apache hudi es un formato de tabla abierta que aporta capacidades de base de datos y almacén de datos a los lagos de datos. Apache Hudi ayuda a los ingenieros de datos a gestionar desafíos complejos, como la gestión de conjuntos de datos en continua evolución con transacciones mientras se mantiene el rendimiento de las consultas. Los ingenieros de datos utilizan Apache Hudi para transmitir cargas de trabajo, así como para crear canales de datos incrementales eficientes. Hudi proporciona tablas, transacciones, Insertaciones y eliminaciones eficientes., índices avanzados, servicios de ingestión de streaming, los datos clustering y compactación optimizaciones y control de concurrencia, todo ello manteniendo sus datos en formatos de archivo de código abierto. Las optimizaciones avanzadas de rendimiento de Hudi agilizan las cargas de trabajo analíticas con cualquiera de los motores de consulta populares, incluidos Apache Spark, Presto, Trino, Hive, etc.
Muchos clientes de AWS adoptaron Apache Hudi en sus lagos de datos creados sobre Amazon S3 utilizando Pegamento AWS, un servicio de integración de datos sin servidor que facilita descubrir, preparar, mover e integrar datos de múltiples fuentes para análisis, aprendizaje automático (ML) y desarrollo de aplicaciones. Rastreador de pegamento de AWS es un componente de AWS Glue, que le permite crear metadatos de tablas a partir del contenido de datos automáticamente sin necesidad de una definición manual de los metadatos.
Los rastreadores de AWS Glue ahora admiten tablas de Apache Hudi, simplificando la adopción de Catálogo de datos de AWS Glue como el catálogo de mesas Hudi. Un caso de uso típico es registrar tablas Hudi, que no tienen una definición de tabla de catálogo. Otro caso de uso típico es la migración desde otros catálogos de Hudi, como Hive Metastore. Al migrar desde otros catálogos de Hudi, puede crear y programar un rastreador de AWS Glue y proporcionar una o más rutas de Amazon S3 donde se encuentran los archivos de la tabla de Hudi. Tiene la opción de proporcionar la profundidad máxima de rutas de Amazon S3 que el rastreador de AWS Glue puede atravesar. Con cada ejecución, los rastreadores de AWS Glue extraerán información de esquema y partición y actualizarán el catálogo de datos de AWS Glue con los cambios de esquema y partición. Los rastreadores de AWS Glue actualizan la ubicación del archivo de metadatos más reciente en el catálogo de datos de AWS Glue que los motores analíticos de AWS pueden usar directamente.
Con este lanzamiento, puede crear y programar un rastreador de AWS Glue para registrar tablas de Hudi en el catálogo de datos de AWS Glue. Luego puede proporcionar una o varias rutas de Amazon S3 donde se encuentran las tablas de Hudi. Tiene la opción de proporcionar la profundidad máxima de rutas de Amazon S3 que los rastreadores pueden atravesar. Con cada ejecución del rastreador, el rastreador inspecciona cada una de las rutas de S3 y cataloga la información del esquema, como nuevas tablas, eliminaciones y actualizaciones de esquemas en el catálogo de datos de AWS Glue. Los rastreadores inspeccionan la información de las particiones y agregan particiones recién agregadas al catálogo de datos de AWS Glue. Los rastreadores también actualizan la ubicación del archivo de metadatos más reciente en el catálogo de datos de AWS Glue que los motores analíticos de AWS pueden usar directamente.
Esta publicación demuestra cómo funciona esta nueva capacidad para rastrear tablas de Hudi.
Cómo funciona el rastreador de AWS Glue con tablas de Hudi
Las tablas Hudi tienen dos categorías, con implicaciones específicas para cada una:
- Copiar al escribir (CoW) – Los datos se almacenan en formato de columnas (Parquet) y cada actualización crea una nueva versión de los archivos durante una escritura.
- Fusionar al leer (MoR) – Los datos se almacenan utilizando una combinación de formatos de columnas (Parquet) y de filas (Avro). Las actualizaciones se registran en base a filas
deltaarchivos y se compactan según sea necesario para crear nuevas versiones de los archivos en columnas.
Con los conjuntos de datos de CoW, cada vez que hay una actualización de un registro, el archivo que contiene el registro se reescribe con los valores actualizados. Con un conjunto de datos MoR, cada vez que hay una actualización, Hudi escribe solo la fila del registro modificado. MoR es más adecuado para cargas de trabajo con muchos cambios o escritura y menos lecturas. CoW es más adecuado para cargas de trabajo de lectura intensa sobre datos que cambian con menos frecuencia.
Hudi proporciona tres tipos de consultas para acceder a los datos:
- Consultas de instantáneas – Consultas que ven la última instantánea de la tabla a partir de una determinada acción de confirmación o compactación. Para las tablas MoR, las consultas de instantáneas exponen el estado más reciente de la tabla fusionando los archivos base y delta del último segmento de archivo en el momento de la consulta.
- Consultas incrementales – Las consultas solo ven datos nuevos escritos en la tabla, desde una confirmación o compactación determinada. Esto proporciona efectivamente flujos de cambios para permitir canalizaciones de datos incrementales.
- Leer consultas optimizadas – Para las tablas MoR, las consultas ven los últimos datos compactados. Para las tablas CoW, las consultas ven los últimos datos confirmados.
Para tablas de copia en escritura, los rastreadores crean una única tabla en el catálogo de datos de AWS Glue con ReadOptimized Serde org.apache.hudi.hadoop.HoodieParquetInputFormat.
Para las tablas de combinación al leer, los rastreadores crean dos tablas en AWS Glue Data Catalog para la misma ubicación de la tabla:
- Una tabla con sufijo
_ro, que utiliza el servidor ReadOptimizedorg.apache.hudi.hadoop.HoodieParquetInputFormat - Una tabla con sufijo
_rt, que utiliza RealTime Serde permitiendo consultas de instantáneas:org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
Durante cada rastreo, para cada ruta de Hudi proporcionada, los rastreadores realizan una llamada API de lista de Amazon S3, filtran según el .hoodie carpetas y busque el archivo de metadatos más reciente en esa carpeta de metadatos de la tabla Hudi.
Rastree una tabla Hudi CoW utilizando el rastreador AWS Glue
En esta sección, veamos cómo rastrear un Hudi CoW utilizando los rastreadores de AWS Glue.
Requisitos previos
Estos son los requisitos previos para este tutorial:
- Instalar y configurar Interfaz de línea de comandos de AWS (AWS CLI).
- Cree su depósito S3 si no lo tiene.
- Cree su rol de IAM para AWS Glue si no lo tienes. Necesitas
s3:GetObjectparas3://your_s3_bucket/data/sample_hudi_cow_table/. - Ejecute el siguiente comando para copiar la tabla Hudi de muestra en su depósito S3. (Reemplazar
your_s3_bucketcon el nombre de su depósito S3).
Esta instrucción lo guía para copiar datos de muestra, pero puede crear cualquier tabla Hudi fácilmente usando AWS Glue. Más información en Presentación del soporte nativo para Apache Hudi, Delta Lake y Apache Iceberg en AWS Glue para Apache Spark, Parte 2: Editor visual de AWS Glue Studio.
Crear un rastreador Hudi
En esta instrucción, cree el rastreador a través de la consola. Complete los siguientes pasos para crear un rastreador Hudi:
- En la consola de AWS Glue, elija Rastreadores.
- Elige Crear rastreador.
- Nombre, introduzca
hudi_cow_crawler. Escoger Siguiente. - under Configuración de la fuente de datos, elegir Añadir fuente de datos.
