En el entorno empresarial actual basado en datos, las organizaciones enfrentan el desafío de preparar y transformar de manera eficiente grandes cantidades de datos para fines analíticos y de ciencia de datos. Las empresas necesitan construir almacenes de datos y lagos de datos basados en datos operativos. Esto se debe a la necesidad de centralizar e integrar datos provenientes de fuentes dispares.
Al mismo tiempo, los datos operativos a menudo se originan en aplicaciones respaldadas por almacenes de datos heredados. La modernización de las aplicaciones requiere una arquitectura de microservicios, que a su vez requiere la consolidación de datos de múltiples fuentes para construir un almacén de datos operativo. Sin la modernización, las aplicaciones heredadas pueden incurrir en costos de mantenimiento cada vez mayores. La modernización de las aplicaciones implica cambiar el motor de base de datos subyacente a una base de datos moderna basada en documentos como MongoDB.
Estas dos tareas (construir lagos de datos o almacenes de datos y modernización de aplicaciones) implican el movimiento de datos, que utiliza un proceso de extracción, transformación y carga (ETL). El trabajo de ETL es una funcionalidad clave para tener un proceso bien estructurado para tener éxito.
Pegamento AWS es un servicio de integración de datos sin servidor que facilita descubrir, preparar, mover e integrar datos de múltiples fuentes para análisis, aprendizaje automático (ML) y desarrollo de aplicaciones. Atlas de MongoDB es un conjunto integrado de servicios de datos y bases de datos en la nube que combina procesamiento transaccional, búsqueda basada en relevancia, análisis en tiempo real y sincronización de datos de dispositivos móviles a la nube en una arquitectura elegante e integrada.
Al usar AWS Glue con MongoDB Atlas, las organizaciones pueden optimizar sus procesos de ETL. Con su solución de base de datos completamente administrada, escalable y segura, MongoDB Atlas proporciona un entorno flexible y confiable para almacenar y administrar datos operativos. Juntos, AWS Glue ETL y MongoDB Atlas son una solución poderosa para las organizaciones que buscan optimizar la forma en que construyen lagos de datos y almacenes de datos, y modernizar sus aplicaciones para mejorar el rendimiento comercial, reducir costos e impulsar el crecimiento y el éxito.
En esta publicación, demostramos cómo migrar datos de Servicio de almacenamiento simple de Amazon (Amazon S3) a MongoDB Atlas usando AWS Glue ETL, y cómo extraer datos de MongoDB Atlas en un lago de datos basado en Amazon S3.
Resumen de la solución
En esta publicación, exploramos los siguientes casos de uso:
- Extrayendo datos de MongoDB – MongoDB es una base de datos popular utilizada por miles de clientes para almacenar datos de aplicaciones a escala. Los clientes empresariales pueden centralizar e integrar datos provenientes de múltiples almacenes de datos mediante la creación de lagos de datos y almacenes de datos. Este proceso implica la extracción de datos de los almacenes de datos operativos. Cuando los datos están en un solo lugar, los clientes pueden usarlos rápidamente para necesidades de inteligencia comercial o para ML.
- Ingerir datos en MongoDB – MongoDB también sirve como una base de datos no SQL para almacenar datos de aplicaciones y crear almacenes de datos operativos. La modernización de las aplicaciones a menudo implica la migración del almacén operativo a MongoDB. Los clientes necesitarían extraer datos existentes de bases de datos relacionales o de archivos planos. Las aplicaciones móviles y web a menudo requieren que los ingenieros de datos construyan canalizaciones de datos para crear una vista única de los datos en Atlas mientras ingiere datos de múltiples fuentes en silos. Durante esta migración, tendrían que unirse a diferentes bases de datos para crear documentos. Esta compleja operación de combinación necesitaría una potencia de cálculo importante y única. Los desarrolladores también tendrían que crear esto rápidamente para migrar los datos.
AWS Glue es útil en estos casos con el modelo de pago por uso y su capacidad para ejecutar transformaciones complejas en grandes conjuntos de datos. Los desarrolladores pueden usar AWS Glue Studio para crear de manera eficiente dichas canalizaciones de datos.
