Rastreadores en el panel de navegación.
- Abra el rastreador que creó y elija Ejecutar.
El rastreador tardará entre 1 y 2 minutos en completarse.
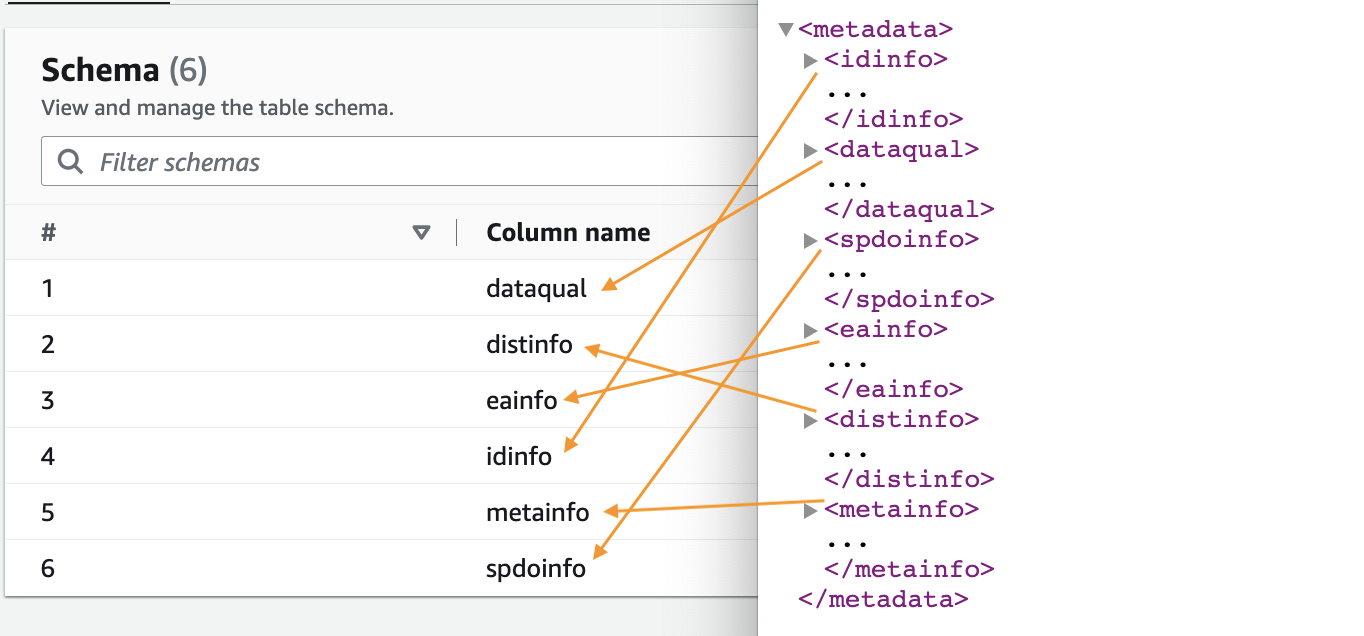
- Cuando el rastreador esté completo, elija Bases de datos en el panel de navegación.
- Elija la base de datos que creó y elija el nombre de la tabla para ver el esquema extraído por el rastreador.
Cree un trabajo de AWS Glue para convertir el formato XML a Parquet
En este paso, creará un trabajo de AWS Glue Studio para convertir el archivo XML en un archivo Parquet. Complete los siguientes pasos:
- En la consola de AWS Glue, elija Empleo en el panel de navegación.
- under Crear trabajo, seleccione Visual con un lienzo en blanco.
- Elige Crear.
- Cambie el nombre del trabajo a
blog_glue_xml_job.
Ahora tiene un editor de trabajos visual de AWS Glue Studio en blanco. En la parte superior del editor están las pestañas para diferentes vistas.
- Elija el Guión para ver un shell vacío del script ETL de AWS Glue.
A medida que agreguemos nuevos pasos en el editor visual, el script se actualizará automáticamente.
- Elija el Detalles del trabajo pestaña para ver todas las configuraciones del trabajo.
- Rol de IAM, escoger
AWSGlueServiceNotebookRoleBlog. - Versión con pegamento, escoger Pegamento 4.0 – Compatible con Spark 3.3, Scala 2, Python 3.
- Set Número solicitado de trabajadores a 2.
- Set Número de reintentos a 0.
