Desplazamiento al rojo de Amazon es un almacén de datos en la nube totalmente administrado y a escala de petabytes que utilizan decenas de miles de clientes para procesar exabytes de datos todos los días para potenciar su carga de trabajo de análisis. Puede estructurar sus datos, medir los procesos comerciales y obtener información valiosa rápidamente mediante el uso de un modelo dimensional. Amazon Redshift proporciona características integradas para acelerar el proceso de modelado, orquestación e informes a partir de un modelo dimensional.
En esta publicación, discutimos cómo implementar un modelo dimensional, específicamente el Metodología Kimball. Analizamos la implementación de dimensiones y hechos en Amazon Redshift. Mostramos cómo realizar extracción, transformación y carga (ELT), un proceso de integración centrado en obtener los datos sin procesar de un lago de datos en una capa de preparación para realizar el modelado. En general, la publicación le brindará una comprensión clara de cómo usar el modelado dimensional en Amazon Redshift.
Resumen de la solución
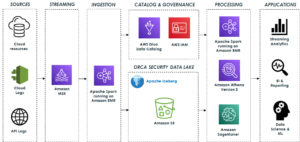
El siguiente diagrama ilustra la arquitectura de la solución.

En las siguientes secciones, primero discutimos y demostramos los aspectos clave del modelo dimensional. Después de eso, creamos un data mart usando Amazon Redshift con un modelo de datos dimensionales que incluye tablas de hechos y dimensiones. Los datos se cargan y organizan utilizando el COPIA comando, los datos en las dimensiones se cargan usando el UNIR declaración, y los hechos se unirán a las dimensiones de donde se derivan las ideas. Planificamos la carga de las dimensiones y hechos utilizando el Editor de consultas Amazon Redshift V2. Por último, usamos Amazon QuickSight para obtener información sobre los datos modelados en forma de panel QuickSight.
Para esta solución, utilizamos un conjunto de datos de muestra (normalizado) proporcionado por Amazon Redshift para la venta de entradas para eventos. Para esta publicación, hemos reducido el conjunto de datos por motivos de simplicidad y demostración. Las siguientes tablas muestran ejemplos de los datos de venta de entradas y lugares.


Según la Metodología de modelado dimensional de Kimball, hay cuatro pasos clave en el diseño de un modelo dimensional:
- Identificar el proceso de negocio.
- Declare el grano de sus datos.
- Identificar e implementar las dimensiones.
- Identificar y poner en práctica los hechos.
Además, agregamos un quinto paso con fines de demostración, que es informar y analizar eventos comerciales.
Requisitos previos
Para este tutorial, debe tener los siguientes requisitos previos:
Identificar el proceso de negocio.
En términos simples, identificar el proceso comercial es identificar un evento medible que genera datos dentro de una organización. Por lo general, las empresas tienen algún tipo de sistema fuente operativo que genera sus datos en su formato original. Este es un buen punto de partida para identificar varias fuentes para un proceso empresarial.
A continuación, el proceso empresarial persiste como un data mart en forma de dimensiones y hechos. Mirando nuestro conjunto de datos de muestra mencionado anteriormente, podemos ver claramente que el proceso comercial son las ventas realizadas para un evento determinado.
Un error común que se comete es utilizar los departamentos de una empresa como proceso comercial. Los datos (proceso comercial) deben integrarse en varios departamentos, en este caso, marketing puede acceder a los datos de ventas. Identificar el proceso de negocio correcto es fundamental: dar un paso incorrecto puede afectar a todo el data mart (puede hacer que el grano se duplique y que las métricas sean incorrectas en los informes finales).
Declare el grano de sus datos
Declarar el grano es el acto de identificar de forma única un registro en su fuente de datos. El grano se usa en la tabla de hechos para medir con precisión los datos y permitirle acumular más. En nuestro ejemplo, esto podría ser un elemento de línea en el proceso comercial de ventas.
En nuestro caso de uso, una venta puede identificarse de manera única observando el momento de la transacción cuando se realizó la venta; este será el nivel más atómico.

Identificar e implementar las dimensiones.
Su tabla de dimensiones describe su tabla de hechos y sus atributos. Al identificar el contexto descriptivo de su proceso comercial, almacene el texto en una tabla separada, teniendo en cuenta el grano de la tabla de hechos. Al unir la tabla de dimensiones a la tabla de hechos, solo debe haber una sola fila asociada a la tabla de hechos. En nuestro ejemplo, usamos la siguiente tabla para separarla en una tabla de dimensiones; estos campos describen los hechos que vamos a medir.