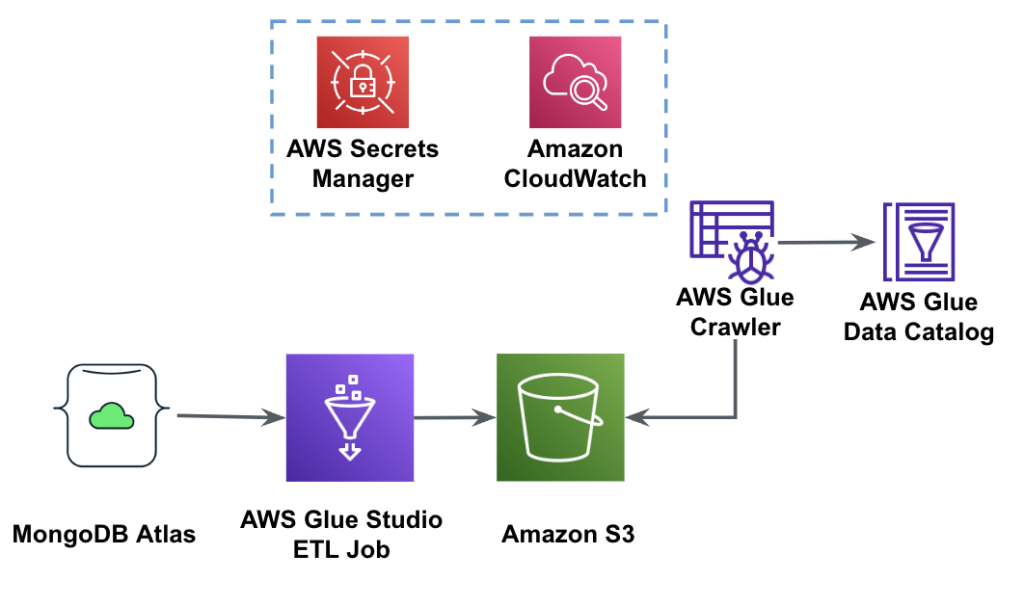
El siguiente diagrama muestra el flujo de trabajo de extracción de datos de MongoDB Atlas en un depósito S3 mediante AWS Glue Studio.
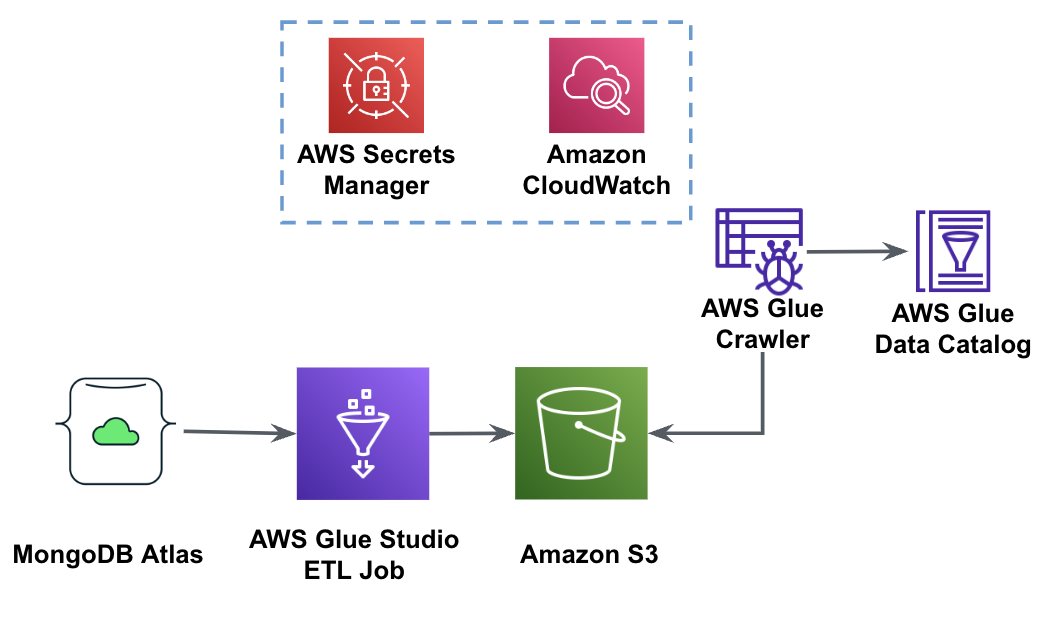
Para implementar esta arquitectura, necesitará un clúster MongoDB Atlas, un depósito S3 y un Gestión de identidades y accesos de AWS (IAM) rol para AWS Glue. Para configurar estos recursos, consulte los pasos de requisitos previos en el siguiente Repositorio GitHub.
