Bienvenido a la era de los datos. El gran volumen de datos capturados diariamente continúa creciendo, lo que exige que las plataformas y las soluciones evolucionen. Servicios como Servicio de almacenamiento simple de Amazon (Amazon S3) ofrecen una solución escalable que se adapta y sigue siendo rentable para conjuntos de datos en crecimiento. El Iniciativa de datos de sostenibilidad de Amazon (ASDI) utiliza las capacidades de Amazon S3 para proporcionar una solución sin costo para almacenar y compartir cargas de trabajo de ciencia climática en todo el mundo. El Programa de patrocinio de datos abiertos de Amazon permite a las organizaciones hospedar sin cargo en AWS.
Durante la última década, hemos visto un aumento en los marcos de ciencia de datos que se están materializando, junto con la adopción masiva por parte de la comunidad de ciencia de datos. Uno de esos marcos es Tablero, que es poderoso por su capacidad para aprovisionar una orquestación de nodos de cómputo de trabajadores, lo que acelera el análisis complejo en grandes conjuntos de datos.
En esta publicación, le mostramos cómo implementar una Kit de desarrollo en la nube de AWS (AWS CDK) que amplía la funcionalidad de Dask para trabajar entre regiones a través de la red global de Amazon. La solución AWS CDK implementa una red de trabajadores de Dask en dos regiones de AWS, conectándose a una región cliente. Para obtener más información, consulte Orientación para la computación distribuida con Cross Regional Dask en AWS y del Repositorio GitHub para el código fuente abierto.
Después de la implementación, el usuario tendrá acceso a un cuaderno Jupyter, donde podrá interactuar con dos conjuntos de datos de ASDI en AWS: Proyecto de intercomparación de modelos acoplados 6 (CMIP6) y Reanálisis ECMWF ERA5. La CMIP6 se centra en la sexta fase del conjunto de modelos de circulación general océano-atmósfera acoplados a nivel mundial; ERA5 es la quinta generación de reanálisis atmosférico del ECMWF del clima global y el primer reanálisis producido como un servicio operativo.
Esta solución se inspiró en el trabajo con un cliente clave de AWS, el Oficina Meteorológica del Reino Unido. La Met Office fue fundada en 1854 y es el servicio meteorológico nacional del Reino Unido. Brindan predicciones meteorológicas y climáticas para ayudarlo a tomar mejores decisiones para mantenerse seguro y prosperar. Una colaboración entre Met Office y EUMETSAT, detallada en Cómputo próximo de datos en un clúster de Dask distribuido entre centros de datos, destaca la creciente necesidad de desarrollar una solución de ciencia de datos sostenible, eficiente y escalable. Esta solución logra esto al acercar la computación a los datos, en lugar de obligar a los datos a acercarse a los recursos de computación, lo que agrega costos, latencia y energía.
Resumen de la solución
Cada día, la Oficina Meteorológica del Reino Unido produce hasta 300 TB de datos meteorológicos y climáticos, una parte de los cuales se publica en ASDI. Estos conjuntos de datos se distribuyen en todo el mundo y se alojan para uso público. Met Office desea permitir que los consumidores aprovechen al máximo sus datos para ayudar a informar decisiones críticas sobre cómo abordar problemas como una mejor preparación para incendios forestales e inundaciones inducidos por el cambio climático y la reducción de la inseguridad alimentaria a través de un mejor análisis del rendimiento de los cultivos.
Las soluciones tradicionales en uso hoy en día, particularmente con datos climáticos, consumen mucho tiempo y son insostenibles, ya que replican conjuntos de datos entre regiones. La transferencia de datos innecesaria en la escala de petabytes es costosa, lenta y consume energía.
Estimamos que si los usuarios de Met Office adoptaran esta práctica, se podría ahorrar el equivalente al consumo de energía diario de 40 hogares, y también se podría reducir la transferencia de datos entre regiones.
El siguiente diagrama ilustra la arquitectura de la solución.
