
A medida que la IA migra de la nube al Edge, vemos que la tecnología se utiliza en una variedad cada vez mayor de casos de uso, que van desde la detección de anomalías hasta aplicaciones que incluyen compras inteligentes, vigilancia, robótica y automatización de fábricas. Por lo tanto, no existe una solución única para todos. Pero con el rápido crecimiento de los dispositivos con cámara, la IA se ha adoptado más ampliamente para analizar datos de video en tiempo real para automatizar el monitoreo de video para mejorar la seguridad, mejorar la eficiencia operativa y brindar mejores experiencias a los clientes, obteniendo en última instancia una ventaja competitiva en sus industrias. . Para respaldar mejor el análisis de video, debe comprender las estrategias para optimizar el rendimiento del sistema en implementaciones de IA perimetral.
- Seleccionar los motores informáticos del tamaño adecuado para cumplir o superar los niveles de rendimiento requeridos. Para una aplicación de IA, estos motores informáticos deben realizar las funciones de todo el proceso de visión (es decir, preprocesamiento y posprocesamiento de vídeo, inferencia de redes neuronales).
Es posible que se requiera un acelerador de IA dedicado, ya sea discreto o integrado en un SoC (en lugar de ejecutar la inferencia de IA en una CPU o GPU).
- Comprender la diferencia entre rendimiento y latencia; donde el rendimiento es la velocidad a la que se pueden procesar los datos en un sistema y la latencia mide el retraso en el procesamiento de datos a través del sistema y, a menudo, se asocia con la capacidad de respuesta en tiempo real. Por ejemplo, un sistema puede generar datos de imágenes a 100 fotogramas por segundo (rendimiento), pero una imagen tarda 100 ms (latencia) en pasar por el sistema.
- Considerar la capacidad de escalar fácilmente el rendimiento de la IA en el futuro para adaptarse a las necesidades crecientes, los requisitos cambiantes y las tecnologías en evolución (por ejemplo, modelos de IA más avanzados para una mayor funcionalidad y precisión). Puede lograr el escalamiento del rendimiento utilizando aceleradores de IA en formato de módulo o con chips aceleradores de IA adicionales.
Los requisitos de rendimiento reales dependen de la aplicación. Normalmente, se puede esperar que, para el análisis de vídeo, el sistema deba procesar flujos de datos procedentes de las cámaras a entre 30 y 60 fotogramas por segundo y con una resolución de 1080p o 4k. Una cámara habilitada para IA procesaría una única transmisión; un dispositivo perimetral procesaría múltiples flujos en paralelo. En cualquier caso, el sistema de IA perimetral debe admitir las funciones de preprocesamiento para transformar los datos del sensor de la cámara en un formato que coincida con los requisitos de entrada de la sección de inferencia de IA (Figura 1).
Las funciones de preprocesamiento toman los datos sin procesar y realizan tareas como cambio de tamaño, normalización y conversión del espacio de color, antes de introducir la entrada en el modelo que se ejecuta en el acelerador de IA. El preprocesamiento puede utilizar bibliotecas de procesamiento de imágenes eficientes como OpenCV para reducir los tiempos de preprocesamiento. El posprocesamiento implica analizar el resultado de la inferencia. Utiliza tareas como la supresión no máxima (NMS interpreta el resultado de la mayoría de los modelos de detección de objetos) y la visualización de imágenes para generar información procesable, como cuadros delimitadores, etiquetas de clase o puntuaciones de confianza.

Figura 1. Para la inferencia de modelos de IA, las funciones de procesamiento previo y posterior generalmente se realizan en un procesador de aplicaciones.
La inferencia del modelo de IA puede tener el desafío adicional de procesar múltiples modelos de redes neuronales por cuadro, según las capacidades de la aplicación. Las aplicaciones de visión por computadora generalmente implican múltiples tareas de IA que requieren una canalización de múltiples modelos. Además, el resultado de un modelo suele ser el insumo del siguiente modelo. En otras palabras, los modelos de una aplicación a menudo dependen unos de otros y deben ejecutarse de forma secuencial. El conjunto exacto de modelos a ejecutar puede no ser estático y podría variar dinámicamente, incluso cuadro por cuadro.