La siguiente figura muestra el flujo de trabajo de carga de datos desde un depósito S3 en MongoDB Atlas mediante AWS Glue.
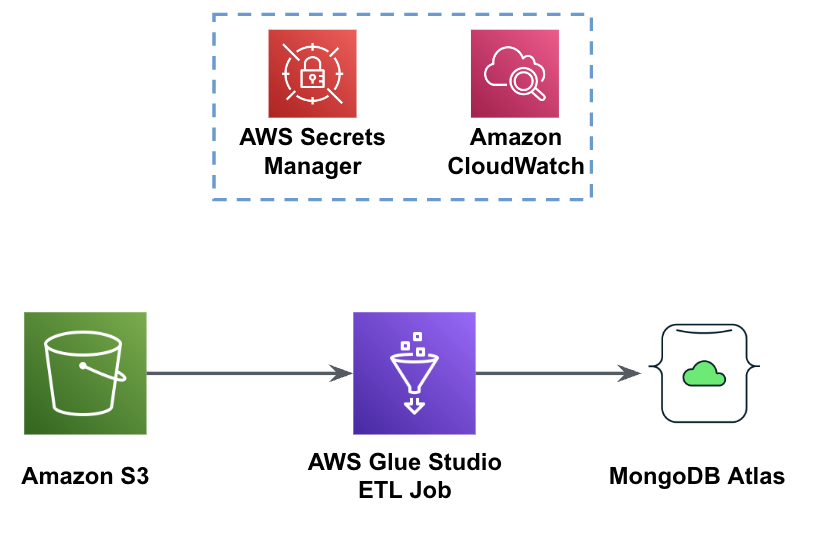
Aquí se necesitan los mismos requisitos previos: un depósito S3, un rol de IAM y un clúster de MongoDB Atlas.
Cargue datos de Amazon S3 a MongoDB Atlas usando AWS Glue
Los siguientes pasos describen cómo cargar datos del depósito S3 en MongoDB Atlas mediante un trabajo de AWS Glue. El proceso de extracción de MongoDB Atlas a Amazon S3 es muy similar, con la excepción del script que se utiliza. Destacamos las diferencias entre los dos procesos.
- Crear un clúster gratuito en MongoDB Atlas.
- Cargar la archivo JSON de muestra a su cubo S3.
- Cree un nuevo trabajo de AWS Glue Studio con el Editor de secuencias de comandos de chispa .

- Dependiendo de si desea cargar o extraer datos del clúster de MongoDB Atlas, ingrese el cargar secuencia de comandos or extraer secuencia de comandos en el editor de secuencias de comandos de AWS Glue Studio.
La siguiente captura de pantalla muestra un fragmento de código para cargar datos en el clúster de MongoDB Atlas.

El código usa Director de secretos de AWS para recuperar el nombre del clúster, el nombre de usuario y la contraseña de MongoDB Atlas. Entonces, crea un DynamicFrame para el depósito de S3 y el nombre del archivo pasado al script como parámetros. El código recupera los nombres de la base de datos y la colección de la configuración de parámetros del trabajo. Finalmente, el código escribe el DynamicFrame al clúster de MongoDB Atlas utilizando los parámetros recuperados.