- Fuente de datos, escoger Malo.
- Incluir rutas de tabla hudi, introduzca
s3://your_s3_bucket/data/sample_hudi_cow_table/. (Reemplazaryour_s3_bucketcon el nombre de su depósito S3). - Elige Agregar fuente de datos Hudi.
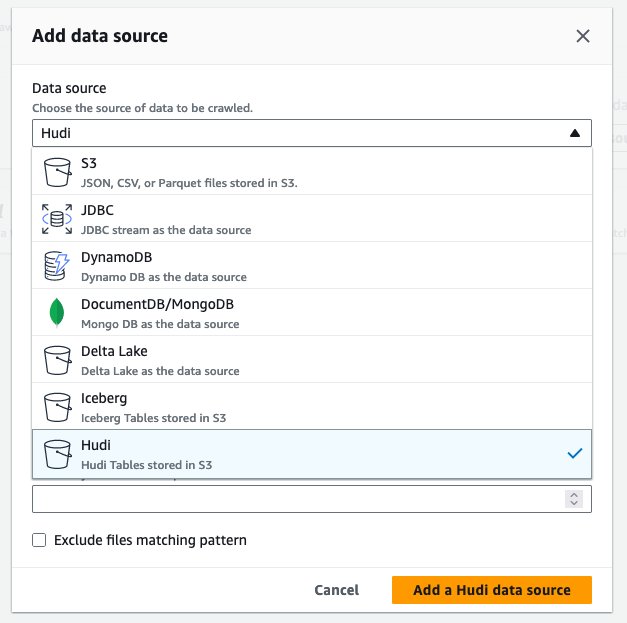
- Elige Siguiente.
- Rol de IAM existente, elija su rol de IAM y luego elija Siguiente.
- Base de datos de destino, escoger Agregar base de datos, Entonces el Agregar base de datos aparece el cuadro de diálogo. Para Nombre de la base de datos, introduzca
hudi_crawler_blog, A continuación, elija Crear. Escoger Siguiente. - Elige Crear rastreador.
Ahora se ha creado con éxito un nuevo rastreador Hudi. El rastreador se puede activar para que se ejecute a través de la consola o a través del SDK o AWS CLI mediante el StartCrawl API. También podría programarse a través de la consola para activar los rastreadores en momentos específicos. En esta instrucción, ejecute el rastreador a través de la consola.
- Elige Ejecutar rastreador.
- Espere a que se complete el rastreador.
Una vez que se haya ejecutado el rastreador, podrá ver la definición de la tabla Hudi en la consola de AWS Glue:
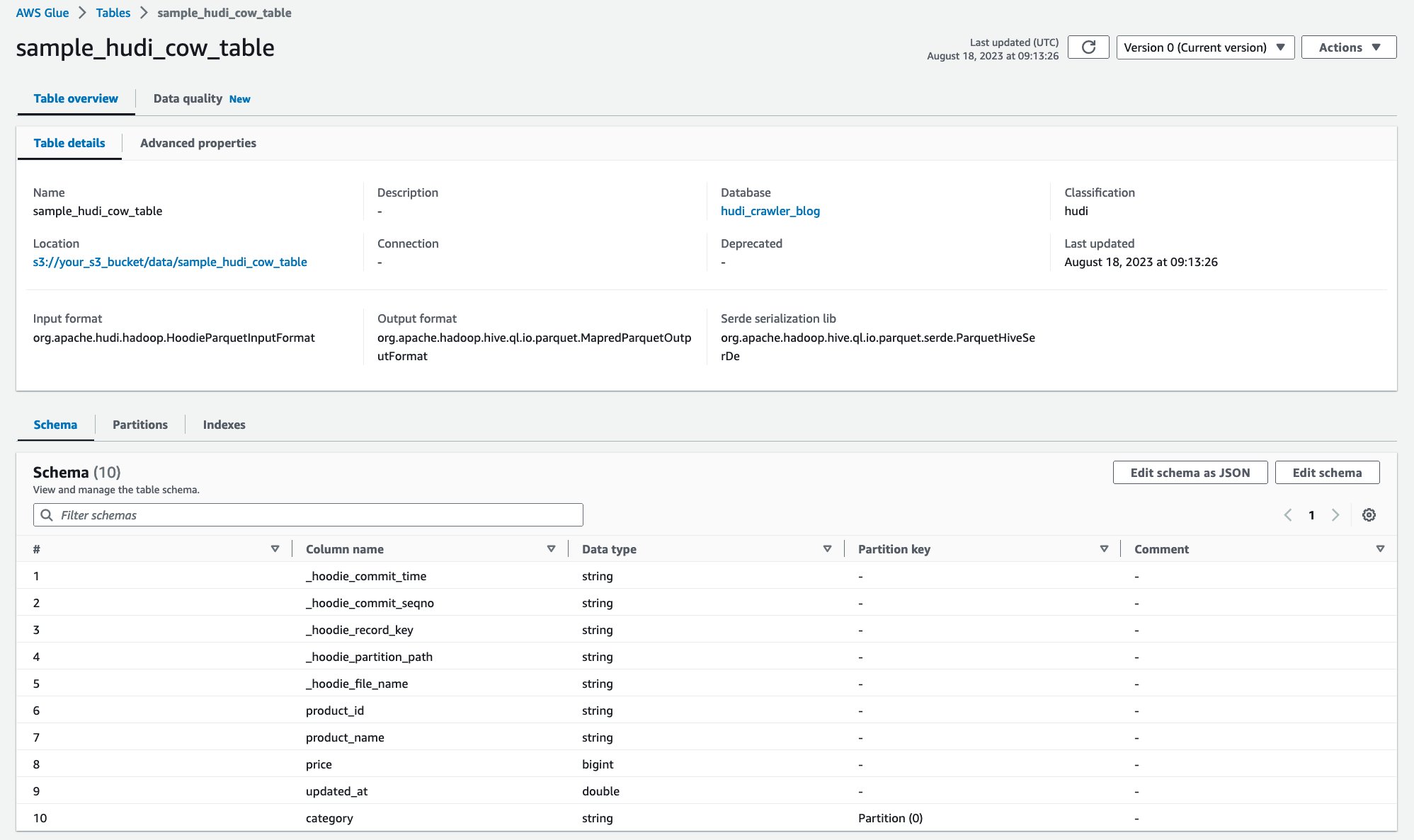
Ha rastreado correctamente la tabla Hudi CoR con datos en Amazon S3 y ha creado una tabla del catálogo de datos de AWS Glue con el esquema completo. Después de crear la definición de la tabla en AWS Glue Data Catalog, los servicios de análisis de AWS, como Amazon Athena, pueden consultar la tabla Hudi.
Complete los siguientes pasos para iniciar consultas en Athena:
- Abra la consola de Amazon Athena.
