
Imagen de Adobe Firefly
“Éramos demasiados. Teníamos acceso a demasiado dinero, demasiado equipo y, poco a poco, nos volvimos locos”.
Francis Ford Coppola no estaba haciendo una metáfora de las empresas de inteligencia artificial que gastan demasiado y pierden el rumbo, pero podría haberlo hecho. Apocalipsis ahora Fue épico pero también un proyecto largo, difícil y costoso de realizar, muy parecido a GPT-4. Yo sugeriría que el desarrollo de los LLM ha gravitado hacia demasiado dinero y demasiado equipo. Y parte de la exageración de “acabamos de inventar la inteligencia general” es un poco descabellada. Pero ahora es el turno de las comunidades de código abierto de hacer lo que mejor saben hacer: ofrecer software competitivo gratuito utilizando mucho menos dinero y equipo.
OpenAI ha recibido más de 11 millones de dólares en financiación y se estima que GPT-3.5 cuesta entre 5 y 6 millones de dólares por ejecución de entrenamiento. Sabemos muy poco sobre GPT-4 porque OpenAI no lo dice, pero creo que es seguro asumir que no es más pequeño que GPT-3.5. Actualmente hay escasez de GPU en todo el mundo y, para variar, no se debe a la última criptomoneda. Las empresas emergentes de IA generativa están consiguiendo rondas de Serie A de más de 100 millones de dólares con valoraciones enormes cuando no poseen ninguna propiedad intelectual para el LLM que utilizan para impulsar su producto. El tren del LLM está en marcha y el dinero fluye.
Parecía que la suerte estaba echada: sólo las empresas con mucho dinero como Microsoft/OpenAI, Amazon y Google podían permitirse el lujo de entrenar cientos de miles de millones de modelos de parámetros. Se suponía que los modelos más grandes eran mejores. ¿GPT-3 se equivocó en algo? ¡Solo espera hasta que haya una versión más grande y todo estará bien! Las empresas más pequeñas que buscaban competir tuvieron que recaudar mucho más capital o quedarse construyendo integraciones de productos en el mercado ChatGPT. La academia, con presupuestos de investigación aún más limitados, quedó relegada a un segundo plano.
Afortunadamente, un grupo de personas inteligentes y proyectos de código abierto tomaron esto como un desafío en lugar de una restricción. Investigadores de Stanford lanzaron Alpaca, un modelo de 7 mil millones de parámetros cuyo rendimiento se acerca al modelo de 3.5 mil millones de parámetros de GPT-175. Al carecer de los recursos para crear un conjunto de capacitación del tamaño utilizado por OpenAI, eligieron inteligentemente tomar un LLM, LLaMA de código abierto capacitado y, en su lugar, ajustarlo en una serie de indicaciones y resultados de GPT-3.5. Básicamente, el modelo aprendió lo que hace GPT-3.5, lo que resulta ser una estrategia muy eficaz para replicar su comportamiento.
Alpaca tiene licencia para uso no comercial solo tanto en código como en datos, ya que utiliza el modelo LLaMA no comercial de código abierto, y OpenAI prohíbe explícitamente cualquier uso de sus API para crear productos de la competencia. Eso crea la tentadora perspectiva de ajustar un LLM de código abierto diferente según las indicaciones y la salida de Alpaca... creando un tercer modelo similar a GPT-3.5 con diferentes posibilidades de licencia.
Hay otra capa de ironía aquí, en el sentido de que todos los principales LLM fueron capacitados en textos e imágenes protegidos por derechos de autor disponibles en Internet y no pagaron ni un centavo a los titulares de los derechos. Las empresas reclaman la exención por “uso justo” según la ley de derechos de autor de EE. UU. con el argumento de que el uso es “transformador”. Sin embargo, cuando se trata del resultado de los modelos que construyen con datos gratuitos, realmente no quieren que nadie les haga lo mismo. Espero que esto cambie a medida que los titulares de derechos se den cuenta y pueda terminar en los tribunales en algún momento.
