Introducción
En el panorama en rápida evolución de la IA generativa, el papel fundamental de las bases de datos vectoriales se ha vuelto cada vez más evidente. Este artículo profundiza en la sinergia dinámica entre las bases de datos vectoriales y las soluciones de IA generativa, explorando cómo estos cimientos tecnológicos están dando forma al futuro de la creatividad de la inteligencia artificial. Únase a nosotros en un viaje a través de las complejidades de esta poderosa alianza, descubriendo conocimientos sobre el impacto transformador que las bases de datos vectoriales aportan a la vanguardia de las soluciones innovadoras de IA.
OBJETIVOS DE APRENDIZAJE
Este artículo le ayuda a comprender los aspectos de la base de datos de vectores a continuación.
- Importancia de las bases de datos vectoriales y sus componentes clave
- Estudio detallado de la comparación de la base de datos vectorial con la base de datos tradicional.
- Exploración de incrustaciones de vectores desde el punto de vista de la aplicación
- Creación de bases de datos vectoriales utilizando Pincone
- Implementación de la base de datos Pinecone Vector utilizando el modelo langchain LLM
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
¿Qué es la base de datos vectorial?
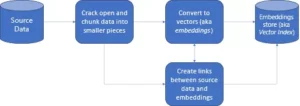
Una base de datos vectorial es una forma de recopilación de datos almacenada en el espacio. Aún así, aquí se almacena en representaciones matemáticas, ya que el formato almacenado en las bases de datos facilita que los modelos abiertos de IA memoricen las entradas y permite que nuestra aplicación abierta de IA utilice búsqueda cognitiva, recomendaciones y generación de texto para diversos casos de uso en las industrias transformadas digitalmente. El almacenamiento y recuperación de datos se denomina “Incrustaciones vectoriales” o “Incrustaciones”. Además, esto se representa en un formato de matriz numérica. La búsqueda es mucho más fácil que las bases de datos tradicionales utilizadas para perspectivas de IA con capacidades indexadas masivas.
Características de las bases de datos vectoriales
- Aprovecha el poder de estas incorporaciones de vectores, lo que lleva a la indexación y búsqueda en un conjunto de datos masivo.
- Compactable con todos los formatos de datos (imágenes, texto o datos).
- Dado que adapta técnicas de incrustación y características altamente indexadas, puede ofrecer una solución completa para administrar datos y entradas para el problema determinado.
- Una base de datos vectorial organiza datos a través de vectores de alta dimensión que contienen cientos de dimensiones. Podemos configurarlos muy rápidamente.
- Cada dimensión corresponde a una característica o propiedad específica del objeto de datos que representa.
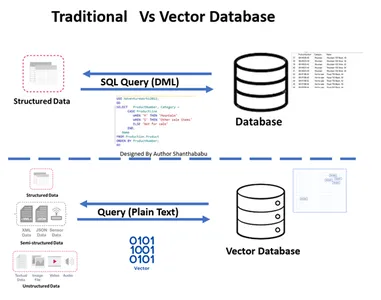
Tradicional vs. Base de datos vectorial
- La imagen muestra el flujo de trabajo de alto nivel de la base de datos tradicional y vectorial.
- Las interacciones formales con la base de datos ocurren a través de SQL declaraciones y datos almacenados en formato tabular y de base de filas.
- En la base de datos Vector, las interacciones se producen a través de texto sin formato (por ejemplo, inglés) y datos almacenados en representaciones matemáticas.
Semejanza de las bases de datos tradicionales y vectoriales
Debemos considerar en qué se diferencian las bases de datos Vector de las tradicionales. Discutamos esto aquí. Una rápida diferencia que puedo dar es la de las bases de datos convencionales. Los datos se almacenan exactamente tal como están; Podríamos agregar algo de lógica empresarial para ajustar los datos y fusionarlos o dividirlos según los requisitos o demandas comerciales. Sin embargo, la base de datos vectorial sufre una transformación masiva y los datos se convierten en una representación vectorial compleja.
Aquí hay un mapa para su perspectiva de comprensión y claridad con bases de datos relacionales contra bases de datos vectoriales. La siguiente imagen se explica por sí misma para comprender las bases de datos vectoriales con las bases de datos tradicionales. En resumen, podemos ejecutar inserciones y eliminaciones en bases de datos vectoriales, no declaraciones de actualización.