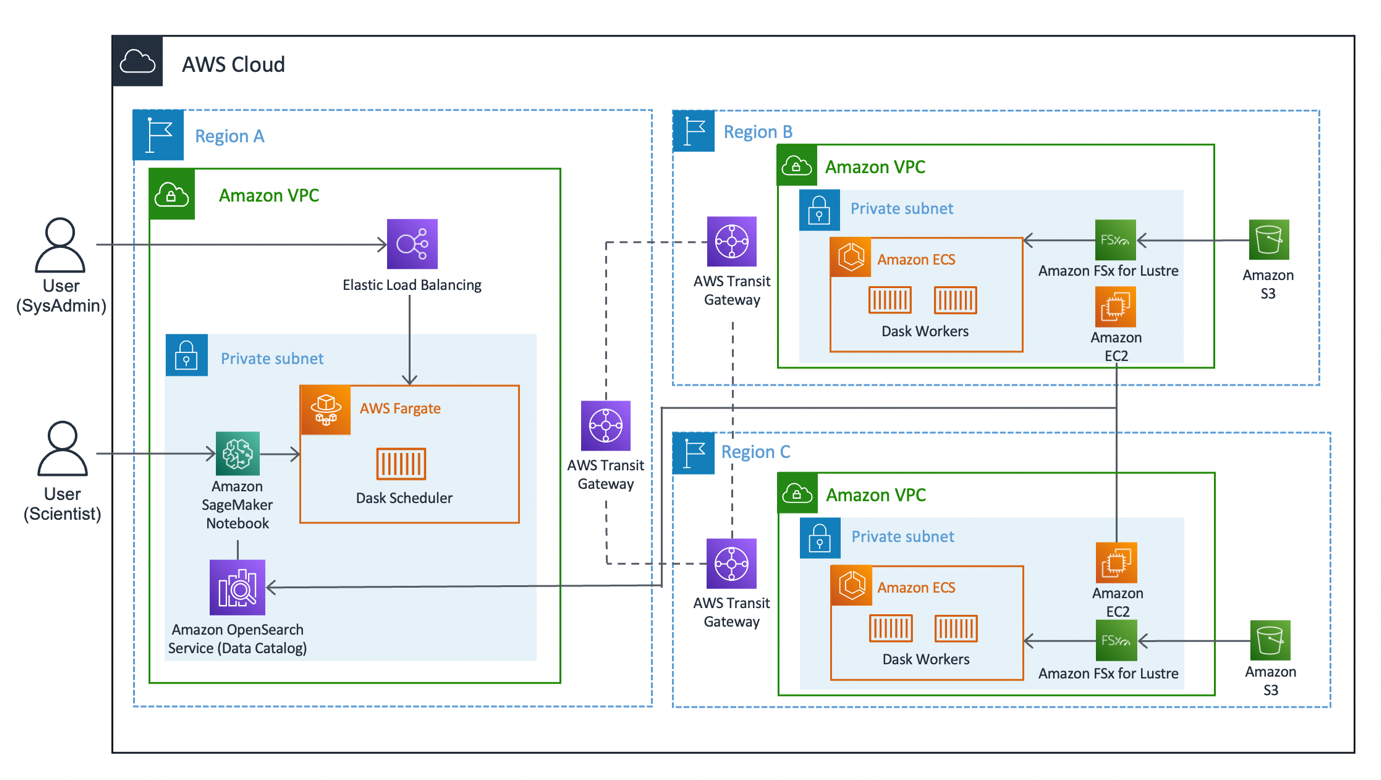
La solución se puede dividir en tres segmentos principales: cliente, trabajadores y red. Profundicemos en cada uno y veamos cómo se juntan.
Cliente
El cliente representa la región de origen donde se conectan los científicos de datos. Esta Región (Región A en el diagrama) contiene una Cuaderno de Amazon SageMaker, un Servicio Amazon OpenSearch dominio y un programador de escritorio como componentes clave. Los administradores del sistema tienen acceso al panel de Dask incorporado expuesto a través de un Balanceador de carga elástico.
Los científicos de datos tienen acceso al cuaderno Jupyter alojado en SageMaker. El portátil puede conectarse y ejecutar cargas de trabajo en el programador de Dask. El dominio del servicio OpenSearch almacena metadatos en los conjuntos de datos conectados en las regiones. Los usuarios de portátiles pueden consultar este servicio para recuperar detalles como la región correcta de los trabajadores de Dask sin necesidad de conocer la ubicación regional de los datos de antemano.
Trabajador
Cada una de las Regiones del trabajador (Regiones B y C en el diagrama) se compone de un Servicio de contenedor elástico de Amazon (Amazon ECS) grupo de trabajadores de escritorio, un Amazon FSx para Lustre sistema de archivos y un sistema independiente Nube informática elástica de Amazon (Amazon EC2) instancia. FSx for Lustre permite a los trabajadores de Dask acceder y procesar datos de Amazon S3 desde un sistema de archivos de alto rendimiento al vincular sus sistemas de archivos a depósitos S3. Proporciona latencias de submilisegundos, hasta cientos de GB/s de rendimiento y millones de IOPS. Una característica clave de Lustre es que solo se sincronizan los metadatos del sistema de archivos. Lustre administra el saldo de archivos que se cargarán y mantendrán calientes, según la demanda.
Los clústeres de trabajadores se escalan en función del uso de la CPU, aprovisionan trabajadores adicionales en períodos prolongados de demanda y se reducen a medida que los recursos quedan inactivos.
Cada noche a las 0:00 UTC, un trabajo de sincronización de datos solicita al sistema de archivos de Lustre que vuelva a sincronizarse con el depósito de S3 adjunto y extrae un catálogo de metadatos actualizado del depósito. Posteriormente, la instancia EC2 independiente envía estas actualizaciones al servicio OpenSearch correspondiente al índice de esa región. OpenSearch Service proporciona la información necesaria al cliente en cuanto a qué grupo de trabajadores se debe llamar para un conjunto de datos en particular.
Nuestra red
La red constituye el quid de esta solución, utilizando la red troncal interna de Amazon. Mediante el uso Pasarela de tránsito de AWS, podemos conectar cada una de las Regiones entre sí sin necesidad de atravesar la Internet pública. Cada uno de los trabajadores puede conectarse dinámicamente al programador de Dask, lo que permite a los científicos de datos ejecutar consultas interregionales a través de Dask.
Requisitos previos
El paquete AWS CDK utiliza el lenguaje de programación TypeScript. Siga los pasos en Introducción a AWS CDK para configurar su entorno local y arrancar su cuenta de desarrollo (deberá arrancar todas las regiones especificadas en el Repositorio GitHub).
Para una implementación exitosa, necesitará Docker instalado y ejecutándose en su máquina local.
Implemente el paquete de CDK de AWS
La implementación de un paquete de CDK de AWS es sencilla. Después de instalar los requisitos previos y arrancar su cuenta, puede continuar con la descarga del código base.
- Descargue nuestra Repositorio GitHub:
- Instalar módulos de nodo:
- Implemente el CDK de AWS:
La pila puede tardar más de una hora y media en implementarse.