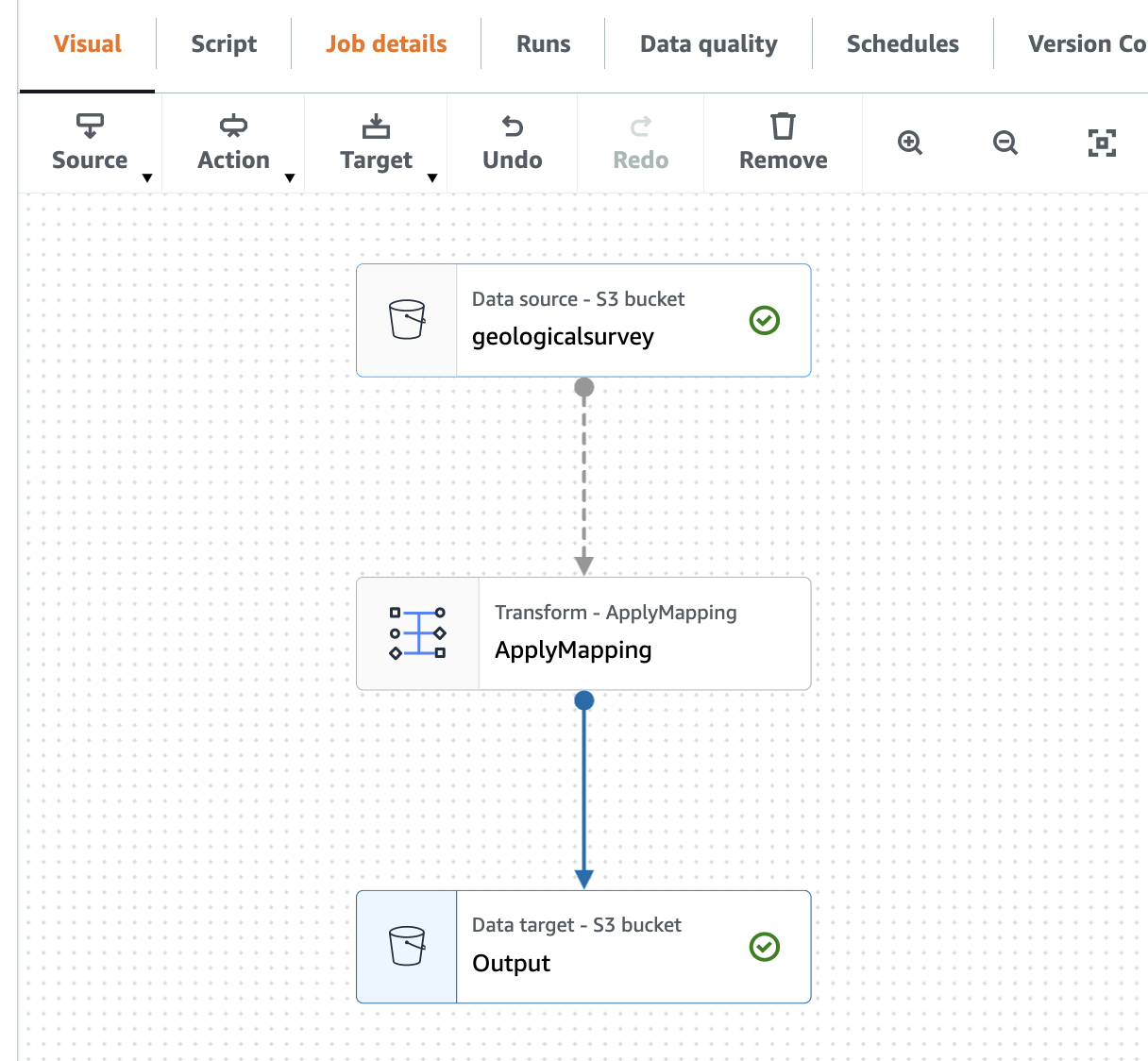
- Elija el Visual pestaña para volver al editor visual.
- En Fuente menú desplegable, elija Catálogo de datos de AWS Glue.
- En Propiedades de la fuente de datos: catálogo de datos pestaña, proporcione la siguiente información:
- Base de datos, escoger
blog_glue_xml. - Mesa, elija la tabla que comienza con el nombre console_ que creó el rastreador (por ejemplo,
console_geologicalsurvey).
- Base de datos, escoger
- En Propiedades del nodo pestaña, proporcione la siguiente información:
- Cambios Nombre a
geologicalsurveyconjunto de datos - Elige la columna Acción y la transformación Cambiar esquema (aplicar asignación).
- Elige Propiedades del nodo y cambie el nombre de la transformación de Cambiar esquema (Aplicar mapeo) a
ApplyMapping. - En Target menú, seleccione S3.
- Cambios Nombre a
- En Propiedades de la fuente de datos: S3 pestaña, proporcione la siguiente información:
- Formato, seleccione parquet.
- Tipo de compresión, seleccione Sin comprimir.
- Tipo de fuente S3, seleccione Ubicación S3.
- URL de S3, introduzca
s3://${BUCKET_NAME}/output/parquet/. - Elige Propiedades del nodo y cambia el nombre a
Output.
- Elige Guardar para salvar el trabajo.
- Elige Ejecutar para ejecutar el trabajo.
La siguiente captura de pantalla muestra el trabajo en el editor visual.
Cree un AWS Gue Crawler para rastrear el archivo Parquet
En este paso, creará un rastreador de AWS Glue para extraer metadatos del archivo Parquet que creó mediante un trabajo de AWS Glue Studio. Esta vez, utiliza el clasificador predeterminado. Complete los siguientes pasos:
- En la consola de AWS Glue, elija Rastreadores en el panel de navegación.