El desafío de ejecutar múltiples modelos dinámicamente requiere un acelerador de IA externo con memoria dedicada y suficientemente grande para almacenar los modelos. A menudo, el acelerador de IA integrado dentro de un SoC no puede gestionar la carga de trabajo de múltiples modelos debido a las limitaciones impuestas por el subsistema de memoria compartida y otros recursos en el SoC.
Por ejemplo, el seguimiento de objetos basado en predicción de movimiento se basa en detecciones continuas para determinar un vector que se utiliza para identificar el objeto rastreado en una posición futura. La eficacia de este enfoque es limitada porque carece de una verdadera capacidad de reidentificación. Con la predicción de movimiento, el seguimiento de un objeto se puede perder debido a detecciones fallidas, oclusiones o que el objeto abandone el campo de visión, incluso momentáneamente. Una vez perdido, no hay forma de volver a asociar la pista del objeto. Agregar reidentificación resuelve esta limitación pero requiere incrustar una apariencia visual (es decir, una huella digital de la imagen). Las incrustaciones de apariencia requieren una segunda red para generar un vector de características procesando la imagen contenida dentro del cuadro delimitador del objeto detectado por la primera red. Esta incrustación se puede utilizar para reidentificar el objeto nuevamente, independientemente del tiempo o el espacio. Dado que se deben generar incrustaciones para cada objeto detectado en el campo de visión, los requisitos de procesamiento aumentan a medida que la escena se vuelve más ocupada. El seguimiento de objetos con reidentificación requiere una cuidadosa consideración entre realizar una detección de alta precisión/alta resolución/alta velocidad de fotogramas y reservar suficiente sobrecarga para la escalabilidad de las incrustaciones. Una forma de resolver el requisito de procesamiento es utilizar un acelerador de IA dedicado. Como se mencionó anteriormente, el motor de inteligencia artificial del SoC puede verse afectado por la falta de recursos de memoria compartida. La optimización del modelo también se puede utilizar para reducir los requisitos de procesamiento, pero podría afectar el rendimiento y/o la precisión.
En una cámara inteligente o un dispositivo perimetral, el SoC integrado (es decir, el procesador host) adquiere los fotogramas de vídeo y realiza los pasos de preprocesamiento que describimos anteriormente. Estas funciones se pueden realizar con los núcleos de CPU o GPU del SoC (si hay uno disponible), pero también se pueden realizar mediante aceleradores de hardware dedicados en el SoC (por ejemplo, procesador de señal de imagen). Una vez completados estos pasos de preprocesamiento, el acelerador de IA integrado en el SoC puede acceder directamente a esta entrada cuantificada desde la memoria del sistema o, en el caso de un acelerador de IA discreto, la entrada se entrega para inferencia, generalmente a través del Interfaz USB o PCIe.
Un SoC integrado puede contener una variedad de unidades de computación, incluidas CPU, GPU, acelerador de IA, procesadores de visión, codificadores/decodificadores de video, procesador de señal de imagen (ISP) y más. Todas estas unidades de cálculo comparten el mismo bus de memoria y, en consecuencia, acceden a la misma memoria. Además, es posible que la CPU y la GPU también deban desempeñar un papel en la inferencia y estas unidades estarán ocupadas ejecutando otras tareas en un sistema implementado. Esto es lo que queremos decir con gastos generales a nivel del sistema (Figura 2).
Muchos desarrolladores evalúan erróneamente el rendimiento del acelerador de IA integrado en el SoC sin considerar el efecto de la sobrecarga a nivel del sistema en el rendimiento total. Como ejemplo, considere ejecutar un punto de referencia YOLO en un acelerador de IA 50 TOPS integrado en un SoC, que podría obtener un resultado de punto de referencia de 100 inferencias/segundo (IPS). Pero en un sistema implementado con todas sus otras unidades computacionales activas, esos 50 TOPS podrían reducirse a algo así como 12 TOPS y el rendimiento general solo produciría 25 IPS, suponiendo un generoso factor de utilización del 25%. La sobrecarga del sistema siempre es un factor si la plataforma procesa continuamente transmisiones de video. Alternativamente, con un acelerador de IA discreto (por ejemplo, Kinara Ara-1, Hailo-8, Intel Myriad X), la utilización a nivel del sistema podría ser superior al 90 % porque una vez que el SoC del host inicia la función de inferencia y transfiere la entrada del modelo de IA. datos, el acelerador se ejecuta de forma autónoma utilizando su memoria dedicada para acceder a los pesos y parámetros del modelo.
