Desplazamiento al rojo de Amazon, un almacén de datos en la nube ampliamente utilizado, ha evolucionado significativamente para cumplir con los requisitos de rendimiento de las cargas de trabajo más exigentes. Esta publicación cubre una de esas nuevas características: la clave de clasificación de diseño de datos multidimensionales.
Amazon Redshift ahora mejora el rendimiento de sus consultas al admitir claves de clasificación de diseño de datos multidimensionales, que es un nuevo tipo de clave de clasificación que ordena los datos de una tabla por predicados de filtro en lugar de columnas físicas de la tabla. Las claves de clasificación de diseño de datos multidimensionales mejorarán significativamente el rendimiento de los escaneos de tablas, especialmente cuando su carga de trabajo de consultas contiene filtros de escaneo repetitivos.
Amazon Redshift ya ofrece la capacidad de optimización automática de la mesa (ATO), que optimiza automáticamente el diseño de tablas aplicando claves de clasificación y distribución sin necesidad de intervención del administrador. En esta publicación, presentamos las claves de clasificación de diseño de datos multidimensionales como una capacidad adicional ofrecida por ATO y fortalecida por el algoritmo asesor de claves de clasificación de Amazon Redshift.
Claves de clasificación de diseño de datos multidimensionales
Cuando define una tabla con la clave de clasificación AUTO, Amazon Redshift ATO analizará su historial de consultas y seleccionará automáticamente una clave de clasificación de una sola columna o una clave de clasificación de diseño de datos multidimensional para su tabla, según qué opción sea mejor para su carga de trabajo. Cuando se selecciona el diseño de datos multidimensionales, Amazon Redshift construirá una función de clasificación multidimensional que ubica filas a las que normalmente acceden las mismas consultas, y la función de clasificación se utiliza posteriormente durante las ejecuciones de consultas para omitir bloques de datos e incluso omitir el escaneo del predicado individual. columnas.
Considere la siguiente consulta de usuario, que es un patrón de consulta dominante en la carga de trabajo del usuario:
Amazon Redshift almacena datos para cada columna en bloques de disco de 1 MB y almacena los valores mínimo y máximo en cada bloque como parte de los metadatos de la tabla. Si una consulta utiliza un predicado de rango restringido, Amazon Redshift puede utilizar los valores mínimo y máximo para omitir rápidamente una gran cantidad de bloques durante los análisis de tablas. Sin embargo, el filtro de esta consulta en la columna de subregión no se puede utilizar para determinar qué bloques omitir en función de los valores mínimos y máximos y, como resultado, Amazon Redshift escanea todas las filas de la tabla de títulos:
Cuando la consulta del usuario se ejecutó con titles utilizando una clave de clasificación de una sola columna en subregion, el resultado de la consulta anterior es el siguiente:
Esto muestra que el escaneo de la tabla leyó 2,164,081,640 filas.
Para mejorar los escaneos en el titles tabla, Amazon Redshift podría decidir automáticamente utilizar una clave de clasificación de diseño de datos multidimensional. Todas las filas que satisfacen el lower(subregion) like '%United States%' El predicado se ubicaría en una región dedicada de la tabla y, por lo tanto, Amazon Redshift solo escaneará bloques de datos que satisfagan el predicado.
Cuando la consulta del usuario se ejecuta con titles utilizando una clave de clasificación de diseño de datos multidimensional que incluye lower(subregion) like '%United States%' como predicado, el resultado de la sys_query_detail consulta es la siguiente:
Esto muestra que el escaneo de la tabla leyó 152,324,046 filas, que es solo el 7% del original, y utilizó la clave de clasificación de diseño de datos multidimensional.
Tenga en cuenta que este ejemplo utiliza una única consulta para mostrar la función de diseño de datos multidimensionales, pero Amazon Redshift considerará todas las consultas que se ejecutan en la tabla y puede crear varias regiones para satisfacer los predicados que se ejecutan con más frecuencia.
Tomemos otro ejemplo, esta vez con predicados más complejos y múltiples consultas.