- Elige Crear rastreador.
- En Establecer propiedades del rastreador página, proporcione un nombre para el nuevo rastreador, como blog-glue-parquet-contact, luego elija Siguiente.
- En Elija fuentes de datos y clasificadores página, seleccione Aún no para Configuración de la fuente de datos.
- Elige Agregar un almacén de datos.
- ruta S3, navegar a
s3://${BUCKET_NAME}/output/parquet/.
Asegúrate de elegir el parquet carpeta en lugar del archivo dentro de la carpeta.
- Elija su rol de IAM creado durante la sección de requisitos previos o elija Crear una nueva función de IAM (por ejemplo,
AWSGlueServiceNotebookRoleBlog), y elige Siguiente. - En Establecer salida y programación página, debajo Configuración de salida, escoger
blog_glue_xmlpara Base de datos. - Participar
parquet_como prefijo agregado a las tablas (opcional) y debajo Horario del rastreador, mantenga la frecuencia establecida en BAJO DEMANDA . - Elige Siguiente.
- Revise todos los parámetros y elija Crear rastreador.
Ahora puede ejecutar el rastreador, que tarda entre 1 y 2 minutos en completarse.

Puede obtener una vista previa del esquema recién creado para el archivo Parquet en el catálogo de datos de AWS Glue, que es similar al esquema del archivo XML.
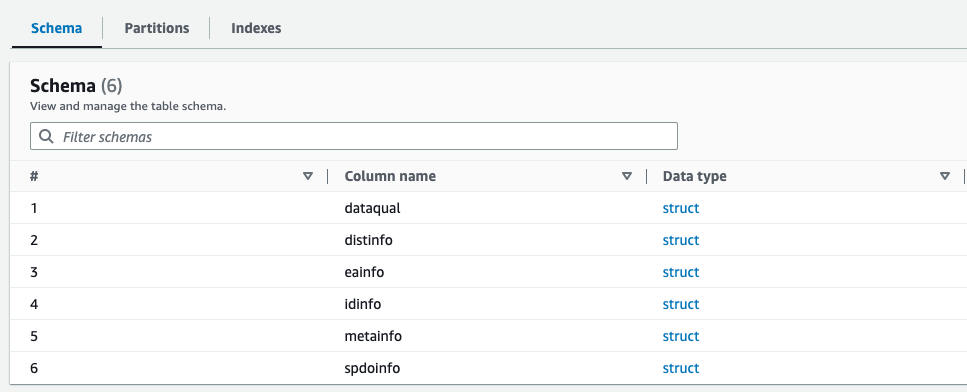
Ahora poseemos datos que son adecuados para su uso con Athena. En la siguiente sección, realizamos consultas de datos utilizando Athena.
Consultar el archivo Parquet usando Athena
Athena no admite la consulta del formato de archivo XML, razón por la cual convirtió el archivo XML a Parquet para una consulta y un uso de datos más eficientes. notación de puntos para consultar tipos complejos y estructuras anidadas.
El siguiente código de ejemplo utiliza notación de puntos para consultar datos anidados:
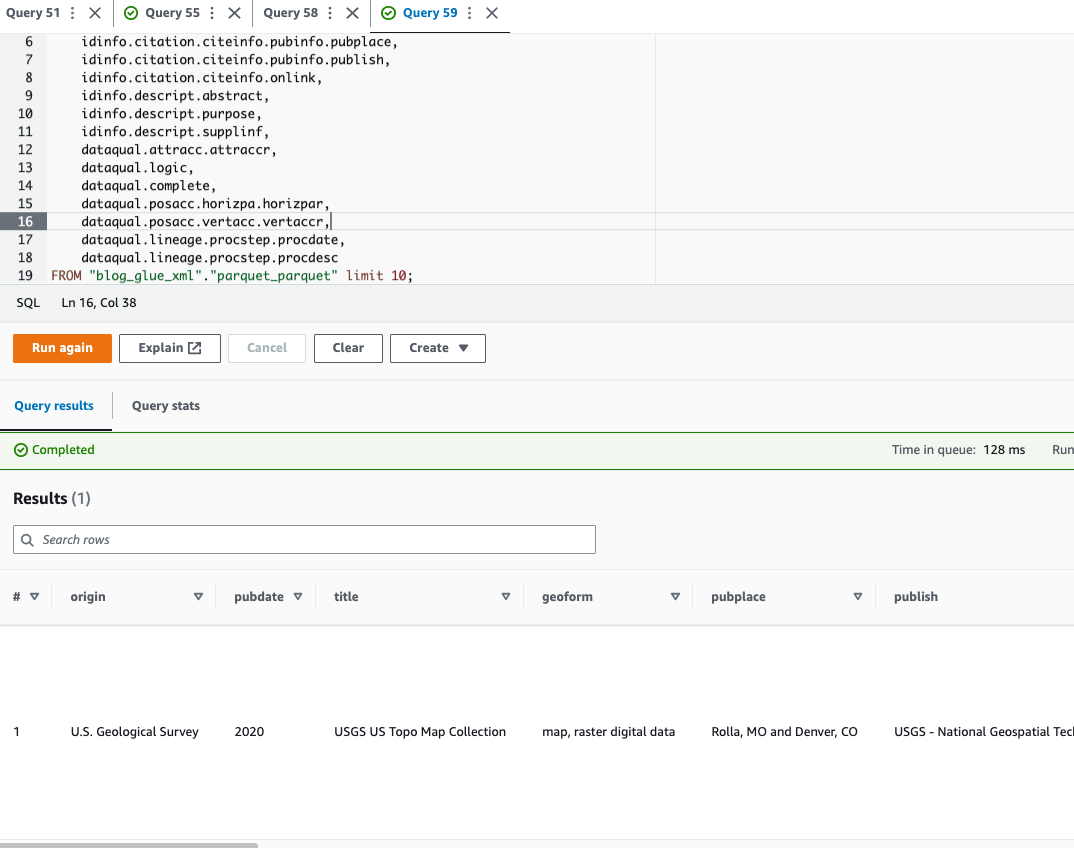
Ahora que hemos completado la técnica 1, pasemos a aprender sobre la técnica 2.