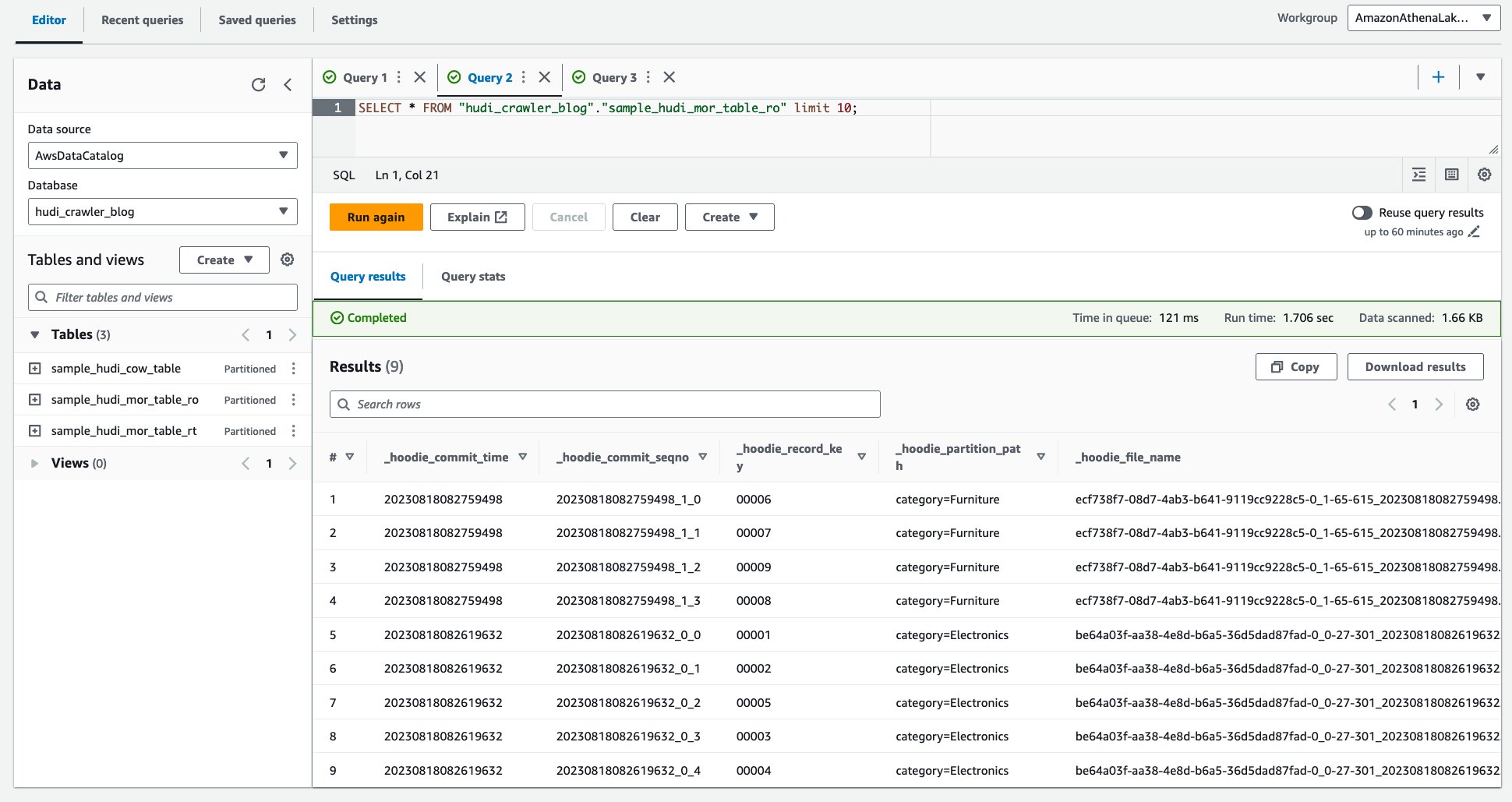
- Ejecute la siguiente consulta.
La siguiente captura de pantalla muestra nuestra salida:
Rastree una tabla Hudi MoR utilizando el rastreador AWS Glue con permisos de datos de AWS Lake Formation
En esta sección, veamos cómo rastrear una tabla Hudi MoR usando AWS Glue. Esta vez, utiliza el permiso de datos de AWS Lake Formation para rastrear fuentes de datos de Amazon S3 en lugar del permiso de IAM y Amazon S3. Esto es opcional, pero simplifica las configuraciones de permisos cuando su lago de datos está administrado por permisos de AWS Lake Formation.
Requisitos previos
Estos son los requisitos previos para este tutorial:
- Instalar y configurar Interfaz de línea de comandos de AWS (AWS CLI).
- Cree su depósito S3 si no lo tiene.
- Cree su rol de IAM para AWS Glue si no lo tienes. Necesitas
lakeformation:GetDataAccess. Pero no necesitass3:GetObjectparas3://your_s3_bucket/data/sample_hudi_mor_table/porque utilizamos el permiso de datos de Lake Formation para acceder a los archivos. - Ejecute el siguiente comando para copiar la tabla Hudi de muestra en su depósito S3. (Reemplazar
your_s3_bucketcon el nombre de su depósito S3).
Además de los pasos de procesamiento, complete los siguientes pasos para actualizar la configuración del catálogo de datos de AWS Glue para utilizar los permisos de Lake Formation para controlar los recursos del catálogo en lugar del control de acceso basado en IAM:
- Inicie sesión en la consola de Lake Formation como administrador del lago de datos.
- Si es la primera vez que accede a la consola de Lake Formation, agréguese como administrador del lago de datos.
- under Administración, escoger Configuración del catálogo de datos.
- Permisos predeterminados para bases de datos y tablas recién creadas, deseleccionar Use solo el control de acceso de IAM para nuevas bases de datos y Use solo el control de acceso de IAM para tablas nuevas en bases de datos nuevas.
- Configuración de versión entre cuentas, escoger Versión 3.
- Elige Guardar.
El siguiente paso es registrar su depósito S3 en las ubicaciones del lago de datos de Lake Formation:
- En la consola de Lake Formation, elija Ubicaciones de data lake, y elige Registrar ubicación.
- Ruta de Amazon S3, introduzca
s3://your_s3_bucket/. (Reemplazaryour_s3_bucketcon el nombre de su depósito S3). - Elige Registrar ubicación.
Luego, otorgue acceso al rol del rastreador de Glue a la ubicación de los datos para que el rastreador pueda usar el permiso de Lake Formation para acceder a los datos y crear tablas en la ubicación:
- En la consola de Lake Formation, elija Ubicaciones de datos y elige Grant.
- Usuarios y roles de IAM, seleccione la función de IAM que utilizó para el rastreador.
- Ubicación de almacenamiento, introduzca
s3://your_s3_bucket/data/. (Reemplazaryour_s3_bucketcon el nombre de su depósito S3). - Elige Grant.
Luego, otorgue la función de rastreador para crear tablas en la base de datos. hudi_crawler_blog:
- En la consola de Lake Formation, elija Permisos del lago de datos.
- Elige Grant.
- Directores, escoger Usuarios y roles de IAMy elija la función del rastreador.
- Etiquetas LF o recursos del catálogo, escoger Recursos de catálogo de datos con nombre.
- Base de datos, elige la base de datos
hudi_crawler_blog. - under Permisos de la base de datos, seleccione Crear una tabla.
- Elige Grant.
Cree un rastreador Hudi con permisos de datos de Lake Formation
Complete los siguientes pasos para crear un rastreador Hudi:
- En la consola de AWS Glue, elija Rastreadores.
- Elige Crear rastreador.
- Nombre, introduzca
hudi_mor_crawler. Escoger Siguiente. - under Configuración de la fuente de datos, elegir Añadir fuente de datos.
- Fuente de datos, escoger Malo.
- Incluir rutas de tabla hudi, introduzca
s3://your_s3_bucket/data/sample_hudi_mor_table/. (Reemplazaryour_s3_bucketcon el nombre de su depósito S3). - Elige Agregar fuente de datos Hudi.
