La resiliencia juega un papel fundamental en el desarrollo de cualquier carga de trabajo, y IA generativa las cargas de trabajo no son diferentes. Existen consideraciones únicas al diseñar cargas de trabajo de IA generativa a través de una lente de resiliencia. Comprender y priorizar la resiliencia es crucial para que las cargas de trabajo de IA generativa cumplan con los requisitos de disponibilidad organizacional y continuidad del negocio. En esta publicación, analizamos las diferentes pilas de una carga de trabajo de IA generativa y cuáles deberían ser esas consideraciones.
IA generativa de pila completa
Aunque gran parte del entusiasmo en torno a la IA generativa se centra en los modelos, una solución completa involucra personas, habilidades y herramientas de varios dominios. Considere la siguiente imagen, que es una vista de AWS de la pila de aplicaciones emergentes a16z para modelos de lenguajes grandes (LLM).
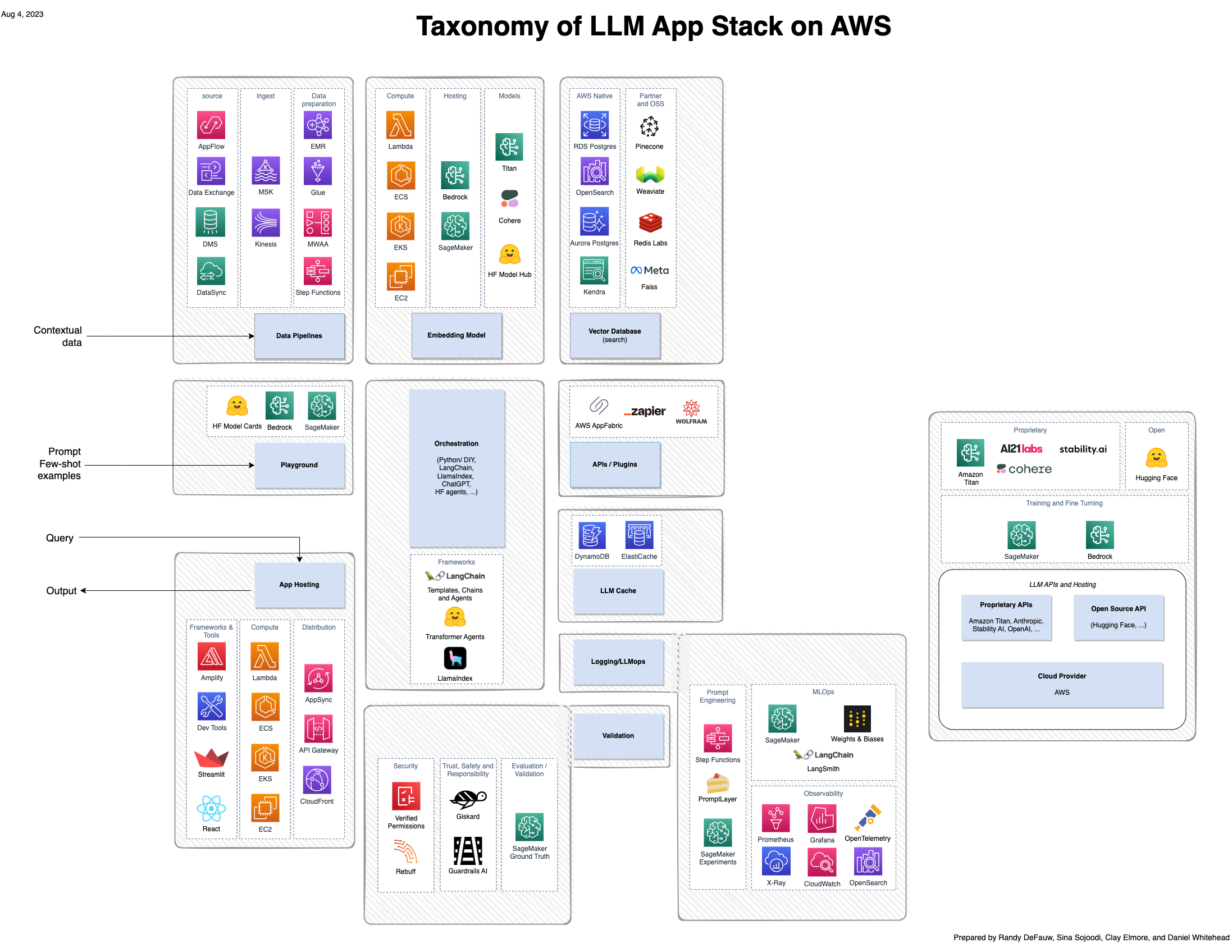
En comparación con una solución más tradicional basada en IA y aprendizaje automático (ML), una solución de IA generativa ahora implica lo siguiente:
- Nuevos roles – Debe considerar tanto a los sintonizadores de modelos como a los constructores e integradores de modelos.