Técnica 2: utilice AWS Glue DynamicFrames con esquemas inferidos y fijos
En la sección anterior, cubrimos el proceso de manejo de un pequeño archivo XML utilizando un rastreador de AWS Glue para generar una tabla, un trabajo de AWS Glue para convertir el archivo al formato Parquet y Athena para acceder a los datos de Parquet. Sin embargo, el rastreador encuentra limitaciones cuando se trata de procesar archivos XML que exceden 1 MB de tamaño. En esta sección, profundizamos en el tema del procesamiento por lotes de archivos XML más grandes, lo que requiere un análisis adicional para extraer eventos individuales y realizar análisis utilizando Athena.
Nuestro enfoque implica leer los archivos XML a través de AWS Glue Marcos dinámicos, empleando esquemas tanto inferidos como fijos. Luego extraemos los eventos individuales en formato Parquet usando el relacionar transformación, lo que nos permite consultarlos y analizarlos sin problemas utilizando Athena.
Para implementar esta solución, complete los siguientes pasos de alto nivel:
- Cree un cuaderno de AWS Glue para leer y analizar el archivo XML.
- Uso
DynamicFramesInferSchemapara leer el archivo XML. - Utilice la función relacional para desanidar cualquier matriz.
- Convierta los datos al formato Parquet.
- Consulta los datos de Parquet usando Athena.
- Repita los pasos anteriores, pero esta vez pase un esquema a
DynamicFramesEn lugar de usarInferSchema.
El archivo XML de datos de población de vehículos eléctricos tiene un response etiqueta en su nivel raíz. Esta etiqueta contiene una serie de row etiquetas, que están anidadas dentro de él. La etiqueta de fila es una matriz que contiene un conjunto de otras etiquetas de fila, que proporcionan información sobre un vehículo, incluida su marca, modelo y otros detalles relevantes. La siguiente captura de pantalla muestra un ejemplo.

Cree un cuaderno de AWS Glue
Para crear un cuaderno de AWS Glue, complete los siguientes pasos:
- Abra la Estudio de pegamento de AWS consola, elige Empleo en el panel de navegación.
- Seleccione Cuaderno Jupyter y elige Crear.
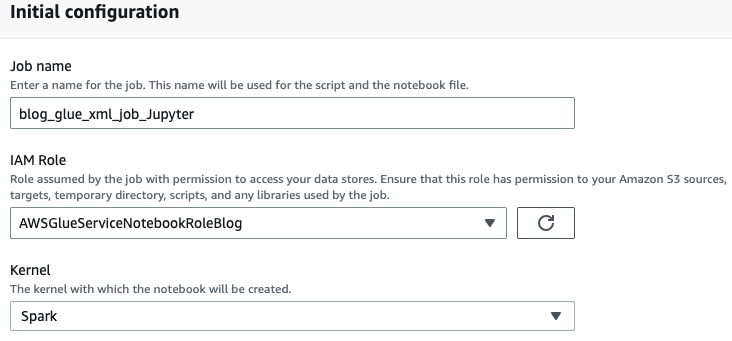
- Introduzca un nombre para su trabajo de AWS Glue, como
blog_glue_xml_job_Jupyter. - Elija el rol que creó en los requisitos previos (
AWSGlueServiceNotebookRoleBlog).
El cuaderno de AWS Glue viene con un ejemplo preexistente que demuestra cómo consultar una base de datos y escribir el resultado en Amazon S3.
- Ajuste el tiempo de espera (en minutos) como se muestra en la siguiente captura de pantalla y ejecute la celda para crear la sesión interactiva de AWS Glue.
Crear variables básicas
Después de crear la sesión interactiva, al final del cuaderno, cree una nueva celda con las siguientes variables (proporcione su propio nombre de depósito):
Leer el archivo XML infiriendo el esquema.