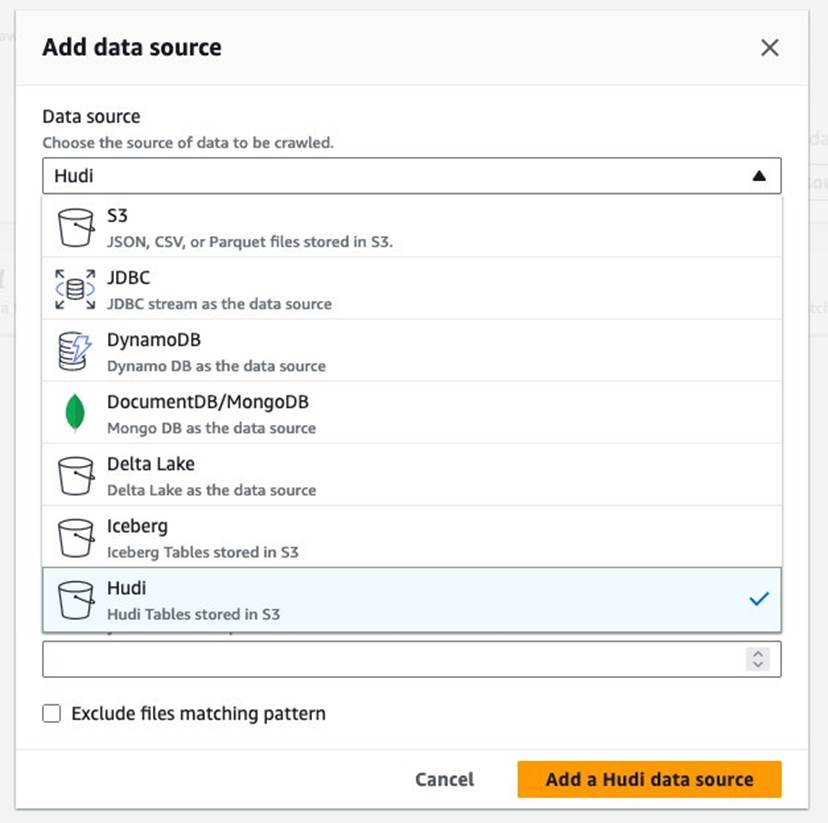
- Elige Siguiente.
- Rol de IAM existente, elija su función de IAM.
- under Configuración de formación de lago: opcional, seleccione Use las credenciales de Lake Formation para rastrear la fuente de datos S3.
- Elige Siguiente.
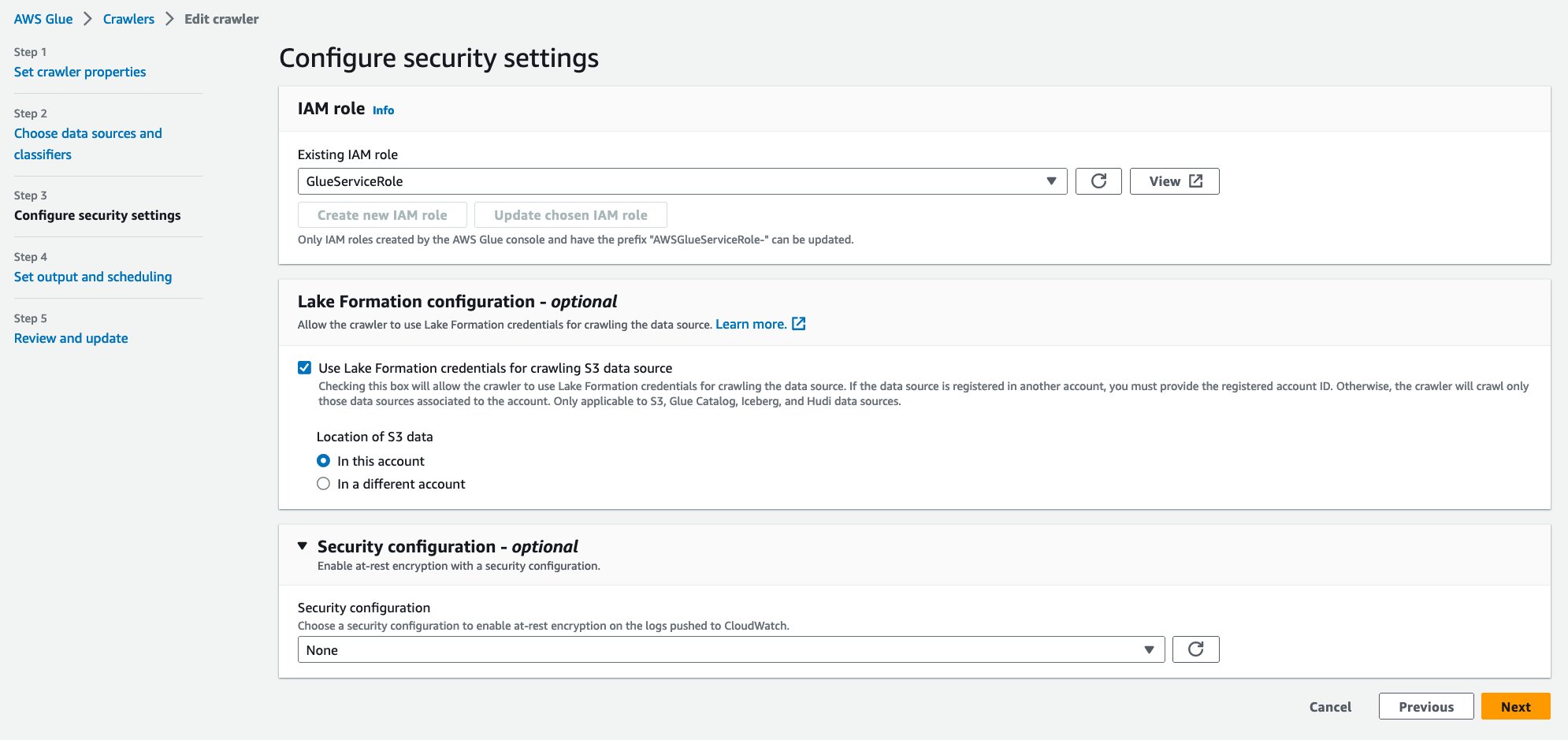
- Base de datos de destino, escoger
hudi_crawler_blog. Escoger Siguiente. - Elige Crear rastreador.
Ahora se ha creado con éxito un nuevo rastreador Hudi. El rastreador utiliza credenciales de Lake Formation para rastrear archivos de Amazon S3. Ejecutemos el nuevo rastreador:
- Elige Ejecutar rastreador.
- Espere a que se complete el rastreador.