- Nuevas herramientas – La pila tradicional de MLOps no se extiende para cubrir el tipo de seguimiento de experimentos u observabilidad necesarios para la ingeniería rápida o agentes que invocan herramientas para interactuar con otros sistemas.
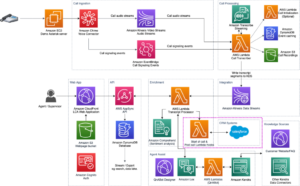
Razonamiento del agente
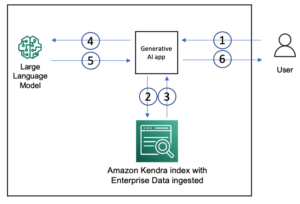
A diferencia de los modelos tradicionales de IA, la recuperación de generación aumentada (RAG) permite respuestas más precisas y contextualmente relevantes mediante la integración de fuentes de conocimiento externas. Las siguientes son algunas consideraciones al usar RAG:
- Establecer tiempos de espera adecuados es importante para la experiencia del cliente. Nada indica mejor una mala experiencia de usuario que estar en medio de un chat y desconectarse.
- Asegúrese de validar los datos de entrada de solicitud y el tamaño de entrada de solicitud para los límites de caracteres asignados definidos por su modelo.
- Si está realizando ingeniería de avisos, debe conservar sus avisos en un almacén de datos confiable. Esto protegerá sus indicaciones en caso de pérdida accidental o como parte de su estrategia general de recuperación ante desastres.
Canalizaciones de datos
En los casos en los que necesite proporcionar datos contextuales al modelo básico utilizando el patrón RAG, necesita una canalización de datos que pueda ingerir los datos de origen, convertirlos en vectores de incrustación y almacenar los vectores de incrustación en una base de datos de vectores. Esta canalización podría ser una canalización por lotes si prepara datos contextuales con anticipación, o una canalización de baja latencia si incorpora nuevos datos contextuales sobre la marcha. En el caso del lote, existen un par de desafíos en comparación con las canalizaciones de datos típicas.
Las fuentes de datos pueden ser documentos PDF en un sistema de archivos, datos de un sistema de software como servicio (SaaS), como una herramienta CRM, o datos de una wiki o base de conocimientos existente. La ingesta de estas fuentes es diferente de las fuentes de datos típicas, como los datos de registro en un Servicio de almacenamiento simple de Amazon (Amazon S3) o datos estructurados de una base de datos relacional. El nivel de paralelismo que puede lograr puede estar limitado por el sistema fuente, por lo que debe tener en cuenta la limitación y utilizar técnicas de retroceso. Algunos de los sistemas fuente pueden ser frágiles, por lo que es necesario incorporar el manejo de errores y la lógica de reintento.
El modelo integrado podría ser un cuello de botella en el rendimiento, independientemente de si lo ejecuta localmente en la canalización o llama a un modelo externo. Los modelos integrados son modelos básicos que se ejecutan en GPU y no tienen capacidad ilimitada. Si el modelo se ejecuta localmente, deberá asignar el trabajo según la capacidad de la GPU. Si el modelo se ejecuta externamente, debe asegurarse de no saturar el modelo externo. En cualquier caso, el nivel de paralelismo que puede lograr estará dictado por el modelo de integración y no por la cantidad de CPU y RAM que tenga disponibles en el sistema de procesamiento por lotes.