Imagínate tener una mesa items (cost int, available int, demand int) con cuatro filas como se muestra en el siguiente ejemplo.
| #carné de identidad | el costo | Hoy Disponibles | demanda |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
Su carga de trabajo dominante consta de dos consultas:
- Patrón de consultas del 70%:
- Patrón de consultas del 20%:
Con las técnicas de clasificación tradicionales, puede optar por ordenar la tabla según la columna de costos, de modo que la evaluación de cost > 3 se beneficiará del tipo. Entonces, la tabla de artículos después de ordenar usando un solo cost La columna tendrá el siguiente aspecto.
| #carné de identidad | el costo | Hoy Disponibles | demanda |
| Región #1, con costo <= 3 | |||
| Región #2, con costo > 3 | |||
| #carné de identidad | el costo | Hoy Disponibles | demanda |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
Al utilizar esta clasificación tradicional, podemos excluir inmediatamente las dos filas superiores (azules) con ID 4 e ID 2, porque no satisfacen cost > 3.
Por otro lado, con una clave de clasificación de diseño de datos multidimensional, la tabla se ordenará según una combinación de los dos predicados que ocurren comúnmente en la carga de trabajo del usuario, que son cost > 3 y available < demand. Como resultado, las filas de la tabla se clasifican en cuatro regiones.
| #carné de identidad | el costo | Hoy Disponibles | demanda |
| Región #1, con costo <= 3 y disponible < demanda | |||
| Región #2, con costo <= 3 y disponible >= demanda | |||
| Región #3, con costo > 3 y disponible < demanda | |||
| Región #4, con costo > 3 y disponible >= demanda | |||
| #carné de identidad | el costo | Hoy Disponibles | demanda |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
Este concepto es aún más poderoso cuando se aplica a bloques completos en lugar de filas individuales, cuando se aplica a predicados complejos que utilizan operadores que no son adecuados para las técnicas de clasificación tradicionales (como like), y cuando se aplica a más de dos predicados.
Tablas del sistema
Las siguientes tablas del sistema de Amazon Redshift mostrarán a los usuarios si se utilizan diseños de datos multidimensionales en sus tablas y consultas:
- Para determinar si una tabla en particular utiliza una clave de clasificación de diseño de datos multidimensional, puede verificar si
sortkey1in svv_table_info es igual aAUTO(SORTKEY(padb_internal_mddl_key_col)). - Para determinar si una consulta en particular utiliza un diseño de datos multidimensional para acelerar los escaneos de tablas, puede verificar