Una vez que se haya ejecutado el rastreador, podrá ver dos tablas de la definición de tabla de Hudi en la consola de AWS Glue:
sample_hudi_mor_table_ro(leer tabla optimizada)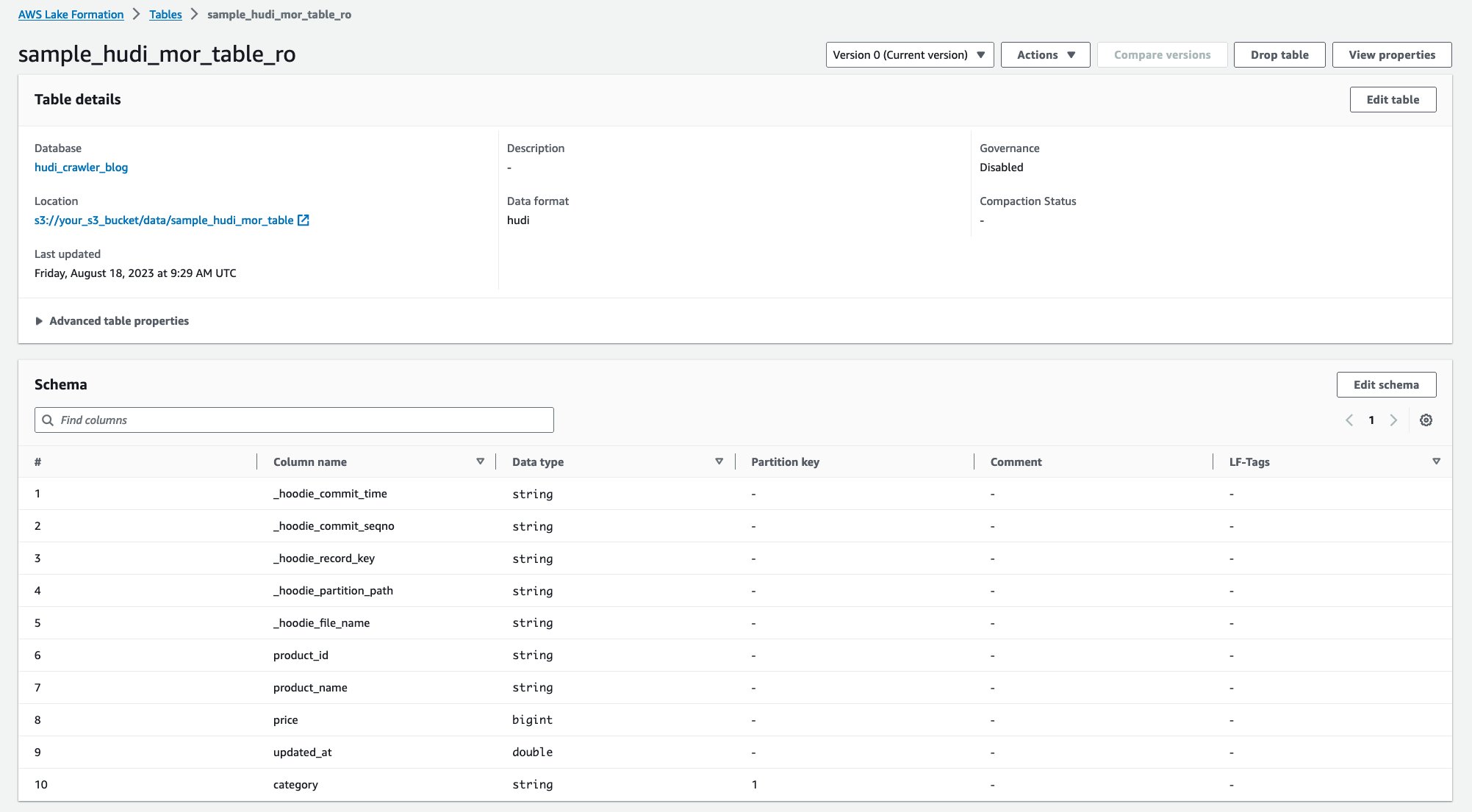
sample_hudi_mor_table_rt(horario real)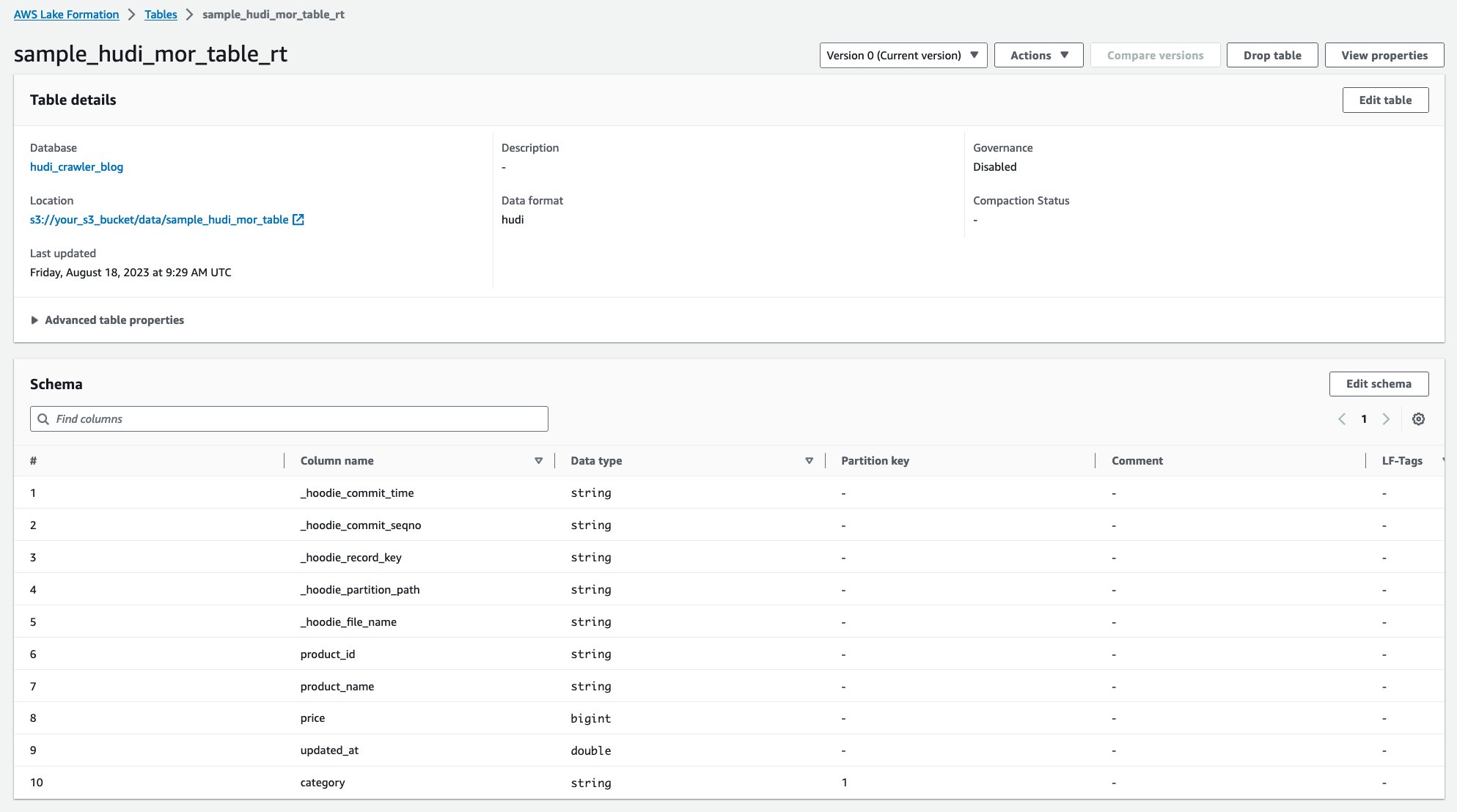
Registró el depósito del lago de datos con Lake Formation y habilitó el acceso de rastreo al lago de datos utilizando los permisos de Lake Formation. Ha rastreado correctamente la tabla Hudi MoR con datos en Amazon S3 y ha creado una tabla del catálogo de datos de AWS Glue con el esquema completo. Después de crear las definiciones de tablas en AWS Glue Data Catalog, los servicios de análisis de AWS, como Amazon Athena, pueden consultar la tabla Hudi.
Complete los siguientes pasos para iniciar consultas en Athena:
- Abra la consola de Amazon Athena.
- Ejecute la siguiente consulta.
