Introducción
la amalgama de inteligencia artificial (IA) y el arte abren nuevas vías en el arte digital creativo, principalmente a través de modelos de difusión. Estos modelos se destacan en la generación de arte creativo de IA y ofrecen un enfoque distinto al de las redes neuronales convencionales. Este artículo lo lleva en un viaje de exploración a las profundidades de los modelos de difusión, aclarando su mecanismo único para crear obras de arte visualmente impresionantes y creativamente ricas. Comprenda los matices de los modelos de difusión y obtenga información sobre su papel en la redefinición de la expresión artística a través de la lente de tecnologías avanzadas de inteligencia artificial.

OBJETIVOS DE APRENDIZAJE
- Comprender los conceptos fundamentales de los modelos de difusión en IA.
- Explore la distinción entre modelos de difusión y redes neuronales tradicionales en la generación de arte.
- Analizar el proceso de creación de arte utilizando modelos de difusión.
- Evaluar las implicaciones creativas y estéticas de la IA en el arte digital.
- Analice las consideraciones éticas en las obras de arte generadas por IA.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Comprender los modelos de difusión

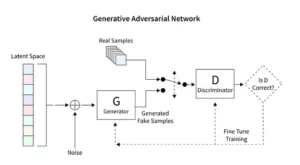
Los modelos de difusión revolucionan la IA generativa al presentar un método de creación de imágenes único, distinto de las técnicas convencionales como las redes generativas adversarias (GAN). Comenzando con ruido aleatorio, estos modelos lo refinan progresivamente, asemejándose a un artista afinando una pintura, dando como resultado imágenes intrincadas y coherentes.
Este proceso de refinamiento incremental refleja la naturaleza metódica de la difusión. Aquí, cada iteración altera sutilmente el ruido, acercándolo a la visión artística final. El resultado no es simplemente un producto del azar sino una obra de arte evolucionada, distinta en su progresión y acabado.
La codificación de modelos de difusión exige un conocimiento profundo de las redes neuronales y los marcos de aprendizaje automático como TensorFlow o PyTorch. El código resultante es complejo y requiere una capacitación exhaustiva en conjuntos de datos expansivos para lograr los efectos matizados observados en el arte generado por IA.
Aplicación de la difusión estable en el arte
La llegada de generadores artísticos de IA, como modelos de difusión estable, requiere una codificación sofisticada dentro de plataformas como TensorFlow o PyTorch. Estos modelos destacan por su capacidad para transformar metódicamente la aleatoriedad en estructura, muy parecido a un artista que perfecciona un boceto preliminar hasta convertirlo en una vívida obra maestra.
Los modelos de difusión estable remodelan la escena artística de la IA al esculpir imágenes ordenadas a partir de la aleatoriedad, evitando la dinámica competitiva característica de las GAN. Se destacan en la interpretación de indicaciones conceptuales en arte visual, fomentando una danza sinérgica entre las capacidades de la IA y el ingenio humano. Al aprovechar PyTorch, observamos cómo estos modelos refinan iterativamente el caos hasta convertirlo en claridad, reflejando el viaje del artista desde una idea incipiente hasta una creación pulida.
Experimentar con arte generado por IA
Esta demostración profundiza en el fascinante mundo del arte generado por IA utilizando una red neuronal convolucional llamada Modelo de difusión de conv. Este modelo está entrenado en diversas imágenes artísticas, que abarcan dibujos, pinturas, esculturas y grabados, procedentes de este conjunto de datos de Kaggle. Nuestro objetivo es explorar la capacidad del modelo para capturar y reproducir la estética compleja de estas obras de arte.
Arquitectura y formación de modelos
Diseño arquitectonico
ConvDiffusionModel, en esencia, es una maravilla de la ingeniería neuronal, que presenta una sofisticada arquitectura de codificador-decodificador adaptada a las demandas de la generación de arte. La estructura del modelo es una red neuronal compleja que integra mecanismos codificadores-decodificadores refinados específicamente perfeccionados para la generación de arte. Con capas convolucionales adicionales y conexiones de salto que emulan la intuición artística, el modelo puede diseccionar y volver a ensamblar arte con una comprensión astuta de la composición y el estilo.