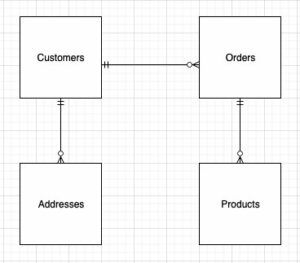
Al diseñar la estructura del modelo dimensional (el esquema), puede crear un estrella or copo de nieve esquema. La estructura debe alinearse estrechamente con el proceso comercial; por lo tanto, un esquema en estrella se ajusta mejor a nuestro ejemplo. La siguiente figura muestra nuestro Diagrama de Relación de Entidad (ERD).

En las siguientes secciones, detallamos los pasos para implementar las dimensiones.
Preparar los datos de origen
Antes de que podamos crear y cargar la tabla de dimensiones, necesitamos datos de origen. Por lo tanto, organizamos los datos de origen en una tabla provisional o temporal. Esto a menudo se conoce como el capa de ensayo, que es la copia sin procesar de los datos de origen. Para hacer esto en Amazon Redshift, usamos el Comando COPY para cargar los datos del depósito público de S3 dimensional-modeling-in-amazon-redshift ubicado en el us-east-1 Región. Tenga en cuenta que el comando COPY utiliza un Gestión de identidades y accesos de AWS (IAM) rol con acceso a Amazon S3. El papel debe ser asociado con el clúster. Complete los siguientes pasos para organizar los datos de origen:
- Crea el
venuetabla fuente:
- Cargue los datos del lugar:
- Crea el
salestabla fuente:
- Cargue los datos de la fuente de ventas:
- Crea el
calendarmesa:
- Cargue los datos del calendario:
Crear la tabla de dimensiones
El diseño de la tabla de dimensiones puede depender de los requisitos de su negocio; por ejemplo, ¿necesita realizar un seguimiento de los cambios en los datos a lo largo del tiempo? Hay siete tipos de dimensiones diferentes. Para nuestro ejemplo, usamos Tipo 1 porque no necesitamos hacer un seguimiento de los cambios históricos. Para obtener más información sobre el tipo 2, consulte Simplifique la carga de datos en las dimensiones de cambio lento de Tipo 2 en Amazon Redshift. La tabla de dimensiones se desnormalizará con una clave principal, una clave sustituta y algunos campos agregados para indicar cambios en la tabla. Ver el siguiente código:
Algunas notas sobre la creación de la tabla de dimensiones:
- Los nombres de campo se transforman en nombres comerciales
- Nuestra clave principal es
VenueID, que usamos para identificar de forma única un lugar en el que se realizó la venta - Se agregarán dos filas adicionales, que indican cuándo se insertó y actualizó un registro (para realizar un seguimiento de los cambios)
- Estamos usando un Estilo de distribución AUTO dar a Amazon Redshift la responsabilidad de elegir y ajustar el estilo de distribución
Otro factor importante a considerar en el modelado dimensional es el uso de llaves sustitutas. Las claves sustitutas son claves artificiales que se utilizan en el modelado dimensional para identificar de forma única cada registro en una tabla de dimensiones. Por lo general, se generan como un número entero secuencial y no tienen ningún significado en el dominio comercial. Ofrecen varias ventajas, como garantizar la exclusividad y mejorar el rendimiento de las uniones, ya que suelen ser más pequeñas que las claves naturales y, como claves sustitutas, no cambian con el tiempo. Esto nos permite ser consistentes y unir hechos y dimensiones más fácilmente.
En Amazon Redshift, las claves sustitutas generalmente se crean utilizando la palabra clave IDENTITY. Por ejemplo, la sentencia CREATE anterior crea una tabla de dimensiones con un VenueSkey clave sustituta. El VenueSkey La columna se completa automáticamente con valores únicos a medida que se agregan nuevas filas a la tabla. Esta columna se puede usar para unir la tabla del lugar con la FactSaleTransactions mesa.
Algunos consejos para diseñar claves sustitutas:
- Utilice un tipo de datos pequeño y de ancho fijo para la clave sustituta. Esto mejorará el rendimiento y reducirá el espacio de almacenamiento.
- Utilice la palabra clave IDENTITY o genere la clave sustituta mediante un valor secuencial o GUID. Esto asegurará que la clave sustituta sea única y no se pueda cambiar.