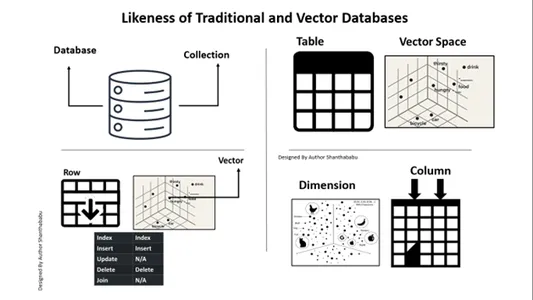
Analogía simple para comprender las bases de datos vectoriales
Los datos se organizan espacialmente automáticamente según la similitud del contenido de la información almacenada. Entonces, consideremos la tienda departamental como analogía con la base de datos vectorial; Todos los productos están ordenados en el estante según la naturaleza, el propósito, la fabricación, el uso y la cantidad. En un comportamiento similar, los datos son
ordenados automáticamente en la base de datos vectorial mediante una clasificación similar, incluso si el género no estaba bien definido al almacenar o acceder a los datos.
Las bases de datos vectoriales permiten una granularidad y dimensiones destacadas sobre las similitudes específicas, de modo que el cliente busca el producto, el fabricante y la cantidad deseados y mantiene el artículo en el carrito. La base de datos vectorial almacena todos los datos en una estructura de almacenamiento perfecta; aquí, los ingenieros de aprendizaje automático e inteligencia artificial no necesitan etiquetar el contenido almacenado manualmente.
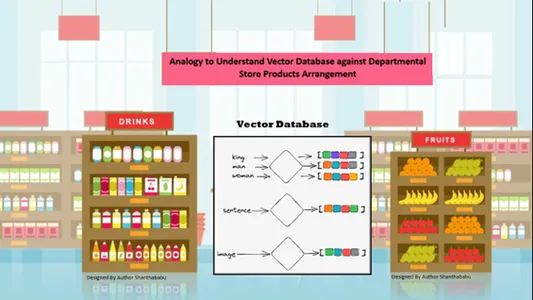
Teorías esenciales detrás de las bases de datos vectoriales
- Incrustaciones de vectores y su alcance
- Requisitos de indexación
- Comprensión de la búsqueda semántica y de similitud
Incrustación de vectores y su alcance
Una incrustación de vectores es una representación vectorial en términos de valores numéricos. En un formato comprimido, las incorporaciones capturan las propiedades y asociaciones inherentes de los datos originales, lo que las convierte en un elemento básico en los casos de uso de inteligencia artificial y aprendizaje automático. El diseño de incrustaciones para codificar información pertinente sobre los datos originales en un espacio de dimensiones inferiores garantiza una alta velocidad de recuperación, eficiencia computacional y almacenamiento eficiente.
Capturar la esencia de los datos de una manera más idénticamente estructurada es el proceso de incrustación de vectores, formando un "modelo de incrustación". En última instancia, estos modelos consideran todos los objetos de datos, extraen patrones y relaciones significativos dentro de la fuente de datos y los transforman en incrustaciones de vectores. . Posteriormente, los algoritmos aprovechan estas incorporaciones de vectores para ejecutar diversas tareas. Numerosos modelos de incrustación altamente desarrollados, disponibles en línea de forma gratuita o de pago por uso, facilitan la realización de la incrustación de vectores.
Alcance de las incrustaciones de vectores desde el punto de vista de la aplicación
Estas incorporaciones son compactas, contienen información compleja, heredan relaciones entre los datos almacenados en una base de datos vectorial, permiten un análisis de procesamiento de datos eficiente para facilitar la comprensión y la toma de decisiones, y construyen dinámicamente varios productos de datos innovadores en cualquier organización.
Las técnicas de incrustación de vectores son esenciales para conectar la brecha entre datos legibles y algoritmos complejos. Dado que los tipos de datos son vectores numéricos, pudimos desbloquear el potencial de una gran variedad de aplicaciones de IA generativa junto con los modelos de IA abierta disponibles.