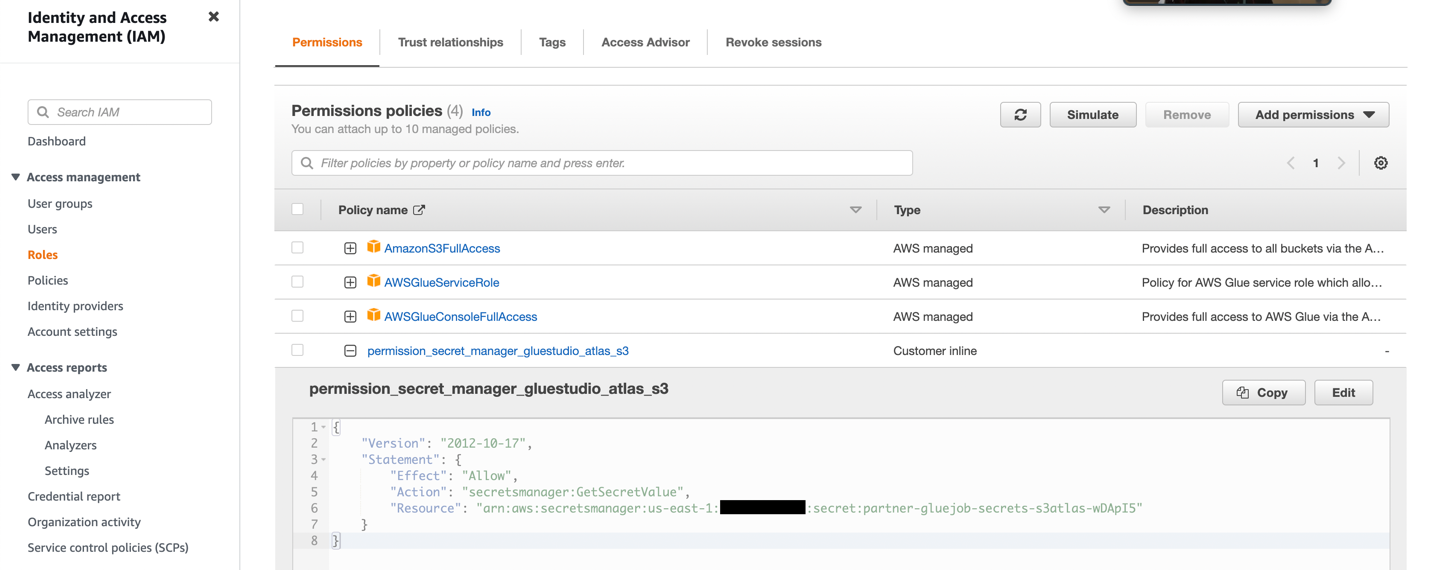
- Cree un rol de IAM con los permisos que se muestran en la siguiente captura de pantalla.
Para más detalles, consulte Configure un rol de IAM para su trabajo de ETL.
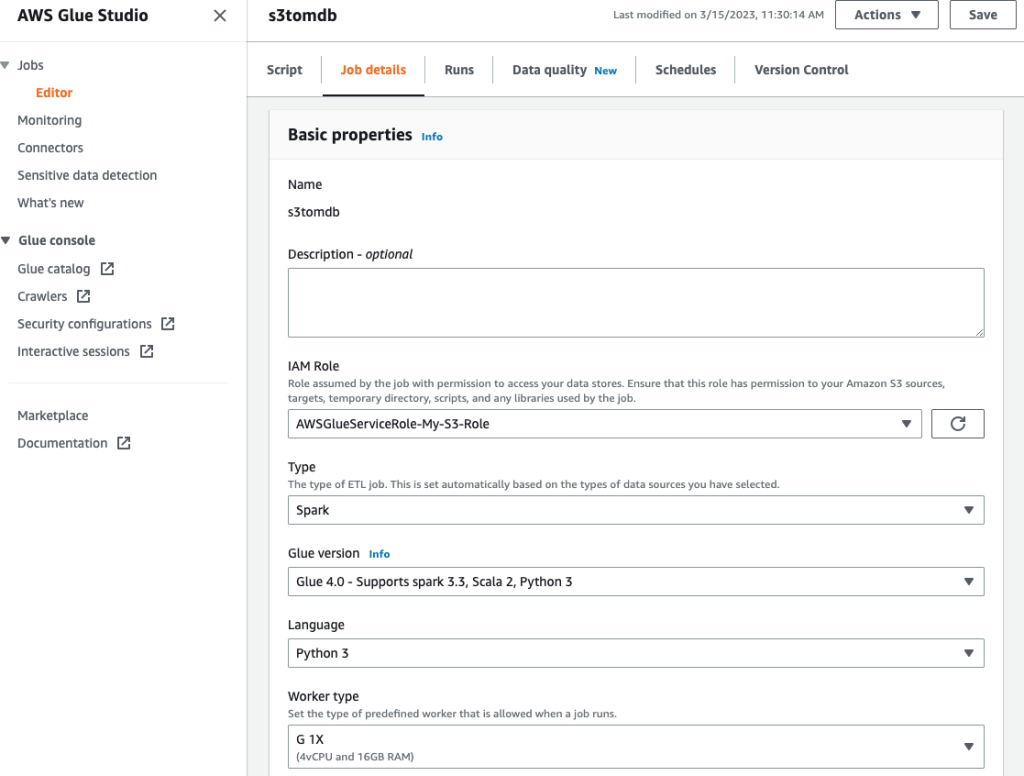
- Asigne un nombre al trabajo y proporcione el rol de IAM creado en el paso anterior en el Detalles del trabajo .