Cargue la tabla dim usando MERGE
Existen numerosas formas de cargar su tabla de atenuación. Se deben considerar ciertos factores, por ejemplo, el rendimiento, el volumen de datos y quizás los tiempos de carga del SLA. Con el UNIR instrucción, realizamos un upsert sin necesidad de especificar varios comandos de inserción y actualización. Puede configurar el UNIR declaración en un procedimiento almacenado para poblar los datos. Luego programa el procedimiento almacenado para que se ejecute mediante programación a través del editor de consultas, lo que demostramos más adelante en la publicación. El siguiente código crea un procedimiento almacenado llamado SalesMart.DimVenueLoad:
Algunas notas sobre la carga de dimensiones:
- Cuando se inserta un registro por primera vez, se completarán la fecha insertada y la fecha actualizada. Cuando cambia cualquier valor, los datos se actualizan y la fecha actualizada refleja la fecha en que se cambió. La fecha insertada permanece.
- Debido a que los usuarios comerciales utilizarán los datos, debemos reemplazar los valores NULL, si los hay, con valores más apropiados para el negocio.
Identificar e implementar los hechos.
Ahora que hemos declarado que nuestro grano es el evento de una venta que tuvo lugar en un momento específico, nuestra tabla de hechos almacenará los hechos numéricos para nuestro proceso comercial.
Hemos identificado los siguientes hechos numéricos a medir:
- Cantidad de entradas vendidas por venta
- comisión por la venta
Implementando el hecho
Existen tres tipos de tablas de hechos (tabla de hechos de transacciones, tabla de hechos de instantáneas periódicas y tabla de hechos de instantáneas acumuladas). Cada uno sirve una vista diferente del proceso de negocio. Para nuestro ejemplo, usamos una tabla de hechos de transacciones. Complete los siguientes pasos:
- Crear la tabla de hechos
Se agrega una fecha insertada con un valor predeterminado, que indica si se cargó un registro y cuándo. Puede usar esto cuando vuelva a cargar la tabla de hechos para eliminar los datos ya cargados y evitar duplicados.
Cargar la tabla de hechos consiste en una declaración de inserción simple que une sus dimensiones asociadas. Nos unimos desde el DimVenue tabla que se creó, que describe nuestros hechos. Es una buena práctica pero opcional tener fecha del calendario dimensiones, que permiten al usuario final navegar por la tabla de hechos. Los datos se pueden cargar cuando hay una nueva venta o diariamente; aquí es donde la fecha insertada o la fecha de carga resulta útil.
Cargamos la tabla de hechos usando un procedimiento almacenado y usamos un parámetro de fecha.
- Cree el procedimiento almacenado con el siguiente código. Para mantener la misma integridad de datos que aplicamos en la carga de la dimensión, reemplazamos los valores NULL, si los hay, con valores más apropiados para el negocio:
- Cargue los datos llamando al procedimiento con el siguiente comando:
Programar la carga de datos
Ahora podemos automatizar el proceso de modelado programando los procedimientos almacenados en Amazon Redshift Query Editor V2. Complete los siguientes pasos:
- Primero llamamos a la carga de dimensión y después de que la carga de dimensión se ejecuta correctamente, comienza la carga de hechos:
Si la carga de dimensión falla, la carga de hechos no se ejecutará. Esto garantiza la coherencia de los datos porque no queremos cargar la tabla de hechos con dimensiones obsoletas.
- Para programar la carga, elija Horarios en el Editor de consultas V2.

- Programamos la consulta para que se ejecute todos los días a las 5:00 a. m.
- Opcionalmente, puede agregar notificaciones de falla al habilitar Servicio de notificación simple de Amazon (Amazon SNS) notificaciones.

Informe y analice los datos en Amazon Quicksight
QuickSight es un servicio de inteligencia comercial que facilita la entrega de información. Como un servicio completamente administrado, QuickSight le permite crear y publicar fácilmente tableros interactivos a los que luego se puede acceder desde cualquier dispositivo e integrarlos en sus aplicaciones, portales y sitios web.
Usamos nuestro data mart para presentar visualmente los hechos en forma de tablero. Para comenzar y configurar QuickSight, consulte Creación de un conjunto de datos utilizando una base de datos que no se detecta automáticamente.
Después de crear su fuente de datos en QuickSight, unimos los datos modelados (mart de datos) en función de nuestra clave sustituta skey. Usamos este conjunto de datos para visualizar el data mart.

Nuestro tablero final contendrá los conocimientos del data mart y responderá preguntas comerciales críticas, como la comisión total por lugar y las fechas con las ventas más altas. La siguiente captura de pantalla muestra el producto final del data mart.

Limpiar
Para evitar incurrir en cargos futuros, elimine cualquier recurso que haya creado como parte de esta publicación.
Conclusión
Ahora hemos implementado con éxito un data mart usando nuestro DimVenue, DimCalendary FactSaleTransactions mesas. Nuestro almacén no está completo; a medida que podamos expandir el data mart con más hechos e implementar más marts, y a medida que el proceso comercial y los requisitos crezcan con el tiempo, también lo hará el almacén de datos. En esta publicación, brindamos una visión integral sobre cómo comprender e implementar el modelado dimensional en Amazon Redshift.