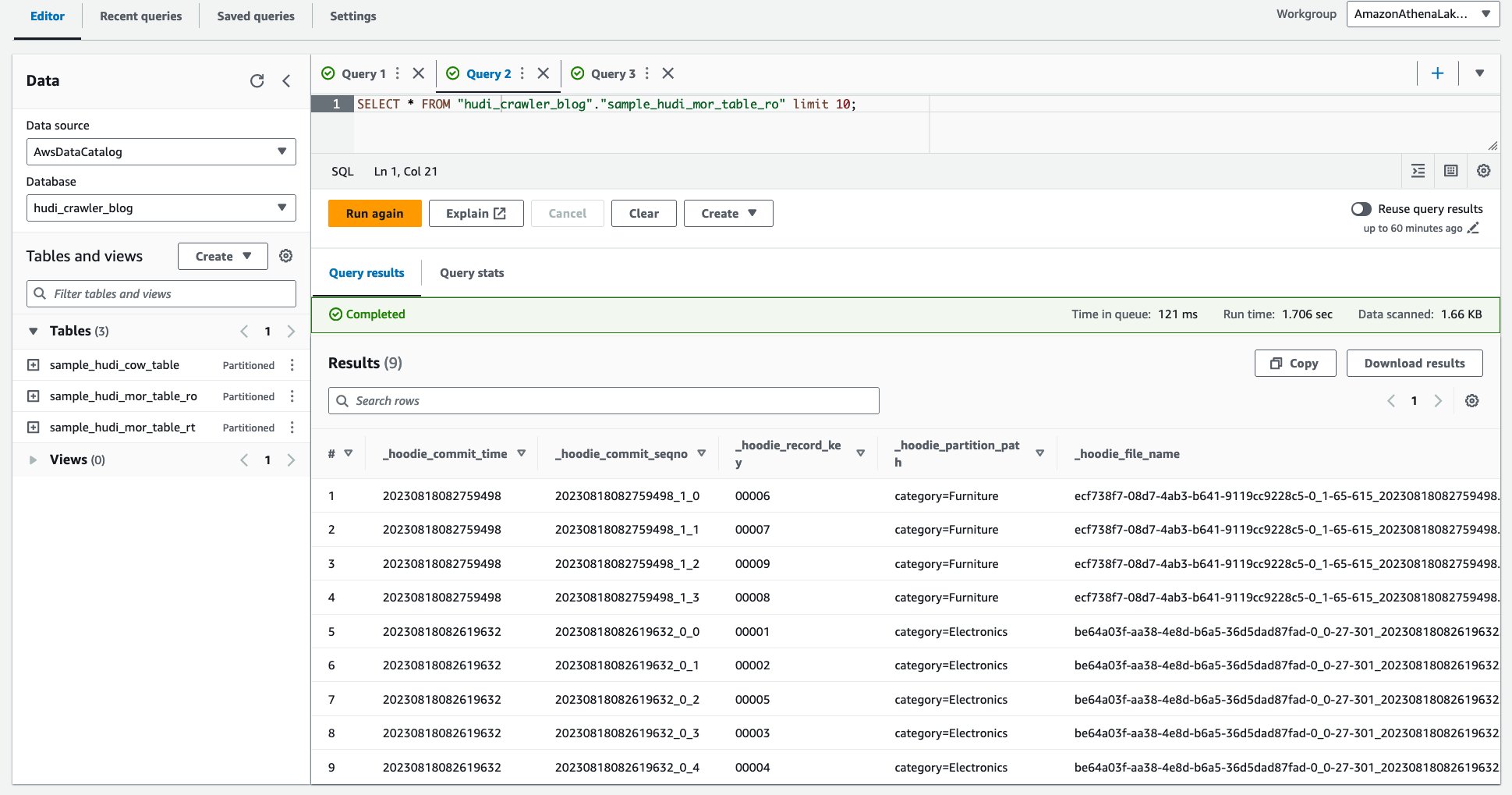
La siguiente captura de pantalla muestra nuestra salida:
- Ejecute la siguiente consulta.
La siguiente captura de pantalla muestra nuestra salida:
Control de acceso detallado mediante permisos de AWS Lake Formation
Para aplicar un control de acceso detallado en la tabla Hudi, puede beneficiarse de los permisos de AWS Lake Formation. Los permisos de Lake Formation le permiten restringir el acceso a tablas, columnas o filas específicas y luego consultar las tablas de Hudi a través de Amazon Athena con un control de acceso detallado. Configuremos el permiso de Lake Formation para la tabla Hudi MoR.
Requisitos previos
Estos son los requisitos previos para este tutorial:
- Completa la sección anterior Rastree una tabla Hudi MoR utilizando el rastreador AWS Glue con permisos de datos de AWS Lake Formation.
- Cree un usuario de IAM DataAnalyst, que tenga una política administrada por AWS AmazonAthenaAcceso completo.
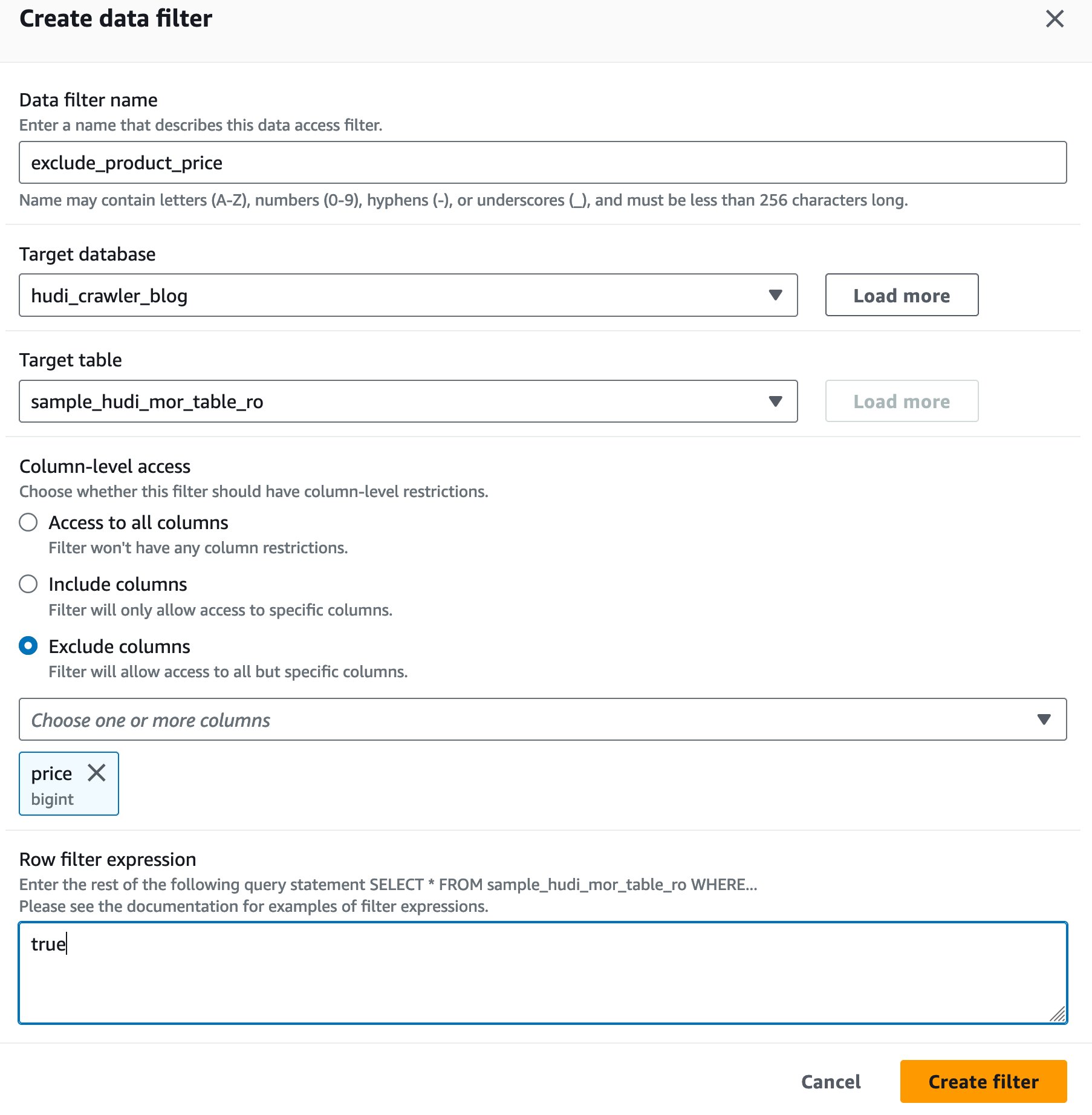
Crear un filtro de celda de datos de Lake Formation
Primero configuremos un filtro para la tabla optimizada de lectura MoR.
