Post patrocinado

Los desafíos de construir modelos multimodales desde cero
Para muchos casos de uso de aprendizaje automático, las organizaciones confían únicamente en datos tabulares y modelos basados en árboles como XGBoost y LightGBM. Esto se debe a que el aprendizaje profundo es simplemente demasiado difícil para la mayoría de los equipos de ML. Los desafíos comunes incluyen:
- Falta de conocimiento experto necesario para desarrollar modelos complejos de aprendizaje profundo
- Los marcos como PyTorch y Tensorflow requieren que los equipos escriban miles de líneas de código que son propensas a errores humanos.
- El entrenamiento de canalizaciones DL distribuidas requiere un conocimiento profundo de la infraestructura y puede llevar semanas entrenar modelos
Como resultado, los equipos pierden señales valiosas ocultas en datos no estructurados como texto e imágenes.
Desarrollo rápido de modelos con sistemas declarativos
Los nuevos sistemas declarativos de aprendizaje automático, como el código abierto que Ludwig comenzó en Uber, brindan un enfoque de código bajo para automatizar el aprendizaje automático que permite a los equipos de datos crear e implementar modelos de última generación más rápido con un archivo de configuración simple. Específicamente, Predibase, la plataforma líder de aprendizaje automático declarativo de código bajo, junto con Ludwig facilitan la creación de modelos de aprendizaje profundo multimodales en < 15 líneas de código.
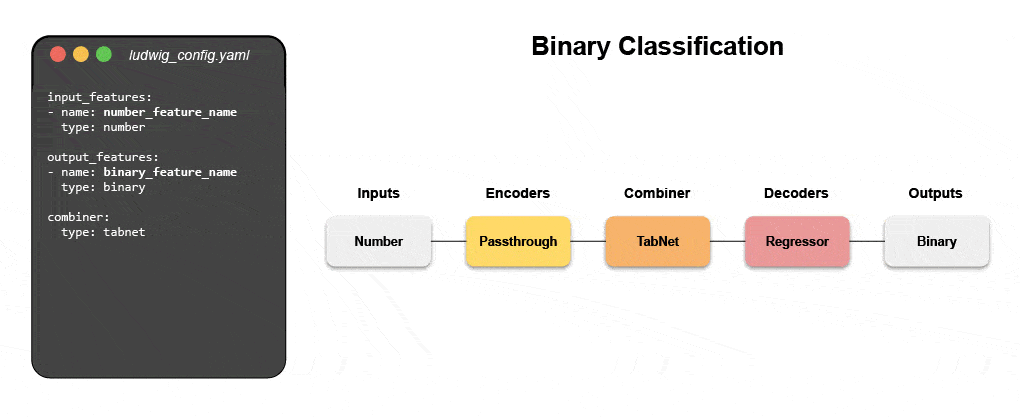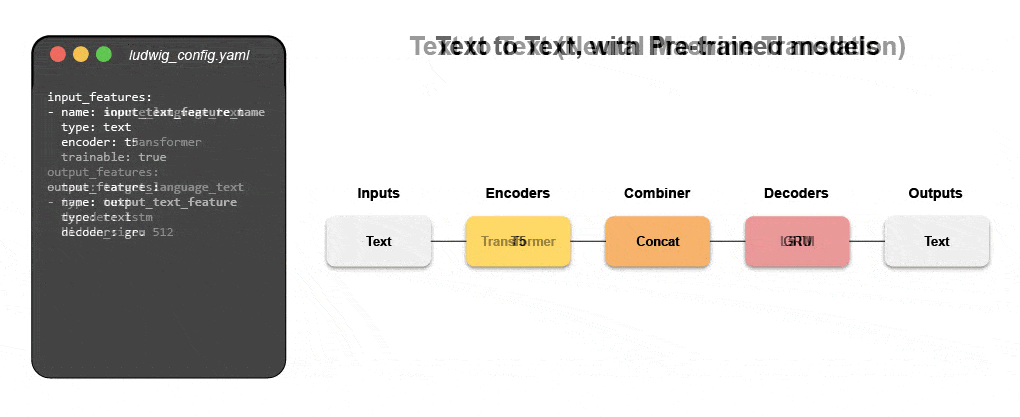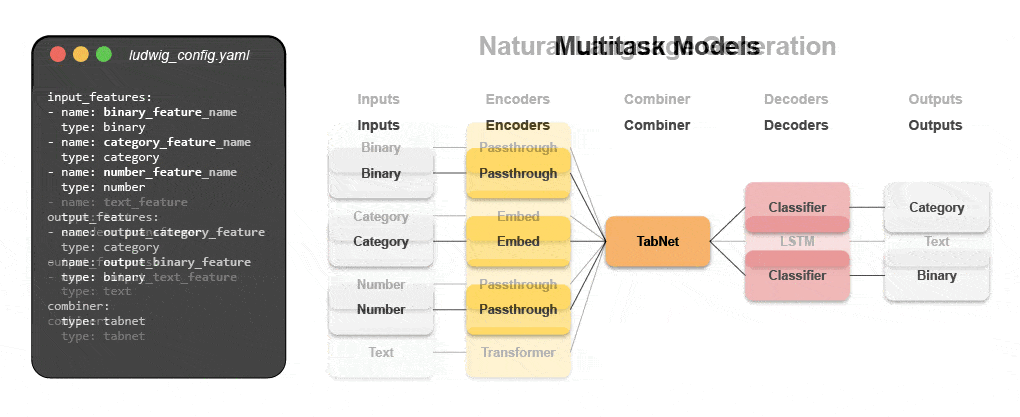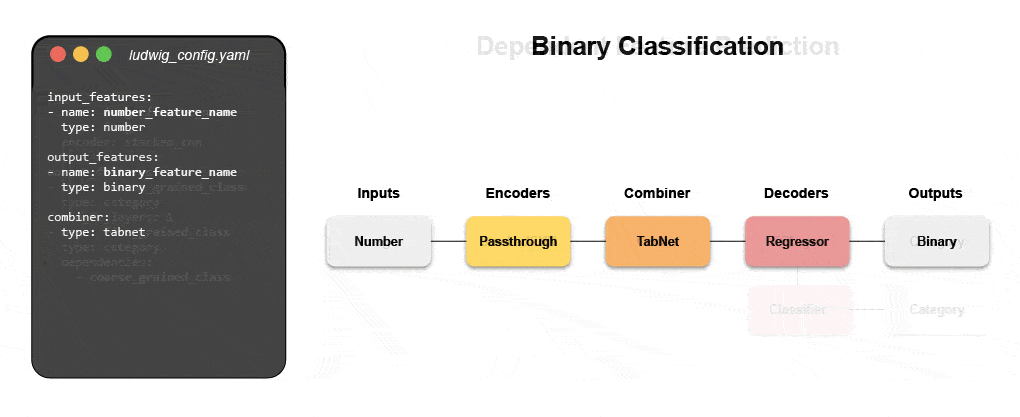
Aprenda a construir un modelo multimodal con ML declarativo
Únase a nuestro próximo seminario web y un tutorial en vivo para aprender sobre sistemas declarativos como Ludwig y seguir las instrucciones paso a paso para crear un modelo de predicción de revisión de clientes multimodal que aproveche el texto y los datos tabulares.
