Servicio Amazon OpenSearch es un servicio administrado que simplifica la protección, implementación y operación de clústeres de OpenSearch a escala en la nube de AWS. El año pasado presentamos Contrapresión de indexación de fragmentos y control de admisión, que supervisa los recursos del clúster y el tráfico entrante para rechazar de forma selectiva las solicitudes que, de otro modo, plantearían riesgos para la estabilidad, como falta de memoria y un impacto en el rendimiento del clúster debido a contenciones de memoria, saturación de la CPU y sobrecarga del GC, y más.
Ahora nos complace presentar la contrapresión de búsqueda y el control de admisión basado en CPU para OpenSearch Service, que mejora aún más la capacidad de recuperación de los clústeres. Estas mejoras están disponibles para todas las versiones de OpenSearch 1.3 o superior.
Buscar contrapresión
La contrapresión evita que un sistema se vea abrumado por el trabajo. Lo hace controlando la tasa de tráfico o eliminando la carga excesiva para evitar bloqueos y pérdida de datos, mejorar el rendimiento y evitar fallas totales del sistema.
La contrapresión de búsqueda es un mecanismo para identificar y cancelar solicitudes de búsqueda con uso intensivo de recursos en curso cuando un nodo está bajo coacción. Es eficaz contra las cargas de trabajo de búsqueda con un uso anormalmente alto de recursos (como consultas complejas, consultas lentas, muchas coincidencias o agregaciones pesadas), que de lo contrario podrían causar fallas en los nodos y afectar la salud del clúster.