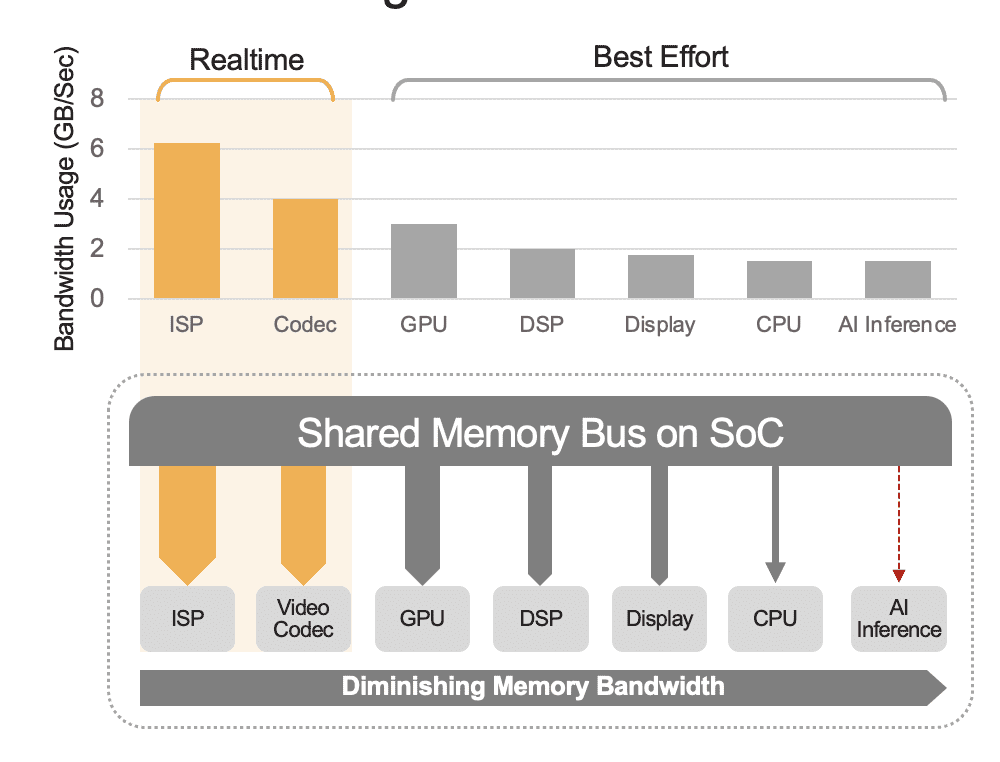
Figura 2. El bus de memoria compartida gobernará el rendimiento a nivel del sistema, que se muestra aquí con valores estimados. Los valores reales variarán según el modelo de uso de su aplicación y la configuración de la unidad de procesamiento del SoC.
Hasta este punto, hemos analizado el rendimiento de la IA en términos de fotogramas por segundo y TOPS. Pero la baja latencia es otro requisito importante para ofrecer capacidad de respuesta en tiempo real de un sistema. Por ejemplo, en los juegos, la baja latencia es fundamental para una experiencia de juego fluida y con capacidad de respuesta, particularmente en juegos controlados por movimiento y sistemas de realidad virtual (VR). En los sistemas de conducción autónoma, la baja latencia es vital para la detección de objetos en tiempo real, el reconocimiento de peatones, la detección de carriles y el reconocimiento de señales de tráfico para evitar comprometer la seguridad. Los sistemas de conducción autónoma suelen requerir una latencia de extremo a extremo de menos de 150 ms desde la detección hasta la acción real. De manera similar, en la fabricación, la baja latencia es esencial para la detección de defectos en tiempo real, el reconocimiento de anomalías y la guía robótica dependen del análisis de vídeo de baja latencia para garantizar un funcionamiento eficiente y minimizar el tiempo de inactividad de la producción.
En general, existen tres componentes de latencia en una aplicación de análisis de vídeo (Figura 3):
- La latencia de captura de datos es el tiempo desde que el sensor de la cámara captura un fotograma de vídeo hasta la disponibilidad del fotograma para el sistema de análisis para su procesamiento. Puede optimizar esta latencia eligiendo una cámara con un sensor rápido y un procesador de baja latencia, seleccionando velocidades de cuadro óptimas y utilizando formatos de compresión de video eficientes.