En el caso de baja latencia, es necesario tener en cuenta el tiempo que lleva generar los vectores de incrustación. La aplicación que llama debe invocar la canalización de forma asincrónica.
Bases de datos vectoriales
Una base de datos de vectores tiene dos funciones: almacenar vectores de incrustación y ejecutar una búsqueda de similitud para encontrar los más cercanos. k coincide con un nuevo vector. Hay tres tipos generales de bases de datos vectoriales:
- Opciones de SaaS dedicadas como Pinecone.
- Funciones de bases de datos vectoriales integradas en otros servicios. Esto incluye servicios nativos de AWS como Servicio Amazon OpenSearch y Aurora amazónica.
- Opciones en memoria que se pueden utilizar para datos transitorios en escenarios de baja latencia.
No cubrimos las capacidades de búsqueda de similitudes en detalle en esta publicación. Aunque son importantes, son un aspecto funcional del sistema y no afectan directamente la resiliencia. En cambio, nos centramos en los aspectos de resiliencia de una base de datos vectorial como sistema de almacenamiento:
- Estado latente – ¿Puede la base de datos vectorial funcionar bien frente a una carga elevada o impredecible? De lo contrario, la aplicación de llamada debe manejar la limitación de velocidad y retroceder y volver a intentarlo.
- Escalabilidad – ¿Cuántos vectores puede contener el sistema? Si excede la capacidad de la base de datos vectorial, deberá buscar fragmentación u otras soluciones.
- Alta disponibilidad y recuperación ante desastres – Los vectores de incrustación son datos valiosos y recrearlos puede resultar costoso. ¿Su base de datos vectorial tiene alta disponibilidad en una única región de AWS? ¿Tiene la capacidad de replicar datos en otra región con fines de recuperación ante desastres?
Nivel de aplicación
Hay tres consideraciones únicas para el nivel de aplicación al integrar soluciones de IA generativa:
- Latencia potencialmente alta – Los modelos Foundation a menudo se ejecutan en instancias de GPU grandes y pueden tener una capacidad finita. Asegúrese de utilizar las mejores prácticas para limitar la velocidad, retroceder y reintentar y deslastrar la carga. Utilice diseños asincrónicos para que la alta latencia no interfiera con la interfaz principal de la aplicación.
- Postura de seguridad – Si utiliza agentes, herramientas, complementos u otros métodos para conectar un modelo a otros sistemas, preste especial atención a su postura de seguridad. Los modelos pueden intentar interactuar con estos sistemas de formas inesperadas. Siga la práctica normal de acceso con privilegios mínimos, por ejemplo, restringiendo las indicaciones entrantes de otros sistemas.
- Marcos en rápida evolución – Los marcos de código abierto como LangChain están evolucionando rápidamente. Utilice un enfoque de microservicios para aislar otros componentes de estos marcos menos maduros.
Capacidad
Podemos pensar en la capacidad en dos contextos: inferencia y canales de datos de modelos de entrenamiento. La capacidad es una consideración cuando las organizaciones están construyendo sus propios canales. Los requisitos de CPU y memoria son dos de los mayores requisitos al elegir instancias para ejecutar sus cargas de trabajo.
Las instancias que pueden admitir cargas de trabajo de IA generativa pueden ser más difíciles de obtener que el tipo de instancia promedio de uso general. La flexibilidad de instancias puede ayudar con la capacidad y la planificación de la capacidad. Dependiendo de la región de AWS en la que esté ejecutando su carga de trabajo, hay diferentes tipos de instancias disponibles.
Para los recorridos de los usuarios que son críticos, las organizaciones querrán considerar reservar o aprovisionar previamente tipos de instancias para garantizar la disponibilidad cuando sea necesario. Este patrón logra una arquitectura estáticamente estable, que es una práctica recomendada de resiliencia. Para obtener más información sobre la estabilidad estática en el pilar de confiabilidad de AWS Well-Architected Framework, consulte Utilice la estabilidad estática para evitar el comportamiento bimodal.