step_attributeexistentes sys_query_detail vista. El valor será igual amulti-dimensionalsi se utilizó la clave de clasificación de diseño de datos multidimensionales de la tabla durante el escaneo.
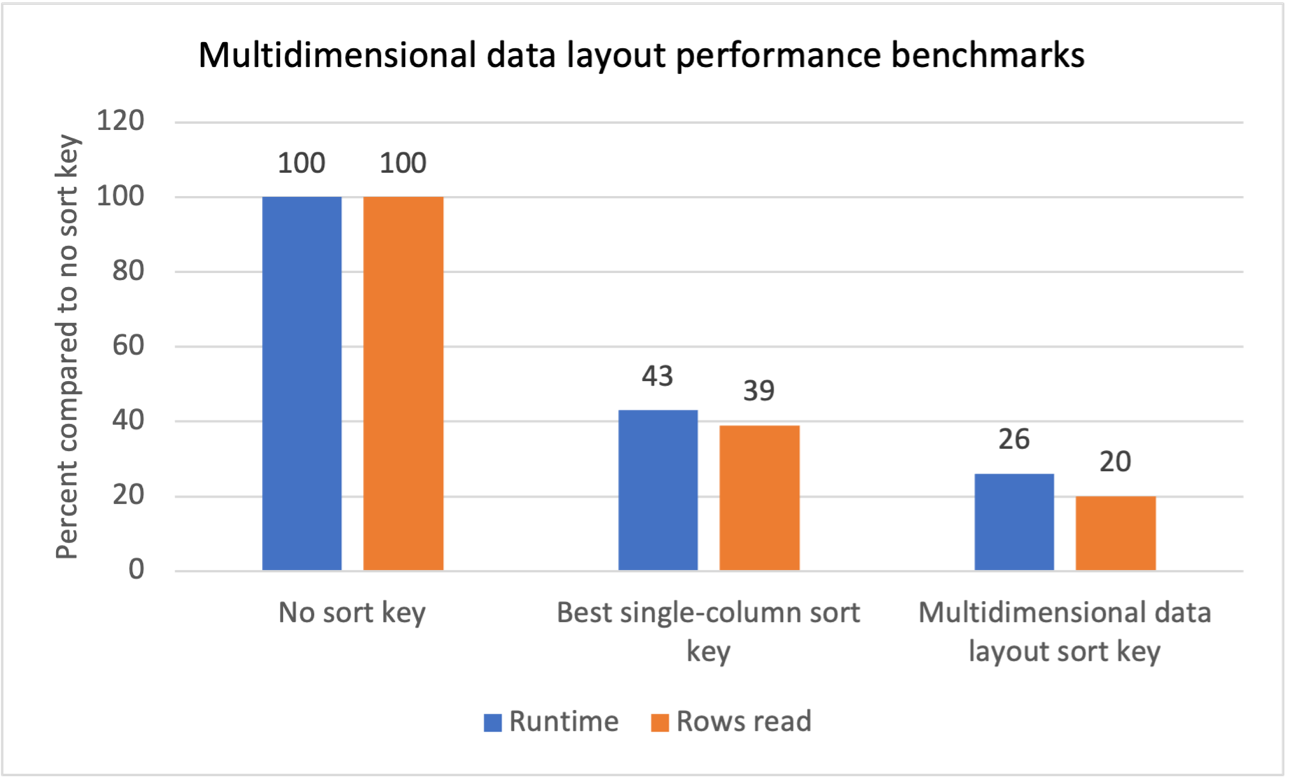
Benchmarks de desempeño
Realizamos pruebas comparativas internas para múltiples cargas de trabajo con filtros de escaneo repetitivos y vimos que la introducción de claves de clasificación de diseño de datos multidimensionales produjo los siguientes resultados:
- Una reducción total del tiempo de ejecución del 74 % en comparación con no tener una clave de clasificación.
- Una reducción total del tiempo de ejecución del 40 % en comparación con tener la mejor clave de clasificación de una sola columna en cada tabla.
- Una reducción del 80 % en el total de filas leídas de las tablas en comparación con no tener una clave de clasificación.
- Una reducción del 47 % en el total de filas leídas de las tablas en comparación con tener la mejor clave de clasificación de una sola columna en cada tabla.
Comparación de características
Con la introducción de claves de clasificación de diseño de datos multidimensionales, sus tablas ahora se pueden ordenar por expresiones basadas en los predicados de filtro que ocurren comúnmente en su carga de trabajo. La siguiente tabla proporciona una comparación de funciones de Amazon Redshift con dos competidores.
| Feature | Desplazamiento al rojo de Amazon | Competidor A | Competidor B |
| Soporte para ordenar en columnas. | Sí | Sí | Sí |
| Soporte para ordenar por expresión. | Sí | Sí | No |
| Selección automática de columnas para ordenar | Sí | No | Sí |
| Selección automática de expresiones para ordenar. | Sí | No | No |
| Selección automática entre ordenación de columnas o ordenación de expresiones. | Sí | No | No |
| Uso automático de propiedades de clasificación para expresiones durante los escaneos | Sí | No | No |
Consideraciones
Tenga en cuenta lo siguiente cuando utilice un diseño de datos multidimensional:
- El diseño de datos multidimensionales se habilita cuando configura su tabla como SORTKEY AUTO.
- Amazon Redshift Advisor elegirá automáticamente una clave de clasificación de una sola columna o un diseño de datos multidimensional para la tabla al analizar su carga de trabajo histórica.
- Amazon Redshift ATO ajusta los resultados de clasificación del diseño de datos multidimensionales en función de la forma en que las consultas en curso interactúan con la carga de trabajo.
- Amazon Redshift ATO mantiene claves de clasificación de diseño de datos multidimensionales de la misma manera que lo hace actualmente para las claves de clasificación existentes. Referirse a Trabajar con optimización automática de tablas para más detalles sobre ATO.
