
Imagen del autor | Creador de imágenes de Bing
Dolly 2.0 es un modelo de lenguaje grande (LLM) de código abierto, seguido de instrucciones, que se ajustó en un conjunto de datos generado por humanos. Se puede utilizar tanto con fines comerciales como de investigación.
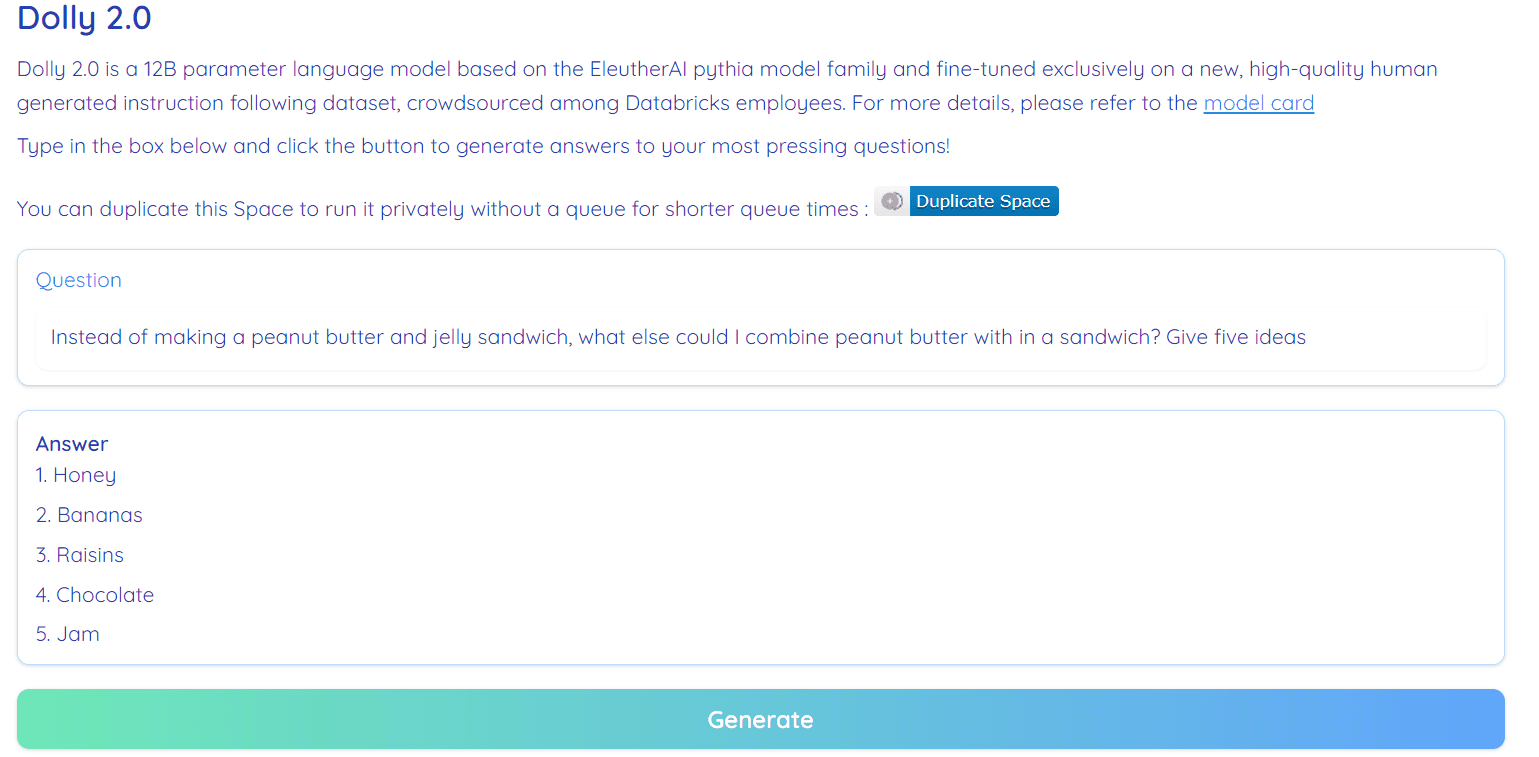
Imagen de Abrazando el espacio de la cara de RamAnanth1
Anteriormente, el equipo de Databricks lanzó Dolly 1.0, LLM, que exhibe una capacidad de seguimiento de instrucciones similar a ChatGPT y cuesta menos de $ 30 para entrenar. Estaba usando el conjunto de datos del equipo Stanford Alpaca, que estaba bajo una licencia restringida (solo para investigación).
Dolly 2.0 ha resuelto este problema ajustando el modelo de lenguaje de parámetros 12B (pitia) en una instrucción de alta calidad generada por humanos en el siguiente conjunto de datos, que fue etiquetado por un empleado de Datbricks. Tanto el modelo como el conjunto de datos están disponibles para uso comercial.
Dolly 1.0 se entrenó en un conjunto de datos de Stanford Alpaca, que se creó con la API de OpenAI. El conjunto de datos contiene la salida de ChatGPT y evita que alguien lo use para competir con OpenAI. En resumen, no puede crear un chatbot comercial o una aplicación de lenguaje basada en este conjunto de datos.
La mayoría de los últimos modelos lanzados en las últimas semanas sufrieron los mismos problemas, modelos como Alpaca, Koala, GPT4Todosy Vicuña. Para moverse, necesitamos crear nuevos conjuntos de datos de alta calidad que se puedan usar para uso comercial, y eso es lo que ha hecho el equipo de Databricks con el conjunto de datos databricks-dolly-15k.