Si no pasa un esquema al DynamicFrame, inferirá el esquema de los archivos. Para leer los datos usando un marco dinámico, puede usar el siguiente comando:
Imprima el esquema DynamicFrame
Imprima el esquema con el siguiente código:
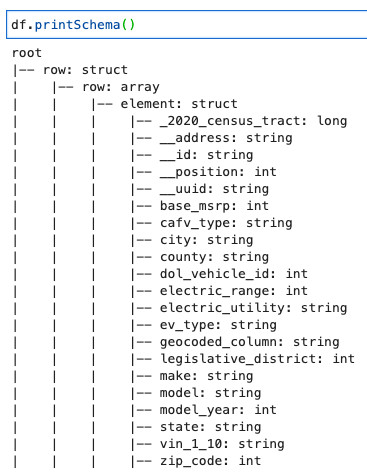
El esquema muestra una estructura anidada con un row matriz que contiene múltiples elementos. Para desanidar esta estructura en líneas, puede utilizar AWS Glue relacionar transformación:
Solo nos interesa la información contenida en la matriz de filas y podemos ver el esquema usando el siguiente comando:
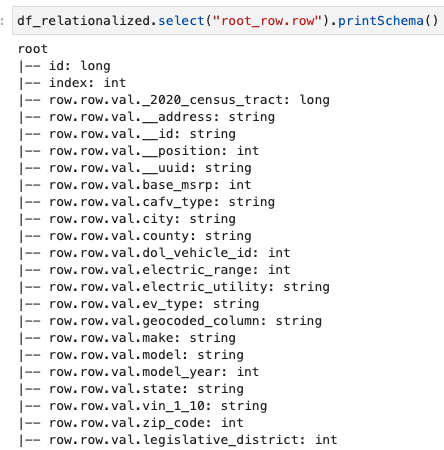
Los nombres de las columnas contienen row.row, que corresponden a la estructura de la matriz y la columna de la matriz en el conjunto de datos. No cambiamos el nombre de las columnas en esta publicación; para obtener instrucciones sobre cómo hacerlo, consulte Automatice el mapeo dinámico y el cambio de nombre de nombres de columnas en archivos de datos con AWS Glue: Parte 1. Luego puede convertir los datos al formato Parquet y crear la tabla de AWS Glue usando el siguiente comando:
Pegamento AWS DynamicFrame proporciona funciones que puede utilizar en su secuencia de comandos ETL para crear y actualizar un esquema en el catálogo de datos. Usamos el updateBehavior parámetro para crear la tabla directamente en el catálogo de datos. Con este enfoque, no necesitamos ejecutar un rastreador de AWS Glue una vez completado el trabajo de AWS Glue.

Leer el archivo XML estableciendo un esquema
Una forma alternativa de leer el archivo es predefinir un esquema. Para hacer esto, complete los siguientes pasos:
- Importe los tipos de datos de AWS Glue:
- Cree un esquema para el archivo XML:
- Pase el esquema al leer el archivo XML:
- Desanida el conjunto de datos como antes:
- Convierta el conjunto de datos a Parquet y cree la tabla de AWS Glue:
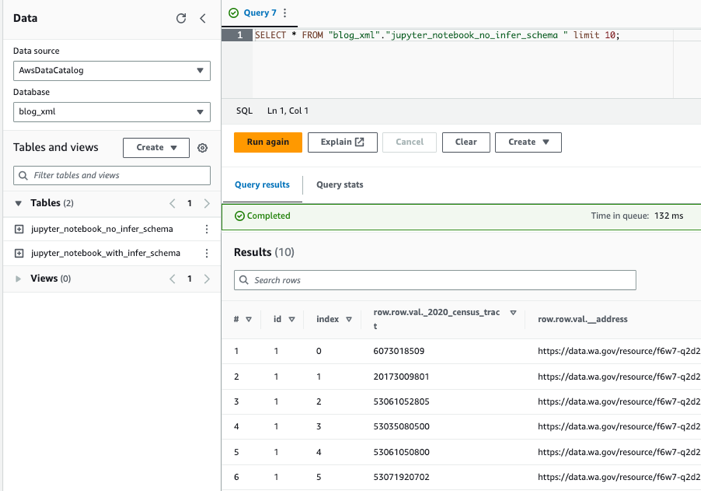
Consultar las tablas usando Athena.
Ahora que hemos creado ambas tablas, podemos consultarlas usando Athena. Por ejemplo, podemos utilizar la siguiente consulta:
Limpiar
En esta publicación, creamos una función de IAM, un cuaderno Jupyter de AWS Glue y dos tablas en el catálogo de datos de AWS Glue. También subimos algunos archivos a un depósito de S3. Para limpiar estos objetos, complete los siguientes pasos:
- En la consola de IAM, elimine el rol que creó.
- En la consola de AWS Glue Studio, elimine el clasificador personalizado, el rastreador, los trabajos ETL y el cuaderno Jupyter.
- Navegue hasta el catálogo de datos de AWS Glue y elimine las tablas que creó.
- En la consola de Amazon S3, navegue hasta el depósito que creó y elimine las carpetas denominadas
temp,infer_schemayno_infer_schema.