- Encoder: El codificador es el ojo analítico del modelo, que examina los detalles minuciosos de cada imagen de entrada. A medida que las imágenes pasan a través de las capas convolucionales del codificador, se comprimen progresivamente en un espacio latente: una representación compacta y codificada de la obra de arte original. Nuestro codificador no solo analiza las imágenes de entrada, sino que ahora lo hace con una profundidad de percepción aumentada, cortesía de capas adicionales y técnicas de normalización por lotes. Este examen extendido permite una representación más rica y condensada dentro del espacio latente, reflejando la profunda contemplación de un artista sobre un tema.
- Descifrador: Por el contrario, el decodificador actúa como la mano creativa del modelo, tomando los bocetos abstractos del codificador y dándoles vida. Reconstruye la obra de arte desde el espacio latente, capa por capa, detalle por detalle, hasta que emerge una imagen completa. Nuestro decodificador se beneficia de las conexiones de salto y puede reconstruir obras de arte con mayor precisión. Revisa la esencia abstracta de la entrada y la embellece progresivamente, logrando una interpretación más fiel al material original. Las capas mejoradas funcionan en conjunto para garantizar que la imagen final sea una pieza vívida e intrincada que refleje el arte de la entrada.
Proceso de entrenamiento
La formación del ConvDiffusionModel es un viaje a través de un paisaje artístico que abarca 150 épocas. Cada época representa un recorrido completo por todo el conjunto de datos, y el modelo se esfuerza por refinar su comprensión y mejorar la fidelidad de las imágenes generadas.
- Función de pérdida híbrida: En el centro del entrenamiento se encuentra la función de pérdida del error cuadrático medio (MSE). Esta función cuantifica la diferencia entre la obra maestra original y la recreación del modelo, proporcionando una métrica clara para minimizar. Introduciremos un componente de pérdida de percepción derivado de una red VGG previamente entrenada que complementa la métrica del error cuadrático medio (MSE). Esta estrategia de doble pérdida impulsa al modelo a honrar la integridad artística de los originales mientras perfecciona la reproducción técnica de sus detalles.
- Optimizador: Con su tasa de aprendizaje ajustada dinámicamente por un programador, el optimizador Adam guía el aprendizaje del modelo con mayor sagacidad. Este enfoque adaptativo garantiza que el progreso del modelo en el aprendizaje de replicar e innovar el arte sea constante y sólido.
- Iteración y refinamiento: Las iteraciones de entrenamiento son una danza entre la preservación de la esencia artística y la búsqueda de la replicación técnica. Con cada ciclo, el modelo se acerca más a una síntesis de fidelidad y creatividad.
- Visualización del progreso: las imágenes se guardan a intervalos regulares durante el entrenamiento para visualizar el progreso del modelo.. Estas instantáneas ofrecen una ventana a la curva de aprendizaje del modelo, mostrando cómo evoluciona el arte generado, volviéndose más claro, más detallado y más coherente artísticamente con cada época.



Lo anterior se demuestra a través del siguiente código:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from torchvision.models import vgg16
from PIL import Image
# Defining a function to check for valid images
def is_valid_image(image_path):
try:
with Image.open(image_path) as img:
img.verify()
return True
except (IOError, SyntaxError) as e:
# Printing out the names of all corrupt files
print(f'Bad file:', image_path)
return False
# Defining the neural network
class ConvDiffusionModel(nn.Module):
def __init__(self):
super(ConvDiffusionModel, self).__init__()
# Encoder
self.enc1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc2 = nn.Sequential(nn.Conv2d(64, 128,
kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3,
padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2,
stride=2))
# Decoder
self.dec1 = nn.Sequential(nn.ConvTranspose2d(256, 128,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(128))
self.dec2 = nn.Sequential(nn.ConvTranspose2d(128, 64,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(64))
self.dec3 = nn.Sequential(nn.ConvTranspose2d(64, 3,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid())
def forward(self, x):
# Encoder
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
# Decoder with skip connections
dec1 = self.dec1(enc3) + enc2
dec2 = self.dec2(dec1) + enc1
dec3 = self.dec3(dec2)
return dec3
# Using a pre-trained VGG16 model to compute perceptual loss
class VGGLoss(nn.Module):
def __init__(self):
super(VGGLoss, self).__init__()
self.vgg = vgg16(pretrained=True).features[:16].cuda()
.eval() # Only the first 16 layers
for param in self.vgg.parameters():
param.requires_grad = False
def forward(self, input, target):
input_vgg = self.vgg(input)
target_vgg = self.vgg(target)
loss = torch.nn.functional.mse_loss(input_vgg,
target_vgg)