Search Backpression se basa en el marco de seguimiento de recursos de tareas, que proporciona una API fácil de usar para monitorear el uso de recursos de cada tarea. Search Backpression utiliza un subproceso en segundo plano que mide periódicamente el uso de recursos del nodo y asigna una puntuación de cancelación a cada tarea de búsqueda en curso en función de factores como el tiempo de CPU, las asignaciones de almacenamiento dinámico y el tiempo transcurrido. Una puntuación de cancelación más alta corresponde a una solicitud de búsqueda que requiere más recursos. Las solicitudes de búsqueda se cancelan en orden descendente de su puntuación de cancelación para recuperar los nodos rápidamente, pero la cantidad de cancelaciones tiene un límite de frecuencia para evitar el desperdicio de trabajo.
El siguiente diagrama ilustra el flujo de trabajo de búsqueda de contrapresión.
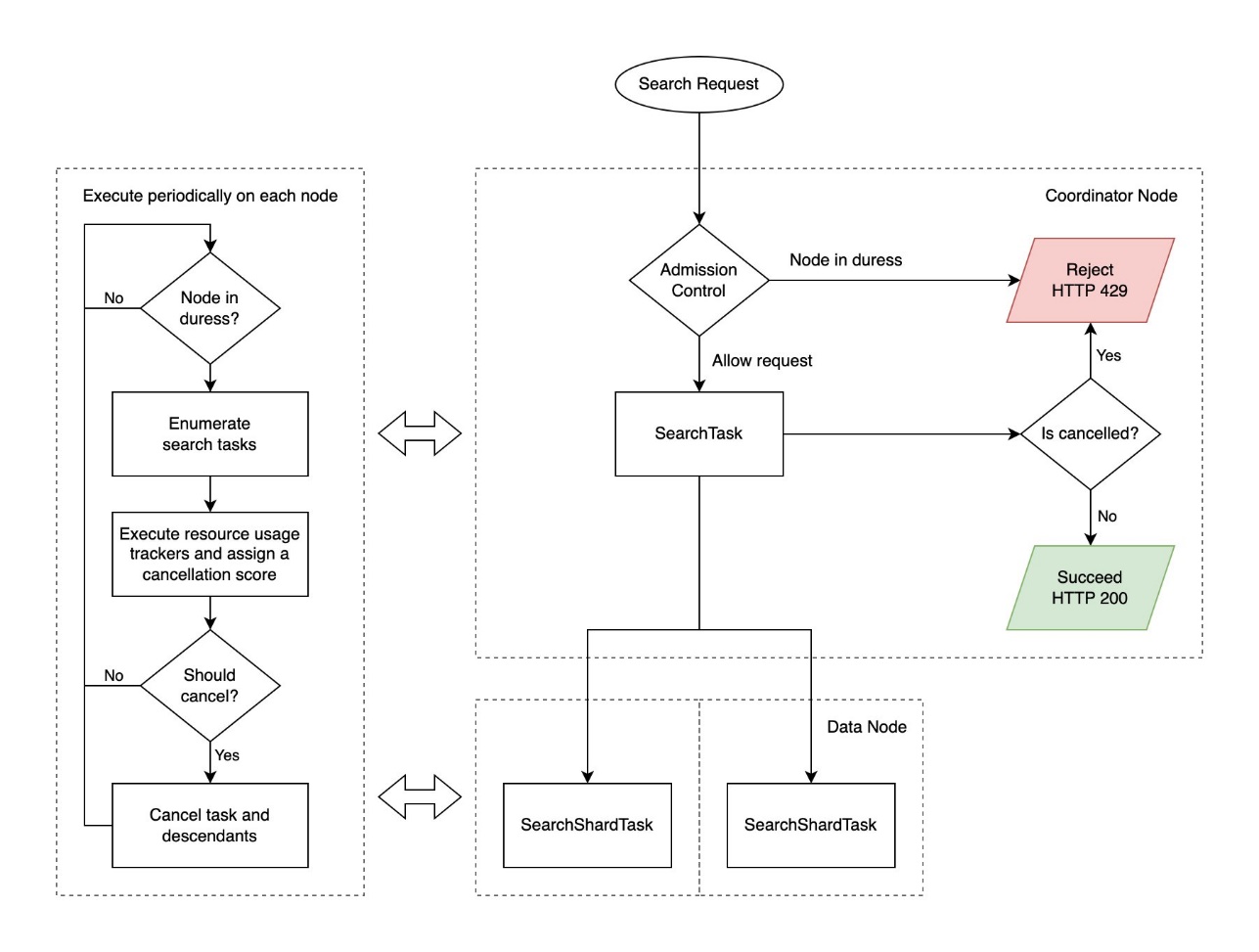
Las solicitudes de búsqueda devuelven un código de estado HTTP 429 "Demasiadas solicitudes" al momento de la cancelación. OpenSearch devuelve resultados parciales si solo fallan algunos fragmentos y se permiten resultados parciales. Ver el siguiente código:
Supervisión de la contrapresión de búsqueda
Puede monitorear el estado detallado de la contrapresión de búsqueda usando la API de estadísticas del nodo:
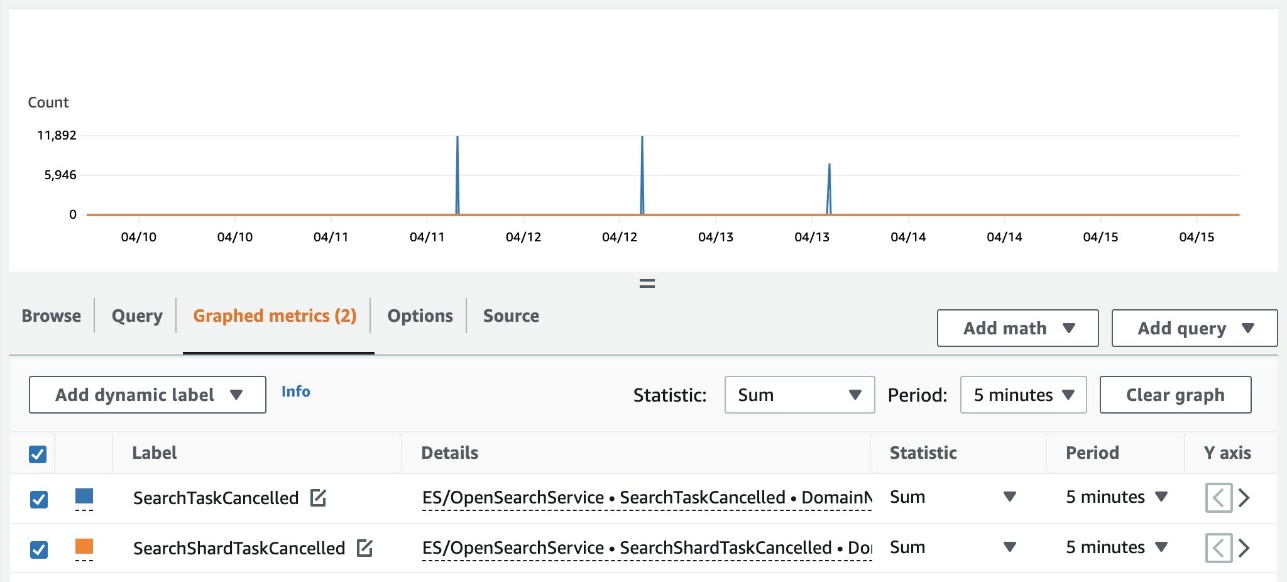
También puede ver el resumen de cancelaciones de todo el clúster usando Reloj en la nube de Amazon. Las siguientes métricas ahora están disponibles en el ES/Servicio OpenSearch espacio de nombres:
- Tarea de búsqueda cancelada – El número de cancelaciones del nodo coordinador
- SearchShardTaskCancelado – El número de cancelaciones de nodos de datos
La siguiente captura de pantalla muestra un ejemplo del seguimiento de estas métricas en la consola de CloudWatch.