Este es un punto separado y distinto al planteado por los autores de código abierto con licencia restrictiva que, para productos de IA generativa para Código como CoPilot, se oponen a que su código se utilice para capacitación con el argumento de que no se está respetando la licencia. El problema para los autores individuales de código abierto es que necesitan demostrar su reputación (copia sustancial) y que han sufrido daños y perjuicios. Y dado que los modelos dificultan vincular el código de salida con la entrada (las líneas de código fuente del autor) y no hay pérdida económica (se supone que es gratuito), es mucho más difícil presentar un caso. Esto es diferente a los creadores con fines de lucro (por ejemplo, fotógrafos) cuyo modelo de negocio consiste en otorgar licencias o vender su trabajo, y que están representados por agregadores como Getty Images que pueden mostrar copias sustanciales.
Otra cosa interesante de LLaMA es que surgió de Meta. Originalmente se lanzó solo para investigadores y luego se filtró al mundo a través de BitTorrent. Meta está en un negocio fundamentalmente diferente al de OpenAI, Microsoft, Google y Amazon en el sentido de que no intenta venderle servicios o software en la nube, por lo que tiene incentivos muy diferentes. Ha abierto sus diseños informáticos en el pasado (OpenCompute) y ha visto a la comunidad mejorarlos: comprende el valor del código abierto.
Meta podría convertirse en uno de los contribuyentes más importantes a la IA de código abierto. No sólo tiene enormes recursos, sino que se beneficia si hay una proliferación de gran tecnología de IA generativa: habrá más contenido para monetizar en las redes sociales. Meta ha lanzado otros tres modelos de IA de código abierto: ImageBind (indexación de datos multidimensionales), DINOv2 (visión por computadora) y Segment Anything. Este último identifica objetos únicos en imágenes y se publica bajo la licencia Apache altamente permisiva.
Finalmente, también tuvimos la supuesta filtración de un documento interno de Google "No tenemos foso, y OpenAI tampoco", que ve con malos ojos los modelos cerrados versus la innovación de las comunidades que producen modelos mucho más pequeños y más baratos que funcionan cerca o mejor que sus homólogos de código cerrado. Digo supuestamente porque no hay forma de verificar que la fuente del artículo sea interna de Google. Sin embargo, contiene este gráfico convincente:
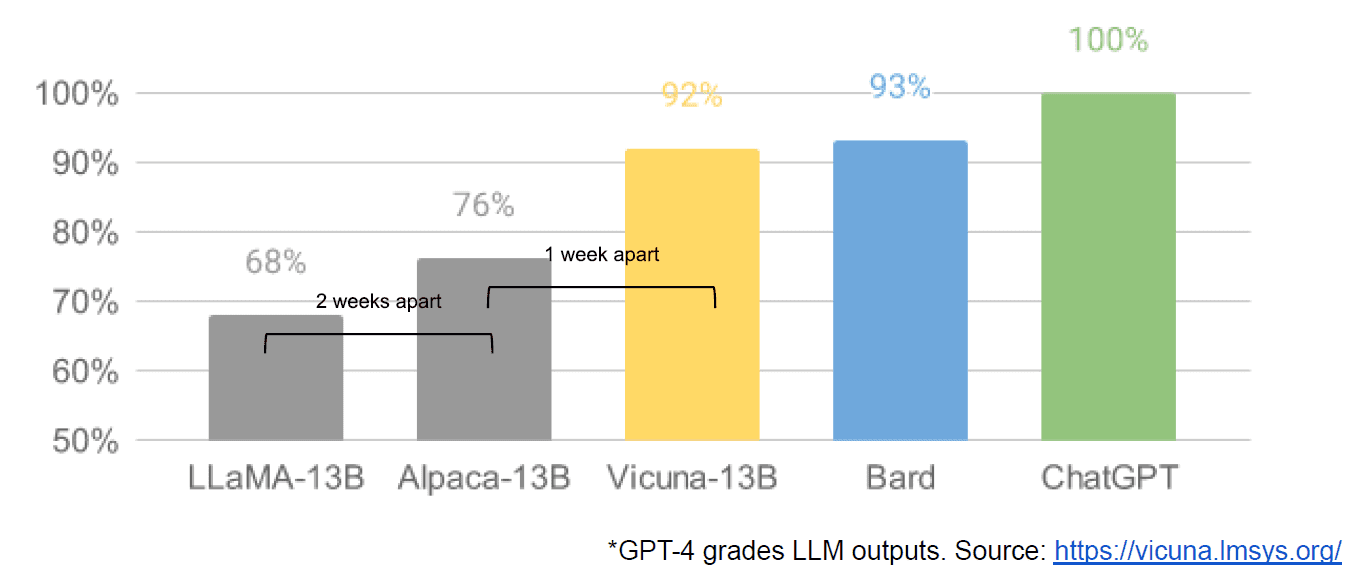
Para ser claros, el eje vertical es la calificación de los resultados del LLM por GPT-4.