Múltiples trabajos con incrustación de vectores
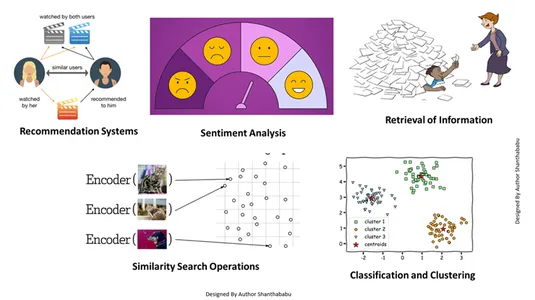
Esta incrustación de vectores nos ayuda a realizar múltiples trabajos:
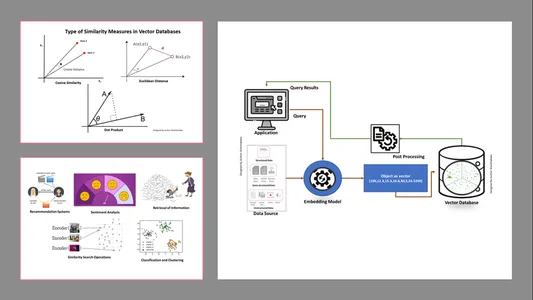
- Recuperación de Información: Con la ayuda de estas poderosas técnicas, podemos crear motores de búsqueda influyentes que pueden ayudarnos a encontrar respuestas basadas en las consultas de los usuarios a partir de archivos, documentos o medios almacenados.
- Operaciones de búsqueda de similitud: Está bien organizado e indexado; nos ayuda a encontrar la similitud entre diferentes ocurrencias en los datos vectoriales.
- Clasificación y agrupación: Utilizando estas técnicas de integración, podemos realizar estos modelos para entrenar algoritmos de aprendizaje automático relevantes y agruparlos y clasificarlos.
- Sistemas de recomendación: Dado que las técnicas de incrustación están organizadas adecuadamente, conduce a sistemas de recomendación que relacionan con precisión productos, medios y artículos basados en datos históricos.
- Análisis de los sentimientos: Este modelo de integración nos ayuda a categorizar y derivar soluciones de sentimiento.
Requisitos de indexación
Como sabemos, el índice mejorará los datos de búsqueda de la tabla en las bases de datos tradicionales, similar a las bases de datos vectoriales, y proporcionará las funciones de indexación.
Las bases de datos vectoriales proporcionan "índices planos", que son la representación directa de la incrustación del vector. La capacidad de búsqueda es completa y no utiliza clústeres previamente entrenados. Realiza la consulta de vectores en cada incrustación de un solo vector y se calculan K distancias para cada par.
- Debido a la facilidad de este índice, se requiere un cálculo mínimo para crear los nuevos índices.
- De hecho, un índice plano puede manejar consultas de manera efectiva y proporcionar tiempos de recuperación rápidos.
Comprensión de la búsqueda semántica y de similitud
Realizamos dos búsquedas diferentes en bases de datos vectoriales: búsquedas semánticas y de similitud.
- Búsqueda semántica: Mientras busca información, en lugar de buscar por palabras clave, puede encontrarlas basándose en una metodología de conversación significativa. La ingeniería rápida juega un papel vital al pasar la entrada al sistema. Sin duda, esta búsqueda permite búsquedas y resultados de mayor calidad que pueden utilizarse para aplicaciones innovadoras, SEO, generación de texto y resúmenes.
- Búsqueda de similitud: Siempre en el análisis de datos, la búsqueda de similitudes permite conjuntos de datos no estructurados y mucho mejor proporcionados. En el caso de las bases de datos vectoriales, debemos comprobar la cercanía de dos vectores y en qué se parecen entre sí: tablas, texto, documentos, imágenes, palabras y archivos de audio. En el proceso de comprensión, la similitud entre vectores se revela como la similitud entre los objetos de datos en el conjunto de datos dado. Este ejercicio nos ayuda a comprender la interacción, identificar patrones, extraer información y tomar decisiones desde la perspectiva de la aplicación. La búsqueda semántica y de similitud nos ayudaría a crear las aplicaciones siguientes para obtener beneficios de la industria.