return loss
# Checking if CUDA is available and set device to GPU if it is.
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
# Initializing the model and perceptual loss
model = ConvDiffusionModel().to(device)
vgg_loss = VGGLoss().to(device)
mse_loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30,
gamma=0.1)
# Dataset and DataLoader setup
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(root='/content/Images',
transform=transform, is_valid_file=is_valid_image)
dataloader = DataLoader(dataset, batch_size=32,
shuffle=True)
# Training loop
num_epochs = 150
for epoch in range(num_epochs):
for i, (inputs, _) in enumerate(dataloader):
inputs = inputs.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
# Calculate losses
mse = mse_loss(outputs, inputs)
perceptual = vgg_loss(outputs, inputs)
loss = mse + perceptual
# Backward pass and optimize
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}],
Step [{i+1}/{len(dataloader)}], Loss: {loss.item()},
Perceptual Loss: {perceptual.item()}, MSE Loss:
{mse.item()}')
# Saving the generated image for visualization
save_image(outputs, f'output_epoch_{epoch+1}
_step_{i+1}.png')
# Updating the learning rate
scheduler.step()
# Saving model checkpoints
if (epoch + 1) % 10 == 0:
torch.save(model.state_dict(),
f'/content/model_epoch_{epoch+1}.pth')
print('Training Complete')
Visualizando la obra de arte generada
Manifestando el arte creado por la IA
Con ConvDiffusionModel ahora completamente entrenado, el enfoque cambia de lo abstracto a lo concreto, del potencial a la actualización del arte creado por IA. El siguiente fragmento de código materializa las capacidades artísticas aprendidas del modelo, transformando los datos de entrada en un lienzo digital de expresión.
import os
import matplotlib.pyplot as plt
# Loading the trained model
model = ConvDiffusionModel().to(device)
model.load_state_dict(torch.load('/content/model_epoch_150.pth'))
model.eval() # Set the model to evaluation mode
# Transforming for the input image
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Function to de-normalize the image for viewing
def denormalize(tensor):
mean = torch.tensor([0.485, 0.456, 0.406]).
to(device).view(-1, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).
to(device).view(-1, 1, 1)
tensor = tensor * std + mean # De-normalize
tensor = tensor.clamp(0, 1) # Clamp to the valid image range
return tensor
# Loading and transforming the image
input_image_path = '/content/Validation/0006.jpg'
input_image = Image.open(input_image_path).convert('RGB')
input_tensor = transform(input_image).unsqueeze(0).to(device)
# Adding a batch dimension
# Generating the image
with torch.no_grad():
generated_tensor = model(input_tensor)
# Converting the generated image tensor to an image
generated_image = denormalize(generated_tensor.squeeze(0))
# Removing the batch dimension and de-normalizing
generated_image = generated_image.cpu() # Move to CPU
# Saving the generated image
save_image(generated_image, '/content/generated_image.png')
print("Generated image saved to '/content/generated_image.png'")
# Displaying the generated image using matplotlib
plt.figure(figsize=(8, 8))
plt.imshow(generated_image.permute(1, 2, 0))
# Rearrange the channels for plotting
plt.axis('off') # Hide the axes
plt.show()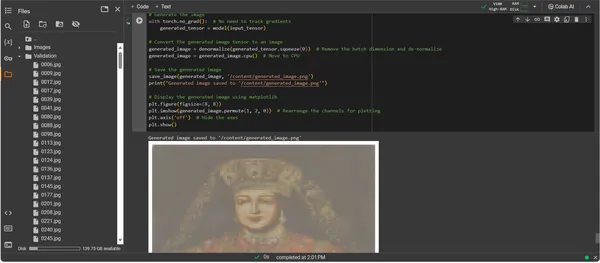

Tutorial del código de generación de ilustraciones
- Modelo de resurrección: El primer paso en la generación de obras de arte es revivir nuestro ConvDiffusionModel entrenado. Los pesos aprendidos del modelo se cargan y se ponen en modo de evaluación, preparando el escenario para la creación sin alterar más sus parámetros.