Tutorial de código
En esta sección, inspeccionamos algunas de las características clave del código base. Si desea inspeccionar el código base completo, consulte la Repositorio GitHub.
Configura y personaliza tu pila
En el archivo bin/variables.ts, encontrará dos declaraciones de variables: una para el cliente y otra para los trabajadores. La declaración del cliente es un diccionario con una referencia a una región y un rango CIDR. La personalización de estas variables cambiará tanto la región como el rango de CIDR donde se implementarán los recursos del cliente.
La variable de trabajo copia esta misma funcionalidad; sin embargo, es una lista de diccionarios para agregar o restar conjuntos de datos que el usuario desea incluir. Además, cada diccionario contiene los campos agregados de dataset y lustreFileSystemPath. El conjunto de datos se usa para especificar el URI de S3 de conexión para que Lustre se conecte. El lustreFileSystemPath La variable se usa como una asignación de cómo el usuario desea que ese conjunto de datos se asigne localmente en el sistema de archivos del trabajador. Ver el siguiente código:
Publicar dinámicamente la IP del programador
Un desafío inherente a la naturaleza interregional de este proyecto fue mantener una conexión dinámica entre los trabajadores de Dask y el programador. ¿Cómo podríamos publicar una dirección IP, que es capaz de cambiar, en las regiones de AWS? Pudimos lograr esto mediante el uso de Mapa de la nube de AWS y asociar-vpc-con-zona alojada. El servicio permite que AWS administre este espacio de nombres DNS de forma privada. Ver el siguiente código:
Interfaz de usuario de la libreta Jupyter
El cuaderno Jupyter alojado en SageMaker proporciona a los científicos un entorno listo para implementar para conectarse fácilmente y experimentar con los conjuntos de datos cargados. usamos un secuencia de comandos de configuración del ciclo de vida para aprovisionar el portátil con un entorno de desarrollador preconfigurado y una base de código de ejemplo. Ver el siguiente código:
Nodos trabajadores de Dask
Cuando se trata de los trabajadores de Dask, se proporciona una mayor personalización, más específicamente en el tipo de instancia, subprocesos por contenedor y alarmas de escala. De forma predeterminada, los trabajadores se aprovisionan en el tipo de instancia m5d.4xlarge, se montan en el sistema de archivos Lustre al iniciarse y subdividen sus trabajadores y subprocesos dinámicamente en puertos. Todo esto es opcionalmente personalizable. Ver el siguiente código:
Rendimiento
Para evaluar el rendimiento, usamos un cálculo de muestra y un gráfico de la temperatura del aire a 2 metros en función de la diferencia entre la predicción de CMIP6 para un mes y la temperatura media del aire de ERA5 para 10 años. Establecimos un punto de referencia de dos trabajadores en cada Región y evaluamos la diferencia en la reducción de tiempo a medida que se agregaron trabajadores adicionales. En teoría, a medida que la solución escala, debería haber una diferencia material productiva en la reducción del tiempo total.
La siguiente tabla resume los detalles de nuestro conjunto de datos.
| Conjunto de datos | Variables | Tamaño del disco | Tamaño del conjunto de datos de rayos X | Región |
| Era5 | 2011–2020 (120 archivos netcdf) | 53.5GB | 364.1 GB | nosotros-este-1 |
| CMIP6 | 1.13GB | 0.11 GB | nosotros-oeste-2 |
La siguiente tabla muestra los resultados recopilados, mostrando el tiempo (en segundos) para cada cálculo y predicción en tres etapas en el cálculo de la predicción CMIP6, ERA5 y diferencia.
| . | . | Numero de trabajadores | |||
| Calcular | Región | 2 (CMIP) + 2 (ERA) | 2 (CMIP) + 4 (ERA) | 2 (CMIP) + 8 (ERA) |
2 (CMIP) + 12 (ERA) |
CMIP6 (predicted_tas_regridded) |
nosotros-oeste-2 | 11.8 | 11.5 | 11.2 | 11.6 |
ERA5 (historic_temp_regridded) |
nosotros-este-1 | 1512 | 711 | 427 | 202 |
Diferencia (propogated pool) |
us-west-2 y us-east-1 | 1527 | 906 | 469 | 251 |
El siguiente gráfico visualiza el rendimiento y la escala.
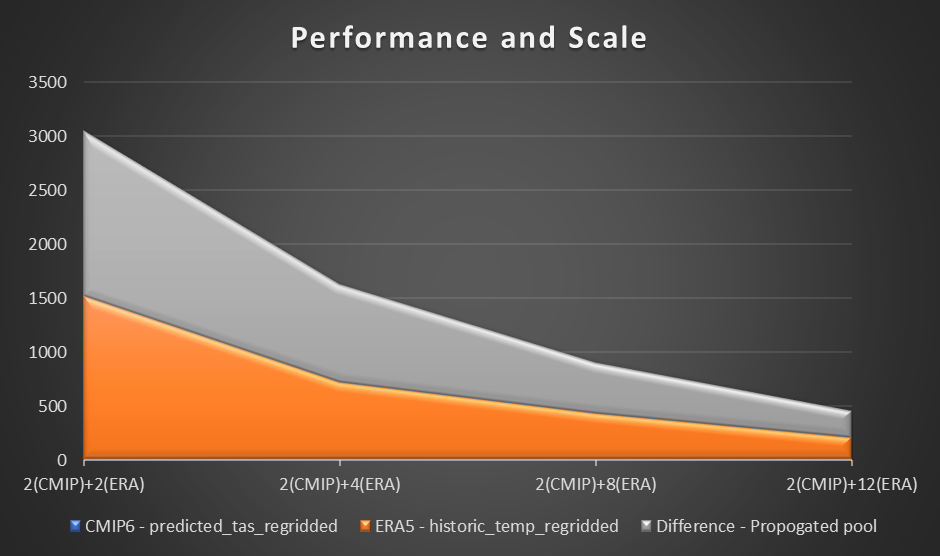
A partir de nuestro experimento, observamos una mejora lineal en el cálculo del conjunto de datos ERA5 a medida que aumentaba la cantidad de trabajadores. A medida que aumentaba el número de trabajadores, los tiempos de cálculo a veces se reducían a la mitad.