- Recuperación de información: Utilizando Open AI y bases de datos vectoriales, construiríamos motores de búsqueda para la recuperación de información utilizando consultas de usuarios comerciales o usuarios finales y documentos indexados dentro de la base de datos vectorial.
- Clasificación y agrupación:Clasificar o agrupar puntos de datos o grupos de objetos similares implica asignarlos a múltiples categorías en función de características compartidas.
- Detección de anomalías: Descubrir anomalías a partir de patrones habituales midiendo la similitud de puntos de datos y detectando irregularidades.
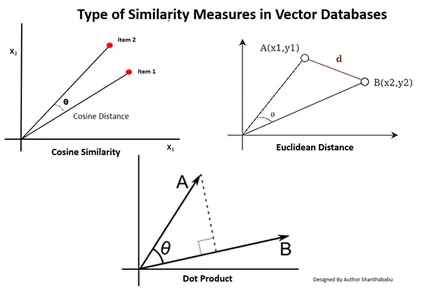
Tipos de medidas de similitud en bases de datos vectoriales
Los métodos de medición dependen de la naturaleza de los datos y de la aplicación específica. Normalmente, se utilizan tres métodos para medir la similitud y familiaridad con el aprendizaje automático.
Distancia euclidiana
En términos simples, la distancia entre los dos vectores es la distancia en línea recta entre los dos puntos del vector que miden el st.
Producto de punto
Esto nos ayuda a comprender la alineación entre dos vectores, indicando si apuntan en la misma dirección, en direcciones opuestas o son perpendiculares entre sí.
Similitud de coseno
Evalúa la similitud de dos vectores utilizando el ángulo entre ellos, como se muestra en la figura. En este caso, los valores y magnitud de los vectores son insignificantes y no afectan los resultados; sólo el ángulo se considera en el cálculo.
Bases de datos tradicionales Busque coincidencias exactas de declaraciones SQL y recupere los datos en formato tabular. Al mismo tiempo, nos ocupamos de bases de datos vectoriales buscando el vector más similar a la consulta de entrada en lenguaje sencillo utilizando técnicas de Prompt Engineering. La base de datos utiliza el algoritmo de búsqueda del vecino más cercano aproximado (ANN) para encontrar datos similares. Proporcione siempre resultados razonablemente precisos con alto rendimiento, precisión y tiempo de respuesta.
Mecanismo de trabajo
- Las bases de datos vectoriales primero convierten los datos en vectores incrustados, los almacenan en bases de datos vectoriales y crean índices para una búsqueda más rápida.
- Una consulta de la aplicación interactuará con el vector de incrustación, buscará el vecino más cercano o datos similares en la base de datos de vectores utilizando un índice y recuperará los resultados pasados a la aplicación.
- Según los requisitos comerciales, los datos recuperados se ajustarían, formatearían y mostrarían al usuario final o al feed de consultas o acciones.
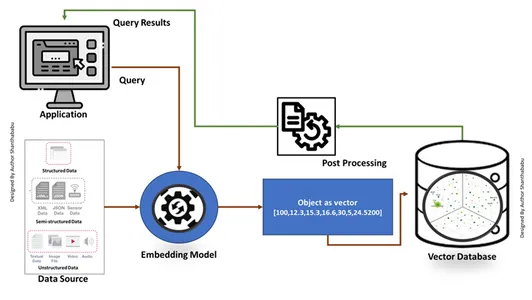
Crear una base de datos de vectores
Conectemos con Pinecone.
Puede conectarse a Pinecone mediante Google, GitHub o Microsoft ID.
Cree un nuevo inicio de sesión de usuario para su uso.
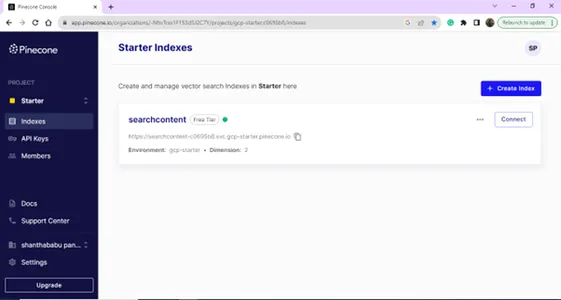
Después de iniciar sesión correctamente, accederá a la página de índice; puede crear un índice para su base de datos de vectores. Haga clic en el botón Crear índice.