- Puede dejar el resto de los parámetros por defecto, como se muestra en las siguientes capturas de pantalla.
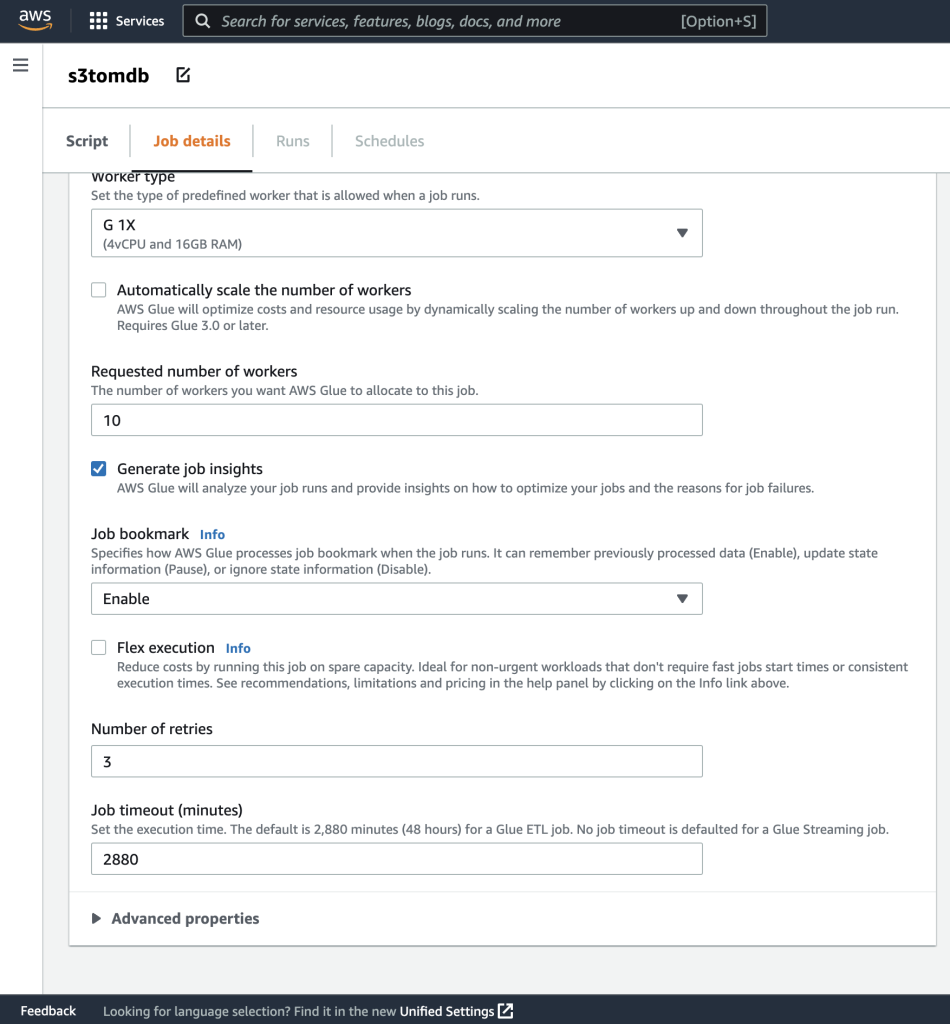
- A continuación, defina los parámetros de trabajo que utiliza el script y proporcione los valores predeterminados.