- Transformación de imagen: Para garantizar la coherencia con el régimen de entrenamiento, las imágenes de entrada se procesan mediante la misma secuencia de transformaciones. Esto incluye cambiar el tamaño para que coincida con las dimensiones de entrada del modelo, conversión de tensor para compatibilidad con PyTorch y normalización basada en el perfil estadístico de los datos de entrenamiento.
- Utilidad de desnormalización: Una función personalizada invierte los efectos de preprocesamiento y reescala el tensor al rango de color de la imagen original. Este paso es esencial para convertir el resultado generado en una representación visualmente precisa.
- Preparación de entrada: Se carga una imagen y se somete a las transformaciones antes mencionadas. Es crucial tener en cuenta que esta imagen sirve como musa en la que se inspirará la IA: el susurro silencioso enciende la imaginación sintética del modelo.
- Síntesis de la obra de arte: En una delicada danza de propagación hacia adelante, el modelo interpreta el tensor de entrada, permitiendo que sus capas colaboren en la producción de una nueva visión artística. Realice este proceso sin seguir los gradientes, ya que ahora estamos en el ámbito de la aplicación, no del entrenamiento.
- Conversión de imágenes: La salida tensor del modelo, que ahora contiene la obra de arte nacida digitalmente, se desnormaliza, traduciendo la creación del modelo nuevamente al espacio familiar de color y luz que nuestros ojos pueden apreciar.
- Revelación de la obra de arte: El tensor transformado se coloca en un lienzo digital y culmina en un archivo de imagen guardado. Este archivo es una ventana al alma creativa de la IA, un eco estático del proceso dinámico que le dio vida.
- Recuperación de obras de arte: El script concluye guardando la imagen generada en una ruta designada y anunciando su finalización. La imagen guardada, una síntesis de principios artísticos aprendidos y creatividad emergente, está lista para ser exhibida y contemplada.
Analizando la salida
El resultado de ConvDiffusionModel presenta una figura con un claro guiño al arte histórico. Envuelta en un atuendo elaborado, la imagen renderizada por IA hace eco de la grandeza de los retratos clásicos pero con un toque distintivo y moderno. El atuendo del modelo es rico en textura y combina los patrones aprendidos del modelo con una interpretación novedosa. Los delicados rasgos faciales y una sutil interacción de luces y sombras muestran la comprensión matizada de la IA de las técnicas artísticas tradicionales. Esta obra de arte es un testimonio del sofisticado entrenamiento del modelo y refleja una elegante síntesis del arte histórico a través del prisma del aprendizaje automático avanzado. En esencia, es un homenaje digital al pasado, elaborado con los algoritmos del presente.
Desafíos y consideraciones éticas
Implementar modelos de difusión para la generación de arte trae consigo varios desafíos y consideraciones éticas que debes considerar:
- Procedencia de los datos: Los conjuntos de datos de capacitación deben curarse de manera responsable. Es esencial verificar que los datos utilizados para entrenar modelos de difusión no contengan obras protegidas o con derechos de autor sin la autorización adecuada.
- Sesgo y representación: Los modelos de IA pueden perpetuar sesgos en sus datos de entrenamiento. Garantizar conjuntos de datos diversos e inclusivos es importante para evitar reforzar los estereotipos en el arte generado por IA.
- Control sobre la salida: Dado que los modelos de difusión pueden generar una amplia gama de resultados, es necesario establecer límites para evitar la creación de contenido inapropiado u ofensivo.
- Marco legal: La falta de un marco legal sólido para abordar los matices de la IA en el proceso creativo presenta un desafío. La legislación debe evolucionar para proteger los derechos de todas las partes involucradas.
Conclusión
El auge de los modelos de difusión en la inteligencia artificial y el arte marca una era transformadora, que fusiona la precisión computacional con la exploración estética. Su viaje en el mundo del arte destaca un importante potencial de innovación, pero conlleva complejidades. Equilibrar la originalidad, la influencia, la creación ética y el respeto por las obras existentes es parte integral del proceso artístico.
Puntos clave
- Los modelos de difusión están a la vanguardia de un cambio transformador en la creación artística. Ofrecen nuevas herramientas digitales que amplían el lienzo de expresión artística más allá de los límites tradicionales.