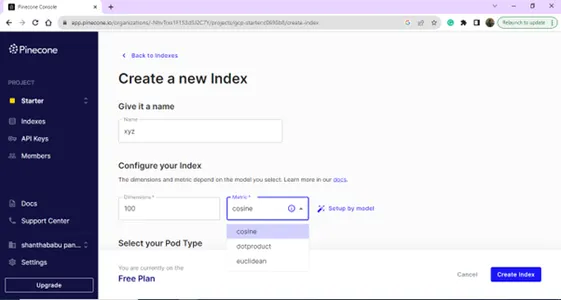
Cree su nuevo índice proporcionando el nombre y las dimensiones.
Página de lista de índice,
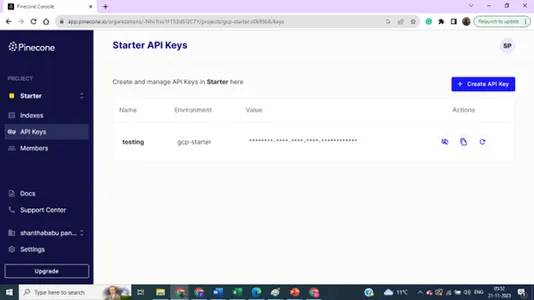
Detalles del índice: nombre, región y entorno: necesitamos todos estos detalles para conectar nuestra base de datos de vectores desde el código de construcción del modelo.
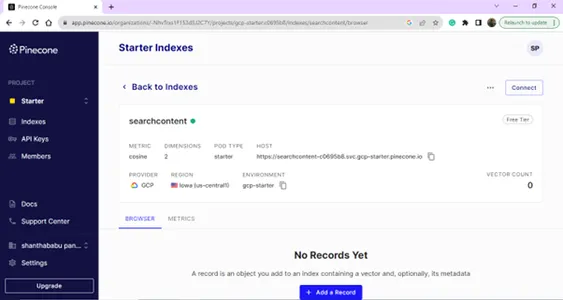
Detalles de configuración del proyecto,
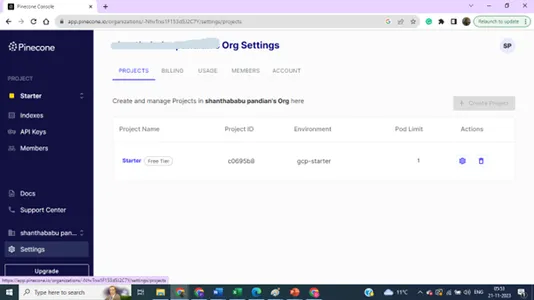
Puede actualizar sus preferencias para múltiples índices y claves para fines del proyecto.
Hasta ahora, hemos discutido la creación del índice y la configuración de la base de datos de vectores en Pinecone.
Implementación de bases de datos vectoriales usando Python
Codifiquemos un poco ahora.
Importación de bibliotecas
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
from langchain.vectorstores import Pinecone
from langchain.document_loaders import TextLoader
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAIProporcionar clave API para la base de datos OpenAI y Vector
import os
os.environ["OPENAI_API_KEY"] = "xxxxxxxx"
PINECONE_API_KEY = os.environ.get('PINECONE_API_KEY', 'xxxxxxxxxxxxxxxxxxxxxxx')
PINECONE_API_ENV = os.environ.get('PINECONE_API_ENV', 'gcp-starter')
api_keys="xxxxxxxxxxxxxxxxxxxxxx"
llm = OpenAI(OpenAI=api_keys, temperature=0.1)Iniciando el LLM
llm=OpenAI(openai_api_key=os.environ["OPENAI_API_KEY"],temperature=0.6)Iniciando piña
import pinecone
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
index_name = "demoindex" Cargando archivo .csv para crear una base de datos vectorial
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="/content/drive/My Drive/Colab_Notebooks/cereal.csv"
,source_column="name")
data = loader.load()Dividir el texto en trozos
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=20)
text_chunks = text_splitter.split_documents(data)Encontrar el texto en text_chunk
text_chunksSalida
[Documento(page_content='nombre: 100% Brannmfr: Nntipo: Cncalorías: 70nproteína: 4ngrasa: 1nsodio: 130nfibra: 10ncarbo: 5nazúcares: 6npotasa: 280nvitaminas: 25nestante: 3npeso: 1ntazas: 0.33nclasificación: 68.402973 nrecomendación: Niños, metadatos={ 'fuente': '100% Bran', 'fila': 0}), , …..
