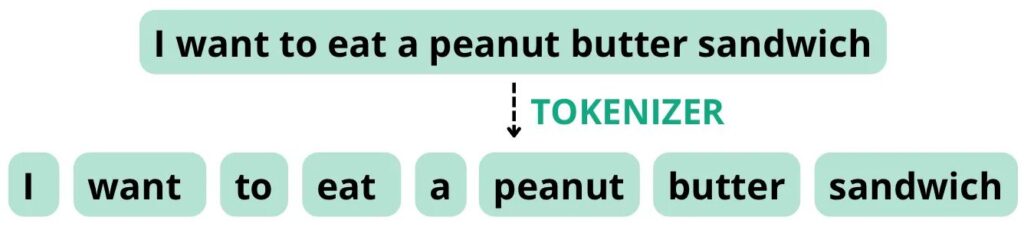
Agentes de resumen imaginados por la herramienta de generación de imágenes de IA Dall-E.
¿Eres parte de la población que deja comentarios en los mapas de Google cada vez que visita un nuevo restaurante?
¿O tal vez eres del tipo que comparte su opinión sobre las compras en Amazon, especialmente cuando te provoca un producto de baja calidad?
No te preocupes, no te culparé, ¡todos tenemos nuestros momentos!
En el mundo de los datos de hoy, todos contribuimos al diluvio de datos de múltiples maneras. Un tipo de datos que encuentro particularmente interesante por su diversidad y dificultad de interpretación son los datos textuales, como las innumerables reseñas que se publican en Internet todos los días. ¿Alguna vez se ha detenido a considerar la importancia de estandarizar y condensar los datos textuales? ¡Bienvenido al mundo de los agentes de resumen!
Los agentes de resúmenes se han integrado a la perfección en nuestra vida diaria condensando información y brindando acceso rápido a contenido relevante en una multitud de aplicaciones y plataformas.
En este artículo, exploraremos la utilización de ChatGPT como un poderoso agente de resumen para nuestras aplicaciones personalizadas. Gracias a la capacidad de Large Language Models (LLM) para procesar y comprender textos, pueden ayudar a leer textos y generar resúmenes precisos o estandarizar información. Sin embargo, es importante saber cómo extraer su potencial al realizar tal tarea, así como reconocer sus limitaciones.
¿La mayor limitación para el resumen? Los LLM a menudo se quedan cortos cuando se trata de adherirse a limitaciones específicas de caracteres o palabras en sus resúmenes.
Exploremos las mejores prácticas para generar resúmenes con ChatGPT para nuestra aplicación personalizada, así como las razones detrás de sus limitaciones y cómo superarlas.
Los agentes de resumen se utilizan en todo Internet. Por ejemplo, los sitios web utilizan agentes de resumen para ofrecer resúmenes concisos de artículos, lo que permite a los usuarios obtener una visión general rápida de las noticias sin sumergirse en todo el contenido. Las plataformas de redes sociales y los motores de búsqueda también hacen esto.
Desde agregadores de noticias y plataformas de redes sociales hasta sitios web de comercio electrónico, los agentes de resumen se han convertido en una parte integral de nuestro panorama digital.. Y con el aumento de los LLM, algunos de estos agentes ahora usan IA para obtener resultados de resumen más efectivos.
ChatGPT puede ser un buen aliado a la hora de construir una aplicación utilizando agentes resúmenes para agilizar tareas de lectura y clasificación de textos. Por ejemplo, imagina que tenemos un negocio de comercio electrónico y estamos interesados en procesar todas las opiniones de nuestros clientes. ChatGPT podría ayudarnos a resumir cualquier reseña dada en unas pocas oraciones, estandarizándola en un formato genérico, determinando el sentimiento de la reseña, y clasificar en consecuencia.
Si bien es cierto que simplemente podríamos enviar la revisión a ChatGPT, hay una lista de mejores prácticas - y cosas a evitar - para aprovechar el poder de ChatGPT en esta tarea concreta.
¡Exploremos las opciones dando vida a este ejemplo!
Ejemplo: Reseñas de comercio electrónico
Gif hecho a sí mismo.