El nuevo conjunto de datos contiene 15,000 XNUMX pares de solicitud/respuesta de alta calidad etiquetados por humanos que se pueden usar para diseñar instrucciones que ajustan modelos de lenguaje grandes. El databricks-dolly-15k el conjunto de datos viene con Licencia Creative Commons Reconocimiento-CompartirIgual 3.0 Unported, que permite que cualquiera pueda usarlo, modificarlo y crear una aplicación comercial en él.
¿Cómo crearon el conjunto de datos databricks-dolly-15k?
La investigación de OpenAI afirma que el modelo InstructGPT original fue entrenado en 13,000 indicaciones y respuestas. Al usar esta información, el equipo de Databricks comenzó a trabajar en ella y resultó que generar 13 5,000 preguntas y respuestas fue una tarea difícil. No pueden usar datos sintéticos o datos generativos de IA, y tienen que generar respuestas originales para cada pregunta. Aquí es donde han decidido utilizar XNUMX empleados de Databricks para crear datos generados por humanos.
Los Databricks organizaron un concurso en el que los 20 mejores etiquetadores obtendrían un gran premio. En este concurso participaron 5,000 empleados de Databricks que estaban muy interesados en los LLM
El dolly-v2-12b no es un modelo de última generación. Tiene un rendimiento inferior a dolly-v1-6b en algunos puntos de referencia de evaluación. Puede deberse a la composición y el tamaño de los conjuntos de datos de ajuste fino subyacentes. La familia de modelos Dolly está en desarrollo activo, por lo que es posible que vea una versión actualizada con un mejor rendimiento en el futuro.
En resumen, el modelo dolly-v2-12b ha funcionado mejor que EleutherAI/gpt-neox-20b y EleutherAI/pythia-6.9b.

Imagen de carro gratis
Dolly 2.0 es 100% de código abierto. Viene con código de entrenamiento, conjunto de datos, pesos de modelo y canalización de inferencia. Todos los componentes son adecuados para uso comercial. Puedes probar el modelo en Hugging Face Spaces Dolly V2 de RamAnanth1.
Imagen de Abrazando la cara
Recursos:
Demostración de Dolly 2.0: Dolly V2 de RamAnanth1
Abid Ali Awan (@ 1abidaliawan) es un profesional científico de datos certificado al que le encanta crear modelos de aprendizaje automático. Actualmente, se está enfocando en la creación de contenido y escribiendo blogs técnicos sobre aprendizaje automático y tecnologías de ciencia de datos. Abid tiene una Maestría en Gestión de Tecnología y una licenciatura en Ingeniería de Telecomunicaciones. Su visión es construir un producto de IA utilizando una red neuronal gráfica para estudiantes que luchan contra enfermedades mentales.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html?utm_source=rss&utm_medium=rss&utm_campaign=dolly-2-0-chatgpt-open-source-alternative-for-commercial-use
- :posee
- :es
- :no
- $ UP
- 000
- 1
- 20
- a
- capacidad
- lector activo
- AI
- Todos
- permite
- alternativa
- an
- y
- respuestas
- nadie
- abejas
- Aplicación
- somos
- en torno a
- autor
- Hoy Disponibles
- de premio
- basado
- BE
- los puntos de referencia
- Berkeley
- mejores
- Big
- Bing
- Blogs
- ambas
- build
- Construir la
- by
- PUEDEN
- no puede
- Ingenieros
- chatterbot
- ChatGPT
- código
- completo
- Los comunes
- competir
- componentes
- contiene
- contenido
- creación de contenido
- concurso
- Precio
- Para crear
- creado
- creación
- En la actualidad
- datos
- Ciencia de los datos
- científico de datos
- Databricks
- conjuntos de datos
- decidido
- Grado
- De demostración
- Diseño
- Desarrollo
- HIZO
- difícil
- Muñequita
- Nuestros
- personas
- Ingeniería
- evaluación
- Cada
- exposiciones
- Cara
- familia
- pocos
- enfoque
- siguiendo
- en
- futuras
- generar
- la generación de
- generativo
- obtener
- gráfica
- Red neuronal gráfica
- Tienen
- he
- alta calidad
- mantiene
- HTML
- HTTPS
- enfermedad
- imagen
- in
- información
- interesado
- cuestiones
- IT
- jpg
- nuggets
- idioma
- large
- Apellido
- más reciente
- aprendizaje
- Licencia
- como
- máquina
- máquina de aprendizaje
- Management
- dominar
- mental
- Enfermedad mental
- podría
- modelo
- modelos
- modificar
- ¿ Necesita ayuda
- del sistema,
- Neural
- red neural
- Nuevo
- of
- on
- , solamente
- habiertos
- de código abierto
- OpenAI
- or
- reconocida por
- salida
- pares
- parámetro
- participaron
- (PDF)
- actuación
- industrial
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- Producto
- Profesional
- fines
- pregunta
- Preguntas
- liberado
- la investigación
- resuelto
- límite
- s
- mismo
- Ciencia:
- Científico
- set
- En Corto
- Tamaño
- So
- algo
- Fuente
- Espacio
- espacios
- stanford
- fundó
- el estado de la técnica
- Zonas
- Luchando
- Estudiantes
- adecuado
- sintético
- datos sintéticos
- Tarea
- equipo
- Técnico
- Tecnologías
- Tecnología
- telecomunicación
- que
- esa
- El
- El futuro de las
- ellos
- así
- a
- parte superior
- Entrenar
- entrenado
- Formación
- bajo
- subyacente
- actualizado
- utilizan el
- usado
- usando
- versión
- visión
- fue
- we
- Semanas
- tuvieron
- ¿
- que
- QUIENES
- Actividades:
- se
- la escritura
- Usted
- zephyrnet