Cuaderno Jupyter
Como parte del lanzamiento de la solución, implementamos un Jupyter Notebook preconfigurado para ayudar a probar la solución Dask interregional. El cuaderno demuestra la eliminación de la preocupación de necesitar conocer la ubicación regional de los conjuntos de datos, en lugar de consultar un catálogo a través de una serie de cuadernos Jupyter que se ejecutan en segundo plano.
Para empezar, siga las instrucciones de esta sección.
El código de los cuadernos se puede encontrar en lib/SagemakerCode siendo el cuaderno principal ux_notebook.ipynb. Este cuaderno recurre a otros cuadernos y activa secuencias de comandos auxiliares. ux_notebook está diseñado para ser el punto de entrada para los científicos, sin necesidad de ir a otro lugar.
Para comenzar, abra este cuaderno en SageMaker después de implementar el CDK de AWS. AWS CDK crea una instancia de notebook con todos los archivos en el repositorio cargados y respaldados en un Compromiso de código de AWS repositorio.
Para ejecutar la aplicación, abra y ejecute la primera celda de ux_notebook. Esta celda ejecuta el get_variables bloc de notas en segundo plano, que le solicita que introduzca los datos que le gustaría seleccionar. Incluimos un ejemplo; sin embargo, tenga en cuenta que las preguntas solo aparecerán después de que se haya seleccionado la opción anterior. Esto es intencional para limitar las opciones desplegables y se puede configurar opcionalmente editando el get_variables cuaderno.
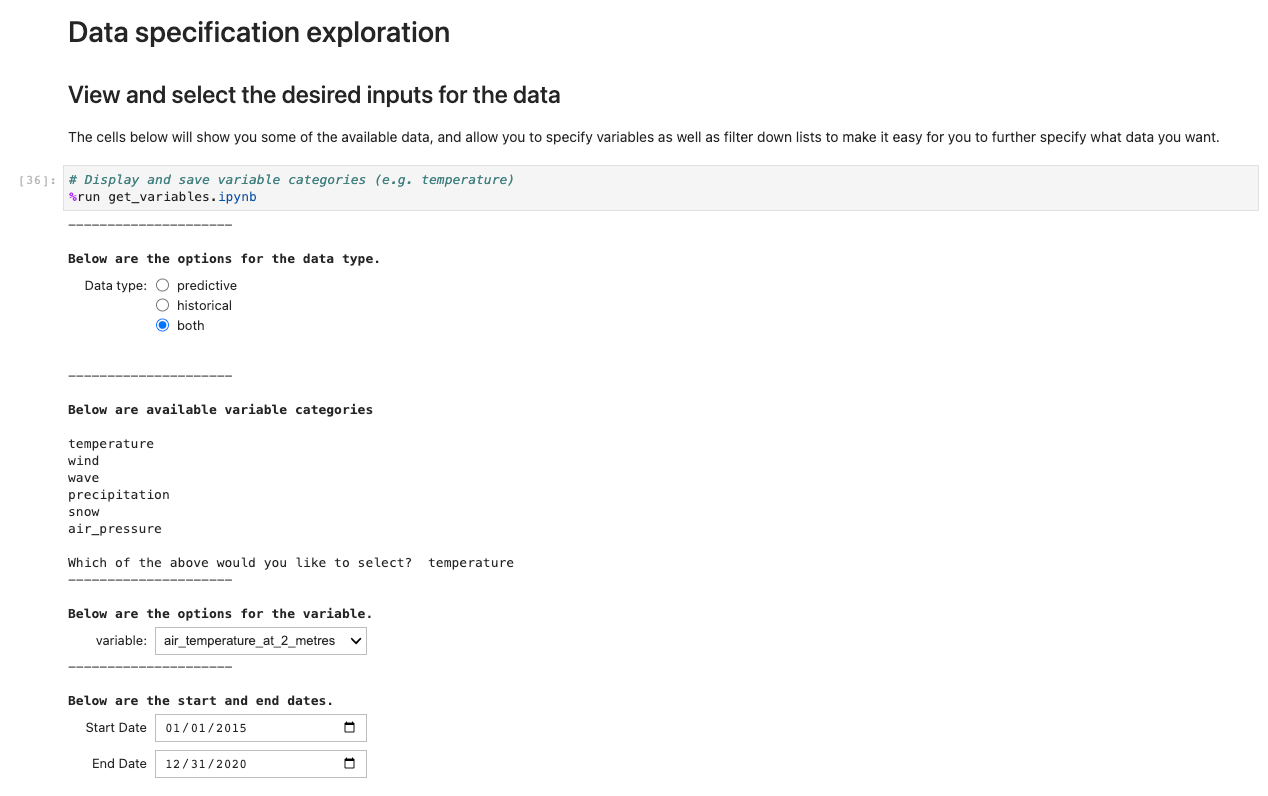
El código anterior almacena variables globalmente para que otros cuadernos puedan recuperar y cargar su selección de opciones. Para demostración, la siguiente celda debe mostrar las variables de guardado anteriores.