Observabilidad
Además de las métricas de recursos que normalmente recopila, como la utilización de CPU y RAM, debe monitorear de cerca la utilización de GPU si aloja un modelo en Amazon SageMaker or Nube informática elástica de Amazon (Amazon EC2). La utilización de la GPU puede cambiar inesperadamente si el modelo base o los datos de entrada cambian, y quedarse sin memoria de la GPU puede poner el sistema en un estado inestable.
Más arriba en la pila, también querrás rastrear el flujo de llamadas a través del sistema, capturando las interacciones entre agentes y herramientas. Debido a que la interfaz entre agentes y herramientas está definida de manera menos formal que un contrato de API, debe monitorear estos seguimientos no solo para verificar el rendimiento sino también para capturar nuevos escenarios de error. Para monitorear el modelo o agente en busca de riesgos y amenazas de seguridad, puede usar herramientas como Servicio de guardia de Amazon.
También debe capturar líneas de base de vectores de incorporación, indicaciones, contexto y resultados, y las interacciones entre estos. Si estos cambian con el tiempo, puede indicar que los usuarios están usando el sistema de nuevas maneras, que los datos de referencia no cubren el espacio de preguntas de la misma manera o que el resultado del modelo es repentinamente diferente.
Recuperación de desastres
Tener un plan de continuidad del negocio con una estrategia de recuperación ante desastres es imprescindible para cualquier carga de trabajo. Las cargas de trabajo de IA generativa no son diferentes. Comprender los modos de falla que son aplicables a su carga de trabajo ayudará a guiar su estrategia. Si utiliza servicios administrados de AWS para su carga de trabajo, como lecho rocoso del amazonas y SageMaker, asegúrese de que el servicio esté disponible en su región de AWS de recuperación. Al momento de escribir este artículo, estos servicios de AWS no admiten la replicación de datos entre regiones de AWS de forma nativa, por lo que debe pensar en sus estrategias de administración de datos para la recuperación ante desastres y es posible que también deba realizar ajustes en varias regiones de AWS.
Conclusión
Esta publicación describió cómo tener en cuenta la resiliencia al crear soluciones de IA generativa. Aunque las aplicaciones de IA generativa tienen algunos matices interesantes, los patrones de resiliencia y las mejores prácticas existentes aún se aplican. Es sólo cuestión de evaluar cada parte de una aplicación de IA generativa y aplicar las mejores prácticas pertinentes.
Para obtener más información sobre la IA generativa y su uso con los servicios de AWS, consulte los siguientes recursos:
Acerca de los autores
 jennifer morán es un arquitecto senior de soluciones especialista en resiliencia de AWS con sede en la ciudad de Nueva York. Tiene una formación diversa, ha trabajado en muchas disciplinas técnicas, incluido el desarrollo de software, el liderazgo ágil y DevOps, y es una defensora de las mujeres en la tecnología. Le gusta ayudar a los clientes a diseñar soluciones resilientes para mejorar la postura de resiliencia y habla públicamente sobre todos los temas relacionados con la resiliencia.
jennifer morán es un arquitecto senior de soluciones especialista en resiliencia de AWS con sede en la ciudad de Nueva York. Tiene una formación diversa, ha trabajado en muchas disciplinas técnicas, incluido el desarrollo de software, el liderazgo ágil y DevOps, y es una defensora de las mujeres en la tecnología. Le gusta ayudar a los clientes a diseñar soluciones resilientes para mejorar la postura de resiliencia y habla públicamente sobre todos los temas relacionados con la resiliencia.
 Randy DeFauw es arquitecto principal de soluciones sénior en AWS. Tiene un MSEE de la Universidad de Michigan, donde trabajó en visión por computadora para vehículos autónomos. También tiene un MBA de la Universidad Estatal de Colorado. Randy ha ocupado diversos puestos en el ámbito tecnológico, desde ingeniería de software hasta gestión de productos. Entró en el espacio del big data en 2013 y continúa explorando esa área. Trabaja activamente en proyectos en el espacio ML y ha presentado en numerosas conferencias, incluidas Strata y GlueCon.