Puntos clave
En AWS Glue, hay una característica llamada InferSchema en pegamento AWS DynamicFrames. Calcula automáticamente la estructura de un marco de datos en función de los datos que contiene. Por el contrario, definir un esquema significa indicar explícitamente cómo debe ser la estructura del marco de datos antes de cargar los datos.
XML, al ser un formato basado en texto, no restringe los tipos de datos de sus columnas. Esto puede causar problemas con la función InferSchema. Por ejemplo, en la primera ejecución, un archivo con la columna A que tiene un valor de 2 da como resultado un archivo Parquet con la columna A como un número entero. En la segunda ejecución, un nuevo archivo tiene la columna A con el valor C, lo que lleva a un archivo Parquet con la columna A como cadena. Ahora hay dos archivos en S3, cada uno con una columna A de diferentes tipos de datos, lo que puede crear problemas posteriores.
Lo mismo ocurre con tipos de datos complejos como estructuras o matrices anidadas. Por ejemplo, si un archivo tiene una entrada de etiqueta llamada transaction, se infiere como una estructura. Pero si otro archivo tiene la misma etiqueta, se infiere como una matriz.
A pesar de estos problemas con el tipo de datos, InferSchema Es útil cuando no se conoce el esquema o definir uno manualmente no es práctico. Sin embargo, no es ideal para conjuntos de datos grandes o que cambian constantemente. Definir un esquema es más preciso, especialmente con tipos de datos complejos, pero tiene sus propios problemas, como requerir esfuerzo manual y ser inflexible a los cambios de datos.
InferSchema tiene limitaciones, como inferencia incorrecta de tipos de datos y problemas con el manejo de valores nulos. La definición de un esquema también tiene limitaciones, como el esfuerzo manual y posibles errores.
La elección entre inferir y definir un esquema depende de las necesidades del proyecto. InferSchema es excelente para la exploración rápida de conjuntos de datos pequeños, mientras que definir un esquema es mejor para conjuntos de datos más grandes y complejos que requieren precisión y coherencia. Considere las ventajas y desventajas de cada método para elegir el que mejor se adapte a su proyecto.
Conclusión
En esta publicación, exploramos dos técnicas para administrar datos XML mediante AWS Glue, cada una diseñada para abordar las necesidades y desafíos específicos que pueda encontrar.
La técnica 1 ofrece un camino fácil de usar para quienes prefieren una interfaz gráfica. Puede utilizar un rastreador de AWS Glue y el editor visual para definir sin esfuerzo la estructura de la tabla para sus archivos XML. Este enfoque simplifica el proceso de gestión de datos y resulta especialmente atractivo para quienes buscan una forma sencilla de gestionar sus datos.
Sin embargo, reconocemos que el rastreador tiene sus limitaciones, específicamente cuando se trata de archivos XML con filas de más de 1 MB. Aquí es donde la técnica 2 viene al rescate. Aprovechando AWS Glue DynamicFrames Con esquemas inferidos y fijos, y empleando un cuaderno de AWS Glue, puede manejar de manera eficiente archivos XML de cualquier tamaño. Este método proporciona una solución sólida que garantiza un procesamiento fluido incluso para archivos XML con filas que superan la restricción de 1 MB.
Mientras navega por el mundo de la gestión de datos, tener estas técnicas en su kit de herramientas le permitirá tomar decisiones informadas basadas en los requisitos específicos de su proyecto. Ya sea que prefiera la simplicidad de la técnica 1 o la escalabilidad de la técnica 2, AWS Glue proporciona la flexibilidad que necesita para manejar datos XML de manera eficaz.
Acerca de los autores
 Navnit ShuklaSe desempeña como arquitecto de soluciones especializado en AWS con un enfoque en análisis. Posee un gran entusiasmo por ayudar a los clientes a descubrir información valiosa a partir de sus datos. A través de su experiencia, construye soluciones innovadoras que permiten a las empresas tomar decisiones informadas y basadas en datos. En particular, Navnit Shukla es el consumado autor del libro titulado “Data Wrangling on AWS”.
Navnit ShuklaSe desempeña como arquitecto de soluciones especializado en AWS con un enfoque en análisis. Posee un gran entusiasmo por ayudar a los clientes a descubrir información valiosa a partir de sus datos. A través de su experiencia, construye soluciones innovadoras que permiten a las empresas tomar decisiones informadas y basadas en datos. En particular, Navnit Shukla es el consumado autor del libro titulado “Data Wrangling on AWS”.
 patricio muller Trabaja como arquitecto senior de laboratorio de datos en AWS. Su principal responsabilidad es ayudar a los clientes a convertir sus ideas en un producto de datos listo para producción. En su tiempo libre, a Patrick le gusta jugar fútbol, ver películas y viajar.
patricio muller Trabaja como arquitecto senior de laboratorio de datos en AWS. Su principal responsabilidad es ayudar a los clientes a convertir sus ideas en un producto de datos listo para producción. En su tiempo libre, a Patrick le gusta jugar fútbol, ver películas y viajar.