Empiece con su Desplazamiento al rojo de Amazon modelo dimensional hoy.
Acerca de los autores
 bernardo verster es un ingeniero de nube experimentado con años de exposición en la creación de modelos de datos escalables y eficientes, la definición de estrategias de integración de datos y la garantía de seguridad y gobierno de datos. Le apasiona usar datos para generar conocimientos, al tiempo que se alinea con los requisitos y objetivos comerciales.
bernardo verster es un ingeniero de nube experimentado con años de exposición en la creación de modelos de datos escalables y eficientes, la definición de estrategias de integración de datos y la garantía de seguridad y gobierno de datos. Le apasiona usar datos para generar conocimientos, al tiempo que se alinea con los requisitos y objetivos comerciales.
 Abhishek Pan es un especialista en SA-Analytics de WWSO que trabaja con clientes del sector público de AWS India. Se relaciona con los clientes para definir una estrategia basada en datos, proporcionar sesiones de inmersión profunda en casos de uso de análisis y diseñar aplicaciones analíticas escalables y de alto rendimiento. Tiene 12 años de experiencia y le apasionan las bases de datos, la analítica y la IA/ML. Es un ávido viajero y trata de capturar el mundo a través de la lente de su cámara.
Abhishek Pan es un especialista en SA-Analytics de WWSO que trabaja con clientes del sector público de AWS India. Se relaciona con los clientes para definir una estrategia basada en datos, proporcionar sesiones de inmersión profunda en casos de uso de análisis y diseñar aplicaciones analíticas escalables y de alto rendimiento. Tiene 12 años de experiencia y le apasionan las bases de datos, la analítica y la IA/ML. Es un ávido viajero y trata de capturar el mundo a través de la lente de su cámara.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- :posee
- :es
- :no
- :dónde
- $ UP
- 1
- 100
- 12
- 15%
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- Nuestra Empresa
- acelerar
- de la máquina
- visitada
- precisamente
- a través de
- Actúe
- add
- adicional
- Adicionales
- Después
- AI / ML
- alinear
- alineando
- permitir
- permite
- ya haya utilizado
- am
- Amazon
- Amazon Web Services
- an
- análisis
- Pruebas analíticas
- Analytics
- analizar
- y
- https://www.youtube.com/watch?v=xB-eutXNUMXJtA&feature=youtu.be
- cualquier
- aplicaciones
- aplicada
- adecuado
- arquitectura
- somos
- artificial
- AS
- aspectos
- asociado
- At
- atributos
- auto
- automatizado
- automáticamente
- evitar
- AWS
- b
- basado
- BE
- porque
- comenzar
- beneficios
- MEJOR
- incorporado
- inteligencia empresarial
- Procesos de negocio
- Procesos de negocios
- pero
- by
- Calendario
- llamar al
- , que son
- llamar
- cámara
- PUEDEN
- capturar
- case
- cases
- Causa
- a ciertos
- el cambio
- cambiado
- Cambios
- cambio
- personaje
- cargos
- Elige
- limpiar
- con claridad.
- de cerca
- Soluciones
- código
- Columna
- proviene
- referencia
- Algunos
- Empresas
- compañía
- completar
- Considerar
- consistente
- consiste
- contexto
- correcta
- podría
- Para crear
- creado
- crea
- Creamos
- creación
- crítico
- Clientes
- todos los días
- página de información de sus operaciones
- de los tableros
- datos
- integración de datos
- Lago de datos
- almacenamiento de datos
- basada en datos
- Estrategia basada en datos
- Base de datos
- bases de datos
- Fecha
- Fechas
- datetime
- día
- profundo
- bucear profundo
- Predeterminado
- definir
- entregamos
- demostrar
- departamentos
- Derivado
- describir
- Diseño
- diseño
- detalle
- dispositivo
- una experiencia diferente
- Dimensiones
- dimensiones
- discutir
- distinto
- do
- dominio
- hecho
- No
- DE INSCRIPCIÓN
- el lado de la transmisión
- duplicados
- cada una
- Más temprano
- pasan fácilmente
- de forma sencilla
- editor
- eficiente
- ya sea
- integrado
- habilitar
- permitiendo
- final
- de extremo a extremo
- participa
- ingeniero
- garantizar
- asegura
- asegurando que
- Todo
- entidad
- Éter (ETH)
- Evento
- Eventos
- Cada
- diario
- ejemplo
- ejemplos
- Expandir
- experience
- experimentado
- Exposición
- extraerlos
- hecho
- factor
- factores importantes
- hechos
- falla
- Fracaso
- Caracteristicas
- pocos
- campo
- Terrenos
- quinto
- Figura
- filtrar
- final
- Nombre
- primer vez
- cómodo
- centrado
- siguiendo
- formulario
- formato
- Digital XNUMXk
- Desde
- completamente
- promover
- futuras
- Obtén
- generar
- generado
- genera
- obtener
- conseguir
- Donar
- dado
- candidato
- gobierno
- Crecer
- práctico
- Tienen
- he
- más alto
- su
- histórico
- Vacaciones
- Cómo
- Como Hacer
- HTML
- http
- HTTPS
- AMI
- no haber aun identificado una solucion para el problema
- Identifique
- identificar
- Identidad
- if
- ilustra
- Impacto
- implementar
- implementado
- implementación
- importante
- mejorar
- la mejora de
- in
- Incluye
- India
- indicar
- indicando
- info
- Insights
- COMPLETAMENTE
- integración
- integridad
- Intelligence
- interactivo
- dentro
- IT
- SUS
- únete
- se unió a
- unión
- Une
- jpg
- Guardar
- acuerdo
- Clave
- claves
- lago
- idioma
- luego
- más reciente
- .