- Las claves de clasificación de diseño de datos multidimensionales funcionarán tanto con clústeres aprovisionados como con grupos de trabajo sin servidor.
- Las claves de clasificación de diseño de datos multidimensionales funcionarán con sus datos existentes siempre que AUTO SORTKEY esté habilitado en su tabla y se detecte una carga de trabajo con filtros de escaneo repetitivos. La tabla se reorganizará según los resultados de la función de clasificación multidimensional.
- Para deshabilitar las claves de clasificación de diseño de datos multidimensionales para una tabla, use alterar tabla:
ALTER TABLE table_name ALTER SORTKEY NONE. Esto desactiva la función de clave de clasificación AUTOMÁTICA en la mesa. - Las claves de clasificación de diseño de datos multidimensionales se conservan al restaurar o migrar su clúster aprovisionado a un clúster sin servidor o viceversa.
Conclusión
En esta publicación, mostramos que las claves de clasificación de diseño de datos multidimensionales pueden mejorar significativamente el rendimiento del tiempo de ejecución de consultas para cargas de trabajo donde las consultas dominantes tienen filtros de escaneo repetitivos.
Para crear un clúster de vista previa desde la consola de Amazon Redshift, navegue hasta el Clusters página y elige Crear clúster de vista previa. Puede crear un clúster en las regiones EE.UU. Este (Ohio), EE.UU. Este (Norte de Virginia), EE.UU. Oeste (Oregón), Asia Pacífico (Tokio), Europa (Irlanda) y Europa (Estocolmo) y probar sus cargas de trabajo.
Nos encantaría escuchar sus comentarios sobre esta nueva función y esperamos sus comentarios sobre esta publicación.
Sobre los autores
 Milind Oke es un arquitecto de soluciones especializado en almacenamiento de datos con sede en Nueva York. Ha estado creando soluciones de almacenamiento de datos durante más de 15 años y se especializa en Amazon Redshift.
Milind Oke es un arquitecto de soluciones especializado en almacenamiento de datos con sede en Nueva York. Ha estado creando soluciones de almacenamiento de datos durante más de 15 años y se especializa en Amazon Redshift.
 jialin ding Es científico aplicado en Learned Systems Group, y se especializa en aplicar técnicas de optimización y aprendizaje automático para mejorar el rendimiento de sistemas de datos como Amazon Redshift.
jialin ding Es científico aplicado en Learned Systems Group, y se especializa en aplicar técnicas de optimización y aprendizaje automático para mejorar el rendimiento de sistemas de datos como Amazon Redshift.
 Yanzhu-ji es gerente de producto en el equipo de Amazon Redshift. Tiene experiencia en visión y estrategia de productos en plataformas y productos de datos líderes en la industria. Tiene una habilidad sobresaliente en la creación de productos de software sustanciales utilizando técnicas de desarrollo web, diseño de sistemas, bases de datos y programación distribuida. En su vida personal, a Yanzhu le gusta pintar, fotografiar y jugar al tenis.