- Inicie sesión en la consola de Lake Formation como administrador del lago de datos.
- Elige Filtros de datos.
- Elige Crear nuevo filtro.
- Nombre del filtro de datos, introduzca
exclude_product_price. - Base de datos de destino, elige la base de datos
hudi_crawler_blog. - Tabla de destino, elige la mesa
sample_hudi_mor_table_ro. - Nivel de columna acceder, seleccionar Excluir columnasy elija el precio de la columna.
- Expresión de filtro de fila, introduzca
true. - Elige Crear filtro.
Otorgar permisos de Lake Formation al usuario de DataAnalyst
Complete los siguientes pasos para otorgar permiso de Lake Formation al DataAnalyst usuario
- En la consola de Lake Formation, elija Permisos del lago de datos.
- Elige Grant.
- Directores, escoger Usuarios y roles de IAMy elige el usuario
DataAnalyst. - Etiquetas LF o recursos del catálogo, escoger Recursos de catálogo de datos con nombre.
- Base de datos, elige la base de datos
hudi_crawler_blog. - Mesa – opcional, elige la mesa
sample_hudi_mor_table_ro. - Filtros de datos – opcionales, Seleccione
exclude_product_price. - Permisos de filtro de datos, seleccione Seleccione.
- Elige Grant.
Le concediste permiso a Lake Formation en la base de datos. hudi_crawler_blog y la mesa sample_hudi_mor_table_ro, excluyendo la columna price al usuario de DataAnalyst. Ahora validemos el acceso del usuario a los datos usando Athena.
- Inicie sesión en la consola de Athena como usuario de DataAnalyst.
- En el editor de consultas, ejecute la siguiente consulta:
La siguiente captura de pantalla muestra nuestra salida:
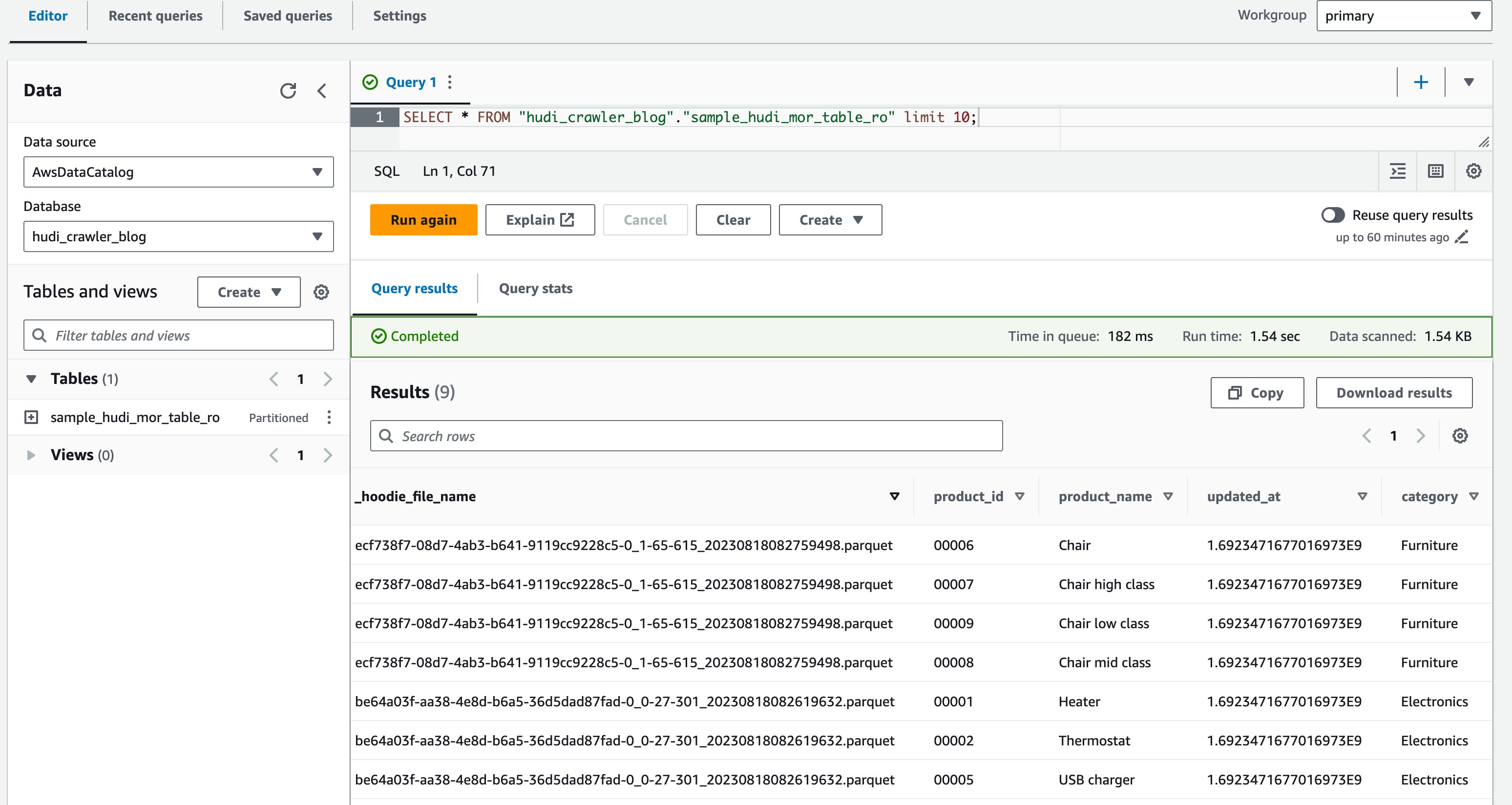
Ahora validaste que la columna price no se muestra, pero las otras columnas product_id, product_name, update_aty category son exhibidos.
Limpiar
Para evitar cargos no deseados en su cuenta de AWS, elimine los siguientes recursos de AWS:
- Eliminar la base de datos de AWS Glue
hudi_crawler_blog. - Eliminar rastreadores de AWS Glue
hudi_cow_crawleryhudi_mor_crawler. - Elimine archivos de Amazon S3 en
s3://your_s3_bucket/data/sample_hudi_cow_table/ys3://your_s3_bucket/data/sample_hudi_mor_table/.