Stable Diffusion, que sintetiza imágenes a partir de texto, es otro ejemplo de cómo la IA generativa de código abierto ha podido avanzar más rápido que los modelos propietarios. Una versión reciente de ese proyecto (ControlNet) lo ha mejorado de tal manera que ha superado las capacidades de Dall-E2. Esto surgió de una gran cantidad de retoques en todo el mundo, lo que dio como resultado un ritmo de avance que es difícil de igualar para cualquier institución por sí sola. Algunos de esos expertos descubrieron cómo hacer que Stable Diffusion sea más rápido de entrenar y ejecutar en hardware más barato, lo que permite ciclos de iteración más cortos para más personas.
Y así hemos cerrado el círculo. No tener demasiado dinero ni demasiado equipo ha inspirado un astuto nivel de innovación por parte de toda una comunidad de gente común y corriente. Qué momento para ser desarrollador de IA.
Mateo Lodge es director ejecutivo de Diffblue, una startup de AI For Code. Tiene más de 25 años de experiencia diversa en liderazgo de productos en empresas como Anaconda y VMware. Actualmente, Lodge forma parte de la junta directiva de Good Law Project y es vicepresidente de la junta directiva de la Royal Photographic Society.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Compra y Vende Acciones en Empresas PRE-IPO con PREIPO®. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/05/llm-apocalypse-revenge-open-source-clones.html?utm_source=rss&utm_medium=rss&utm_campaign=llm-apocalypse-now-revenge-of-the-open-source-clones
- :posee
- :es
- :no
- :dónde
- $ UP
- 9
- a
- Poder
- Sobre
- Academia
- de la máquina
- adobe
- avanzar
- Agregadores
- AI
- Todos
- presunto
- pretendidamente
- también
- Amazon
- an
- y
- Otra
- cualquier
- nadie
- cualquier cosa
- APACHE
- API
- somos
- argumento
- artículo
- AS
- ficticio
- At
- autor
- Autorzy
- Hoy Disponibles
- Eje
- BE
- porque
- esto
- "Ser"
- beneficios
- MEJOR
- mejores
- más grande
- BitTorrent
- tablero
- ambas
- Presupuestos
- build
- Construir la
- Manojo
- modelo de negocio
- pero
- by
- llegó
- PUEDEN
- capacidades
- capital
- case
- ceo
- Presidente
- Reto
- el cambio
- ChatGPT
- más barato
- eligió
- Círculo
- reclamo
- limpiar
- Cerrar
- cerrado
- Soluciones
- servicios en la nube
- código
- cómo
- proviene
- mercancía
- Comunidades
- vibrante e inclusiva
- Empresas
- irresistible
- competir
- compitiendo
- Calcular
- computadora
- Visión por computador
- contenido
- contribuyentes
- proceso de copiar
- derechos de autor,
- Precio
- podría
- CORTE
- Para crear
- Creamos
- creadores
- cryptocoin
- En la actualidad
- de ciclos
- datos
- entregar
- diputado
- diseños
- Developer
- Desarrollo
- El
- una experiencia diferente
- difícil
- Difusión
- distinto
- diverso
- do
- documento
- sí
- No
- e
- Economic
- Eficaz
- permitiendo
- final
- Todo
- EPIC
- equipo
- esencialmente
- estimado
- Incluso