Incrustación de edificios
embeddings = OpenAIEmbeddings()Cree una instancia de Pinecone para una base de datos vectorial a partir de 'datos'
vectordb = Pinecone.from_documents(text_chunks,embeddings,index_name="demoindex")Cree un recuperador para consultar la base de datos de vectores.
retriever = vectordb.as_retriever(score_threshold = 0.7)Recuperar datos de una base de datos vectorial
rdocs = retriever.get_relevant_documents("Cocoa Puffs")
rdocsUsando Preguntar y recuperar los datos
from langchain.prompts import PromptTemplate
prompt_template = """Given the following context and a question,
generate an answer based on this context only.
,Please state "I don't know." Don't try to make up an answer.
CONTEXT: {context}
QUESTION: {question}"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
input_key="query",
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs)
Consultamos los datos.
chain('Can you please provide cereal recommendation for Kids?')Salida de la consulta
{'query': 'Can you please provide cereal recommendation for Kids?',
'result': [Document(page_content='name: Crispixnmfr: Kntype: Cncalories: 110nprotein: 2nfat: 0nsodium: 220nfiber: 1ncarbo: 21nsugars: 3npotass: 30nvitamins: 25nshelf: 3nweight: 1ncups: 1nrating: 46.895644nrecommendation: Kids', metadata={'row': 21.0, 'source': '/content/drive/My Drive/Colab_Notebooks/cereal.csv'}), ..]Conclusión
Espero que pueda comprender cómo funcionan las bases de datos vectoriales, sus componentes, arquitectura y características de las bases de datos vectoriales en soluciones de IA generativa. Comprender en qué se diferencia la base de datos vectorial de la base de datos tradicional y compararla con los elementos de la base de datos convencional. De hecho, la analogía le ayuda a comprender mejor la base de datos vectorial. La base de datos de vectores de Pinecone y los pasos de indexación lo ayudarán a crear una base de datos de vectores y brindarán la clave para la siguiente implementación del código.
Puntos clave
- Compactable con datos estructurados, no estructurados y semiestructurados.
- Adapta técnicas de incrustación y características altamente indexadas.
- Las interacciones se producen a través de texto sin formato mediante un mensaje (por ejemplo, inglés). Y datos almacenados en representaciones matemáticas.
- La similitud se calibra en bases de datos vectoriales mediante: distancia euclidiana, similitud de coseno y producto escalar.
Preguntas frecuentes
A. Una base de datos vectorial almacena una colección de datos en el espacio. Mantiene los datos en representaciones matemáticas. ya que el formato almacenado en las bases de datos facilita que los modelos abiertos de IA memoricen las entradas anteriores y permite que nuestra aplicación de IA abierta utilice búsqueda cognitiva, recomendaciones y generación de texto preciso para diversos casos de uso en industrias transformadas digitalmente.
R. Algunas de las características son: 1. Aprovecha el poder de estas incorporaciones de vectores, lo que lleva a la indexación y búsqueda en un conjunto de datos masivo. 2. Compactable con datos estructurados, no estructurados y semiestructurados. 3. Una base de datos vectorial organiza datos a través de vectores de alta dimensión que contienen cientos de dimensiones.
A. Base de datos ==> Colecciones
Tabla ==> Espacio vectorial
Fila==>Cector
Columna==>Dimensión
Es posible insertar y eliminar en las bases de datos vectoriales, al igual que en una base de datos tradicional.
Actualizar y Unirse no están dentro del alcance.
– Recuperación de Información para recolección masiva de datos rápidamente.
– Operaciones de búsqueda semántica y de similitud a partir de documentos de gran tamaño.