Considere el ejemplo anterior en el que estamos interesados en procesar todas las reseñas de un producto determinado en nuestro sitio web de comercio electrónico. Estaríamos interesados en tramitar valoraciones como la siguiente sobre nuestro producto estrella: la primera computadora para niños!
prod_review = """
I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlier
than expected, so I got to play with it myself before I gave it to him. """
En este caso, nos gustaría que ChatGPT:
Clasifica la reseña en positiva o negativa.
Proporcionar un resumen de la revisión de 20 palabras.
Genere la respuesta con una estructura concreta para estandarizar todas las revisiones en un solo formato.
Notas de implementación
Esta es la estructura de código básica que podríamos usar para activar ChatGPT desde nuestra aplicación personalizada. También proporciono un enlace a un Cuaderno Jupyter con todos los ejemplos utilizados en este artículo.
import openai
import os openai.api_key_path = "/path/to/key" def get_completion(prompt, model="gpt-3.5-turbo"): """
This function calls ChatGPT API with a given prompt
and returns the response back. """ messages = [{"role": "user", "content": prompt}] response = openai.ChatCompletion.create( model=model, messages=messages, temperature=0 ) return response.choices[0].message["content"] user_text = f"""
<Any given text> """ prompt = f"""
<Any prompt with additional text> """{user_text}""" """ # A simple call to ChatGPT
response = get_completion(prompt)
La función get_completion() llama a la API de ChatGPT con un determinado puntual. Si el mensaje contiene información adicional texto de usuario, como la propia reseña en nuestro caso, se separa del resto del código mediante comillas triples.
Usemos el get_completion() función para solicitar ChatGPT!
Aquí hay un aviso que cumple con los requisitos descritos anteriormente:
prompt = f"""
Your task is to generate a short summary of a product review from an e-commerce site. Summarize the review below, delimited by triple backticks, in exactly 20 words. Output a json with the sentiment of the review, the summary and original review as keys. Review: ```{prod_review}``` """
response = get_completion(prompt)
print(response)
{ "sentiment": "positive", "summary": "Durable and engaging children's computer with intuitive interface and educational games. Volume could be louder.", "review": "I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlierthan expected, so I got to play with it myself before I gave it to him."
}
Como podemos observar en el resultado, la revisión es precisa y bien estructurada, aunque le falta alguna información que nos podría interesar como dueños del e-commerce, como información sobre la entrega del producto.
Resumir con un enfoque en
Podemos mejorar de manera iterativa nuestro aviso pidiéndole a ChatGPT que se centre en ciertas cosas en el resumen. En este caso, estamos interesados en los detalles dados sobre el envío y la entrega:
prompt = f"""
Your task is to generate a short summary of a product review from an ecommerce site. Summarize the review below, delimited by triple backticks, in exactly 20 words and focusing on any aspects that mention shipping and delivery of the product. Output a json with the sentiment of the review, the summary and original review as keys. Review: ```{prod_review}``` """ response = get_completion(prompt)
print(response)
Esta vez, la respuesta de ChatGPT es la siguiente:
{ "sentiment": "positive", "summary": "Durable and engaging children's computer with intuitive interface. Arrived a day earlier than expected.", "review": "I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlierthan expected, so I got to play with it myself before I gave it to him."
}
Ahora la revisión es mucho más completa. Brindar detalles sobre el enfoque importante de la revisión original es crucial para evitar que ChatGPT omita alguna información que podría ser valiosa para nuestro caso de uso..
¿Has notado que aunque este segundo ensayo incluye información sobre la entrega, se saltó el único aspecto negativo de la revisión original?
¡Arreglemos eso!
"Extraer" en lugar de "Resumir"
Al investigar las tareas de resumen, descubrí que el resumen puede ser una tarea complicada para los LLM si el aviso del usuario no es lo suficientemente preciso.
Al pedirle a ChatGPT que proporcione un resumen de un texto determinado, puede omitir información que podría ser relevante para nosotros. — como hemos experimentado recientemente — o le dará la misma importancia a todos los temas del texto, proporcionando sólo una visión general de los puntos principales.
Los expertos en LLM utilizan el término extraerlos e información adicional sobre sus enfoques en lugar de resumir al realizar tales tareas asistidos por este tipo de modelos.