- La latencia de transferencia de datos es el tiempo que tardan los datos de vídeo capturados y comprimidos en viajar desde la cámara hasta los dispositivos periféricos o los servidores locales. Esto incluye retrasos en el procesamiento de la red que ocurren en cada punto final.
- La latencia del procesamiento de datos se refiere al tiempo que tardan los dispositivos perimetrales en realizar tareas de procesamiento de video, como descompresión de cuadros y algoritmos de análisis (por ejemplo, seguimiento de objetos basado en predicción de movimiento, reconocimiento facial). Como se señaló anteriormente, la latencia de procesamiento es aún más importante para las aplicaciones que deben ejecutar múltiples modelos de IA para cada cuadro de video.
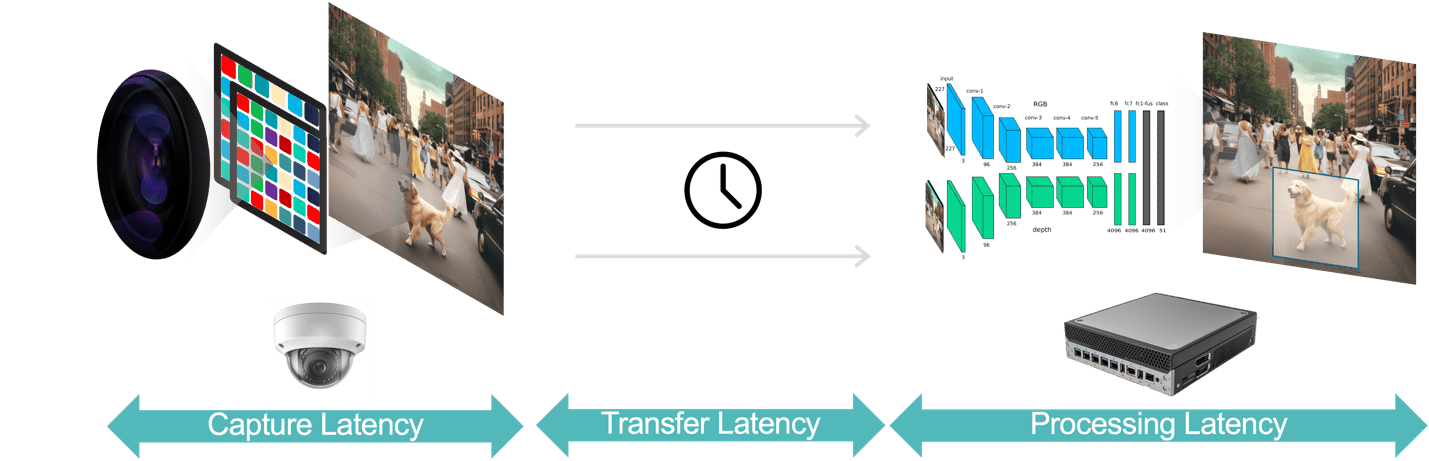
Figura 3. El proceso de análisis de vídeo consta de captura de datos, transferencia de datos y procesamiento de datos.
La latencia del procesamiento de datos se puede optimizar utilizando un acelerador de IA con una arquitectura diseñada para minimizar el movimiento de datos a través del chip y entre la computación y varios niveles de la jerarquía de memoria. Además, para mejorar la latencia y la eficiencia a nivel del sistema, la arquitectura debe admitir un tiempo de conmutación cero (o casi cero) entre modelos, para admitir mejor las aplicaciones multimodelo que analizamos anteriormente. Otro factor para mejorar el rendimiento y la latencia se relaciona con la flexibilidad algorítmica. En otras palabras, algunas arquitecturas están diseñadas para un comportamiento óptimo solo en modelos de IA específicos, pero con el entorno de IA que cambia rápidamente, aparecen nuevos modelos para un mayor rendimiento y una mayor precisión en lo que parece ser cada dos días. Por lo tanto, seleccione un procesador de IA de vanguardia sin restricciones prácticas en cuanto a topología, operadores y tamaño del modelo.