Control de admisión basado en CPU
El control de admisión es un mecanismo de control que limita de manera proactiva la cantidad de solicitudes a un nodo en función de su capacidad actual, tanto para aumentos orgánicos como para picos de tráfico.
Además de la presión de la memoria JVM y los umbrales de tamaño de la solicitud, ahora también supervisa el uso promedio móvil de la CPU de cada nodo para rechazar los mensajes entrantes. _search y _bulk peticiones. Evita que los nodos se sobrecarguen con demasiadas solicitudes, lo que genera puntos calientes, problemas de rendimiento, tiempos de espera de solicitudes y otras fallas en cascada. Las solicitudes excesivas devuelven un código de estado HTTP 429 "Demasiadas solicitudes" al ser rechazadas.
Manejo de errores HTTP 429
Recibirá errores HTTP 429 si envía demasiado tráfico a un nodo. Indica recursos de clúster insuficientes, solicitudes de búsqueda con uso intensivo de recursos o un pico no deseado en la carga de trabajo.
La contrapresión de búsqueda proporciona el motivo del rechazo, lo que puede ayudar a afinar las solicitudes de búsqueda que consumen muchos recursos. Para los picos de tráfico, recomendamos reintentos del lado del cliente con retraso y fluctuación exponenciales.
También puede seguir estas guías de solución de problemas para depurar rechazos excesivos:
Conclusión
La contrapresión de búsqueda es un mecanismo reactivo para eliminar la carga excesiva, mientras que el control de admisión es un mecanismo proactivo para limitar el número de solicitudes a un nodo más allá de su capacidad. Ambos funcionan en conjunto para mejorar la resiliencia general de un clúster de OpenSearch.
La contrapresión de búsqueda está disponible en Opensearch, y siempre estamos buscando contribuciones externas. Puede consultar el RFC para comenzar.
Sobre los autores
 Ketan Verma es un SDE sénior que trabaja en Amazon OpenSearch Service. Le apasiona construir sistemas distribuidos a gran escala, mejorar el rendimiento y simplificar ideas complejas con abstracciones simples. Fuera del trabajo, le gusta leer y mejorar sus habilidades como barista en casa.
Ketan Verma es un SDE sénior que trabaja en Amazon OpenSearch Service. Le apasiona construir sistemas distribuidos a gran escala, mejorar el rendimiento y simplificar ideas complejas con abstracciones simples. Fuera del trabajo, le gusta leer y mejorar sus habilidades como barista en casa.
 Suresh NS es un SDE sénior que trabaja en Amazon OpenSearch Service. Le apasiona resolver problemas en sistemas distribuidos a gran escala.
Suresh NS es un SDE sénior que trabaja en Amazon OpenSearch Service. Le apasiona resolver problemas en sistemas distribuidos a gran escala.
 pritkumar ladani es un SDE-2 que funciona en Amazon OpenSearch Service. Le gusta contribuir al desarrollo de software de código abierto y le apasionan los sistemas distribuidos. Es un jugador aficionado de bádminton y disfruta del senderismo.
pritkumar ladani es un SDE-2 que funciona en Amazon OpenSearch Service. Le gusta contribuir al desarrollo de software de código abierto y le apasionan los sistemas distribuidos. Es un jugador aficionado de bádminton y disfruta del senderismo.