Conclusión
Esta publicación demostró cómo funcionan los rastreadores de AWS Glue para tablas Hudi. Con la compatibilidad con el rastreador Hudi, puede pasar rápidamente a utilizar AWS Glue Data Catalog como su catálogo de tablas Hudi principal. Puede comenzar a crear su lago de datos transaccionales sin servidor utilizando Hudi en AWS mediante AWS Glue, AWS Glue Data Catalog y controles de acceso detallados de Lake Formation para tablas y formatos compatibles con los motores analíticos de AWS.
Sobre los autores
 Noritaka Sekiyama es Arquitecto Principal de Big Data en el equipo de AWS Glue. Trabaja en Tokio, Japón. Es responsable de crear artefactos de software para ayudar a los clientes. En su tiempo libre, disfruta andar en bicicleta con su bicicleta de carretera.
Noritaka Sekiyama es Arquitecto Principal de Big Data en el equipo de AWS Glue. Trabaja en Tokio, Japón. Es responsable de crear artefactos de software para ayudar a los clientes. En su tiempo libre, disfruta andar en bicicleta con su bicicleta de carretera.
 kyle duong es ingeniero de desarrollo de software en el equipo de AWS Glue y Lake Formation. Le apasiona la construcción de tecnologías de big data y sistemas distribuidos.
kyle duong es ingeniero de desarrollo de software en el equipo de AWS Glue y Lake Formation. Le apasiona la construcción de tecnologías de big data y sistemas distribuidos.
 Sandeep Adwankar es gerente sénior de productos técnicos en AWS. Con sede en el Área de la Bahía de California, trabaja con clientes de todo el mundo para traducir los requisitos comerciales y técnicos en productos que permitan a los clientes mejorar la forma en que administran, protegen y acceden a los datos.
Sandeep Adwankar es gerente sénior de productos técnicos en AWS. Con sede en el Área de la Bahía de California, trabaja con clientes de todo el mundo para traducir los requisitos comerciales y técnicos en productos que permitan a los clientes mejorar la forma en que administran, protegen y acceden a los datos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- :posee
- :es
- :no
- :dónde
- $ UP
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- Poder
- Nuestra Empresa
- de la máquina
- Acceso a los datos
- el acceso
- Mi Cuenta
- la columna Acción
- add
- adicional
- adición
- adoptado
- Adopción
- avanzado
- Después
- Todos
- permitir
- Permitir
- permite
- también
- Amazon
- Atenea amazónica
- Amazon Web Services
- an
- Pruebas analíticas
- Analytics
- y
- Otra
- cualquier
- APACHE
- Apache Spark
- abejas
- aparece
- Aplicación
- Desarrollo de aplicaciones
- Aplicá
- somos
- Reservada
- en torno a
- AS
- At
- automáticamente
- evitar
- AWS
- Pegamento AWS
- Formación del lago AWS
- bases
- basado
- Bay
- BE
- porque
- esto
- es el beneficio
- mejores
- Big
- Big Data
- Trae
- Construir la
- construido
- pero
- by
- California
- llamar al
- PUEDEN
- capacidades
- capacidad
- case
- catalogar
- catálogos
- categoría
- (SCD por sus siglas en inglés),
- retos
- el cambio
- cambiado
- Cambios
- cargos
- Elige
- Columna
- Columnas
- combinación
- hacer
- comprometido
- completar
- integraciones
- componente
- Configuración
- Consola
- contiene
- contenido
- continuamente
- control
- controles
- podría
- rastreador
- Para crear
- creado
- crea
- Referencias
- Clientes
- datos
- integración de datos
- Lago de datos
- almacenamiento de datos
- Base de datos
- bases de datos
- conjuntos de datos
- definición
- Definiciones
- Delta
- demostrado
- demuestra
- profundidad
- Desarrollo
- directamente
- descrubrir
- distribuidos
- sistemas distribuidos
- do
- sí
- durante
- cada una
- más fácil
- pasan fácilmente
- editor
- de manera eficaz
- eficiente
- habilitar
- facilita
- ingeniero
- certificados
- motores
- Participar
- Éter (ETH)
- evolución
- excluyendo
- extraerlos
- más rápida
- menos
- Archive
- archivos
- filtrar
- filtros
- Encuentre
- Nombre
- primer vez
- siguiendo
- formato
- formación
- frecuentemente
- Desde
- dado
- globo
- Go
- conceder
- concedido
- Guías
- Hadoop
- Tienen
- he
- ayuda
- ayuda
- su
- Colmena
- Cómo
- Como Hacer
- HTML
- HTTPS
- AMI
- if
- implicaciones
- mejorar
- in
- Incluye
- incrementales
- información
- integrar
- integración
- Interfaz
- dentro
- Presentamos
- IT
- Japón
- jpg
- acuerdo
- lago
- lagos
- más reciente
- lanzamiento
- APRENDE:
- aprendizaje
- menos
- LIMITE LAS
- línea
- Lista
- situados
- Ubicación
- Ubicaciones
- conectado
- máquina
- máquina de aprendizaje
- el mantenimiento de
- para lograr
- HACE
- gestionan
- gestionado
- gerente
- administrar
- manual
- máximas
- la fusión de
- metadatos
- migrar
- migración
- ML
- más,
- MEJOR DE TU
- movimiento
- múltiples
- nombre
- nativo
- ¿ Necesita ayuda
- Nuevo
- recién
- Next
- ahora
- of
- on
- ONE
- , solamente
- habiertos
- de código abierto
- optimizado
- Optión
- or
- Otro
- nuestros
- salida
- parte
- apasionado
- camino
- caminos
- actuación
- permiso
- permisos
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- Popular
- poblado
- Publicación
- Preparar
- requisitos previos
- anterior
- precio
- primario
- Director de la escuela
- tratamiento
- Producto
- gerente de producto
- Productos
- proporcionar
- previsto
- proporciona un
- consultas
- con rapidez
- Leer
- real
- en tiempo real
- en tiempo real
- reciente
- grabar
- registrarte
- registrado
- reemplazar
- Requisitos
- Recursos
- responsable
- restringir
- carretera
- Función
- FILA
- Ejecutar
- mismo
- programa
- programada
- Sdk
- Sección
- seguro
- ver
- selecciona
- mayor
- Sin servidor
- de coches
- Servicios
- set
- ajustes
- mostrado
- Shows
- simplifica
- desde
- soltero
- Rebanada
- Instantánea
- So
- Software
- Desarrollo de software ad-hoc
- Fuente
- Fuentes
- Spark
- soluciones y
- comienzo
- Estado
- paso
- pasos
- almacenados
- en streaming
- corrientes
- estudio
- Con éxito
- tal
- SOPORTE
- Soportado
- sincronizar
- Todas las funciones a su disposición
- mesa
- equipo
- Técnico
- Tecnologías
- esa
- La
- su
- luego
- Ahí.
- ellos
- así
- Tres
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- veces
- a
- Tokio
- parte superior
- transaccional
- Transacciones
- la traducción
- atravesar
- detonante
- desencadenados
- tutoriales
- dos
- tipos
- principiante
- bajo
- no deseado
- Actualizar
- actualizado
- Actualizaciones
- utilizan el
- caso de uso
- usado
- Usuario
- usuarios
- usos
- usando
- VALIDAR
- validado
- Valores
- versión
- visual
- Manejo de
- we
- web
- servicios web
- WELL
- cuando
- que
- mientras
- QUIENES
- seguirá
- sin
- Actividades:
- funciona
- escribir
- escrito
- Usted
- tú
- a ti mismo
- zephyrnet