Hay muchos factores que se deben considerar para maximizar el rendimiento en un dispositivo de IA perimetral, incluidos los requisitos de rendimiento y latencia y la sobrecarga del sistema. Una estrategia exitosa debería considerar un acelerador de IA externo para superar las limitaciones de memoria y rendimiento en el motor de IA del SoC.
CH Chee Chee, un destacado ejecutivo de gestión y marketing de productos, tiene amplia experiencia en la promoción de productos y soluciones en la industria de semiconductores, centrándose en IA basada en visión, conectividad e interfaces de vídeo para múltiples mercados, incluidos el empresarial y el de consumo. Como empresario, Chee cofundó dos nuevas empresas de semiconductores de vídeo que fueron adquiridas por una empresa pública de semiconductores. Chee dirigió equipos de marketing de productos y le gusta trabajar con un equipo pequeño que se centra en lograr excelentes resultados.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- :posee
- :es
- :no
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- capacidad
- acelerador
- aceleradores
- de la máquina
- el acceso
- acomodar
- lograr
- la exactitud
- el logro de
- adquirido
- Adquiere
- a través de
- la columna Acción
- lector activo
- real
- la adición de
- Adicionales
- adoptado
- avanzado
- Después
- de nuevo
- AI
- Motor de IA
- Modelos AI
- algorítmico
- algoritmos
- Todos
- también
- hacerlo
- an
- análisis
- Analytics
- el análisis de
- y
- Detección de anomalías
- Otra
- Aplicación
- aplicaciones
- enfoque
- arquitectura
- somos
- AS
- asociado
- At
- automatizado
- Automatización
- autónomo
- autónomamente
- disponibilidad
- Hoy Disponibles
- evitar
- basado
- base
- BE
- porque
- se convierte en
- esto
- antes
- "Ser"
- mejores
- entre
- ambas
- Box
- cajas
- incorporado
- autobús
- ocupado
- pero
- by
- cámara
- cámaras
- PUEDEN
- capacidades
- capacidad
- capturar
- capturado
- Capturando
- cuidadoso
- case
- cases
- Reto
- cambio
- chip
- Papas fritas
- la elección de
- clase
- Soluciones
- Color
- viniendo
- compañía
- competitivos
- Completado
- componentes
- comprometer
- cálculo
- computational
- Calcular
- computadora
- Visión por computador
- Aplicaciones de visión artificial
- confianza
- Configuración
- Conectividad
- En consecuencia
- Considerar
- consideración
- considerado
- en vista de
- consiste
- restricciones
- consumidor
- que no contengo
- contenida
- continuo
- continuamente
- Conversión
- podría
- CPU
- crítico
- cliente
- datos
- proceso de datos
- día
- a dedicados
- retrasar
- retrasos
- entregamos
- liberado
- dependiente
- Dependiente
- desplegado
- Despliegues
- descrito
- diseñado
- detectado
- Detección
- Determinar
- desarrolladores
- Dispositivos
- un cambio
- directamente
- discutido
- Pantalla
- el tiempo de inactividad
- conducción
- dos
- dinamicamente
- e
- cada una
- Más temprano
- pasan fácilmente
- Southern Implants
- efecto
- eficacia
- eficiencias
- eficiencia
- eficiente
- ya sea
- incrustación
- final
- de extremo a extremo
- Motor
- motores
- mejorar
- garantizar
- Empresa
- Todo
- Emprendedor
- Entorno
- esencial
- estimado
- evaluar
- Incluso
- Cada
- evolución
- ejemplo
- exceden
- ejecutar
- ejecutado
- ejecutivos
- esperar
- experience
- Experiencias
- en los detalles
- Amplia experiencia
- externo
- Cara
- Reconocimiento facial
- factor
- factores importantes
- personal
- RÁPIDO
- Feature
- alimentación
- campo
- Figura
- huella dactilar
- Nombre
- Flexibilidad
- se centra
- enfoque
- formato
- FRAME
- Desde
- función
- a la fatiga
- funciones
- Además
- futuras
- ganando
- Juegos
- juego de azar
- experiencia de juego
- General
- generar
- generado
- generoso
- Go
- GPU
- GPU
- maravillosa
- mayor
- Creciendo
- Crecimiento
- guía
- Materiales
- Tienen
- por lo tanto
- esta página
- jerarquía
- Alta
- más alto
- fortaleza
- HTTPS
- i
- Identifique
- if
- imagen
- Impacto
- importante
- Impuesta
- mejorar
- mejorado
- in
- En otra
- incluye
- Incluye
- aumente
- aumentado
- industrias
- energético
- Iniciados
- Las opciones de entrada
- dentro
- Insights
- COMPLETAMENTE
- Intel
- Interfaz
- las interfaces
- dentro
- involucrar
- implica
- desconsiderado
- proveedor de servicios Internet
- IT
- SUS
- nuggets
- Etiquetas
- Falta
- Lane
- large
- Estado latente
- dejarlo
- LED
- menos
- bibliotecas
- como
- la limitación
- limitaciones
- Limitada
- Etiqueta LinkedIn
- local
- perdido
- Baja
- inferior
- gestionan
- Management
- Fabricación
- muchos
- Marketing
- Industrias
- Maximizar
- maximizando
- Puede..