 Bujtawar Khan es un ingeniero principal que trabaja en Amazon OpenSearch Service. Está interesado en construir sistemas distribuidos y autónomos. Es mantenedor y colaborador activo de OpenSearch.
Bujtawar Khan es un ingeniero principal que trabaja en Amazon OpenSearch Service. Está interesado en construir sistemas distribuidos y autónomos. Es mantenedor y colaborador activo de OpenSearch.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- EVM Finanzas. Interfaz unificada para finanzas descentralizadas. Accede Aquí.
- Grupo de medios cuánticos. IR/PR amplificado. Accede Aquí.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/improved-resiliency-with-backpressure-and-admission-control-for-amazon-opensearch-service/
- :es
- 1
- 1.3
- 100
- 26
- 7
- 77
- a
- Nuestra Empresa
- lector activo
- adición
- en contra
- Todos
- asignaciones
- también
- hacerlo
- aficionado
- Amazon
- Amazon Web Services
- an
- y
- abejas
- somos
- AS
- At
- autónomo
- sistemas autónomos
- Hoy Disponibles
- promedio
- evitar
- AWS
- fondo
- barista
- basado
- "Ser"
- Más allá de
- ambas
- Construir la
- construido
- pero
- by
- PUEDEN
- Capacidad
- Causa
- Soluciones
- Médico
- código
- integraciones
- Consola
- contribuir
- contribuyente
- control
- CONTROL
- Director
- corresponde
- podría
- CPU
- Current
- datos
- De pérdida de datos
- desplegar
- detallado
- Desarrollo
- distribuidos
- sistemas distribuidos
- sí
- dos
- cada una
- fácil de usar
- Eficaz
- ya sea
- ingeniero
- Mejora
- error
- Errores
- Éter (ETH)
- ejemplo
- excedido
- excitado
- exponencial
- factores importantes
- FALLO
- Fracaso
- seguir
- siguiendo
- Marco conceptual
- Desde
- promover
- portero
- obtener
- Guías
- he
- Salud
- pesado
- ayuda
- Alta
- más alto
- su
- Golpes
- Inicio
- HOT
- http
- HTTPS
- ideas
- Identifique
- if
- ilustra
- Impacto
- mejorar
- mejorado
- mejoras
- la mejora de
- in
- Entrante
- Los aumentos
- índice
- Indica
- interesado
- introducir
- Introducido
- IT
- SUS
- jpg
- large
- Gran escala
- Apellido
- El año pasado
- líder
- como
- LIMITE LAS
- límites
- carga
- mirando
- de
- HACE
- gestionado
- muchos
- medidas
- mecanismo
- Salud Cerebral
- Métrica
- Monitorear
- monitores
- más,
- nodo
- nodos
- ahora
- número
- of
- on
- , solamente
- habiertos
- de código abierto
- funcionar
- or
- solicite
- ecológicos
- Otro
- de otra manera
- salir
- afuera
- total
- abrumado
- apasionado
- actuación
- fase
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- jugador
- presión
- evitar
- evita
- Director de la escuela
- Proactiva
- problemas
- proporciona un
- consultas
- con rapidez
- Rate
- Leer
- razón
- recepción
- recomiendan
- Recuperar
- solicita
- solicitudes
- Recurso
- muchos recursos
- Recursos
- Resultados
- volvemos
- devoluciones
- riesgos
- Rolling
- Escala
- Puntuación
- Buscar
- seguro
- ver
- envío
- mayor
- de coches
- Servicios
- cobertizo
- Shows
- sencillos
- simplificando
- Tamaño
- habilidades
- lento
- So
- Software
- Desarrollo de software ad-hoc
- Resolver
- algo
- Fuente
- espiga
- picos
- Estabilidad
- fundó
- Estado
- estadísticas
- Estado
- tal
- RESUMEN
- te
- Todas las funciones a su disposición
- Tandem
- Tarea
- esa
- La
- su
- Estas
- equipo
- a
- demasiado
- parte superior
- Total
- hacia
- Seguimiento
- tráfico
- verdadero
- tipo
- bajo
- a
- Uso
- usos
- usando
- Ver
- fue
- we
- web
- servicios web
- cuando
- que
- mientras
- Actividades:
- flujo de trabajo
- trabajando
- se
- año
- Usted
- zephyrnet