- En el arte mejorado por la IA, priorizar la recopilación ética de datos de entrenamiento y respetar la propiedad intelectual de los creadores es imperativo para mantener la integridad en el arte digital.
- La convergencia de la visión artística y la innovación tecnológica abre las puertas a una relación simbiótica entre artistas y desarrolladores de IA. Fomentar un entorno colaborativo que pueda dar lugar a arte innovador.
- Es vital garantizar que el arte generado por IA represente un amplio espectro de perspectivas. Incorporar una gama variada de datos que refleje la riqueza de diferentes culturas y puntos de vista, promoviendo así la inclusión.
- El creciente interés en el arte creado con inteligencia artificial requiere el establecimiento de marcos legales sólidos. Estos marcos deberían aclarar las cuestiones de derechos de autor, reconocer las contribuciones y regular el uso comercial de las obras de arte generadas por IA.
Los albores de esta evolución artística ofrecen un camino repleto de potencial creativo, pero que requiere una vigilancia cuidadosa. Nos corresponde a nosotros cultivar un paisaje donde prospere la fusión de la IA y el arte, guiados por prácticas responsables y culturalmente sensibles.
Preguntas frecuentes
R. Los modelos de difusión son algoritmos de aprendizaje automático generativo que crean imágenes comenzando con un patrón de ruido aleatorio y dándole forma gradualmente en una imagen coherente. Este proceso es similar a un artista que comienza con un lienzo en blanco y agrega lentamente capas de detalles.
R. Los modelos de difusión GAN no requieren una red separada para juzgar la salida. Funcionan añadiendo y eliminando ruido de forma iterativa, lo que a menudo da como resultado imágenes más detalladas y matizadas.
R. Sí, los modelos de difusión pueden generar obras de arte originales aprendiendo de un conjunto de datos de imágenes. Sin embargo, la originalidad está influenciada por la diversidad y el alcance de los datos de entrenamiento. Existe un debate en curso sobre la ética de utilizar obras de arte existentes para entrenar estos modelos.
R. Las preocupaciones éticas abarcan evitar la infracción de los derechos de autor del arte generado por IA. Respetar la originalidad de los artistas humanos, evitar la perpetuación de prejuicios y garantizar la transparencia en el proceso creativo de la IA.
R. El futuro del arte generado por IA parece prometedor, con modelos de difusión que ofrecen nuevas herramientas para artistas y creadores. Podemos esperar ver obras de arte más sofisticadas e intrincadas a medida que avanza la tecnología. Sin embargo, la comunidad creativa debe navegar por consideraciones éticas y trabajar hacia pautas claras y mejores prácticas.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/12/implementing-diffusion-models-for-creative-ai-art-generation/
- :es
- :no
- :dónde
- 001
- 1
- 10
- 100
- 11
- 12
- 15%
- 150
- 16
- 19
- 224
- 225
- 8
- 9
- a
- capacidad
- Nuestra Empresa
- arriba
- RESUMEN
- preciso
- Lograr
- el logro de
- Adam
- adaptado
- la adición de
- Adicionales
- dirección
- Equilibrado
- avanzado
- avances
- adviento
- adversario
- AI
- arte ai
- parecido
- algoritmos
- Todos
- Permitir
- permite
- an
- Pruebas analíticas
- Analytics
- Analítica Vidhya
- y
- Anunciando
- Aplicación
- apreciar
- enfoque
- arquitectura
- somos
- Arte
- artículo
- artista
- artístico
- artísticamente
- arte
- Artistas
- obras de arte
- obras de arte
- AS
- At
- aumentado
- autorización
- Hoy Disponibles
- avenidas
- evitar
- evitar
- EJES
- Atrás
- Malo
- equilibrio
- basado
- BE
- cada vez
- beneficios
- MEJOR
- y las mejores prácticas
- entre