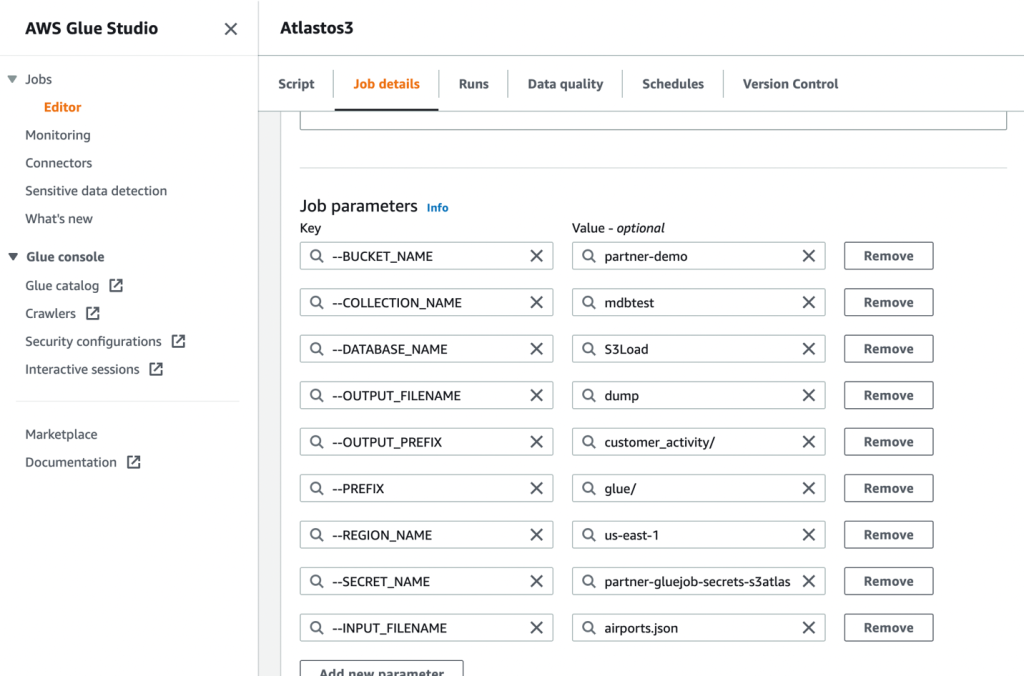
- Guarde el trabajo y ejecútelo.
- Para confirmar una ejecución exitosa, observe el contenido de la recopilación de la base de datos de MongoDB Atlas si está cargando los datos, o el depósito S3 si estaba realizando una extracción.



La siguiente captura de pantalla muestra los resultados de una carga de datos exitosa desde un depósito de Amazon S3 en el clúster de MongoDB Atlas. Los datos ahora están disponibles para consultas en la interfaz de usuario de MongoDB Atlas.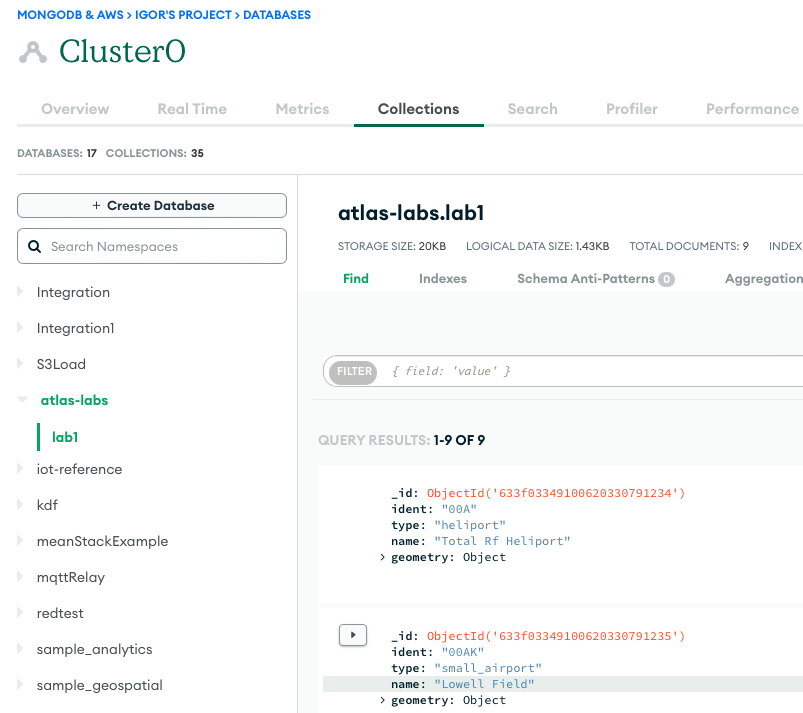
- Para solucionar los problemas de sus ejecuciones, revise la Reloj en la nube de Amazon registros usando el enlace en el trabajo Ejecutar .