En esta sesión aprenderás a:
- Entrene, itere e implemente rápidamente un modelo multimodal para predicciones de revisión de clientes,
- Utilice herramientas de aprendizaje automático declarativo de código bajo para reducir drásticamente el tiempo que lleva crear varios modelos de aprendizaje automático.
- Aproveche los datos no estructurados con la misma facilidad que los datos estructurados con Ludwig y Predibase de código abierto
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/01/predibase-multi-modal-deep-learning-less-15-lines-code.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-modal-deep-learning-in-less-than-15-lines-of-code
- a
- Sobre nosotros
- y
- enfoque
- automatizar
- porque
- build
- Construir la
- retos
- código
- Algunos
- integraciones
- Configuración
- cliente
- datos
- profundo
- deep learning
- desplegar
- desarrollar
- Desarrollo
- distribuidos
- dramáticamente
- pasan fácilmente
- permite
- error
- experto
- más rápida
- Archive
- seguir
- en
- gif
- Difícil
- Oculto
- Cómo
- Como Hacer
- HTML
- HTTPS
- humana
- imágenes
- in
- incluir
- EN LA MINA
- Instrucciones
- IT
- nuggets
- especialistas
- líder
- APRENDE:
- aprendizaje
- aprovechando
- líneas
- para vivir
- máquina
- máquina de aprendizaje
- para lograr
- muchos
- ML
- modelo
- modelos
- MEJOR DE TU
- múltiples
- de código abierto
- para las fiestas.
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- predicción
- Predicciones
- piñón
- reducir
- exigir
- requiere
- resultado
- una estrategia SEO para aparecer en las búsquedas de Google.
- Sesión
- señales
- sencillos
- simplemente
- específicamente
- fundó
- el estado de la técnica
- paso
- estructurado
- Todas las funciones a su disposición
- ¡Prepárate!
- toma
- equipos
- tensorflow
- El
- miles
- equipo
- a
- demasiado
- Entrenar
- tutoriales
- próximos
- casos de uso
- Valioso
- Semanas
- seguirá
- dentro de
- escribir
- XGBoost
- tú
- zephyrnet