- personalizado
- medidas
- Conoce a
- Salud Cerebral
- mencionado
- podría
- perdida
- modelo
- modelos
- módulo
- monitoreo
- más,
- MEJOR DE TU
- movimiento
- movimiento
- múltiples
- debe
- miríada
- Cerca
- del sistema,
- Neural
- red neural
- Nuevo
- Next
- no
- objeto
- Detección de objetos
- ocurrir
- of
- a menudo
- on
- una vez
- ONE
- , solamente
- OpenCV
- Inteligente
- operativos.
- operadores
- opuesto
- óptimo
- optimización
- Optimización
- optimizado
- optimizando
- or
- Otro
- salir
- salida
- Más de
- total
- Superar
- Paralelo
- parámetros
- particularmente
- para
- realizar
- actuación
- realizado
- realizar
- realiza
- industrial
- plataforma
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- Jugar
- punto
- posición
- Postprocesamiento
- Metodología
- predicción
- procesado
- tratamiento
- Procesador
- procesadores
- Producto
- Producción
- Productos
- Promoción
- proporcionar
- público
- distancia
- que van
- rápido
- rápidamente
- Rate
- Tarifas
- Crudo
- datos en bruto
- real
- en tiempo real
- Realidad
- reconocimiento
- reducir
- se refiere
- exigir
- Requisitos
- requisito
- Requisitos
- requiere
- Resolución
- Recursos
- sensible
- restricciones
- resultado
- Resultados
- robótica
- Función
- Ejecutar
- correr
- corre
- Safety
- mismo
- Escalabilidad
- Escala
- escala ia
- la ampliación
- escena
- puntuaciones
- sin costura
- Segundo
- Sección
- ver
- parece
- seleccionar
- semiconductor
- set
- Compartir
- compartido
- Compras
- tienes
- mostrado
- firmar
- Signal
- Del mismo modo
- desde
- soltero
- Tamaño
- chica
- inteligente
- a medida
- Soluciones
- RESOLVER
- Resuelve
- algo
- algo
- Espacio
- soluciones y
- la creación de empresas
- pasos
- tienda
- estrategias
- Estrategia
- stream
- corrientes
- exitosos
- tal
- suficiente
- SOPORTE
- supresión
- vigilancia
- te
- Todas las funciones a su disposición
- ¡Prepárate!
- toma
- tareas
- equipo
- equipos
- Tecnologías
- Tecnología
- términos
- que
- esa
- La
- El futuro de las
- su
- luego
- Ahí.
- por lo tanto
- Estas
- ellos
- así
- aquellos
- Tres
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- rendimiento
- equipo
- veces
- a
- Tops
- Total
- seguir
- Seguimiento
- tráfico
- transferir
- transferencias
- Transformar
- viajes
- verdadero
- dos
- típicamente
- Finalmente, a veces
- incapaz
- entender
- unidad
- unidades que
- Uso
- usb
- utilizan el
- usado
- usos
- usando
- generalmente
- Utilizando
- Valores
- variedad
- diversos
- Video
- Ver
- Virtual
- Realidad virtual
- visión
- vital
- vr
- Camino..
- we
- tuvieron
- ¿
- sean
- que
- extensamente
- seguirá
- sin
- palabras
- trabajando
- se
- X
- Rendimiento
- Yolo
- Usted
- tú
- zephyrnet
- cero