 Amogh Gaikwad es desarrollador senior de soluciones en Amazon Web Services. Ayuda a clientes globales a crear e implementar soluciones de IA/ML en AWS. Su trabajo se centra principalmente en la visión por computadora y el procesamiento del lenguaje natural, y en ayudar a los clientes a optimizar sus cargas de trabajo de IA/ML para lograr la sostenibilidad. Amogh recibió su maestría en Ciencias de la Computación con especialización en Aprendizaje Automático.
Amogh Gaikwad es desarrollador senior de soluciones en Amazon Web Services. Ayuda a clientes globales a crear e implementar soluciones de IA/ML en AWS. Su trabajo se centra principalmente en la visión por computadora y el procesamiento del lenguaje natural, y en ayudar a los clientes a optimizar sus cargas de trabajo de IA/ML para lograr la sostenibilidad. Amogh recibió su maestría en Ciencias de la Computación con especialización en Aprendizaje Automático.
 Sheela Sonone es arquitecto residente sénior en AWS. Ayuda a los clientes de AWS a tomar decisiones informadas y hacer concesiones sobre la aceleración de sus cargas de trabajo e implementaciones de datos, análisis y AI/ML. En su tiempo libre le gusta pasar tiempo con su familia, normalmente en las canchas de tenis.
Sheela Sonone es arquitecto residente sénior en AWS. Ayuda a los clientes de AWS a tomar decisiones informadas y hacer concesiones sobre la aceleración de sus cargas de trabajo e implementaciones de datos, análisis y AI/ML. En su tiempo libre le gusta pasar tiempo con su familia, normalmente en las canchas de tenis.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- :posee
- :es
- :no
- :dónde
- $ UP
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- Nuestra Empresa
- RESUMEN
- acelerador
- de la máquina
- accesibilidad
- logrado
- la exactitud
- a través de
- la columna Acción
- add
- adicional
- Adicionales
- dirección
- Después
- edad
- AI / ML
- Todos
- permitir
- Permitir
- permite
- también
- alternativa
- Amazon
- Atenea amazónica
- Amazon Web Services
- an
- análisis
- Analytics
- analizar
- el análisis de
- y
- Otra
- cualquier
- APACHE
- atractivo
- aplicaciones
- Aplicá
- enfoque
- enfoques
- arquitectura
- somos
- Formación
- AS
- ayudar
- ayudando
- At
- autor
- automáticamente
- Hoy Disponibles
- AWS
- Pegamento AWS
- Atrás
- basado
- básica
- BE
- porque
- antes
- comenzar
- "Ser"
- MEJOR
- mejores
- entre
- en blanco
- primer libro
- ambas
- build
- negocios
- pero
- by
- , que son
- PUEDEN
- catalogar
- Causa
- (SCD por sus siglas en inglés),
- retos
- el cambio
- Cambios
- cambio
- opciones
- Elige
- Ciudad
- clasificación
- clientes
- código
- Columna
- Columnas
- COM
- proviene
- Algunos
- comúnmente
- completar
- Completado
- integraciones
- computadora
- Ciencias de la Computación
- Visión por computador
- condición
- Conducir
- conjunción
- Considerar
- Consola
- constantemente
- restricciones
- construir
- que no contengo
- contenida
- contiene
- contraste
- control
- convertir
- convertido
- rentable
- solución rentable
- condado
- Tribunales
- cubierto
- rastreador
- Para crear
- creado
- Creamos
- crucial
- personalizado
- cliente
- Clientes
- datos
- integración de datos
- datos de gestión
- basada en datos
- Base de datos
- conjuntos de datos
- tratar
- decisiones
- Predeterminado
- definir
- definir
- ahondar
- demuestra
- depende
- desplegar
- diseñado
- detallado
- detalles
- Developer
- una experiencia diferente
- difícil
- digital
- era digital
- directamente
- descubrir
- distinto
- do
- No
- hecho
- No
- DOT
- durante
- lugar de trabajo dinámico
- cada una
- facilidad
- pasan fácilmente
- de forma sencilla
- editor
- efecto
- de manera eficaz
- eficiencia
- eficiente
- eficiente.