Yanzhu-ji es gerente de producto en el equipo de Amazon Redshift. Tiene experiencia en visión y estrategia de productos en plataformas y productos de datos líderes en la industria. Tiene una habilidad sobresaliente en la creación de productos de software sustanciales utilizando técnicas de desarrollo web, diseño de sistemas, bases de datos y programación distribuida. En su vida personal, a Yanzhu le gusta pintar, fotografiar y jugar al tenis.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- :posee
- :es
- :no
- :dónde
- 1
- 100
- 15 años
- 15%
- 152
- 7
- 8
- 9
- a
- acelerar
- visitada
- Adicionales
- tutor
- Después
- en contra
- algoritmo
- Todos
- ya haya utilizado
- Amazon
- Amazon Web Services
- an
- analizar
- el análisis de
- y
- Otra
- aplicada
- La aplicación de
- somos
- AS
- Asia
- asia pacifico
- auto
- Automático
- automáticamente
- Hoy Disponibles
- AWS
- basado
- BE
- porque
- esto
- es el beneficio
- MEJOR
- mejores
- entre
- Bloquear
- Bloques
- Azul
- ambas
- Construir la
- pero
- by
- PUEDEN
- capacidad
- comprobar
- Elige
- Soluciones
- Médico
- Columna
- Columnas
- combinación
- comentarios
- comúnmente
- en comparación con
- comparación
- competidores
- integraciones
- concepto
- Considerar
- consiste
- Consola
- construir
- contiene
- Cost
- cubre suministros para
- Para crear
- En la actualidad
- datos
- almacenamiento de datos
- Base de datos
- decidir
- a dedicados
- definir
- Demanda
- exigente
- Diseño
- detalles
- detectado
- Determinar
- Desarrollo
- distribuidos
- sí
- dominante
- No
- durante
- cada una
- Este
- ya sea
- facilita
- Todo
- igual
- especialmente
- Éter (ETH)
- Europa
- evaluación
- Incluso
- evolucionado
- ejemplo
- existente
- experience
- expresiones
- Feature
- realimentación
- filtrar
- filtros
- siguiendo
- siguiente
- adelante
- Digital XNUMXk
- Desde
- función
- Grupo procesos
- mano
- Tienen
- es
- he
- oír
- aquí
- histórico
- historia
- Sin embargo
- HTML
- HTTPS
- ID
- if
- inmediatamente
- mejorar
- mejora
- in
- incluye
- INSTRUMENTO individual
- líderes en la industria
- interactuar
- interno
- intervención
- dentro
- introducir
- Presentamos
- Introducción
- Irlanda
- IT
- artículos
- Clave
- claves
- large
- Disposición
- aprendido
- aprendizaje
- Vida
- como
- Me gusta
- Largo
- Mira
- parece
- amar
- máquina
- máquina de aprendizaje
- mantiene
- gerente
- manera
- máximas
- Conoce a
- metadatos
- podría
- migrar
- mente
- mínimo
- más,
- MEJOR DE TU
- múltiples
- Navegar
- ¿ Necesita ayuda
- Nuevo
- nueva función
- New York
- no
- ahora
- números
- ocurriendo
- of
- off
- Ofrecido
- Ohio
- on
- ONE
- en marcha
- , solamente
- operadores
- optimización
- Optimiza
- Optión
- or
- solicite
- Oregón
- reconocida por
- Otro
- salir
- excepcional
- Más de
- Costa
- pintura
- parte
- particular
- Patrón de Costura
- actuación
- realizado
- con
- fotografía
- los libros físicos
- Plataformas
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- jugando
- Publicación
- poderoso
- en conserva
- Vista previa
- producido
- Producto
- gerente de producto
- Productos
- Programación
- propiedades
- proporciona un
- consultas
- rápidamente
- Leer
- reducción
- remitir
- región
- regiones
- repetitivo
- Requisitos
- restauración
- resultado
- Resultados
- Ejecutar
- correr
- corre
- mismo
- escanear
- exploración
- escanea
- Científico
- Temporada
- ver
- selecciona
- seleccionado
- selección
- Sin servidor
- Servicios
- set
- ella
- Mostrar
- mostrar
- mostró
- mostrado
- Shows
- significativamente
- soltero
- habilidad
- So
- Software
- Soluciones
- especialista
- se especializa
- especializada
- tiendas
- Estrategia
- Después
- sustancial
- tal
- adecuado
- Apoyar
- te
- Todas las funciones a su disposición
- mesa
- ¡Prepárate!
- equipo
- técnicas
- tenis
- test
- Pruebas
- que
- esa
- La
- su
- por lo tanto
- ellos
- así
- equipo
- títulos
- a
- Tokio
- parte superior
- Total
- tradicional
- dos
- tipo
- típicamente
- us
- utilizan el
- usado
- Usuario
- usuarios
- usos
- usando
- propuesta de
- Valores
- vicio
- Ver
- Virginia
- visión
- Manejo de
- fue
- Camino..
- we
- web
- Desarrollo web
- servicios web
- West
- cuando
- sean
- que
- extensamente
- seguirá
- sin
- Actividades:
- se
- años
- york
- Usted
- tú
- zephyrnet