A continuación, aparece un aviso para más especificaciones de datos. Esta celda refina los datos que busca al presentar los ID de las tablas en un formato legible por humanos. Los usuarios seleccionan como si fuera un formulario, pero los títulos se asignan a tablas en segundo plano que ayudan al sistema a recuperar los conjuntos de datos apropiados.
Una vez que haya almacenado todas sus opciones y celdas de selección, cargue los datos en Regiones ejecutando la celda en el Obteniendo los datos set sección. El comando %%capture suprimirá las salidas innecesarias del get_data computadora portátil. Tenga en cuenta que puede eliminar esto para inspeccionar los resultados de los otros portátiles. Luego, los datos se recuperan en el backend.
Mientras que otros portátiles se ejecutan en segundo plano, el único punto de contacto para el usuario es el ux_notebook. Esto es para abstraer el tedioso proceso de importar datos a un formato que cualquier usuario pueda seguir con facilidad.
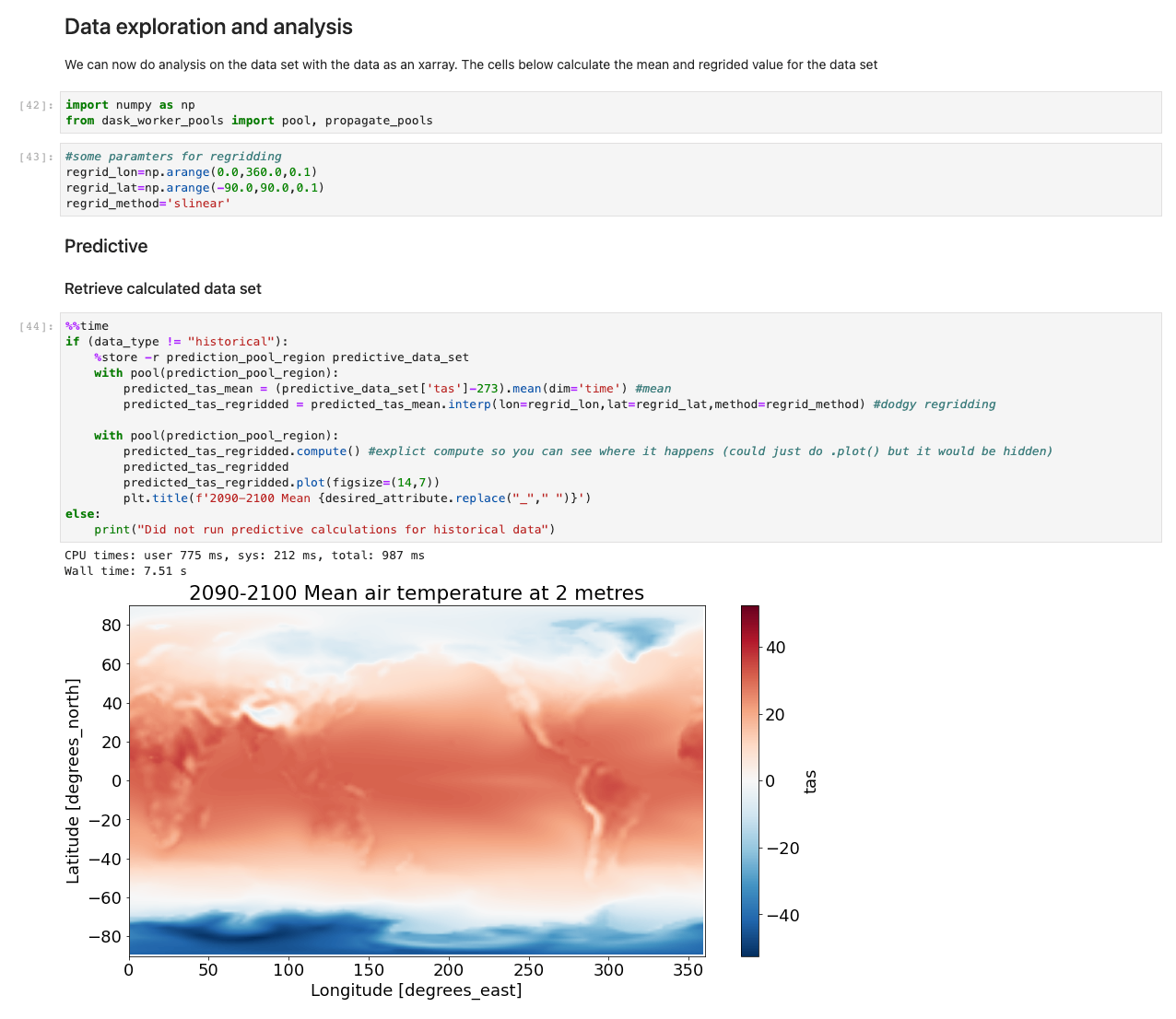
Con los datos ahora cargados, podemos comenzar a interactuar con ellos. Las siguientes celdas son ejemplos de cálculos que puede ejecutar en datos meteorológicos. Usando xarrays, importamos, calculamos y luego trazamos esos conjuntos de datos.