La siguiente captura de pantalla muestra que el trabajo se ejecutó correctamente, con detalles adicionales, como enlaces a los registros de CloudWatch.

Conclusión
En esta publicación, describimos cómo extraer e ingerir datos en MongoDB Atlas utilizando AWS Glue.
Con los trabajos ETL de AWS Glue, ahora podemos transferir los datos de MongoDB Atlas a fuentes compatibles con AWS Glue y viceversa. También puede ampliar la solución para crear análisis mediante los servicios de IA y ML de AWS.
Para obtener más información, consulte el Repositorio GitHub para obtener instrucciones paso a paso y código de muestra. puedes adquirir Atlas de MongoDB en el mercado de AWS.
Acerca de los autores

Igor Alekseev es socio sénior de arquitectura de soluciones en AWS en el dominio de datos y análisis. En su función, Igor está trabajando con socios estratégicos ayudándolos a construir arquitecturas complejas optimizadas para AWS. Antes de unirse a AWS, como arquitecto de soluciones/datos, implementó muchos proyectos en el dominio de Big Data, incluidos varios lagos de datos en el ecosistema de Hadoop. Como ingeniero de datos, participó en la aplicación de AI/ML a la detección de fraudes y la automatización de oficinas.
 Babu Srinivasan es Arquitecto de Soluciones de Socio Senior en MongoDB. En su puesto actual, trabaja con AWS para crear integraciones técnicas y arquitecturas de referencia para las soluciones de AWS y MongoDB. Cuenta con más de dos décadas de experiencia en tecnologías de Base de Datos y Nube. Le apasiona brindar soluciones técnicas a los clientes que trabajan con múltiples integradores de sistemas globales (GSI) en múltiples geografías.
Babu Srinivasan es Arquitecto de Soluciones de Socio Senior en MongoDB. En su puesto actual, trabaja con AWS para crear integraciones técnicas y arquitecturas de referencia para las soluciones de AWS y MongoDB. Cuenta con más de dos décadas de experiencia en tecnologías de Base de Datos y Nube. Le apasiona brindar soluciones técnicas a los clientes que trabajan con múltiples integradores de sistemas globales (GSI) en múltiples geografías.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Compra y Vende Acciones en Empresas PRE-IPO con PREIPO®. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/compose-your-etl-jobs-for-mongodb-atlas-with-aws-glue/
- :posee
- :es
- 100
- 11
- a
- capacidad
- Nuestra Empresa
- de la máquina
- a través de
- Adicionales
- AI
- AI / ML
- también
- Amazon
- cantidades
- an
- Analytics
- y
- Aplicación
- Desarrollo de aplicaciones
- aplicaciones
- La aplicación de
- aplicaciones
- arquitectura
- somos
- AS
- At
- atlas
- Automatización
- Hoy Disponibles
- AWS
- Pegamento AWS
- AWS Marketplace
- Respaldados
- basado
- "Ser"
- entre
- Big
- Big Data
- build
- Construir la
- inteligencia empresarial
- el rendimiento del negocio
- negocios
- by
- llamar al
- PUEDEN
- cases
- Reto
- cambio
- Soluciones
- Médico
- código
- --
- combina
- proviene
- viniendo
- integraciones
- Calcular
- Configuración
- Confirmar
- consolidación
- construir
- contenido
- continuado
- Precio
- Para crear
- creado
- crea
- creación
- Current
- Clientes
- datos
- ingeniero de datos
- integración de datos
- Lago de datos
- Ciencia de los datos
- almacenes de datos
- basada en datos
- Base de datos
- bases de datos
- conjuntos de datos
- décadas
- Predeterminado
- demostrar
- describir
- descrito
- detalles
- Detección
- desarrolladores
- Desarrollo
- diferencias
- una experiencia diferente
- descrubrir
- dispar
- documentos
- dominio
- el lado de la transmisión
- impulsados
- durante
- ecosistema
- editor
- eficiente.