Randy DeFauw es arquitecto principal de soluciones sénior en AWS. Tiene un MSEE de la Universidad de Michigan, donde trabajó en visión por computadora para vehículos autónomos. También tiene un MBA de la Universidad Estatal de Colorado. Randy ha ocupado diversos puestos en el ámbito tecnológico, desde ingeniería de software hasta gestión de productos. Entró en el espacio del big data en 2013 y continúa explorando esa área. Trabaja activamente en proyectos en el espacio ML y ha presentado en numerosas conferencias, incluidas Strata y GlueCon.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/designing-generative-ai-workloads-for-resilience/
- :posee
- :es
- :no
- :dónde
- $ UP
- 100
- 2013
- 90
- a
- a16z
- capacidad
- Nuestra Empresa
- de la máquina
- accidentalmente
- Mi Cuenta
- preciso
- Lograr
- Logra
- a través de
- activamente
- avanzar
- defensor
- afectar
- en contra
- Agente
- agentes
- ágil
- AI
- Modelos AI
- Todos
- asignado
- permite
- también
- Aunque
- Amazon
- Amazon EC2
- Amazon Web Services
- an
- y
- Otra
- cualquier
- abejas
- applicación
- aplicable
- Aplicación
- aplicaciones
- Aplicá
- La aplicación de
- enfoque
- adecuado
- arquitectura
- somos
- Reservada
- en torno a
- AS
- aspecto
- aspectos
- At
- aumentado
- autónomo
- vehículos autónomos
- disponibilidad
- Hoy Disponibles
- promedio
- AWS
- fondo
- Malo
- bases
- basado
- BE
- porque
- "Ser"
- MEJOR
- y las mejores prácticas
- entre
- Big
- Big Data
- Mayor
- embotellamiento
- build
- constructores
- Construir la
- construido
- continuidad del negocio
- pero
- by
- llamar al
- llamar
- Calls
- PUEDEN
- capacidades
- Capacidad
- capturar
- Capturando
- case
- cases
- retos
- el cambio
- Cambios
- personaje
- chat
- la elección de
- Ciudad
- de cerca
- recoger
- Colorado
- en comparación con
- completar
- componentes
- Calcular
- computadora
- Visión por computador
- conferencias
- Conectándote
- Considerar
- consideración
- consideraciones
- contexto
- contextos
- contextual
- continúa
- continuidad
- contrato
- convertir
- podría
- Parejas
- Protectora
- cubierta
- CPU
- crítico
- CRM
- crucial
- cliente
- experiencia del cliente
- Clientes
- datos
- datos de gestión
- Base de datos
- bases de datos
- se define
- Dependiente
- descrito
- Diseño
- diseño
- diseños
- detalle
- Desarrollo
- DevOps
- dictado
- una experiencia diferente
- difícil
- directamente
- desastre
- disciplinas
- desconectado
- discutir
- diverso
- do
- documentos
- sí
- No
- dominios
- No
- cada una
- ya sea
- incrustación
- emergentes
- Ingeniería
- garantizar
- entrado
- error
- Éter (ETH)
- evaluación
- evolución
- ejemplo
- exceden
- Emoción
- existente
- costoso
- experience
- experimento
- explorar
- ampliar
- externo
- externamente
- extra
- Fracaso
- Caracteristicas
- Archive
- Encuentre
- Flexibilidad
- de tus señales
- Focus
- se centra
- seguir
- siguiendo
- Formalmente
- Fundación
- Marco conceptual
- marcos
- Desde
- funcional
- funciones
- General
- propósito general
- generar
- generación de AHSS
- generativo
- IA generativa
- conseguir
- GPU
- GPU
- guía
- encargarse de
- Manejo
- Tienen
- es
- he
- Retenida
- ayuda
- ayudando
- Alta
- altamente
- mantener
- mantiene
- fortaleza
- Cómo
- Como Hacer
- HTML
- http
- HTTPS
- if
- importante
- mejorar
- in
- incluye
- Incluye
- Entrante
- incorporando
- indicar
- información
- Las opciones de entrada
- ejemplo
- instancias
- Integración
- interactuar
- interacciones
- interesante
- Interfaz
- interferir
- dentro
- implica
- IT
- Viajes
- solo
- especialistas
- idioma
- large
- Estado latente
- Liderazgo
- APRENDE:
- aprendizaje
- Lente
- menos
- Nivel
- como
- Limitada
- limitar
- límites
- llm
- carga
- localmente
- log
- lógica
- Mira
- de
- Lote
- máquina
- máquina de aprendizaje
- Inicio
- para lograr
- gestionado
- Management
- muchos
- cerillas
- Materia
- un estudiante adulto
- Puede..