Nuestro ejemplo ilustra un gráfico de datos predictivos que recuperan datos, ejecutan el cálculo y grafican los resultados en menos de 7.5 segundos, órdenes de magnitud más rápido que un enfoque típico.
Bajo el capó
Los cuadernos get_catalog_input y get_variables usar la biblioteca ipywidgets para mostrar widgets como menús desplegables y selecciones de casillas múltiples. Estas opciones se guardan globalmente usando el comando %%store para que se pueda acceder a ellas desde el ux_notebook. Una de las opciones le pregunta si desea datos históricos, datos predictivos o ambos. Esta variable se pasa al get_data notebook para determinar qué notebooks subsiguientes ejecutar.
La get_data notebook primero recupera el dominio compartido de OpenSearch Service guardado en Almacén de parámetros de AWS Systems Manager. Este dominio permite que nuestro cuaderno ejecute una consulta sobre la recopilación de información que indicará dónde se almacenan los conjuntos de datos seleccionados a nivel regional. Con esos conjuntos de datos ubicados regionalmente, la computadora portátil intentará conectarse al programador Dask, pasando la información recopilada del servicio OpenSearch. El programador de Dask, a su vez, podrá llamar a los trabajadores en las regiones correctas.
Cómo personalizar y continuar el desarrollo
Estos cuadernos están destinados a ser un ejemplo de cómo puede crear una forma para que los usuarios interactúen e interactúen con los datos. El cuaderno de esta publicación sirve como ilustración de lo que es posible, y lo invitamos a continuar desarrollando la solución para mejorar aún más la participación de los usuarios. La parte central de esta solución es la tecnología de back-end, pero sin algún mecanismo para interactuar con ese back-end, los usuarios no se darán cuenta de todo el potencial de la solución.
Para evitar incurrir en cargos futuros, elimine los recursos. Destruyamos nuestra solución implementada con el siguiente comando:
Conclusión
Esta publicación muestra la extensión de Dask entre regiones en AWS y una posible integración con conjuntos de datos públicos en AWS. La solución se creó como un patrón genérico y se pueden cargar más conjuntos de datos para acelerar los análisis de E/S en datos complejos.
Los datos están transformando todos los campos y todos los negocios. Sin embargo, dado que los datos crecen más rápido de lo que la mayoría de las empresas pueden rastrear, recopilar datos y obtener valor de esos datos es un desafío. Una estrategia de datos moderna puede ayudarlo a crear mejores resultados comerciales con datos. AWS proporciona el conjunto de servicios más completo para el viaje de datos de un extremo a otro para ayudarlo a obtener valor de sus datos y convertirlos en información.
Para obtener más información sobre las diversas formas de usar sus datos en la nube, visite la Blog de grandes datos de AWS. Además, lo invitamos a comentar con sus pensamientos sobre esta publicación y si esta es una solución que planea probar.
Acerca de los autores
 Patrick O'Connor es un ingeniero de prototipos de WWSO con sede en Londres. Es un solucionador de problemas creativo, adaptable a una amplia gama de tecnologías, como IoT, tecnología sin servidor, tecnología espacial 3D y ML/AI, junto con una curiosidad implacable sobre cómo la tecnología puede seguir evolucionando en los enfoques cotidianos.
Patrick O'Connor es un ingeniero de prototipos de WWSO con sede en Londres. Es un solucionador de problemas creativo, adaptable a una amplia gama de tecnologías, como IoT, tecnología sin servidor, tecnología espacial 3D y ML/AI, junto con una curiosidad implacable sobre cómo la tecnología puede seguir evolucionando en los enfoques cotidianos.
 Chakra Nagarajan es Principal Machine Learning Prototyping SA con 21 años de experiencia en aprendizaje automático, big data y computación de alto rendimiento. En su puesto actual, ayuda a los clientes a resolver problemas comerciales complejos del mundo real mediante la creación de prototipos con soluciones integrales de inteligencia artificial y aprendizaje automático en la nube y dispositivos perimetrales. Su especialización en ML incluye visión por computadora, procesamiento de lenguaje natural, pronóstico de series temporales y personalización.
Chakra Nagarajan es Principal Machine Learning Prototyping SA con 21 años de experiencia en aprendizaje automático, big data y computación de alto rendimiento. En su puesto actual, ayuda a los clientes a resolver problemas comerciales complejos del mundo real mediante la creación de prototipos con soluciones integrales de inteligencia artificial y aprendizaje automático en la nube y dispositivos perimetrales. Su especialización en ML incluye visión por computadora, procesamiento de lenguaje natural, pronóstico de series temporales y personalización.
 valle cohen es un ingeniero senior de creación de prototipos de WWSO con sede en Londres. Como solucionadora de problemas por naturaleza, Val disfruta escribiendo código para automatizar procesos, construir herramientas obsesionadas con el cliente y crear infraestructura para varias aplicaciones para su base global de clientes. Val tiene experiencia en una amplia variedad de tecnologías, como desarrollo web front-end, trabajo de back-end e IA/ML.
valle cohen es un ingeniero senior de creación de prototipos de WWSO con sede en Londres. Como solucionadora de problemas por naturaleza, Val disfruta escribiendo código para automatizar procesos, construir herramientas obsesionadas con el cliente y crear infraestructura para varias aplicaciones para su base global de clientes. Val tiene experiencia en una amplia variedad de tecnologías, como desarrollo web front-end, trabajo de back-end e IA/ML.