- Más allá de
- parcialidad
- los prejuicios
- en blanco
- mezcla
- blogatón
- nacido
- ambas
- límites
- respiración
- rebosante
- Trae
- general
- Traído
- floreciendo
- pero
- by
- calcular
- , que son
- PUEDEN
- lienzo
- capacidades
- capacidad
- capturar
- Reto
- retos
- canales
- Chaos
- característica
- comprobar
- comprobación
- abrazadera
- transparencia
- clase
- limpiar
- más clara
- más cerca
- código
- Codificación
- COHERENTE
- colaboran
- colaboración
- Color
- proviene
- completo
- vibrante e inclusiva
- compacto
- compatibilidad
- competitivos
- completar
- terminación
- integraciones
- complejidades
- componente
- composición
- computational
- Calcular
- conceptos
- conceptual
- Inquietudes
- octubre
- concluye
- Conexiones
- Considerar
- consideraciones
- que no contengo
- contenido
- contraste
- contribuciones
- convencional
- Convergencia
- Conversión
- la conversión de
- red neuronal convolucional
- derechos de autor,
- infracción de derechos de autor
- Core
- corrupto
- CPU
- Elaborado
- Para crear
- Creamos
- creación
- Estudio
- Creativamente
- creatividad
- creadores
- crucial
- culminante
- Cultivar
- culturalmente
- comisariada
- curva
- personalizado
- Cycle
- danza
- datos
- conjuntos de datos
- debate
- profundo
- definir
- demandas
- demostrado
- profundidad
- Profundidades
- Derivado
- designada
- detalle
- detallado
- detalles
- desarrolladores
- dispositivo
- diferir de
- un cambio
- una experiencia diferente
- Difusión
- digital
- arte digital
- digitalmente
- Dimensiones
- dimensiones
- discreción
- Pantalla
- mostrar
- distinto
- distinción
- diverso
- Diversidad
- do
- sí
- puertas
- dibujar
- Dibujos
- durante
- lugar de trabajo dinámico
- dinamicamente
- dinámica
- e
- cada una
- echo
- ecos
- los efectos
- Elaborar
- más
- emerge
- codificado
- abarcar
- que abarca
- Ingeniería
- mejorado
- garantizar
- asegura
- asegurando que
- Todo
- Entorno
- época
- épocas
- Era
- error
- esencia
- esencial
- establecimiento
- Éter (ETH)
- ético
- ética
- evaluación
- Cada
- evolución
- evoluciona
- evolucionado
- evoluciona
- examen
- Excel
- Excepto
- existente
- Expandir
- expansivo
- esperar
- exploración
- explorar
- expresión
- extendido
- en los detalles
- ojos
- Ojos
- facial
- fiel
- false
- familiar
- fascinante
- Caracteristicas
- Con la participación de:
- fidelidad
- Figura
- Archive
- archivos
- final
- acabado
- Nombre
- Focus
- siguiendo
- primer plano
- adelante
- Cuidados de acogida
- el fomento de
- Marco conceptual
- marcos
- Desde
- completamente
- función
- funcional
- fundamental
- promover
- fusión
- futuras
- Obtén
- GAN
- reunión
- dio
- generar
- generado
- la generación de
- generación de AHSS
- generativo
- redes adversas generativas
- IA generativa
- generadores
- Donar
- objetivo
- GPU
- gradientes
- gradualmente
- grandeza
- agarrar
- mayor
- innovador
- guiado
- orientaciones
- Guías
- mano
- Aprovechamiento
- Corazón
- esta página
- Esconder
- destacados
- histórico
- tenencia
- homenaje
- honor
- Cómo
- Sin embargo
- HTTPS
- humana
- i
- idea
- if
- enciende
- imagen
- imágenes
- imaginación
- INDISPENSABLE
- implementación
- implicaciones
- importar
- importante
- mejorar
- in
- incluye
- INTEGRAL
- Inclusividad
- incorporar
- aumentado
- incrementales
- Titular
- influir
- influenciado
- infracción
- ingenio
- innovar
- Innovation
- Las opciones de entrada
- entradas
- penetración
- un elemento indispensable
- Integración
- integridad
- propiedad
- la propiedad intelectual
- intereses
- Automática
- dentro
- intrincado
- introducir
- intuición
- involucra
- cuestiones
- IT
- iteración
- iteraciones
- SUS
- jpg
- juez
- Falta
- paisaje
- .