- ejemplo
- esperar
- costoso
- experience
- muchos
- más rápida
- calculado
- Fluido
- seguido
- Ford
- Gratuito
- en
- ser completados
- fundamentalmente
- universidad
- Equipo
- General
- generativo
- IA generativa
- candidato
- GPU
- gráfica
- maravillosa
- tenido
- Difícil
- Materiales
- Tienen
- es
- he
- esta página
- Alta
- altamente
- titulares
- Cómo
- Como Hacer
- Sin embargo
- HTTPS
- enorme
- Bombo
- i
- identifica
- if
- imágenes
- importante
- mejorar
- mejorado
- in
- Incentivos
- INSTRUMENTO individual
- Innovation
- Las opciones de entrada
- INSANO
- inspirado
- Institución
- integraciones
- interesante
- interno
- Internet
- inventado
- IP
- ironía
- IT
- iteración
- SUS
- solo
- nuggets
- Saber
- aterrizaje
- más reciente
- de derecho criminal
- .
- Liderazgo
- aprendido
- izquierda
- menos
- Nivel
- Licencia
- Con licencia
- Licencias
- como
- líneas
- LINK
- Etiqueta LinkedIn
- pequeño
- Llama
- Largo
- miró
- mirando
- perder
- de
- Lote
- gran
- para lograr
- Realizar
- muchos
- mercado
- masivo
- Match
- Puede..
- Medios
- Meta
- Microsoft
- modelo
- modelos
- monetizar
- dinero
- más,
- MEJOR DE TU
- mucho más
- ¿ Necesita ayuda
- Neither
- no
- no comercial
- ahora
- objeto
- objetos
- of
- on
- ONE
- , solamente
- habiertos
- de código abierto
- proyectos de código abierto
- OpenAI
- or
- ordinario
- originalmente
- Otro
- salir
- salida
- Más de
- EL DESARROLLADOR
- Paz
- parámetro
- pasado
- Pagar
- Personas
- realizar
- actuación
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- punto
- POSIBILIDADES
- industria
- Problema
- Producto
- Productos
- proyecto
- proyecta
- propietario
- perspectiva
- aumento
- elevado
- más bien
- realmente
- reciente
- liberado
- representado
- la investigación
- investigadores
- Recursos
- restricción
- resultante
- derechos
- rondas
- real
- Ejecutar
- s
- ambiente seguro
- mismo
- dices
- visto
- segmento
- venta
- separado
- Serie
- Serie A
- sirve
- Servicios
- set
- escasez
- Mostrar
- desde
- soltero
- Tamaño
- menores
- inteligente
- So
- Social
- redes sociales
- Sociedades
- Software
- algo
- algo
- Fuente
- código fuente
- pasar
- estable
- stanford
- la creación de empresas
- inicio
- Estrategia
- tal
- sugieren
- Supuesto
- superado
- ¡Prepárate!
- toma
- toma
- Tecnología
- que
- esa
- El
- La Fuente
- el mundo
- su
- Les
- luego
- Ahí.
- ellos
- cosa
- pensar
- Código
- así
- aquellos
- Tres
- equipo
- a
- demasiado
- se
- Entrenar
- entrenado
- Formación
- GIRO
- se convierte
- bajo
- entiende
- único
- diferente a
- hasta
- us
- utilizan el
- usado
- usos
- usando
- Valoraciones
- propuesta de
- verificar
- versión
- vertical
- muy
- vía
- Ver
- visión
- vmware
- vs
- esperar
- quieres
- fue
- Camino..
- we
- fuimos
- tuvieron
- ¿
- cuando
- que
- QUIENES
- todo
- cuyo
- seguirá
- FUNDACION
- Actividades:
- mundo
- Mal
- Usted
- zephyrnet