 niall robinson es Jefe de futuros de productos en la Oficina Meteorológica del Reino Unido. Él y su equipo exploran nuevas formas en que Met Office puede brindar valor a través de la innovación de productos y asociaciones estratégicas. Ha tenido una carrera variada, liderando un equipo multidisciplinario de I+D en informática, investigación académica en ciencia de datos y científico de campo junto con experiencia en modelado climático.
niall robinson es Jefe de futuros de productos en la Oficina Meteorológica del Reino Unido. Él y su equipo exploran nuevas formas en que Met Office puede brindar valor a través de la innovación de productos y asociaciones estratégicas. Ha tenido una carrera variada, liderando un equipo multidisciplinario de I+D en informática, investigación académica en ciencia de datos y científico de campo junto con experiencia en modelado climático.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Compra y Vende Acciones en Empresas PRE-IPO con PREIPO®. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/build-efficient-cross-regional-i-o-intensive-workloads-with-dask-on-aws/
- :posee
- :es
- :dónde
- $ UP
- 1
- 10
- 100
- 11
- 12
- 20
- 24
- 3d
- 40
- 50
- 7
- 9
- a
- capacidad
- Poder
- Nuestra Empresa
- arriba
- RESUMEN
- enviados
- académico
- la investigación académica
- acelerar
- acelerador
- de la máquina
- visitada
- acomodar
- lograr
- Mi Cuenta
- Logra
- a través de
- se adapta
- adicional
- la adición de
- Adicionales
- Adicionalmente
- dirección
- direccionamiento
- Añade
- administradores
- adoptado
- Adopción
- Después
- AI / ML
- AIRE
- Todos
- Permitir
- permite
- a lo largo de
- también
- Amazon
- Amazon EC2
- an
- análisis
- y
- cualquier
- Aparecer
- Aplicación
- aplicaciones
- enfoque
- enfoques
- adecuado
- arquitectura
- somos
- AS
- At
- Atmósfera
- atmosférico
- automatizado
- evitar
- AWS
- Cliente de AWS
- Columna vertebral
- Respaldados
- Backend
- fondo
- Balance
- bases
- basado
- BE
- a las que has recomendado
- esto
- antes
- "Ser"
- a continuación
- mejores
- entre
- Big
- Big Data
- Bootstrap
- ambas
- Trayendo
- Roto
- build
- Construir la
- construido
- incorporado
- pero
- by
- calcular
- llamar al
- , que son
- llamar
- Calls
- PUEDEN
- capacidades
- capaz
- Propósito
- catalogar
- CD
- Células
- Reto
- desafiante
- el cambio
- cambio
- CHARGE
- cargos
- opciones
- Circulación
- cliente
- Clima
- más cerca
- Soluciones
- Médico
- CO
- código
- base de código
- colaboración
- El cobro
- cómo
- proviene
- viniendo
- comentario
- vibrante e inclusiva
- Empresas
- completar
- integraciones
- componentes
- Compuesto
- cálculo
- Calcular
- computadora
- Visión por computador
- informática
- Configuración
- Contacto
- conectado
- Conectándote
- conexión
- Clientes
- consumo
- Envase
- contiene
- continue
- continúa
- copias
- Core
- correcta
- Cost
- rentable
- podría
- acoplado
- CPU
- Para crear
- crea
- Estudio
- crítico
- cultivo
- Cruz
- la curiosidad
- Current
- personalizado
- cliente
- Clientes
- personalizable
- personalizan
- todos los días
- página de información de sus operaciones
- datos
- Ciencia de los datos
- estrategia de datos
- conjuntos de datos
- día
- década
- decisiones
- Predeterminado
- Demanda
- demuestra
- desplegar
- desplegado
- despliegue
- despliega
- diseñado
- destruir
- detallado
- detalles
- Determinar
- desarrollar
- Developer
- Desarrollo
- Dispositivos
- un cambio
- discapacitados
- descubrimiento
- Pantalla
- distribuidos
- Computación distribuída
- dns
- Docker
- dominio
- DE INSCRIPCIÓN
- lugar de trabajo dinámico
- dinamicamente
- cada una
- facilidad
- pasan fácilmente
- Southern Implants
- .
- eficiente
- en otra parte
- habilitar
- de extremo a extremo
- energía
- de su negocio.
- ingeniero
- entrada
- Entorno
- Equivalente a
- Era
- estimado
- Éter (ETH)
- Cada
- diario
- diario
- evoluciona
- ejemplo
- ejemplos
- experience
- experimento
- Experiencia
- explorar
- exportar
- expuesto
- extensión
- más rápida
- Feature
- Caracteristicas
- campo
- Terrenos
- Archive
- archivos
- Encuentre
- Nombre
- se centra
- seguir
- siguiendo
- Comida
- formulario
- formato
- Formularios
- encontrado
- Fundado
- Marco conceptual
- marcos
- Gratis
- Desde
- fruición
- ser completados
- a la fatiga
- promover
- futuras
- Futuros
- General
- generación de AHSS
- obtener
- conseguir
- Git
- Buscar
- red global
- En todo el mundo
- globo
- va
- gráfica
- mayor
- Cuadrícula
- Crecer
- Creciendo
- tenido
- A Mitad
- cortado por la mitad
- Tienen
- he
- cabeza
- ayuda
- ayuda
- aquí
- Alta
- Alto rendimiento
- destacados
- su
- histórico
- fortaleza
- organizado
- horas.