- ponedoras
- aprendido
- aprendizaje
- Legal
- marco legal
- Legislación
- Lente
- se encuentra
- Vida
- luz
- como
- carga
- MIRADAS
- de
- pérdidas
- máquina
- máquina de aprendizaje
- mantener
- maravilla
- obra maestra
- Match
- materiales
- matplotlib
- personalizado
- mecanismo
- los mecanismos de
- Medios
- simplemente
- la fusión de
- Método
- metódico
- métrico
- minimizar
- minuto
- reflejando
- ML
- Algoritmos ML
- Moda
- modelo
- modelos
- Moderno
- módulo
- más,
- movimiento
- mucho más
- MUSE
- debe
- nombres
- naciente
- Naturaleza
- Navegar
- necesario
- del sistema,
- telecomunicaciones
- Neural
- ingeniería neuronal
- red neural
- redes neuronales
- Nuevo
- ruido
- nota
- novela
- ahora
- matices
- observar
- observado
- of
- off
- ofensiva
- LANZAMIENTO
- que ofrece
- Ofertas
- a menudo
- on
- en marcha
- , solamente
- abre
- Optimización
- or
- reconocida por
- originalidad
- Originales
- OS
- Otro
- "nuestr
- salir
- salida
- salidas
- Más de
- propiedad
- pintura
- pinturas
- parámetro
- parámetros
- parte
- partes
- pass
- pasado
- camino
- Patrón de Costura
- .
- percepción
- perfeccionamiento
- realizar
- perspectivas
- imagen
- pieza
- piezas
- Plataformas
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- retratos
- posible
- prácticas
- Precisión
- preliminar
- presente
- regalos
- conservación
- evitar
- la prevención
- principios
- impresión
- priorización
- procesado
- productor
- Producto
- Mi Perfil
- un profundo
- Progreso
- progresión
- progresivamente
- prometedor
- Promoción
- ideas
- propagación
- apropiado
- perfecta
- proteger
- protegido
- procedencia
- proporcionando
- publicado
- perseguir
- piñón
- cuantifica
- azar
- aleatoriedad
- distancia
- Rate
- ready
- reino
- reconocer
- Redefiniendo
- FILTRO
- refinado
- reflejando
- refleja
- régimen
- regular
- relación
- la eliminación de
- representación
- replicación
- representación
- representa
- reproducción
- exigir
- requiere
- parecido a
- remodelar
- respeto
- respecto a
- responsable
- responsablemente
- resultante
- volvemos
- revelación
- Revive
- revolucionar
- RGB
- Rico
- derechos
- Subir
- robusto
- Función
- mismo
- salvado
- ahorro
- escena
- Ciencia:
- alcance
- guión
- ver
- AUTO
- sensible
- separado
- Secuencia
- sirve
- set
- pólipo
- Configure
- Varios
- Shadow
- la formación
- Turno
- Turnos
- tienes
- mostrar
- Demostramos a usted
- mostrado
- importante
- desde
- Despacio
- retazo
- So
- sofisticado
- Soul
- Fuente
- originario
- Espacio
- abarcando
- específicamente
- Spectrum
- Squared
- estable
- Etapa
- stand
- Comience a
- estadístico
- estable
- paso
- Estrategia
- esforzarse
- estructura
- Maravillosos
- papa
- sujeto
- posterior
- tal
- Simbiótico
- sinérgico
- síntesis
- sintético
- adaptado
- toma
- toma
- Target
- Técnico
- técnicas
- tecnológico
- Tecnologías
- Tecnología
- tensorflow
- testamento
- esa
- La
- El futuro de las
- La Fuente
- su
- Les
- Ahí.
- Estas
- ellos
- así
- prospera
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- Así
- a
- antorcha
- visión de antorcha
- contacto
- hacia
- Seguimiento
- tradicional
- Entrenar
- entrenado
- Formación
- Transformar
- transformaciones
- transformador
- transformado
- transformadora
- transformadas
- Transparencia
- verdadero
- try
- entender
- comprensión
- único
- hasta
- Revela
- actualización
- a
- us
- utilizan el
- usado
- usando
- utilidad
- IMPORTANTE
- verificando
- vía
- visita
- puntos de vista
- visión
- visual
- arte visual
- visualización
- visualizar
- visualmente
- vital
- fue
- we
- webp
- ¿
- Que es
- que
- mientras
- Susurro
- QUIENES
- amplio
- Amplia gama
- seguirá
- ventana
- dentro de
- sin
- Actividades:
- funciona
- mundo
- X
- si
- aún
- Usted
- zephyrnet
- cero