- Motor
- ingeniero
- certificados
- Participar
- Empresa
- clientes empresariales
- Entorno
- Éter (ETH)
- excepción
- existente
- experience
- explorar
- ampliar
- extraerlos
- Extracción
- Cara
- Figura
- Archive
- archivos
- Finalmente
- plano
- flexible
- siguiendo
- fraude
- detección de fraude
- Gratuito
- en
- completamente
- a la fatiga
- geografías
- Buscar
- Crecimiento
- Hadoop
- práctico
- es
- he
- ayudando
- esta página
- su
- Cómo
- Como Hacer
- HTML
- http
- HTTPS
- enorme
- AMI
- Identidad
- if
- implementar
- implementado
- mejorar
- in
- Incluye
- creciente
- Las opciones de entrada
- Instrucciones
- integrar
- COMPLETAMENTE
- integración
- integraciones
- Intelligence
- dentro
- involucrar
- involucra
- IT
- SUS
- Trabajos
- Empleo
- únete
- unión
- json
- Clave
- lago
- large
- APRENDE:
- aprendizaje
- Abandonar
- Legado
- como
- LINK
- enlaces
- carga
- carga
- mirando
- máquina
- máquina de aprendizaje
- un mejor mantenimiento.
- HACE
- gestionado
- administrar
- muchos
- mercado
- Puede..
- migrado
- migración
- ML
- Móvil
- modelo
- Moderno
- modernización
- modernizar
- MongoDB
- más,
- movimiento
- movimiento
- múltiples
- nombre
- nombres
- ¿ Necesita ayuda
- Nuevo
- ahora
- observar
- of
- Oficina
- a menudo
- on
- ONE
- Inteligente
- operativos.
- Optimización
- Optión
- or
- solicite
- para las fiestas.
- salir
- parámetros
- Socio
- socios
- pasado
- apasionado
- Contraseña
- actuación
- realizar
- permisos
- Colocar
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- Popular
- Publicación
- industria
- poderoso
- Preparar
- preparación
- requisitos previos
- anterior
- Anterior
- en costes
- tratamiento
- proyecta
- proporciona un
- proporcionando
- fines
- consultas
- con rapidez
- en tiempo real
- reducir
- confianza
- exigir
- requiere
- Recursos
- RESTO
- Resultados
- una estrategia SEO para aparecer en las búsquedas de Google.
- Función
- Ejecutar
- mismo
- escalable
- Escala
- Ciencia:
- capturas de pantalla
- Buscar
- seguro
- mayor
- Sin servidor
- sirve
- de coches
- Servicios
- Varios
- mostrado
- Shows
- importante
- similares
- sencillos
- soltero
- a medida
- Soluciones
- Fuentes
- paso
- pasos
- STORAGE
- tienda
- tiendas
- sencillo
- Estratégico
- socios estratégicos
- aerodinamizar
- estudio
- tener éxito
- comercial
- exitosos
- Con éxito
- tal
- suite
- suministro
- sincronización
- te
- tareas
- Técnico
- Tecnologías
- que
- esa
- El
- su
- Les
- luego
- Estas
- ellos
- así
- miles
- equipo
- a
- de hoy
- juntos
- transaccional
- transferir
- Transformar
- transformaciones
- transformadora
- GIRO
- dos
- ui
- subyacente
- utilizan el
- usado
- Usuario
- usando
- Valores
- muy
- Ver
- quieres
- fue
- we
- web
- tuvieron
- cuando
- sean
- que
- mientras
- seguirá
- sin
- flujo de trabajo
- trabajando
- se
- Usted
- tú
- zephyrnet