Mientras que el resumen tiene como objetivo proporcionar una descripción general concisa de los puntos principales del texto, incluidos temas no relacionados con el tema de enfoque, la extracción de información se enfoca en recuperar detalles específicos. y puede darnos exactamente lo que estamos buscando. ¡Probemos entonces con la extracción!
prompt = f"""
Your task is to extract relevant information from a product review from an ecommerce site to give feedback to the Shipping department. From the review below, delimited by triple quotes extract the information relevant to shipping and delivery. Use 100 characters. Review: ```{prod_review}``` """ response = get_completion(prompt)
print(response)
En este caso, al usar la extracción, solo obtenemos información sobre nuestro tema de enfoque: Shipping: Arrived a day earlier than expected.
Automatización
Este sistema funciona para una sola revisión. Sin embargo, al diseñar un aviso para una aplicación concreta, es importante probarlo en un lote de ejemplos para que podamos detectar cualquier valor atípico o mal comportamiento en el modelo.
En caso de procesar múltiples revisiones, aquí hay una estructura de código Python de muestra que puede ayudar.
reviews = [ "The children's computer I bought for my daughter is absolutely fantastic! She loves it and can't get enough of the educational games. The delivery was fast and arrived right on time. Highly recommend!", "I was really disappointed with the children's computer I received. It didn't live up to my expectations, and the educational games were not engaging at all. The delivery was delayed, which added to my frustration.", "The children's computer is a great educational toy. My son enjoys playing with it and learning new things. However, the delivery took longer than expected, which was a bit disappointing.", "I am extremely happy with the children's computer I purchased. It's highly interactive and keeps my kids entertained for hours. The delivery was swift and hassle-free.", "The children's computer I ordered arrived damaged, and some of the features didn't work properly. It was a huge letdown, and the delivery was also delayed. Not a good experience overall."
] prompt = f""" Your task is to generate a short summary of each product review from an e-commerce site. Extract positive and negative information from each of the given reviews below, delimited by triple backticks in at most 20 words each. Extract information about the delivery, if included. Review: ```{reviews}``` """
Aquí están los resúmenes de nuestro lote de reseñas:
1. Positive: Fantastic children's computer, fast delivery. Highly recommend.
2. Negative: Disappointing children's computer, unengaging games, delayed delivery.
3. Positive: Great educational toy, son enjoys it. Delivery took longer than expected.
4. Positive: Highly interactive children's computer, swift and hassle-free delivery.
5. Negative: Damaged children's computer, some features didn't work, delayed delivery.
⚠️ Tenga en cuenta que aunque la restricción de palabras de nuestros resúmenes fue lo suficientemente clara en nuestras indicaciones, podemos ver fácilmente que esta limitación de palabras no se logra en ninguna de las iteraciones.
Este desajuste en el conteo de palabras ocurre porque los LLM no tienen una comprensión precisa del conteo de palabras o caracteres. La razón detrás de esto se basa en uno de los principales componentes importantes de su arquitectura: el tokenizador.
Tokenizer
Los LLM como ChatGPT están diseñados para generar texto basado en patrones estadísticos aprendidos de grandes cantidades de datos de idiomas. Si bien son muy eficaces para generar textos fluidos y coherentes, carecen de un control preciso sobre el recuento de palabras..
En los ejemplos anteriores, cuando hemos dado instrucciones sobre un conteo de palabras muy preciso, ChatGPT estaba luchando para cumplir con esos requisitos. En su lugar, ha generado un texto que en realidad es más corto que el recuento de palabras especificado.
En otros casos, puede generar textos más largos o simplemente texto demasiado verboso o carente de detalles. Además, ChatGPT puede priorizar otros factores, como la coherencia y la relevancia, sobre el cumplimiento estricto del conteo de palabras.. Esto puede dar como resultado un texto de alta calidad en términos de contenido y coherencia, pero que no cumple exactamente con el requisito de recuento de palabras.
El tokenizador es el elemento clave en la arquitectura de ChatGPT que claramente influye en la cantidad de palabras en la salida generada..
Gif hecho a sí mismo.
Arquitectura tokenizadora
El tokenizador es el primer paso en el proceso de generación de texto. Es responsable de dividir el fragmento de texto que ingresamos en ChatGPT en elementos individuales. — fichas —, que luego son procesados por el modelo de lenguaje para generar texto nuevo.
Cuando el generador de tokens divide un fragmento de texto en tokens, lo hace en función de un conjunto de reglas diseñadas para identificar las unidades significativas del idioma de destino. Sin embargo, estas reglas no siempre son perfectas, y puede haber casos en los que el tokenizador divida o combine tokens de una manera que afecte el recuento total de palabras del texto.