- Cómo
- Como Hacer
- Sin embargo
- HTML
- HTTPS
- legible por humanos
- Cientos
- Idle
- ids
- if
- ilustra
- importar
- importador
- mejorar
- es la mejora continua
- in
- incluir
- incluye
- aumentado
- índice
- indicar
- informar
- información
- EN LA MINA
- inherente
- Innovation
- Las opciones de entrada
- inseguridad
- penetración
- inspirado
- instalar
- ejemplo
- Instrucciones
- integración
- Intencional
- interactuar
- interactuando
- Interfaz
- interno
- Internet
- dentro
- invitar
- IOT
- IP
- Dirección IP
- cuestiones
- IT
- SUS
- Trabajos
- jpg
- Cuaderno Jupyter
- Guardar
- Clave
- Saber
- idioma
- large
- Apellidos
- Estado latente
- lanzamiento
- líder
- APRENDE:
- aprendizaje
- Biblioteca
- ciclo de vida
- como
- Etiqueta LinkedIn
- enlace
- Lista
- carga
- local
- localmente
- situados
- Ubicación
- Londres
- máquina
- máquina de aprendizaje
- gran
- para lograr
- gestionan
- gerente
- gestiona
- mapa
- cartografía
- Misa
- Adopción masiva
- materiales
- Puede..
- personalizado
- mecanismo
- metadatos
- millones
- ML
- modelo
- Moderno
- Módulos
- Mes
- mensual
- datos mensuales
- más,
- MEJOR DE TU
- MONTE
- multidisciplinario
- nombre
- Nacional
- Natural
- Lenguaje natural
- Procesamiento natural del lenguaje
- Naturaleza
- necesario
- ¿ Necesita ayuda
- necesidad
- del sistema,
- Nuevo
- Next
- noche
- nodo
- nodos
- cuaderno
- ordenadores portátiles
- ahora
- número
- números
- of
- LANZAMIENTO
- Oficina
- on
- ONE
- , solamente
- habiertos
- datos abiertos
- de código abierto
- código de fuente abierta
- operativos.
- Optión
- Opciones
- or
- orquestación
- para las fiestas.
- Otro
- nuestros
- salir
- resultados
- salida
- Más de
- total
- paquete
- parámetro
- parte
- particular
- particularmente
- asociaciones
- pasado
- Pasando (Paso)
- Patrón de Costura
- actuación
- períodos
- personalización
- petabyte
- fase
- plan
- Plataformas
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- punto
- alberca
- puertos
- posible
- Publicación
- posible
- industria
- poderoso
- predicción
- Predicciones
- requisitos previos
- anterior
- primario
- Director de la escuela
- privada
- Problema
- problemas
- en costes
- tratamiento
- producido
- Producto
- Innovación de producto
- productivo
- Programa
- Programación
- proyecto
- prototipos
- prototipado
- proporcionar
- previsto
- proporciona un
- provisión
- público
- publicar
- publicado
- Tira
- consultas
- Preguntas
- I + D
- distancia
- más bien
- confeccionado
- mundo real
- darse cuenta de
- reducir
- la reducción de
- reducción
- región
- regional
- regiones
- implacable
- permanece
- remove
- Remoto
- repositorio
- representa
- la investigación
- Recursos
- aquellos
- Resultados
- Función
- Ejecutar
- correr
- SA
- ambiente seguro
- sabio
- mismo
- Guardar
- escalable
- Escala
- escamas
- la ampliación
- Ciencia:
- Científico
- los científicos
- guiones
- segundos
- Sección
- ver
- visto
- segmentos
- seleccionado
- selección
- mayor
- Serie
- Sin servidor
- sirve
- de coches
- Servicios
- set
- Compartir
- compartido
- tienes
- Mostrar
- Demostramos a usted
- Shows
- sencillos
- simplemente
- sexto
- lento
- So
- a medida
- Soluciones
- RESOLVER
- algo
- Fuente
- Espacial
- específicamente
- Especificaciones
- especificado
- patrocinio
- montón
- etapas
- independiente
- comienzo
- fundó
- quedarse
- pasos
- STORAGE
- tienda
- almacenados
- tiendas
- sencillo
- Estratégico
- Socios Estratégicos
- Estrategia
- posterior
- Después
- exitosos
- tal
- Superficie
- oleada
- Sostenibilidad
- sostenible,
- te
- Todas las funciones a su disposición
- mesa
- ¡Prepárate!
- equipo
- tecnología
- Tecnologías
- Tecnología
- test
- que
- esa
- La
- la información
- La Fuente
- el Reino Unido
- el mundo
- su
- luego
- Ahí.
- de este modo
- Estas
- ellos
- así
- aquellos
- Tres
- Prosperar
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- rendimiento
- equipo
- Series de tiempo
- veces
- títulos
- a
- hoy
- juntos
- seguir
- Seguimiento
- transferir
- transformadora
- tránsito
- desencadenando
- GIRO
- dos
- tipo
- Mecanografiado
- principiante
- Uk
- bajo
- desbloquear
- insostenible
- hasta a la fecha
- Actualizaciones
- a
- URI
- Uso
- utilizan el
- usado
- Usuario
- usuarios
- usando
- UTC
- Utilizando
- VAL
- propuesta de
- variedad
- diversos
- vía
- visión
- Visite
- volumen
- quieres
- quiere
- caliente
- fue
- Camino..
- formas
- we
- Tiempo
- web
- Desarrollo web
- tuvieron
- sean
- que
- amplio
- Amplia gama
- seguirá
- deseos
- sin
- Actividades:
- obrero
- los trabajadores.
- mundo
- preocuparse
- se
- la escritura
- años
- aún
- Rendimiento
- Usted
- tú
- zephyrnet