– Aplicación de Clasificación y Agrupación.
– Sistemas de Recomendación y Análisis de Sentimiento.
R5: A continuación se muestran los tres métodos para medir la similitud:
- Distancia euclidiana
– Similitud del coseno
– Producto escalar
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/12/vector-databases-in-generative-ai-solutions/
- :posee
- :es
- :no
- $ UP
- 1
- 10
- 12
- 13
- 46
- 7
- 8
- 9
- a
- Poder
- Nuestra Empresa
- el acceso
- la exactitud
- preciso
- precisamente
- a través de
- se adapta
- add
- afectar
- AI
- Modelos AI
- algoritmo
- algoritmos
- alineación
- Todos
- Alliance
- permitir
- permite
- a lo largo de
- hacerlo
- entre
- an
- análisis
- Analytics
- Analítica Vidhya
- y
- https://www.youtube.com/watch?v=xB-eutXNUMXJtA&feature=youtu.be
- cualquier
- abejas
- aparente
- Aplicación
- aplicación específica
- aplicaciones
- aproximado
- arquitectura
- somos
- arreglado
- Formación
- artículo
- artificial
- inteligencia artificial
- Inteligencia Artificial y Aprendizaje Automático
- AS
- aspectos
- evalúa
- asociaciones
- At
- audio
- automáticamente
- Hoy Disponibles
- basado
- BE
- a las que has recomendado
- se convierte en
- comportamiento
- detrás de
- "Ser"
- a continuación
- beneficios
- mejores
- entre
- blogatón
- llevar
- build
- Construir la
- .
- by
- calculado
- cálculo
- , que son
- PUEDEN
- capacidades
- capacidad
- capturar
- case
- cases
- categoría
- cadena
- cadenas
- características
- transparencia
- clasificación
- clasificar
- clic
- clustering
- código
- Codificación
- cognitivo
- --
- comúnmente
- compacto
- comparar
- comparación
- completar
- integraciones
- componentes
- exhaustivo
- cálculo
- computational
- Contacto
- Conectándote
- Considerar
- considerado
- que no contengo
- contenido
- contexto
- convencional
- Conversación
- convertir
- corresponde
- podría
- Para crear
- Creamos
- creatividad
- cliente
- datos
- análisis de los datos
- puntos de datos
- proceso de datos
- Base de datos
- bases de datos
- conjuntos de datos
- acuerdo
- Toma de Decisiones
- decisiones
- demandas
- derivar
- diseño
- deseado
- detalles
- Detección
- desarrollado
- diferir de
- un cambio
- una experiencia diferente
- digitalmente
- Dimensiones
- dimensiones
- de reservas
- dirección
- direcciones
- descubrir
- discreción
- discutir
- discutido
- aquí
- distancia
- do
- documentos
- sí
- don
- DOT
- lugar de trabajo dinámico
- dinamicamente
- e
- cada una
- facilidad
- más fácil
- de manera eficaz
- eficiencia
- eficiente
- ya sea
- elementos
- incrustación
- habilitar
- final
- Ingeniería
- certificados
- motores
- Inglés
- asegura
- Entorno
- esencia
- esencial
- Éter (ETH)
- Incluso
- evolución
- ejecutar
- Haz ejercicio
- Explorar
- extraerlos
- facilitar
- Familiaridad
- muchos
- Feature
- Caracteristicas
- Fed
- Figura
- Archive
- archivos
- Encuentre
- Nombre
- plano
- siguiendo
- primer plano
- formulario
- formato
- Gratuito
- Desde
- futuras
- brecha
- generar
- generación de AHSS
- generativo
- IA generativa
- género
- GitHub
- Donar
- dado
- Grupo procesos
- Grupo
- encargarse de
- suceder
- Tienen
- ayuda
- ayuda
- esta página
- Alta
- de alto nivel
- altamente
- histórico
- Cómo
- Sin embargo
- HTTPS
- enorme
- Cientos
- i
- ID
- Identifique
- if
- imágenes
- Impacto
- implementación
- importar
- mejorar
- in
- cada vez más
- índice
- indexado
- índices
- indicando
- Indices
- industrias