- izquierda
- Lente
- Permíteme
- Nivel
- línea
- carga
- carga
- cargas
- situados
- mirando
- hecho
- HACE
- gestionado
- Marketing
- emparejado
- sentido
- medir
- mencionado
- ir
- Métrica
- mente
- Error
- modelo
- modelado
- modelización
- modelos
- Mes
- más,
- MEJOR DE TU
- múltiples
- nombres
- Natural
- Navegar
- ¿ Necesita ayuda
- necesidad
- Nuevo
- Notas
- .
- notificaciones
- ahora
- numeroso
- ,
- of
- LANZAMIENTO
- a menudo
- on
- , solamente
- operativos.
- or
- organización
- nuestros
- Más de
- total
- parámetro
- parte
- apasionado
- para
- realizar
- actuación
- quizás
- periódico
- Colocar
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- punto
- poblado
- Publicación
- industria
- requisitos previos
- presente
- primario
- procedimientos
- procedimientos
- en costes
- Producto
- proporcionar
- previsto
- proporciona un
- público
- publicar
- fines
- Preguntas
- con rapidez
- aumento
- Crudo
- datos en bruto
- grabar
- archivos
- reducir
- referido
- refleja
- región
- relación
- permanece
- remove
- reemplazar
- reporte
- Informes
- Informes
- Requisitos
- Recursos
- responsabilidad
- Función
- Rodar
- FILA
- Ejecutar
- corre
- Venta
- ventas
- mismo
- Conjunto de datos de muestra
- escalable
- programa
- programación
- (secciones)
- sector
- EN LINEA
- ver
- separado
- sirve
- de coches
- Servicios
- sesiones
- set
- Varios
- tienes
- Mostrar
- Shows
- sencillos
- sencillez
- soltero
- Despacio
- chica
- menores
- Instantánea
- So
- vendido
- a medida
- algo
- Fuente
- Fuentes
- Espacio
- especialista
- soluciones y
- específicamente
- Etapa
- puesta en escena
- Estrella
- fundó
- Comience a
- Posicionamiento
- paso
- pasos
- STORAGE
- tienda
- almacenados
- estrategias
- Estrategia
- estructura
- exitosos
- Con éxito
- tal
- te
- mesa
- temporal
- tener
- términos
- que
- esa
- La
- La Fuente
- el mundo
- su
- luego
- Ahí.
- por lo tanto
- Estas
- ellos
- así
- miles
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- boleto
- venta de boletos
- entradas
- equipo
- veces
- fecha y hora
- recomendaciones
- a
- hoy
- juntos
- se
- Total
- seguir
- transaccional
- Transformar
- transformado
- viajero
- tipo
- tipos
- típicamente
- comprensión
- único
- únicamente
- unicidad
- desconocido
- Actualizar
- actualizado
- us
- Uso
- utilizan el
- caso de uso
- usado
- usuarios
- usos
- usando
- generalmente
- Valioso
- propuesta de
- Valores
- diversos
- Información
- lugares
- vía
- Ver
- volumen
- tutorial
- quieres
- Manejo de
- fue
- formas
- we
- web
- servicios web
- sitios web
- semana
- cuando
- que
- mientras
- seguirá
- dentro de
- sin
- trabajando
- mundo
- Mal
- año
- años
- Usted
- tú
- zephyrnet