- MBA
- Conoce a
- Salud Cerebral
- métodos
- Métrica
- Michigan
- microservicios
- Ed. Media
- ML
- MLOps
- modelo
- modelos
- los modos
- Monitorear
- más,
- mucho más
- múltiples
- debe
- nativo
- nativamente
- necesario
- ¿ Necesita ayuda
- Nuevo
- New York
- Ciudad de Nueva York
- no
- normal
- nada
- ahora
- matices
- numeroso
- obtener
- of
- a menudo
- on
- , solamente
- habiertos
- de código abierto
- Opciones
- or
- organizativo
- para las fiestas.
- Otro
- salir
- salida
- Más de
- total
- EL DESARROLLADOR
- parte
- Patrón de Costura
- .
- Pagar
- (PDF)
- Personas
- realizar
- actuación
- realizar
- imagen
- Pillar
- industrial
- esencial
- plan
- planificar
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- juega
- plugins
- abiertas
- Publicación
- prácticas
- Preparar
- presentó
- evitar
- Director de la escuela
- priorización
- tratamiento
- Producto
- gestión de producto
- proyecta
- ideas
- proporcionar
- en público
- fines
- poner
- pregunta
- trapo
- RAM
- que van
- rápidamente
- Rate
- más bien
- recuperación
- remitir
- referencia
- Independientemente
- región
- regiones
- relacionado
- fiabilidad
- confianza
- replicación
- Requisitos
- resiliencia y se la estamos enseñando a nuestro hijos e hijas.
- resistente
- Recurso
- Recursos
- respuestas
- restringiendo
- recuperación
- riesgos
- Función
- Ejecutar
- correr
- corre
- SaaS
- sabio
- mismo
- dice
- escenarios
- Buscar
- búsqueda
- EN LINEA
- los riesgos de seguridad
- mayor
- de coches
- Servicios
- Varios
- sharding
- ella
- derramamiento
- tienes
- sencillos
- soltero
- Tamaño
- habilidades
- So
- Software
- software como servicio
- Desarrollo de software ad-hoc
- Ingeniería de software
- a medida
- Soluciones
- algo
- Fuente
- Fuentes
- Espacio
- Habla
- especialista
- Estabilidad
- estable
- montón
- Stacks
- Estado
- Sin embargo
- STORAGE
- tienda
- estrategias
- Estrategia
- estructurado
- tal
- SOPORTE
- seguro
- te
- Todas las funciones a su disposición
- ¡Prepárate!
- toma
- taxonomía
- tecnología
- Técnico
- técnicas
- Tecnología
- que
- esa
- El
- La Fuente
- su
- Les
- Ahí.
- Estas
- ellos
- pensar
- así
- aquellos
- amenazas
- Tres
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- nivel
- equipo
- a
- del IRS
- Temas
- rastrear
- Seguimiento
- tradicional
- Formación
- try
- dos
- tipo
- tipos
- principiante
- típicamente
- comprensión
- Inesperado
- único
- universidad
- Universidad de Michigan
- ilimitado
- imprevisible
- utilizan el
- usado
- Usuario
- experiencia como usuario
- usuarios
- usando
- VALIDAR
- Valioso
- variedad
- Vehículos
- Ver
- visión
- quieres
- Camino..
- formas
- we
- web
- servicios web
- WELL
- ¿
- cuando
- sean
- que
- seguirá
- Mujeres
- mujeres en tecnología
- Actividades:
- trabajado
- trabajando
- la escritura
- york
- Usted
- tú
- zephyrnet