- energético
- Influyente
- información
- inherente
- originales
- Las opciones de entrada
- entradas
- Insertos
- dentro
- Insights
- ejemplo
- Intelligence
- interactuar
- interacción
- interacciones
- dentro
- complejidades
- implica
- IT
- SUS
- Empleo
- únete
- Unáse con nosotros
- solo
- Clave
- claves
- las palabras claves
- Niños
- Saber
- Label
- CARGA TERRESTRE
- paisaje
- large
- líder
- Prospectos
- aprendizaje
- Apalancamiento
- apalancamientos
- como
- Lista
- cargador
- lógica
- Inicie sesión
- máquina
- máquina de aprendizaje
- gran
- para lograr
- HACE
- Realizar
- administrar
- manera
- a mano
- Fabricante
- mapa
- masivo
- cerillas
- matemático
- significativo
- medir
- medidas
- medición
- mecanismo
- Medios
- ir
- Metodología
- métodos
- Microsoft
- mínimo
- modelo
- modelos
- más,
- Por otra parte
- MEJOR DE TU
- mucho más
- múltiples
- debe
- nombre
- Naturaleza
- ¿ Necesita ayuda
- Nuevo
- ahora
- numeroso
- objeto
- objetos
- of
- LANZAMIENTO
- on
- ONE
- las
- en línea
- , solamente
- habiertos
- OpenAI
- Operaciones
- opuesto
- or
- organización
- Organizado
- organiza
- reconocida por
- OS
- Otro
- nuestros
- propiedad
- página
- par
- parte
- pasado
- Pasando (Paso)
- .
- perfecto
- realizar
- actuación
- realizado
- realiza
- la perspectiva
- perspectivas
- imagen
- esencial
- Natural
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- juega
- Por favor
- punto
- puntos
- posible
- posible
- industria
- poderoso
- Metodología
- Aplicaciones Prácticas
- necesidad
- precisamente
- preferencias
- anterior
- Problema
- Producto
- Productos
- proyecto
- destacado
- ideas
- correctamente
- propiedades
- perfecta
- proporcionar
- proporcionando
- provisión
- publicado
- Puffs
- propósito
- fines
- la cantidad
- consultas
- pregunta
- Búsqueda
- más rápido
- con rapidez
- rápidamente
- Recomendación
- recomendaciones
- con respecto a
- región
- relaciones
- Relaciones
- representación
- representado
- representa
- Requisitos
- Requisitos
- respuesta
- respuestas
- resultado
- Resultados
- Revelado
- Función
- FILA
- s
- mismo
- Ciencia:
- alcance
- Buscar
- Los motores de búsqueda
- Búsquedas
- búsqueda
- sentimiento
- SEO
- ajustes
- Forma
- la formación
- compartido
- Estante
- En Corto
- mostrado
- Shows
- lado
- similares
- similitudes
- sencillos
- desde
- soltero
- Tamaño
- So
- a medida
- Soluciones
- algo
- Fuente
- Espacio
- soluciones y
- velocidad
- dividido
- punteo
- SQL
- Estado
- Posicionamiento
- declaraciones
- pasos
- Sin embargo
- STORAGE
- tienda
- almacenados
- tiendas
- estructura
- estructurado
- ESTUDIO
- Después
- exitosos
- sinergia
- te
- Todas las funciones a su disposición
- T
- mesa
- ETIQUETA
- tareas
- técnicas
- tecnológico
- términos
- texto
- generación de texto
- que
- esa
- La
- El futuro de las
- su
- Les
- Estas
- ellos
- así
- Tres
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- veces
- a
- tradicional
- Entrenar
- Transformar
- transformador
- transformado
- try
- dos
- tipos
- Finalmente, a veces
- entender
- comprensión
- indudablemente
- desbloquear
- desbloqueo
- Actualizar
- actualizar
- us
- Uso
- utilizan el
- usado
- Usuario
- usos
- usando
- usual
- Valores
- variedad
- diversos
- muy
- vital
- vs
- fue
- we
- webp
- bien definido
- tuvieron
- ¿
- Que es
- sean
- que
- mientras
- seguirá
- dentro de
- palabras
- Actividades:
- trabajando
- se
- Usted
- tú
- zephyrnet