Por ejemplo, considere la siguiente oración: “Quiero comer un sándwich de mantequilla de maní”. Si el generador de tokens está configurado para dividir tokens en función de los espacios y la puntuación, puede dividir esta oración en los siguientes tokens con un recuento total de 8 palabras, igual al recuento de tokens.
Imagen hecha a sí misma.
Sin embargo, si el tokenizador está configurado para tratar "mantequilla de maní" como palabra compuesta, puede dividir la oración en los siguientes tokens, con un recuento total de palabras de 8, pero un recuento de fichas de 7.
Por lo tanto, la forma en que se configura el tokenizador puede afectar el recuento total de palabras del texto., y esto puede afectar la capacidad del LLM para seguir instrucciones sobre recuentos precisos de palabras. Si bien algunos tokenizadores ofrecen opciones para personalizar cómo se tokeniza el texto, esto no siempre es suficiente para garantizar el cumplimiento preciso de los requisitos de conteo de palabras. Para ChatGPT en este caso, no podemos controlar esta parte de su arquitectura.
Esto hace que ChatGPT no sea tan bueno para cumplir con las limitaciones de caracteres o palabras, pero en su lugar se puede intentar con oraciones ya que el tokenizador no afecta el número de oraciones, pero su longitud.
Ser consciente de esta restricción puede ayudarlo a crear el indicador más adecuado para su aplicación en mente. Con este conocimiento sobre cómo funciona el conteo de palabras en ChatGPT, ¡hagamos una iteración final con nuestro aviso para la aplicación de comercio electrónico!
Concluyendo: Reseñas de comercio electrónico
¡Combinemos nuestros aprendizajes de este artículo en un mensaje final! En este caso, estaremos preguntando por los resultados en HTML formato para una mejor salida:
from IPython.display import display, HTML prompt = f"""
Your task is to extract relevant information from a product review from an ecommerce site to give feedback to the Shipping department and generic feedback from the product. From the review below, delimited by triple quotes construct an HTML table with the sentiment of the review, general feedback from
the product in two sentences and information relevant to shipping and delivery. Review: ```{prod_review}``` """ response = get_completion(prompt)
display(HTML(response))
Y aquí está el resultado final de ChatGPT:
Captura de pantalla hecha a sí misma del Cuaderno Jupyter con los ejemplos utilizados en este artículo.
Resumen
En este artículo, hemos discutido las mejores prácticas para usar ChatGPT como un agente de resumen para nuestra aplicación personalizada.
Hemos visto que al crear una aplicación, es extremadamente difícil encontrar el indicador perfecto que coincida con los requisitos de su aplicación en la primera prueba. Creo que un buen mensaje para llevar a casa es para pensar en las indicaciones como un proceso iterativo donde refina y modela su mensaje hasta que obtiene exactamente el resultado deseado.
Al refinar iterativamente su mensaje y aplicarlo a un lote de ejemplos antes de implementarlo en producción, puede asegurarse de que el resultado es consistente en múltiples ejemplos y cubre respuestas atípicas. En nuestro ejemplo, podría suceder que alguien proporcione un texto aleatorio en lugar de una reseña. Podemos indicarle a ChatGPT que también tenga una salida estandarizada para excluir estas respuestas atípicas.
Además, al usar ChatGPT para una tarea específica, también es una buena práctica conocer los pros y los contras de usar LLM para nuestra tarea objetivo. Así es como nos encontramos con el hecho de que las tareas de extracción son más efectivas que el resumen cuando queremos un resumen común similar al humano de un texto de entrada. También hemos aprendido que proporcionar el enfoque del resumen puede ser una cambio de juego sobre el contenido generado.
Finalmente, si bien los LLM pueden ser muy efectivos para generar texto, no son ideales para seguir instrucciones precisas sobre el recuento de palabras u otros requisitos de formato específicos. Para lograr estos objetivos, puede ser necesario ceñirse al conteo de oraciones o utilizar otras herramientas o métodos, como la edición manual o un software más especializado.
Este artículo se publicó originalmente el Hacia la ciencia de datos y re-publicado a TOPBOTS con permiso del autor.
¿Disfrutas este artículo? Regístrese para obtener más actualizaciones de investigación de IA.
Le informaremos cuando publiquemos más artículos de resumen como este.