- esfuerzo
- sin esfuerzo
- Los
- vehículo eléctrico
- elementos
- empleando
- empoderar a
- empodera
- vacío
- habilitar
- permitiendo
- encuentro
- final
- motores
- mejorar
- garantizar
- asegura
- Participar
- entusiasmo
- entrada
- Errores
- especialmente
- Éter (ETH)
- Incluso
- Eventos
- Cada
- ejemplo
- exceden
- intercambiar
- Experiencia
- exploración
- explorar
- explorado
- extraerlos
- Extracción
- familia
- Feature
- Caracteristicas
- Figuras
- Archive
- archivos
- financiar
- Nombre
- fijas
- Flexibilidad
- Focus
- centrado
- siguiendo
- formato
- FRAME
- Gratuito
- Frecuencia
- Desde
- función
- Obtén
- propósito general
- generar
- Buscar
- Go
- objetivo
- Gobierno
- maravillosa
- encargarse de
- Manejo
- que sucede
- Aprovechamiento
- Tienen
- es
- he
- la salud
- Corazón
- ayuda
- ayudando
- ayuda
- aquí
- de alto nivel
- altamente
- su
- Cómo
- Como Hacer
- Sin embargo
- HTML
- http
- HTTPS
- AMI
- ideal
- ideas
- Identidad
- if
- ilustra
- implementar
- implementaciones
- implementación
- importar
- mejorar
- mejorado
- in
- Incluye
- INSTRUMENTO individual
- individuos
- industrias
- información
- informó
- EN LA MINA
- originales
- dentro
- Insights
- Instrucciones
- integrar
- integración
- interactivo
- interesado
- Interfaz
- dentro
- implica
- cuestiones
- IT
- SUS
- Trabajos
- Empleo
- jpg
- json
- Cuaderno Jupyter
- Guardar
- Saber
- el lab
- idioma
- large
- mayores
- líder
- APRENDE:
- aprendizaje
- Nivel
- como
- LIMITE LAS
- la limitación
- limitaciones
- línea
- líneas
- carga
- carga
- lógica
- mirando
- máquina
- máquina de aprendizaje
- Inicio
- principalmente
- para lograr
- Realizar
- Management
- administrar
- manual
- a mano
- muchos
- cartografía
- Máster
- Puede..
- significa
- Menú
- metadatos
- Método
- minutos
- modelo
- más,
- más eficiente
- MEJOR DE TU
- movimiento
- Películas
- múltiples
- nombre
- Llamado
- nombres
- Natural
- Lenguaje natural
- Procesamiento natural del lenguaje
- Navegar
- Navegación
- necesario
- ¿ Necesita ayuda
- Nuevo
- recién
- Next
- notablemente
- cuaderno
- ahora
- número
- objetos
- of
- Ofertas
- on
- ONE
- , solamente
- Operaciones
- óptimo
- Optimización
- Optimiza
- Opciones
- or
- solicite
- para las fiestas.
- Natural
- Otro
- nuestros
- salir
- salida
- Más de
- Superar
- EL DESARROLLADOR
- página
- cristal
- parámetro
- parámetros
- parte
- particularmente
- pass
- camino
- Patricio
- realizar
- actuación
- permisos
- recoger
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- jugando
- política
- población
- poseer
- Publicación
- posible
- necesidad
- preferir
- requisitos previos
- Vista previa
- anterior
- problemas
- procesado
- tratamiento
- Producto
- proyecto
- proyecta
- propiedades
- proporcionar
- proporciona un
- publicar
- propósito
- Python
- consultas
- Búsqueda
- más bien
- Leer
- fácilmente
- Reading
- razones
- recibido
- reconocer
- remitir
- Requisitos
- rescatar
- Recurso
- respuesta
- responsabilidad
- RESTO
- restringir
- restricción
- Resultados
- robusto
- Función
- raíz
- FILA
- Ejecutar
- mismo
- Guardar
- Scala
- Escalabilidad
- escalable
- Ciencia:
- guión
- sin costura
- sin problemas
- Segundo
- Sección
- ver
- mayor
- Servicios
- Sesión
- set
- pólipo
- Varios
- ella
- Cáscara
- tienes
- Mostrar
- mostrado
- Shows
- similares
- sencillos
- sencillez
- simplificando
- soltero
- Tamaño
- chica
- So
- Fútbol
- a medida
- Soluciones
- algo
- Fuente
- Fuentes
- Spark
- especialista
- especializada
- soluciones y
- específicamente
- velocidad
- Gastos
- SQL
- estándar
- comienza
- Estado
- Posicionamiento
- indicando
- paso
- pasos
- STORAGE
- almacenados
- sencillo
- aerodinamizar
- Cordón
- fuerte
- estructura
- estructuras
- estudio
- comercial
- tal
- adecuado
- SOPORTE
- seguro
- Sostenibilidad
- Todas las funciones a su disposición
- mesa
- ETIQUETA
- adaptado
- ¡Prepárate!
- toma
- tareas
- técnicas
- tenis
- que
- esa
- La
- la información
- el mundo
- su
- Les
- luego
- Ahí.
- Estas
- ellos
- así
- aquellos
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- Título
- titulada
- a
- de hoy
- caja de herramientas
- parte superior
- tema
- Transformar
- Viajar
- Turning
- tutoriales
- dos
- tipo
- tipos
- superior
- bajo
- Actualizar
- actualizado
- subido
- us
- usabilidad
- utilizan el
- usado
- Usuario
- Interfaz de usuario
- fácil de utilizar
- usos
- usando
- generalmente
- Utilizando
- Valioso
- propuesta de
- Valores
- vehículo
- versión
- vía
- Ver
- vistas
- visión
- ver
- Camino..
- we
- web
- servicios web
- ¿
- cuando
- mientras
- sean
- que
- QUIENES
- porque
- seguirá
- dentro de
- sin
- Actividades:
- flujo de trabajo
- flujos de trabajo
- funciona
- mundo
- escribir
- XML
- Usted
- tú
- zephyrnet